本地大模型推理实战
摘要: 本文记录了本地大模型从部署到落地的实践过程,重点介绍了Ollama在Windows环境下的安装与推理环境搭建。文章详细说明了硬件推荐配置(如RTX3060显卡、≥16GB内存),并指导用户通过nvidia-smi验证GPU环境。Ollama的安装步骤包括下载、版本验证及运行DeepSeek、Qwen等模型。此外,还提供了模型存储路径、GPU参与推理的验证方法及常见问题解决方案(如显存不足、
目录
0. 前言
过去一年,本地大模型推理已经从“极客玩法”逐渐进入企业实际应用。
最近两年时间里,我开始在实际项目中尝试将大模型部署到本地硬件环境,并把大模型作为推理引擎,用于输出业务分析与辅助决策建议。
从 DeepSeek 到 Qwen,再到 Llama 系列,越来越多开发者开始尝试:
- 在个人电脑运行AI
- 构建本地知识库
- 私有化部署大模型
- 使用 Ollama 搭建 AI 开发环境
- 基于本地模型构建行业推理应用
但真正开始实践后会发现,问题远比“安装成功”复杂:
- 什么显卡才能真正跑得动?
- 16GB 内存到底够不够?
- Windows 与 Linux 推理性能差异有多大?
- 为什么相同模型在不同机器上的输出结果并不一致?
- 为什么长时间推理后系统会出现卡顿甚至崩溃?
因此,我准备通过这个系列,完整记录本地大模型从部署到落地实践的全过程,包括:
- Ollama 安装与本地推理环境搭建
- DeepSeek / Qwen 模型部署实战
- 多种硬件平台推理性能对比
- 本地大模型长时间稳定性测试
- Ollama API 开发实战
- 企业级本地 AI 部署方案实践
希望能够给正在尝试本地 AI部署的开发者一些真实、可落地的参考,也记录自己在本地 AI 推理实践过程中的一些经验与踩坑。
第一章Ollama 安装与本地推理环境搭建
1.1. Windows 环境要求
在
在开始之前,建议先确认当前电脑是否满足本地推理的基础要求。
虽然 Ollama 对硬件要求并不算特别高,但模型推理会持续占用:
• GPU显存
• 系统内存
• 硬盘缓存
• CPU 调度资源
如果配置过低,可能会出现:
• 推理速度过慢
• GPU 无法加载模型
• 系统卡顿
• 长时间运行崩溃
推荐配置如下
|
项目 |
推荐配置 |
|
操作系统 |
Windows 10 / Windows 11 64位 |
|
内存 |
≥16GB(推荐32GB) |
|
显卡 |
