DeepSeek终于能看懂图了:这次不只是识图,而是让模型学会“边指边想”
识图模式目前还是灰度,不是全量发布。媒体实测也显示,基础画面描述、文字读取、常见物体理解表现不错,但遇到隐藏图形、碎块化反色图、复杂数量统计、图形逻辑题时仍会出错。比如有测试中,老虎数量题正确答案为 10,只回答成 7;隐藏数字类图片也没有识别出来。这说明它现在更像是 “可用的视觉理解入口 + 研究型视觉推理机制”,还不是一个稳定碾压 GPT、Claude、Gemini 的全能多模态模型。另外,官
DeepSeek终于能看图了
这次不只是识图,而是让模型学会“边指边想”
DeepSeek终于补上了多模态能力了,这一次大众心心念念的识图能力也在慢慢灰度起来。
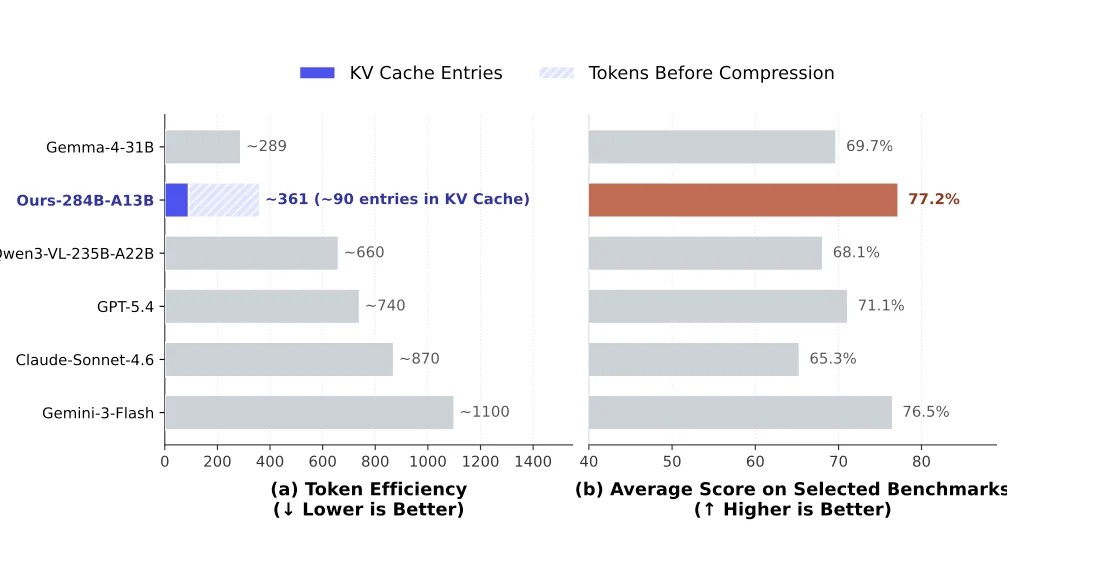
在模型能力上,同样在 800×800 图像输入下,DS模型平均分约 77.2%,高于 Gemini-3-Flash 的 76.5%,也高于 GPT-5.4 的 71.1%、Claude-Sonnet-4.6 的 68.1%、Qwen3-VL 的 65.3%。同时它的 token/KV cache 使用明显更低:DS模型约 361 tokens,KV cache 约 90 entries,而 Gemini-3-Flash 约 1100,Claude-Sonnet-4.6 约 870,GPT-5.4 约 740。官方同时也很诚实的强调,这个平均分只覆盖与本文研究主题相关的 7 个 benchmark,不代表模型整体能力排名。
于是,我把DS官方发布的技术报告进行了拟人化,看起来确实是有点东西~

