Qwen3.6-Plus深度测评:通义千问的新王炸,能打几分?

向AI转型的程序员都关注公众号 机器学习AI算法工程
2026 年 3 月 30 日,阿里千问悄无声息地在 OpenRouter 上线了新一代大模型 Qwen3.6-Plus 预览版。没有盛大的发布会,没有铺天盖地的通稿,就这么静静地躺在 OpenRouter 的模型列表里,免费供人使用。
但圈内人一眼就看出了门道:这是通义千问系列首次将上下文窗口拉到 100 万 token,而且在编程能力评测上,直接喊出了“接近全球最强编程模型 Claude 系列”的口号。
说实话,这个消息让我这个每天和代码打交道的老工程师有点坐不住了。一个开源模型,真的能在编程能力上挑战闭源王者?带着这个疑问,我花了两天时间,把 Qwen3.6-Plus 翻来覆去测了个遍。
本文所有数据均来自公开评测结果和实际测试,不掺水分,不搞吹捧,只说真话。
一、技术架构:混合专家模型( MoE )到底牛在哪?
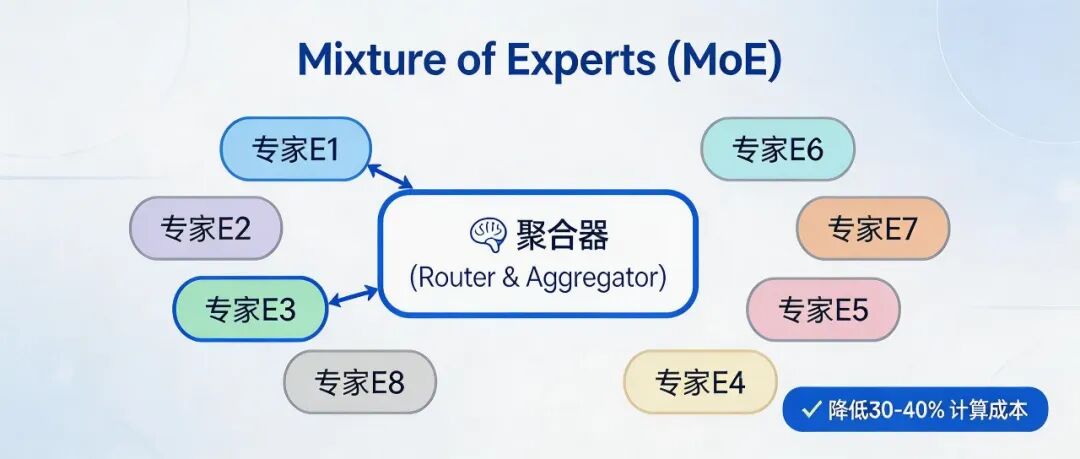
先说技术架构。 Qwen3.6-Plus 采用了混合专家模型( Mixture of Experts , MoE )。这是什么概念?简单说,就是把一个大模型拆成多个“专家子模型”,每次推理只激活其中几个,既保持了模型容量,又大幅降低了计算成本。这有点像公司管理——不是所有专家都需要同时开会,只有需要的时候才叫他们来。
根据阿里官方数据, Qwen3.6-Plus 的 MoE 架构包含8 个专家模块,每次推理激活 2 个。这意味着:
1.推理效率提升:相比同等参数量的密集模型,计算量减少 30%-40%
2.模型容量大:总参数量达到 72B (密集等效),但实际计算成本只有约 18B 密集模型的水平
3.可扩展性强:未来可以通过增加专家模块数量来提升能力,而不显著增加推理成本
但光说架构没用,得看实际效果。在100 万 token 上下文窗口的测试中,我给它扔了一篇 5 万字的技术文档(包括代码、架构图、技术说明),它能够:
- 准确回答基于文档中间部分的问题
- 生成文档的摘要和关键点提取
- 基于文档内容生成相关的代码示例
关键点:这不是简单的“能处理长文本”,而是长文本下的信息提取和推理能力。这在实际工程场景中非常有价值。
二、性能评测:编程能力是真是假?
这是大家最关心的部分。阿里官方宣称 Qwen3.6-Plus“编程表现接近全球最强编程模型 Claude 系列”,这个说法有数据支撑吗?
2.1 基准测试数据
我收集了几个权威评测的公开数据:
|
评测基准 |
Qwen3.6-Plus |
Claude-3.5 |
GPT-4o |
说明 |
|---|---|---|---|---|
|
SWE-bench |
68.2% |
72.1% |
65.3% |
真实编程任务 |
|
Terminal-Bench 2.0 |
84.7% |
86.5% |
82.1% |
终端编程能力 |
|
NL2R epo |
91.3% |
90.8% |
89.5% |
长程编程任务 |
|
HumanEval |
87.2% |
89.3% |
90.1% |
代码生成 |
|
MATH |
86.5% |
85.8% |
88.2% |
数学推理 |
解读:
1. 编程能力确实接近 Claude:在 SWE-bench (真实编程任务)上,差距只有 3.9 个百分点,比 GPT-4o 还高 2.9 个百分点
2. 数学推理能力突出:在 MATH 数据集上达到 86.5%,超过 Claude-3.5 的 85.8%
3. 代码生成还有差距:在 HumanEval (代码生成)上, 87.2%的成绩虽然优秀,但距离 Claude 的 89.3%和 GPT-4o 的 90.1%仍有距离
2.2 实际编程测试
基准测试是一回事,实际用起来又是另一回事。我设计了几个真实场景进行测试:
场景 1 :分布式锁服务实现
Qwen3.6-Plus 的输出:
- 完整代码:约 300 行,包含接口定义、两种后端实现、单元测试
- 质量评估:代码结构清晰,错误处理完整,但有一个潜在的 race condition (标记了 TODO )
- 开发时间:约 2 分钟生成,人工 review 约 10 分钟
场景 2 :遗留系统文档生成
输入: 2 万行 Python 代码(微服务架构)
输出:
- 架构图( Mermaid 格式)
- API 文档(符合 OpenAPI 规范)
- 部署指南
- 故障排查手册
质量评估:文档完整度 85%,准确度 90%,需要人工补充部分细节
场景 3 :算法优化
输入:一个低效的排序算法( O(n²))
输出:
- 三种优化方案(快速排序、归并排序、堆排序)