NVIDIA RTX 系列(推荐 RTX3060 及以上) |
|
显存 |
建议 8GB 以上 |
|
硬盘空间 |
至少 50GB 可用空间 |
|
显卡驱动 |
最新 NVIDIA 驱动 |
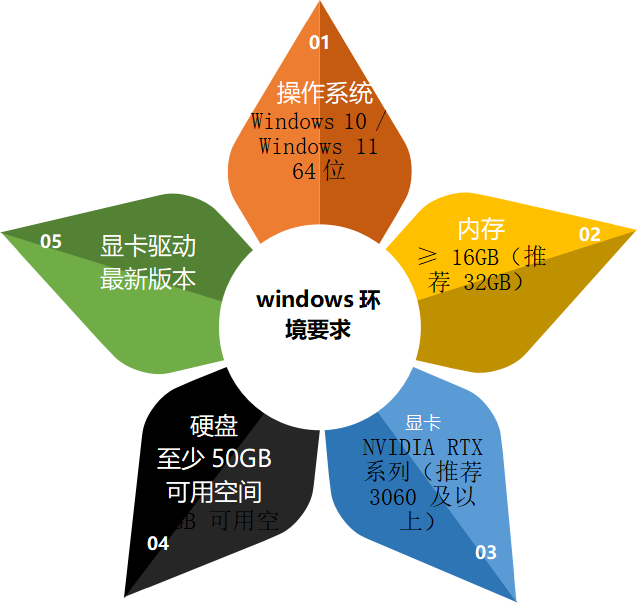
实际测试中,RTX2060 虽然能够运行部分 7B 模型,但长时间推理时显存压力会比较明显;而 RTX3060 12GB 在本地开发环境下会更加稳定。
1.2. 检查 NVIDIA 显卡环境
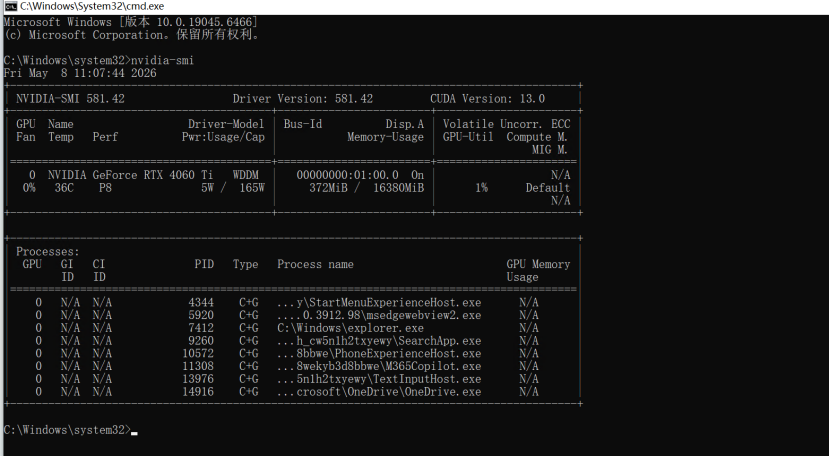
在安装 Ollama 之前,建议先确认 GPU 是否能够被系统正常识别。
打开命令行执行:
nvidia-smi
如果能够看到以下信息:
• GPU 型号
• 显存大小
• 驱动版本
• CUDA 版本
说明当前 GPU 环境基本正常。
如果无法识别 GPU,则需要优先安装 NVIDIA 驱动。
在开始安装之前,先确认 GPU 是否正常工作。
打开命令行执行:
nvidia-smi
1.3. 安装 Ollama
Ollama 是目前本地大模型部署中最流行的工具之一。
它最大的优势是:
• 安装简单
• 模型管理方便
• 支持多种主流模型
• API 调用非常友好
• 对开发者环境支持较好
1.3.0图文示意步骤
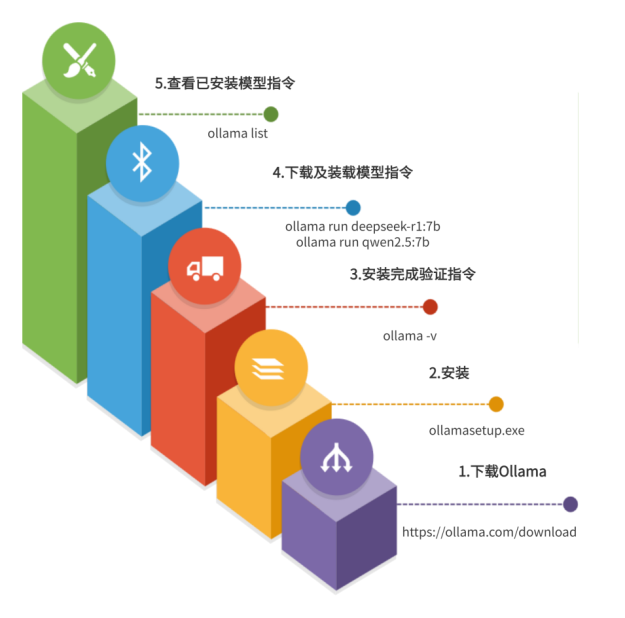
1.3.1 下载 Ollama
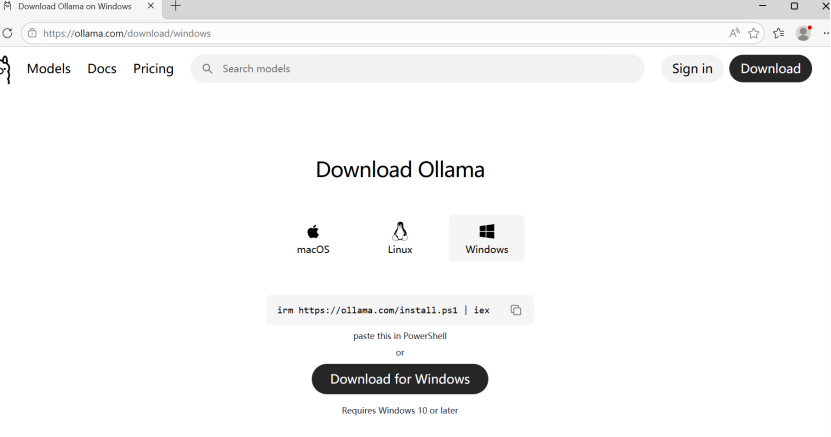
访问网站有以下几个:
- 文档(Docs):https://docs.ollama.com
- 下载页面:https://ollama.com/download
- GitHub(开源代码):https://github.com/ollama/ollama
访问官网如下所示:
下载 Windows 版本并安装。
1.3.2 安装完成验证
安装完成后打开命令行,执行:
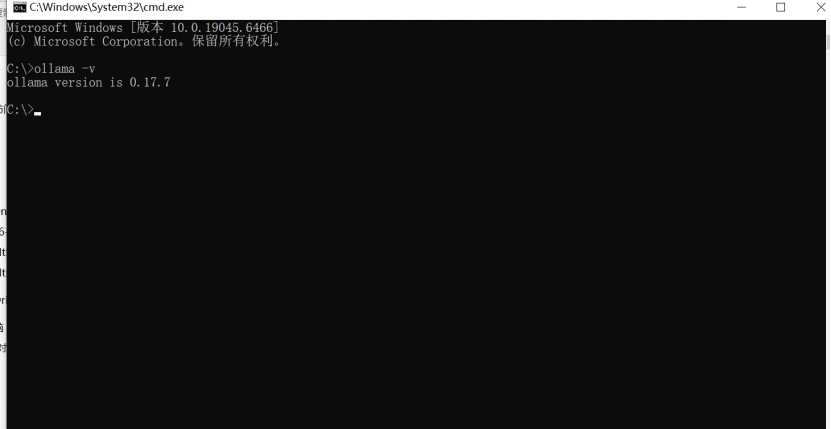
ollama -v
如果输出版本号,说明安装成功,如下图所示:
1.4. 运行第一个本地模型
Ollama 支持大量主流开源模型,例如:
• DeepSeek
• Qwen
• Llama
• Gemma
• Mistral
首次运行模型时,系统会自动下载模型文件。
不同模型指令图形示意
不同模型指令图形示意如下:

1.4.1 运行 DeepSeek 模型
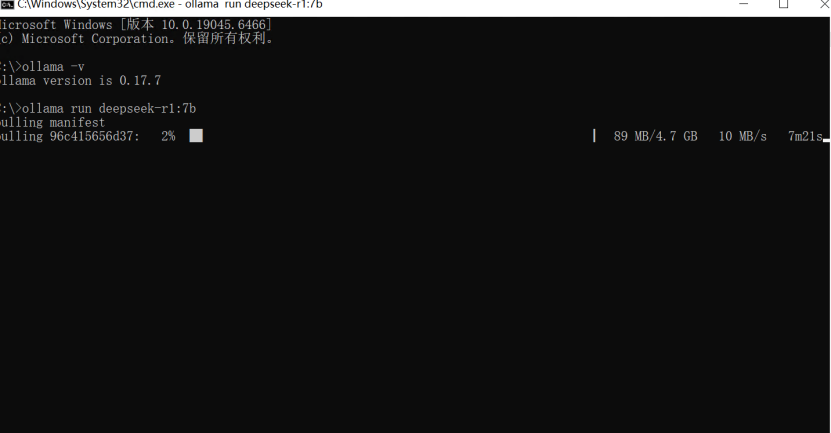
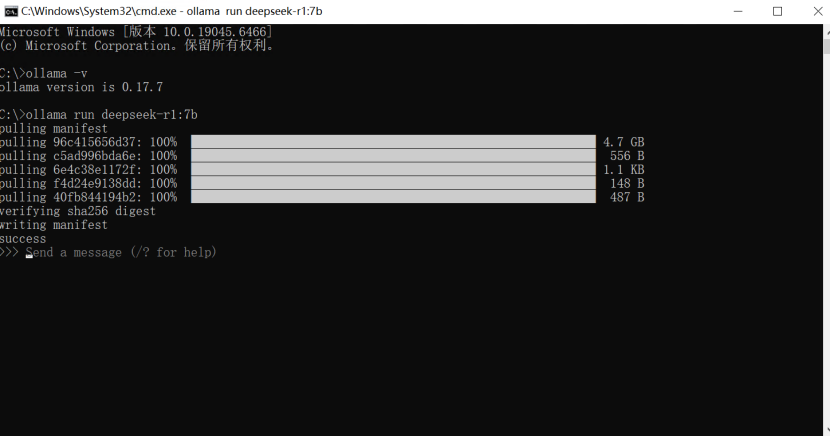
ollama run deepseek-r1:7b
首次运行时会自动下载模型,请耐心等待。如下图所示

