千问qwen系列模型统计
通义千问(Qwen)系列模型自2023年起陆续发布,涵盖文本、视觉语言、全模态以及专用模型等多个类别。以下按发布时间由远及近对主要模型进行归纳,并附上参数规模、核心特性与技术要点。以上统计覆盖了截至 2025 年 11 月已发布的通义千问系列主要模型,包括文本、图像、多模态、视频等类型,并按发布时间线由远及近展开。所有信息均基于官方公告、技术报告与开源文档。以下图表展示了各系列模型的参数规模(单位
·
通义千问(Qwen)系列模型自2023年起陆续发布,涵盖文本、视觉语言、全模态以及专用模型等多个类别。以下按发布时间由远及近对主要模型进行归纳,并附上参数规模、核心特性与技术要点。
1. 早期文本模型(2023年)
- Qwen-1.8B/7B/14B/72B
- 参数规模:1.8B、7B、14B、72B
- 核心特性:中文预训练、支持多语言、基础对话与生成能力
- 技术要点:Transformer 解码器架构,训练数据约 3 万亿 token
2. 视觉语言模型(2024年)
- Qwen-VL(2B/7B/72B)
- 参数规模:2B、7B、72B
- 核心特性:视觉‑语言多模态,支持图像理解与问答
- 技术要点:跨模态注意力机制,实现图文联合理解[[2]]
3. Qwen1.5 系列(2024年)
- Qwen1.5(0.5B/1.8B/4B/7B/14B/72B/110B)
- 参数规模:0.5B‑110B
- 核心特性:大幅提升多语言支持、代码与数学能力,上下文长度最高 32K(110B)
- 技术要点:Transformer 改进、分组查询注意力(GQA)等[[3]][[4]]
- Qwen1.5-MoE(7B)
- 参数规模:7B(激活参数约 1/3)
- 核心特性:混合专家结构,在同等计算成本下保持高性能
- 技术要点:Mixture-of-Experts(MoE)架构[[5]]
4. Qwen2 系列(2024年)
- Qwen2(0.5B/1.5B/7B/57B‑A14B/72B)
- 参数规模:0.5B‑72B(57B‑A14B 为稀疏激活 MoE)
- 核心特性:支持 27 种语言,上下文最长 128K(72B‑Instruct),代码与推理能力显著提升
- 技术要点:Transformer 升级、MoE 设计(57B‑A14B)[[6]][[7]]
5. Qwen2.5 系列(2025年)