目前我的deepseek好像还没有灰度到,但是已经有网友说新的多模态版本准备要来的。如果你是灰度到的用户,在界面上就会多一个显示“识图模式”
有网友形象的称,这一次的DeepSeek多模态模型,像是给小鲸鱼去掉了眼罩一样,真正的有眼镜看清粗世界
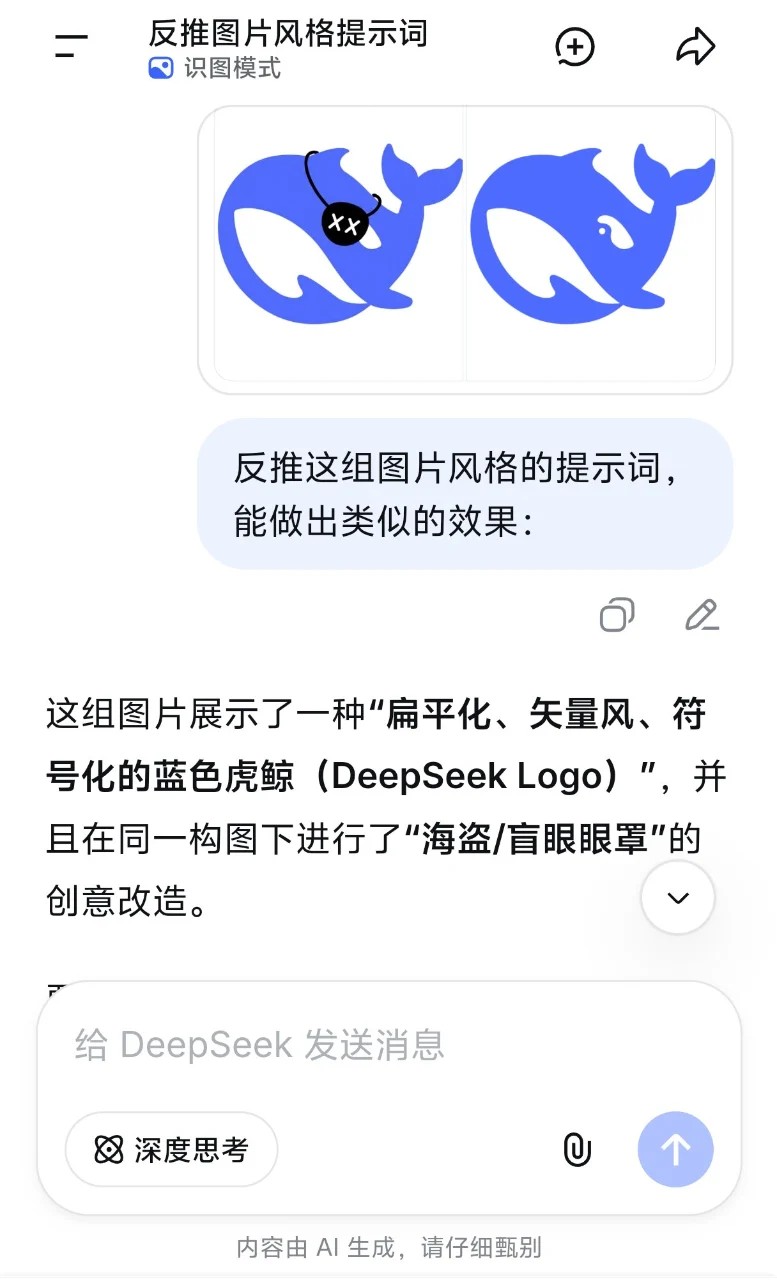
下面是网友的一些测试分享案例。
Q:让它去识别手表的款式。

