非对称拉普拉斯分布及其性质(deepseek出品)
好的,首先我们来详细探讨一下非对称拉普拉斯分布。非对称拉普拉斯分布是一种在统计学和计量经济学中非常重要的连续概率分布。它本质上是经典拉普拉斯分布(或称双指数分布)的推广,通过引入一个不对称参数,使其能够处理不对称的数据。好的,我们来重点关注与分位数相关的非对称拉普拉斯分布的概率密度函数(PDF)。这种参数化形式直接将其与分位数回归联系起来,是其最重要的形式。μ位置参数。当我们将该分布用作回归的误差
目录
0、引言
今天介绍一些非对称拉普拉斯分布及其一些性质。为了偷懒主要的公式markdown均借助与deepseek一问一答来整理。我负责会内容进行整合和审核。
1、非对称拉普拉斯的定义
好的,首先我们来详细探讨一下非对称拉普拉斯分布。
非对称拉普拉斯分布是一种在统计学和计量经济学中非常重要的连续概率分布。它本质上是经典拉普拉斯分布(或称双指数分布)的推广,通过引入一个不对称参数,使其能够处理不对称的数据。
1.1. 核心概念与直观理解
想象一下经典的拉普拉斯分布,它关于其均值对称,形状像两个背对背的指数分布。非对称拉普拉斯分布打破了这种对称性。
- 核心思想:它由两个具有不同比率的指数分布“拼接”而成,在众数(mode)处连接。众数左侧是一个指数分布,右侧是另一个。
- 控制不对称性的参数:通常用 κ 或 τ 表示。
- 当 κ = 1(或 τ = 0.5)时,分布是对称的,即退化为标准的拉普拉斯分布。
- 当 κ < 1(或 τ < 0.5)时,分布是右偏的(右侧尾部更长,质量集中在左侧)。
- 当 κ > 1(或 τ > 0.5)时,分布是左偏的(左侧尾部更长,质量集中在右侧)。
1.2 主要参数说明
非对称拉普拉斯分布通常由三个参数定义:
- 位置参数:通常用 μ 表示。它决定了分布的中心。对于标准的非对称拉普拉斯分布,μ 也是分布的众数和中位数(注意:中位数仅在对称时才等于众数,但这里μ被定义为众数)。
- 尺度参数:通常用 σ 表示(σ > 0)。它控制分布的分散程度或宽度,类似于正态分布中的标准差。
- 不对称参数(偏度参数):有几种等价的参数化方式,最常见的是:
- κ κ κ: 取值范围 (0, +∞)。 κ κ κ = 1 表示对称。
- τ τ τ: 取值范围 (0, 1)。 τ τ τ = 0.5 表示对称。 τ τ τ 和 κ κ κ 的关系是 κ = ( τ / ( 1 − τ ) ) κ = \sqrt{(τ / (1-τ))} κ=(τ/(1−τ)) 或 τ = κ 2 / ( 1 + κ 2 ) τ = κ² / (1 + κ²) τ=κ2/(1+κ2)。
1.3 概率密度函数 ( κ κ κ的版本)
其概率密度函数是分段定义的,体现了它由两个指数分布组成的特点。
一种常见的参数化形式(使用 μ, σ, κ κ κ)如下:
f ( x ; μ , σ , κ ) = { κ σ ⋅ 1 1 + κ 2 exp ( − κ σ ∣ x − μ ∣ ) 如果 x ≥ μ κ σ ⋅ 1 1 + κ 2 exp ( − 1 κ σ ∣ x − μ ∣ ) 如果 x < μ f(x; \mu, \sigma, \kappa) = \begin{cases} \frac{\kappa}{\sigma} \cdot \frac{1}{1 + \kappa^2} \exp\left( -\frac{\kappa}{\sigma} |x - \mu| \right) & \text{如果 } x \geq \mu \\ \frac{\kappa}{\sigma} \cdot \frac{1}{1 + \kappa^2} \exp\left( -\frac{1}{\kappa \sigma} |x - \mu| \right) & \text{如果 } x < \mu \end{cases} f(x;μ,σ,κ)={σκ⋅1+κ21exp(−σκ∣x−μ∣)σκ⋅1+κ21exp(−κσ1∣x−μ∣)如果 x≥μ如果 x<μ
另一种使用分位数参数 τ 的形式也更常见:
f ( x ; μ , σ , τ ) = τ ( 1 − τ ) σ exp ( − ρ τ ( x − μ σ ) ) f(x; \mu, \sigma, \tau) = \frac{\tau(1-\tau)}{\sigma} \exp\left( -\rho_\tau\left(\frac{x-\mu}{\sigma}\right) \right) f(x;μ,σ,τ)=στ(1−τ)exp(−ρτ(σx−μ))
