项目实践9—全球证件智能识别系统(通义千问Qwen3-VL-8B-Thinking图文多模态大模型本地部署)
本文介绍了在本地部署阿里巴巴Qwen团队研发的多模态大模型Qwen3-VL-8B-Thinking的完整流程。该模型具备强大的视觉语言理解能力,支持图像、视频、OCR等多模态处理。文章详细阐述了本地化部署的优势(数据安全、成本可控、低延迟响应)、GPU资源规划方法,并重点推荐使用vLLM框架进行部署,因其具备高吞吐量、高效内存管理等特性。安装指南部分提供了NVIDIA驱动、CUDA Toolkit
目录
一、概述
1.1 背景介绍
随着人工智能技术的飞速发展,大语言模型在自然语言处理领域取得了革命性突破。然而,现实世界的信息是多模态的,不仅包含文本,还涵盖了图像、视频、音频等多种形式。为了让AI更好地理解和认知复杂的真实世界,多模态大语言模型应运而生。
本文将要部署的 Qwen3-VL-8B-Thinking,是由阿里巴巴Qwen团队研发的新一代多模态大模型。该模型具备强大的视觉语言理解能力,能够处理并理解高清图像和长视频内容。其核心能力包括:
- 高级视觉感知与推理:模型能精准识别图像中的物体位置、判断遮挡关系,并具备初步的3D空间推理能力。
- 强大的图文理解与生成:不仅能处理复杂的图文混合输入,还能根据图像或视频内容生成代码,例如直接产出Draw.io流程图、HTML/CSS/JS网页代码等。
- 出色的OCR能力:支持32种语言的光学字符识别(OCR),即使在低光、模糊或倾斜等复杂场景下依然表现稳健,并能有效解析长文档的结构化信息。
- 视频与长上下文理解:支持长达256K的上下文窗口,可以处理数小时的视频内容,并实现秒级的内容定位与理解。
1.2 为何选择本地化部署
尽管通过API调用云端大模型服务非常便捷,但在特定场景下,本地化部署具有不可替代的优势:
- 数据安全与隐私保护:对于处理敏感数据(如企业内部文档、个人隐私信息)的应用场景,本地化部署可以将数据完全保留在本地局域网内,杜绝了数据在传输过程中泄露的风险。
- 成本可控与性能定制:对于高频次的调用需求,长期来看本地部署的硬件投入成本可能低于持续的API调用费用。同时,可以根据自身硬件资源对模型进行深度优化和定制,以满足特定的性能要求。
- 低延迟响应:数据无需通过公网传输,请求在局域网内完成,能够实现更低的响应延迟,对于实时性要求高的应用至关重要。
1.3 GPU资源规划与计算
部署大模型前,必须精确评估所需GPU显存。总显存需求主要由三部分构成:模型参数显存、键值缓存(KV Cache)显存 和 计算过程中的中间变量显存。
-
模型参数显存:这是最主要的显存开销。计算公式为:
- 模型参数显存 = 参数量 × 每个参数占用的字节数
对于一个80亿(8B)参数的模型:
- 在 FP16/BF16 精度下,每个参数占2个字节,所需显存为
8B * 2 bytes ≈ 16 GB。 - 在 FP8 精度下,每个参数占1个字节,所需显存为
8B * 1 byte ≈ 8 GB。
-
KV缓存显存:在模型推理过程中,为了避免重复计算,需要缓存每个Token的键(Key)和值(Value)。其大小与批处理大小(Batch Size)、序列长度(Sequence Length)和模型结构正相关。在高并发或长文本场景下,这部分开销不容忽视。
-
中间变量显存:包括激活值、梯度(仅训练时)等在计算过程中产生的临时数据。
根据计算,8B参数的FP16模型至少需要16GB显存来加载权重。本次实践采用4张NVIDIA TITAN RTX显卡,每张拥有24GB GDDR6显存,总显存为 4 * 24GB = 96GB。这为模型参数(约8GB)以及KV缓存和计算开销提供了充足的空间,完全绰绰有余(后续可以考虑部署更大的模型)。
1.4 为何选择vLLM框架
vLLM 是一个为大语言模型推理和部署而设计的高性能开源库。它通过引入多项创新技术,极大地提升了模型的吞吐量和运行效率。选择vLLM进行部署,主要基于以下几点原因:
- 高吞吐量:vLLM的核心创新是 PagedAttention 机制。它借鉴了操作系统中虚拟内存和分页的思想,有效解决了KV缓存在传统部署方式下存在的大量内存浪费和碎片化问题,从而可以将更多请求合并处理,将吞吐量提升数倍至数十倍。
- 高效的内存管理:通过PagedAttention,vLLM可以更精细化地管理GPU显存,实现近乎100%的显存利用率,避免了因内存不足导致的请求失败(Out of Memory)。
- 张量并行:vLLM原生支持张量并行技术,能够自动将模型权重和计算任务切分到多张GPU上协同执行。这对于无法在单张GPU上完整加载的大模型是必需的部署方案。
- 连续批处理:不同于静态批处理必须等待批次中所有请求都完成才能返回结果,vLLM允许在请求完成时动态地将其从批次中移除,并立即调度新的请求加入,从而减少了GPU空闲时间,提高了处理效率。
