长上下文模型(1M token)会杀死RAG吗?—— 理性分析
摘要: 随着Gemini 1.5 Pro、Claude 3等模型支持百万级token上下文,有人认为长上下文模型将取代RAG(检索增强生成)。但实际分析表明,长上下文模型存在四大硬伤:高昂成本(如GPT-4 Turbo处理500K token需5美元/次)、延迟问题(O(n²)复杂度)、注意力稀释(关键信息易遗漏)和知识更新困难。相比之下,RAG在成本、实时性、可解释性上优势显著,尤其适合企业级场
写在前面
2024年以来,Gemini 1.5 Pro 率先将上下文窗口扩展到1M token,随后Claude 3支持200K、GPT-4 Turbo支持128K,国内厂商也纷纷推出百万token级别的模型。一时间,“长上下文模型将杀死RAG”的声音甚嚣尘上。有人认为:既然能把整本书甚至整个知识库塞进Prompt,何必还要复杂的检索增强?作为RAG开发者,我一开始也有点慌——难道辛辛苦苦搭的向量库、切分策略、重排序全都白费了?但冷静下来分析几个实际数据之后,我发现:长上下文模型不但不会杀死RAG,反而可能让RAG变得更重要。本文将从成本、效果、可维护性三个维度,理性分析两者的关系。

