通义千问3技术报告
阿里巴巴达摩院通义实验室推出Qwen3系列大模型,包括密集型和MoE架构,参数规模从0.6亿到235亿,支持119种语言。关键创新包括: 整合"思考模式"和"非思考模式",实现动态切换; 引入"思考预算"机制优化计算资源分配; 通过知识迁移技术减少小模型训练成本。 评估显示,Qwen3在代码、数学和多语言任务上达到SOTA性能,MoE模型
阿里巴巴达摩院通义实验室
https://huggingface.co/Qwen
https://modelscope.cn/organization/qwen
https://github.com/QwenLM/Qwen3
摘要
在本报告中,我们介绍了Qwen3,这是Qwen系列模型的最新版本。Qwen3包括一系列大型语言模型(LLMs),旨在提升性能、效率和多语言能力。Qwen3系列包含密集模型和专家混合(MoE)架构的模型,参数规模从0.6亿到235亿不等。Qwen3的一项关键创新是将“思考模式”(用于复杂、多步骤推理)和“非思考模式”(用于快速、上下文驱动的响应)整合到一个统一框架中。这消除了在不同模型之间切换的需求——例如聊天优化模型(如GPT-4o)和专用推理模型(如QwQ32B)——并能够根据用户查询或聊天模板动态切换模式。同时,Qwen3引入了“思考预算”机制,允许用户在推理过程中自适应分配计算资源,从而在任务复杂度基础上平衡延迟和性能。此外,通过利用旗舰模型的知识,我们显著减少了构建小规模模型所需的计算资源,同时确保其具有高度竞争力的性能。实证评估表明,Qwen3在多样化的基准测试中取得了最先进的结果,涵盖代码生成、数学推理、代理任务等领域,与更大的MoE模型和专有模型相竞争。与前代模型Qwen2.5相比,Qwen3将支持的多语言数量从29种扩展到了119种,通过改进跨语言理解和生成能力,提升了全球可访问性。为了便于复现性和社区驱动的研究与开发,所有Qwen3模型均以Apache 2.0协议公开提供。
1 引言
追求通用人工智能(AGI)或超级人工智能(ASI)一直是人类的目标。最近,基础模型的进展,例如GPT-4o(OpenAI, 2024)、Claude 3.7(Anthropic, 2025)、Gemini 2.5(DeepMind, 2025)、DeepSeek-V3(Liu et al., 2024a)、Llama-4(Meta-AI, 2025)和Qwen2.5(Yang et al., 2024b),已经在这个目标上取得了显著进展。这些模型在横跨多个领域和任务的海量数据集上进行训练,有效将人类知识和能力融入其参数之中。此外,近期推理模型的发展,通过强化学习优化,突显了基础模型在推理时扩展和实现更高智能水平的潜力,例如o3(OpenAI, 2025)和DeepSeek-R1(Guo et al., 2025)。尽管大多数最先进模型仍为专有模型,开源社区的迅速增长已大幅缩小了开源权重模型与专有模型之间的性能差距。值得注意的是,越来越多的顶级模型(Meta-AI, 2025;Liu et al., 2024a;Guo et al., 2025;Yang et al., 2024b)被作为开源发布,促进了人工智能领域的广泛研究和创新。
在本报告中,我们介绍Qwen3,这是我们基础模型家族Qwen的最新系列。Qwen3是一系列开源权重大型语言模型(LLMs),在各种任务和领域中实现了最先进的性能。我们发布了密集模型和专家混合(MoE)模型,参数范围从0.6亿到235亿,以满足不同下游应用的需求。特别地,旗舰模型Qwen3-235B-A22B是一个MoE模型,总共有235亿个参数,每个token激活22亿个参数。这种设计确保了高性能和高效的推理。
Qwen3引入了若干关键技术进步以增强其功能和可用性。首先,它将两种不同的操作模式,即“思考模式”和“非思考模式”,集成到单个模型中。这使得用户可以在这些模式之间切换而无需更换不同的模型,例如从Qwen2.5切换到QwQ(Qwen团队,2024)。这种灵活性确保了开发者和用户可以高效地调整模型行为以适应特定任务。此外,Qwen3引入了“思考预算”,让用户对模型执行任务时所应用的推理努力程度进行细粒度控制。这一能力对于优化计算资源和性能至关重要,使模型的思考行为能够适应现实世界应用中的各种复杂性。此外,Qwen3在覆盖多达119种语言和方言的预训练数据上进行了训练,有效增强了其多语言能力。这种广泛的语言支持放大了其在全球应用场景和国际应用中的潜力。这些进步共同确立了Qwen3作为一个前沿的开源大语言模型家族的地位,能够有效应对各个领域和语言中的复杂任务。
Qwen3的预训练过程使用了一个大规模的数据集,约包含36万亿个token,经过精心策划以确保语言和领域的多样性。为了高效扩展训练数据,我们采用了多模态方法:微调Qwen2.5-VL(Bai et al., 2025)以从大量PDF文档中提取文本。我们还使用特定领域的模型生成合成数据:Qwen2.5-Math(Yang et al., 2024c)用于数学内容,Qwen2.5-Coder(Hui et al., 2024)用于代码相关数据。预训练过程遵循三阶段策略。第一阶段,该模型在约30万亿个token上进行训练,序列长度为4096个token,以建立强大的语言能力和一般性知识基础。第二阶段,我们在知识密集型数据上进一步训练模型,以提高其在科学、技术、工程和数学(STEM)及编码方面的推理能力,并使用更高质量的5万亿个token进行训练,加速了此阶段的学习率衰减。第三阶段,我们收集了高质量的长上下文语料库来扩展Qwen3模型的上下文长度。所有模型都在数百亿个token上进行预训练,序列长度为32768个token。长上下文语料库中,75%的文本长度在16384至32768个token之间,25%的文本长度在4096至16384个token之间。参照Qwen2.5(Yang et al., 2024b),我们将RoPE的基础频率从10,000增加到1,000,000,使用ABF技术(Xiong et al., 2023)。同时,我们引入YARN(Peng et al., 2023)和Dual Chunk Attention(DCA, An et al., 2024)以实现推理时序列长度容量的四倍增长。
类似于Qwen2.5(Yang et al., 2024b),我们基于上述三个预训练阶段开发了最佳超参数(例如学习率调度器和批量大小)的缩放定律。通过广泛的实验,我们系统地研究了模型架构、训练数据、训练阶段和最优训练超参数之间的关系。最后,我们为每个密集或MoE模型设置了预测的最佳学习率和批量大小策略。
我们对Qwen3系列的基础语言模型进行了全面评估。基础模型的评估主要关注其在一般知识、推理、数学、科学知识、编码和多语言能力方面的表现。预训练基础模型的评估数据集包括15个基准:
- 一般任务:MMLU (Hendrycks et al., 2021a)(5次shot),MMLU-Pro (Wang et al., 2024)(5次shot,CoT),MMLU-redux (Gema et al., 2024)(5次shot),BBH (Suzgun et al., 2023)(3次shot,CoT),SuperGPQA (Du et al., 2025)(5次shot,CoT)。
-
- 数学与STEM任务:GPQA (Rein et al., 2023)(5次shot,CoT),GSM8K (Cobbe et al., 2021)(4次shot,CoT),MATH (Hendrycks et al., 2021b)(4次shot,CoT)。
-
- 编码任务:EvalPlus (Liu et al., 2023a)(0次shot)(HumanEval (Chen et al., 2021),MBPP (Austin et al., 2021),Humaneval+,MBPP+ 的平均值)(Liu et al., 2023a),MultiPL-E (Cassano et al., 2023)(0次shot)(Python,C++,JAVA,PHP,TypeScript,C#,Bash,JavaScript),MBPP-3shot (Austin et al., 2021),CRUX-O of CRUXEval(1次shot)(Gu et al., 2024)。
-
- 多语言任务:MGSM (Shi et al., 2023)(8次shot,CoT),MMMLU (OpenAI, 2024)(5次shot),INCLUDE (Romanou et al., 2024)(5次shot)。
对于基础模型基线,我们将Qwen3系列基础模型与Qwen2.5基础模型(Yang et al., 2024b)和其他领先的开源基础模型进行比较,包括DeepSeek-V3 Base (Liu et al., 2024a)、Gemma-3 (Team et al., 2025)、Llama-3 (Dubey et al., 2024) 和 Llama-4 (Meta-AI, 2025) 系列基础模型,在参数规模方面进行对比。所有模型都使用相同的评估管道和广泛使用的评估设置,以确保公平比较。
- 多语言任务:MGSM (Shi et al., 2023)(8次shot,CoT),MMMLU (OpenAI, 2024)(5次shot),INCLUDE (Romanou et al., 2024)(5次shot)。
总体评估结果总结
基于总体评估结果,我们强调Qwen3基础模型的一些关键结论:
(1) 相比以前的开源SOTA密集和MoE基础模型(如DeepSeekV3 Base、Llama-4-Maverick Base和Qwen2.5-72B-Base),Qwen3-235B-A22B-Base在大多数任务中表现优于这些模型,且总参数或激活参数显著更少。
(2) 对于Qwen3 MoE基础模型,我们的实验结果表明:(a) 使用相同的预训练数据,Qwen3 MoE基础模型只需1/5\mathbf{1 / 5}1/5的激活参数即可达到与Qwen3密集基础模型相似的性能。(b) 由于Qwen3 MoE架构的改进、训练token的扩展以及更先进的训练策略,Qwen3 MoE基础模型即使在激活参数和总参数较少的情况下也能超越Qwen2.5 MoE基础模型。© 即使Qwen3 MoE基础模型的激活参数仅为Qwen2.5密集基础模型的1/10\mathbf{1 / 10}1/10,也能实现相当的性能,这在推理和训练成本上带来了显著优势。
(3) Qwen3密集基础模型的整体性能在更高的参数规模下与Qwen2.5基础模型相当。例如,Qwen3-1.7B/4B/8B/14B/32B-Base分别达到了与Qwen2.5-3B/7B/14B/32B/72B-Base相当的性能。尤其是在STEM、编码和推理基准测试中,Qwen3密集基础模型的表现甚至超过了Qwen2.5基础模型。
详细结果如下。
Qwen3-235B-A22B-Base 我们将Qwen3-235B-A22B-Base与之前的类似规模MoE模型Qwen2.5-Plus-Base(Yang et al., 2024b)以及其他领先的开源基础模型:Llama-4-Maverick(Meta-AI, 2025),Qwen2.5-72B-Base(Yang et al., 2024b),DeepSeek-V3 Base(Liu et al., 2024a)进行比较。从表3的结果来看,Qwen3-235B-A22B-Base模型在大多数评估基准中获得了最高的性能分数。我们进一步单独分析Qwen3-235B-A22B-Base与其他基线模型的比较。
(1) 与最近发布的开源模型Llama-4-Maverick-Base相比,Qwen3-235B-A22B-Base虽然参数大约是其两倍,但在大多数基准测试中仍然表现更好。
(2) 与之前最先进的开源模型DeepSeek-V3-Base相比,Qwen3-235B-A22B-Base在15个评估基准中有14个表现优于后者,仅使用约1/3\mathbf{1 / 3}1/3的总参数和2/3\mathbf{2 / 3}2/3的激活参数,展示了我们模型的强大性能和成本效益。
(3) 与我们之前的MoE模型Qwen2.5-Plus相比,Qwen3-235B-A22B-Base在更少的参数和激活参数下表现显著优越,显示出Qwen3在预训练数据、训练策略和模型架构方面的卓越优势。
(4) 与我们之前的旗舰开源密集模型Qwen2.5-72B-Base相比,Qwen3-235B-A22B-Base在所有基准测试中都超越了后者,使用的激活参数不到其1/3\mathbf{1 / 3}1/3。同时,由于模型架构的优势,Qwen3-235B-A22B-Base每万亿token的推理成本和训练成本远低于Qwen2.5-72B-Base。
Qwen3-32B-Base Qwen3-32B-Base是我们Qwen3系列中最大的密集模型。我们将其与类似规模的基线模型进行比较,包括Gemma-3-27B(Team et al., 2025)和Qwen2.5-32B(Yang et al., 2024b)。此外,我们引入两个强基线模型:最近发布的开源MoE模型Llama-4-Scout,其参数是Qwen3-32B-Base的三倍但激活参数为其一半;
表3:Qwen3-235B-A22B-Base与其他代表性强大开源基线的比较。最高和次高得分分别以粗体和下划线显示。
| Qwen2.5-72B | Qwen2.5-Plus | Llama-4-Maverick | DeepSeek-V3 | Qwen3-235B-A22B |
|---|---|---|---|---|
| 架构 | 密集 | MoE | MoE | MoE |
| 参数总数 | 72B | 271B | 402B | 671B |
| 激活参数 | 72B | 37B | 17B | 37B |
一般任务
| MMLU | 86.06 | 85.02 | 85.16 | 87.19 | 87.81 |
|---|---|---|---|---|---|
