DeepSeek V4编程能力实测:写代码、修Bug、解释代码表现如何?
最近 DeepSeek V4 的热度很高,很多开发者关心的不只是它会不会聊天,而是它到底能不能真正帮我们写代码、修 Bug、解释代码逻辑,甚至参与到日常开发流程里。这篇文章就从开发者视角,围绕。
DeepSeek V4编程能力实测:写代码、修Bug、解释代码表现如何?
最近 DeepSeek V4 的热度很高,很多开发者关心的不只是它会不会聊天,而是它到底能不能真正帮我们写代码、修 Bug、解释代码逻辑,甚至参与到日常开发流程里。
这篇文章就从开发者视角,围绕 DeepSeek V4编程能力 做一次简单实测,重点看三个方向:
- 写代码能力
- 修 Bug 能力
- 解释代码能力

一、为什么要单独测编程能力?
大模型的综合能力很重要,但对程序员来说,真正有价值的是它能不能解决具体开发问题。
比如:
- 能不能根据需求写出可运行的代码?
- 能不能发现隐藏的边界问题?
- 能不能解释一段陌生代码?
- 能不能给出合理的实现思路?
- 能不能避免过度设计?
所以,测试 DeepSeek V4编程能力,不能只看它回答得长不长,而要看代码是否准确、清晰、可执行。
二、测试一:写代码能力
我先给 DeepSeek V4 一个常见开发任务:
用 Python 写一个函数,读取 CSV 文件,按指定列分组统计平均值,并处理缺失值。
这个任务看似简单,但其实包含几个关键点:
- 是否能正确读取 CSV
- 是否能按列分组
- 是否能处理缺失值
- 是否能给出可复用函数
- 是否能避免写死字段名
一个表现较好的模型,应该不会只写几行演示代码,而是会考虑参数化、异常处理和结果输出。
例如比较合理的实现思路是:
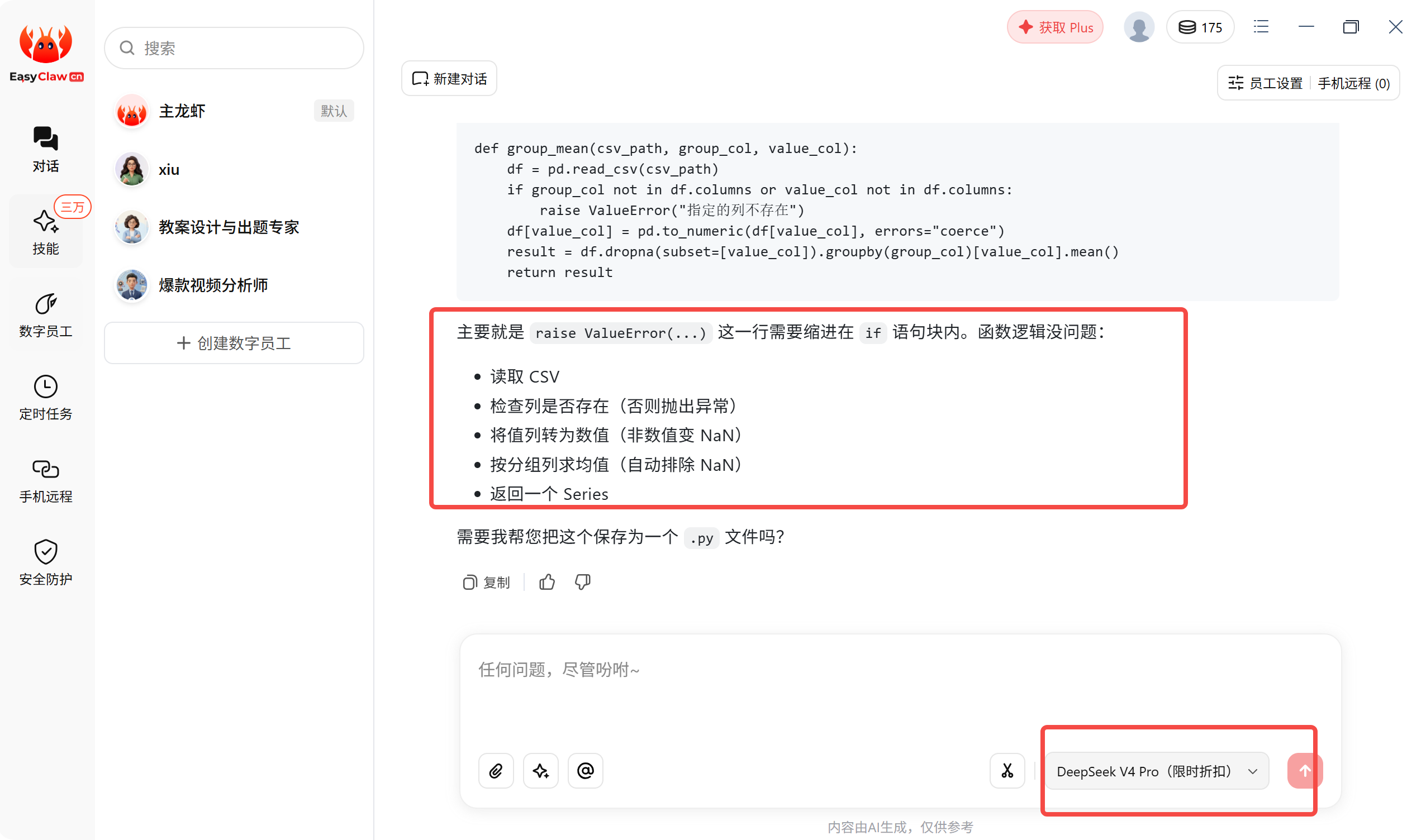
import pandas as pd
def group_mean(csv_path, group_col, value_col):
df = pd.read_csv(csv_path)
if group_col not in df.columns or value_col not in df.columns:
raise ValueError("指定的列不存在")
df[value_col] = pd.to_numeric(df[value_col], errors="coerce")
result = df.dropna(subset=[value_col]).groupby(group_col)[value_col].mean()
return result
从这个任务来看,DeepSeek V4 如果能主动处理缺失值、字段不存在、数值类型转换等问题,就说明它不只是“会写代码”,而是具备一定工程意识。
三、测试二:修 Bug能力
接着测试修 Bug 能力。我给它一段有明显边界问题的代码:
def average(numbers):
total = 0
for n in numbers:
total += n
return total / len(numbers)
print(average([1, 2, 3, 4, 5]))
print(average([]))
这段代码的问题是:当传入空列表时,len(numbers) 等于 0,会触发 ZeroDivisionError。
理想回答应该指出:
- 空列表是边界情况
- 原代码没有处理除以 0 的问题
- 应该明确返回值策略
- 可以返回
None,也可以抛出更清晰的异常
更推荐的修复方式是:
def average(numbers):
if not numbers:
raise ValueError("numbers cannot be empty")
total = 0
for n in numbers:
total += n
return total / len(numbers)
这里重点不是 DeepSeek V4 能不能看出错误,而是它能不能解释为什么错、如何修复,以及不同修复方案的适用场景。
如果一个模型只说“空数组会报错”,但不给修复建议,说明它的代码分析能力还不够完整。如果它能进一步说明返回 0、返回 None、抛异常之间的区别,就说明它更适合真实开发场景。
四、测试三:解释代码能力
很多时候,我们不是让 AI 写新代码,而是让它帮我们读旧代码。
比如给它这样一段代码:
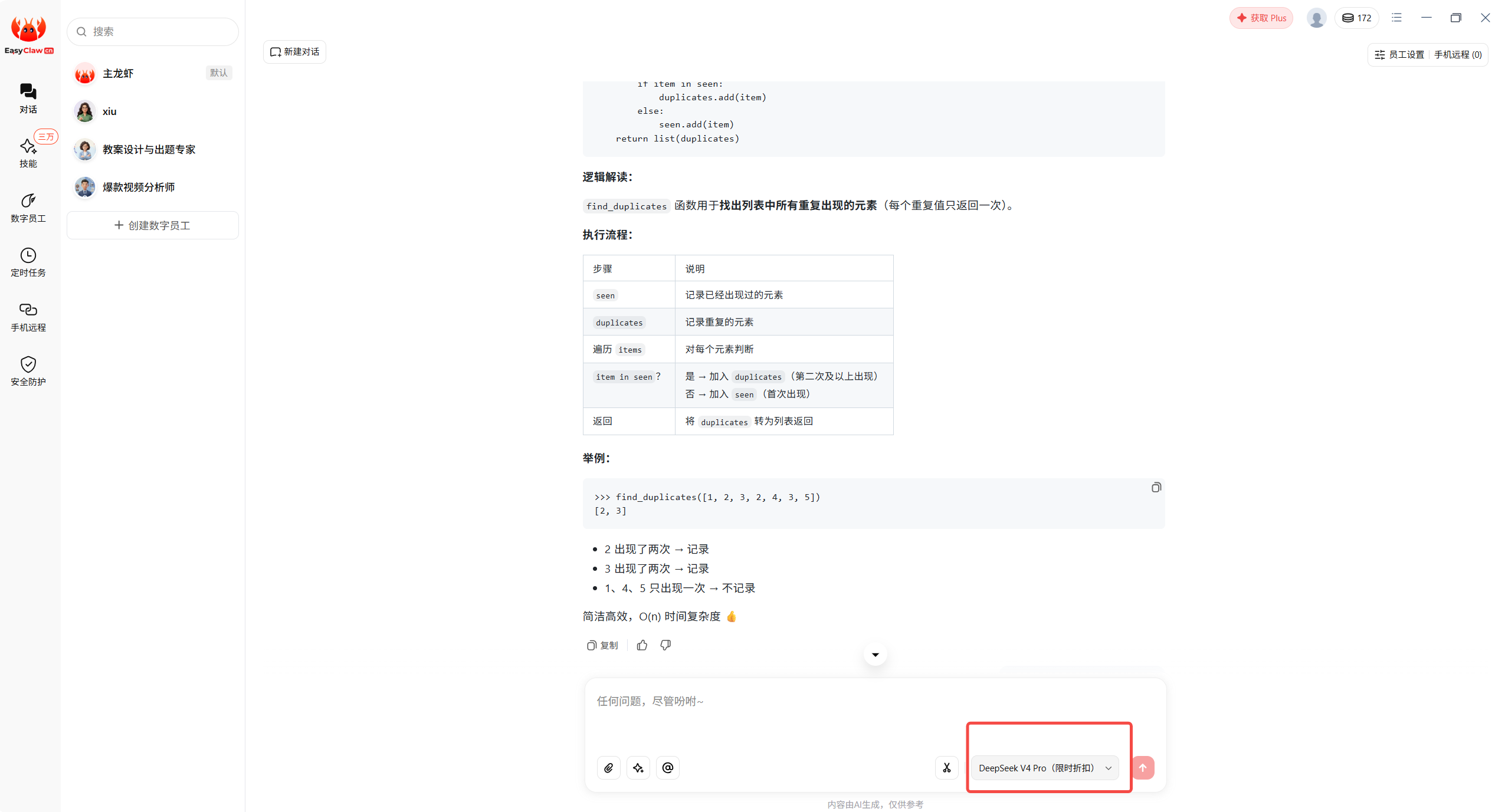
def find_duplicates(items):
seen = set()
duplicates = set()
for item in items:
if item in seen:
duplicates.add(item)
else:
seen.add(item)
return list(duplicates)
一个好的解释应该包含:
- 这段代码的功能:找出列表中的重复元素
seen的作用:记录已经出现过的元素duplicates的作用:记录重复出现的元素- 时间复杂度:大致为 O(n)
- 注意点:返回结果是列表,但顺序不保证稳定
如果 DeepSeek V4 能解释到复杂度和返回顺序问题,说明它不只是逐行翻译代码,而是真的理解了代码行为。
五、DeepSeek V4 Coding能力适合哪些场景?