一、长上下文模型的“高光时刻”
先看一组数据:
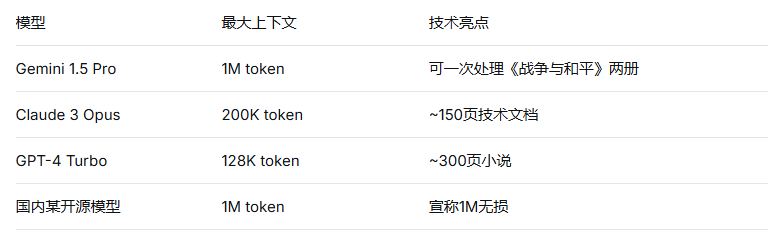
这些模型可以一次性接收海量文本,用户不再需要切分文档、构建索引。对于“读完整本书然后回答问题”这类任务,长上下文模型确实直击痛点——直接丢进去就行,无需任何预处理。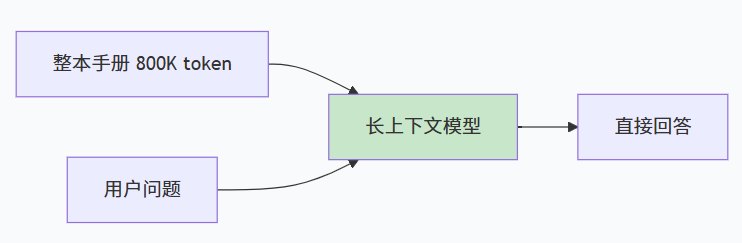
二、光鲜背后的四个“硬伤”
2.1 成本:算力不是免费的
以GPT-4 Turbo为例,输入10/1Mtoken,输出10/1Mtoken,输出30/1M token。如果每次问答都塞进500K token的上下文,仅输入成本就高达$5/次。而对于一个日活10万的应用,一天的成本就是50万美元——这还没算输出和推理延迟。相比之下,RAG的向量检索成本几乎可以忽略。
2.2 延迟:越长越慢
Transformer的注意力计算复杂度是O(n²),上下文越长,推理时间呈平方级增长。1M token的模型,一次前向传播可能需要几十秒甚至几分钟。用户不会为了一次查询等待半分钟。RAG可以把响应时间控制在1-2秒内。
2.3 注意力稀释:“大海捞针”依然难
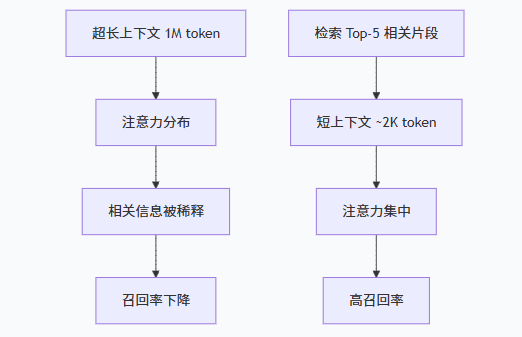
尽管厂商宣传“1M无损”,但实际测试表明:当相关信息分散在超长上下文中时,模型很容易“漏掉”关键信息。著名的“大海捞针”(Needle in a Haystack)测试中,长上下文模型在文档中间位置的召回率明显下降。原因很简单:注意力机制会平均分配给所有token,而真正相关的信息可能只占0.1%。RAG通过检索将相关片段集中到几K token内,让模型只关注最相关的内容。
2.4 知识更新:模型不能动态重训
企业内部知识库每天都有新文档加入、旧文档修订。长上下文模型要么每次重新加载全部内容(成本爆炸),要么需要重新微调(不现实)。RAG则可以实时更新向量库,增删改查随心所欲。
三、RAG的“护城河”:低成本、可扩展、可解释
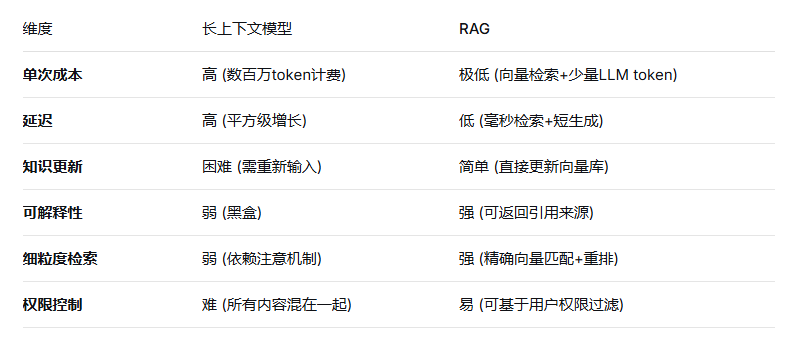
尤其在企业级场景中,可解释性是刚需。用户希望知道答案来自哪份文档、哪个章节。RAG天然支持来源引用,而长上下文模型只能给出答案,无法精确溯源。
四、两者不是替代,而是互补
理性看待:长上下文模型和RAG解决的是不同层面的问题。
-
长上下文模型适合:一次性理解超长文档(如分析年报、审阅合同)、需要全局推理的任务(如找出一本书中的矛盾点)、小规模数据集的临时分析。
-
RAG适合:大规模知识库问答(百万级文档)、需要实时更新的场景、成本敏感的生产环境、对可解释性有要求的业务。
更聪明的做法是混合架构:
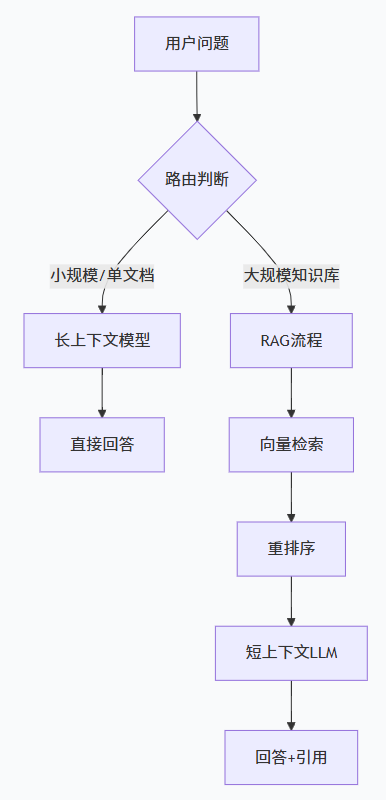
也有一类工作探索RAG增强长上下文模型:先用RAG从超长文档中检索出最相关的片段,再交给长上下文模型进行深度推理——兼顾效率与效果。
五、结论:RAG不会死,只会进化
长上下文模型的出现确实让RAG面临“被替代”的质疑,但深入分析后会发现:
-
成本:长上下文模型太贵,无法大规模商业化。
-
延迟:用户体验不允许等待几十秒。
-
注意力稀释:长文本中的信息召回率不如检索。
-
动态知识:RAG更新成本远低于重新加载或微调。
未来的趋势更可能是:短上下文时用RAG,长上下文时用“RAG + 长上下文模型”的混合体。RAG不会死,反而会因为长上下文模型的出现,催生出更智能的检索路由和上下文压缩技术。
如果你的企业内部知识库有100万份文档,每次用户提问都需要全局理解,你会选择把全部文档塞进1M上下文的模型(假设能塞下),还是用RAG检索Top-5后交给模型?为什么?欢迎在评论区展示你的技术选型思路。

欢迎加入DeepSeek 技术社区。在这里,你可以找到志同道合的朋友,共同探索AI技术的奥秘。
更多推荐
 9
9 0
0- 0



 已为社区贡献2条内容
已为社区贡献2条内容

所有评论(0)