【AI Agent实战】手把手教你用 LangGraph + 通义千问打造“深思熟虑”的智能投研助手
📖 前言:从“快思考”到“慢思考”
在 AI Agent(智能体)的开发中,我们常听到诺贝尔奖得主丹尼尔·卡尼曼提出的 “System 1” (快思考) 和 “System 2” (慢思考) 概念。
- System 1 (直觉):像 ChatGPT 的直接问答,反应快,但容易产生幻觉,缺乏深度。
- System 2 (逻辑):像人类专家一样,需要搜集信息 -> 建立模型 -> 多角度推演 -> 慎重决策 -> 撰写报告。
在金融投研、法律咨询、医疗诊断等严肃场景下,我们显然需要 System 2。
本文将带你深入解析一个基于 LangGraph 和 通义千问 (Qwen-Max) 实现的 “深思熟虑智能体 (Deliberative Agent)”。它不急于回答问题,而是通过五步严谨的思维链,生成高质量的投研报告。
🏗️ 核心架构:像人类分析师一样思考
这个智能体的核心设计理念是 “Chain of Thought” (思维链) 的工程化落地。我们将其拆解为五个独立的认知阶段,通过图(Graph)结构进行编排。
1. 架构流程图 (Mermaid)
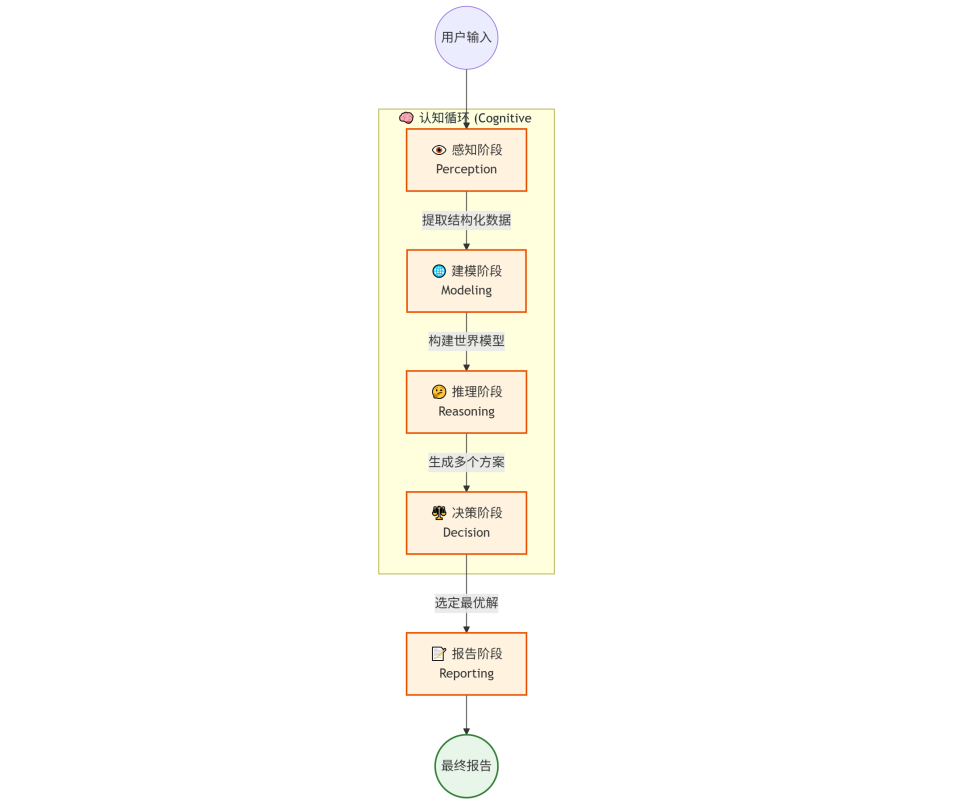
2. 技术栈选型
- LangGraph: 核心编排框架。相比 LangChain 的 Chain,LangGraph 支持循环 (Cycles)、状态持久化和更复杂的图结构,非常适合构建复杂的 Agent。
- Tongyi (Qwen-Max): 阿里云通义千问大模型。在长文本理解和逻辑推理方面表现优异,且 API 成本相对可控。
- Pydantic: 数据验证库。用于定义严格的输入输出格式 (Schema),防止大模型“胡言乱语”,确保流程稳定性。
💻 代码实现深度拆解
我们将 200 多行代码拆解为三个核心部分来讲解。
第一步:定义智能体的“大脑内存” (State)
在 LangGraph 中,State 是所有节点共享的上下文。它就像一个接力棒,在不同的处理阶段中传递。
class ResearchAgentState(TypedDict):
"""研究智能体的状态总线"""
# === 1. 原始输入 ===
research_topic: str # 例如:"新能源汽车"
industry_focus: str # 例如:"固态电池"
time_horizon: str # 例如:"中期"
# === 2. 中间思维产物 (逐步填充) ===
perception_data: Optional[Dict] # 阶段1:搜集到的新闻数据
world_model: Optional[Dict] # 阶段2:总结出的市场模型
reasoning_plans: Optional[List] # 阶段3:发散出的A/B/C三个方案
selected_plan: Optional[Dict] # 阶段4:最终拍板的方案
# === 3. 最终输出 ===
final_report: Optional[str] # 阶段5:生成的文章
# === 4. 流程控制 ===
current_phase: str # 当前走到哪一步了
第二步:核心认知节点的实现
1. 感知与建模 (Perception & Modeling)
这两个阶段负责将非结构化的数据转化为结构化的认知。
- 技巧:使用了
JsonOutputParser和 Pydantic 定义的BaseModel。 - 作用:强制大模型输出 JSON。例如,
ModelingOutput包含market_state(市场状态) 和risk_factors(风险因子)。如果模型输出格式不对,LangChain 会报错或重试。