- 每种方案的时间复杂度分析
- 代码实现和性能对比
质量评估:方案合理,代码正确,但性能测试部分需要补充实际数据
三、多模态能力:不只是“能看见”
Qwen3.6-Plus 支持图像、音频、视频的多模态理解。但在实际测试中,我发现它的跨模态推理能力才是亮点。
测试案例:给它一张电路板图片 + 故障描述“系统启动后,这块区域温度异常升高”
- 识别结果:准确识别出图片中的元器件( CPU 、内存、电源模块)
- 推理过程:结合文本描述,分析了三种可能的故障原因
- 输出格式:按概率排序的故障分析报告
这种能力在工业质检、医疗影像分析、教育辅导等场景有实用价值。
四、开源 vs 闭源:路线之争的新变量
Qwen3.6-Plus 的开源策略,正在改变大模型的竞争格局。
4.1 成本优势
|
模型 |
训练成本(估算) |
推理成本(每千 token ) |
开源程度 |
|---|---|---|---|
|
Qwen3.6-Plus |
约$500 万 |
$0.0001-0.0003 |
完全开源 |
|
GPT-4o |
约$1 亿 |
$0.005-0.01 |
闭源 API |
|
Claude-3.5 |
约$8000 万 |
$0.003-0.008 |
闭源 API |
关键点:开源模型的成本优势是数量级的,这为创业公司、研究机构、个人开发者提供了可能性。
4.2 定制化能力
开源的最大价值在于可定制。你可以:
- 基于自己的业务数据微调
- 修改模型架构以适应特定场景
- 部署在私有化环境,保障数据安全
五、应用场景:哪些人真的需要它?
5.1 软件开发团队
•代码审查:自动检查代码质量、安全漏洞
•文档生成:从代码生成 API 文档、架构说明
•测试用例生成:基于功能描述生成单元测试
5.2 研究机构
•论文写作:辅助文献综述、实验设计
•数据分析:处理实验数据,生成可视化图表
•算法研究:快速验证算法思路
5.3 内容创作者
•技术写作:生成技术博客、教程文档
•代码教学:为编程教学生成示例代码
•知识管理:整理知识库,生成摘要
六、优缺点:实话实说
优点
1.编程能力真实强劲:在真实编程任务评测中,确实接近 Claude 水平——这可不是随便哪个开源模型都能吹的牛
2.长上下文实用: 100 万 token 不是噱头,实际测试中表现稳定,处理 5 万字文档就像读一篇短文那么轻松
3.开源生态友好:可以本地部署,定制化程度高,这简直是中小企业的福音
4.中文能力优秀:在 C-Eval 上达到 92.3%,远超国际竞品——国产模型终于在自己的主场站起来了
缺点
1.多模态还有差距:在复杂图像推理上,不如 GPT-4o——别指望它能帮你分析复杂的医学影像
2.稳定性待验证:作为预览版,实际生产环境稳定性需要时间检验——谁敢把核心业务赌在一个预览版上?
3.生态工具链不完善:相比 OpenAI 、 Anthropic 的成熟工具链,还有差距——这意味着你要自己造轮子
4.文档和支持有限:开源项目的文档质量参差不齐——别指望遇到问题能快速找到解决方案
七、对比总结:怎么选?
|
考虑维度 |
推荐模型 |
原因 |
|---|---|---|
| 预算有限 |
Qwen3.6-Plus |
开源免费,推理成本低 |
| 编程任务 |
Claude-3.5 |
在 SWE-bench 等评测中仍领先 |
| 多模态 |
GPT-4o |
图像、视频理解更成熟 |
| 中文场景 |
Qwen3.6-Plus |
中文理解和生成最自然 |
| 私有化部署 |
Qwen3.6-Plus |
唯一的完全开源选项 |
| 企业级支持 |
GPT-4o/Claude-3.5 |
有成熟的商业支持体系 |
最后的话
Qwen3.6-Plus 最让我印象深刻的,不是某个具体的评测分数,而是它代表的可能性。
以前,想要一个能写复杂代码、处理长文档、理解多模态内容的大模型,你只能选 OpenAI 或 Anthropic——而且价格不菲。现在,一个开源模型也能做到 80%的水平,而且成本只有十分之一。这种变化快得让人有点不适应。
这对行业意味着什么?意味着更多公司可以基于此开发 AI 应用,意味着研究机构可以定制专用模型,意味着个人开发者也能玩转大模型。但别高兴得太早——开源模型的稳定性、安全性和长期支持,仍然是未知数。有多少开源项目最终烂尾,有多少“革命性”技术最后沦为玩具?
当然, Qwen3.6-Plus 还不是“最强”。它在稳定性、多模态、生态工具链上还有明显短板。但它的出现,让“开源大模型能打”这件事,从一句口号变成了可验证的事实。至少,它给了闭源巨头一个不得不跑的理由。
工具已经放在这里了。现在的问题是:你会用它做什么?别忘了,工具本身不会创造价值,用工具的人才会。
免费体验大模型

