微调豆包大模型:仅用1.03元解决业务问题,经验分享!
本文探讨了如何通过SFT(监督微调)解决大模型输出格式问题。针对业务需求中型号名称被错误添加空格的问题,作者尝试了提示词优化和更换模型方案,最终选择对国产模型Doubao进行微调。文章详细介绍了SFT的原理、适用场景和实施步骤,包括训练集生成、参数配置方法(如epoch、batch_size调整)以及验证集处理策略。通过42条训练数据微调后成功解决了格式问题,同时提供了后处理正则修正作为备用方案。
先看下花费:1.03元

花费不多。那为什么要微调模型呢?没有别的办法了吗?最后效果怎样?
在回答这些问题前,先看看业务的需求:
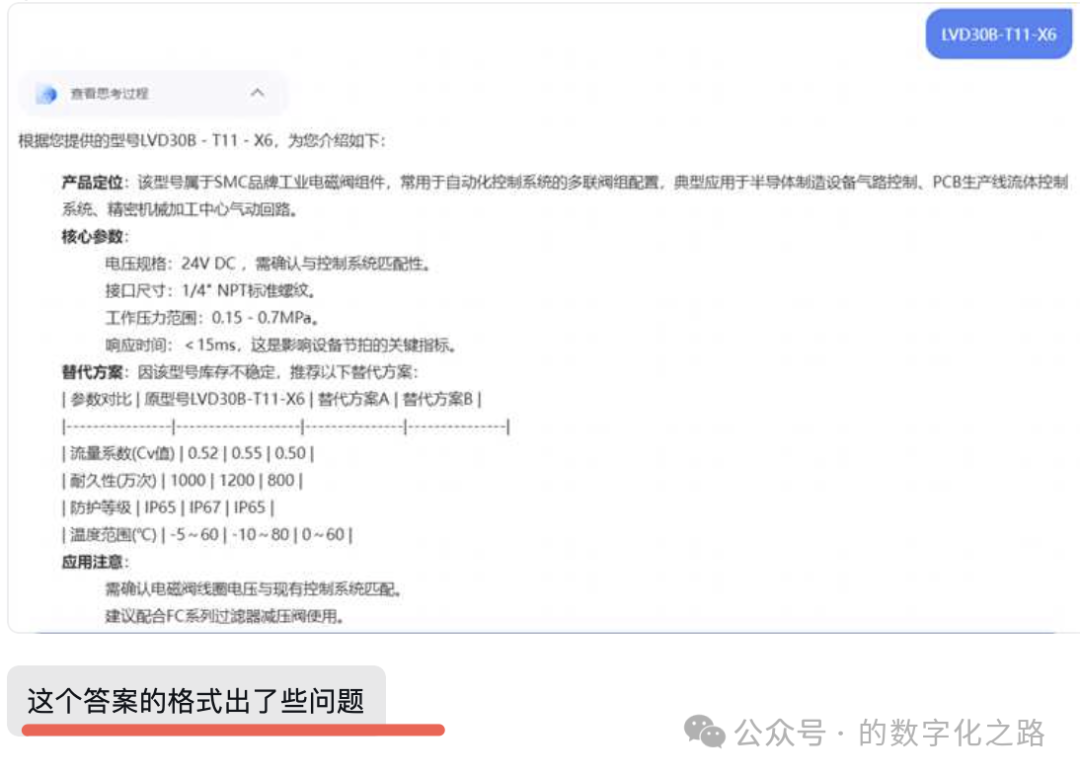
这是个体验类的需求。