其中 ρ τ ( u ) = u ( τ − I ( u < 0 ) ) \rho_\tau(u) = u(\tau - I(u < 0)) ρτ(u)=u(τ−I(u<0)) 称为检查函数,是分位数回归中的核心函数。 I I I 是示性函数。
1.4 概率密度函数 ( τ \tau τ的版本)
1.4.1 定义
好的,我们来重点关注与分位数相关的非对称拉普拉斯分布的概率密度函数(PDF)。这种参数化形式直接将其与分位数回归联系起来,是其最重要的形式。该分布由三个参数定义:
- μ: 位置参数。当我们将该分布用作回归的误差分布时,这个 μ 直接对应着我们想要估计的 τ τ τ-条件分位数。
- σ: 尺度参数(σ > 0)。控制分布的离散程度。
- τ τ τ: 不对称参数或分位数参数(0 < τ τ τ < 1)。它指定了我们所关注的分位数。例如, τ τ τ = 0.5 对应中位数, τ τ τ = 0.9 对应第90百分位数。
其概率密度函数为:
f ( x ; μ , σ , τ ) = τ ( 1 − τ ) σ exp ( − ρ τ ( x − μ σ ) ) f(x; \mu, \sigma, \tau) = \frac{\tau(1-\tau)}{\sigma} \exp\left( -\rho_\tau\left(\frac{x - \mu}{\sigma}\right) \right) f(x;μ,σ,τ)=στ(1−τ)exp(−ρτ(σx−μ))
其中, ρ τ ( u ) \rho_\tau(u) ρτ(u) 是分位数回归中至关重要的检查函数:
ρ τ ( u ) = u ( τ − I ( u < 0 ) ) = { τ ∣ u ∣ if u ≥ 0 ( 1 − τ ) ∣ u ∣ if u < 0 \rho_\tau(u) = u(\tau - I(u < 0)) = \begin{cases} \tau |u| & \text{if } u \geq 0 \\ (1-\tau)|u| & \text{if } u < 0 \end{cases} ρτ(u)=u(τ−I(u<0))={τ∣u∣(1−τ)∣u∣if u≥0if u<0
这里的 I ( u < 0 ) I(u < 0) I(u<0) 是示性函数,当 u < 0 u < 0 u<0 时为 1,否则为 0。 u u u 是标准化后的残差,即 u = x − μ σ u = \frac{x - \mu}{\sigma} u=σx−μ。
1.4.2 直观理解与分段形式
将检查函数 ρ τ ( u ) \rho_\tau(u) ρτ(u) 代入PDF,可以更清楚地看到其分段指数分布的本质:
f ( x ; μ , σ , τ ) = { τ ( 1 − τ ) σ exp ( − τ σ ( x − μ ) ) for x ≥ μ (右侧) τ ( 1 − τ ) σ exp ( − 1 − τ σ ( μ − x ) ) for x < μ (左侧) f(x; \mu, \sigma, \tau) = \begin{cases} \frac{\tau(1-\tau)}{\sigma} \exp\left( -\frac{\tau}{\sigma} (x - \mu) \right) & \text{for } x \geq \mu \quad \text{(右侧)} \\ \frac{\tau(1-\tau)}{\sigma} \exp\left( -\frac{1-\tau}{\sigma} (\mu - x) \right) & \text{for } x < \mu \quad \text{(左侧)} \end{cases} f(x;μ,σ,τ)={στ(1−τ)exp(−στ(x−μ))στ(1−τ)exp(−σ1−τ(μ−x))for x≥μ(右侧)for x<μ(左侧)
让我们来解析这个分段函数:
- 众数 (Mode): 密度函数在 x = μ x = \mu x=μ 处达到峰值。这意味着 μ \mu μ 是分布的众数。
- 右侧尾巴 ( x ≥ μ x \geq \mu x≥μ): 这是一个衰减率为 λ right = τ σ \lambda_{\text{right}} = \frac{\tau}{\sigma} λright=στ 的指数分布。 τ \tau τ 越大,衰减越快,尾巴越短。
- 左侧尾巴 ( x < μ x < \mu x<μ): 这是一个衰减率为 λ left = 1 − τ σ \lambda_{\text{left}} = \frac{1-\tau}{\sigma} λleft=σ1−τ 的指数分布。 1 − τ 1-\tau 1−τ 越大(即 τ \tau τ 越小),衰减越快,尾巴越短。
为什么 τ τ τ 能控制不对称性?