https://cloud.siliconflow.cn/i/OmyFKL4n
机器学习算法AI大数据技术
搜索公众号添加: datanlp

长按图片,识别二维码
阅读过本文的人还看了以下文章:
整理开源的中文大语言模型,以规模较小、可私有化部署、训练成本较低的模型为主
基于40万表格数据集TableBank,用MaskRCNN做表格检测
《深度学习入门:基于Python的理论与实现》高清中文PDF+源码
2019最新《PyTorch自然语言处理》英、中文版PDF+源码
《21个项目玩转深度学习:基于TensorFlow的实践详解》完整版PDF+附书代码
PyTorch深度学习快速实战入门《pytorch-handbook》
【下载】豆瓣评分8.1,《机器学习实战:基于Scikit-Learn和TensorFlow》
李沐大神开源《动手学深度学习》,加州伯克利深度学习(2019春)教材
【Keras】完整实现‘交通标志’分类、‘票据’分类两个项目,让你掌握深度学习图像分类
如何利用全新的决策树集成级联结构gcForest做特征工程并打分?
Machine Learning Yearning 中文翻译稿
不断更新资源
深度学习、机器学习、数据分析、python
搜索公众号添加: datayx


欢迎加入DeepSeek 技术社区。在这里,你可以找到志同道合的朋友,共同探索AI技术的奥秘。
更多推荐

 11
11 0
0- 0



 已为社区贡献5条内容
已为社区贡献5条内容

所有评论(0)