Q:反向推出图片的风格提示词
Q:网页复刻
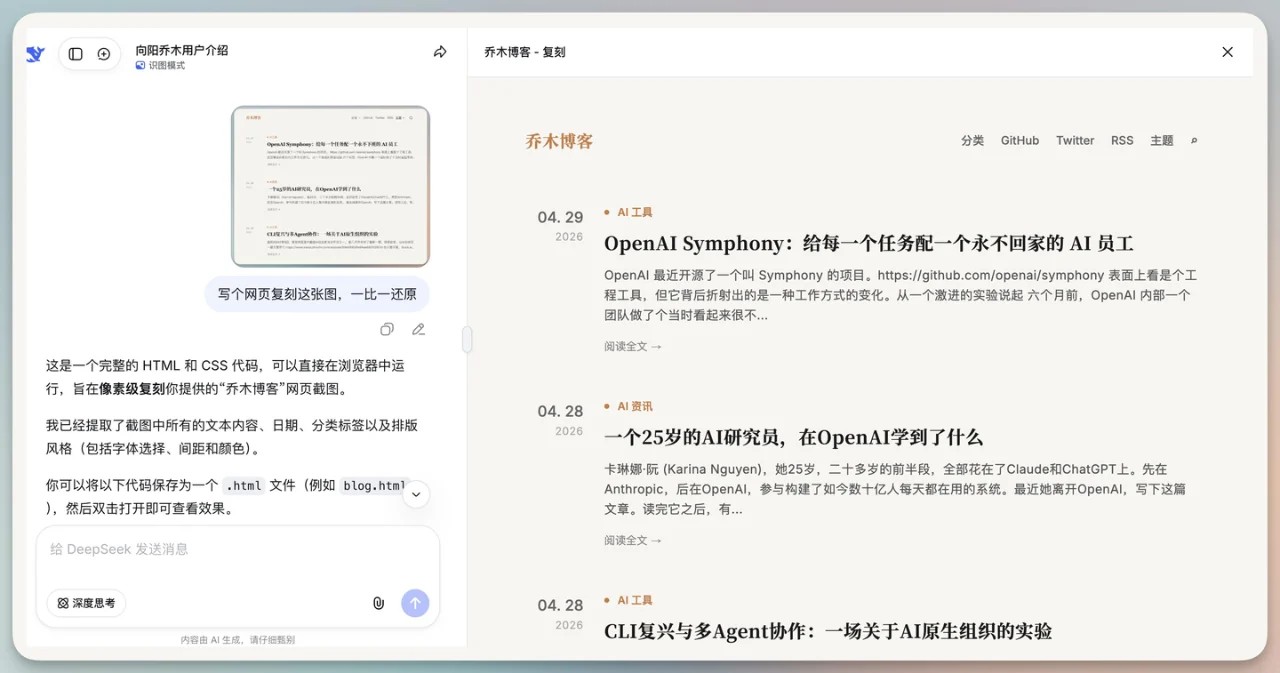
一比一直接复刻网页。而且生成的速度还是挺快的,同时网页复刻还原度相当不错,这下前端开发就更好用了。
Q:动漫特朗普画像识别
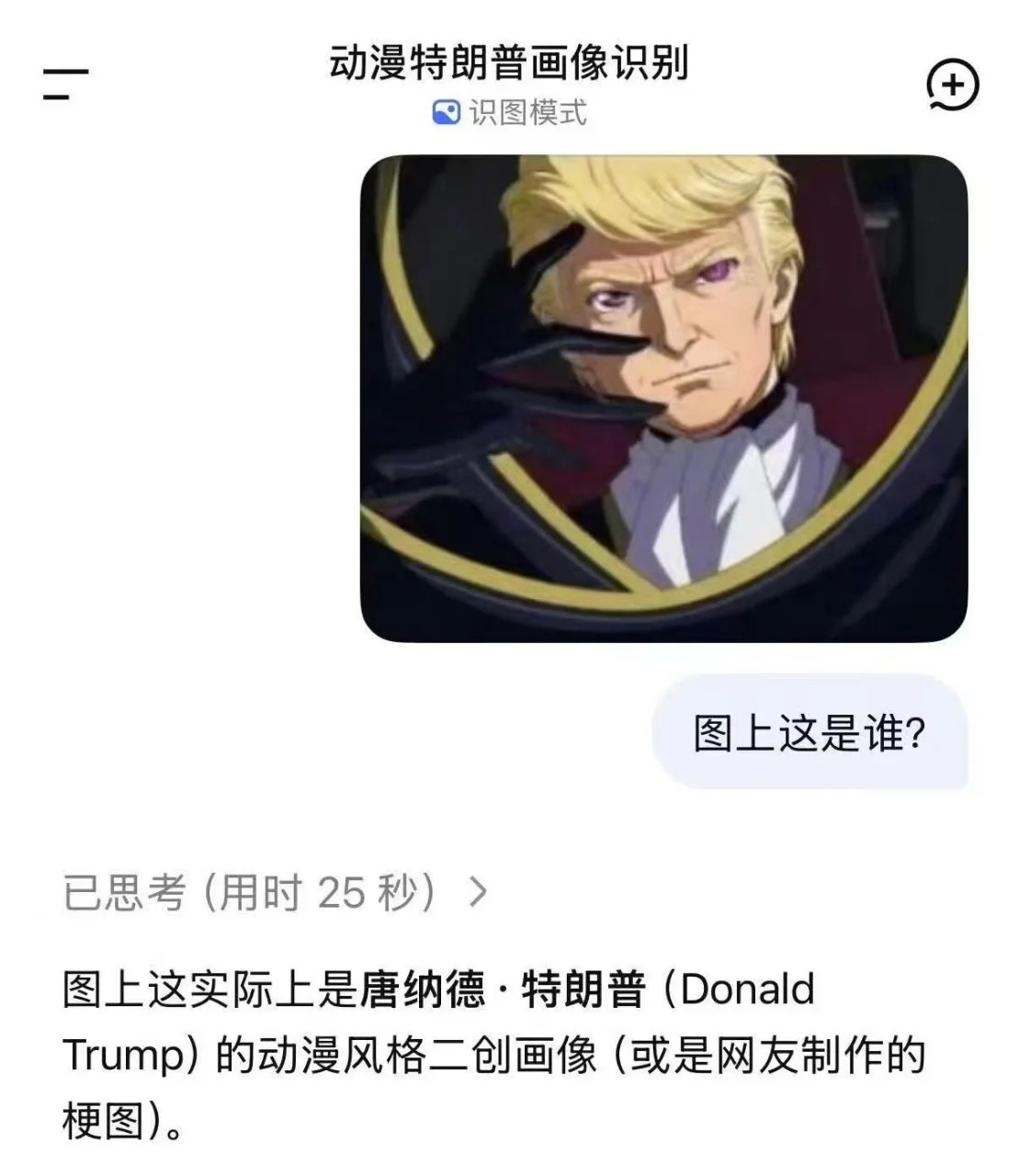
Q:美术还原图图像