输出的型号中间有空格,直接copy这个型号作为关键词去其它系统中可能就会查不到。
因为,传统的系统中要么是精确匹配,要么是基于RDB的like,这是无法支持关键词中间加空格的查询。
一、怎么办?
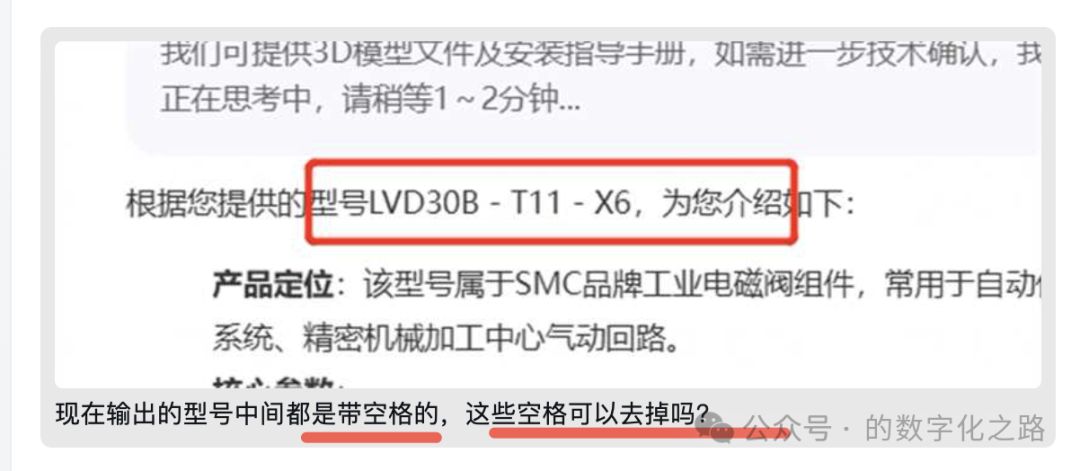
方案1:调提示词,让大模型控制输出的结果。试了下,不是很理想,没有彻底根除。
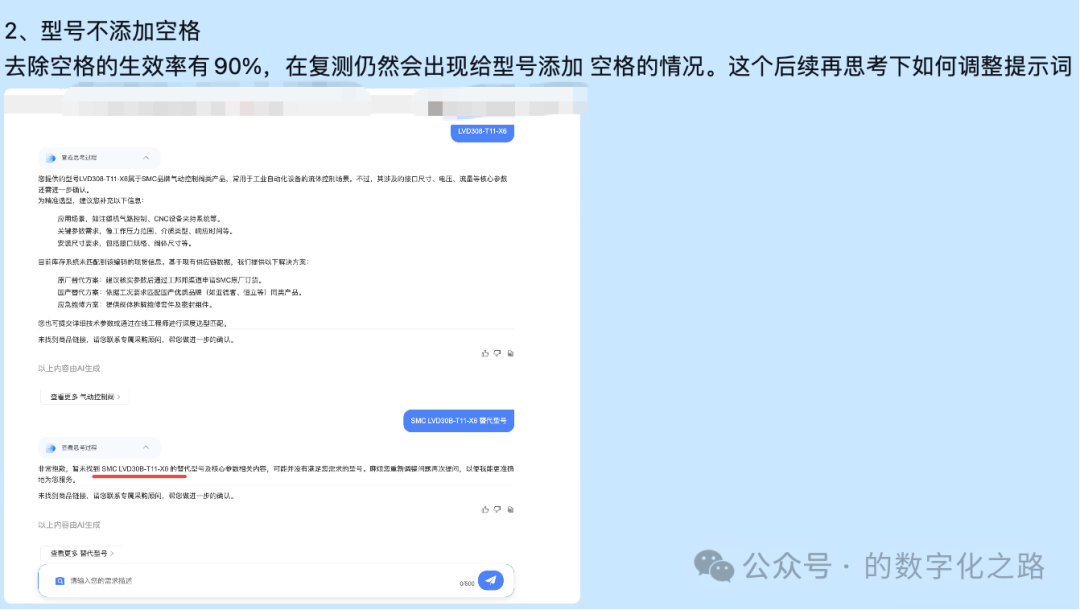
方案2:换大模型。
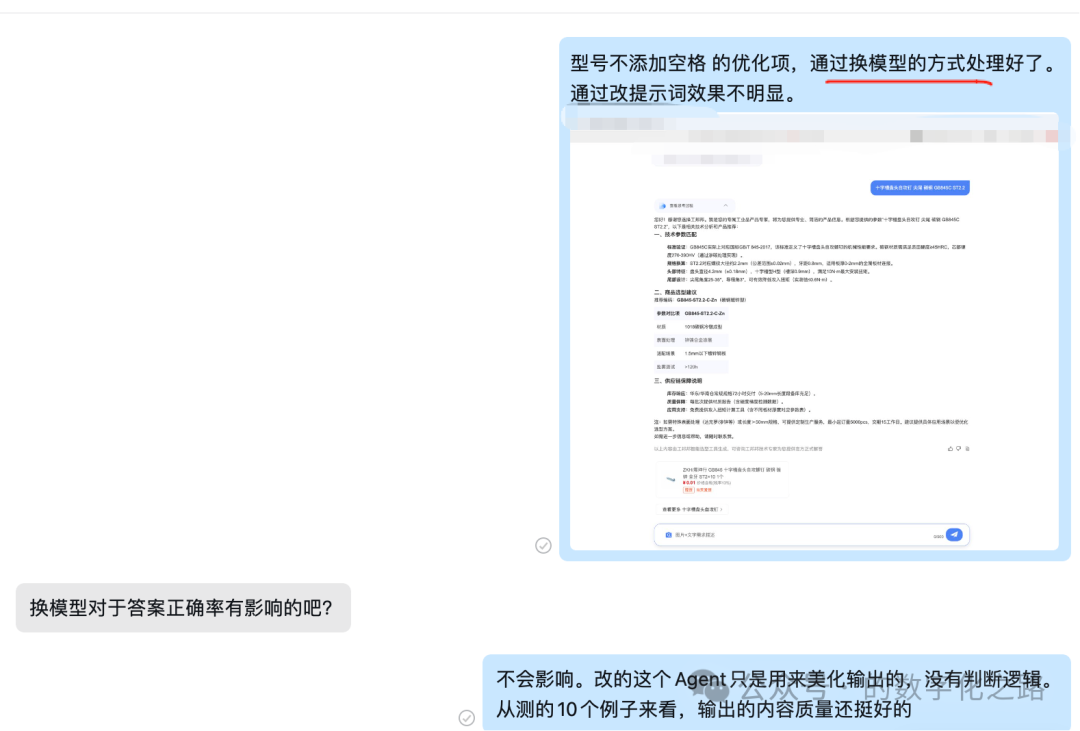
提示词无法解决问题时,换大模型也是一个解决问题的办法。不过这会增加额外回归测试的工作。
先换了gpt-4o-mini临时解决了问题。gpt-40-mini这个模型输出结果的型号中间没有额外加空格。

