大模型行业全景:小白也能轻松入门的收藏必备指南
大语言模型(Large Language Model,LLM)是指参数规模达到数十亿甚至万亿级别的深度学习语言模型,能够理解和生成人类语言,在2022年ChatGPT发布后引发全球AI革命。大模型预训练工程师是LLM领域的"金字塔尖"岗位,负责设计和训练大语言模型的基座,决定模型的能力上限。核心职责设计Transformer架构变体(FlashAttention、Mamba等)构建千卡/万卡级分布
本文系统性地介绍了大模型(LLM)行业的全景图,包括国内外发展现状、产业链构成、核心数据等。文章详细解析了大模型相关职位分类及各职位的详细解读,涵盖了从预训练工程师到AI安全工程师等核心岗位。此外,还深入探讨了大模型的核心技术知识图谱,包括Transformer架构、预训练方法、SFT/RLHF/DPO对齐方法、推理优化技术、RAG技术栈、Agent框架与工具调用、多模态架构等。最后,文章提供了候选人评估与面试提问技巧,以及大模型人才寻访策略,并附有行业术语速查表,旨在为想要进入大模型行业的读者提供全面的指导。
一、大模型行业全景
1.1 什么是大语言模型(LLM)
大语言模型(Large Language Model,LLM)是指参数规模达到数十亿甚至万亿级别的深度学习语言模型,能够理解和生成人类语言,在2022年ChatGPT发布后引发全球AI革命。
1.2 国内外大模型发展现状
国际大模型格局
| 公司 | 代表模型 | 核心能力 | 特点 |
|---|---|---|---|
| OpenAI | GPT-4o、o1、o3 | 多模态理解、复杂推理 | 行业标杆闭源模型 |
| Anthropic | Claude 3.5、Claude 4 | 长上下文、安全对齐 | 擅长复杂长文档处理 |
| Gemini 2.0 | 原生多模态 | Google全家桶深度集成 | |
| Meta | LLaMA 3.1/3.2 | 开源、效率优化 | 开源生态领导者 |
| xAI | Grok 3 | 实时信息、幽默风格 | 与X平台深度整合 |
国产大模型格局(2025-2026)
| 公司/机构 | 代表模型 | 核心优势 | 应用场景 |
|---|---|---|---|
| 深度求索 | DeepSeek-V3/R1 | 推理能力、开源策略 | 企业级AI应用 |
| 阿里云 | 通义千问Qwen2.5 | 开源生态、中文能力 | 电商、金融、云服务 |
| 字节跳动 | 豆包大模型 | 用户量大、日token处理领先 | 抖音生态、C端应用 |
| 百度 | 文心一言4.0 | 搜索增强、知识图谱 | 搜索、企业服务 |
| 月之暗面 | Kimi、Moonshot | 超长上下文(200K) | 文档处理、长文分析 |
| 智谱AI | GLM-4、GLM-Z1 | 学术背景、国产替代 | 科研、企业B端 |
| MiniMax | 海螺AI | 语音交互、视频生成 | 社交娱乐、音视频 |
| 阶跃星辰 | Step系列 | 多模态、科学智能 | 科学研究、医疗 |
1.3 大模型产业链全景
| 层级 | 核心组成 | 关键玩家 | 人才需求 |
|---|---|---|---|
| 基础层(算力) | GPU集群、云服务、芯片 | NVIDIA、华为昇腾,寒武纪 | Infra工程师、CUDA开发 |
| 模型层(基座) | 预训练模型、SFT、RLHF | OpenAI、DeepSeek、阿里、百度 | 预训练工程师、对齐工程师 |
| 数据层(语料) | 数据采集、清洗、标注 | Scale AI、海天瑞声 | 数据工程师、标注PM |
| 框架层(工具) | 训练框架、推理引擎 | HuggingFace、vLLM、SGLang | 框架开发工程师 |
| 应用层(落地) | RAG、Agent、行业应用 | 各行业AI+公司 | 应用开发、RAG/Agent工程师 |
| 安全层(治理) | 内容安全、对齐、安全评估 | 监管机构、各企业安全团队 | AI安全、风控工程师 |
1.4 大模型行业核心数据(2025-2026)
市场规模
:2025年全球大模型产业规模突破5000亿美元,中国AI人才缺口超400万。
| 指标 | 数据 | 说明 |
|---|---|---|
| AI岗位增长率 | 2026年同比增长14倍 | 脉脉高聘数据 |
| 顶尖博士应届薪资 | 200-300万年薪 | 头部企业抢人策略 |
| 算法工程师需求占比 | 67.17% | AI技术人才需求第一 |
| 大模型岗位平均薪资 | 45.5%岗位月薪20-50K | 年薪约24-60万 |
| 人才供需比 | 1:3(每个求职者3个岗位) | 核心技术人才仍稀缺 |
二、大模型相关职位分类
2.1 职位全景图
大模型相关职位
├── 🔥第一梯队:核心研发(硬核技术)
│ ├── 大模型预训练工程师
│ ├── 大模型Infra工程师
│ └── 大模型算法研究员
│
├── ⭐第二梯队:模型优化(技术关键)
│ ├── 大模型对齐/RLHF工程师
│ ├── 多模态大模型工程师
│ └── 模型推理部署工程师
│
├── 🚀第三梯队:应用落地(商业价值)
│ ├── RAG系统工程师
│ ├── AI Agent工程师
│ └── 大模型应用开发工程师
│
├── 🔧第四梯队:配套支撑(生态保障)
│ ├── Prompt工程师
│ ├── 大模型数据工程师
│ └── 模型评估工程师
│
└── 🛡️第五梯队:安全治理
└── AI安全/风控工程师
2.2 各梯队薪资分布
| 梯队 | 代表岗位 | 薪资范围(月薪) | 入门门槛 |
|---|---|---|---|
| 第一梯队 | 预训练、Infra、研究员 | 50-150K+ | 博士/顶级硕士+顶会论文 |
| 第二梯队 | 对齐、多模态、推理 | 40-100K | 硕士+大模型项目经验 |
| 第三梯队 | RAG、Agent、应用开发 | 25-70K | 本科+框架使用经验 |
| 第四梯队 | Prompt、数据、评估 | 20-45K | 本科+领域经验 |
| 第五梯队 | 安全、风控 | 25-60K | 本科+AI安全经验 |
三、各职位详细解读
3.1 大模型预训练工程师
3.1.1 职位定义与核心职责
大模型预训练工程师是LLM领域的"金字塔尖"岗位,负责设计和训练大语言模型的基座,决定模型的能力上限。
核心职责:
- 设计Transformer架构变体(FlashAttention、Mamba等)
- 构建千卡/万卡级分布式训练系统
- 负责海量数据的清洗、配比、质量评估
- 监控训练稳定性,解决OOM、通信瓶颈等核心问题
- 研究Scaling Law并指导模型 scaling
3.1.2 技术栈要求
| 类别 | 技术要求 | 说明 |
|---|---|---|
| 深度学习框架 | PyTorch、Megatron-LM、DeepSpeed | 必须精通 |
| 分布式训练 | 数据并行、张量并行、流水线并行 | 核心技能 |
| 系统能力 | CUDA编程、NCCL通信、GPU集群管理 | 加分项 |
| 算法理解 | Transformer原理、Attention机制 | 必备基础 |
3.1.3 候选人画像
顶级候选人(★★★★★):
- 985/211博士,顶会论文一作(NeurIPS/ICML/ACL)
- 主导过千亿参数模型训练项目
- 熟悉分布式训练框架底层实现
- 有万卡集群训练经验
优质候选人(★★★★☆):
- 985硕士,有大模型预训练经验
- 掌握至少一种分布式训练框架
- 了解模型 scaling 策略
3.1.4 寻访方向
| 类型 | 代表公司/团队 | 说明 |
|---|---|---|
| 顶级实验室 | 清华NLP、北大MMLab、上交APEX | 学术背景强、科研能力强 |
| 头部大厂 | 阿里通义、百度文心、字节Seed | 资源充足、项目经验 |
| AI独角兽 | DeepSeek、智谱AI、月之暗面 | 技术驱动、快速成长 |
| 海外人才 | OpenAI、Google、Meta FAIR | 前沿视野、高端引进 |
3.2 大模型Infra工程师
3.2.1 职位定义与核心职责
大模型Infra工程师是连接算法与硬件的关键桥梁,负责构建大模型训练和推理的"基础设施"。
核心职责:
- 设计和优化训练/推理引擎
- 万卡集群调度策略与通信优化
- 模型压缩、量化、加速技术研发
- 保障大模型训练稳定性和推理效率
3.2.2 技术栈要求
