AiPy发布第五期大模型适配度测评报告:Claude、GLM、豆包位居前三,美团LongCat落后
本次测评通过优化后的10个常见用户真实使用场景,评估20款主流和新晋大模型的实战能力。以90%的成功率证明了其在复杂任务处理方面的领先地位,而GLM-4.5和等国产模型的优异表现,代表了中国AI技术已经跻身世界一流水平。同时,我们也看到不同模型在速度、成本、专业领域等方面各有特色,为用户提供了丰富的选择空间。测评过程中发现的代码质量、指令跟随、中文支持、服务稳定性等问题,为模型优化指明了方向。我们
10月13日,AiPy正式发布《大模型适配度测评第五期报告》。距上次测评发布已近2个月,期间全球人工智能领域持续高速演进。智谱发布了新一代Coding模型GLM-4.6,Anthropic推出号称“全球最强编码模型”的Claude-Sonnet-4.5,各大厂商的密集动作不仅反映出行业竞争的加剧,也标志着大模型正加速迈向专业化、场景化的深度应用阶段。
为进一步为用户提供更具实用参考价值的模型选型依据,AiPy团队对测评体系进行了系统优化与全面升级——参评范围更广、任务更贴近真实场景、评估维度更具代表性。
本期共测试20款国内外代表性大模型,既有国际知名厂商的旗舰产品,也纳入多个具有代表性的开源模型和新晋模型,重点聚焦于AiPy典型场景,包括数据分析、生成创作、编程开发、本地批量处理、UI设计、软件控制和大文件处理等,力求呈现模型的真实适配力与实战表现。
🏆 综合排名
以下排名综合考虑了成功率和资源消耗维度,排名相同成功率的模型,按照Tokens消耗从低到高排序,体现了模型在保证质量的同时对资源的优化利用能力。(注:由于不同模型计费模式不同,实际成本效益建议结合具体情况综合考量)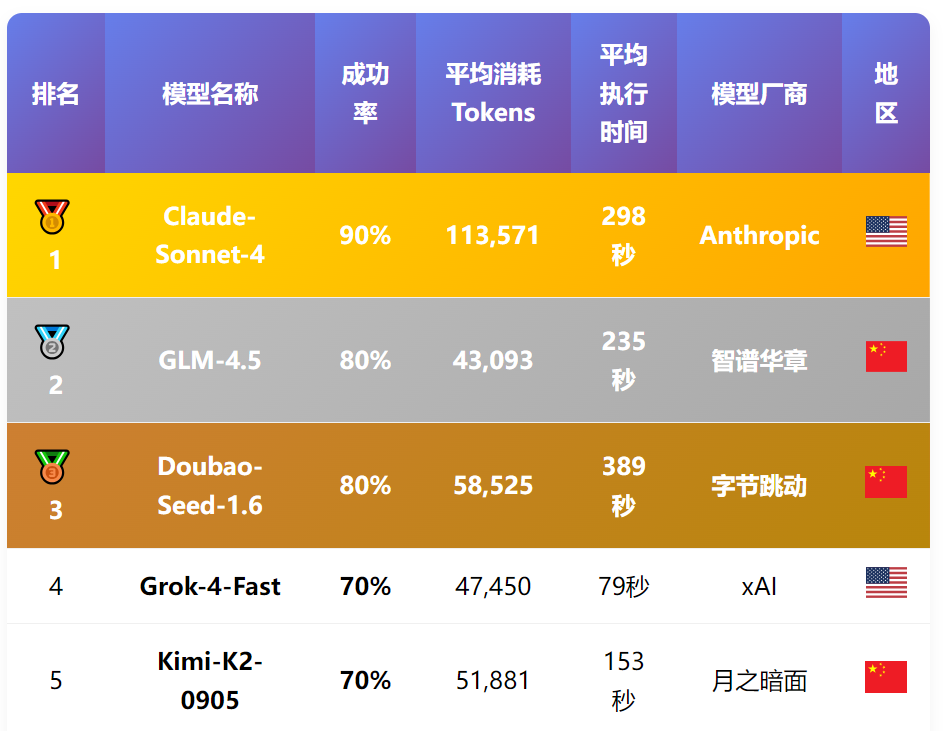
关键发现:代码质量问题(29.5%)和代码块标记问题(18.2%)是导致失败的两大主因,合计占比近50%。这表明模型在代码生成规范性和指令跟随方面仍有较大提升空间。此外,模型服务不稳定(14.8%)和绘图时中文乱码问题(9.1%)也是影响用户体验的重要因素。
-
冠军:Claude-Sonnet-4
-