格式的问题解决了,但是这引发了另一个新问题:就是gpt-4o-mini比国内的大模型要贵不少。
二、怎么办?
对国内的模型Doubao-1.5-pro-32k进行微调。准确的讲是SFT(精调)。
什么是SFT?
SFT(Supervised Fine-Tuning,监督微调)精调:通过已标注好的数据对模型进行精调优化,以适应特定的任务或领域。
-
在自然语言处理(NLP)领域,Supervised Finetuning(SFT)是一种至关重要的技术手段,用来提升大模型在某一特定领域的表现。通过精细的策划和实施,SFT 能够指导模型的学习过程,确保其学习成果与既定目标高度吻合。
-
SFT 指的是,用户提供一份标注好的数据集,即,包含输入的 prompt 和预期输出的 response。然后,在已有的某个基座模型上继续调整参数,来达到和下游任务对齐的目的。
为什么是SFT?
因为SFT并不需要大量的训练集,因为SFT可以解决这类输入内容格式化的问题。
-
什么时候需要SFT:
-
通过 prompt engineering 无法解决或 prompt 中描述过于复杂时。
-
对大模型输出内容有格式要求时,而模型仍有部分 case 不符合要求。
-
期望通过 SFT 来减少 prompt 中的内容,加速线上推理的耗时。
-
做SFT的前置依赖:
-
0)一方面,把 prompt engineering 做到极致,通过优化 prompt 已经不能解决剩余的 badcase。另一方面,SFT 数据集中也依赖 prompt。因此,做 SFT 之前尽量把 prompt 工程做到最优。
-
1)一开始不需要急着构造大量 SFT 数据集,可以先用少量数据(50条~100条)对模型做 SFT 后观察真实评估是否有收益。如果有收益,可以尝试以部分数据为种子数据集继续扩充,找到 scaling law。
微调的核心任务是让模型从 “能生成文本” 进化为 “能听懂指令、按意图做事”。这个过程中,数据的作用不是 “喂饱模型”,而是 “给模型清晰的‘行为示范’”。
SFT是用来画龙点睛的。
三、怎么做?
本次使用字节火山引擎的模型精调工具。
1、在模型精调页面,点击左上角 创建精调任务 按钮。
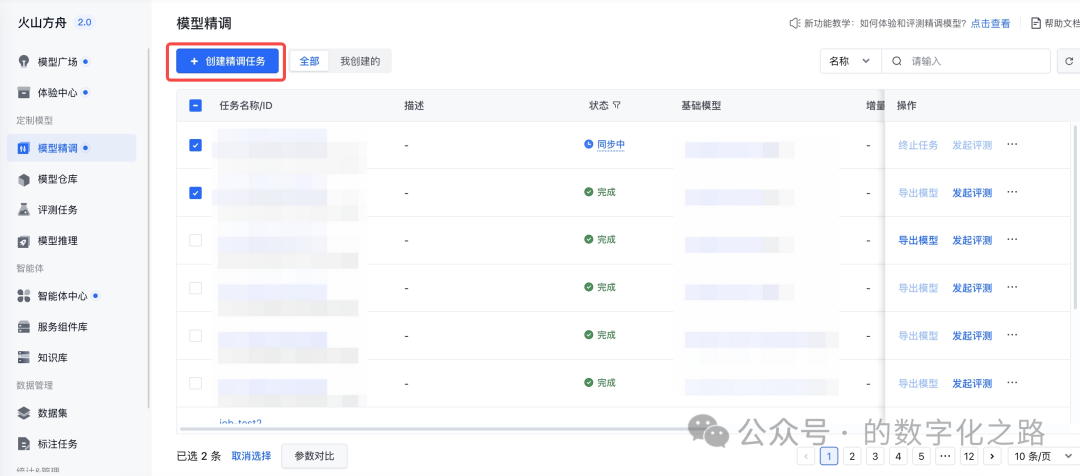
2、填写模型精调任务名称等基本信息。
任务名称(必填):本次精调任务命名,方便记录检索;支持1~200位可见字符,且只包含大小写字母、中文、数字、中划线、下划线。
任务描述:本次精调任务添加除名称以外的其他描述信息,方便多次迭代版本,重要信息记录;包含大小写字母、中文、数字、中划线、下划线。
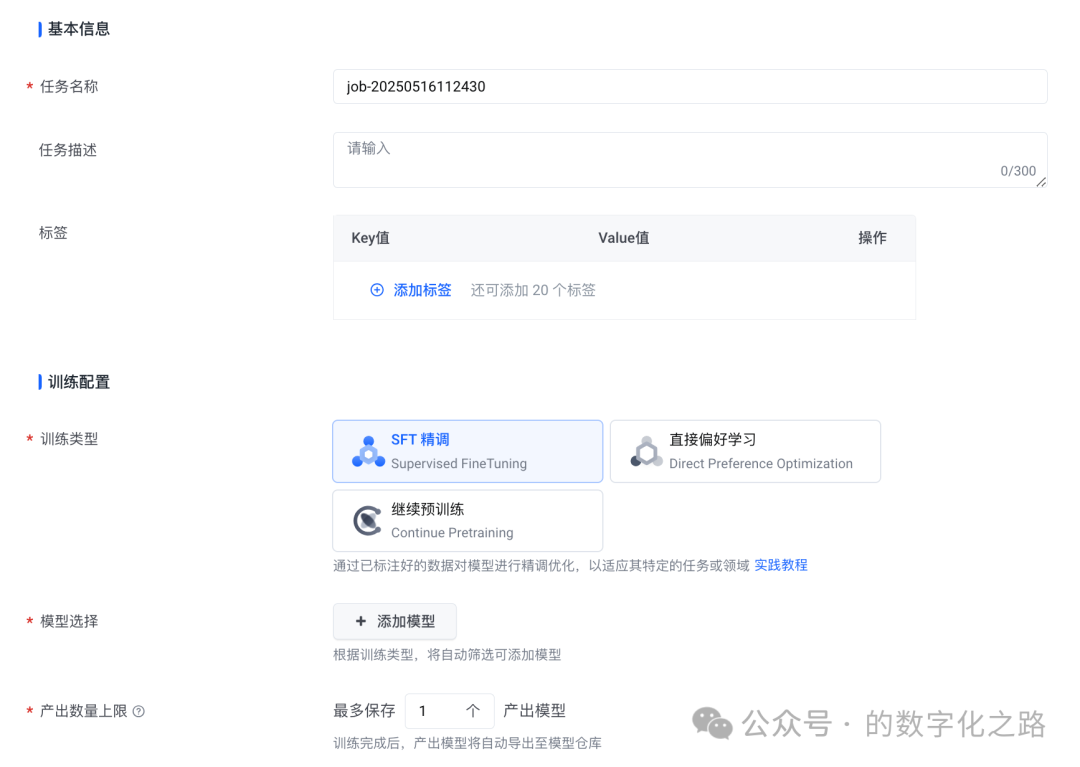
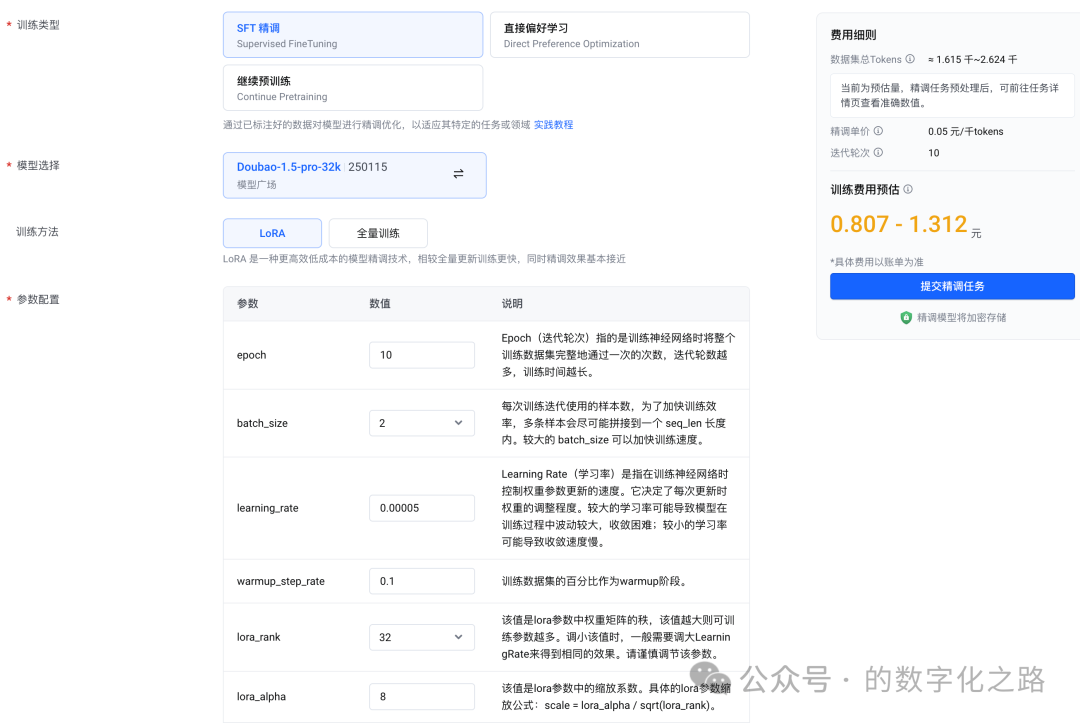
SFT参数配置中的参数如何确定?
与训练集有关。
训练集怎么得到?
使用大模型生成。因为SFT并不需要大量的训练集,微调的核心任务,是让模型从 “能生成文本” 进化为 “能听懂指令、按意图做事”。这个过程中,数据的作用不是 “喂饱模型”,而是 “给模型清晰的‘行为示范’”。
这份完整版的大模型 AI 学习和面试资料已经上传CSDN,朋友们如果需要可以微信扫描下方CSDN官方认证二维码免费领取【保证100%免费】