| MMLU-Redux | 83.91 | 82.69 | 84.05 | 86.14 | 87.40 |
| MMLU-Pro | 58.07 | 63.52 | 63.91 | 59.84 | 68.18 |
| SuperGPQA | 36.20 | 37.18 | 40.85 | 41.53 | 44.06 |
| BBH | 86.30 | 85.60 | 83.62 | 86.22 | 88.87 |
数学与STEM任务
| GPQA | 45.88 | 41.92 | 43.94 | 41.92 | 47.47 |
|---|---|---|---|---|---|
| GSM8K | 91.50 | 91.89 | 87.72 | 87.57 | 94.39 |
| MATH | 62.12 | 62.78 | 63.32 | 62.62 | 71.84 |
编码任务
| EvalPlus | 65.93 | 61.43 | 68.38 | 63.75 | 77.60 |
|---|---|---|---|---|---|
| MultiPL-E | 58.70 | 62.16 | 57.28 | 62.26 | 65.94 |
| MBPP | 76.00 | 74.60 | 75.40 | 74.20 | 81.40 |
| CRUX-O | 66.20 | 68.50 | 77.00 | 76.60 | 79.00 |
多语言任务
| MGSM | 82.40 | 82.21 | 79.69 | 82.68 | 83.53 |
|---|---|---|---|---|---|
| MMMLU | 84.40 | 83.49 | 83.09 | 85.88 | 86.70 |
| INCLUDE | 69.05 | 66.97 | 73.47 | 75.17 | 73.46 |
表4:Qwen3-32B-Base与其他强大的开源基线的比较。最高和次高得分分别以粗体和下划线显示。
| Qwen2.5-32B | Qwen2.5-72B | Gemma-3-27B | Llama-4-Scout | Qwen3-32B |
|---|---|---|---|---|
| 架构 | 密集 | 密集 | 密集 | MoE |
| 参数总数 | 32B | 72B | 27B | 109B |
| 激活参数 | 32B | 72B | 27B | 17B |
一般任务
| MMLU | 83.32 | 86.06 | 78.69 | 78.27 | 83.61 |
|---|---|---|---|---|---|
| MMLU-Redux | 81.97 | 83.91 | 76.53 | 71.09 | 83.41 |
| MMLU-Pro | 55.10 | 58.07 | 52.88 | 56.13 | 65.54 |
| SuperGPQA | 33.55 | 36.20 | 29.87 | 26.51 | 39.78 |
| BBH | 84.48 | 86.30 | 79.95 | 82.40 | 87.38 |
数学与STEM任务
| GPQA | 47.97 | 45.88 | 26.26 | 40.40 | 49.49 |
|---|---|---|---|---|---|
| GSM8K | 92.87 | 91.50 | 81.20 | 85.37 | 93.40 |
| MATH | 57.70 | 62.12 | 51.78 | 51.66 | 61.62 |
编码任务
| EvalPlus | 66.25 | 65.93 | 55.78 | 59.90 | 72.05 |
|---|---|---|---|---|---|
| MultiPL-E | 58.30 | 58.70 | 45.03 | 47.38 | 67.06 |
| MBPP | 73.60 | 76.00 | 68.40 | 68.60 | 78.20 |
| CRUX-O | 67.80 | 66.20 | 60.00 | 61.90 | 72.50 |
多语言任务
| MGSM | 78.12 | 82.40 | 73.74 | 79.93 | 83.06 |
|---|---|---|---|---|---|
| MMMLU | 82.40 | 84.40 | 77.62 | 74.83 | 83.83 |
| INCLUDE | 64.35 | 69.05 | 68.94 | 68.09 | 67.87 |
与我们之前旗舰开源密集模型Qwen2.5-72B-Base相比,Qwen3-32B-Base的参数超过两倍以上。结果显示见表4,支持以下三个关键结论:
(1) 在类似规模的模型中,Qwen3-32B-Base在大多数基准测试中优于Qwen2.5-32B-Base和Gemma-3-27B Base。特别是,Qwen3-32B-Base在MMLUPro上获得65.54分,在SuperGPQA上获得39.78分,显著优于其前身Qwen2.5-32B-Base。此外,Qwen3-32B-Base在编码基准测试中也显著高于所有基线模型。
(2) 出人意料的是,我们发现Qwen3-32B-Base在15个基准测试中有10个成绩优于Qwen2.5-72B-Base。尽管Qwen3-32B-Base的参数不足Qwen2.5-72B-Base的一半,但它在编码、数学和推理基准测试中表现出显著优势。
(3) 相较于Llama-4-Scout-Base,Qwen3-32B-Base在15个基准测试中全部胜出,参数仅为前者三分之一,但激活参数是其两倍。
Qwen3-14B-Base & Qwen3-30B-A3B-Base 对Qwen3-14B-Base和Qwen3-30B-A3B-Base的评估与类似规模的基线模型进行比较,包括Gemma-3-12B Base、Qwen2.5-14B Base。同样,我们也引入了两个强大的基线:(1) Qwen2.5-Turbo(Yang et al., 2024b),拥有42B参数和6B激活参数。请注意,它的激活参数是Qwen3-30B-A3B-Base的两倍。(2) Qwen2.5-32B-Base,其激活参数是Qwen3-30B-A3B-Base的11倍,也是Qwen3-14B-Base的两倍以上。结果如表5所示,我们可以得出以下结论。
(1) 在类似规模的模型中,Qwen3-14B-Base在所有15个基准测试中显著优于Qwen2.5-14B-Base和Gemma-3-12B-Base。
(2) 同样,Qwen3-14B-Base在参数不足Qwen2.5-32B-Base一半的情况下,也在几乎所有基准测试中表现优异。
(3) 只需Qwen3-14B-Base激活非嵌入参数的1/51 / 51/5,Qwen3-30B-A3B就能够在所有任务中显著优于Qwen2.5-14B-Base,并且在Qwen3-14B-Base和Qwen2.5-32B-Base上取得可比的成绩,再次证明了Qwen3相较我们之前Qwen2.5系列模型的根本性改进。
Qwen3-8B / 4B / 1.7B / 0.6B-Base 对于边缘侧模型,我们选取类似规模的Qwen2.5、Llama-3和Gemma-3基础模型作为基线。结果见表6、表7和表8。几乎在所有基准测试中,Qwen3-8B / 4B / 1.7B / 0.6B-Base都保持了强劲的表现。值得注意的是,Qwen3-8B / 4B / 1.7B-Base模型在超过一半的基准测试中甚至优于更大的Qwen2.5-14B / 7B / 3B-Base模型,特别是在与STEM和编码相关的基准测试中,反映了Qwen3模型的显著改进。
4 训练后处理
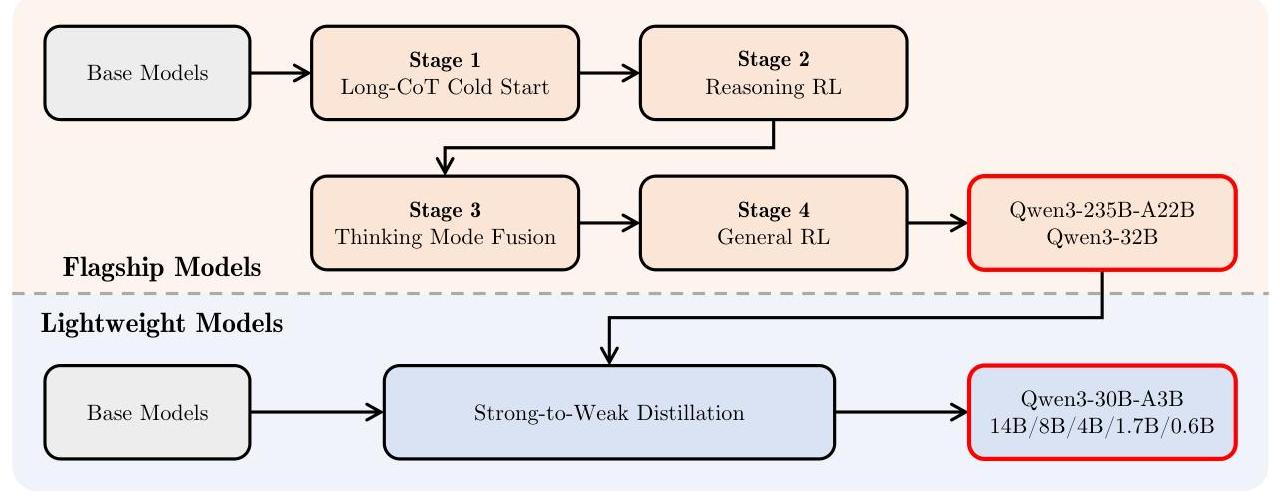
图1:Qwen3系列模型的训练后处理流程。Qwen3的训练后处理流程设计有两个核心目标:
(1) 思维控制:这涉及集成两种不同模式,即"非思维"和"思维"模式,为用户提供选择是否让模型进行推理的灵活性,并通过指定思维过程的token预算来控制思维深度。
(2) 由强到弱蒸馏:旨在简化轻量级模型的训练后处理流程。通过利用大规模模型的知识,我们大大降低了构建小规模模型所需的计算成本和发展投入。
如图1所示,Qwen3系列的旗舰模型遵循一个复杂的四阶段训练流程。前两个阶段专注于开发模型的"思维"能力。接下来的两个阶段旨在将强大的"非思维"功能集成到模型中。
初步实验表明,直接将教师模型的输出logits蒸馏到轻量级学生模型中可以有效提高其性能,同时保持对其推理过程的精细控制。这种方法消除了为每个小型模型单独进行详尽四阶段训练的必要性。它不仅带来了更好的即时性能(反映在更高的Pass@1分数上),而且提高了模型的探索能力(反映在改进的Pass@64结果上)。此外,这种方法还实现了更高的训练效率,仅需四阶段训练方法所需GPU小时数的1/101 / 101/10。在下面的部分中,我们将详细介绍四阶段训练流程,并详细解释由强到弱蒸馏方法。
4.1 长链思维冷启动
我们首先整理了一个涵盖广泛类别的综合数据集,包括数学、代码、逻辑推理和一般STEM问题。数据集中的每个问题都配对有验证过的参考答案或基于代码的测试用例。这个数据集构成了长链思维(Long Chain-of-Thought,简称long-CoT)训练的"冷启动"阶段的基础。
数据集构建涉及严格的两阶段过滤过程:查询过滤和响应过滤。在查询过滤阶段,我们使用Qwen2.5-72B-Instruct识别并删除不易验证的问题。这包括包含多个子问题或要求生成一般文本的问题。此外,我们排除了Qwen2.5-72B-Instruct可以在不使用CoT推理的情况下正确回答的问题。这有助于防止模型依赖表面猜测,确保只包含需要深入推理的复杂问题。此外,我们使用Qwen2.5-72B-Instruct标注每个查询的领域,以保持数据集中领域表示的平衡。
保留验证查询集之后,我们使用QwQ-32B(Qwen团队,2025)为剩余的每个查询生成NNN个候选响应。当QwQ-32B无法一致生成正确解决方案时,人工注释员手动评估响应的准确性。对于具有正向Pass@N的问题,进一步应用严格的过滤标准,以去除(1)最终答案错误的响应,(2)存在大量重复的内容,(3)明显表明猜测而没有充分推理的响应,(4)思维和摘要内容不一致的响应,(5)不适当的语言混合或风格转换,(6)怀疑与潜在验证集项目过于相似的响应。随后,从精炼后的数据集中仔细选择一个子集,用于初始冷启动训练推理模式。此阶段的目标是在不过度强调即时推理性能的前提下,灌输基础推理模式。这种方法确保模型的潜力不受限制,允许在后续的强化学习(RL)阶段进行更大的灵活性和改进。为了有效实现这一目标,在准备阶段应尽量减少训练样本的数量和训练步骤。
4.2 推理RL
推理RL阶段使用的查询-验证者对必须满足以下四个条件:(1) 它们未在冷启动阶段使用过。(2) 冷启动模型可以学会它们。(3) 它们尽可能具有挑战性。(4) 它们覆盖广泛的不同子域。我们最终收集了总共3995个查询-验证者对,并采用GRPO(Shao et al., 2024)更新模型参数。我们观察到,使用大的批次大小和每个查询的高rollouts数量,结合off-policy训练以提高样本效率,对训练过程是有益的。我们还解决了如何通过控制模型熵值来平衡探索与利用的问题,使其逐步稳定或保持不变,这对于保持稳定的训练至关重要。结果是,我们在单一RL运行过程中持续改进了训练奖励和验证性能,而无需任何手动干预超参数。例如,Qwen3-235B-A22B模型的AIME’24得分从70.1提高到85.1,共进行了170个RL训练步骤。
4.3 思维模式融合
思维模式融合阶段的目标是将"非思维"能力集成到先前开发的"思维"模型中。这种方法允许开发者管理和控制推理行为,同时减少部署独立模型以处理思维和非思维任务的成本和复杂性。为此,我们对推理RL模型进行持续监督式微调(SFT),并设计了一个聊天模板来融合两种模式。此外,我们发现能够熟练处理这两种模式的模型在不同思维预算下的表现始终良好。
SFT数据的构建。SFT数据集结合了"思维"和"非思维"数据。为了确保Stage 2模型的性能不会因额外的SFT而降低,"思维"数据通过拒绝抽样在Stage 1查询上生成,由Stage 2模型本身完成。另一方面,"非思维"数据经过精心策划,涵盖了多种任务,包括编码、数学、指令跟随、多语言任务、创意写作、问答和角色扮演。此外,我们自动生成检查清单来评估"非思维"数据的响应质量。为了增强低资源语言任务的性能,我们特别增加了翻译任务的比例。
聊天模板设计。为了更好地整合两种模式并使用户能够动态切换模型的思维过程,我们为Qwen3设计了聊天模板,如表9所示。具体而言,对于处于思维模式和非思维模式的样本,我们在用户查询或系统消息中分别引入/think和/no_think标志。这允许模型根据用户的输入选择适当的思维模式。对于非思维模式样本,我们在助手的响应中保留一个空的思维块。这种设计确保了模型内部格式的一致性,并允许开发者通过在聊天模板中连接一个空的思维块来防止模型进行思维行为。默认情况下,模型在思维模式下运行;因此,我们添加了一些思维模式训练样本,其中用户查询不包含/think标志。对于更复杂的多轮对话,我们在用户查询中随机插入多个/think和/no_think标志,模型响应则遵循遇到的最后一个标志。
思维预算。思维模式融合的另一个优势在于,一旦模型学会了在非思维和思维模式下做出响应,它自然会发展出处理中间情况的能力——基于不完整的思维生成响应。这种能力为实施对模型思维过程的预算控制奠定了基础。具体而言,当模型的思维长度达到用户定义的阈值时,我们手动停止思维过程并插入停止思维指令:“考虑到用户的时间有限,我必须现在基于直接的思维给出解决方案。\n\n\n”。插入此指令后,模型继续基于其到那时为止的推理生成最终响应。值得注意的是,这种能力并未显式训练,而是随着思维模式融合的应用自然形成的。
4.4 通用RL
通用RL阶段旨在广泛增强模型在不同场景中的能力和稳定性。为此,我们建立了涵盖20多个不同任务的复杂奖励体系,每个任务都有定制的评分标准。这些任务具体针对以下核心能力的增强:
- 指令跟随:确保模型准确解读和执行用户指令,包括内容、格式、长度和结构化输出的要求,交付符合用户期望的响应。
-
- 格式跟随:除了明确的指令外,我们希望模型能遵守特定的格式约定。例如,它应该通过在思维和非思维模式之间切换来正确响应/think和/no_think标志,并始终使用指定的标记(例如,和)来分离最终输出中的思维和响应部分。
-
- 偏好对齐:对于开放式查询,偏好对齐侧重于提升模型的帮助性、参与度和风格,最终提供更自然和令人满意的用户体验。
-
- 代理能力:涉及训练模型通过指定接口正确调用工具。在RL rollout过程中,模型可以与真实环境执行反馈进行完全的多轮交互循环,从而提高其在长期决策任务中的表现和稳定性。
-
- 特殊场景能力:在更专业的场景中,我们设计了针对特定上下文的任务。例如,在检索增强生成(RAG)任务中,我们引入奖励信号来引导模型生成准确和合适的上下文响应,从而最小化幻觉的风险。
为了提供对上述任务的反馈,我们利用了三种不同的奖励类型:
(1) 基于规则的奖励:基于规则的奖励已在推理RL阶段广泛使用,并且对一般任务如指令跟随(Lambert et al., 2024)和格式遵循也很有用。设计良好的基于规则的奖励可以高精度地评估模型输出的正确性,防止奖励黑客等问题。
(2) 带有参考答案的基于模型的奖励:在这种方法中,我们为每个查询提供一个参考答案,并提示Qwen2.5-72B-Instruct根据这个参考答案对模型响应进行评分。这种方法可以灵活处理多种任务,而不需要严格的格式,避免了纯基于规则的奖励可能产生的假阴性。
(3) 不带参考答案的基于模型的奖励:利用人类偏好数据,我们训练了一个奖励模型,为模型响应分配标量分数。这种方法不依赖参考答案,可以处理更广泛的查询,同时有效增强模型的参与度和帮助性。
- 特殊场景能力:在更专业的场景中,我们设计了针对特定上下文的任务。例如,在检索增强生成(RAG)任务中,我们引入奖励信号来引导模型生成准确和合适的上下文响应,从而最小化幻觉的风险。
4.5 由强到弱蒸馏
由强到弱蒸馏流程专门设计用于优化轻量级模型,包括5个密集模型(Qwen3-0.6B,1.7B,4B,8B和14B)和一个MoE模型(Qwen3-30B-A3B)。这种方法提高了模型性能,同时有效地赋予了稳健的模式切换能力。蒸馏过程分为两个主要阶段:
(1) 离线策略蒸馏:在此初始阶段,我们将教师模型生成的/think和/no_think模式输出结合起来用于响应蒸馏。这有助于轻量级学生模型开发基本的推理技能和在不同思维模式之间切换的能力,为下一阶段的在线策略训练打下坚实基础。
(2) 在线策略蒸馏:在此阶段,学生模型生成在线策略序列进行微调。具体来说,抽取提示词,学生模型以/think或/no_think模式生成响应。然后通过将学生模型的logits与教师模型(Qwen3-32B或Qwen3-235B-A22B)对齐,以最小化KL散度,对学生模型进行微调。
4.6 训练后评估
为了全面评估指令微调模型的质量,我们采用了自动基准测试来评估模型在思维和非思维模式下的表现。这些基准测试
表10:多语言基准测试及其包含的语言。语言以IETF语言标签标识。
| 基准测试 | # 语言 | 语言 |
|---|---|---|
| Multi-IF | 8 | en, es, fr, hi, it, pt, ru, zh |
| INCLUDE | 44 | ar, az, be, bg, bn, de, el, es, eu, fa, fi, fr, he, hi, hr, hu, hy, id, it, ja, ka, kk, ko, lt, mk, ml, ms, ne, nl, pl, pt, ru, sq, sr, ta, te, tl, tr, uk, ur, uz, vi, zh |
| MMMLU | 14 | ar, bn, de, en, es, fr, hi, id, it, ja, ka, kk, ko, lt, lv, mk, ml, ms, ne, nl, pl, pt, ru, sw, zh |
| MT-AIME2024 | 55 | af, ar, bg, bn, ca, cs, cy, da, de, el, en, es, et, fa, fi, fr, gu, he, hi, hr, hu, id, it, ja, kn, ko, lt, lv, mk, ml, mr, ne, nl, no, pa, pl, pt, ro, ru, sk, sl, so, sq, sv, sw, ta, te, th, tl, tr, uk, ur, vi, zh-Hans, zh-Hant |
| PolyMath | 18 | ar, bn, de, en, es, fr, id, it, ja, ko, ms, pt, ru, sw, ta, te, th, tl, tr, vi, zh |
| MLogiQA | 10 | ar, en, es, fr, ja, ko, pt, th, vi, zh |
被分类为几个维度:
- 一般任务:我们使用包括MMLU-Redux(Gema等人,2024年)、GPQADiamond(Rein等人,2023年)、C-Eval(Huang等人,2023年)和LiveBench(2024-11-25)(White等人,2024年)在内的基准测试。对于GPQA-Diamond,我们为每个查询采样10次并报告平均准确率。
-
- 对齐任务:为了评估模型与人类偏好的对齐程度,我们使用了一系列专业基准测试。对于指令跟随性能,我们报告IFEval(Zhou等人,2023年)的严格提示准确率。为了评估与一般主题的人类偏好对齐,我们使用Arena-Hard(Li等人,2024年)和AlignBench v1.1(Liu等人,2023b)。对于写作任务,我们依赖Creative Writing V3(Paech,2024年)和WritingBench(Wu等人,2025年)来评估模型的熟练程度和创造力。
-
- 数学与文本推理:为了评估数学和逻辑推理能力,我们使用了高水平的数学基准测试,包括MATH-500(Lightman等人,2023年)、AIME’24和AIME’25(AIME,2025年),以及文本推理任务,包括ZebraLogic(Lin等人,2025年)和AutoLogi(Zhu等人,2025年)。对于AIME问题,每年的问题包括第I部分和第II部分,总计30个问题。对于每个问题,我们采样64次并取平均准确率为最终得分。
-
- 代理与编码:为了测试模型在编码和基于代理任务中的熟练程度,我们使用BFCL v3(Yan等人,2024年)、LiveCodeBench(v5, 2024.10-2025.02)(Jain等人,2024年)和来自CodeElo的Codeforces评级(Quan等人,2025年)。对于BFCL,所有Qwen3模型都使用FC格式进行评估,并使用yarn将模型部署到64k的上下文长度以进行多轮评估。一些基线来自于BFCL排行榜,取FC和Prompt格式中的较高得分。对于未在排行榜上报告的模型,使用Prompt格式进行评估。对于LiveCodeBench,在非思考模式下,我们使用官方推荐的提示;而在思考模式下,我们调整提示模板,使模型能够更自由地思考,移除You will not return anything except for the program的限制。为了评估模型与竞争编程专家之间的性能差距,我们使用CodeForces计算Elo评级。在我们的基准测试中,每个问题通过最多八次独立推理尝试来解决。
-
- 多语言任务:对于多语言能力,我们评估四种任务:指令跟随、知识、数学和逻辑推理。指令跟随使用Multi-IF(He等人,2024年)进行评估,重点关注8种主要语言。知识评估包括两种类型:通过INCLUDE(Romanou等人,2024年)评估区域知识,涵盖44种语言,以及通过MMMLU(OpenAI,2024年)在14种语言上评估一般知识,不包括未经优化的约鲁巴语;在这两个基准测试中,我们仅采样原始数据的10%10 \%10%以提高评估效率。数学任务使用MT-AIME2024(Son等人,2025年)进行评估,涵盖55种语言,以及PolyMath(Wang等人,2025年),涵盖18种语言。逻辑推理使用MlogiQA进行评估,涵盖10种语言,来源Zhang等人(2024年)。
对于Qwen3系列的所有思维模式下的模型,我们使用采样温度为0.6,top-p值为0.95,top-k值为20。此外,对于Creative Writing v3和WritingBench,我们应用了1.5的存在惩罚,以鼓励生成更多样化的内容。对于Qwen3系列的非思考模式下的模型,我们配置了采样超参数,温度=0.7,top-p=0.8,top-k=20,存在惩罚=1.5。对于思考和非思考模式,我们都将最大输出长度设置为32,768个token,除了AIME’24和AIME’25,我们将此长度扩展到38,912个token,以提供足够的思考空间。
表11:Qwen3-235B-A22B(思考)与其他推理基线的比较。最高和次高得分分别以粗体和下划线显示。
- 多语言任务:对于多语言能力,我们评估四种任务:指令跟随、知识、数学和逻辑推理。指令跟随使用Multi-IF(He等人,2024年)进行评估,重点关注8种主要语言。知识评估包括两种类型:通过INCLUDE(Romanou等人,2024年)评估区域知识,涵盖44种语言,以及通过MMMLU(OpenAI,2024年)在14种语言上评估一般知识,不包括未经优化的约鲁巴语;在这两个基准测试中,我们仅采样原始数据的10%10 \%10%以提高评估效率。数学任务使用MT-AIME2024(Son等人,2025年)进行评估,涵盖55种语言,以及PolyMath(Wang等人,2025年),涵盖18种语言。逻辑推理使用MlogiQA进行评估,涵盖10种语言,来源Zhang等人(2024年)。
| OpenAI-o1 | DeepSeek-R1 | Grok-3-Beta (思考) |
Gemini2.5-Pro | Qwen3-235B-A22B | ||
| 架构 | - | MoE | - | - | MoE | |
| 激活参数 | - | 37B | - | - | 22B | |
| 总参数 | - | 671B | - | - | 235B | |
| 一般任务 | MMLU-Redux | 92.8 | 92.9 | - | 93.7 | 92.7 |
| GPQA-Diamond | 78.0 | 71.5 | 80.2 | 84.0 | 71.1 | |
| C-Eval | 85.5 | 91.8 | - | 82.9 | 89.6 | |
| LiveBench 2024-11-25 | 75.7 | 71.6 | - | 82.4 | 77.1 | |
| 对齐任务 | IFEval 严格提示 | 92.6 | 83.3 | - | 89.5 | 83.4 |
| Arena-Hard | 92.1 | 92.3 | - | 96.4 | 95.6 | |
| AlignBench v1.1 | 8.86 | 8.76 | - | 9.03 | 8.94 | |
| Creative Writing v3 | 81.7 | 85.5 | - | 86.0 | 84.6 | |
| WritingBench | 7.69 | 7.71 | - | 8.09 | 8.03 | |
| 数学与文本推理 | MATH-500 | 96.4 | 97.3 | 98.8 | 98.0 | |
| AIME’24 | 74.3 | 79.8 | 83.9 | 92.0 | 85.7 | |
| AIME’25 | 79.2 | 70.0 | 77.3 | 86.7 | 81.5 | |
| ZebraLogic | 81.0 | 78.7 | - | 87.4 | 80.3 | |
| AutoLogi | 79.8 | 86.1 | - | 85.4 | 89.0 | |
| 代理与编码 | BFCL v3 | 67.8 | 56.9 | - | 62.9 | 70.8 |
| LiveCodeBench v5 | 63.9 | 64.3 | 70.6 | 70.4 | 70.7 | |
| CodeForces(评分 / 百分位) | 1891 / 96.7% | 2029 / 98.1% | - | 2001 / 97.9% | 2056 / 98.2% | |
| 多语言任务 | Multi-IF | 48.8 | 67.7 | - | 77.8 | 71.9 |
| INCLUDE | 84.6 | 82.7 | - | 85.1 | 78.7 | |
| MMMLU 14种语言 | 88.4 | 86.4 | - | 86.9 | 84.3 | |
| MT-AIME2024 | 67.4 | 73.5 | - | 76.9 | 80.8 | |
| PolyMath | 38.9 | 47.1 | - | 52.2 | 54.7 | |
| MLogiQA | 75.5 | 73.8 | - | 75.6 | 77.1 |
表12:Qwen3-235B-A22B(非思考)与其他非推理基线的比较。最高和次高得分分别以粗体和下划线显示。
| | | | | | | |
| — | — | — | — | — | — |
| | GPT-40 -2024-11-20 | DeepSeek-R1 | Grok-3-Beta
(思考) | Gemini2.5-Pro | Qwen3-235B-A22B |
| | 架构 | - | MoE | - | - | MoE |
| | 激活参数 | - | 37B | - | - | 22B |
| | 总参数 | - | 671B | - | - | 235B |
| 一般任务 | MMLU-Redux | 87.0 | 89.1 | - | 91.8 | 89.2 |
| | GPQA-Diamond | 46.0 | 59.1 | - | 69.8 | 62.9 |