| 类别 | 技术要求 | 说明 |
|---|---|---|
| 编程语言 | Python、C/C++、Go | 核心技能 |
| 推理框架 | vLLM、SGLang、TensorRT-LLM | 必备 |
| 分布式系统 | Kubernetes、Docker、Slurm | 基础能力 |
| GPU优化 | CUDA、Nsight、NCCL | 核心竞争力 |
| 框架 | PyTorch、DeepSpeed、Megatron-LM | 常用框架 |
3.2.3 候选人画像
顶级候选人(★★★★★):
- 5年以上大规模分布式系统经验
- 主导过千亿参数模型的训练/推理优化
- 有CUDA kernel开发经验
- 顶会论文(NeurIPS MLSys/OSDI)或开源贡献
优质候选人(★★★★☆):
- 3年以上深度学习系统经验
- 熟悉至少一种推理框架
- 有GPU性能优化经验
3.2.4 寻访方向
| 类型 | 代表公司/团队 | 说明 |
|---|---|---|
| 云计算大厂 | 阿里云、腾讯云、字节云 | 基础设施团队 |
| AI平台团队 | 字节Seed Infra、美团算法平台 | 内部AI基建 |
| AI创业公司 | 月之暗面、DeepSeek | 自研大模型 |
| 芯片公司 | 华为昇腾、寒武纪 | 软硬结合 |
3.3 大模型对齐/RLHF工程师
3.3.1 职位定义与核心职责
大模型对齐工程师负责通过SFT、RLHF、DPO等技术让模型输出更符合人类期望,是模型"调教"的关键角色。
核心职责:
- 构建高质量SFT训练数据集
- 设计并实施RLHF全流程
- 训练和优化Reward Model
- 建立对齐效果评估体系
- 研究DPO、ORPO等新型对齐方法
3.3.2 技术栈要求
| 类别 | 技术要求 | 说明 |
|---|---|---|
| 深度学习 | PyTorch、强化学习基础 | 核心 |
| 对齐技术 | RLHF、DPO、PPO、KTO | 必备 |
| 数据工程 | 数据清洗、标注流程设计 | 重要 |
| 评估体系 | 自动化评估、人工评估 | 关键能力 |
| 框架 | DeepSpeed、TRL、Axolotl | 常用工具 |
3.3.3 候选人画像
顶级候选人(★★★★★):
- 有RLHF实战经验(千亿参数级别)
- 熟悉Reward Model训练和PPO实施
- 了解大模型评估方法论
- 有数据闭环优化经验
优质候选人(★★★★☆):
- 有大模型SFT经验
- 了解RL基础概念
- 有数据标注和质检经验
3.3.4 寻访方向
| 类型 | 代表公司/团队 | 说明 |
|---|---|---|
| 头部大厂 | 字节Seed、阿里通义、百度文心 | 对齐团队 |
| AI独角兽 | DeepSeek、智谱AI | 自研对齐 |
| AI创业公司 | 各垂类大模型公司 | 对齐岗位 |
| 海外人才 | Anthropic、OpenAI相关团队 | 高端引进 |
3.4 多模态大模型工程师
3.4.1 职位定义与核心职责
多模态大模型工程师负责训练和优化同时处理文本、图像、视频、语音等多种模态的大模型。
核心职责:
- 多模态模型架构设计与实现
- 图文/音视频对齐训练
- 多模态理解与生成能力提升
- 探索多模态Agent、文档智能等前沿方向
3.4.2 技术栈要求
| 类别 | 技术要求 | 说明 |
|---|---|---|
| CV基础 | 图像处理、目标检测、OCR | 重要 |
| 多模态架构 | CLIP、BLIP、LLaVA架构 | 核心 |
| 生成模型 | Diffusion、VAE、GANS | 加分项 |
| 框架 | PyTorch、Transformers | 必备 |
| 论文积累 | CVPR、ICCV、NeurIPS | 顶会背景 |
3.4.3 候选人画像
顶级候选人(★★★★★):
- CV顶会论文(CVPR/ICCV/ECCV)
- 有CLIP/LLaVA类项目经验
- 熟悉多模态预训练流程
- 有端到端多模态生成经验
薪资参考:硕士30-50K+,博士可达100K+
3.4.4 寻访方向
| 类型 | 代表公司/团队 | 说明 |
|---|---|---|
| 视觉大厂 | 字节视觉、阿里达摩院CV | 视觉+LLM |
| AI创业公司 | Midjourney、Stability AI | 多模态生成 |
| 科研机构 | 智源研究院、清华MMLab | 前沿研究 |
| 互联网大厂 | 腾讯优图、商汤科技 | CV+多模态 |
3.5 模型推理部署工程师
3.5.1 职位定义与核心职责
推理部署工程师负责将训练好的大模型高效、稳定地部署到生产环境,是模型落地的关键保障。
核心职责:
- 推理引擎的部署与优化
- 模型量化(INT8/INT4/FP8)
- 高并发服务架构设计
- 端侧/边缘部署方案
3.5.2 技术栈要求
| 类别 | 技术要求 | 说明 |
|---|---|---|
| 推理框架 | vLLM、SGLang、TGI、TensorRT-LLM | 必备 |
| 量化技术 | GPTQ、AWQ、INT8/INT4 | 核心技能 |
| 工程能力 | Docker、K8s、高并发架构 | 基础 |
| 编程语言 | Python、C++、Go | 必须掌握 |
| 性能优化 | profiling、CUDA优化 | 竞争力 |
3.5.3 候选人画像
顶级候选人(★★★★★):
- 3年以上大模型推理优化经验
- 主导过千亿模型的推理部署
- 有量化实战经验
- 了解vLLM/SGLang源码
优质候选人(★★★★☆):
- 1年以上推理框架使用经验
- 熟悉Docker/K8s部署
- 有性能优化经验
3.5.4 寻访方向
| 类型 | 代表公司/团队 | 说明 |
|---|---|---|
| 云服务厂商 | 阿里云、腾讯云、华为云 | 推理平台 |
| 大厂AI平台 | 字节AI平台、美团平台 | 内部基建 |
| AI公司 | DeepSeek、智谱AI | 模型服务 |
| 企业IT | 京东云、携程AI | 业务落地 |
3.6 RAG系统工程师
3.6.1 职位定义与核心职责
RAG(检索增强生成)工程师负责构建"模型+知识库"的混合架构,让大模型能够准确回答私有知识相关问题。
核心职责:
- RAG系统设计与实现
- 文档解析与向量化
- 检索策略优化(混合检索、重排序)
- RAG评估体系建立
3.6.2 技术栈要求
| 类别 | 技术要求 | 说明 |
|---|---|---|
| 框架 | LangChain、LlamaIndex、RAGFlow | 核心框架 |
| 向量数据库 | Milvus、Pinecone、Chroma | 必备技能 |
| Embedding | BGE、GTE、text-embedding | 关键能力 |
| 搜索技术 | Elasticsearch、BM25、Hybrid Search | 常用技术 |
| Python | 熟练掌握 | 基础能力 |
3.6.3 候选人画像
顶级候选人(★★★★★):
- 有完整RAG系统开发经验
- 熟悉向量数据库底层原理
- 有RAG效果优化实战经验
- 了解多跳RAG、Agentic RAG
优质候选人(★★★★☆):
- 了解RAG原理,有demo经验
- 熟悉LangChain/LlamaIndex
- 有NLP/搜索背景
3.6.4 寻访方向
| 类型 | 代表公司/团队 | 说明 |
|---|---|---|
| 企业服务 | 各行业SaaS公司 | 知识库问答 |
| AI应用公司 | 各行业AI+解决方案 | RAG落地 |
| 大厂AI Lab | 阿里、腾讯、百度 | 前沿探索 |
| 创业公司 | Dify、RAGFlow等工具公司 | 框架开发 |
3.7 AI Agent工程师
3.7.1 职位定义与核心职责
AI Agent工程师负责设计能够自主规划、工具调用、多步骤执行的智能体系统,是2025-2026年最热门的岗位方向之一。
核心职责:
- Agent架构设计与实现(ReAct、Plan-and-Execute等)
- 工具定义与调用编排
- 多Agent协作系统
- Agent评估与优化
3.7.2 技术栈要求
| 类别 | 技术要求 | 说明 |
|---|---|---|
| Agent框架 | LangGraph、AutoGen、CrewAI | 核心框架 |
| Prompt工程 | CoT、ReAct、Few-shot | 必备技能 |
