告别API收费,ollama+Deepseek 本地部署 全攻略!
告别API收费,ollama+Deepseek 本地部署 全攻略!
什么是ollama
Ollama 是一个免费、开源、跨平台的工具,让你能在自己的电脑(Windows/macOS/Linux)上一键运行、管理各种开源大语言模型(如 DeepSeek、 Llama 3、Qwen、Gemma 等),完全本地、离线、隐私安全。
Ollama官网:https://ollama.com/
Ollama的优势
一、核心定位:LLM 的 "Docker"
- 它不是模型本身,而是模型管理器 / 运行时。
- 作用:把复杂的本地部署(环境、依赖、量化、GPU 加速)全部自动化,一行命令跑 AI。
- 口号:Get up and running with large language models.(快速跑起大模型)Ollama
二、主要特点
- 开箱即用
-
- 自动下载、配置、量化、启动模型。
- 不需要懂 CUDA、Python、深度学习环境。
- 跨平台
-
- Windows、macOS、Linux、Docker 全支持。
- 模型库极丰富
-
- 支持 Llama 3、Mistral、Gemma、Qwen(通义千问)、DeepSeek、CodeLlama、LLaVA(多模态看图)等Ollama。
- 硬件友好
-
- 自动 4-bit 量化,8GB 内存就能跑 7B 模型。
- 支持 CPU / NVIDIA GPU / Apple Silicon 加速Ollama。
- API 服务化
-
- 启动后自动提供 REST API(兼容 OpenAI 格式)Ollama。
- 可直接接入你的 Java / 前端 / Python 项目(你正在做的 RAG 项目非常适合)。
- 隐私安全
-
- 所有数据、对话都在本地,绝不外传。
Windows安装Ollama
ollama官网:https://ollama.com/download
下载完成直接安装即可
Ollama 模型选择 × 电脑配置对照表
表格
|
你的电脑配置 |
推荐模型 |
模型大小 |
速度 |
适合场景 |
|
8GB 内存 / 无独显 / 轻薄本 |
qwen2:0.5b / tinyllama |
0.5B~1.1B |
极快 |
简单问答、测试、学习 |