- 当 τ = 0.5 \tau = 0.5 τ=0.5 (中位数): 两个衰减率相等: λ right = 0.5 σ \lambda_{\text{right}} = \frac{0.5}{\sigma} λright=σ0.5, λ left = 0.5 σ \lambda_{\text{left}} = \frac{0.5}{\sigma} λleft=σ0.5。分布是对称的,即标准的拉普拉斯分布。
- 当 τ > 0.5 \tau > 0.5 τ>0.5 (例如, τ=0.9): λ right = 0.9 σ \lambda_{\text{right}} = \frac{0.9}{\sigma} λright=σ0.9 比 λ left = 0.1 σ \lambda_{\text{left}} = \frac{0.1}{\sigma} λleft=σ0.1 大得多。
- 右侧衰减非常快,尾巴很短。
- 左侧衰减非常慢,尾巴很长。
- 结果:分布是左偏的(长尾巴在左边,质量集中在右边)。众数 μ 对应的是第90分位数,这意味着90%的数据都小于 μ。
- 当 τ < 0.5 \tau < 0.5 τ<0.5 (例如, τ τ τ=0.1): 情况正好相反。右侧尾巴长,左侧尾巴短,分布是右偏的。众数 μ 对应的是第10分位数。
1.4.3 与分位数回归的完美连接
这个PDF的设计是精巧绝伦的,因为它与分位数回归的目标函数完美契合。在分位数回归中,我们的目标是找到参数 β \beta β,使得检查损失函数最小化:
min β ∑ i = 1 n ρ τ ( y i − X i β ) \min_{\beta} \sum_{i=1}^n \rho_\tau(y_i - X_i\beta) βmini=1∑nρτ(yi−Xiβ)
现在,假设我们的回归残差 ϵ i = y i − X i β \epsilon_i = y_i - X_i\beta ϵi=yi−Xiβ 服从一个位置参数为 0 的非对称拉普拉斯分布: ϵ i ∼ A L ( 0 , σ , τ ) \epsilon_i \sim AL(0, \sigma, \tau) ϵi∼AL(0,σ,τ)。那么,对于残差 ϵ i \epsilon_i ϵi,其概率密度为:
f ( ϵ i ; 0 , σ , τ ) = τ ( 1 − τ ) σ exp ( − ρ τ ( ϵ i σ ) ) f(\epsilon_i; 0, \sigma, \tau) = \frac{\tau(1-\tau)}{\sigma} \exp\left( -\rho_\tau\left(\frac{\epsilon_i}{\sigma}\right) \right) f(ϵi;0,σ,τ)=στ(1−τ)exp(−ρτ(σϵi))
整个样本的似然函数为:
L ( β , σ ) = ∏ i = 1 n f ( ϵ i ; 0 , σ , τ ) = ( τ ( 1 − τ ) σ ) n exp ( − 1 σ ∑ i = 1 n ρ τ ( y i − X i β ) ) L(\beta, \sigma) = \prod_{i=1}^n f(\epsilon_i; 0, \sigma, \tau) = \left( \frac{\tau(1-\tau)}{\sigma} \right)^n \exp\left( -\frac{1}{\sigma} \sum_{i=1}^n \rho_\tau(y_i - X_i\beta) \right) L(β,σ)=i=1∏nf(ϵi;0,σ,τ)=(στ(1−τ))nexp(−σ1i=1∑nρτ(yi−Xiβ))
对似然函数取对数并求最大似然估计(MLE),即最大化 ln L ( β , σ ) \ln L(\beta, \sigma) lnL(β,σ)。由于表达式中的负号,最大化似然函数等价于最小化检查函数之和:
max β , σ ln L ( β , σ ) ⟺ min β ∑ i = 1 n ρ τ ( y i − X i β ) \max_{\beta, \sigma} \ln L(\beta, \sigma) \quad \Longleftrightarrow \quad \min_{\beta} \sum_{i=1}^n \rho_\tau(y_i - X_i\beta) β,σmaxlnL(β,σ)⟺βmini=1∑nρτ(yi−Xiβ)
结论: 假设误差服从非对称拉普拉斯分布,然后进行最大似然估计,数学上完全等价于直接求解分位数回归问题。这就是该分布在分位数回归理论和计算中占据核心地位的原因。
2、ALD的有限距
2.1 任意阶距
这节我们来详细探讨非对称拉普拉斯分布 (ALD) 的均值、方差、偏度和峰度。这些矩是理解分布形状和特性的关键。由于分布的不对称性,其矩的表达式比对称分布要复杂一些。首先,为了推导方便,我们通常对标准化的 ALD 进行分析。设 Z = Y − μ σ Z = \frac{Y - \mu}{\sigma} Z=σY−μ,则 Z ∼ A L D ( 0 , 1 , τ ) Z \sim ALD(0, 1, \tau) Z∼ALD(0,1,τ),其概率密度函数 (PDF) 为:
f ( z ∣ τ ) = τ ( 1 − τ ) exp ( − ρ τ ( z ) ) f(z | \tau) = \tau(1-\tau) \exp\left( -\rho_\tau(z) \right) f(z∣τ)=τ(1−τ)exp(−ρτ(z))
其中 ρ τ ( z ) \rho_\tau(z) ρτ(z) 是检查函数。我们要求 Y Y Y 的矩,即 E [ Y n ] = E [ ( μ + σ Z ) n ] E[Y^n] = E[(\mu + \sigma Z)^n] E[Yn]=E[(μ+σZ)n]。这等价于先求出 Z Z Z 的各阶矩 E [ Z n ] E[Z^n] E[Zn],然后再进行变换。
Z Z Z 的 n n n 阶矩 E [ Z n ] E[Z^n] E[Zn] 的计算需要将积分分为 z < 0 z < 0 z<0 和 z ≥ 0 z \geq 0 z≥0 两部分:
E [ Z n ] = ∫ − ∞ ∞ z n f ( z ) d z = τ ( 1 − τ ) [ ∫ − ∞ 0 z n e ( 1 − τ ) z d z + ∫ 0 ∞ z n e − τ z d z ] E[Z^n] = \int_{-\infty}^{\infty} z^n f(z) dz = \tau(1-\tau) \left[ \int_{-\infty}^{0} z^n e^{(1-\tau)z} dz + \int_{0}^{\infty} z^n e^{-\tau z} dz \right] E[Zn]=∫−∞∞znf(z)dz=τ(1−τ)[∫−∞0zne(1−τ)zdz+∫0∞zne−τzdz]
利用伽马函数 Γ ( n + 1 ) = ∫ 0 ∞ x n e − x d x = n ! \Gamma(n+1) = \int_{0}^{\infty} x^n e^{-x} dx = n! Γ(n+1)=∫0∞xne−xdx=n! 的性质,可以求解上述积分。经过计算,我们得到 Z Z Z 的前四阶矩:
-
一阶矩 (期望)
E [ Z ] = 1 − 2 τ τ ( 1 − τ ) E[Z] = \frac{1 - 2\tau}{\tau(1-\tau)} E[Z]=τ(1−τ)1−2τ -
二阶中心矩 (方差)
Var ( Z ) = E [ ( Z − E [ Z ] ) 2 ] = E [ Z 2 ] − ( E [ Z ] ) 2 = 1 − 2 τ + 2 τ 2 τ 2 ( 1 − τ ) 2 \text{Var}(Z) = E[(Z - E[Z])^2] = E[Z^2] - (E[Z])^2 = \frac{1 - 2\tau + 2\tau^2}{\tau^2(1-\tau)^2} Var(Z)=E[(Z−E[Z])2]=E[Z2]−(E[Z])2=τ2(1−τ)21−2τ+2τ2 -