| 工具调用 | Function Calling、API集成 | 关键能力 |
| RAG | 向量检索、知识库 | 辅助技能 |
| Python | 异步编程、微服务 | 工程能力 |
3.7.3 候选人画像
顶级候选人(★★★★★):
- 有生产级Agent系统开发经验
- 熟悉多种Agent框架原理
- 有多Agent协作项目经验
- 了解MCP/A2A等协议
市场数据:59.6%岗位月薪超25K,北京平均40K+
3.7.4 寻访方向
| 类型 | 代表公司/团队 | 说明 |
|---|---|---|
| 互联网大厂 | 字节、阿里、腾讯 | Agent平台 |
| AI创业公司 | 各Agent应用公司 | 商业落地 |
| 企业服务 | 金融、医疗、律所AI+ | 垂直领域 |
| 工具公司 | LangChain、Dify | Agent框架 |
3.8 大模型应用开发工程师
3.8.1 职位定义与核心职责
大模型应用开发工程师基于现有大模型API或开源模型,快速搭建各类AI应用,是目前需求量最大的方向。
核心职责:
- AI应用设计与开发
- Prompt工程优化
- LLM API集成与封装
- 应用效果调优与监控
3.8.2 技术栈要求
| 类别 | 技术要求 | 说明 |
|---|---|---|
| 编程语言 | Python、JavaScript/TypeScript | 必备 |
| 后端框架 | FastAPI、Flask、Node.js | 常用框架 |
| LLM调用 | OpenAI API、国产模型API | 核心技能 |
| 数据库 | PostgreSQL、Redis、MongoDB | 基础能力 |
| 部署 | Docker、云服务 | 工程能力 |
3.8.3 候选人画像
可培养候选人(★★★☆☆):
- 有后端/全栈开发经验
- 对AI应用有热情
- 学习能力强
- 有实际项目经验(哪怕是个人项目)
3.8.4 寻访方向
| 类型 | 代表公司/团队 | 说明 |
|---|---|---|
| 互联网公司 | 各公司AI应用团队 | 需求量大 |
| 传统行业 | 金融、医疗、制造AI部门 | 数字化转型 |
| SaaS公司 | 企业服务SaaS | 产品开发 |
| 创业公司 | AI应用创业团队 | 快速发展 |
3.9 Prompt工程师
3.9.1 职位定义与核心职责
Prompt工程师专注于设计和优化AI指令,是大模型应用的"调参师",门槛相对较低但价值显著。
核心职责:
- Prompt设计与优化
- 业务场景Prompt模板开发
- AI输出质量评估与迭代
- Prompt库管理与规范制定
3.9.2 技术栈要求
| 类别 | 技术要求 | 说明 |
|---|---|---|
| Prompt技巧 | CoT、Few-shot、角色设定 | 核心 |
| AI工具 | ChatGPT、Claude、国产模型 | 必备 |
| 业务理解 | 需求拆解、场景设计 | 关键 |
| 评估方法 | 自动化评估、人工评估 | 重要 |
| 基础编程 | Python/JavaScript | 加分项 |
3.9.3 薪资参考(2025-2026)
| 经验 | 月薪范围 | 年薪范围 |
|---|---|---|
| 应届生 | 20-25K | 24-30万 |
| 1-3年 | 25-60K | 30-80万 |
| 3-5年 | 40-80K | 50-100万 |
3.9.4 寻访方向
- 传统文科专业转AI(新闻、中文、英语)
- 产品经理转型
- 传统NLP从业者
- AI产品公司
3.10 大模型数据工程师
3.10.1 职位定义与核心职责
大模型数据工程师负责构建大模型训练所需的"燃料",涵盖数据采集、清洗、标注全流程。
核心职责:
- 海量数据采集与清洗
- 数据质量评估与监控
- SFT/RLHF数据标注流程设计
- 数据配比与策略优化
3.10.2 技术栈要求
| 类别 | 技术要求 | 说明 |
|---|---|---|
| 大数据工具 | Spark、Hadoop、Flink | 基础能力 |
| 编程语言 | Python、SQL | 必须掌握 |
| 数据处理 | 去重、过滤、清洗 | 核心技能 |
| 标注工具 | Label Studio、Scale AI | 常用工具 |
| NLP理解 | 分词、实体识别 | 加分项 |
3.10.3 寻访方向
| 类型 | 代表公司/团队 | 说明 |
|---|---|---|
| 数据标注公司 | Scale AI、海天瑞声 | 专业数据 |
| 大厂数据团队 | 阿里、腾讯、字节 | 内部数据 |
| AI创业公司 | 各模型公司数据团队 | 核心岗位 |
| 科研机构 | 高校NLP实验室 | 学术数据 |
3.11 AI安全/风控工程师
3.11.1 职位定义与核心职责
AI安全工程师负责保障大模型的输出安全、内容合规,防范模型被滥用和攻击。
核心职责:
- 内容安全审核系统
- Prompt注入防御
- 模型安全评估与红队测试
- 合规体系建设
3.11.2 技术栈要求
| 类别 | 技术要求 | 说明 |
|---|---|---|
| 安全基础 | 网络安全、内容安全 | 基础 |
| AI安全 | 对抗样本、Prompt注入 | 核心 |
| 检测模型 | Llama Guard、内容审核模型 | 关键能力 |
| 合规知识 | AI法规、政策要求 | 重要 |
| 工具 | 安全检测平台、日志分析 | 工程能力 |
3.11.3 寻访方向
- 传统安全公司
- 大厂安全团队
- AI监管机构
- 法律合规背景转AI安全
四、大模型核心技术知识图谱
4.1 Transformer架构深入
4.1.1 Transformer核心组件
Transformer架构
├── 输入处理
│ ├── Tokenization(分词)
│ ├── Embedding(词嵌入)
│ └── Positional Encoding(位置编码)
│
├── Encoder(编码器)
│ ├── Multi-Head Self-Attention
│ ├── Feed Forward Network
│ └── Layer Normalization
│
├── Decoder(解码器)
│ ├── Masked Self-Attention
│ ├── Cross-Attention
│ └── Feed Forward Network
│
└── 输出层
└── Linear + Softmax
4.1.2 关键技术演进
| 技术 | 提出时间 | 核心改进 | 代表模型 |
|---|---|---|---|
| Transformer | 2017 | 全新架构 | 原始论文 |
| GPT | 2018 | Decoder-only | GPT系列 |
| BERT | 2018 | Encoder-only | BERT系列 |
| GPT-2 | 2019 | 规模 scaling | GPT-2 |
| GPT-3 | 2020 | 1750亿参数 | GPT-3 |
| LLaMA | 2023 | 高效开源 | LLaMA系列 |
| GPT-4 | 2023 | 多模态 | GPT-4 |
| DeepSeek-V3 | 2024 | 混合专家+FP8 | DeepSeek |
4.1.3 Attention机制变体
| 变体 | 核心思想 | 优势 | 应用场景 |
|---|---|---|---|
| Multi-Head Attention | 多组注意力并行 | 捕捉多种关系 | 通用 |
| Flash Attention | IO感知的精确注意力 | 显存高效 | 长上下文 |
| Grouped Query Attention | K/V头数少于Q | 平衡效果与效率 | LLaMA 2+ |
| Sparse Attention | 选择性计算注意力 | 长序列处理 | 长文档 |
| Ring Attention | 分布式注意力计算 | 超长序列 | 百万上下文 |
4.2 预训练方法
4.2.1 预训练范式
| 范式 | 说明 | 代表模型 | 适用场景 |
|---|---|---|---|
| CLM (Causal LM) | 因果语言建模 | GPT、LLaMA | 文本生成 |
| MLM (Masked LM) | 掩码语言建模 | BERT | 理解任务 |
| UL2 | 混合去噪器 | UL2 | 通用 |
| Prefix LM | 前缀语言建模 | UniLM | 通用 |