| | C-Eval | 75.5 | 86.5 | - | 83.5 | 86.1 |
| | LiveBench 2024-11-25 | 52.2 | 60.5 | - | 59.5 | 62.5 |
| 对齐任务 | IFEval 严格提示 | 86.5 | 86.1 | - | 86.7 | 83.2 |
| | Arena-Hard | 85.3 | 85.5 | - | 82.7 | 96.1 |
| | AlignBench v1.1 | 7.43 | 7.25 | - | 7.67 | 8.10 |
| | Creative Writing v3 | 52.8 | 55.0 | - | 55.8 | 75.0 |
| | WritingBench | 6.03 | 6.13 | - | 6.49 | 7.59 |
| 数学与文本推理 | MATH-500 | 93.9 | 94.3 | | 98.0 | 97.4 |
| | AIME’24 | 69.7 | 72.6 | 83.8 | 92.0 | 85.7 |
| | AIME’25 | 44.5 | 49.6 | 65.6 | 86.7 | 81.5 |
| | ZebraLogic | 59.1 | 69.6 | - | 87.4 | 89.1 |
| | AutoLogi | 78.6 | 74.6 | - | 85.4 | 89.1 |
| 代理与编码 | BFCL v3 | 49.5 | 53.5 | - | 62.9 | 68.1 |
| | LiveCodeBench v5 | 45.5 | 54.5 | 70.6 | 70.4 | 57.5 |
| | CodeForces(评分 / 百分位) | 1574 / 89.1% | 1691 / 93.4% | - | 1671 / 92.8% | 1785 / 95.6% |
| 多语言任务 | Multi-IF | 29.8 | 31.3 | - | 70.0 | 71.2 |
| | INCLUDE | 59.7 | 68.0 | - | 61.8 | 67.8 |
| | MMMLU 14种语言 | 73.8 | 78.6 | - | 69.8 | 74.4 |
| | MT-AIME2024 | 33.7 | 44.6 | - | 60.7 | 65.4 |
| | PolyMath | 28.6 | 35.1 | - | 40.0 | 42.7 |
| | MLogiQA | 53.6 | 63.3 | - | 40.9 | 39.5 |
1/10激活参数,证明了我们的由强到弱蒸馏方法在赋予轻量级模型深度推理能力方面的有效性。
(2) 从表16中可以看出,Qwen3-30B-A3B和Qwen3-14B(非思考模式)在大多数基准测试中超越了非推理基线。它们以显著更少的激活和总参数超越了我们之前的Qwen2.5-32B-Instruct模型,从而实现更高效且更具成本效益的性能。
Qwen3-8B / 4B / 1.7B / 0.6B 对于Qwen3-8B和Qwen3-4B,我们在思考模式下与DeepSeek-R1-Distill-Qwen-14B和DeepSeek-R1-Distill-Qwen-32B进行比较,在非思考模式下与LLaMA-3.1-8B-Instruct(Dubey et al., 2024),Gemma-3-12B-IT(Team et al., 2025),Qwen2.5-7B-Instruct和Qwen2.5-14B-Instruct进行比较。对于Qwen3-1.7B和Qwen3-0.6B,我们在思考模式下与DeepSeek-R1-Distill-Qwen-1.5B和DeepSeek-R1-Distill-Llama-8B进行比较,在非思考模式下与Gemma-3-1B-IT,Phi-4-mini,Qwen2.5-1.5B-Instruct和Qwen2.5-3B-Instruct进行比较。我们展示了Qwen3-8B和Qwen3-4B的评估结果,如表17和18所示,Qwen3-1.7B和Qwen3-0.6B的评估结果,如表19和20所示。总的来说,这些边缘侧模型表现出色的性能,并且在思考或非思考模式下,即使是更多的参数,包括我们之前的Qwen2.5模型,也优于基线。这些结果再次证明了我们由强到弱蒸馏方法的有效性,使我们能够以显著减少的成本和努力构建轻量级Qwen3模型。
4.7 讨论
思维预算的有效性
为了验证Qwen3能否通过增加思维预算提升其智能水平,我们在数学、编码和STEM领域上的四个基准测试中调整了分配的思维预算。由此产生的扩展曲线如图2所示,Qwen3展示了一种与分配的思维预算相关的可扩展且平滑的性能提升。此外,我们观察到,如果我们进一步将输出长度扩展到32 K以上,预计未来模型性能将进一步提升。我们将这一探索留作未来工作。
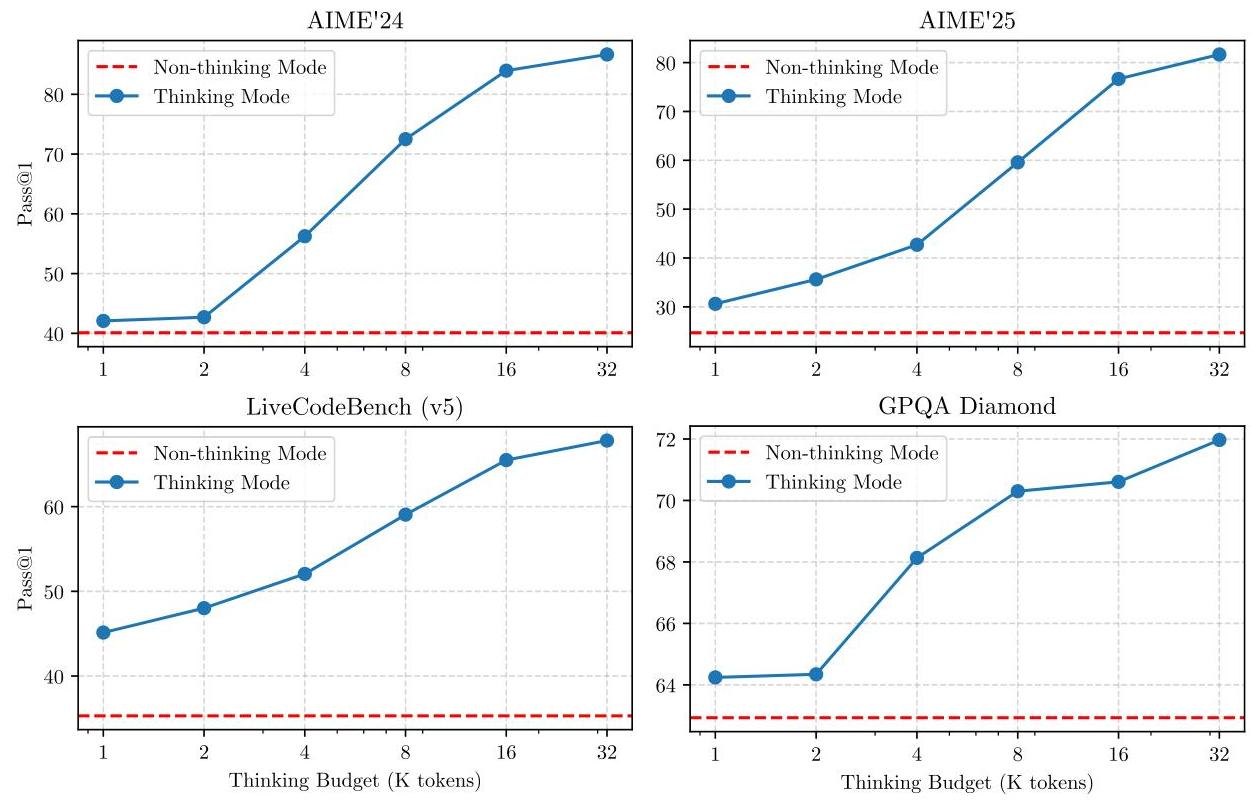
图2:Qwen3-235B-A22B相对于思维预算的性能。
在线策略蒸馏的有效性和效率
我们通过比较经过蒸馏和直接强化学习后的性能和计算成本(以GPU小时衡量)来评估在线策略蒸馏的有效性和效率,两者都从同一个离线策略蒸馏的8B检查点开始。为了简单起见,我们只关注数学和代码相关查询。
这项比较汇总在表21中,结果显示,蒸馏在性能上显著优于强化学习,同时只需要大约1/101 / 101/10的GPU小时。此外,从教师模型logit进行蒸馏可以使学生模型扩展其探索空间并增强推理潜力,如在AIME’24和AIME’25基准测试中蒸馏后pass@64分数的改善所证实,相较于初始检查点。相反,强化学习并没有导致pass@64分数的任何改进。这些观察结果突出了利用更强的教师模型指导学生模型学习的优势。
表21:在Qwen3-8B上的强化学习和在线策略蒸馏比较。括号中的数字表示pass@64分数。
| 方法 | AIME’24 | AIME’25 | MATH500 | LiveCodeBench v5 | MMLU-Redux | GPQA-Diamond | GPU小时 |
|---|---|---|---|---|---|---|---|
| 离线蒸馏 | 55.0(90.0)55.0(90.0)55.0(90.0) | 42.8(83.3)42.8(83.3)42.8(83.3) | 92.4 | 42.0 | 86.4 | 55.6 | - |
| + 强化学习 | 67.6(90.0)67.6(90.0)67.6(90.0) | 55.5(83.3)55.5(83.3)55.5(83.3) | 94.8 | 52.9 | 86.9 | 61.3 | 17,920 |
| + 在线策略蒸馏 | 74.4(93.3)\mathbf{74.4(93.3)}74.4(93.3) | 65.5(86.7)\mathbf{65.5(86.7)}65.5(86.7) | 97.0\mathbf{97.0}97.0 | 60.3\mathbf{60.3}60.3 | 88.3\mathbf{88.3}88.3 | 63.3\mathbf{63.3}63.3 | 1,800 |
思维模式融合和通用RL的效果
为了评估训练后思维模式融合和通用强化学习(RL)的有效性,我们在Qwen-32B模型的各种阶段进行评估。除了前面提到的数据集,我们还引入了几个内部基准测试来监控其他能力。这些基准测试包括:
- CounterFactQA:包含反事实问题,模型需要识别这些问题不是事实性的,并避免生成虚假答案。
-
- LengthCtrl:包括有长度要求的创意写作任务;最终得分基于生成内容长度与目标长度之间的差异。
-
- ThinkFollow:涉及随机插入/think和/no_think标志的多轮对话,测试模型是否能根据用户查询正确切换思维模式。
-
- ToolUse:评估模型在单轮、多轮和多步调用过程中的稳定性。得分包括调用过程中的意图识别准确性、格式准确性和参数准确性。
表22:Qwen3-32B模型在推理RL(第2阶段)、思维模式融合(第3阶段)和通用RL(第4阶段)后的性能。带有*的基准测试是内部数据集。
- ToolUse:评估模型在单轮、多轮和多步调用过程中的稳定性。得分包括调用过程中的意图识别准确性、格式准确性和参数准确性。
| 基准测试 | 第2阶段 推理RL |
第3阶段 思维模式融合 |
第4阶段 通用RL |
|||
|---|---|---|---|---|---|---|
| 思维 | 思维 | 非思维 | 思维 | 非思维 | ||
| 一般 任务 |
LiveBench 2024-11-25 | 68.6 | 70.9-2.3 | 57.1 | 74.9-4.0 | 59.8-2.6 |
| Arena-Hard | 86.8 | 89.4-2.6 | 88.5 | 93.8-4.4 | 92.8-4.3 | |
| CounterFactQA* | 50.4 | 61.3-10.9 | 64.3 | 68.1-6.8 | 66.4-2.1 | |
| 指令 E\mathcal{E}E 格式 跟随 |
IFEval 严格提示 | 73.0 | 78.4-5.4 | 78.4 | 85.0-6.6 | 83.2-4.8 |
| Multi-IF | 61.4 | 64.6-3.2 | 65.2 | 73.0-8.4 | 70.7-5.5 | |
| LengthCtrl* | 62.6 | 70.6-8.0 | 84.9 | 73.5-2.9 | 87.3-2.4 | |
| ThinkFollow* | - | 88.7 | 98.9-10.2 | |||
| 代理 | BFCL v3 | 69.0 | 68.4-0.6 | 61.5 | 70.3-3.9 | 63.0-1.5 |
| ToolUse* | 63.3 | 70.4-7.1 | 73.2 | 85.5-15.1 | 86.5-13.3 | |
| 知识 E\mathcal{E}E STEM | MMLU-Redux | 91.4 | 91.0-0.4 | 86.7 | 90.9-0.1 | 85.7-1.0 |
| GPQA-Diamond | 68.8 | 69.0-0.2 | 50.4 | 68.4-0.6 | 54.6-4.3 | |
| 数学 E\mathcal{E}E 编码 | AIME’24 | 83.8 | 81.9-1.9 | 28.5 | 81.4-0.5 | 31.0-2.5 |
| LiveCodeBench v5 | 68.4 | 67.2-1.2 | 31.1 | 65.7-1.5 | 31.3-0.2 |
结果如表22所示,我们可以得出以下结论:
(1) 第3阶段将非思维模式集成到模型中,该模型在前两个阶段训练后已具备思维能力。ThinkFollow基准测试得分为88.7,表明模型已初步具备模式切换能力,尽管偶尔还会出错。第3阶段还增强了模型在思维模式下的整体和指令跟随能力,CounterFactQA提高了10.9分,LengthCtrl提高了8.0分。
(2) 第4阶段进一步加强了模型在思维和非思维模式下的整体、指令跟随和代理能力。值得一提的是,ThinkFollow得分提高到98.9,确保准确的模式切换。
(3) 对于知识、STEM、数学和编码任务,思维模式融合和通用RL并未带来显著改进。相比之下,对于像AIME’24和LiveCodeBench这样的挑战性任务,在这两个训练阶段之后,思维模式下的性能实际上有所下降。我们推测这种退化是由于模型在更广泛的一般任务上训练,可能会削弱其处理复杂问题的专业能力。在Qwen3的开发过程中,我们选择接受这种性能权衡,以增强模型的整体通用性。
5 结论
在本技术报告中,我们介绍了Qwen3,Qwen系列的最新版本。Qwen3兼具思考模式和非思考模式,允许用户动态管理用于复杂思考任务的token数量。该模型在一个包含36万亿token的庞大数据库上进行预训练,使其能够理解并在119种语言和方言中生成文本。通过一系列全面的评估,Qwen3在预训练和后训练模型的标准基准测试中展现了强大的性能,包括代码生成、数学、推理和代理任务。
在不久的将来,我们的研究将集中在几个关键领域。我们将继续扩大预训练,使用质量和内容更加丰富多样的数据。同时,我们将改进模型架构和训练方法,以实现有效的压缩和扩展到极长的上下文。此外,我们计划增加强化学习的计算资源,特别强调从环境反馈中学习的基于代理的RL系统。这将使我们能够构建能够处理需要推理时间扩展的复杂任务的代理。
6 作者
核心贡献者:杨安、李安峰、杨宝松、张北辰、惠彬原、郑博、余博文、高畅、黄成恩、吕晨旭、郑楚杰、刘大业、周帆、黄飞、胡峰、葛浩、魏昊然、林焕、唐嘉龙、杨健、涂建宏、张健伟、杨建新、杨佳欣、周静、周敬仁、林俊阳、党凯、包克勤、杨柯鑫、余乐、邓亮浩、李梅、薛明峰、李铭泽、张佩、王鹏、朱琴、门瑞、高睿泽、刘世轩、罗双、李天豪、唐天逸、尹文彪、任星章、王新宇、张新宇、任玄成、范阳、苏阳、张一常、张颖哲、万宇、刘玉琼、王泽昆、崔泽宇、张振如、周志鹏、邱子涵
贡献者:陈蓓、孙彪、罗斌、张斌、王炳海、平博闻、邓波义、司昌、杨朝杰、程晨、吴晨飞、李成鹏、李承元、洪凡、赵国宾、张航、胡杭瑞、赵含宇、林浩、向浩、黄浩炎、高宏伟、钟虎门、王家林、蒋建东、万建国、曾建源、陈佳伟、张洁、徐金、王金凯、张金阳、何金政、唐军、张凯、易柯、卢科明、陈克勤、陈朗诗、姜磊、张蕾、吴林娟、袁满、杨铭坤、孙敏敏、陈谋生、陈诺、刘朋、王鹏、朱鹏、张彭程、王鹏飞、汤乔瑜、付青、王秋月、张荣、胡瑞、林润吉、黄深、白帅、蒋树桐、宋思博、张斯奇、陈颂、陈涛、贺涛、贺婷、惠廷峰、丁伟、廖伟、林伟、张威、徐伟佳、葛文、周文猛、于文渊、贾先岩、石宪中、邓晓东、黄小明、李小元、李骁东、李小明、周曦延、牛新尧、韦西平、刘学敬、刘阳、姚阳、张杨、李彦鹏、刘彦涛、张毅丹、朱一凯、王奕文、胡艺文、江一文、李勇、朱元之、储云飞、冯云龙、周雨欣、蔡宇轩、马泽耀、李兆海、李政、唐政阳、符哲仁、富志远、张志朋、顾忠深、乔紫乐、孟子野、张宗萌
A 附录
A.1 额外评估结果
A.1.1 长期背景能力
表23:Qwen3模型在RULER基准测试中的表现。