以90%的成功率稳居榜首,连续第二次夺冠,展现出卓越的技术稳定性与复杂任务处理能力。
-
亚军:GLM-4.5
-
以80%的成功率和低Tokens消耗获得总榜第二,国产榜首,超越Doubao-Seed-1.6、Grok-4-Fast、Kimi-K2-0905等强劲对手。
-
季军:Doubao-Seed-1.6
-
从上期第8名跃升至本期第三,展现出国产模型在执行稳定性与代码生成质量上的显著提升。
-
Kimi-K2-0905:上期亚军,本期降至第五,主要受指令跟随问题影响。
-
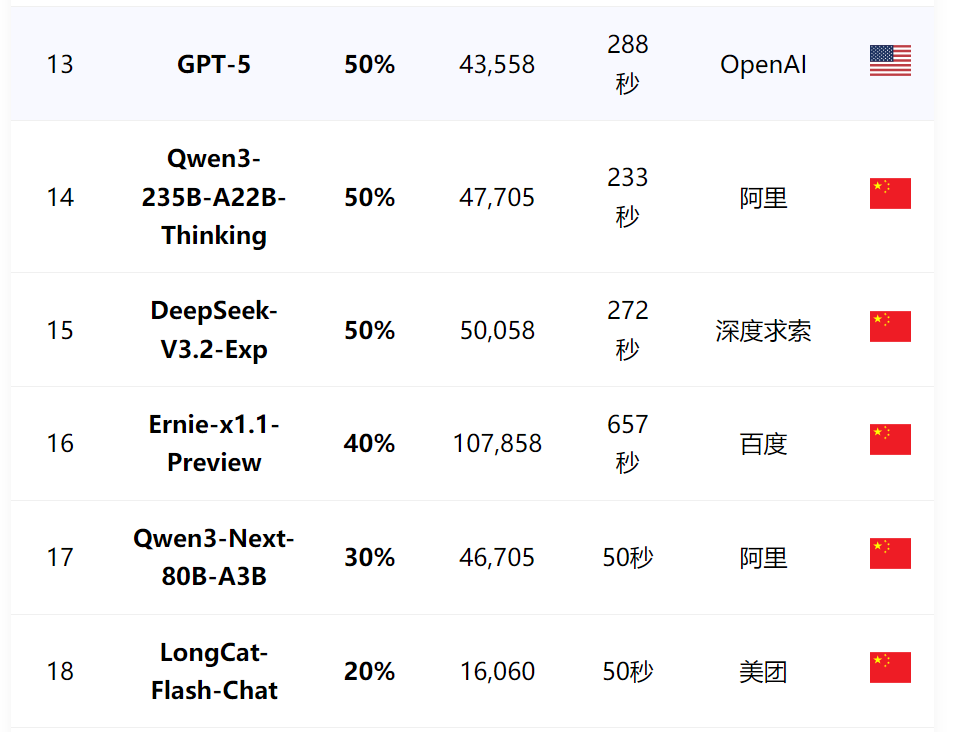
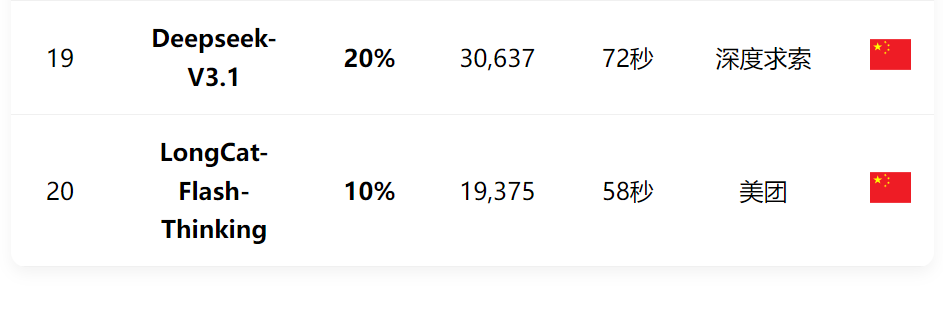
美团LongCat系列:LongCat-Flash-Thinking、LongCat-Flash-Chat两款参评大模型成功率表现均不佳,位列榜单末尾。
-
百度Ernie-X1.1-Preview:执行速度最慢、成功率40%,位列第16名
-
整体来看,Claude-Sonnet-4以90%的成功率证明了其在复杂任务处理方面的领先地位,而GLM-4.5和Doubao-Seed-1.6等国产模型的优异表现,代表了中国AI技术已经跻身世界一流水平。
二、核心指标分析
1、成功率
成功率是衡量模型实战能力的核心指标。本期结果显示,20款模型的成功率差距显著,从最高90%至最低10%跨度达80个百分点,反映出不同模型在任务理解、代码生成、错误处理等方面存在明显的能力差距。
-
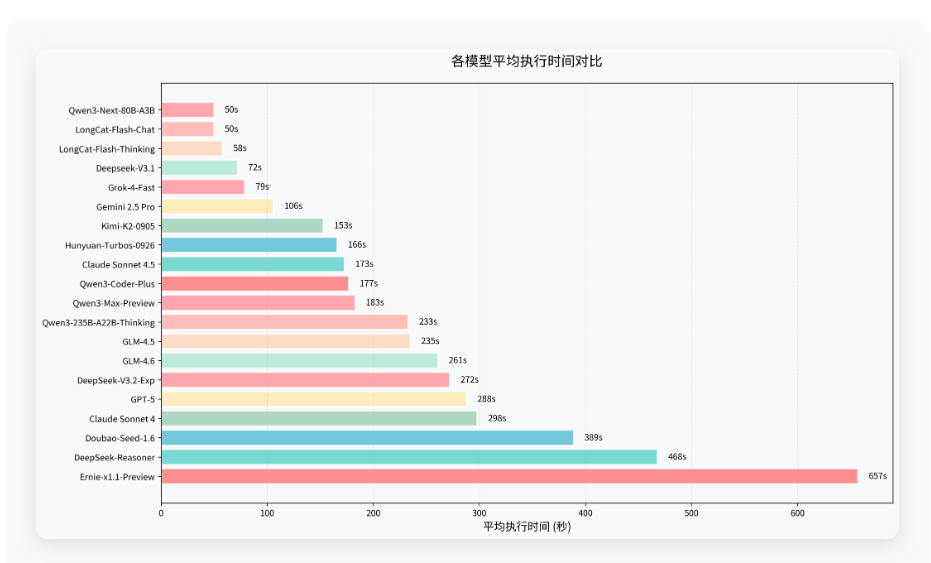
执行时间会直接影响用户体验,测试数据显示,最快的模型(Qwen3-Next-80B-A3B,50秒)与最慢的模型(Ernie-x1.1-Preview,657秒)相差超过13倍。执行时间受模型架构、推理策略、任务复杂度等多重因素影响。值得注意的是,执行时间与成功率并非简单的负相关关系,部分高成功率模型同样保持了较快的响应速度,用户在选用模型时可综合考虑。
-
各模型平均消耗Tokens对比分析