- 广泛的模型兼容性:vLLM支持包括Qwen系列在内的众多主流大模型,并且对FP8等量化格式提供了良好支持,是社区推荐的部署方案之一。
综上所述,通过在4张TITAN RTX GPU上利用vLLM框架部署Qwen3-VL-8B-Thinking-FP8模型,可以构建一个兼具数据安全、高性能和高并发处理能力的本地多模态AI服务。
二、安装英伟达显卡驱动、CUDA、cuDNN和NCCL
部署大语言模型是一个软硬件紧密结合的过程,正确的环境配置是模型能够稳定、高效运行的基石。其中,NVIDIA显卡驱动、CUDA以及cuDNN三者之间存在严格的版本对应关系,任何环节的不匹配都可能导致安装失败或运行时错误。
大语言模型框架(如vLLM)的更新迭代速度很快,通常会依赖于特定版本的CUDA Toolkit以利用最新的GPU加速特性。因此,部署流程应遵循“自顶向下”的依赖关系进行:
- 确定vLLM版本:选择安装最新版的vLLM,以获取最佳性能和最广泛的模型支持。
- 查询CUDA版本:根据vLLM官方文档,确定其编译和测试所依赖的CUDA版本。
- 匹配驱动版本:根据所选CUDA版本,在NVIDIA官方文档中查找其支持的最低显卡驱动版本。
根据目前vLLM的最新发布说明,其预编译二进制文件已支持CUDA 12.8。 查阅NVIDIA官方发布的CUDA Toolkit与驱动版本对应关系可知,CUDA 12.8要求Linux x86_64平台安装不低于570.26版本的驱动程序。
本次实践将以CUDA 12.8为目标环境,并安装与之兼容的最新NVIDIA驱动。
2.1 安装NVIDIA显卡驱动
首先使用下面的命令查看可用驱动:
sudo apt-get update
ubuntu-drivers devices
然后选择高版本的驱动进行安装:
sudo apt-get install nvidia-driver-580
安装完成后重启系统,然后使用下面的命令查看显卡状态:
nvidia-smi

注意,右上角显示的CUDA Version:13.0表示当前驱动支持的最高CUDA版本。因此,后续安装CUDA12.8就没有问题了。
2.2 安装CUDA Toolkit 12.8
驱动安装完成后,接下来安装CUDA Toolkit。
-
访问CUDA Toolkit历史版本页面:
https://developer.nvidia.com/cuda-toolkit-archive -
选择CUDA 12.8版本:
在列表中找到CUDA Toolkit 12.8,并选择与系统匹配的配置:- Operating System:
Linux - Architecture:
x86_64 - Distribution:
Ubuntu - Version:
24.04 - Installer Type:
runfile (local)
- Operating System:
-
下载并安装:
根据网页生成的指令,下载.run文件并执行安装。由于已手动安装了最新驱动,安装时需取消选择驱动程序的安装选项。wget https://developer.download.nvidia.com/compute/cuda/12.8.0/local_installers/cuda_12.8.0_570.26_linux.run sudo sh cuda_12.8.0_570.26_linux.run在安装界面中,按空格键阅读协议,输入
accept,然后使用方向键移动到Driver选项,按空格键取消勾选,最后选择Install开始安装(这一步非常重要)。
-
配置环境变量:
安装完成后,需要将CUDA的路径添加到系统环境变量中,以便编译器和应用程序能够找到它。
打开~/.bashrc文件:vim ~/.bashrc在文件末尾添加以下内容:
export PATH=/usr/local/cuda-12.8/bin${PATH:+:${PATH}} export LD_LIBRARY_PATH=/usr/local/cuda-12.8/lib64${LD_LIBRARY_PATH:+:${LD_LIBRARY_PATH}}保存文件后,执行
source命令使配置立即生效:source ~/.bashrc -
验证安装:
执行以下命令查看CUDA编译器版本:nvcc -V如果输出显示CUDA 12.8版本信息,则表明CUDA Toolkit已成功安装。
2.3 安装cuDNN
cuDNN是用于深度神经网络的GPU加速库,vLLM等框架依赖它来提升计算性能。
-
访问cuDNN下载页面:
https://developer.nvidia.com/cudnn-downloads?target_os=Linux&target_arch=x86_64&Distribution=Ubuntu&target_version=24.04&target_type=deb_local&Configuration=Full
需要登录NVIDIA开发者账号。 -
选择对应版本:
在下载列表中,选择与CUDA 12.8兼容的最新版cuDNN。下载适用于Ubuntu 24.04的Debian本地安装包。 -
安装cuDNN:
按照官方提示命令进行安装:
三、安装PyTorch与NCCL
在完成底层的驱动和CUDA环境配置后,接下来需要安装核心的深度学习框架——PyTorch。PyTorch是vLLM运行的基础,它提供了强大的张量计算能力和GPU加速支持。随后,还将安装NVIDIA NCCL,这是一个用于多GPU通信的集合通信库,对于vLLM实现高效的张量并行至关重要。
3.1 安装PyTorch
PyTorch社区为不同CUDA版本提供了预编译的二进制包,可以直接通过pip进行安装。这将确保PyTorch与其底层的CUDA环境完全兼容。
- 确定安装命令:
访问PyTorch官方网站,根据当前环境(Stable,Linux,Pip,Python,CUDA 12.8)生成安装命令。如下图所示: 本文选择安装的torch版本为2.8.0(需要根据后续安装的vLLM版本来确定)。具体安装命令如下:
本文选择安装的torch版本为2.8.0(需要根据后续安装的vLLM版本来确定)。具体安装命令如下:
pip install torch==2.8.0 torchvision==0.23.0 torchaudio==2.8.0 --index-url https://download.pytorch.org/whl/cu128
-
验证PyTorch安装:
安装完成后,需要验证PyTorch是否能正确识别并使用GPU。创建一个Python验证脚本,然后输入以下代码:import torch # 检查CUDA是否可用 cuda_available = torch.cuda.is_available() print(f"CUDA available: {cuda_available}") # 如果CUDA可用,则进行下一步检查 if cuda_available: # 获取GPU数量 gpu_count = torch.cuda.device_count() print(f"Number of GPUs: {gpu_count}") # 获取当前GPU设备名称 current_device_name = torch.cuda.get_device_name(torch.cuda.current_device()) print(f"Current GPU name: {current_device_name}") # 检查cuDNN是否启用 cudnn_enabled = torch.backends.cudnn.enabled print(f"cuDNN enabled: {cudnn_enabled}") # 在GPU上执行一个简单的张量运算 print("\nTesting a simple computation on GPU...") try: # 创建一个张量并将其移动到GPU x = torch.tensor([1.0, 2.0, 3.0]).to("cuda") # 执行加法操作 y = x + x print("Computation successful!") print(f"Input tensor on GPU: {x}") print(f"Result tensor on GPU: {y}") except Exception as e: print(f"An error occurred during GPU computation: {e}")如果环境配置正确,将会看到类似下面的输出:
CUDA available: True Number of GPUs: 4 Current GPU name: NVIDIA TITAN RTX cuDNN enabled: True Testing a simple computation on GPU... Computation successful! Input tensor on GPU: tensor([1., 2., 3.], device='cuda:0') Result tensor on GPU: tensor([2., 4., 6.], device='cuda:0')看到以上输出,特别是
CUDA available: True以及最后的计算成功信息,就表明PyTorch已正确安装并可以利用GPU进行加速计算。
如果以上输出均正常,则说明PyTorch已正确安装。
3.2 安装NCCL