| 模型 | | RULER | | | | | | | |
| :–: | :–: | :–: | :–: | :–: | :–: | :–: | :–: | :–: |
| | | 平均值 | 4K | 8K | 16K | 32K | 64K | 128K |
| | Qwen2.5-7B-Instruct | 85.4 | 96.7 | 95.1 | 93.7 | 89.4 | 82.3 | 55.1 |
| | Qwen2.5-14B-Instruct | 91.4 | 97.7 | 96.8 | 95.9 | 93.4 | 86.7 | 78.1 |
| | Qwen2.5-32B-Instruct | 92.9 | 96.9 | 97.1 | 95.5 | 95.5 | 90.3 | 82.0 |
| | Qwen2.5-72B-Instruct | 95.1 | 97.7 | 97.2 | 97.7 | 96.5 | 93.0 | 88.4 |
| 非思考模式 | Qwen3-4B | 85.2 | 95.1 | 93.6 | 91.0 | 87.8 | 77.8 | 66.0 |
| | Qwen3-8B | 89.1 | 96.3 | 96.0 | 91.8 | 91.2 | 82.1 | 77.4 |
| 2025年,Qwen3-14B | 94.6 | 98.0 | 97.8 | 96.4 | 96.1 | 94.0 | 85.1 |
| | Qwen3-32B | 93.7 | 98.4 | 96.0 | 96.2 | 94.4 | 91.8 | 85.6 |
| | Qwen3-30B-A3B | 91.6 | 96.5 | 97.0 | 95.3 | 92.4 | 89.1 | 79.2 |
| | Qwen3-235B-A22B | 95.0 | 97.7 | 97.2 | 96.4 | 95.1 | 93.3 | 90.6 |
| 思考模式 | Qwen3-4B | 83.5 | 92.7 | 88.7 | 86.5 | 83.2 | 83.0 | 67.2 |
| | Qwen3-8B | 84.4 | 94.7 | 94.4 | 86.1 | 80.8 | 78.3 | 72.0 |
| | Qwen3-14B | 90.1 | 95.4 | 93.6 | 89.8 | 91.9 | 90.6 | 79.0 |
| | Qwen3-32B | 91.0 | 94.7 | 93.7 | 91.6 | 92.5 | 90.0 | 83.5 |
| | Qwen3-30B-A3B | 86.6 | 94.1 | 92.7 | 89.0 | 86.6 | 82.1 | 75.0 |
| | Qwen3-235B-A22B | 92.2 | 95.1 | 94.8 | 93.0 | 92.3 | 92.0 | 86.0 |
为了评估长上下文处理能力,我们在表23中报告了RULER基准测试(Hsieh et al., 2024)的结果。为了实现长度外推,我们使用YARN(Peng et al., 2023)并设置scaling_factor=4。在思考模式下,我们设置了8192个token的思考预算,以减轻对极长输入的过度冗长推理。
结果表明:
- 在非思考模式下,Qwen3在长上下文处理任务中优于类似规模的Qwen2.5模型。
-
- 在思考模式下,模型的性能略有下降。我们假设思考内容对这些不依赖推理的检索任务没有显著好处,反而可能干扰检索过程。我们承诺在未来版本中增强思考模式下的长上下文能力。
A.1.2 多语言能力
表24-35展示了西班牙语、法语、葡萄牙语、意大利语、阿拉伯语、日语、韩语、印尼语、俄语、越南语、德语和泰语等多种语言的详细基准测试得分。这些表格中的结果表明,Qwen3系列模型在所有评估基准测试中都展现出具有竞争力的性能,展示了其强大的多语言能力。为了评估Qwen3在更广泛语言上的表现,我们利用Belebele(Bandarkar et al., 2023)这一自然语言理解的基准测试。我们在基准测试支持的80种语言中进行了评估,排除了42种未经优化的语言,如表36所示(按语言家族组织)。Qwen3与其他基线模型在Belebele基准测试中的性能比较见表37。结果显示,Qwen3在多语言能力上与类似规模的Gemma模型表现相当,同时显著优于Qwen2.5。
表24:西班牙语(es)基准测试得分。最高和次高得分分别以粗体和下划线表示。
| 模型 | Multi-IF | MLogiQA | INCLUDE | MMMLU | MT-AIME2024 | PolyMath | 平均 | |
|---|---|---|---|---|---|---|---|---|
| 思维模式 | Gemini2.5-Pro | 80.1 | 70.0 | 96.4 | 88.7 | 90.0 | 54.4 | 79.9 |
| QwQ-32B | 70.0 | 75.0 | 81.8 | 84.5 | 76.7 | 52.2 | 73.4 | |
| Qwen3-235B-A22B | 74.2 | 76.2 | 89.1 | 86.7 | 86.7 | 57.3 | 78.4 | |
| Qwen3-32B | 74.7 | 68.8 | 90.9 | 82.8 | 76.7 | 51.8 | 74.3 | |
| Qwen3-30B-A3B | 74.9 | 71.2 | 80.0 | 81.9 | 76.7 | 48.5 | 72.2 | |
| Qwen3-14B | 76.2 | 67.5 | 83.6 | 81.1 | 73.3 | 50.3 | 72.0 | |
| Qwen3-8B | 74.1 | 70.0 | 78.2 | 79.2 | 70.0 | 43.7 | 69.2 | |
| Qwen3-4B | 69.1 | 68.8 | 72.7 | 75.7 | 66.7 | 42.3 | 65.9 | |
| Qwen3-1.7B | 56.0 | 55.0 | 72.7 | 64.5 | 46.7 | 30.2 | 54.2 | |
| Qwen3-0.6B | 39.2 | 42.5 | 54.5 | 48.8 | 13.3 | 14.3 | 35.4 | |
| 非思维模式 | GPT-4o-2024-1120 | 67.5 | 52.5 | 89.1 | 80.6 | 10.0 | 15.5 | 52.5 |
| Gemma-3-27b-IT | 73.5 | 57.5 | 89.1 | 77.7 | 30.0 | 22.4 | 58.4 | |
| Qwen2.5-72B-Instruct | 66.7 | 61.3 | 80.0 | 80.1 | 20.0 | 18.8 | 54.5 | |
| Qwen3-235B-A22B | 71.7 | 66.2 | 83.6 | 83.7 | 33.3 | 29.5 | 61.3 | |
| Qwen3-32B | 72.1 | 65.0 | 83.6 | 80.4 | 26.7 | 24.7 | 58.8 | |
| Qwen3-30B-A3B | 72.1 | 53.8 | 85.5 | 78.3 | 33.3 | 25.0 | 58.0 | |
| Qwen3-14B | 76.2 | 63.7 | 78.2 | 77.4 | 40.0 | 25.0 | 60.1 | |
| Qwen3-8B | 73.1 | 50.0 | 80.0 | 73.7 | 16.7 | 21.3 | 52.5 | |
| Qwen3-4B | 65.8 | 50.0 | 60.0 | 68.3 | 13.3 | 17.3 | 45.8 | |
| Qwen3-1.7B | 47.9 | 43.8 | 50.9 | 54.3 | 10.0 | 11.6 | 36.4 | |
| Qwen3-0.6B | 35.5 | 37.5 | 43.6 | 39.5 | 3.3 | 5.8 | 27.5 |
表25:法语(fr)基准测试得分。最高和次高得分分别以粗体和下划线表示。
| 模型 | Multi-IF | MLogiQA | INCLUDE | MMMLU | MT-AIME2024 | PolyMath | 平均 | |
|---|---|---|---|---|---|---|---|---|
| 思维模式 | Gemini2.5-Pro | 80.5 | 73.8 | 85.7 | 88.3 | 80.0 | 52.8 | 76.8 |
| QwQ-32B | 72.4 | 78.8 | 76.2 | 84.0 | 80.0 | 49.4 | 73.5 | |
| Qwen3-235B-A22B | 77.3 | 78.8 | 85.7 | 86.6 | 86.7 | 57.4 | 78.8 | |
| Qwen3-32B | 76.7 | 81.2 | 76.2 | 82.1 | 83.3 | 47.1 | 74.4 | |
| Qwen3-30B-A3B | 75.2 | 67.5 | 83.3 | 81.0 | 76.7 | 46.9 | 71.8 | |
| Qwen3-14B | 77.6 | 71.2 | 73.8 | 80.4 | 73.3 | 44.2 | 70.1 | |
| Qwen3-8B | 73.8 | 66.2 | 85.7 | 77.9 | 70.0 | 45.3 | 69.8 | |
| Qwen3-4B | 71.3 | 63.7 | 71.4 | 74.5 | 66.7 | 40.2 | 64.6 | |
| Qwen3-1.7B | 52.6 | 56.2 | 54.8 | 64.8 | 60.0 | 28.7 | 52.8 | |
| Qwen3-0.6B | 36.1 | 48.8 | 47.6 | 48.4 | 6.7 | 14.0 | 33.6 | |
| 非思维模式 | GPT-4o-2024-1120 | 67.8 | 56.2 | 85.7 | 81.8 | 10.0 | 15.3 | 52.8 |
| Gemma-3-27b-IT | 73.9 | 57.5 | 73.8 | 78.3 | 23.3 | 21.5 | 54.7 | |
| Qwen2.5-72B-Instruct | 72.1 | 55.0 | 81.0 | 80.2 | 26.7 | 15.7 | 55.1 | |
| Qwen3-235B-A22B | 73.2 | 65.0 | 88.1 | 81.1 | 36.7 | 28.1 | 62.0 | |
| Qwen3-32B | 75.8 | 60.0 | 73.8 | 79.5 | 30.0 | 23.0 | 57.0 | |
| Qwen3-30B-A3B | 75.6 | 52.5 | 69.0 | 77.9 | 26.7 | 27.3 | 54.8 | |
| Qwen3-14B | 78.4 | 63.7 | 73.8 | 75.1 | 33.3 | 24.4 | 58.1 | |
| Qwen3-8B | 71.9 | 52.5 | 71.4 | 71.7 | 20.0 | 21.4 | 51.5 | |
| Qwen3-4B | 64.2 | 47.5 | 61.9 | 67.6 | 20.0 | 19.2 | 46.7 | |
| Qwen3-1.7B | 46.1 | 43.8 | 64.3 | 53.2 | 3.3 | 11.6 | 37.0 | |
| Qwen3-0.6B | 32.8 | 35.0 | 38.1 | 39.4 | 6.7 | 4.6 | 26.1 |
表26:葡萄牙语(pt)基准测试得分。最高和次高得分分别以粗体和下划线表示。
| 模型 | Multi-IF | MLogiQA | INCLUDE | MMMLU | MT-AIME2024 | PolyMath | 平均 | |
|---|---|---|---|---|---|---|---|---|
| 思维模式 | Gemini2.5-Pro | 80.5 | 73.8 | 83.9 | 88.9 | 73.3 | 52.2 | 75.4 |
| QwQ-32B | 70.5 | 70.0 | 80.4 | 84.0 | 80.0 | 48.7 | 72.3 | |
| Qwen3-235B-A22B | 73.6 | 78.8 | 78.6 | 86.2 | 86.7 | 58.3 | 77.0 | |
| Qwen3-32B | 74.1 | 76.2 | 76.8 | 82.6 | 80.0 | 52.4 | 73.7 | |
| Qwen3-30B-A3B | 76.1 | 71.2 | 71.4 | 81.0 | 76.7 | 49.3 | 71.0 | |
| Qwen3-14B | 77.3 | 68.8 | 75.0 | 81.6 | 83.3 | 46.7 | 72.1 | |
| Qwen3-8B | 73.9 | 67.5 | 75.0 | 78.6 | 56.7 | 44.8 | 66.1 | |
| Qwen3-4B | 70.6 | 62.5 | 71.4 | 75.1 | 73.3 | 44.2 | 66.2 | |
| Qwen3-1.7B | 55.6 | 60.0 | 53.6 | 64.6 | 46.7 | 28.2 | 51.4 | |
| Qwen3-0.6B | 38.7 | 33.8 | 42.9 | 47.5 | 10.0 | 12.7 | 30.9 | |
| 非思维模式 | GPT-4o-2024-1120 | 66.8 | 57.5 | 78.6 | 80.7 | 10.0 | 15.0 | 51.4 |
| Gemma-3-27b-IT | 72.9 | 55.0 | 75.0 | 77.1 | 33.3 | 20.9 | 55.7 | |
| Qwen2.5-72B-Instruct | 68.8 | 55.0 | 71.4 | 82.2 | 23.3 | 11.3 | 52.0 | |