引用两句业内比较流行的话:
Quality Is All You Need.
Less Is More for Aligment.
话不多说,先来看看生成训练集的提示词:
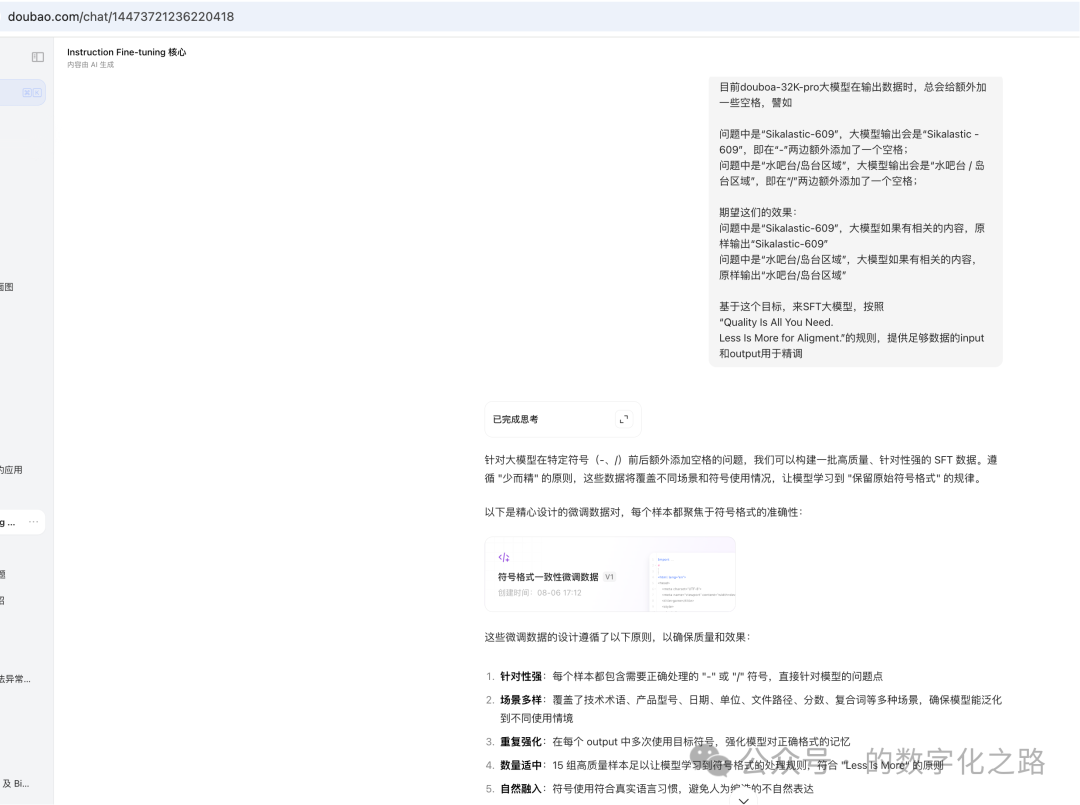
提示词:“
目前douboa-32K-pro大模型在输出数据时,总会给额外加一些空格,譬如
问题中是“Sikalastic-609”,大模型输出会是“Sikalastic - 609”,即在“-”两边额外添加了一个空格;
问题中是“水吧台/岛台区域”,大模型输出会是“水吧台 / 岛台区域”,即在“/”两边额外添加了一个空格;
期望这们的效果:
问题中是“Sikalastic-609”,大模型如果有相关的内容,原样输出“Sikalastic-609”
问题中是“水吧台/岛台区域”,大模型如果有相关的内容,原样输出“水吧台/岛台区域”
基于这个目标,来SFT大模型,按照
“Quality Is All You Need.
Less Is More for Aligment.”的规则,提供足够数据的input和output用于精调。
按“扩充高质量格式数据”的策略输出包含新增符号场景样本 和 增加 “错误 - 修正” 对比样本。
补充至少 50 条严格格式对齐的样本,覆盖更多领域(如技术文档、日常对话、专业术语)
"
本次生成并使用的训练集,共42条,具体数据见文末。
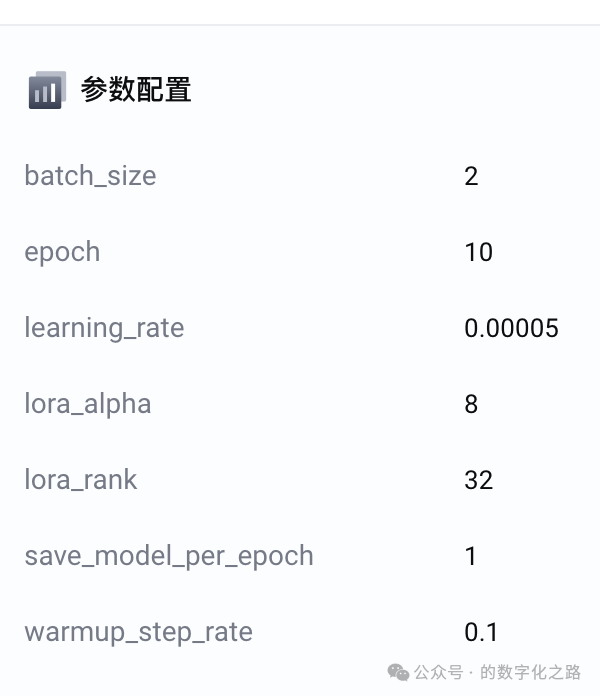
提示词:“使用上面生成的42条训练集,给出截图中参数的配置值”
Answer:结合 42 条训练集的小数据场景,以下是适配的参数配置思路及说明,在原有参数基础上优化以适配小数据的高效学习、避免过拟合:
1、参数配置表
|
参数名 |
原数值 |
调整后推荐值 |
调整逻辑(适配 42 条小数据集) |
|---|---|---|---|
epoch |
1 |
2 - 3 |
小数据需多轮学习强化记忆,2 - 3 轮平衡拟合与过拟合 |
batch_size |
8 |
4 或 8 |
42 条数据用 8 可整除(42÷8=5.25,实际取整为 5 个完整 batch + 2 条余数据;若硬件允许,8 可保留,加速训练;若显存紧张,调为 4 ) |
learning_rate |
0.00001 |
5e - 5 |
原学习率(1e - 5)偏低,小数据场景适度调高至 5e - 5 加速收敛,若训练中出现震荡,可再调回 3e - 5 |
warmup_step_rate |
0.05 |
0.1 |
增加 warmup 比例(10% 步数),让模型逐步适应学习率,避免小数据下初始更新幅度过大 |
lora_rank |
32 |
32 |
因只能选 32 或 64,32 更适配小数据,减少过拟合风险,保留该值 |
lora_alpha |
4 |
8 |
配合 |
save_model_per_epoch |
1 |
1 |
每 epoch 保存一次,42 条数据训练快,1 次 /epoch 足够记录过程,保留该值 |
dyn_bsz |
true |
true |
保持开启,最大化利用 seq_len×batch_size 填充 token,加速小数据训练效率,保留该值 |