为了让vLLM能够充分利用全部4张TITAN RTX显卡进行高效的张量并行计算,建议安装NVIDIA集合通信库(NCCL)。NCCL提供了针对多GPU优化的通信原语,如All-Reduce、Broadcast等,是实现模型并行和数据并行的关键组件。
-
访问NCCL下载页面:
前往NCCL官方下载页面(需要登录NVIDIA开发者账号)。 -
选择并下载对应版本:
根据环境选择与CUDA 12.8匹配的NCCL版本。例如,选择NCCL v2.26.2, for CUDA 12.8,并下载适用于Ubuntu 24.04的本地仓库DEB包(nccl-local-repo-ubuntu2404-2.26.2-cuda12.8_1.0-1_amd64.deb)。 -
安装NCCL:
下载完成后,在文件所在目录打开终端,依次执行以下命令进行安装。# 1. 安装本地仓库DEB包 sudo dpkg -i ./nccl-local-repo-ubuntu2404-2.26.2-cuda12.8_1.0-1_amd64.deb # 2. 导入GPG密钥 sudo cp /var/nccl-local-repo-ubuntu2404-2.26.2-cuda12.8/nccl-local-A5BB8512-keyring.gpg /usr/share/keyrings/ # 3. 更新APT包列表 sudo apt-get update # 4. 安装NCCL开发库和运行时库 sudo apt-get install libnccl2=2.26.2-1+cuda12.8 libnccl-dev=2.26.2-1+cuda12.8注意:通过
=指定版本号可以确保安装与CUDA环境精确匹配的NCCL版本。
四、下载大模型
在底层硬件驱动和深度学习框架准备就绪后,下一步是获取Qwen3-VL-8B-Thinking模型本身。模型文件通常托管在专门的模型社区平台,如ModelScope或Hugging Face。本次实践将通过阿里巴巴的官方模型社区ModelScope来下载模型。
ModelScope提供了便捷的Python库,可以轻松地从其平台下载和管理模型。首先,需要通过pip安装modelscope库。为了获得更好的兼容性,特别是与Hugging Face生态系统的互操作性,建议安装包含huggingface依赖的完整版本。
打开终端,执行以下命令:
pip3 install "modelscope[hf]" -U -i https://pypi.tuna.tsinghua.edu.cn/simple
该命令会安装ModelScope库及其相关依赖,-U参数确保安装的是最新版本。
下面开始下载:
modelscope download --model Qwen/Qwen3-VL-8B-Thinking --local_dir ./Qwen3-VL-8B-Thinking
其中local_dir参数用于指明要下载的模型存储路径。
由于模型文件较大(16G左右),整个下载过程需要一定时间,具体取决于网络带宽。下载完成后,脚本会打印出模型文件在本地的最终存储路径。
五、大模型启动和测试
完成所有环境配置和模型下载后,最后一步是启动模型服务并进行推理测试。将使用vLLM框架以API服务的形式启动模型,该服务将兼容OpenAI的API标准,极大地简化了客户端的调用。
5.1 安装vLLM框架
vLLM是一个高性能的大语言模型推理服务框架。在之前的章节已经介绍了其核心优势。安装vLLM可以直接通过pip完成。
在终端中执行以下命令来安装vLLM:
pip3 install -U vllm -i https://pypi.tuna.tsinghua.edu.cn/simple
pip3 install qwen-vl-utils==0.0.14 -i https://pypi.tuna.tsinghua.edu.cn/simple
安装过程会自动检测环境中已安装的PyTorch和CUDA版本,并下载与之匹配的vLLM预编译包。
5.2 启动vLLM推理服务器
vLLM可以将下载好的本地模型加载起来,并通过一个HTTP服务器对外提供服务。通过设置参数,可以轻松实现多GPU的张量并行。
-
确定模型路径:
根据第四节中的下载脚本,模型文件被保存在./Qwen3-VL-8B-Thinking-FP8/Qwen/Qwen3-VL-8B-Thinking-FP8目录下。这是启动服务时需要指定的模型路径。 -
编写启动命令:
打开终端,执行以下命令来启动模型服务:python3 -m vllm.entrypoints.openai.api_server \ --model ./Qwen3-VL-8B-Thinking \ --tensor-parallel-size 4 \ --host 0.0.0.0 \ --port 8000 \ --max-model-len 8192命令参数详解:
--model: 指定加载模型的本地路径。--tensor-parallel-size 4: 这是实现多GPU部署的关键参数。设置为4,vLLM会自动将模型的权重和计算任务平均分配到4张GPU上。--quantization fp8: 指明该模型是FP8量化模型。vLLM会采用相应的FP8内核进行计算,以实现最佳性能。--host 0.0.0.0: 使服务监听在本机的所有网络接口上,这样局域网内的其他设备才能访问到该服务。--port 8000: 指定服务监听的端口号。--max-model-len 8192: 设置模型能处理的最大序列长度。对于多模态任务,适当增大此值有助于处理高分辨率图像。
-
验证服务启动:
执行命令后,vLLM会开始加载模型到4张GPU中。终端会输出详细的日志信息。如果看到类似以下的日志,并且没有报错,则表示服务已成功启动:(APIServer pid=8816) INFO: Started server process [8816] (APIServer pid=8816) INFO: Waiting for application startup. (APIServer pid=8816) INFO: Application startup complete.看到
Uvicorn running on http://0.0.0.0:8000的提示,即代表模型API服务已准备就绪,可以接收推理请求。
查看显卡运行情况,如下图所示: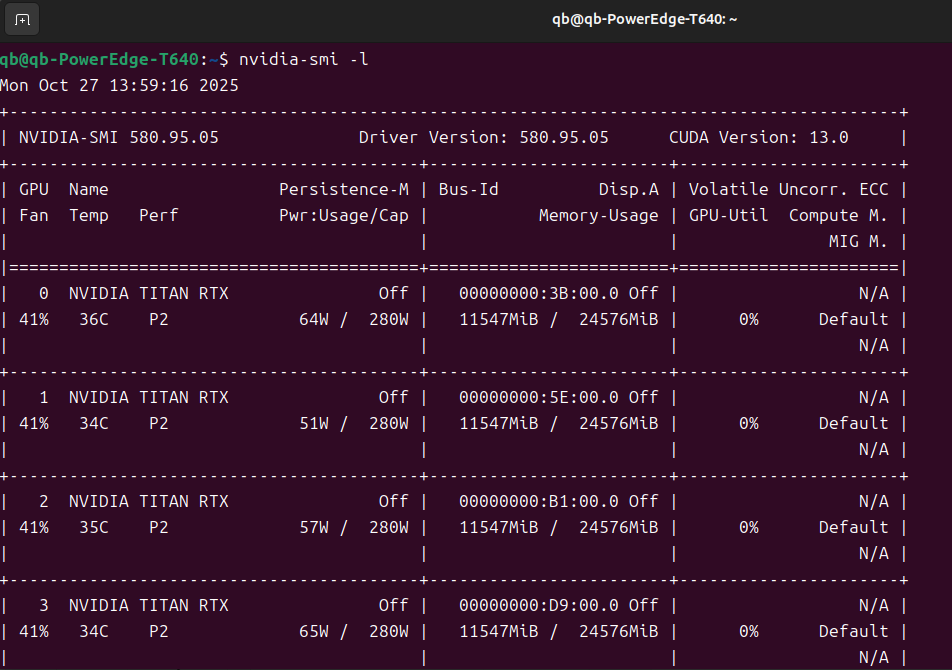
可以看到,每张显卡占用了将近12G左右。
5.3 编写本地推理脚本
现在,可以编写一个Python脚本,作为客户端来调用刚刚部署好的模型API。该脚本将模拟一个真实的应用场景:向模型发送一张本地图片和一个相关的文本问题,并获取模型的回答。
-
准备测试图片:
在本地准备一张图片,例如命名为test.webp,并将其与下面的Python脚本放在同一个目录下。 -
安装依赖库:
客户端脚本需要openai库来与vLLM的API进行交互。pip install openai -i https://pypi.tuna.tsinghua.edu.cn/simple -
创建推理脚本:
创建一个名为client.py的Python文件,并输入以下代码:import base64 import os from openai import OpenAI # --- 配置 --- # 替换为vLLM服务器所在的局域网IP地址 SERVER_IP = "127.0.0.1" SERVER_PORT = 8000 # vLLM加载的模型路径,必须与启动命令中的--model参数一致 MODEL_PATH = "./Qwen3-VL-8B-Thinking" # API的基地址 BASE_URL = f"http://{SERVER_IP}:{SERVER_PORT}/v1" # 本地图片文件路径 IMAGE_PATH = "test.webp" # 要向模型提出的问题 TEXT_PROMPT = "识别这张证件上所有内容并翻译成中文,非公历日期需要转换成公历表示。" # --- 脚本核心 --- def encode_image_to_base64(image_path): """将图片文件编码为Base64字符串""" if not os.path.exists(image_path): raise FileNotFoundError(f"错误:找不到图片文件 '{image_path}'") with open(image_path, "rb") as image_file: return base64.b64encode(image_file.read()).decode('utf-8') def run_inference(): """执行推理请求""" print("--- 开始进行多模态推理 ---") # 1. 初始化OpenAI客户端,指向本地vLLM服务器 # 由于是本地服务,API密钥是可选的,可以填任意字符串 client = OpenAI( api_key="not-used", base_url=BASE_URL, ) try: # 2. 将图片编码为Base64 print(f"读取并编码图片: {IMAGE_PATH}") base64_image = encode_image_to_base64(IMAGE_PATH) image_url = f"data:image/jpeg;base64,{base64_image}" # 3. 