|
16GB 内存 / 无独显 / 办公本 |
qwen2:1.8b / gemma:2b |
1.8B~2B |
流畅 |
日常对话、简单 RAG 测试 |
|
16GB 内存 + 入门独显(4G) |
llama3:8b / qwen2:7b |
7B~8B |
流畅 |
正式 RAG、知识库、企业问答 |
|
24GB 内存 + 中高端显卡(6G+) |
llama3:8b / qwen2:7b / qwen:14b |
7B~14B |
很快 |
高质量 RAG、长文本、多轮对话 |
|
32GB 内存 + 高性能显卡(8G+) |
llama3:70b / qwen:32b |
32B+ |
较快 |
专业级、复杂推理、企业级应用 |
这里我们选择先简单下载一个模型,做测试,生产环境 需严格评估 适用的大模型。
下载DeepSeek 大模型
下载deepseek-1.5b
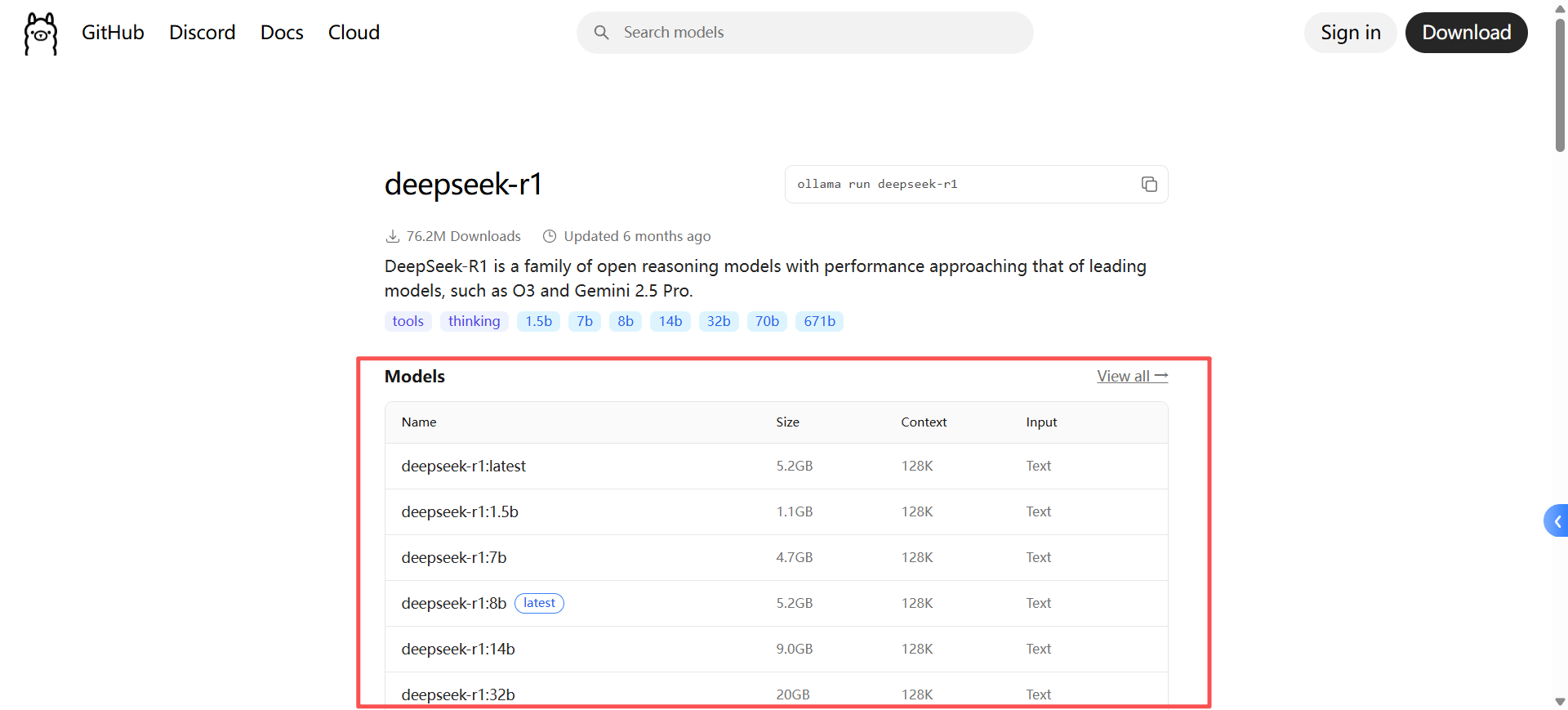
这里根据自己的机器版本部署模型就可以
打开cmd窗口
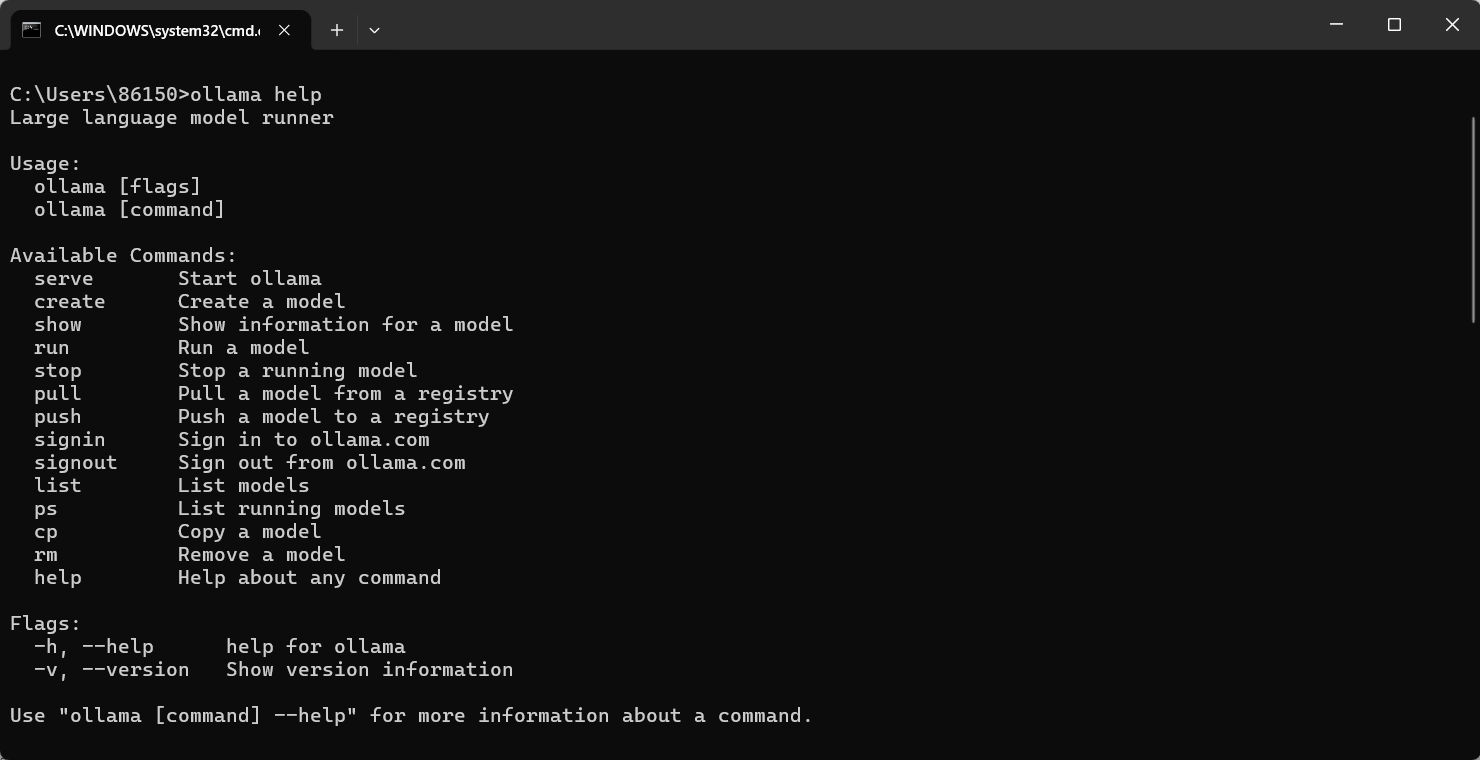