2、核心调整逻辑
- 小数据强化学习
通过增加
epoch、适度调高learning_rate,让模型在有限数据中多轮学习、加速收敛,弥补数据量少的短板。 - 控制过拟合风险
保留
lora_rank=32(相对 64 更安全),配合warmup延长学习率适应过程,避免模型 “死记硬背” 小数据集。 - 参数协同适配
调整
lora_alpha匹配学习率变化,保证 Lora 模块参数更新的缩放比例合理,让训练更稳定。
按此配置,可在小数据场景下高效训练模型学习符号格式对齐,同时降低过拟合可能,若训练后验证集效果不佳(如过拟合),可进一步降低 epoch 或 learning_rate ;若收敛慢,则继续微调学习率或 warmup 比例 。
参数配置有了:
“混入预置数据集”和“验证集”怎么配?
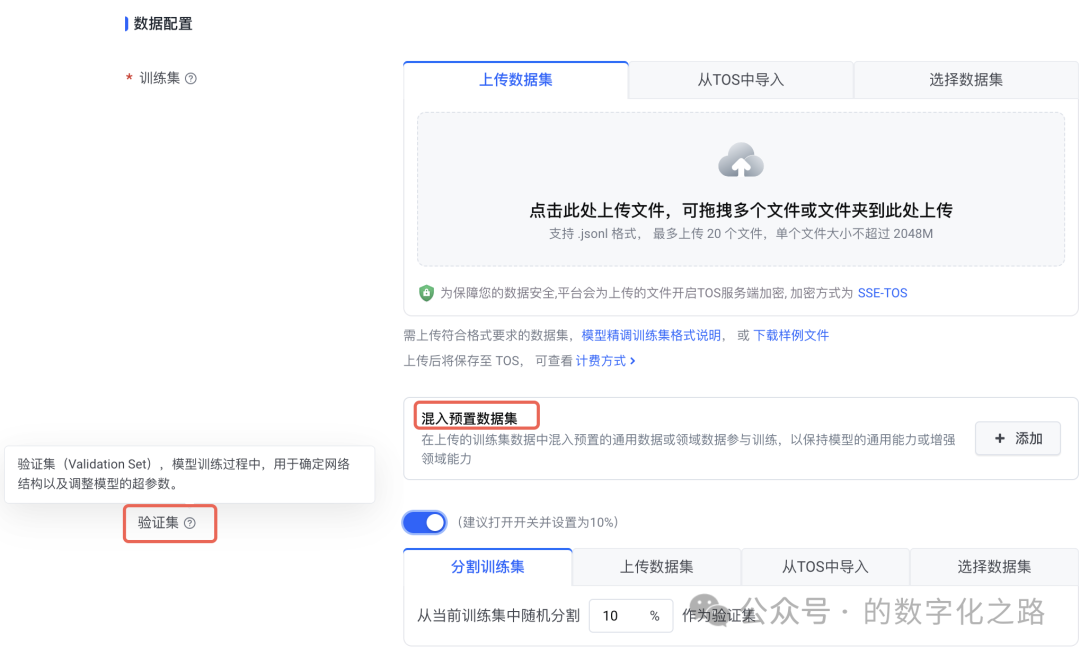
Query:“给出下面这两个指标的值: 混入预置数据集:在用户上传的训练集数据中混入豆包模型的SFT(Supervised Fine Tuning,有监督微调)数据,混入比例表示混合后SFT数据占总数据量的比例 验证集:Validation Set,模型训练过程中,用于确定网络结构以及调整模型的超参数。可以从训练集中随机分割一定比例作为验证集,也可以上传独立于训练集的数据集。”
Answer:
结合你提供的 40 条专项微调数据(输出格式对齐V1),以及 “Quality Is All You Need” 和 “Less Is More” 的原则,这两个指标的推荐值及设置逻辑如下:
1. 混入预置数据集比例:0%(不混入)
核心原因:
-
本次 SFT 目标极其明确(仅解决 “-”“/” 前后多余空格问题),40 条数据已精准覆盖该场景,信号纯度极高。
-
混入通用 SFT 数据会稀释专项信号,可能导致模型注意力分散(比如通用数据中可能存在符号格式不严格的样本,反而干扰学习)。
-
小数据场景下,“纯专项数据” 更利于模型快速锁定目标规律,符合 “少而精” 的对齐逻辑。
2. 验证集比例:20%(从训练集中随机分割)
推荐设置:
-
从 40 条数据中随机抽取 8 条作为验证集,剩余 32 条作为训练集。
核心原因: -
数据量极小(仅 40 条),独立验证集难以保证分布一致性,从训练集中分割更能匹配数据分布。
-
20% 比例既能保留足够训练样本(32 条),又能通过验证集监控过拟合(比如验证集中符号格式的正确率是否与训练集一致)。
-
若后续补充数据至 100 条以上,可考虑独立验证集;当前规模下,优先保证验证集与训练集的场景一致性。
这两个指标的设置均以 “强化专项信号、控制过拟合” 为核心,适配小数据量下的精准微调需求。
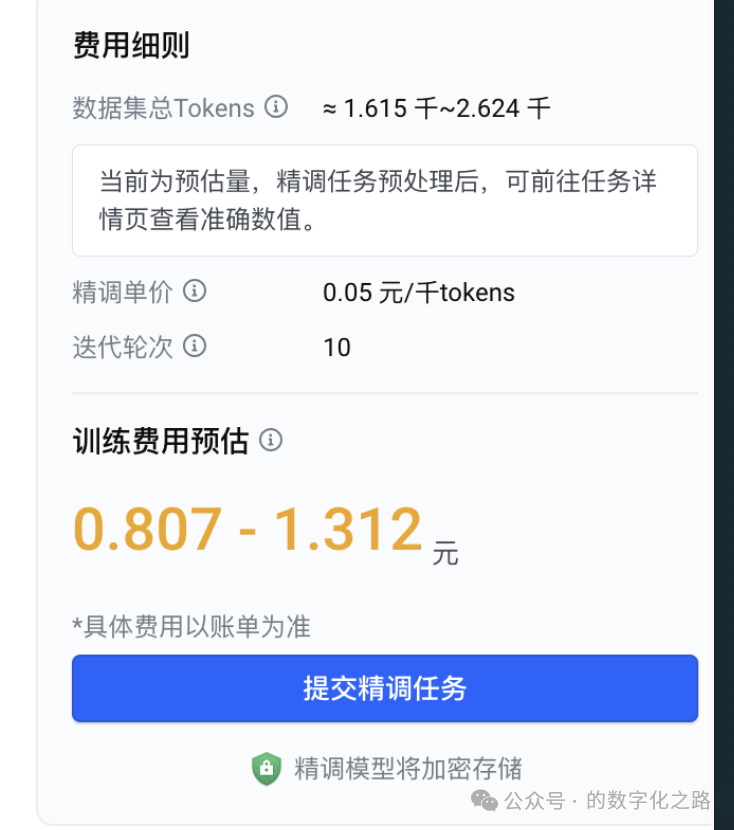
万事俱备,点击“提交精调任务”。
经过49 分 38 秒,SFT任务执行完成。
看下效果:
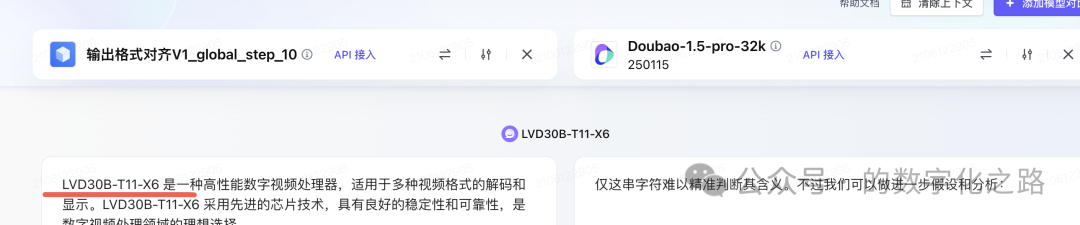
精调后,格式ok。
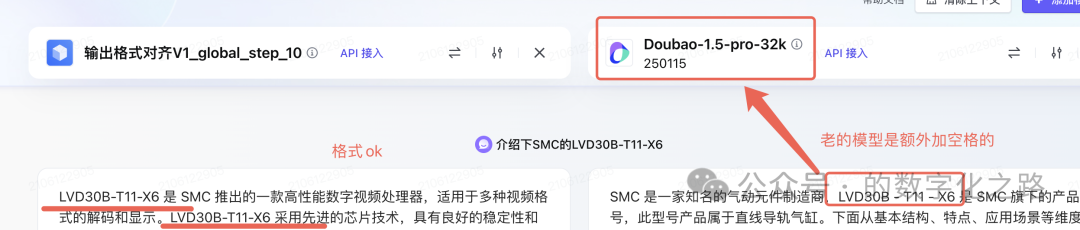
精调后,格式ok。