Tokens消耗直接关系到使用成本,是企业级应用选型的重要考量因素。测试结果显示,不同模型的Tokens消耗差异巨大,从最低的16,060到最高的113,571,相差超过7倍。低消耗模型在保持任务完成质量的同时,能够显著降低运营成本,特别适合大规模部署场景。但由于各模型厂商计费方式的不同,测评中仅计算tokens消耗,实际考量成本因素时还需结合具体情况考虑。
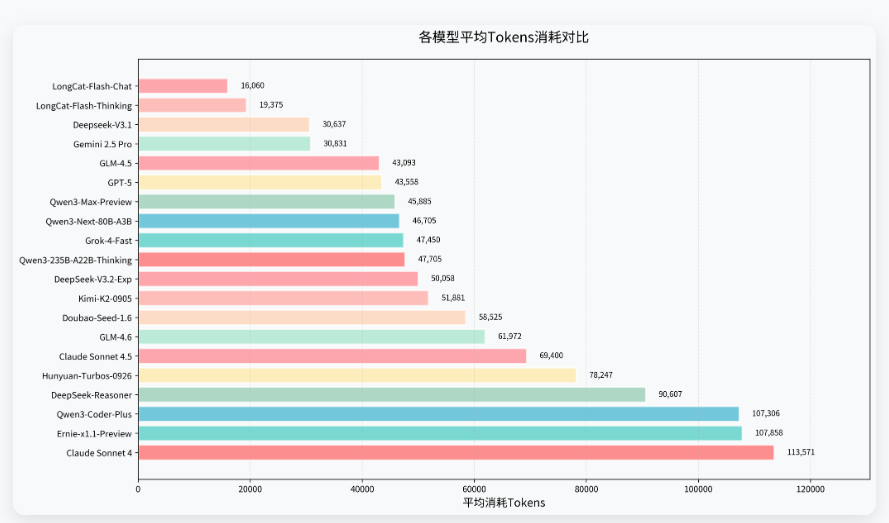
Tokens消耗分析
- 高性价比选择:GLM-4.5(43,093)在高成功率的情况下,资源消耗控制方面表现优异
- 低消耗选择:Gemini-2.5-Pro(30,831)、Grok-4-Fast(47,450)在相对友好成功率的情况下,资源消耗控制方面较好
- 中等消耗:Doubao-Seed-1.6(58,525)、Kimi-K2-0905(51,881)在成本与性能间取得良好平衡
- 高消耗高性能:Claude-Sonnet-4(113,571)虽然消耗较高,但成功率和任务完成质量也相应更优
-
各测试任务类型分布与模型表现
- 本次测评精心挑选10大常见AiPy应用场景,热力图清晰展示了各模型在不同任务类型上的表现差异,帮助用户根据实际需求选择最适合的模型。颜色越深表示该模型在该任务类型上的成功率越高。

任务类型洞察
- 网络爬取类:整体表现最佳,18款模型达到100%成功率,说明该类任务技术成熟度高,用户使用时注意合规使用即可
- 批量任务类:16款模型成功,自动化处理能力普遍较强
- 软件控制类:13款模型成功,但存在系统权限和软件知识积累的挑战
- 大文件处理:难度最高,仅4款模型成功,对模型的任务规划能力和数据处理能力要求极高
- 工具制造类:仅3款模型成功,涉及复杂的代码生成和打包流程,重点考验任务规划能力和编程能力
-
多维度性能雷达图
- 雷达图从成功率、速度、效率、稳定性和综合表现五个维度展示TOP5模型的能力画像。每个维度满分100分,图形面积越大表示综合实力越强。通过雷达图可以直观看出各模型的优势领域和短板所在,为不同应用场景提供选型参考。
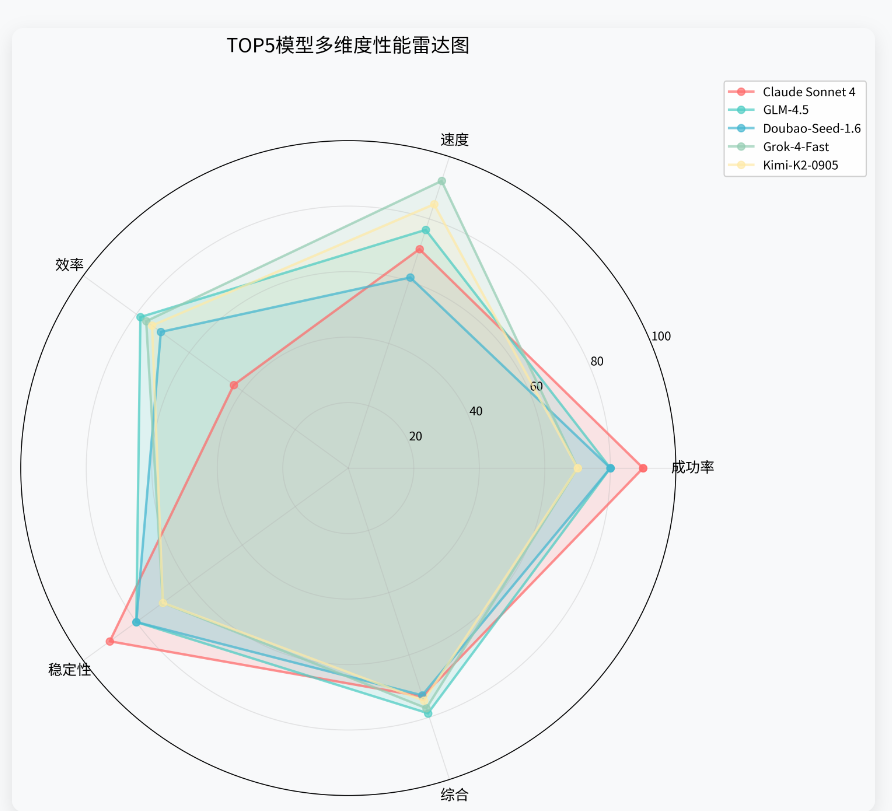
-
🌟 TOP5模型特征
- Claude-Sonnet-4:五边形最为均衡,成功率和稳定性双高,综合实力最强