三阶标准矩 (偏度)
偏度 γ 1 = E [ ( Z − E [ Z ] ) 3 ] ( Var ( Z ) ) 3 / 2 = 2 ( 1 − 2 τ ) ( 1 − τ + τ 2 ) ( 1 − 2 τ + 2 τ 2 ) 3 / 2 \gamma_1 = \frac{E[(Z - E[Z])^3]}{(\text{Var}(Z))^{3/2}} = \frac{2(1 - 2\tau)(1 - \tau + \tau^2)}{(1 - 2\tau + 2\tau^2)^{3/2}} γ1=(Var(Z))3/2E[(Z−E[Z])3]=(1−2τ+2τ2)3/22(1−2τ)(1−τ+τ2) -
四阶标准矩 (超值峰度)
峰度 γ 2 = E [ ( Z − E [ Z ] ) 4 ] ( Var ( Z ) ) 2 − 3 = 6 ( 1 − 2 τ + 4 τ 2 − 4 τ 3 + 2 τ 4 ) ( 1 − 2 τ + 2 τ 2 ) 2 − 6 \gamma_2 = \frac{E[(Z - E[Z])^4]}{(\text{Var}(Z))^2} - 3 = \frac{6(1 - 2\tau + 4\tau^2 - 4\tau^3 + 2\tau^4)}{(1 - 2\tau + 2\tau^2)^2} - 6 γ2=(Var(Z))2E[(Z−E[Z])4]−3=(1−2τ+2τ2)26(1−2τ+4τ2−4τ3+2τ4)−6
(这里减3是与正态分布比较,正态分布的峰度为3,所以超值峰度为0)。
2.2 原始变量 Y ∼ A L D ( μ , σ , τ ) Y \sim ALD(\mu, \sigma, \tau) Y∼ALD(μ,σ,τ)前4阶距
利用 Y = μ + σ Z Y = \mu + \sigma Z Y=μ+σZ 的性质,我们可以得到:
| 矩 | 公式 |
|---|---|
| 均值 E [ Y ] E[Y] E[Y] |
E [ Y ] = μ + σ ⋅ E [ Z ] = μ + σ ⋅ 1 − 2 τ τ ( 1 − τ ) E[Y] = \mu + \sigma \cdot E[Z] = \mu + \sigma \cdot \frac{1 - 2\tau}{\tau(1-\tau)} E[Y]=μ+σ⋅E[Z]=μ+σ⋅τ(1−τ)1−2τ |
| 方差 Var ( Y ) \text{Var}(Y) Var(Y) |
Var ( Y ) = σ 2 ⋅ Var ( Z ) = σ 2 ⋅ 1 − 2 τ + 2 τ 2 τ 2 ( 1 − τ ) 2 \text{Var}(Y) = \sigma^2 \cdot \text{Var}(Z) = \sigma^2 \cdot \frac{1 - 2\tau + 2\tau^2}{\tau^2(1-\tau)^2} Var(Y)=σ2⋅Var(Z)=σ2⋅τ2(1−τ)21−2τ+2τ2 |
| 偏度 Skewness ( Y ) \text{Skewness}(Y) Skewness(Y) |
γ 1 = 2 ( 1 − 2 τ ) ( 1 − τ + τ 2 ) ( 1 − 2 τ + 2 τ 2 ) 3 / 2 \gamma_1 = \frac{2(1-2\tau)(1 - \tau + \tau^2)}{(1 - 2\tau + 2\tau^2)^{3/2}} γ1=(1−2τ+2τ2)3/22(1−2τ)(1−τ+τ2) (与 μ \mu μ 和 σ \sigma σ 无关) |
| 峰度 Kurtosis ( Y ) \text{Kurtosis}(Y) Kurtosis(Y) |
γ 2 = 6 ( 1 − 2 τ + 4 τ 2 − 4 τ 3 + 2 τ 4 ) ( 1 − 2 τ + 2 τ 2 ) 2 − 6 \gamma_2 = \frac{6(1 - 2\tau + 4\tau^2 - 4\tau^3 + 2\tau^4)}{(1 - 2\tau + 2\tau^2)^2} - 6 γ2=(1−2τ+2τ2)26(1−2τ+4τ2−4τ3+2τ4)−6 (与 μ \mu μ 和 σ \sigma σ 无关) |