现在就等真的多模态最强DeepSeek版本进行全量推送,让大众也能体验一下。
技术报告解读
目前DeepSeek官方已经放出了具体的技术论文:

它提出了一个新的方向:多模态推理不能只靠语言 CoT,必须把视觉坐标纳入推理过程,让模型具备“边指边想”的能力。
这句话怎么理解呢?回到现有的多模态大模型做推理的时候,通常是用文字写思考过程,比如“左边的人”“右上角的物体”“靠近门口的那只狗”。问题是,图像里的对象很多、位置复杂、遮挡频繁时,这些语言描述并不稳定。模型上一句说“左边那个球”,下一句可能已经把它和另一个球混了。也就是说,语言能描述对象,但不一定能精确绑定对象。
比如在用GPT的时候,它的推理过程其实就是使用文字进行描述,然后辅助推理

所以这一次DS不走寻常路,直接让模型在识别图片的时候,给出了一个锚点如果模型在思考时不仅说“左边那个人”,还输出一个框:<box>[[120,230,260,580]]</box>
那它就明确指向了图像中的某个区域。后续判断“这个人是不是穿红衣服”“他旁边有没有车”“他和另一个人距离多远”时,都可以围绕这个坐标继续推理,不容易混淆。
同时,“边指边想”就是让模型像人一样用手指辅助思考。
人类数人头、走迷宫、看地图、找路线时,通常不会只在脑子里念:“左边、右边、上面、下面”。我们会用手指点、沿着线走、圈出目标。这个动作能降低记忆负担,也能避免数重、漏数、走错路径。
举个简单例子:
用户问:图里有多少只白色的狗?
普通语言 CoT 可能是:
我看到左边有一只白狗,中间有一只,右边好像还有一只,所以一共三只。
但这个过程很难验证,模型可能把猫看成狗,也可能重复数同一只。
“边指边想”的方式是:
我先定位所有狗:box1、box2、box3、box4。然后检查颜色:box1 是白色,box2 是黑色,box3 是白色,box4 是棕色。所以白色狗有 2 只。
这样推理链更稳,因为每一步都有视觉坐标支撑。
总结起来,论文中对于视觉上的创新有亮点
第一类是 Bounding Box。
适合用于目标定位、计数、细粒度识别。比如数图里有多少只熊,模型不是直接猜数字,而是先把每只熊框出来,再判断哪些符合条件,最后统计数量。论文里给了“树上熊不算,地面上的熊算”的例子,模型通过框选每只熊来完成细粒度计数。