- GLM-4.5:速度和效率表现突出,成功率优秀,国产模型标杆
- Doubao-Seed-1.6:成功率与GLM-4.5并列,但速度稍慢,适合对质量要求高的场景
- Grok-4-Fast:速度维度接近满分,适合对响应时间敏感的应用
- Kimi-K2-0905:各维度均衡发展,综合表现稳定
-
⚠️ TOP5主要失败原因分析
- 代码质量问题:26次(29.9%),普遍问题,反映出大模型在编码方面还有较大优化空间
- 代码块标记问题:16次(18.4%),主要集中在个别模型,如Deepseek-V3.1、Kimi-K2-0905,反应模型对指令遵循方面的问题
- 模型服务不稳定:13次(14.9%),主要出现在LongCat-Flash-Chat和LongCat-Flash-Thinking模型
- 中文乱码问题:8次(9.2%),多个模型绘图时存在中文乱码问题,反应模型在识别字体方面的缺陷
- 任务规划问题:7次(8.0%),主要出现在大文件处理时,模型任务规划不周导致处理数据偏差或执行失败
📝 测评任务分类表
以下展示10个具有代表性的测评任务,涵盖了本次测评的主要应用场景。这些任务设计贴近实际应用需求,从简单的信息检索到复杂的数据分析,重点考察模型的综合实战能力。
| 序号 | 问题 | 任务类型 |
|---|---|---|
| 1 | XX文件(10G)是网站访问日志,请先对少量日志分析识别URL、IP、UA等关键字段,然后再分析全量日志生成一份精美的HTML网站日志分析报告。 | 大文件处理 |
| 2 | 分析当前电脑中CPU、内存占用率最高的TOP10软件分别是哪些,生成一份优化建议HTML | 本地分析类 |
| 3 | 访问https://www.aipyaipy.com/首页,爬取aipy和manus的区别相关内容并总结。 | 网络爬取类 |
| 4 | 使用系统默认邮件客户端,给XXX发一封邮件,邮件主题为“test”邮件内容是:“test”,最后一步发送时控制键盘使用快捷键ctrl+enter发送 | 软件控制类 |
| 5 | 生成一个AiPy的调研分析报告,包括其产品介绍、功能亮点,优缺点,下载安装链接,github开源链接,官方论坛链接 | 联网搜索类 |