2.3 关键解读和特性
-
均值 ≠ 分位数点:
- 位置参数 μ \mu μ 是分布的 τ \tau τ-分位数,即 P ( Y ≤ μ ) = τ P(Y \leq \mu) = \tau P(Y≤μ)=τ。
- 但是,分布的均值 E [ Y ] E[Y] E[Y] 并不等于 μ \mu μ(除非 τ = 0.5 \tau=0.5 τ=0.5)。均值是 μ \mu μ 加上一个由 τ \tau τ 和 σ \sigma σ 决定的调整项。这直观地反映了分布的不对称性。
-
对称情况 ( τ = 0.5 \tau = 0.5 τ=0.5):
- 均值: E [ Y ] = μ + σ ⋅ 1 − 2 ⋅ 0.5 0.5 ⋅ 0.5 = μ + σ ⋅ 0 0.25 = μ E[Y] = \mu + \sigma \cdot \frac{1 - 2\cdot0.5}{0.5\cdot0.5} = \mu + \sigma \cdot \frac{0}{0.25} = \mu E[Y]=μ+σ⋅0.5⋅0.51−2⋅0.5=μ+σ⋅0.250=μ
- 方差: Var ( Y ) = σ 2 ⋅ 1 − 1 + 0.5 0.25 ⋅ 0.25 = σ 2 ⋅ 0.5 0.0625 = 8 σ 2 \text{Var}(Y) = \sigma^2 \cdot \frac{1 - 1 + 0.5}{0.25 \cdot 0.25} = \sigma^2 \cdot \frac{0.5}{0.0625} = 8\sigma^2 Var(Y)=σ2⋅0.25⋅0.251−1+0.5=σ2⋅0.06250.5=8σ2
- 偏度: γ 1 = 0 \gamma_1 = 0 γ1=0(对称分布)
- 峰度: γ 2 = 6 ( 0.5 ) ( 0.5 ) 2 − 6 = 3 0.25 − 6 = 12 − 6 = 6 \gamma_2 = \frac{6(0.5)}{(0.5)^2} - 6 = \frac{3}{0.25} - 6 = 12 - 6 = 6 γ2=(0.5)26(0.5)−6=0.253−6=12−6=6
这表明即使是对称的拉普拉斯分布,其峰度(尖峰、厚尾程度)也远高于正态分布(峰度=3)。
-
不对称性的影响:
- 偏度 (Skewness):
- 当 τ < 0.5 \tau < 0.5 τ<0.5 时, ( 1 − 2 τ ) > 0 (1-2\tau) > 0 (1−2τ)>0,偏度 γ 1 > 0 \gamma_1 > 0 γ1>0,分布为右偏(长尾在右侧)。
- 当 τ > 0.5 \tau > 0.5 τ>0.5 时, ( 1 − 2 τ ) < 0 (1-2\tau) < 0 (1−2τ)<0,偏度 γ 1 < 0 \gamma_1 < 0 γ1<0,分布为左偏(长尾在左侧)。
- 偏度的绝对值在 τ \tau τ 接近 0 或 1 时变得非常大,意味着极端的分位数会导致非常陡峭的偏斜。
- 峰度 (Kurtosis):
- ALD 的峰度始终大于 0(相对于正态分布是尖峰厚尾的)。
- 峰度在 τ \tau τ 接近 0 或 1 时达到最大值,意味着在极端分位数下,分布不仅偏斜,而且尾部更厚。
- 偏度 (Skewness):
2.4 总结
非对称拉普拉斯分布的矩明确地展示了其核心特征:
- 可控的不对称性:通过一个参数 τ \tau τ 精确控制偏度的方向和程度。
- 尖峰厚尾:其峰度总是高于正态分布,使其能更好地拟合现实世界中具有异常值或极端情况的数据。
- 分位数与均值的分离:其 τ \tau τ-分位数 ( μ \mu μ) 和均值是两个不同的概念,这直接服务于分位数回归的目标——估计条件分位数而非条件均值。