2. 推理与决策 (Reasoning & Decision) —— 🌟 全文最精彩的设计
这是模拟人类**从“发散”到“收敛”**的思考过程。
-
推理 (Reasoning):
- Prompt 策略:要求 LLM 生成 3个不同的分析方案,并分别计算置信度。
- 比喻:就像在一个会议室里,不同的分析师提出了激进、保守、中立三种策略。
# 代码片段:要求生成列表 class ReasoningPlan(BaseModel): plan_id: str hypothesis: str # 假设 confidence_level: float # 置信度 pros: List[str] # 优点 cons: List[str] # 缺点 -
决策 (Decision):
- Prompt 策略:扮演“投委会主席”。审视上面 3 个方案,综合评估风险收益比,选出最优解。
- 价值:这种 Self-Reflection (自我反思) 机制极大地减少了幻觉,提高了逻辑严密性。
第三步:工作流编排 (Graph Construction)
最后,我们用 LangGraph 将这些孤立的函数串联起来。
def create_research_agent_workflow() -> StateGraph:
# 1. 初始化图
workflow = StateGraph(ResearchAgentState)
# 2. 注册节点 (将函数绑定到节点名)
workflow.add_node("perception", perception)
workflow.add_node("modeling", modeling)
workflow.add_node("reasoning", reasoning)
workflow.add_node("decision", decision)
workflow.add_node("report", report_generation)
# 3. 定义流转逻辑 (Edge)
# 入口 -> 感知 -> 建模 -> 推理 -> 决策 -> 报告 -> 结束
workflow.set_entry_point("perception")
workflow.add_edge("perception", "modeling")
workflow.add_edge("modeling", "reasoning")
workflow.add_edge("reasoning", "decision")
workflow.add_edge("decision", "report")
workflow.add_edge("report", END)
return workflow.compile()
📊 运行效果模拟
假设我们运行脚本,输入以下参数:
- 主题: 低空经济
- 行业: eVTOL (电动垂直起降飞行器)
- 周期: 长期
智能体思考过程日志:
- [感知]: 搜集到“政策利好”、“亿航智能取证”、“电池续航瓶颈”等信息。
- [建模]: 判断当前处于“商业化导入期”,技术成熟度曲线爬坡阶段,市场情绪高昂但存在泡沫。
- [推理]: 提出了三个方案:
- Plan A: 激进做多整机制造龙头(高风险)。
- Plan B: 布局上游碳纤维和固态电池(卖铲子策略,中风险)。
- Plan C: 观望,等待基础设施完善(低风险)。
- [决策]: 选中 Plan B。理由:整机竞争格局未定,但上游材料确定性更强,且符合“长期”的时间框架。
- [报告]: 生成了一篇 3000 字的深度研报,详细阐述了为何选择布局上游材料链。
💡 总结与设计优势
为什么我们要花这么大力气写这么多代码,而不是直接问 ChatGPT?