从开发者角度看,deepseek v4 coding 更适合这些任务:
| 场景 | 是否适合 |
|---|---|
| 写小工具脚本 | 适合 |
| 解释陌生代码 | 适合 |
| 修复常见 Bug | 适合 |
| 生成单元测试 | 适合 |
| 复杂系统架构设计 | 需要人工审核 |
| 高安全要求代码 | 必须人工审查 |
| 大规模项目重构 | 不建议完全依赖 |
也就是说,DeepSeek V4 可以作为一个开发辅助工具,但不应该替代代码审查和测试流程。
六、DeepSeek V4 Coding Plan应该怎么用?
很多人搜索 deepseek v4 coding plan,其实可以理解为:让模型先给出编码计划,再写代码。
这比直接让模型写代码更稳。
比如不要直接问:
帮我写一个用户登录系统。
更好的问法是:
请先给出实现用户登录系统的 coding plan,包括数据库表设计、接口设计、密码加密、登录态管理和异常处理。确认方案后再写代码。
这样做有几个好处:
- 先看方案,避免模型一上来就乱写
- 可以提前发现设计问题
- 方便控制技术栈
- 更适合复杂任务拆解
- 后续代码更容易维护
对开发者来说,Coding Plan 的价值不只是“写代码”,而是让模型参与到需求拆解和技术方案设计里。
七、在 EasyClaw中体验 DeepSeek V4 Pro
对于很多开发者来说,真正关心的不是模型参数有多强,而是能不能马上用起来。
目前 EasyClaw已经正式接入 DeepSeek V4 Pro。用户不需要自己申请和配置复杂的模型接口,也不需要切换多个平台,直接在 EasyClaw中就可以使用 DeepSeek V4 Pro完成代码生成、Bug修复、代码解释和 coding plan等任务。
你可以在 EasyClaw聊天框中直接输入:
请用 Python写一个 CSV数据分组统计函数,并处理缺失值。
或者:
请检查下面这段代码有什么边界问题,并给出修复版本。
模型会直接在聊天框中返回结果,适合用来快速验证 DeepSeek V4 Pro在编程任务中的实际表现。
如果你想亲自体验 DeepSeek V4 Pro的代码能力,可以直接打开 EasyClaw进行测试。
体验地址:EasyClaw官网
八、我的结论
整体来看,DeepSeek V4 在编程场景下比较适合做三类事情。
第一,写中小型代码片段,比如 Python脚本、数据处理函数、接口示例等。
第二,修复常见 Bug,尤其是空值、边界条件、类型转换、下标越界这类问题。
第三,解释代码逻辑,帮助开发者快速理解陌生代码。
但它也不是万能的。对于生产环境代码,尤其涉及权限、安全、支付、并发、数据一致性等问题时,仍然需要人工审查、单元测试和真实运行验证。
如果你想测试 DeepSeek V4编程能力,建议不要只问一个问题,而是用同一组任务测试:
- 写代码
- 修 Bug
- 解释代码
- 生成测试用例
- 给出 coding plan
- 多轮修改需求
这样得到的结果会比单纯看榜单更接近真实开发体验。
对开发者来说,最适合自己的模型,不一定是参数最大或榜单最高的那个,而是能在你的实际任务里稳定输出、容易验证、成本可控的那个。

欢迎加入DeepSeek 技术社区。在这里,你可以找到志同道合的朋友,共同探索AI技术的奥秘。
更多推荐



 8
8 0
0- 0



 已为社区贡献6条内容
已为社区贡献6条内容

所有评论(0)