| 6 | 【设计】运动健身APP原型图 | UI设计 |
| 7 | 批量将文件夹下所有文件中涉及的"sk-"密钥信息脱敏,并将脱敏的具体详情输出给我核对。 | 批量任务类 |
| 8 | https://github.com/jiasule/jsl-open-api/blob/master/lib/python/white_black_list.py是云防御黑白名单配置的API示例脚本,请帮我包装其中的功能为一个云防御配置工具.exe的程序保存到桌面 | 工具制造类 |
| 9 | 查询AiPy相关的信息,先生成1张宣传海报,然后再根据海报图片制作成一个5s的宣传视频,要求要有“aipy”字样,且体现aipy的核心优势 | 生成创作类 |
| 10 | 我是一家3C家电全国连锁品牌的销售负责人,请帮我分析这份各门店销售情况汇总数据。 1、文件路径::"C:\AiPyPro\resources\app.asar.unpacked\resources\demo\3c_sales.xlsx" 2、文件内容:表头分别为:order_id date、... |
深度洞察
🏆 性能冠军
🏆Claude-Sonnet-4 - 全能王者
以90%的成功率稳居榜首,仅在数据分析场景因中文字体处理失分。其强大的代码生成能力、精准的任务理解和出色的错误处理机制,使其成为当前最可靠的生产环境选择。特别是在大文件处理(3170万条日志)、工具制造(exe程序打包)等高难度任务中的完美表现,充分展示了其技术实力。
🏆GLM-4.5 - 国产冠军
以80%的成功率和低Tokens消耗稳居国内榜首,该模型在前面几期测评中表现也整体优异,仅在大文件处理中因空响应和数据分析类中因中文字体处理失分,值得注意的是GLM-4.5在高成功率的情况下,时间和Tokens消耗均得到平衡,为国内用户使用提供了优质选择。
✨ 亮点发现
- 国产崛起:GLM-4.5和Doubao-Seed-1.6均达80%成功率,与国际一流模型同台竞技,且在前几期模型测评中也表现优异,展现中国AI技术的快速进步;