| Qwen3-235B-A22B | 72.5 | 67.5 | 82.1 | 83.5 | 33.3 | 28.3 | 61.2 | |
| Qwen3-32B | 71.1 | 61.3 | 73.2 | 80.6 | 30.0 | 23.9 | 56.7 | |
| Qwen3-30B-A3B | 72.3 | 47.5 | 67.9 | 77.8 | 26.7 | 24.0 | 52.7 | |
| Qwen3-14B | 75.5 | 58.8 | 75.0 | 76.5 | 26.7 | 25.8 | 56.4 | |
| Qwen3-8B | 71.9 | 56.2 | 71.4 | 72.9 | 20.0 | 19.7 | 52.0 | |
| Qwen3-4B | 66.1 | 50.0 | 73.2 | 66.7 | 10.0 | 18.1 | 47.4 | |
| Qwen3-1.7B | 49.5 | 33.8 | 39.3 | 52.9 | 6.7 | 12.8 | 32.5 | |
| Qwen3-0.6B | 36.6 | 37.5 | 42.9 | 37.5 | 3.3 | 5.7 | 27.2 |
表27:意大利语(it)基准测试得分。最高和次高得分分别以粗体和下划线表示。
| 模型 | Multi-IF | INCLUDE | MMMLU | MT-AIME2024 | PolyMath | 平均 | |
|---|---|---|---|---|---|---|---|
| 思维模式 | Gemini2.5-Pro | 80.9 | 100.0 | 87.2 | 90.0 | 54.1 | 82.4 |
| QwQ-32B | 71.2 | 96.4 | 84.9 | 76.7 | 49.3 | 75.7 | |
| Qwen3-235B-A22B | 73.7 | 96.4 | 85.7 | 80.0 | 57.4 | 78.6 | |
| Qwen3-32B | 76.6 | 90.9 | 81.6 | 80.0 | 49.7 | 75.8 | |
| Qwen3-30B-A3B | 75.9 | 94.5 | 81.9 | 80.0 | 48.1 | 76.1 | |
| Qwen3-14B | 79.0 | 94.5 | 80.2 | 70.0 | 47.0 | 74.1 | |
| Qwen3-8B | 74.6 | 89.1 | 77.5 | 76.7 | 46.1 | 72.8 | |
| Qwen3-4B | 69.8 | 83.6 | 74.4 | 76.7 | 44.5 | 69.8 | |
| Qwen3-1.7B | 54.6 | 74.5 | 64.2 | 53.3 | 29.6 | 55.2 | |
| Qwen3-0.6B | 37.8 | 45.5 | 45.9 | 6.7 | 13.3 | 29.8 | |
| 非思维模式 | GPT-4o-2024-1120 | 67.6 | 98.2 | 80.7 | 13.3 | 15.2 | 55.0 |
| Gemma-3-27b-IT | 74.6 | 90.9 | 78.4 | 23.3 | 20.5 | 57.5 | |
| Qwen2.5-72B-Instruct | 67.2 | 94.5 | 80.7 | 16.7 | 16.7 | 55.2 | |
| Qwen3-235B-A22B | 72.9 | 92.7 | 82.6 | 33.3 | 28.6 | 62.0 | |
| Qwen3-32B | 71.4 | 92.7 | 79.5 | 30.0 | 23.0 | 59.3 | |
| Qwen3-30B-A3B | 73.9 | 87.3 | 77.7 | 33.3 | 24.8 | 59.4 | |
| Qwen3-14B | 75.8 | 89.1 | 75.7 | 26.7 | 27.6 | 59.0 | |
| Qwen3-8B | 72.1 | 85.5 | 72.9 | 13.3 | 23.8 | 53.5 | |
| Qwen3-4B | 63.0 | 78.2 | 67.8 | 23.3 | 19.3 | 50.3 | |
| Qwen3-1.7B | 46.1 | 70.9 | 53.4 | 6.7 | 11.9 | 37.8 | |
| Qwen3-0.6B | 35.1 | 43.6 | 39.0 | 0.0 | 4.5 | 24.4 |
表28:阿拉伯语(ar)基准测试得分。最高和次高得分分别以粗体和下划线表示。
| 模型 | MLogiQA | INCLUDE | MMMLU | MT-AIME2024 | PolyMath | 平均 | |
|---|---|---|---|---|---|---|---|
| 思维模式 | Gemini2.5-Pro | 75.0 | 89.3 | 87.8 | 76.7 | 52.6 | 76.3 |
| QwQ-32B | 75.0 | 67.9 | 81.8 | 80.0 | 41.3 | 69.2 | |
| Qwen3-235B-A22B | 80.0 | 71.4 | 83.6 | 76.7 | 53.7 | 73.1 | |
| Qwen3-32B | 66.2 | 73.2 | 80.1 | 86.7 | 47.0 | 70.6 | |
| Qwen3-30B-A3B | 66.2 | 66.1 | 77.2 | 83.3 | 47.3 | 68.0 | |
| Qwen3-14B | 71.2 | 67.9 | 77.4 | 83.3 | 46.6 | 69.3 | |
| Qwen3-8B | 65.0 | 67.9 | 74.4 | 76.7 | 44.9 | 65.8 | |
| Qwen3-4B | 62.5 | 55.4 | 67.7 | 66.7 | 41.2 | 58.7 | |
| Qwen3-1.7B | 55.0 | 44.6 | 53.2 | 36.7 | 25.8 | 43.1 | |
| Qwen3-0.6B | 40.0 | 41.1 | 38.9 | 10.0 | 11.7 | 28.3 | |
| 非思维模式 | GPT-4o-2024-1120 | 51.2 | 78.6 | 80.9 | 13.3 | 12.9 | 47.4 |
| Gemma-3-27b-IT | 56.2 | 62.5 | 74.4 | 26.7 | 22.8 | 48.5 | |
| Qwen2.5-72B-Instruct | 56.2 | 66.1 | 77.2 | 6.7 | 14.7 | 44.2 | |
| Qwen3-235B-A22B | 66.2 | 67.9 | 79.5 | 40.0 | 28.2 | 56.4 | |
| Qwen3-32B | 55.0 | 69.6 | 75.7 | 23.3 | 25.4 | 49.8 | |
| Qwen3-30B-A3B | 48.8 | 64.3 | 71.6 | 30.0 | 22.6 | 47.5 | |
| Qwen3-14B | 52.5 | 60.7 | 69.5 | 23.3 | 23.5 | 45.9 | |
| Qwen3-8B | 45.0 | 58.9 | 64.6 | 13.3 | 16.4 | 39.6 | |
| Qwen3-4B | 52.5 | 42.9 | 56.7 | 13.3 | 15.3 | 36.1 | |
| Qwen3-1.7B | 31.2 | 37.5 | 43.6 | 3.3 | 9.4 | 25.0 | |
| Qwen3-0.6B | 40.0 | 39.3 | 35.4 | 0.0 | 3.8 | 23.7 |
表29:日语(ja)基准测试得分。最高和次高得分分别以粗体和下划线表示。
| 模型 | MLogiQA | INCLUDE | MMMLU | MT-AIME2024 | PolyMath | 平均 | |
|---|---|---|---|---|---|---|---|
| 思维模式 | Gemini2.5-Pro | 72.5 | 74.5 | 83.8 | 83.3 | 55.4 | 73.9 |
| QwQ-32B | 73.8 | 86.3 | 82.3 | 53.3 | 39.9 | 67.1 | |
| Qwen3-235B-A22B | 75.0 | 94.1 | 84.8 | 73.3 | 52.7 | 76.0 | |
| Qwen3-32B | 70.0 | 90.2 | 80.2 | 76.7 | 47.7 | 73.0 | |
| Qwen3-30B-A3B | 66.2 | 88.2 | 79.9 | 73.3 | 47.4 | 71.0 | |
| Qwen3-14B | 68.8 | 88.2 | 79.4 | 66.7 | 45.7 | 69.8 | |
| Qwen3-8B | 71.2 | 86.3 | 74.9 | 73.3 | 44.7 | 70.1 | |
| Qwen3-4B | 63.7 | 80.4 | 72.5 | 53.3 | 40.7 | 62.1 | |
| Qwen3-1.7B | 53.8 | 74.5 | 61.8 | 36.7 | 28.5 | 51.1 | |
| Qwen3-0.6B | 47.5 | 47.1 | 45.1 | 13.3 | 14.5 | 33.5 | |
| 非思维模式 | GPT-4o-2024-1120 | 60.0 | 92.2 | 81.9 | 10.0 | 12.5 | 51.3 |
| Gemma-3-27b-IT | 66.2 | 86.3 | 76.5 | 20.0 | 17.3 | 53.3 | |
| Qwen2.5-72B-Instruct | 55.0 | 94.1 | 77.7 | 16.7 | 17.7 | 52.2 | |
| Qwen3-235B-A22B | 67.5 | 92.2 | 80.9 | 26.7 | 26.9 | 58.8 | |
| Qwen3-32B | 58.8 | 92.2 | 78.0 | 20.0 | 20.5 | 53.9 | |
| Qwen3-30B-A3B | 51.2 | 82.4 | 74.9 | 30.0 | 20.6 | 51.8 | |
| Qwen3-14B | 55.0 | 84.3 | 73.8 | 33.3 | 19.8 | 53.2 | |
| Qwen3-8B | 47.5 | 82.4 | 69.9 | 20.0 | 18.5 | 47.7 | |
| Qwen3-4B | 46.2 | 76.5 | 64.8 | 13.3 | 15.1 | 43.2 | |
| Qwen3-1.7B | 40.0 | 68.6 | 46.3 | 3.3 | 11.6 | 34.0 | |
| Qwen3-0.6B | 37.5 | 37.3 | 37.9 | 3.3 | 3.7 | 23.9 |
表30:韩语(ko)基准测试得分。最高和次高得分分别以粗体和下划线表示。
| 模型 | MLogiQA | INCLUDE | MMMLU | MT-AIME2024 | PolyMath | 平均 | |
|---|---|---|---|---|---|---|---|
| 思维模式 | Gemini2.5-Pro | 75.0 | 88.0 | 85.9 | 76.7 | 50.0 | 75.1 |
| QwQ-32B | 76.2 | 72.0 | 81.8 | 60.0 | 40.0 | 66.0 | |
| Qwen3-235B-A22B | 71.2 | 80.0 | 84.7 | 80.0 | 55.7 | 74.3 | |
| Qwen3-32B | 71.2 | 74.0 | 79.2 | 80.0 | 48.5 | 70.6 | |
| Qwen3-30B-A3B | 68.8 | 72.0 | 78.6 | 76.7 | 46.6 | 68.5 | |
| Qwen3-14B | 67.5 | 74.0 | 79.6 | 76.7 | 46.0 | 68.8 | |
| Qwen3-8B | 60.0 | 80.0 | 74.7 | 76.7 | 42.3 | 66.7 | |
| Qwen3-4B | 66.2 | 74.0 | 68.8 | 70.0 | 40.6 | 63.9 | |
| Qwen3-1.7B | 53.8 | 66.0 | 57.8 | 43.3 | 25.2 | 49.2 | |
| Qwen3-0.6B | 33.8 | 52.0 | 41.5 | 13.3 | 11.8 | 30.5 | |
| 非思维模式 | GPT-4o-2024-1120 | 63.7 | 80.0 | 80.5 | 13.3 | 12.9 | 50.1 |
| Gemma-3-27b-IT | 58.8 | 76.0 | 75.9 | 20.0 | 18.3 | 49.8 | |
| Qwen2.5-72B-Instruct | 58.8 | 68.0 | 76.7 | 6.7 | 17.7 | 45.6 | |
| Qwen3-235B-A22B | 63.7 | 76.0 | 79.8 | 33.3 | 27.9 | 56.1 | |
| Qwen3-32B | 60.0 | 74.0 | 77.2 | 26.7 | 21.2 | 51.8 | |
| Qwen3-30B-A3B | 52.5 | 72.0 | 72.5 | 16.7 | 20.7 | 46.9 | |
| Qwen3-14B | 52.5 | 68.0 | 73.3 | 20.0 | 18.7 | 46.5 | |
| Qwen3-8B | 52.5 | 76.0 | 66.5 | 23.3 | 16.3 | 46.9 | |
| Qwen3-4B | 46.2 | 74.0 | 59.9 | 13.3 | 16.6 | 42.0 | |
| Qwen3-1.7B | 48.8 | 58.0 | 46.0 | 6.7 | 9.0 | 33.7 | |