4.2.2 分布式训练策略
分布式训练并行策略
├── 数据并行(Data Parallelism)
│ ├── DDP (Distributed Data Parallel)
│ └── ZeRO (Zero Redundancy Optimizer)
│ ├── ZeRO-1: 优化器状态分片
│ ├── ZeRO-2: +梯度分片
│ └── ZeRO-3: +参数分片
│
├── 模型并行(Model Parallelism)
│ ├── 张量并行(Tensor Parallelism, TP)
│ ├── 流水线并行(Pipeline Parallelism, PP)
│ └── 序列并行(Sequence Parallelism, SP)
│
└── 混合专家(Mixture of Experts, MoE)
├── 专家路由
├── Top-K激活
└── 稀疏激活
4.2.3 训练稳定性技术
| 技术 | 作用 | 说明 |
|---|---|---|
| Mixed Precision | 加速训练 | FP16/BF16+FP32 |
| Gradient Checkpointing | 节省显存 | 用时间换空间 |
| Learning Rate Schedule | 稳定收敛 | Warmup+Cosine |
| Batch Size Scaling | 自适应调参 | LAMB等 |
| Gradient Clipping | 防止梯度爆炸 | 常用技巧 |
4.3 SFT/RLHF/DPO对齐方法
4.3.1 对齐技术全景
对齐技术体系
├── SFT(监督微调)
│ ├── 指令数据构建
│ ├── 高质量样本筛选
│ └── 微调策略
│
├── RLHF(基于人类反馈的强化学习)
│ ├── Reward Model训练
│ ├── PPO强化学习
│ └── 人类反馈收集
│
├── DPO(直接偏好优化)
│ ├── 偏好数据构建
│ ├── 偏好损失函数
│ └── 无需Reward Model
│
└── 其他对齐方法
├── RLAIF(AI反馈)
├── KTO(隐式偏好)
└── ORPO(赔率比)
4.3.2 SFT关键要点
| 要点 | 说明 | 常见问题 |
|---|---|---|
| 数据质量 | 高质量指令-响应对 | 噪声数据影响大 |
| 数据多样性 | 覆盖多种任务类型 | 分布不均 |
| 数据量 | 适量优于过量 | 过拟合风险 |
| 学习率 | 通常较低 | 过高易过拟合 |
| Epoch | 2-3个epoch | 过多易过拟合 |
4.3.3 RLHF vs DPO对比
| 维度 | RLHF | DPO |
|---|---|---|
| 复杂度 | 高(多阶段) | 低(端到端) |
| 计算资源 | 大(需要PPO) | 小 |
| 训练稳定性 | 较难调优 | 相对稳定 |
| 效果 | 通常更好 | 已接近RLHF |
| 适用场景 | 复杂对齐任务 | 快速迭代 |
4.4 推理优化技术
4.4.1 推理优化全景
推理优化技术
├── 模型压缩
│ ├── 量化(Quantization)
│ │ ├── INT8/INT4
│ │ ├── FP8
│ │ └── GPTQ/AWQ/BBPE
│ ├── 剪枝(Pruning)
│ │ ├── 结构化剪枝
│ │ └── 非结构化剪枝
│ └── 蒸馏(Distillation)
│ ├── 知识蒸馏
│ └── self-Distillation
│
├── 推理引擎优化
│ ├── vLLM(PagedAttention)
│ ├── SGLang
│ ├── TensorRT-LLM
│ └── LMDeploy
│
├── 服务架构优化
│ ├── Continuous Batching
│ ├── Prefix Caching
│ └── KV Cache复用
│
└── 投机解码
└── Speculative Decoding
4.4.2 量化技术对比
| 量化方法 | 精度损失 | 加速比 | 适用场景 |
|---|---|---|---|
| FP16 | 无 | 1x | 基线 |
| INT8 | 低 | 2-3x | 通用 |
| INT4 | 中 | 4-6x | 内存受限 |
| GPTQ | 低-中 | 4-8x | 推理加速 |
| AWQ | 低 | 4-8x | 推理加速 |
| FP8 | 极低 | 1.5-2x | 新硬件 |
4.4.3 KV Cache优化
| 技术 | 原理 | 效果 |
|---|---|---|
| PagedAttention | 分页管理KV | 显存利用率↑40% |
| Prefix Caching | 共享前缀KV | 首token延迟↓ |
| KV Cache量化 | 压缩KV存储 | 显存↓30-50% |
| StreamingLLM | 注意力 sink | 长文本生成稳定 |
4.5 RAG技术栈
4.5.1 RAG系统架构
RAG系统架构
├── 文档处理层
│ ├── 文档解析(PDF、Word、HTML)
│ ├── 文本切分(Chunking)
│ └── 文本清洗与标准化
│
├── 向量化层
│ ├── Embedding模型(BGE、GTE)
│ ├── 向量数据库(Milvus、Pinecone)
│ └── 索引构建
│
├── 检索层
│ ├── 稀疏检索(BM25)
│ ├── 稠密检索(向量相似度)
│ ├── 混合检索
│ └── 重排序(Rerank)
│
├── 生成层
│ ├── Query改写
│ ├── Context组装
│ ├── Prompt模板
│ └── LLM生成
│
└── 评估层
├── 召回率评估
├── 答案准确度
└── 端到端评估
4.5.2 文档切分策略
| 策略 | 说明 | 适用场景 |
|---|---|---|
| 固定长度 | 按token/字符数切分 | 简单场景 |
| 语义切分 | 按段落/句子切分 | 通用 |
| 模型切分 | 用模型判断切分点 | 高质量场景 |
| 递归切分 | 按层级结构递归切分 | 结构化文档 |
| Late Chunking | 先Embedding后切分 | 保留全局语义 |
4.5.3 RAG优化技术
| 优化方向 | 技术方法 | 效果 |
|---|---|---|
| 召回优化 | HyDE查询改写 | 召回率↑ |
| 召回优化 | Query Decomposition | 多跳问题 |
| 召回优化 | Sentence Window | 上下文丰富 |
| 生成优化 | Self-RAG | 减少幻觉 |
| 整体优化 | Agentic RAG | 自主决策 |
4.6 Agent框架与工具调用
4.6.1 Agent核心组件
Agent系统组成
├── 规划(Planning)
│ ├── 任务分解(ReAct、Plan-and-Execute)
│ ├── 自我反思(Reflexion)
│ └── 子目标分解
│
├── 记忆(Memory)
│ ├── 短期记忆(上下文)
│ ├── 长期记忆(向量存储)
│ └── 混合记忆
│
├── 工具(Tools)
│ ├── 搜索引擎
│ ├── 数据库查询
│ ├── API调用
│ └── 代码执行
│
└── 协作(Multi-Agent)
├── 角色分配
├── 消息传递
└── 协同决策
4.6.2 主流Agent框架对比
| 框架 | 公司/组织 | 特点 | 适用场景 |
|---|---|---|---|
| LangGraph | LangChain | 状态机编程 | 复杂工作流 |
| AutoGen | Microsoft | 多Agent协作 | 对话系统 |
| CrewAI | CrewAI | 角色扮演 | 多角色协作 |
| Claude Agent SDK | Anthropic | 工具生态 | 企业应用 |
| Dify | 开源社区 | 低代码 | 快速搭建 |
| Coze | 字节跳动 | 易用性 | 国内市场 |
4.6.3 工具调用协议
| 协议 | 说明 | 生态 |
|---|---|---|
| MCP (Model Context Protocol) | Anthropic推出的标准 | 快速普及 |
| A2A (Agent to Agent) | Agent间通信协议 | 新兴标准 |
| Function Calling | 模型原生能力 | 通用 |