这些性质使得它成为分位数回归一个非常自然且强大的概率框架。
3、非对称拉普拉斯和R语言可视化
# 定义一个函数来计算ALD的偏度
ald_skewness <- function(tau) {
numerator <- 2 * (1 - 2*tau) * (1 - tau + tau^2)
denominator <- (1 - 2*tau + 2*tau^2)^(3/2)
skewness <- numerator / denominator
return(skewness)
}
# 创建一个tau值的序列(从0.01到0.99,避免0和1的边界)
tau_values <- seq(0.01, 0.99, by = 0.01)
# 计算对应的偏度值
skewness_values <- ald_skewness(tau_values)
# 创建数据框以便于绘图
skewness_data <- data.frame(tau = tau_values, skewness = skewness_values)
# 加载ggplot2包
library(ggplot2)
# 绘制偏度随tau变化的曲线
ggplot(skewness_data, aes(x = tau, y = skewness)) +
geom_line(color = "steelblue", size = 1.2) +
geom_hline(yintercept = 0, linetype = "dashed", color = "red", size = 0.8) +
geom_vline(xintercept = 0.5, linetype = "dashed", color = "green", size = 0.8) +
labs(title = "非对称拉普拉斯分布 (ALD) 的偏度",
subtitle = expression(paste("偏度 ", gamma[1], " 随分位数参数 ", tau, " 的变化")),
x = expression(tau),
y = "偏度") +
theme_minimal() +
theme(plot.title = element_text(hjust = 0.5, size = 16, face = "bold"),
plot.subtitle = element_text(hjust = 0.5, size = 12),
axis.title = element_text(size = 12))
ggplot(skewness_data, aes(x = tau, y = skewness)) +
geom_line(color = "steelblue", size = 1.5) +
geom_hline(yintercept = 0, linetype = "dashed", color = "red", size = 0.8) +
geom_vline(xintercept = 0.5, linetype = "dashed", color = "green", size = 0.8) +
# 添加注释
annotate("text", x = 0.25, y = 3, label = "τ < 0.5\n右偏", color = "darkorange", size = 4) +
annotate("text", x = 0.75, y = -3, label = "τ > 0.5\n左偏", color = "purple", size = 4) +
annotate("text", x = 0.5, y = 5, label = "τ = 0.5\n对称", color = "darkgreen", size = 4) +
# 添加箭头指示
annotate("segment", x = 0.2, xend = 0.05, y = 8, yend = 10,
arrow = arrow(length = unit(0.3, "cm")), color = "darkorange", size = 1) +