| Qwen3-0.6B | 40.0 | 52.0 | 36.9 | 0.0 | 5.5 | 26.9 |
表31:印尼语(id)基准测试得分。最高和次高得分分别以粗体和下划线表示。
| 模型 | INCLUDE | MMMLU | MT-AIME2024 | PolyMath | 平均 | |
|---|---|---|---|---|---|---|
| 思维 模式 |
Gemini2.5-Pro | 80.0 | 86.3 | 83.3 | 51.3 | 75.2 |
| QwQ-32B | 76.4 | 83.7 | 73.3 | 47.3 | 70.2 | |
| Qwen3-235B-A22B | 80.0 | 87.2 | 80.0 | 53.5 | 75.2 | |
| Qwen3-32B | 80.0 | 82.0 | 76.7 | 45.6 | 71.1 | |
| Qwen3-30B-A3B | 81.8 | 80.4 | 80.0 | 44.9 | 71.8 | |
| Qwen3-14B | 78.2 | 79.6 | 70.0 | 45.3 | 68.3 | |
| Qwen3-8B | 72.7 | 77.7 | 70.0 | 43.8 | 66.0 | |
| Qwen3-4B | 70.9 | 72.3 | 66.7 | 41.2 | 62.8 | |
| Qwen3-1.7B | 63.6 | 61.2 | 36.7 | 26.8 | 47.1 | |
| Qwen3-0.6B | 36.4 | 46.6 | 10.0 | 12.6 | 26.4 | |
| 非思维模式 | GPT-4o-2024-1120 | 80.0 | 81.1 | 10.0 | 14.7 | 46.4 |
| Gemma-3-27b-IT | 76.4 | 75.9 | 13.3 | 22.6 | 47.0 | |
| Qwen2.5-72B-Instruct | 74.5 | 78.8 | 10.0 | 16.6 | 45.0 | |
| Qwen3-235B-A22B | 81.8 | 81.9 | 33.3 | 27.5 | 56.1 | |
| Qwen3-32B | 81.8 | 77.2 | 23.3 | 24.3 | 51.6 | |
| Qwen3-30B-A3B | 70.9 | 76.4 | 30.0 | 25.9 | 50.8 | |
| Qwen3-14B | 70.9 | 74.1 | 26.7 | 24.6 | 49.1 | |
| Qwen3-8B | 78.2 | 69.6 | 20.0 | 21.6 | 47.4 | |
| Qwen3-4B | 67.3 | 66.5 | 13.3 | 19.0 | 41.5 | |
| Qwen3-1.7B | 52.7 | 49.0 | 3.3 | 10.8 | 29.0 | |
| Qwen3-0.6B | 52.7 | 40.0 | 3.3 | 5.1 | 25.3 |
表32:俄语(ru)基准测试得分。最高和次高得分分别以粗体和下划线表示。
| 模型 | Multi-IF | INCLUDE | MT-AIME2024 | PolyMath | 平均 | |
|---|---|---|---|---|---|---|
| 思维 模式 |
Gemini2.5-Pro | 68.1 | 80.4 | 70.0 | 52.3 | 67.7 |
| QwQ-32B | 61.2 | 73.2 | 76.7 | 43.6 | 63.7 | |
| Qwen3-235B-A22B | 62.2 | 80.4 | 80.0 | 53.1 | 68.9 | |
| Qwen3-32B | 62.5 | 73.2 | 63.3 | 46.5 | 61.4 | |
| Qwen3-30B-A3B | 60.7 | 76.8 | 73.3 | 45.4 | 64.0 | |
| Qwen3-14B | 63.6 | 80.4 | 66.7 | 46.4 | 64.3 | |
| Qwen3-8B | 62.9 | 69.6 | 63.3 | 37.7 | 58.4 | |
| Qwen3-4B | 52.8 | 69.6 | 56.7 | 36.6 | 53.9 | |
| Qwen3-1.7B | 37.8 | 46.4 | 20.0 | 22.8 | 31.8 | |
| Qwen3-0.6B | 26.4 | 46.4 | 3.3 | 7.0 | 20.8 | |
| 非思维模式 | GPT-4o-2024-1120 | 52.0 | 80.4 | 20.0 | 13.7 | 41.5 |
| Gemma-3-27b-IT | 57.3 | 71.4 | 23.3 | 21.6 | 43.4 | |
| Qwen2.5-72B-Instruct | 54.1 | 67.9 | 20.0 | 13.3 | 38.8 | |
| Qwen3-235B-A22B | 56.7 | 75.0 | 40.0 | 26.1 | 49.4 | |
| Qwen3-32B | 58.6 | 71.4 | 30.0 | 23.3 | 45.8 | |
| Qwen3-30B-A3B | 58.0 | 73.2 | 30.0 | 21.1 | 45.6 | |
| Qwen3-14B | 60.3 | 71.4 | 26.7 | 24.2 | 45.6 | |
| Qwen3-8B | 59.3 | 58.9 | 20.0 | 22.8 | 40.2 | |
| Qwen3-4B | 46.1 | 58.9 | 13.3 | 17.8 | 34.0 | |
| Qwen3-1.7B | 34.8 | 41.1 | 3.3 | 13.2 | 23.1 | |
| Qwen3-0.6B | 25.5 | 46.4 | 0.0 | 5.8 | 19.4 |
表33:越南语(vi)基准测试得分。最高和次高得分分别以粗体和下划线表示。
| 模型 | MLogiQA | INCLUDE | MT-AIME2024 | PolyMath | 平均 | |
|---|---|---|---|---|---|---|
| 思维 模式 |
Gemini2.5-Pro | 72.5 | 89.1 | 70.0 | 52.1 | 70.9 |
| QwQ-32B | 71.2 | 69.1 | 70.0 | 49.2 | 64.9 | |
| Qwen3-235B-A22B | 75.0 | 87.3 | 83.3 | 55.1 | 75.2 | |
| Qwen3-32B | 67.5 | 81.8 | 83.3 | 44.0 | 69.2 | |
| Qwen3-30B-A3B | 68.8 | 78.2 | 76.7 | 46.1 | 67.4 | |
| Qwen3-14B | 72.5 | 72.7 | 73.3 | 45.8 | 66.1 | |
| Qwen3-8B | 65.0 | 72.7 | 73.3 | 42.9 | 63.5 | |
| Qwen3-4B | 63.7 | 63.6 | 60.0 | 42.2 | 58.6 | |
| Qwen3-1.7B | 52.5 | 60.0 | 30.0 | 26.8 | 42.8 | |
| Qwen3-0.6B | 33.8 | 38.2 | 6.7 | 9.8 | 22.1 | |
| 非思维模式 | GPT-4o-2024-1120 | 57.5 | 81.8 | 10.0 | 13.0 | 40.6 |
| Gemma-3-27b-IT | 52.5 | 74.5 | 33.3 | 20.6 | 45.2 | |
| Qwen2.5-72B-Instruct | 61.3 | 72.7 | 26.7 | 18.6 | 44.8 | |
| Qwen3-235B-A22B | 70.0 | 83.6 | 36.7 | 27.1 | 54.4 | |
| Qwen3-32B | 60.0 | 81.8 | 23.3 | 21.8 | 46.7 | |
| Qwen3-30B-A3B | 52.5 | 81.8 | 20.0 | 24.7 | 44.8 | |
| Qwen3-14B | 63.7 | 67.3 | 20.0 | 21.6 | 43.2 | |
| Qwen3-8B | 48.8 | 65.5 | 20.0 | 19.1 | 38.4 | |
| Qwen3-4B | 48.8 | 65.5 | 20.0 | 19.0 | 38.3 | |
| Qwen3-1.7B | 36.2 | 60.0 | 3.3 | 10.9 | 27.6 | |
| Qwen3-0.6B | 30.0 | 36.4 | 3.3 | 3.9 | 18.4 |
表34:德语(de)基准测试得分。最高和次高得分分别以粗体和下划线表示。
| 模型 | INCLUDE | MMMLU | MT-AIME2024 | PolyMath | 平均 | |
|---|---|---|---|---|---|---|
| 思维 模式 |
Gemini2.5-Pro | 50.0 | 85.6 | 86.7 | 53.8 | 69.0 |
| QwQ-32B | 57.1 | 83.8 | 76.7 | 51.0 | 67.2 | |
| Qwen3-235B-A22B | 71.4 | 86.0 | 83.3 | 55.4 | 74.0 | |
| Qwen3-32B | 64.3 | 81.9 | 86.7 | 48.1 | 70.2 | |
| Qwen3-30B-A3B | 64.3 | 81.9 | 80.0 | 46.6 | 68.2 | |
| Qwen3-14B | 57.1 | 80.9 | 70.0 | 48.1 | 64.0 | |
| Qwen3-8B | 64.3 | 78.1 | 66.7 | 43.6 | 63.2 | |
| Qwen3-4B | 57.1 | 74.0 | 73.3 | 43.1 | 61.9 | |
| Qwen3-1.7B | 64.3 | 63.4 | 36.7 | 26.8 | 47.8 | |
| Qwen3-0.6B | 57.1 | 47.6 | 10.0 | 13.7 | 32.1 | |
| 非思维模式 | GPT-4o-2024-1120 | 57.1 | 80.4 | 10.0 | 13.5 | 40.2 |
| Gemma-3-27b-IT | 57.1 | 76.1 | 26.7 | 20.2 | 45.0 | |
| Qwen2.5-72B-Instruct | 64.3 | 79.9 | 16.7 | 19.3 | 45.0 | |
| Qwen3-235B-A22B | 71.4 | 81.7 | 40.0 | 25.9 | 54.8 | |
| Qwen3-32B | 57.1 | 77.2 | 30.0 | 21.9 | 46.6 | |
| Qwen3-30B-A3B | 57.1 | 77.7 | 23.3 | 25.2 | 45.8 | |
| Qwen3-14B | 57.1 | 76.0 | 30.0 | 24.5 | 46.9 | |
| Qwen3-8B | 64.3 | 70.8 | 20.0 | 19.9 | 43.8 | |
| Qwen3-4B | 64.3 | 66.0 | 26.7 | 16.4 | 43.4 | |
| Qwen3-1.7B | 42.9 | 53.2 | 10.0 | 10.6 | 29.2 | |
| Qwen3-0.6B | 42.9 | 37.8 | 3.3 | 5.7 | 22.4 |
表35:泰语(th)基准测试得分。最高和次高得分分别以粗体和下划线表示。
| 模型 | MLogiQA | MT-AIME2024 | PolyMath | 平均 | |
|---|---|---|---|---|---|
| 思维 模式 |
Gemini2.5-Pro | 73.8 | 80.0 | 50.7 | 68.2 |
| QwQ-32B | 75.0 | 60.0 | 41.3 | 58.8 | |
| Qwen3-235B-A22B | 73.8 | 86.7 | 53.6 | 71.4 | |
| Qwen3-32B | 73.8 | 76.7 | 46.9 | 65.8 | |
| Qwen3-30B-A3B | 63.7 | 80.0 | 45.2 | 63.0 | |
| Qwen3-14B | 65.0 | 76.7 | 44.4 | 62.0 | |
| Qwen3-8B | 68.8 | 70.0 | 41.3 | 60.0 | |
| Qwen3-4B | 60.0 | 60.0 | 39.4 | 53.1 | |
| Qwen3-1.7B | 48.8 | 33.3 | 23.7 | 35.3 | |
| Qwen3-0.6B | 33.8 | 13.3 | 11.4 | 19.5 | |
| 非思维模式 | GPT-4o-2024-1120 | 52.5 | 10.0 | 11.9 | 24.8 |
| Gemma-3-27b-IT | 50.0 | 16.7 | 19.0 | 28.6 | |
| Qwen2.5-72B-Instruct | 58.8 | 6.7 | 17.4 | 27.6 | |
| Qwen3-235B-A22B | 61.3 | 23.3 | 27.6 | 37.4 | |
| Qwen3-32B | 61.3 | 13.3 | 22.2 | 32.3 | |
| Qwen3-30B-A3B | 50.0 | 30.0 | 22.3 | 34.1 | |
| Qwen3-14B | 47.5 | 23.3 | 22.1 | 31.0 | |
| Qwen3-8B | 42.5 | 10.0 | 17.2 | 23.2 | |
| Qwen3-4B | 43.8 | 13.3 | 16.1 | 24.4 | |
| Qwen3-1.7B | 42.5 | 6.7 | 9.5 | 19.6 | |