精调后,格式ok。
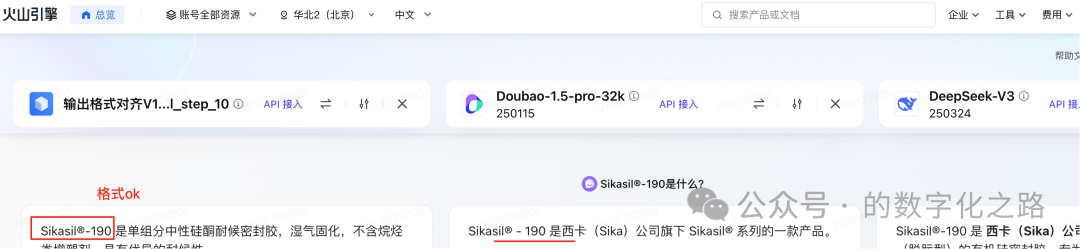
精调后,格式ok。
等等,你忘记大模型的“幻觉”了吗?

要有PlanB。
四、PlanB
1、后处理层:兜底的格式修正
若训练后仍有残留问题,通过推理阶段后处理兜底修正,确保最终输出符合要求:
1.1 正则表达式替换(简单有效)
推理时,用 Python 正则自动清理符号前后空
import re
def fix_symbol_format(text):
# 处理“/”前后空格
text = re.sub(r'\s*/\s*','/', text)
# 处理“-”前后空格(注意区分连字符与减号,可根据场景调整)
text = re.sub(r'\s*-\s*','-', text)
return text
# 推理示例
output = model.generate(...)
fixed_output = fix_symbol_format(output)
1.2 构建格式校验器
-
用规则引擎或小型分类模型,对输出文本做 “格式合规性检查”:
-
若检测到符号格式错误,触发 “重新生成” 或 “后处理替换”;
-
结合业务场景,可定制更复杂的格式规则(如 “/ 仅用于领域术语分隔,日常对话中保留空格”)。
-
2、验证与迭代:闭环优化确保效果
2.1 构建格式测试集
准备 100 + 条含 “/”、“-” 的测试用例,覆盖训练 / 未训练场景,验证格式对齐率。
2.2 迭代优化流程
-
-
若测试集格式错误率>5%,回到数据层补充样本;
-
若训练中验证集格式正确率低,调整训练参数增强约束;
-
若推理后仍有漏网,优化后处理规则覆盖更多边界情况。
-
核心逻辑总结
格式对齐的本质是让模型在小数据中精准学习 “人类对符号的严格规范”,需通过:
- 数据强化
提供充足且清晰的格式样本;
- 训练优化
让模型聚焦格式学习而非过拟合;
- 后处理兜底
确保极端情况也能修正。
SFT训练数据集
https://f.chaojihao.net/ai/dataset/sft/format/symbol_format_finetune_data20250808V2.jsonl
SFT 最佳实践
https://www.volcengine.com/docs/82379/1221664
创建模型精调任务
https://www.volcengine.com/docs/82379/1099459
最后再补张图,没有完全理解的朋友可以整体再看一下,找找感觉:

面对传统Code RAG和Code Agent在召回率、准确率和稳定性上的不足,以及领域“黑话”和代码风格差异带来的挑战,使用以大模型微调(SFT)为核心的解决方案成功解决了问题。
博跃,公众号:阿里云开发者让AI读懂代码需求:模块化大模型微调助力高效代码理解与迁移
什么是LoRA?
LoRA(Low-Rank Adaptation,低秩适应)是一种高效微调大模型的技术,由微软团队于 2021 年提出。
LoRA的核心是在不改变原模型参数的情况下,通过添加少量低秩矩阵参数来适配新任务。训练时仅优化这些新增的少量参数,大幅降低计算成本;推理时将低秩矩阵的影响合并回原模型,不增加额外开销。这种方式用极少参数就能实现接近全量微调的效果,广泛用于大模型的任务适配。
具体来说,传统微调需要更新模型的全部参数,当模型规模庞大(如数十亿甚至千亿参数)时,会消耗大量计算资源和存储空间。而 LoRA 的做法是:
-
在预训练模型的关键层(如注意力层的权重矩阵)中插入两个低秩矩阵(可理解为维度较小的矩阵),这两个矩阵的乘积近似于该层在新任务上所需的参数更新量;
-
训练过程中,仅优化这两个低秩矩阵的参数,而冻结预训练模型的原始参数;
-
推理时,将低秩矩阵的乘积与原始参数相加,等效于完成了参数更新,不增加额外计算开销。
由于低秩矩阵的参数规模远小于原始模型参数(通常仅为原始参数的 1%-10%),LoRA 大幅降低了微调的成本,同时还能有效避免过拟合,在多种自然语言处理任务(如文本分类、翻译、问答等)中表现出色,目前已成为大模型微调的主流技术之一。
五、AI大模型学习路线
如果你对AI大模型入门感兴趣,那么你需要的话可以点击这里大模型重磅福利:入门进阶全套104G学习资源包免费分享!
这份完整版的大模型 AI 学习和面试资料已经上传CSDN,朋友们如果需要可以微信扫描下方CSDN官方认证二维码免费领取【保证100%免费】