annotate("segment", x = 0.8, xend = 0.95, y = -8, yend = -10,
arrow = arrow(length = unit(0.3, "cm")), color = "purple", size = 1) +
labs(title = "非对称拉普拉斯分布 (ALD) 的偏度特性",
x = expression(tau),
y = "偏度",
caption = "红色虚线:零偏度参考线\n绿色虚线:对称点 (τ = 0.5)") +
theme_minimal() +
theme(plot.title = element_text(hjust = 0.5, size = 16, face = "bold"),
plot.subtitle = element_text(hjust = 0.5, size = 10),
axis.title = element_text(size = 12),
plot.caption = element_text(hjust = 0, color = "gray50"))
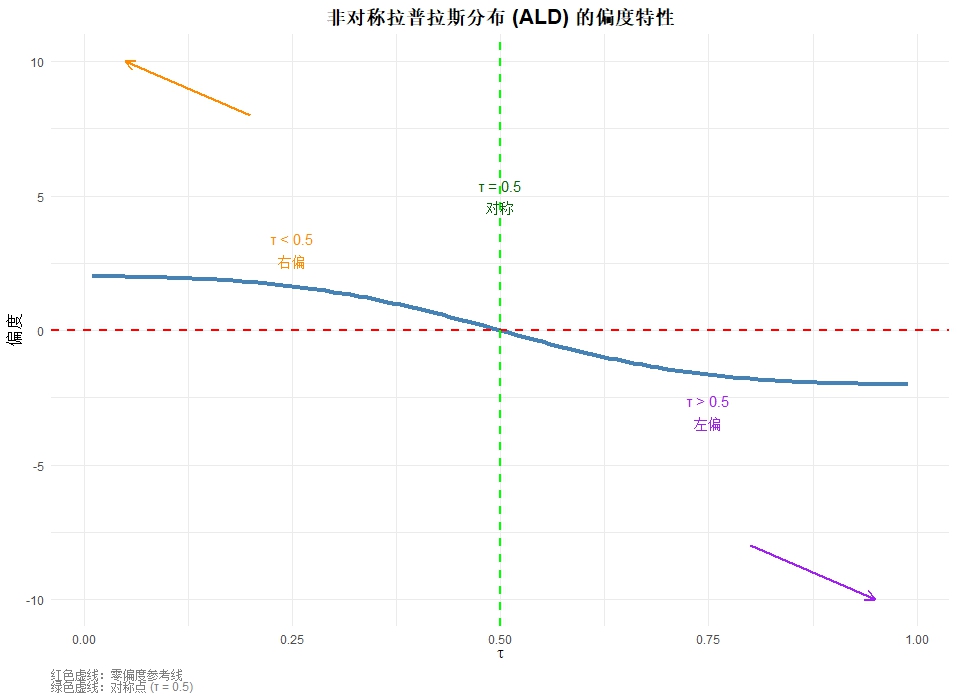
好的,我们可以使用R语言来可视化非对称拉普拉斯分布 (ALD) 的偏度如何随着分位数参数 τ \tau τ 的变化而变化。我们将使用之前推导出的偏度公式:
γ 1 = 2 ( 1 − 2 τ ) ( 1 − τ + τ 2 ) ( 1 − 2 τ + 2 τ 2 ) 3 / 2 \gamma_1 = \frac{2(1-2\tau)(1 - \tau + \tau^2)}{(1 - 2\tau + 2\tau^2)^{3/2}} γ1=(1−2τ+2τ2)3/22(1−2τ)(1−τ+τ2)
运行上述代码后,你会看到:
-
对称点:在 τ = 0.5 \tau = 0.5 τ=0.5 处(绿色虚线),偏度为 0,对应对称的拉普拉斯分布。
-
右偏区域 ( τ < 0.5 \tau < 0.5 τ<0.5):
- 偏度值为正
- 随着 τ \tau τ 趋近于 0,偏度急剧增大趋向于 +∞
- 这意味着分布有长长的右尾
-
左偏区域 ( τ > 0.5 \tau > 0.5 τ>0.5):
- 偏度值为负
- 随着 τ \tau τ 趋近于 1,偏度急剧减小趋向于 -∞
- 这意味着分布有长长的左尾
-
不对称性:曲线在 τ = 0.5 \tau = 0.5 τ=0.5 两侧并不完全对称,这表明 ALD 的偏度行为本身也是不对称的。
这个图像完美地展示了为什么 τ \tau τ 参数被称为"偏度参数"——它直接且强烈地控制着分布的形状和不对称程度,这正是分位数回归能够捕捉变量在不同分位点处不同关系的基础。
4、 其他应用
除了分位数回归,非对称拉普拉斯分布还用于:
- 金融:对股票收益率等金融数据进行建模,这些数据常常表现出尖峰、厚尾和不对称性。
- 信号处理:在需要处理具有不对称脉冲或噪声的信号时。
- 生存分析:对生存时间进行建模,尤其是在风险率不对称的情况下。
| 特性 | 描述 |
|---|---|
| 本质 | 拉普拉斯分布的非对称推广,由两个不同速率的指数分布拼接而成 |
| 关键参数 | 位置 μ(众数),尺度 σ,不对称参数 κ 或 τ |
| 主要特点 | 尖峰、厚尾、不对称,数学形式易于处理 |
| 核心应用 | 为分位数回归提供概率基础和计算工具 |
| 优势 | 在分位数建模中,其最大似然估计等价于最小化检查函数,非常自然和高效 |
简单来说,非对称拉普拉斯分布是将“对称”和“指数尾巴”这两个概念结合起来,用以描述现实世界中大量存在的不对称数据的最直接、最有力的工具之一。

欢迎加入DeepSeek 技术社区。在这里,你可以找到志同道合的朋友,共同探索AI技术的奥秘。
更多推荐



 29
29 0
0- 0



 已为社区贡献2条内容
已为社区贡献2条内容

所有评论(0)