| Qwen3-0.6B | 37.5 | 0.0 | 3.6 | 13.7 |
表36:Qwen3支持的Belebele基准测试语言族和语言代码
| 语言族 | # 语言 | 语言代码 (ISO 639-3_ISO 15924) | | | | | | | | |
| :–: | :–: | :–: | :–: | :–: | :–: | :–: | :–: | :–: | :–: |
| | | por_Latn, deu_Latn, tgk_cyrl, ces_latn, nob_latn, dan_latn, snd_arab, spa_latn, isl_latn, slv_latn, eng_latn, ory_orya, hrv_latn, ell_grek, ukr_cyrl, pan_guru, | | | | | | | |
| 印欧语系 | 40 | srp_cyrl, npi_deva, mkd_cyrl, guj_gujr, nld_latn, swe_latn, hin_deva, rus_cyrl, asm_beng, cat_latn, als_latn, sin_sinh, urd_arab, mar_deva, lit_latn, slk_latn, ita_latn, pol_latn, bul_cyrl, afr_latn, ron_latn, fra_latn, ben_beng, hye_armn | | | | | | | |
| 汉藏语系 | 3 | zho_Hans, mya_Mymr, zho_Hant | | | | | | | | |
| 亚非语系 | 8 | heb_hebr, apc_arab, acm_arab, ary_arab, ars_arab, arb_arab, mlt_latn, erz_arab | | | | | | | |
| 南岛语系 | 7 | ilo_latn, ceb_latn, tgl_latn, sun_latn, jav_latn, war_latn, ind_latn | | | | | | | | |
| 德拉威达语系 | 4 | mal_mlym, kan_knda, tel_telu, tam_taml | | | | | | | | |
| 突厥语系 | 4 | kaz_cyrl, azj_latn, tur_latn, uzn_latn | | | | | | | | |
| 台-卡岱语系 | 2 | tha_thai, lao_laoo | | | | | | | | |
| 乌拉尔语系 | 3 | fin_latn, hun_latn, est_latn | | | | | | | | |
| 南亚语系 | 2 | vie_latn, khm_khmr | | | | | | | | |
| 其他 | 7 | eus_latn, kor_hang, hat_latn, swh_latn, kea_latn, jpn_jpan, kat_geor | | | | | | | | |
表37:Qwen3与其他基线模型在Belebele基准测试中的性能比较。分数以最高分加粗、次高分加下划线显示。
| 模型 | 印欧语系 | 汉藏语系 | 亚非语系 | 南岛语系 | 德拉威达语系 | 突厥语系 | 台-卡岱语系 | 乌拉尔语系 | 南亚语系 | 其他 |
|---|---|---|---|---|---|---|---|---|---|---|
| Gemma-3-27B-IT | 89.2 | 86.3 | 85.9\mathbf{85.9}85.9 | 84.1 | 83.5 | 86.8 | 81.0 | 91.0 | 86.5 | 87.0\mathbf{87.0}87.0 |
| Qwen2.5-32B-Instruct | 85.5 | 82.3 | 80.4 | 70.6 | 67.8 | 80.8 | 74.5 | 87.0 | 79.0 | 72.6 |
| QwQ-32B | 86.1 | 83.7 | 81.9 | 71.3 | 69.3 | 80.3 | 77.0 | 88.0 | 83.0 | 74.0 |
| Qwen3-32B (思考) | 90.7\mathbf{90.7}90.7 | 89.7\mathbf{89.7}89.7 | 84.8 | 86.7\mathbf{86.7}86.7 | 84.5\mathbf{84.5}84.5 | 89.3\mathbf{89.3}89.3 | 83.5 | 91.3\mathbf{91.3}91.3 | 88.0\mathbf{88.0}88.0 | 83.1 |
| Qwen3-32B (非思考) | 89.1 | 88.0 | 82.3 | 83.7 | 84.0 | 85.0 | 85.0\mathbf{85.0}85.0 | 88.7 | 88.0\mathbf{88.0}88.0 | 81.3 |
| Gemma-3-12B-IT | 85.8 | 83.3 | 83.4\mathbf{83.4}83.4 | 79.3 | 79.0 | 82.8 | 77.5 | 89.0 | 83.0\mathbf{83.0}83.0 | 81.6 |
| Qwen2.5-14B-Instruct | 82.7 | 78.9 | 80.4 | 69.1 | 66.2 | 74.2 | 72.2 | 83.9 | 77.9 | 70.4 |
| Qwen3-14B (思考) | 88.6\mathbf{88.6}88.6 | 87.3\mathbf{87.3}87.3 | 82.4 | 82.4\mathbf{82.4}82.4 | 81.0\mathbf{81.0}81.0 | 83.8\mathbf{83.8}83.8 | 83.5\mathbf{83.5}83.5 | 91.0\mathbf{91.0}91.0 | 82.5 | 81.7\mathbf{81.7}81.7 |
| Qwen3-14B (非思考) | 87.4 | 82.7 | 80.1 | 80.7 | 78.0 | 81.8 | 80.5 | 87.7 | 81.5 | 77.0 |
| Gemma-3-4B-IT | 71.8 | 72.0 | 63.5 | 61.7 | 64.8 | 64.0 | 61.5 | 70.7 | 71.0 | 62.6 |
| Qwen2.5-3B-Instruct | 58.0 | 62.3 | 57.2 | 47.9 | 36.9 | 45.1 | 49.8 | 50.6 | 56.8 | 48.4 |
| Qwen3-4B (思考) | 82.2\mathbf{82.2}82.2 | 77.7\mathbf{77.7}77.7 | 74.1 | 73.0\mathbf{73.0}73.0 | 74.3 | 76.3 | 68.5 | 83.0 | 74.5 | 67.9 |
| Qwen3-4B (非思考) | 76.0 | 77.0 | 65.6 | 65.6 | 65.5 | 64.0 | 60.5 | 74.0 | 74.0 | 61.0 |
| Gemma-3-1B-IT | 36.5 | 36.0 | 30.0 | 29.1 | 28.8 | 27.3 | 28.0 | 32.7 | 33.0 | 30.9 |
| Qwen2.5-1.5B-Instruct | 41.5 | 43.0 | 39.6 | 34.8 | 28.6 | 29.7 | 39.4 | 33.8 | 42.0 | 36.0 |
| Qwen3-1.7B (思考) | 69.7\mathbf{69.7}69.7 | 66.0\mathbf{66.0}66.0 | 59.4 | 58.6\mathbf{58.6}58.6 | 52.8\mathbf{52.8}52.8 | 57.8\mathbf{57.8}57.8 | 53.5\mathbf{53.5}53.5 | 70.3\mathbf{70.3}70.3 | 63.5\mathbf{63.5}63.5 | 53.4\mathbf{53.4}53.4 |
| Qwen3-1.7B (非思考) | 58.8 | 62.7 | 50.8 | 53.0 | 43.3 | 48.0 | 46.0 | 54.3 | 54.0 | 43.9 |
| 表37:Qwen3与其他基线模型在Belebele基准测试中的性能比较。分数以最高分加粗,次高分加下划线。 |
| 模型 | 印欧语系 | 汉藏语系 | 亚非语系 | 南岛语系 | 德拉威达语系 | 突厥语系 | 台-卡岱语系 | 乌拉尔语系 | 南亚语系 | 其他 |
|---|---|---|---|---|---|---|---|---|---|---|
| Gemma-3-27B-IT | 89.2 | 86.3 | 85.9\mathbf{85.9}85.9 | 84.1 | 83.5 | 86.8 | 81.0 | 91.0 | 86.5 | 87.0\mathbf{87.0}87.0 |
| Qwen2.5-32B-Instruct | 85.5 | 82.3 | 80.4 | 70.6 | 67.8 | 80.8 | 74.5 | 87.0 | 79.0 | 72.6 |
| QwQ-32B | 86.1 | 83.7 | 81.9 | 71.3 | 69.3 | 80.3 | 77.0 | 88.0 | 83.0 | 74.0 |
| Qwen3-32B (思考) | 90.7\mathbf{90.7}90.7 | 89.7\mathbf{89.7}89.7 | 84.8 | 86.7\mathbf{86.7}86.7 | 84.5\mathbf{84.5}84.5 | 89.3\mathbf{89.3}89.3 | 83.5 | 91.3\mathbf{91.3}91.3 | 88.0\mathbf{88.0}88.0 | 83.1 |
| Qwen3-32B (非思考) | 89.1 | 88.0 | 82.3 | 83.7 | 84.0 | 85.0 | 85.0\mathbf{85.0}85.0 | 88.7 | 88.0\mathbf{88.0}88.0 | 81.3 |
| Gemma-3-12B-IT | 85.8 | 83.3 | 83.4\mathbf{83.4}83.4 | 79.3 | 79.0 | 82.8 | 77.5 | 89.0 | 83.0\mathbf{83.0}83.0 | 81.6 |
| Qwen2.5-14B-Instruct | 82.7 | 78.9 | 80.4 | 69.1 | 66.2 | 74.2 | 72.2 | 83.9 | 77.9 | 70.4 |
| Qwen3-14B (思考) | 88.6\mathbf{88.6}88.6 | 87.3\mathbf{87.3}87.3 | 82.4 | 82.4\mathbf{82.4}82.4 | 81.0\mathbf{81.0}81.0 | 83.8\mathbf{83.8}83.8 | 83.5\mathbf{83.5}83.5 | 91.0\mathbf{91.0}91.0 | 82.5 | 81.7\mathbf{81.7}81.7 |
| Qwen3-14B (非思考) | 87.4 | 82.7 | 80.1 | 80.7 | 78.0 | 81.8 | 80.5 | 87.7 | 81.5 | 77.0 |
| Gemma-3-4B-IT | 71.8 | 72.0 | 63.5 | 61.7 | 64.8 | 64.0 | 61.5 | 70.7 | 71.0 | 62.6 |
| Qwen2.5-3B-Instruct | 58.0 | 62.3 | 57.2 | 47.9 | 36.9 | 45.1 | 49.8 | 50.6 | ------ | |
| 56.8 | 48.4 | |||||||||
| Qwen3-4B (思考) | 82.2\mathbf{82.2}82.2 | 77.7\mathbf{77.7}77.7 | 74.1 | 73.0\mathbf{73.0}73.0 | 74.3 | |||||
| 76.3 | 68.5 | 83.0 | 74.5 | 67.9 | ||||||
| Qwen3-4B (非思考) | 76.0 | 77.0 | 65.6 | 65.6 | 65.5 | 64.0 | 60.5 | |||
| ------ | 74.0 | 74.0 | 61.0 | |||||||
| Gemma-3-1B-IT | 36.5 | 36.0 | 30.0 | 29.1 | 28.8 | 27.3 | 28.0 | 32.7 | 33.0 | 30.9 |
| Qwen2.5-1.5B-Instruct | 41.5 | 43.0 | 39.6 | 34.8 | 28.6 | 29.7 | 39.4 | 33.8 | 42.0 | 36.0 |
| Qwen3-1.7B (思考) | 69.7\mathbf{69.7}69.7 | 66.0\mathbf{66.0}66.0 | 59.4 | 58.6\mathbf{58.6}58.6 | 52.8\mathbf{52.8}52.8 | 57.8\mathbf{57.8}57.8 | 53.5\mathbf{53.5}53.5 | 70.3\mathbf{70.3}70.3 | 63.5\mathbf{63.5}63.5 | 53.4\mathbf{53.4}53.4 |
| Qwen3-1.7B (非思考) | 58.8 | 62.7 | 50.8 | 53.0 | 43.3 | 48.0 | 46.0 | 54.3 | 54.0 | 43.9 |
参考论文:https://arxiv.org/pdf/2505.09388

欢迎加入DeepSeek 技术社区。在这里,你可以找到志同道合的朋友,共同探索AI技术的奥秘。
更多推荐
 20
20 0
0- 0



 已为社区贡献80条内容
已为社区贡献80条内容

所有评论(0)