| ToolNet | 工具调用框架 | LangChain |
4.7 多模态架构
4.7.1 多模态技术演进
| 阶段 | 技术 | 代表工作 | 特点 |
|---|---|---|---|
| 第一代 | 独立编码器+融合 | CLIP | 图文对齐 |
| 第二代 | 冻结LLM+适配器 | LLaVA | 高效适配 |
| 第三代 | 端到端多模态 | GPT-4V | 原生融合 |
| 第四代 | 原生多模态 | Gemini | 统一架构 |
4.7.2 多模态架构对比
| 架构 | 原理 | 优势 | 劣势 |
|---|---|---|---|
| CLIP-style | 双塔图文编码器 | 检索强大 | 生成弱 |
| LLaVA-style | 视觉编码器+LLM | 高效微调 | 理解有限 |
| Flamingo-style | 交叉注意力融合 | 生成强大 | 计算量大 |
| GPT-4V-style | 端到端 | 统一理解 | 训练成本高 |
4.7.3 多模态任务类型
| 任务 | 说明 | 代表应用 |
|---|---|---|
| 图文理解 | 图像描述、VQA | 智能客服 |
| 文档理解 | 图表理解、OCR | 文档处理 |
| 视频理解 | 视频摘要、对话 | 视频助手 |
| 语音交互 | 语音对话 | 智能音箱 |
| 图像生成 | 文生图、图生图 | 创意设计 |
| 视频生成 | 文生视频 | 内容创作 |
五、候选人评估与面试提问技巧
5.1 如何判断候选人的真实水平
核心原则
:理论+实践双重验证,口头回答≠真实能力
5.1.1 评估维度矩阵
| 维度 | 考察内容 | 验证方法 |
|---|---|---|
| 理论基础 | Transformer原理、Attention机制 | 原理推导 |
| 工程能力 | 代码实现、系统设计 | 实际编码 |
| 项目经验 | 做过什么、效果如何 | 项目深挖 |
| 问题解决 | 遇到问题如何分析 | 场景假设 |
| 学习能力 | 新技术如何上手 | 趋势讨论 |
5.1.2 常见虚假信号识别
红旗信号
:
- 只懂概念,无法深入细节
- 参与项目但非核心贡献
- 效果数据模糊,无法量化
- 对技术选型理由不清
- 避重就轻,转移话题
积极信号
:
- 能讲清每个技术决策的原因
- 对负面结果坦诚且有复盘
- 主动提到项目的局限性
- 关注业务价值而非技术炫技
5.2 分级提问策略
5.2.1 初级工程师提问(P5及以下)
理论问题:
“请简要描述Transformer的整体架构?”“Attention机制的公式是什么?”“BERT和GPT的主要区别是什么?”
实践问题:
“你用过哪些大模型?如何调用它们的API?”“描述一个你用LangChain/LlamaIndex做的项目?”“如何处理长文本超过模型context限制的问题?”
考察重点:基础知识、项目经验、学习态度
5.2.2 中级工程师提问(P6-P7)
深度问题:
“LoRA的原理是什么?为什么能实现高效微调?”“RLHF中Reward Model是如何训练的?”“vLLM的PagedAttention解决了什么问题?”
系统设计:
“如果要设计一个企业级RAG系统,你会考虑哪些方面?”“如何设计一个多Agent协作系统解决复杂任务?”
项目深挖:
“在你的项目中,如何评估RAG系统的效果?”“你们是如何解决模型幻觉问题的?”“RLHF训练中遇到了哪些挑战?如何解决的?”
考察重点:技术深度、系统思维、问题解决
5.2.3 高级工程师/专家提问(P8+)
前沿问题:
“如何看待MoE架构的未来发展?”“长上下文(100K+)的技术挑战有哪些?”“Agent系统的安全性如何保障?”
架构设计:
“如果要训练一个行业大模型,整体流程是什么?”“如何设计一个支持百万并发的推理服务?”“多模态模型训练的核心难点在哪里?”
团队管理:
“如何组建和培养大模型团队?”“如何评估团队的技术债和优先级?”
考察重点:技术视野、战略思维、团队领导
5.3 关键技术问题清单
5.3.1 预训练方向
| 问题 | 考察点 | 评估标准 |
|---|---|---|
| Transformer各组件作用 | 基础原理 | 清晰准确 |
| 分布式训练并行策略 | 系统理解 | 理解TP/PP/DP |
| Gradient Checkpointing原理 | 显存优化 | 能解释trade-off |
| 混合精度训练注意点 | 工程实践 | 有实战经验 |
| Scaling Law的理解 | 前沿认知 | 有深入研究 |
5.3.2 对齐/RLHF方向
| 问题 | 考察点 | 评估标准 |
|---|---|---|
| SFT数据构建流程 | 数据工程 | 有实战经验 |
| Reward Model训练技巧 | 强化学习 | 理解原理 |
| PPO训练流程 | 强化学习 | 能描述细节 |
| DPO vs RLHF | 技术对比 | 理解各自优劣 |
| 对齐效果评估方法 | 评估体系 | 有系统方法 |
5.3.3 RAG/Agent方向
| 问题 | 考察点 | 评估标准 |
|---|---|---|
| RAG整体流程 | 整体理解 | 清晰描述 |
| 文档切分策略 | 工程实践 | 有经验 |
| 向量检索原理 | 基础原理 | 能解释 |
| Rerank的作用 | 检索优化 | 理解原理 |
| Agent框架原理 | 系统设计 | 能对比选型 |
| 工具调用设计 | 架构能力 | 有实践 |
5.3.4 推理部署方向
| 问题 | 考察点 | 评估标准 |
|---|---|---|
| 量化原理 | 模型压缩 | 理解原理 |
| INT8 vs INT4 | 精度vs性能 | 理解trade-off |
| vLLM核心原理 | 推理框架 | 深入理解 |
| Continuous Batching | 服务架构 | 理解原理 |
| 模型部署全流程 | 工程实践 | 有经验 |
5.4 面试评估表
5.4.1 技术能力评估
| 评估项 | 权重 | 评分标准(1-5分) |
|---|---|---|
| 理论基础 | 20% | 1-不理解 3-理解 5-精通 |
| 工程能力 | 25% | 1-弱 3-良好 5-优秀 |
| 项目经验 | 25% | 1-浅 3-丰富 5-主导标杆 |
| 问题解决 | 15% | 1-弱 3-良好 5-出色 |
| 学习能力 | 15% | 1-慢 3-正常 5-快速 |
5.4.2 软性能力评估
| 评估项 | 考察方法 | 关注点 |
|---|---|---|
| 沟通表达 | 技术讲解 | 条理清晰 |
| 团队协作 | 项目描述 | 角色认知 |
| 业务理解 | 场景讨论 | 价值导向 |
| 职业规划 | 动机了解 | 稳定性 |
| 文化匹配 | 价值观交流 | 融入意愿 |
六、大模型人才寻访策略
6.1 人才来源分类
6.1.1 学术界来源
| 来源 | 特点 | 寻访方式 |
|---|---|---|
| 顶级高校NLP/AI实验室 | 理论基础强、科研潜力大 | 校园招聘、导师推荐 |
| 研究院(智源、自动化所) | 前沿研究、顶会论文 | 社招、学术会议 |
| 海外顶尖院校 | 国际视野、前沿技术 | 海外招聘、猎头 |
| 博士后 | 研究深入、稳定 | 直接联系 |
重点实验室名单:
- 清华NLP实验室、孙茂松组、刘知远组
- 北大MMLab、CLUE
- 上交APEX、跨媒体所
- 浙大赵洲团队
- 中科院自动化所、计算所
6.1.2 工业界来源
| 来源 | 特点 | 寻访方式 |
|---|---|---|
| 一线大厂AI Lab | 资源丰富、经验足 | 猎头、网络 |
| AI独角兽 | 技术驱动、快速成长 | 行业人脉 |
| 海外科技公司 | 前沿技术、国际化 | 海外渠道 |
| 芯片公司 | 底层优化、系统能力强 | 技术社区 |
6.1.3 跨界人才来源
| 来源 | 特点 | 寻访方式 |
|---|---|---|
| 推荐/搜索算法 | 算法基础扎实 | 转岗引导 |
| CV算法 | 视觉+语言跨界 | 技能迁移 |
| 传统NLP | 领域知识深厚 | 技术升级 |
| 后端/全栈 | 工程能力强 | 应用开发 |
6.2 核心人才池
6.2.1 头部公司人才分布
| 公司 | 核心团队 | 人才特点 |
|---|---|---|
| 字节跳动 | Seed团队、豆包团队 | 资源多、项目新 |