- 速度突破:Grok-4-Fast、Gemini-2.5-Pro、Kimi-K2-0905、Hunyuan-Turbos-0926在保持合理成功率的同时维持快速响应,为实时交互场景提供新选择;
- 全能选手:Claude-Sonnet-4虽然Tokens消耗较高,但成功率和任务完成质量相当优秀,再次验证了模型的综合实力;
- 工具生态:Kimi-K2-0905和GLM系列在工具制造类任务中表现突出,展现出色的代码打包和系统集成能力。
🔧 改进建议
对模型开发者
- 代码规范化:加强代码块标记的规范性训练,减少格式错误导致的任务失败;
- 中文支持:优化中文字体处理机制,特别是在图表生成、HTML报告等场景中的中文渲染;
- 任务规划:增强复杂任务的分解和规划能力,特别是在大文件处理等多步骤场景中;
- 错误处理:完善异常捕获和重试机制,提高任务执行的容错性。
对用户选型
- 场景匹配:根据实际应用场景选择模型,可在成功率满足需求的情况下结合耗时和Tokens消耗情况选择;
- 本地化优先:中文场景下优先考虑国产模型,如GLM-4.5、Doubao-Seed-1.6等;
- 专业场景:参考热力图中不同模型在特定任务类型中的表现选择使用;
- 备选方案:关键业务建议配置多个模型作为备选,提高可用性。
📋 测评总结
本次测评通过优化后的10个常见用户真实使用场景,评估20款主流和新晋大模型的实战能力。Claude-Sonnet-4以90%的成功率证明了其在复杂任务处理方面的领先地位,而GLM-4.5和Doubao-Seed-1.6等国产模型的优异表现,代表了中国AI技术已经跻身世界一流水平。同时,我们也看到不同模型在速度、成本、专业领域等方面各有特色,为用户提供了丰富的选择空间。
测评过程中发现的代码质量、指令跟随、中文支持、服务稳定性等问题,为模型优化指明了方向。我们期待在下一期测评中看到更多模型在这些方面的改进。AiPy团队将持续跟踪大模型技术发展,定期发布适配度测评报告,为用户提供最新、最全面的模型选型参考。感谢您的关注与支持!

欢迎加入DeepSeek 技术社区。在这里,你可以找到志同道合的朋友,共同探索AI技术的奥秘。
更多推荐



 7
7 0
0- 0



 已为社区贡献1条内容
已为社区贡献1条内容

所有评论(0)