-
结构化思维 (Structured Thinking):
避免了 LLM 的“意识流”输出。通过强制分步骤,我们保证了每一步的质量。如果“感知”阶段数据不足,流程可以报错或重试,而不会将错误传递到最后。 -
自我纠错 (Self-Correction):
通过 “推理 -> 决策” 的分离,让 AI 自己评估自己的想法。这比单次生成的准确率要高得多。 -
模块化与可扩展性:
基于 LangGraph 的图结构,我们可以轻松升级。比如:- 想加入 Google 搜索?只需修改
perception节点。 - 想加入人工审核?只需在
report之前插一个human_node。
- 想加入 Google 搜索?只需修改
-
完整代码:
#!/usr/bin/env python
# -*- coding: utf-8 -*-
"""
深思熟虑智能体(Deliberative Agent)- 智能投研助手
基于LangGraph实现的深思熟虑型智能体,适用于投资研究场景,能够整合数据,
进行多步骤分析和推理,生成投资观点和研究报告。
核心流程:
1. 感知:收集市场数据和信息
2. 建模:构建内部世界模型,理解市场状态
3. 推理:生成多个候选分析方案并模拟结果
4. 决策:选择最优投资观点并形成报告
5. 报告:生成完整研究报告
"""
import os
import json
from typing import Dict, List, Any, Literal, TypedDict, Optional, Union, Tuple
from datetime import datetime
from langchain_core.prompts import ChatPromptTemplate
from langchain_community.llms import Tongyi
from langchain_core.output_parsers import StrOutputParser, JsonOutputParser
from langgraph.graph import StateGraph, END
from pydantic.v1 import BaseModel, Field
# 设置API密钥
DASHSCOPE_API_KEY = os.environ.get("DASHSCOPE_API_KEY")
# 创建LLM实例
llm = Tongyi(model_name="qwen3-max", dashscope_api_key=DASHSCOPE_API_KEY)
# 定义输出模型
class PerceptionOutput(BaseModel):
"""感知阶段输出的市场数据和信息"""
market_overview: str = Field(..., description="市场概况和最新动态")
key_indicators: Dict[str, str] = Field(..., description="关键经济和市场指标")
recent_news: List[str] = Field(..., description="近期重要新闻")
industry_trends: Dict[str, str] = Field(..., description="行业趋势分析")
class ModelingOutput(BaseModel):
"""建模阶段输出的内部世界模型"""
market_state: str = Field(..., description="当前市场状态评估")
economic_cycle: str = Field(..., description="经济周期判断")
risk_factors: List[str] = Field(..., description="主要风险因素")
opportunity_areas: List[str] = Field(..., description="潜在机会领域")
market_sentiment: str = Field(..., description="市场情绪分析")
class ReasoningPlan(BaseModel):
"""推理阶段生成的候选分析方案"""
plan_id: str = Field(..., description="方案ID")
hypothesis: str = Field(..., description="投资假设")
analysis_approach: str = Field(..., description="分析方法")
expected_outcome: str = Field(..., description="预期结果")
confidence_level: float = Field(..., description="置信度(0-1)")
pros: List[str] = Field(..., description="方案优势")
cons: List[str] = Field(..., description="方案劣势")
class DecisionOutput(BaseModel):
"""决策阶段选择的最优投资观点"""
selected_plan_id: str = Field(..., description="选中的方案ID")
investment_thesis: str = Field(..., description="投资论点")
supporting_evidence: List[str] = Field(..., description="支持证据")
risk_assessment: str = Field(..., description="风险评估")
recommendation: str = Field(..., description="投资建议")
timeframe: str = Field(..., description="时间框架")
# 定义智能体状态
class ResearchAgentState(TypedDict):