| 阿里 | 通义实验室、达摩院 | 技术全面 |
| 百度 | 文心团队、AI Lab | 搜索+AI |
| 腾讯 | 混元团队、优图 | 游戏+AI |
| DeepSeek | 核心研发 | 顶级技术、OpenAI背景 |
| 月之暗面 | Kimi团队 | 长上下文专家 |
| 智谱AI | 核心团队 | 学术背景强 |
6.2.2 海外人才来源
| 来源 | 人才特点 | 引进价值 |
|---|---|---|
| OpenAI | 前沿技术、顶级人才 | 极高 |
| Google DeepMind | 多模态、科学智能 | 极高 |
| Meta FAIR | 开源生态、效率优化 | 高 |
| Anthropic | 安全对齐、Claude | 高 |
| 微软研究院 | 系统、AI for Science | 高 |
| 英伟达 | GPU优化、CUDA | 高 |
6.3 寻访渠道与方法
6.3.1 高效寻访渠道
| 渠道 | 适用场景 | 效果 |
|---|---|---|
| 脉脉 | 精准mapping、技术氛围 | ⭐⭐⭐⭐⭐ |
| 海外人才、专业形象 | ⭐⭐⭐⭐⭐ | |
| GitHub | 技术展示、开源贡献 | ⭐⭐⭐⭐ |
| 学术会议 | 顶级人才、前沿研究 | ⭐⭐⭐⭐ |
| 技术社区 | 框架开发者、深度用户 | ⭐⭐⭐⭐ |
| 内推 | 信任度高、效率高 | ⭐⭐⭐⭐⭐ |
| 猎头 | 高端人才、快速定位 | ⭐⭐⭐⭐ |
6.3.2 Mapping技巧
Mapping小技巧
:利用目标公司招聘官网获取部门简介、业务方向、候选人能力模型画像等信息。
推荐资源:
- 目标公司招聘官网
- AI领域创业公司官网
- 达摩院、百度大脑官网
- 技术博客(PaperWeekly、AI科技媒体)
6.4 人才吸引力话术
6.4.1 不同层级候选人话术
初级候选人:
“大模型是当前最热门的方向,你现在做的工作将直接影响数亿用户。”
中级候选人:
“我们提供完整的大模型项目机会,从预训练到部署全链路参与。”
高级候选人:
“您将有机会主导公司大模型战略,从0到1搭建核心技术团队。”
6.4.2 竞争优势对比
| 维度 | 大厂 | 中小厂 | 创业公司 |
|---|---|---|---|
| 薪资 | 顶薪+股票 | 中等+期权 | 薪资+股权 |
| 资源 | 万卡集群 | 千卡集群 | 灵活 |
| 项目 | 成熟业务 | 新业务 | 从0到1 |
| 成长 | 体系化 | 全面锻炼 | 快速晋升 |
| 稳定性 | 高 | 中 | 风险 |
6.4.3 应对候选人顾虑
| 顾虑 | 应对策略 |
|---|---|
| 担心技术方向不合适 | 提供技术调研期、支持转型 |
| 担心薪资涨幅不够 | 提供薪资谈判支持、期权和福利 |
| 担心团队氛围 | 安排与未来同事交流 |
| 担心业务前景 | 分享公司战略和行业分析 |
| 担心技术挑战太大 | 提供导师制、团队支持 |
七、行业术语速查表
7.1 核心术语解释
模型训练相关
| 术语 | 全称 | 解释 |
|---|---|---|
| LLM | Large Language Model | 大语言模型 |
| GPT | Generative Pre-trained Transformer | 生成式预训练Transformer |
| BERT | Bidirectional Encoder Representations from Transformers | 双向Transformer编码器 |
| SFT | Supervised Fine-Tuning | 监督微调 |
| RLHF | Reinforcement Learning from Human Feedback | 基于人类反馈的强化学习 |
| DPO | Direct Preference Optimization | 直接偏好优化 |
| MoE | Mixture of Experts | 混合专家 |
| PEFT | Parameter-Efficient Fine-Tuning | 高效参数微调 |
| LoRA | Low-Rank Adaptation | 低秩适配 |
| prefix tuning | 前缀微调 | 在输入前添加可学习前缀 |
| prompt tuning | 提示微调 | 学习软提示向量 |
模型架构相关
| 术语 | 全称 | 解释 |
|---|---|---|
| Transformer | Transformer | 注意力机制模型架构 |
| Attention | Attention | 注意力机制 |
| Self-Attention | 自注意力 | 输入内部的注意力计算 |
| Cross-Attention | 交叉注意力 | 不同输入间的注意力 |
| Multi-Head Attention | 多头注意力 | 多组并行注意力 |
| FFN | Feed-Forward Network | 前馈神经网络 |
| LN/Layer Norm | Layer Normalization | 层归一化 |
| GQA | Grouped Query Attention | 分组查询注意力 |
| MHA | Multi-Head Attention | 多头注意力(标准) |
训练技术相关
| 术语 | 全称 | 解释 |
|---|---|---|
| pretraining | 预训练 | 在大规模数据上训练 |
| pre-training | 预训练阶段 | 训练基座模型 |
| post-training | 后训练阶段 | SFT/RLHF等 |
| fine-tuning | 微调 | 在特定数据上调整 |
| scaling | scaling | 模型规模扩大 |
| scaling law | scaling律 | 规模与性能关系 |
| TP | Tensor Parallelism | 张量并行 |
| PP | Pipeline Parallelism | 流水线并行 |
| DP | Data Parallelism | 数据并行 |
| ZeRO | Zero Redundancy Optimizer | 零冗余优化器 |
| gradient checkpointing | 梯度检查点 | 节省显存技术 |
| mixed precision | 混合精度 | 多精度计算 |
推理优化相关
| 术语 | 全称 | 解释 |
|---|---|---|
| inference | 推理 | 模型预测/生成 |
| serving | 服务化 | 模型部署上线 |
| quantization | 量化 | 模型精度压缩 |
| INT8/INT4 | 8位/4位整数量化 | 低比特量化 |
| FP16/BF16 | 半精度/脑浮点 | 混合精度 |
| pruning | 剪枝 | 去除冗余参数 |
| distillation | 蒸馏 | 知识迁移压缩 |
| KV cache | 键值缓存 | 加速生成 |
| batch inference | 批推理 | 批量处理请求 |
| streaming | 流式输出 | 逐步返回结果 |
RAG相关
| 术语 | 全称 | 解释 |
|---|---|---|
| RAG | Retrieval-Augmented Generation | 检索增强生成 |
| retrieval | 检索 | 从知识库找相关文档 |
| embedding | 嵌入 | 将文本转为向量 |
| vector DB | 向量数据库 | 存储向量数据 |
| chunking | 切分 | 将文档分成小块 |
| rerank | 重排序 | 调整检索结果顺序 |
| hybrid search | 混合检索 | 稀疏+稠密检索 |
| BM25 | Best Matching 25 | 关键词检索算法 |
| 召回率 | recall | 检索到相关文档的比例 |
| 精确率 | precision | 检索结果中相关比例 |
Agent相关
| 术语 | 全称 | 解释 |
|---|---|---|
| Agent | 智能体 | 能自主行动的AI系统 |
| tool calling | 工具调用 | Agent使用外部工具 |
| function calling | 函数调用 | 模型调用预定义函数 |
| planning | 规划 | Agent分解和计划任务 |
| memory | 记忆 | Agent存储和检索信息 |