- Qwen2.5(0.5B/1.5B/3B/7B/14B/32B/72B)
- 参数规模:0.5B‑72B
- 核心特性:全系列多语言增强,长上下文优化
- 技术要点:持续架构优化,更高吞吐与更低延迟[[8]]
- Qwen2.5-Omni-7B
- 参数规模:7B
- 核心特性:端到端全模态,可同时处理文本、图像、音频、视频并生成语音
- 技术要点:Thinker‑Talker 双核架构、Position Embedding 融合、TMRoPE 位置编码[[9]]
- Qwen2.5-Math
- 核心特性:专用数学推理,支持 LaTeX 公式、分步推导
- 技术要点:定制系统提示与推理机制[[10]]
- Qwen2.5-VL
- 核心特性:视觉语言模型,提升图像理解与对话能力
- 技术要点:跨模态注意力升级[[11]]
6. Qwen3 系列(2025年)
- Qwen3(0.6B/1.7B/4B/8B/14B/32B)
- 参数规模:0.6B‑32B(稠密模型)
- 核心特性:基础语言理解与生成,适用于轻量部署
- 技术要点:标准 Transformer 结构[[12]]
- Qwen3-30B-A3B / Qwen3-235B-A22B
- 参数规模:30B(激活 3B)、235B(激活 22B)
- 核心特性:混合专家模型,在多项基准超越同类开源模型
- 技术要点:MoE 架构,支持多种推理模式(思考‑加速平衡)[[13]][[14]]
- Qwen3-4B-Instruct-2507 / Qwen3-4B-Thinking-2507
- 参数规模:4B
- 核心特性:指令微调与思考模式,支持 256K 长上下文,推理能力接近中等模型
- 技术要点:长上下文优化、思考链增强[[15]]
模型参数规模对比图
以下图表展示了各系列模型的参数规模(单位:B)及其类别(文本、MoE、多模态、全模态、专用)。
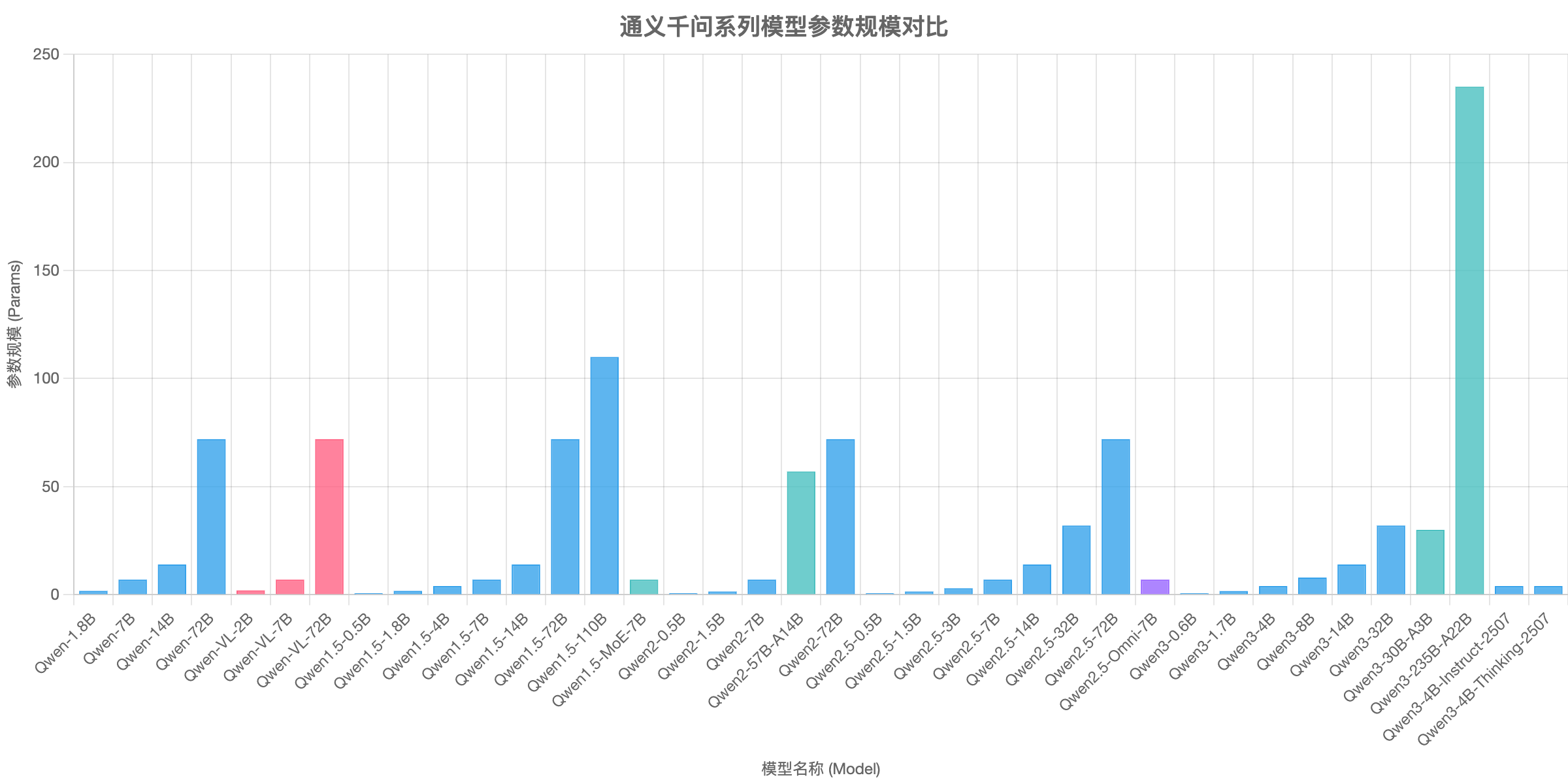
以上统计覆盖了截至 2025 年 11 月已发布的通义千问系列主要模型,包括文本、图像、多模态、视频等类型,并按发布时间线由远及近展开。所有信息均基于官方公告、技术报告与开源文档。

欢迎加入DeepSeek 技术社区。在这里,你可以找到志同道合的朋友,共同探索AI技术的奥秘。
更多推荐



 13
13 0
0- 0



 已为社区贡献5条内容
已为社区贡献5条内容

所有评论(0)