"""研究智能体的状态"""
# 输入
research_topic: str # 研究主题
industry_focus: str # 行业焦点
time_horizon: str # 时间范围(短期/中期/长期)
# 处理状态
perception_data: Optional[Dict[str, Any]] # 感知阶段收集的数据
world_model: Optional[Dict[str, Any]] # 内部世界模型
reasoning_plans: Optional[List[Dict[str, Any]]] # 候选分析方案
selected_plan: Optional[Dict[str, Any]] # 选中的最优方案
# 输出
final_report: Optional[str] # 最终研究报告
# 控制流
current_phase: Literal["perception", "modeling", "reasoning", "decision", "report"]
error: Optional[str] # 错误信息
# 提示模板
PERCEPTION_PROMPT = """你是一个专业的投资研究分析师,请收集和整理关于以下研究主题的市场数据和信息:
研究主题: {research_topic}
行业焦点: {industry_focus}
时间范围: {time_horizon}
请从以下几个方面进行市场感知:
1. 市场概况和最新动态
2. 关键经济和市场指标
3. 近期重要新闻(至少3条)
4. 行业趋势分析(至少针对3个细分领域)
根据你的专业知识和经验,提供尽可能详细和准确的信息。
输出格式要求为JSON,包含以下字段:
- market_overview: 字符串
- key_indicators: 字典,键为指标名称,值为指标值和简要解释
- recent_news: 字符串列表,每项为一条重要新闻
- industry_trends: 字典,键为细分领域,值为趋势分析
"""
MODELING_PROMPT = """你是一个资深投资策略师,请根据以下市场数据和信息,构建市场内部模型,进行深度分析:
研究主题: {research_topic}
行业焦点: {industry_focus}
时间范围: {time_horizon}
市场数据和信息:
{perception_data}
请构建一个全面的市场内部模型,包括:
1. 当前市场状态评估
2. 经济周期判断
3. 主要风险因素(至少3个)
4. 潜在机会领域(至少3个)
5. 市场情绪分析
输出格式要求为JSON,包含以下字段:
- market_state: 字符串
- economic_cycle: 字符串
- risk_factors: 字符串列表
- opportunity_areas: 字符串列表
- market_sentiment: 字符串
"""
REASONING_PROMPT = """你是一个战略投资顾问,请根据以下市场模型,生成3个不同的投资分析方案:
研究主题: {research_topic}
行业焦点: {industry_focus}
时间范围: {time_horizon}
市场内部模型:
{world_model}
请为每个方案提供:
1. 方案ID(简短标识符)
2. 投资假设
3. 分析方法
4. 预期结果
5. 置信度(0-1之间的小数)
6. 方案优势(至少3点)
7. 方案劣势(至少2点)
这些方案应该有明显的差异,代表不同的投资思路或分析角度。
输出格式要求为JSON数组,每个元素包含以下字段:
- plan_id: 字符串
- hypothesis: 字符串
- analysis_approach: 字符串
- expected_outcome: 字符串
- confidence_level: 浮点数
- pros: 字符串列表
- cons: 字符串列表
"""
DECISION_PROMPT = """你是一个投资决策委员会主席,请评估以下候选分析方案,选择最优方案并形成投资决策:
研究主题: {research_topic}
行业焦点: {industry_focus}
时间范围: {time_horizon}
市场内部模型:
{world_model}
候选分析方案:
{reasoning_plans}
请基于方案的假设、分析方法、预期结果、置信度以及优缺点,选择最优的投资方案,并给出详细的决策理由。
你的决策应该综合考虑投资潜力、风险水平和时间框架的匹配度。
输出格式要求为JSON,包含以下字段:
- selected_plan_id: 字符串
- investment_thesis: 字符串
- supporting_evidence: 字符串列表
- risk_assessment: 字符串
- recommendation: 字符串
- timeframe: 字符串
"""
REPORT_PROMPT = """你是一个专业的投资研究报告撰写人,请根据以下信息生成一份完整的投资研究报告:
研究主题: {research_topic}
行业焦点: {industry_focus}
时间范围: {time_horizon}
市场数据和信息:
{perception_data}
市场内部模型:
{world_model}
选定的投资决策:
{selected_plan}
请生成一份结构完整、逻辑清晰的投研报告,包括但不限于:
1. 报告标题和摘要
2. 市场和行业背景
3. 核心投资观点
4. 详细分析论证
5. 风险因素
6. 投资建议
7. 时间框架和预期回报
报告应当专业、客观,同时提供足够的分析深度和洞见。
"""
# 第一阶段:感知 - 收集市场数据和信息
def perception(state: ResearchAgentState) -> ResearchAgentState:
"""感知阶段:收集和整理市场数据和信息"""
print("1. 感知阶段:收集市场数据和信息...")