| ReAct | Reason+Act | 推理+行动框架 |
| reflexion | 反思 | Agent自我反思改进 |
| multi-agent | 多智能体 | 多个Agent协作 |
| MCP | Model Context Protocol | 模型上下文协议 |
| A2A | Agent to Agent | Agent间通信协议 |
评估相关
| 术语 | 全称 | 解释 |
|---|---|---|
| perplexity | 困惑度 | 语言模型评估指标 |
| BLEU | Bilingual Evaluation Understudy | 机器翻译评估 |
| ROUGE | Recall-Oriented Understudy for Gisting Evaluation | 摘要评估 |
| ARC | AI2 Reasoning Challenge | 推理评估 |
| MMLU | Massive Multitask Language Understanding | 多任务理解 |
| HumanEval | HumanEval | 代码生成评估 |
| M贝尔 | MMLU | 通用知识评估 |
| GSM8K | Grade School Math 8K | 数学推理评估 |
| chat benchmark | 对话基准 | 对话能力评估 |
7.2 常见缩写对照表
| 缩写 | 全称 | 中文 |
|---|---|---|
| AI | Artificial Intelligence | 人工智能 |
| ML | Machine Learning | 机器学习 |
| DL | Deep Learning | 深度学习 |
| NLP | Natural Language Processing | 自然语言处理 |
| CV | Computer Vision | 计算机视觉 |
| ASR | Automatic Speech Recognition | 自动语音识别 |
| TTS | Text-to-Speech | 语音合成 |
| NLU | Natural Language Understanding | 自然语言理解 |
| NLG | Natural Language Generation | 自然语言生成 |
| KG | Knowledge Graph | 知识图谱 |
| QA | Question Answering | 问答系统 |
| OCR | Optical Character Recognition | 光学字符识别 |
| API | Application Programming Interface | 应用程序接口 |
| SDK | Software Development Kit | 软件开发包 |
| SLA | Service Level Agreement | 服务级别协议 |
| ROI | Return on Investment | 投资回报率 |
| POC | Proof of Concept | 概念验证 |
| MVP | Minimum Viable Product | 最小可行产品 |
| CI/CD | Continuous Integration/Continuous Deployment | 持续集成/部署 |
| K8s | Kubernetes | 容器编排系统 |
7.3 大模型评估标准
7.3.1 通用能力评估
| 能力 | 评估指标 | 说明 |
|---|---|---|
| 语言理解 | MMLU、BBH | 通用知识、推理 |
| 代码能力 | HumanEval、MBPP | 代码生成 |
| 数学能力 | GSM8K、MATH | 数学解题 |
| 对话能力 | MT-Bench、ChatArena | 多轮对话 |
| 中文能力 | CMMLU、C-Eval | 中文理解 |
7.3.2 垂直能力评估
| 领域 | 评估数据集 | 说明 |
|---|---|---|
| 医疗 | MedQA、PubMedQA | 医学问答 |
| 法律 | JEQ-Bench | 法律咨询 |
| 金融 | FinanceIQ | 金融知识 |
| 教育 | MathVista | 数学教学 |
| 代码 | SWE-bench | 代码修复 |
7.4 顶级学术会议
| 会议 | 全称 | 领域 | 难度 |
|---|---|---|---|
| NeurIPS | Neural Information Processing Systems | 机器学习 | ⭐⭐⭐⭐⭐ |
| ICML | International Conference on Machine Learning | 机器学习 | ⭐⭐⭐⭐⭐ |
| ICLR | International Conference on Learning Representations | 表征学习 | ⭐⭐⭐⭐⭐ |
| ACL | Annual Meeting of the Association for Computational Linguistics | 计算语言学 | ⭐⭐⭐⭐ |
| EMNLP | Empirical Methods in Natural Language Processing | NLP实证方法 | ⭐⭐⭐⭐ |
| NAACL | North American Chapter of the ACL | 北美NLP | ⭐⭐⭐ |
| CVPR | Computer Vision and Pattern Recognition | 计算机视觉 | ⭐⭐⭐⭐⭐ |
| ICCV | International Conference on Computer Vision | 计算机视觉 | ⭐⭐⭐⭐⭐ |
| ECCV | European Conference on Computer Vision | 计算机视觉 | ⭐⭐⭐⭐ |
| AAAI | AAAI Conference on Artificial Intelligence | AI | ⭐⭐⭐⭐ |
| IJCAI | International Joint Conference on AI | AI | ⭐⭐⭐⭐ |
| SIGIR | Special Interest Group on Information Retrieval | 信息检索 | ⭐⭐⭐⭐ |
| KDD | ACM SIGKDD Conference on Knowledge Discovery | 数据挖掘 | ⭐⭐⭐⭐⭐ |
| RecSys | ACM Conference on Recommender Systems | 推荐系统 | ⭐⭐⭐⭐ |
| MLSys | Machine Learning and Systems | AI系统 | ⭐⭐⭐⭐⭐ |
| OSDI | USENIX Symposium on Operating Systems Design and Implementation | 系统 | ⭐⭐⭐⭐⭐ |
最后
对于正在迷茫择业、想转行提升,或是刚入门的程序员、编程小白来说,有一个问题几乎人人都在问:未来10年,什么领域的职业发展潜力最大?
答案只有一个:人工智能(尤其是大模型方向)
当下,人工智能行业正处于爆发式增长期,其中大模型相关岗位更是供不应求,薪资待遇直接拉满——字节跳动作为AI领域的头部玩家,给硕士毕业的优质AI人才(含大模型相关方向)开出的月基础工资高达5万—6万元;即便是非“人才计划”的普通应聘者,月基础工资也能稳定在4万元左右。
再看阿里、腾讯两大互联网大厂,非“人才计划”的AI相关岗位应聘者,月基础工资也约有3万元,远超其他行业同资历岗位的薪资水平,对于程序员、小白来说,无疑是绝佳的转型和提升赛道。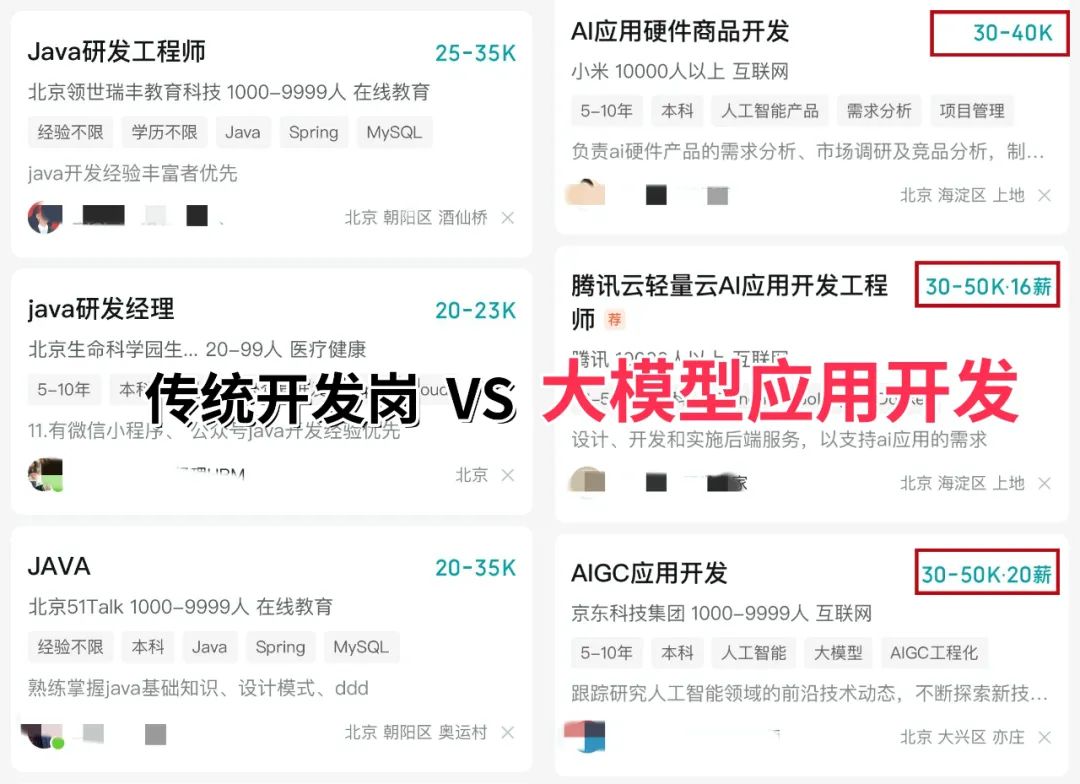
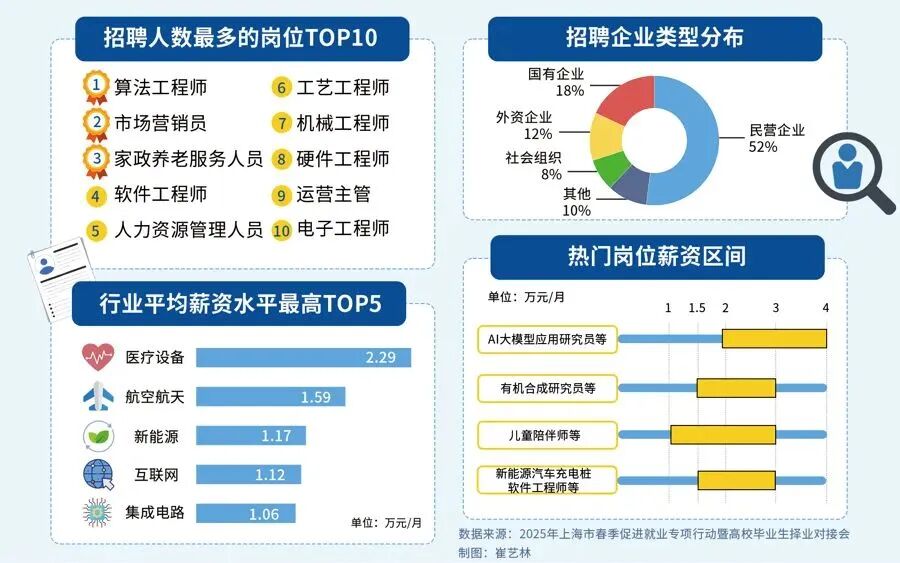
对于想入局大模型、抢占未来10年行业红利的程序员和小白来说,现在正是最好的学习时机:行业缺口大、大厂需求旺、薪资天花板高,只要找准学习方向,稳步提升技能,就能轻松摆脱“低薪困境”,抓住AI时代的职业机遇。
如果你还不知道从何开始,我自己整理一套全网最全最细的大模型零基础教程,我也是一路自学走过来的,很清楚小白前期学习的痛楚,你要是没有方向还没有好的资源,根本学不到东西!
下面是我整理的大模型学习资源,希望能帮到你。
👇👇扫码免费领取全部内容👇👇
1、大模型学习路线