安装deepseek-1.5b
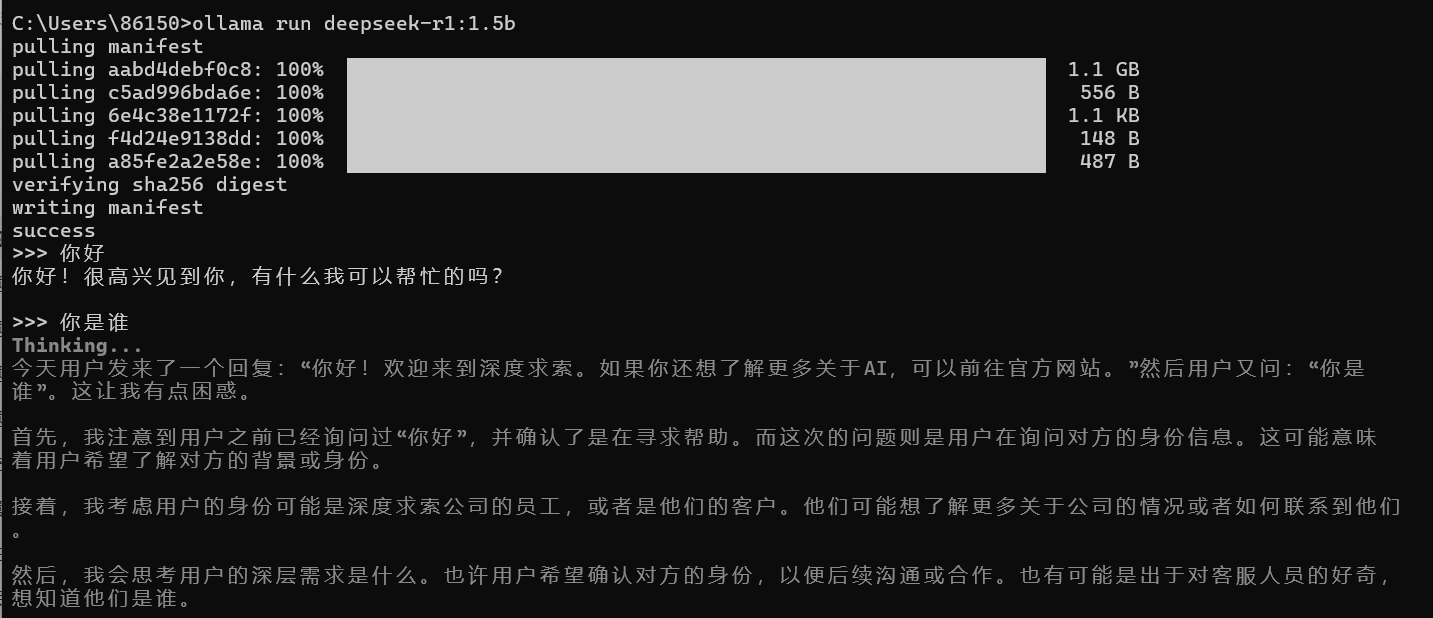
下载向量模型
下载向量模型
我们想要使用deepseek rag,需要用到向量数据库
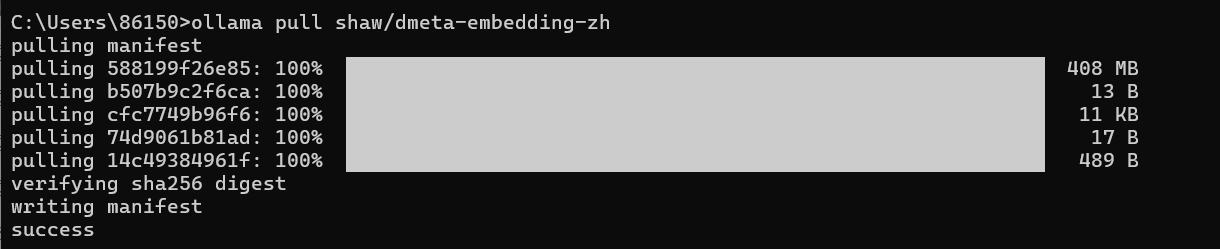
安装向量模型
查看已安装的模型列表

测试Ollama
打开Ollama对话框,输入问题,等待大模型返回响应结果。
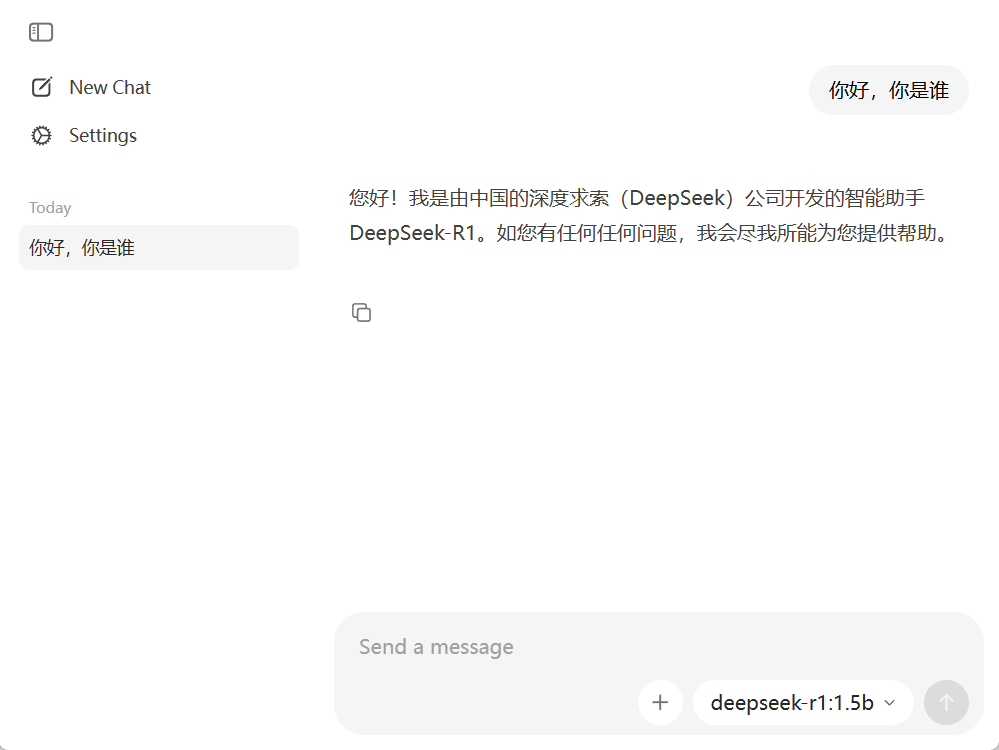
结语
本地部署大模型最好的选择就是 Ollama,当我们的环境要求必须内网开发,数据严格隐私,则使用Ollama是最佳选择。 Ollama 是本地 AI 大模型的一键启动器 + 管理器 + API 服务器。后续我们使用Java或Python需要调用大模型API时,可以直接调用本地大模型API,方便快捷,注重隐私安全。

欢迎加入DeepSeek 技术社区。在这里,你可以找到志同道合的朋友,共同探索AI技术的奥秘。
更多推荐

 1
1 0
0- 0



 已为社区贡献2条内容
已为社区贡献2条内容

所有评论(0)