第二类是 Point。
适合路径、轨迹、拓扑推理。比如走迷宫、追踪曲线、判断路线是否可达。模型不能只说“往左再往右”,而是输出一串坐标点,表示它实际走过或追踪的路径。论文里的 path tracing 任务就是让模型沿着复杂交叉曲线,从起点追踪到终点。

这个设计很像人类做视觉推理时的“手指辅助”:数人头时会一个一个点过去,走迷宫时会沿着路径比划,找物体时会先定位再判断。论文把这个过程形式化到了模型输出里。
在模型架构上也做了极致压缩
论文模型基于 DeepSeek-V4-Flash,语言 backbone 是 MoE 架构,总参数 284B,推理激活 13B。视觉侧用自研 DeepSeek-ViT,整体结构类似 LLaVA:图像经过 ViT 编码,再和文本 instruction 拼接输入 LLM。不同点在于它非常重视视觉 token 压缩。
它做了两级压缩:
一是 ViT 输出阶段做 3×3 spatial token compression,把 9 个邻近视觉 patch token 压成 1 个。
二是 LLM 内部用 Compressed Sparse Attention / CSA,进一步压缩 KV cache。
论文举例:一张 756×756 图像,原始会产生 2916 个 patch token,经过 3×3 压缩后输入 LLM 的视觉 token 变成 324 个,最后 KV cache 里只保留 81 个视觉 KV entries。整体从像素到最终 KV cache entry 的压缩比达到 7056×。这说明它不是靠“疯狂塞图像 token”来提升效果,而是靠更强的视觉引用机制和压缩架构提高效率。
在训练流程上,这一次DS采用了新的方法。先进行专家化训练,然后再统一
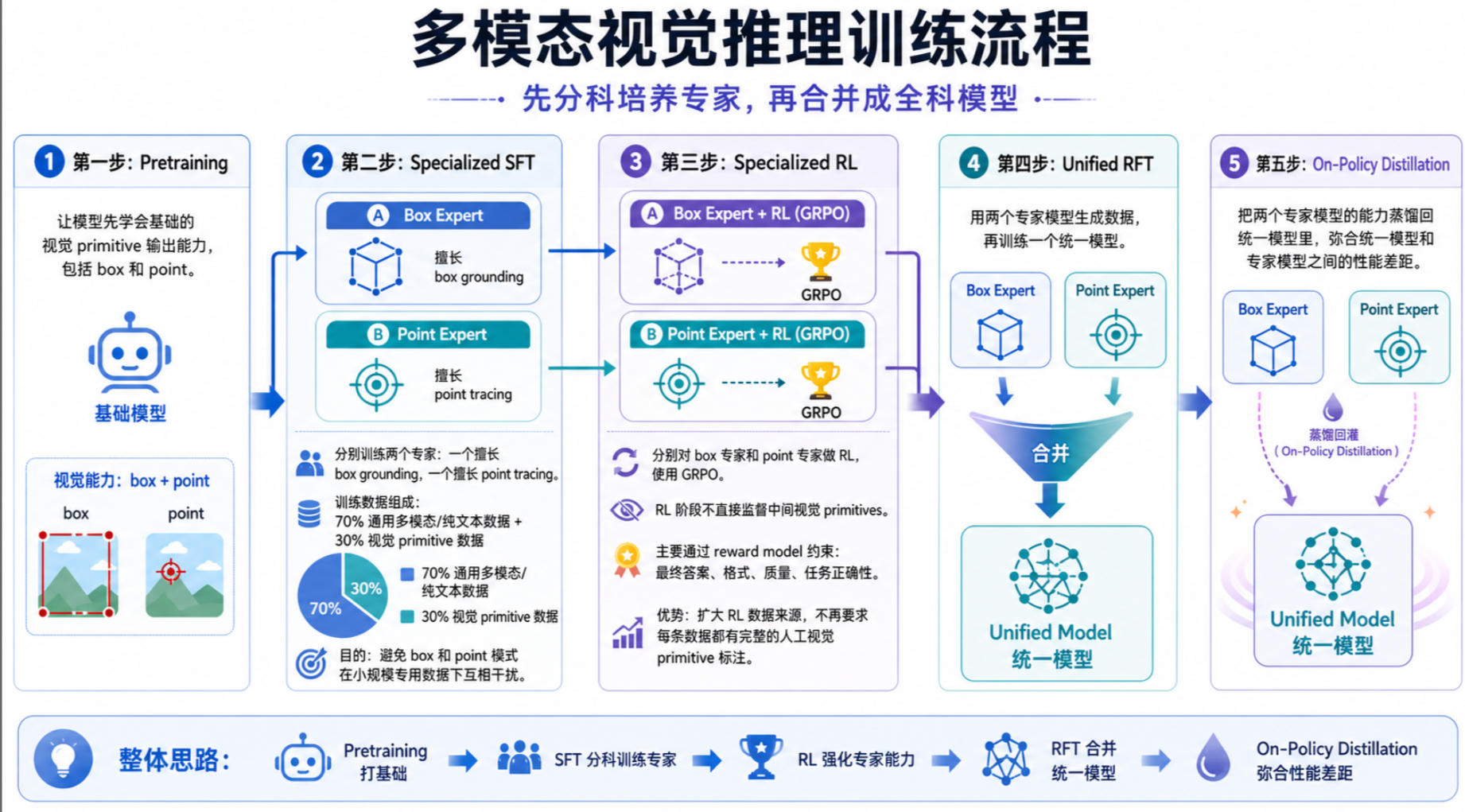
第一步:Pretraining。让模型先学会基础的视觉 primitive 输出能力,包括 box 和 point。
第二步:Specialized SFT。分别训练两个专家:一个擅长 box grounding,一个擅长 point tracing。SFT 数据里 70% 是通用多模态/纯文本数据,30% 是视觉 primitive 数据。这样做是为了避免 box 和 point 模式在小规模专用数据下互相干扰。