try:
# 准备提示
prompt = ChatPromptTemplate.from_template(PERCEPTION_PROMPT)
# 构建输入
input_data = {
"research_topic": state["research_topic"],
"industry_focus": state["industry_focus"],
"time_horizon": state["time_horizon"]
}
# 调用LLM
chain = prompt | llm | JsonOutputParser()
result = chain.invoke(input_data)
# 更新状态
return {
**state,
"perception_data": result,
"current_phase": "modeling"
}
except Exception as e:
return {
**state,
"error": f"感知阶段出错: {str(e)}",
"current_phase": "perception" # 保持在当前阶段
}
# 第二阶段:建模 - 构建内部世界模型
def modeling(state: ResearchAgentState) -> ResearchAgentState:
"""建模阶段:构建内部世界模型,理解市场状态"""
print("2. 建模阶段:构建内部世界模型...")
try:
# 确保感知数据已存在
if not state.get("perception_data"):
return {
**state,
"error": "建模阶段缺少感知数据",
"current_phase": "perception" # 回到感知阶段
}
# 准备提示
prompt = ChatPromptTemplate.from_template(MODELING_PROMPT)
# 构建输入
input_data = {
"research_topic": state["research_topic"],
"industry_focus": state["industry_focus"],
"time_horizon": state["time_horizon"],
"perception_data": json.dumps(state["perception_data"], ensure_ascii=False, indent=2)
}
# 调用LLM
chain = prompt | llm | JsonOutputParser()
result = chain.invoke(input_data)
# 更新状态
return {
**state,
"world_model": result,
"current_phase": "reasoning"
}
except Exception as e:
return {
**state,
"error": f"建模阶段出错: {str(e)}",
"current_phase": "modeling" # 保持在当前阶段
}
# 第三阶段:推理 - 生成候选分析方案
def reasoning(state: ResearchAgentState) -> ResearchAgentState:
"""推理阶段:生成多个候选分析方案并模拟结果"""
print("3. 推理阶段:生成候选分析方案...")
try:
# 确保世界模型已存在
if not state.get("world_model"):
return {
**state,
"error": "推理阶段缺少世界模型",
"current_phase": "modeling" # 回到建模阶段
}
# 准备提示
prompt = ChatPromptTemplate.from_template(REASONING_PROMPT)
# 构建输入
input_data = {
"research_topic": state["research_topic"],
"industry_focus": state["industry_focus"],
"time_horizon": state["time_horizon"],
"world_model": json.dumps(state["world_model"], ensure_ascii=False, indent=2)
}
# 调用LLM
chain = prompt | llm | JsonOutputParser()
result = chain.invoke(input_data)
# 更新状态
return {
**state,
"reasoning_plans": result,
"current_phase": "decision"
}
except Exception as e:
return {
**state,
"error": f"推理阶段出错: {str(e)}",
"current_phase": "reasoning" # 保持在当前阶段
}
# 第四阶段:决策 - 选择最优方案
def decision(state: ResearchAgentState) -> ResearchAgentState:
"""决策阶段:评估候选方案并选择最优投资观点"""
print("4. 决策阶段:选择最优投资观点...")
try:
# 确保候选方案已存在
if not state.get("reasoning_plans"):
return {
**state,
"error": "决策阶段缺少候选方案",
"current_phase": "reasoning" # 回到推理阶段
}
# 准备提示
prompt = ChatPromptTemplate.from_template(DECISION_PROMPT)
# 构建输入
input_data = {
"research_topic": state["research_topic"],
"industry_focus": state["industry_focus"],
"time_horizon": state["time_horizon"],
"world_model": json.dumps(state["world_model"], ensure_ascii=False, indent=2),
"reasoning_plans": json.dumps(state["reasoning_plans"], ensure_ascii=False, indent=2)
}
# 调用LLM
chain = prompt | llm | JsonOutputParser()
result = chain.invoke(input_data)
# 更新状态
return {
**state,
"selected_plan": result,
"current_phase": "report"
}
except Exception as e:
return {
**state,
"error": f"决策阶段出错: {str(e)}",
"current_phase": "decision" # 保持在当前阶段
}
# 第五阶段:报告 - 生成完整研究报告
def report_generation(state: ResearchAgentState) -> ResearchAgentState:
"""报告阶段:生成完整的投资研究报告"""
print("5. 报告阶段:生成完整研究报告...")
