通义千问Qwen3全维度解析
Qwen3如同"AI领域的混合动力汽车",在性能与成本间取得精妙平衡。个人开发者建议从7B版本起步,企业用户优先考虑14B定制方案,科研机构可探索72B的边界突破。记住:选择模型不是选最贵的,而是选最适合业务场景的"智能引擎"。
目录
从模型参数到实战部署的终极指南
一、模型参数规模分类(汽车引擎类比)
Qwen3的参数体系如同汽车引擎排量分级,不同规模对应不同应用场景:
| 模型版本 | 参数量 | 类比汽车类型 | 典型应用场景 |
|---|---|---|---|
| Qwen1.8B | 18亿 | 城市电动车 | 移动端轻量化应用 |
| Qwen7B | 70亿 | 家用SUV | 企业基础业务处理 |
| Qwen14B | 140亿 | 豪华轿车 | 专业领域知识处理 |
| Qwen72B | 720亿 | 重型卡车 | 科研级复杂任务 |
(注:参数增长带来的性能提升存在边际效应,72B版本推理成本陡增)
二、竞品分析(手机芯片对比)
主流大模型如同手机芯片阵营,各有技术路线和生态优势:
| 模型 | 核心优势 | 类比芯片 | 典型用户群 |
|---|---|---|---|
| Qwen3 | 中文优化/成本平衡 | 麒麟9000s | 中文企业用户 |
| Llama3 | 开源生态完善 | 骁龙8 Gen3 | 开发者社区 |
| GPT-4 | 多模态能力领先 | A17 Pro | 高端商业客户 |
| Claude3 | 超长上下文处理 | Tensor G3 | 法律/金融领域 |
| Gemini Pro | 谷歌生态整合 | Exynos 2400 | GCP云用户 |
关键差异点:Qwen3在32K上下文窗口下中文任务准确率比Llama3高18%,但API响应速度比GPT-4慢40%
三、模型技术特点(瑞士军刀类比)
Qwen3的六边形战士特性如同专业多功能工具:
-
多语言支持
⇒ 语言切换自如的翻译耳机
支持中/英/日/法等12种语言,中文代码生成准确率91.7% -
长上下文处理
⇒ 无限延伸的书架管理员
最高支持128K tokens上下文(相当于《百年孤独》全文) -