2、从0到进阶大模型学习视频教程
从入门到进阶这里都有,跟着老师学习事半功倍。

3、 入门必看大模型学习书籍&文档.pdf(书面上的技术书籍确实太多了,这些是我精选出来的,还有很多不在图里)

4、 AI大模型最新行业报告
2026最新行业报告,针对不同行业的现状、趋势、问题、机会等进行系统地调研和评估,以了解哪些行业更适合引入大模型的技术和应用,以及在哪些方面可以发挥大模型的优势。

5、面试试题/经验

【大厂 AI 岗位面经分享(107 道)】

【AI 大模型面试真题(102 道)】

【LLMs 面试真题(97 道)】

6、大模型项目实战&配套源码

适用人群

四阶段学习规划(共90天,可落地执行)
第一阶段(10天):初阶应用
该阶段让大家对大模型 AI有一个最前沿的认识,对大模型 AI 的理解超过 95% 的人,可以在相关讨论时发表高级、不跟风、又接地气的见解,别人只会和 AI 聊天,而你能调教 AI,并能用代码将大模型和业务衔接。
- 大模型 AI 能干什么?
- 大模型是怎样获得「智能」的?
- 用好 AI 的核心心法
- 大模型应用业务架构
- 大模型应用技术架构
- 代码示例:向 GPT-3.5 灌入新知识
- 提示工程的意义和核心思想
- Prompt 典型构成
- 指令调优方法论
- 思维链和思维树
- Prompt 攻击和防范
- …
第二阶段(30天):高阶应用
该阶段我们正式进入大模型 AI 进阶实战学习,学会构造私有知识库,扩展 AI 的能力。快速开发一个完整的基于 agent 对话机器人。掌握功能最强的大模型开发框架,抓住最新的技术进展,适合 Python 和 JavaScript 程序员。
- 为什么要做 RAG
- 搭建一个简单的 ChatPDF
- 检索的基础概念
- 什么是向量表示(Embeddings)
- 向量数据库与向量检索
- 基于向量检索的 RAG
- 搭建 RAG 系统的扩展知识
- 混合检索与 RAG-Fusion 简介
- 向量模型本地部署
- …
第三阶段(30天):模型训练
恭喜你,如果学到这里,你基本可以找到一份大模型 AI相关的工作,自己也能训练 GPT 了!通过微调,训练自己的垂直大模型,能独立训练开源多模态大模型,掌握更多技术方案。
到此为止,大概2个月的时间。你已经成为了一名“AI小子”。那么你还想往下探索吗?
- 为什么要做 RAG
- 什么是模型
- 什么是模型训练
- 求解器 & 损失函数简介
- 小实验2:手写一个简单的神经网络并训练它
- 什么是训练/预训练/微调/轻量化微调
- Transformer结构简介
- 轻量化微调
- 实验数据集的构建
- …
第四阶段(20天):商业闭环
对全球大模型从性能、吞吐量、成本等方面有一定的认知,可以在云端和本地等多种环境下部署大模型,找到适合自己的项目/创业方向,做一名被 AI 武装的产品经理。
-
硬件选型
-
带你了解全球大模型
-
使用国产大模型服务
-
搭建 OpenAI 代理
-
热身:基于阿里云 PAI 部署 Stable Diffusion
-
在本地计算机运行大模型
-
大模型的私有化部署
-
基于 vLLM 部署大模型
-
案例:如何优雅地在阿里云私有部署开源大模型
-
部署一套开源 LLM 项目
-
内容安全
-
互联网信息服务算法备案
-
…
👇👇扫码免费领取全部内容👇👇
3、这些资料真的有用吗?
这份资料由我和鲁为民博士(北京清华大学学士和美国加州理工学院博士)共同整理,现任上海殷泊信息科技CEO,其创立的MoPaaS云平台获Forrester全球’强劲表现者’认证,服务航天科工、国家电网等1000+企业,以第一作者在IEEE Transactions发表论文50+篇,获NASA JPL火星探测系统强化学习专利等35项中美专利。本套AI大模型课程由清华大学-加州理工双料博士、吴文俊人工智能奖得主鲁为民教授领衔研发。
资料内容涵盖了从入门到进阶的各类视频教程和实战项目,无论你是小白还是有些技术基础的技术人员,这份资料都绝对能帮助你提升薪资待遇,转行大模型岗位。

这份完整版的大模型 AI 学习资料已经上传CSDN,朋友们如果需要可以微信扫描下方CSDN官方认证二维码免费领取【保证100%免费】

欢迎加入DeepSeek 技术社区。在这里,你可以找到志同道合的朋友,共同探索AI技术的奥秘。
更多推荐


 7
7 0
0- 0



 已为社区贡献148条内容
已为社区贡献148条内容

所有评论(0)