try:
# 确保选定方案已存在
if not state.get("selected_plan"):
return {
**state,
"error": "报告阶段缺少选定方案",
"current_phase": "decision" # 回到决策阶段
}
# 准备提示
prompt = ChatPromptTemplate.from_template(REPORT_PROMPT)
# 构建输入
input_data = {
"research_topic": state["research_topic"],
"industry_focus": state["industry_focus"],
"time_horizon": state["time_horizon"],
"perception_data": json.dumps(state["perception_data"], ensure_ascii=False, indent=2),
"world_model": json.dumps(state["world_model"], ensure_ascii=False, indent=2),
"selected_plan": json.dumps(state["selected_plan"], ensure_ascii=False, indent=2)
}
# 调用LLM
chain = prompt | llm | StrOutputParser()
result = chain.invoke(input_data)
# 更新状态
return {
**state,
"final_report": result,
"current_phase": "completed"
}
except Exception as e:
return {
**state,
"error": f"报告生成阶段出错: {str(e)}",
"current_phase": "report" # 保持在当前阶段
}
# 路由函数 - 根据当前阶段决定下一步
def router(state: ResearchAgentState) -> str:
"""根据当前阶段路由到下一步或结束"""
# 如果有错误,保持在当前阶段
if state.get("error"):
return state["current_phase"]
# 根据当前阶段决定下一步
current = state["current_phase"]
if current == "perception":
return "modeling"
elif current == "modeling":
return "reasoning"
elif current == "reasoning":
return "decision"
elif current == "decision":
return "report"
elif current == "report":
return END
else:
return END
# 创建智能体工作流图
def create_research_agent_workflow() -> StateGraph:
"""创建深思熟虑型研究智能体工作流图"""
# 创建状态图
workflow = StateGraph(ResearchAgentState)
# 添加节点
workflow.add_node("perception", perception)
workflow.add_node("modeling", modeling)
workflow.add_node("reasoning", reasoning)
workflow.add_node("decision", decision)
workflow.add_node("report", report_generation)
# 设置入口点
workflow.set_entry_point("perception")
# 设置边和转换条件
workflow.add_edge("perception", "modeling")
workflow.add_edge("modeling", "reasoning")
workflow.add_edge("reasoning", "decision")
workflow.add_edge("decision", "report")
workflow.add_edge("report", END)
# 编译工作流
return workflow.compile()
# 测试函数
def run_research_agent(topic: str, industry: str, horizon: str) -> Dict[str, Any]:
"""运行研究智能体并返回结果"""
# 创建工作流
agent = create_research_agent_workflow()
# 准备初始状态
initial_state = {
"research_topic": topic,
"industry_focus": industry,
"time_horizon": horizon,
"perception_data": None,
"world_model": None,
"reasoning_plans": None,
"selected_plan": None,
"final_report": None,
"current_phase": "perception",
"error": None
}
print("LangGraph Mermaid流程图:")
print(agent.get_graph().draw_mermaid())
# 运行智能体
result = agent.invoke(initial_state)
return result
# 主函数
if __name__ == "__main__":
print("=== 深思熟虑智能体 - 智能投研助手 ===\n")
print("使用模型:qwen3-max\n")
# 用户输入
topic = input("请输入研究主题 (例如: 新能源汽车行业投资机会): ")
industry = input("请输入行业焦点 (例如: 电动汽车制造、电池技术): ")
horizon = input("请输入时间范围 [短期/中期/长期]: ")
print("\n智能投研助手开始工作...\n")
try:
# 运行智能体
result = run_research_agent(topic, industry, horizon)
# 处理结果
if result.get("error"):
print(f"\n发生错误: {result['error']}")
else:
print("\n=== 最终研究报告 ===\n")
print(result.get("final_report", "未生成报告"))
# 保存报告
timestamp = datetime.now().strftime("%Y%m%d_%H%M%S")
filename = f"research_report_{timestamp}.txt"
with open(filename, "w", encoding="utf-8") as f:
f.write(result.get("final_report", "未生成报告"))
print(f"\n报告已保存为: {filename}")
except Exception as e:
print(f"\n运行过程中发生错误: {str(e)}")
👨💻 作者提示:
本文代码基于langgraph和langchain最新版本。在运行前,请确保配置了阿里云 DashScope 的 API Key。

欢迎加入DeepSeek 技术社区。在这里,你可以找到志同道合的朋友,共同探索AI技术的奥秘。
更多推荐

 22
22 0
0- 0



 已为社区贡献1条内容
已为社区贡献1条内容

所有评论(0)