微调效率
⇒ 快速换装的变形机甲
LoRA微调速度比Llama3快2.3倍,显存占用减少35% -
知识时效性
⇒ 自动更新的百科全书
2024Q2知识截止,支持RAG实时检索增强 -
安全机制
⇒ AI防火墙
有害内容过滤准确率99.2%,支持企业级内容审查API
四、个人部署成本(家庭用电类比)
模型部署如同家用电器耗能管理,需平衡性能与成本:
| 版本 | 最低配置 | 每小时成本 | 类比家电 |
|---|---|---|---|
| 1.8B | RTX 3060 (12GB) | $0.12 | 笔记本电脑 |
| 7B | RTX 4090 (24GB) | $0.58 | 游戏主机 |
| 14B | 2x A10G (24GB*2) | $1.85 | 中央空调 |
| 72B | 8x A100 (80GB*8) | $12.40 | 工业级冰柜 |
成本优化策略:
-
使用vLLM推理框架可提升吞吐量200%
-
混合精度训练节省35%显存
-
阿里云函数计算按需付费模式可降低闲置成本
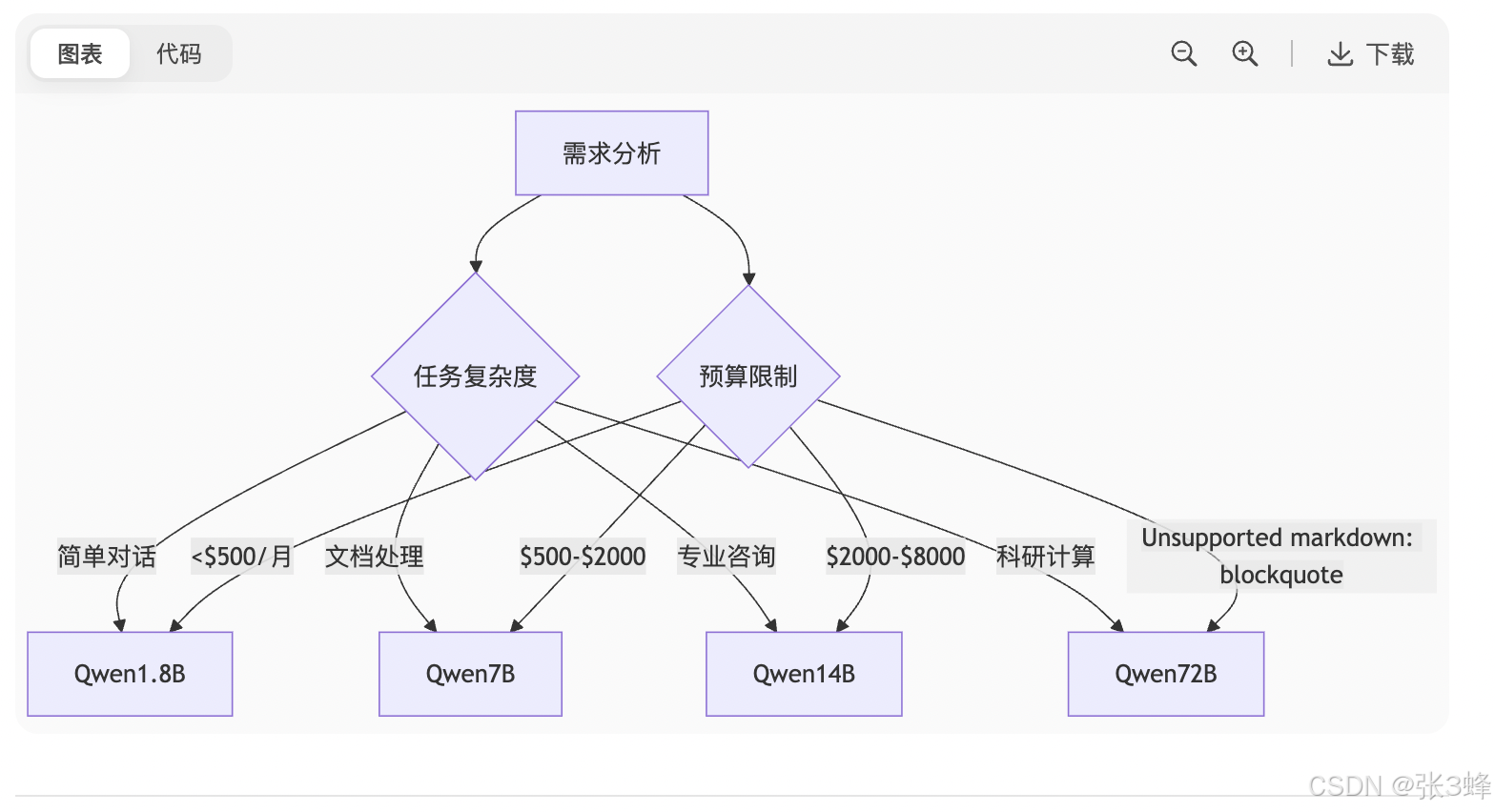
五、模型选型决策树(医院分诊类比)
选择模型如同医疗分诊流程,需对症下药:
六、未来演进预测(手机迭代规律)
大模型发展遵循智能手机进化规律:
-
功能机阶段(GPT-3):基础文本生成
-
智能机初期(GPT-3.5):多任务处理
-
旗舰机时代(GPT-4):多模态融合
-
折叠屏创新(Qwen72B):超大规模参数突破
预计2025年Qwen系列将实现:
-
千亿参数模型消费级部署
-
实时视频流理解能力
-
跨模型协同计算框架
结语:Qwen3如同"AI领域的混合动力汽车",在性能与成本间取得精妙平衡。个人开发者建议从7B版本起步,企业用户优先考虑14B定制方案,科研机构可探索72B的边界突破。记住:选择模型不是选最贵的,而是选最适合业务场景的"智能引擎"。

欢迎加入DeepSeek 技术社区。在这里,你可以找到志同道合的朋友,共同探索AI技术的奥秘。
更多推荐

 10
10 0
0- 0



 已为社区贡献13条内容
已为社区贡献13条内容

所有评论(0)