1.4.2 运行 Qwen 模型
ollama run qwen2.5:7b
1.4.3 运行 Llama 模型
ollama run llama3
1.5. 查看已安装模型
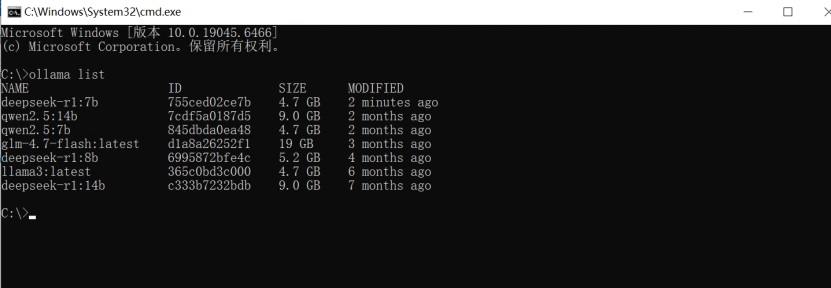
ollama list
可以看到当前本地已下载的模型列表。如下图所示:
1.6. 模型存储位置(Windows)
Ollama 默认模型存储路径,具体取决于安装时候的设置。
C:\Users\你的用户名\.ollama\models
如果后续需要清理空间,可以从这里管理模型文件。
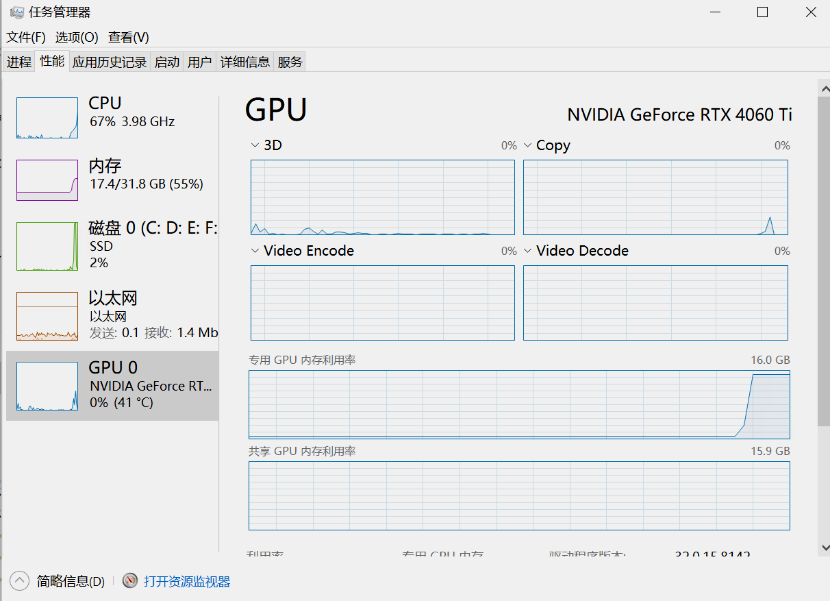
1.7. 验证 GPU 是否参与推理
例如要求写个集装箱算法:如下示意:
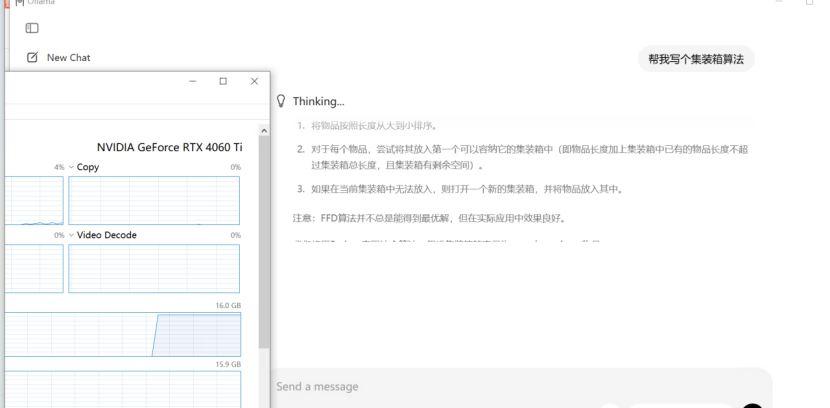
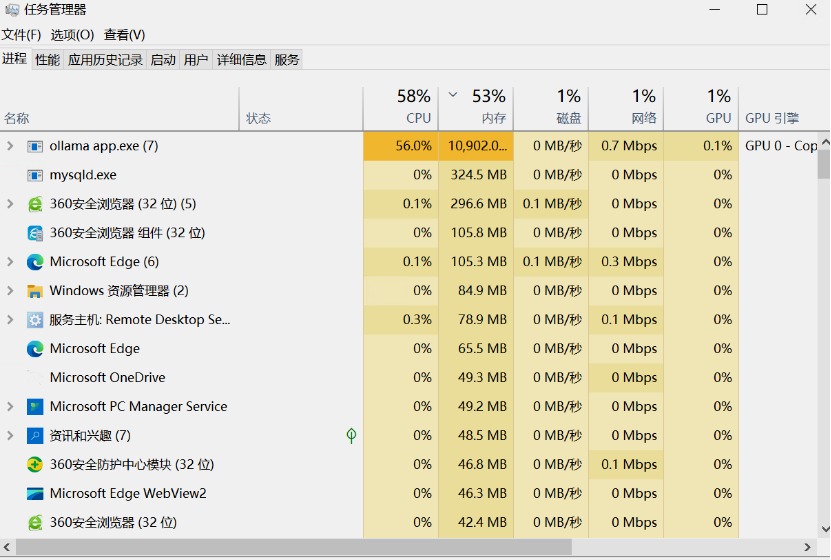
在模型运行时,可以打开:
- 任务管理器
- 性能 → GPU
观察:
- GPU 利用率是否上升
- 显存是否占用
如果 GPU 有明显使用,说明推理已经在 GPU 上运行。如下图所示:
1.8. 常见问题
- 模型运行很慢:通常是因为模型运行在 CPU 上、显存不足或者模型规模过大。
- GPU 没有被调用:检查 NVIDIA 驱动、CUDA 环境以及当前是否误使用了集成显卡。
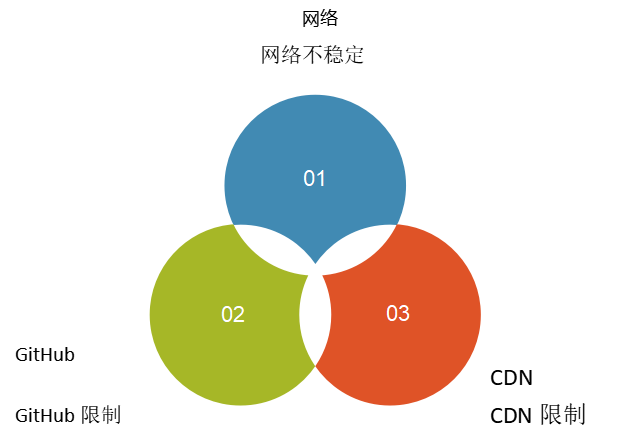
- 模型下载失败:可能与网络环境、GitHub/CDN 访问限制有关。
- 显存不足:建议优先使用 7B 模型或量化版本模型。
1.8.1 模型运行很慢
可能原因如下示意:

1.8.2 GPU 没有被使用
检查示意如下图所示:

1.8.3 下载模型失败
可能原因如下图示意:
1.8.4 显存不足
建议如下示意:

1.9. 本章总结
通过本章,我们已经完成:
• Windows 本地 AI 环境准备
• NVIDIA GPU 环境验证
• Ollama 安装
• 本地模型运行
• GPU 推理验证

此时你已经具备了一个最基础的本地大模型运行环境。

欢迎加入DeepSeek 技术社区。在这里,你可以找到志同道合的朋友,共同探索AI技术的奥秘。
更多推荐



 11
11 0
0- 0



 已为社区贡献1条内容
已为社区贡献1条内容

所有评论(0)