构建符合OpenAI多模态格式的请求消息 messages = [ { "role": "user", "content": [ {"type": "text", "text": TEXT_PROMPT}, {"type": "image_url", "image_url": {"url": image_url}} ] } ] print(f"向模型发送请求: \"{TEXT_PROMPT}\"") # 4. 发送请求到vLLM服务器 response = client.chat.completions.create( model=MODEL_PATH, messages=messages, max_tokens=2048, # 设置期望的最大回复长度 temperature=0.7, # 控制生成文本的随机性 ) # 5. 打印模型的回复 print("\n--- 模型回复 ---") result = response.choices[0].message.content print(result) print("------------------\n") except FileNotFoundError as fnf_error: print(fnf_error) except Exception as e: print(f"\n请求过程中发生错误: {e}") print("请检查vLLM服务是否正常运行,以及服务器IP和端口是否配置正确。") if __name__ == "__main__": run_inference()代码说明:
- 配置区域:在使用前,需要将
SERVER_IP修改为部署vLLM服务器的实际局域网IP地址。如果是本机测试,使用127.0.0.1即可。MODEL_PATH必须与启动服务器时使用的路径完全一致。 - 图片编码:
encode_image_to_base64函数负责将图片文件转换为Base64编码的字符串,这是通过HTTP API传递图像数据的标准方法。 - 客户端初始化:创建
OpenAI客户端实例时,base_url参数被指向本地服务的地址。api_key在此处为非必需项。 - 消息构建:请求的内容
content是一个列表,其中包含两个部分:一个是type: "text"的文本提示,另一个是type: "image_url"的图片数据。 - 发送请求:
client.chat.completions.create函数负责发起API调用,并将模型的响应解析出来。
- 配置区域:在使用前,需要将
-
执行推理:
在终端中运行客户端脚本:python client.py脚本会首先加载图片,然后将图片和文本问题一起发送给在后台运行的vLLM服务。片刻之后,终端将打印出模型对图片的描述,完成一次端到端的本地多模态推理。
测试图像如下:

模型返回结果如下:
- 2종보통(2种普通):可能指驾照类别,2种普通驾驶执照
- 자동차운전면허증 (Driver's License):汽车驾驶执照(驾驶证)
- 서울 13-627569-00:首尔 13-627569-00(驾照编号)
- LI CAN:LI CAN(姓名)
- 920828-6160195:920828-6160195(可能为身份证号或注册号)
- 서울특별시 동작구:首尔特别市东大门区
- 정승배기로24일 46, 202호:正盛配基路24号 46, 202室
- (노령전등):(老年免考)
- 면허 종 2023.01.01:驾照种类 2023年1月1日
- 갱신기간 2023.12.31:更新期限 2023年12月31日
- 조 A:类别 A
- 2013.05.30 서울지방방찰청장:2013年5月30日 首尔地方警察厅厅长
另外,右下角有“7279DA”,可能是编号或代码,翻译可能为“7279DA”。
小结
本文详尽阐述了在本地环境中,利用vLLM框架部署Qwen3-VL-8B-Thinking多模态大语言模型的完整流程。
该实践从基础环境的搭建入手,系统地介绍了如何根据vLLM框架的要求,规划并安装匹配的NVIDIA显卡驱动、CUDA Toolkit、cuDNN及NCCL通信库,为模型的高效运行奠定了坚实基础。随后,文章清晰地演示了核心依赖PyTorch的安装与验证过程。
在部署阶段,文章展示了如何从ModelScope平台获取模型资源,并利用vLLM的核心功能启动一个支持四卡张量并行的推理服务。该服务通过暴露与OpenAI兼容的API接口,实现了标准化、便捷化的访问。
最终,通过一个客户端测试脚本,成功调用了本地部署的模型服务,完成了一项图文理解与光学字符识别(OCR)的复合任务。这不仅验证了整个部署流程的正确性,也体现了该方案在构建高性能、保障数据隐私的本地多模态AI应用方面的可行性与优势。

欢迎加入DeepSeek 技术社区。在这里,你可以找到志同道合的朋友,共同探索AI技术的奥秘。
更多推荐

 16
16 0
0- 0



 已为社区贡献2条内容
已为社区贡献2条内容

所有评论(0)