第三步:Specialized RL。分别对 box 专家和 point 专家做 RL,使用 GRPO。这里有意思的是,RL 阶段不直接监督中间视觉 primitives,而主要通过 reward model 约束最终答案、格式、质量和任务正确性。这样可以扩大 RL 数据来源,因为不再要求每条数据都有完整的人工视觉 primitive 标注。
第四步:Unified RFT。用两个专家模型生成数据,再训练一个统一模型。
第五步:On-Policy Distillation。把两个专家模型的能力蒸馏回统一模型里,弥合统一模型和专家模型之间的性能差距。
整体思路就是:先分科培养专家,再合并成全科模型。
写在最后
识图模式目前还是灰度,不是全量发布。媒体实测也显示,基础画面描述、文字读取、常见物体理解表现不错,但遇到隐藏图形、碎块化反色图、复杂数量统计、图形逻辑题时仍会出错。比如有测试中,老虎数量题正确答案为 10,只回答成 7;隐藏数字类图片也没有识别出来。
这说明它现在更像是 “可用的视觉理解入口 + 研究型视觉推理机制”,还不是一个稳定碾压 GPT、Claude、Gemini 的全能多模态模型。
另外,官方 GitHub 也写得比较谨慎:目前发布的是技术报告,未来计划开放内部 benchmark 和一部分 cold-start 数据,模型权重会在未来整合进基础模型后发布。也就是说,当前还不是完整模型权重开源。
过去一段时间,国产模型厂商基本都在补多模态:Qwen-VL、GLM-V、豆包视觉、Kimi 视觉、阶跃全模态、混元多模态等都已经在产品或模型侧铺开。DeepSeek 之前强在文本推理、代码和成本效率,但主线产品缺视觉,确实像少一块拼图。现在这块补上后,国产头部模型基本进入了 “全员睁眼” 阶段。

欢迎加入DeepSeek 技术社区。在这里,你可以找到志同道合的朋友,共同探索AI技术的奥秘。
更多推荐



 11
11 0
0- 0



 已为社区贡献11条内容
已为社区贡献11条内容

所有评论(0)