这是一份大模型从零基础到进阶的学习路线大纲全览,小伙伴们记得点个收藏!

第一阶段: 从大模型系统设计入手,讲解大模型的主要方法;
第二阶段: 在通过大模型提示词工程从Prompts角度入手更好发挥模型的作用;
第三阶段: 大模型平台应用开发借助阿里云PAI平台构建电商领域虚拟试衣系统;
第四阶段: 大模型知识库应用开发以LangChain框架为例,构建物流行业咨询智能问答系统;
第五阶段: 大模型微调开发借助以大健康、新零售、新媒体领域构建适合当前领域大模型;
第六阶段: 以SD多模态大模型为主,搭建了文生图小程序案例;
第七阶段: 以大模型平台应用与开发为主,通过星火大模型,文心大模型等成熟大模型构建大模型行业应用。
100套AI大模型商业化落地方案

大模型全套视频教程

200本大模型PDF书籍

👉学会后的收获:👈
• 基于大模型全栈工程实现(前端、后端、产品经理、设计、数据分析等),通过这门课可获得不同能力;
• 能够利用大模型解决相关实际项目需求: 大数据时代,越来越多的企业和机构需要处理海量数据,利用大模型技术可以更好地处理这些数据,提高数据分析和决策的准确性。因此,掌握大模型应用开发技能,可以让程序员更好地应对实际项目需求;
• 基于大模型和企业数据AI应用开发,实现大模型理论、掌握GPU算力、硬件、LangChain开发框架和项目实战技能, 学会Fine-tuning垂直训练大模型(数据准备、数据蒸馏、大模型部署)一站式掌握;
• 能够完成时下热门大模型垂直领域模型训练能力,提高程序员的编码能力: 大模型应用开发需要掌握机器学习算法、深度学习框架等技术,这些技术的掌握可以提高程序员的编码能力和分析能力,让程序员更加熟练地编写高质量的代码。
LLM面试题合集

大模型产品经理资源合集

大模型项目实战合集

👉获取方式:
😝有需要的小伙伴,可以保存图片到wx扫描二v码免费领取【保证100%免费】🆓


欢迎加入DeepSeek 技术社区。在这里,你可以找到志同道合的朋友,共同探索AI技术的奥秘。
更多推荐



 25
25 0
0- 0



 已为社区贡献15条内容
已为社区贡献15条内容

所有评论(0)