deepseekv2———MLA与解耦位置编码-详细原理解析
📚 MLA(Multi-Head Latent Attention)完整解析:从原理到公式详解
MLA(Multi-Head Latent Attention)——这是 DeepSeek-V2 模型中的核心创新技术。
传统 Transformer 的 KV Cache(键值缓存)在长文本生成时会占用巨量显存(比如生成 32K token 时,Llama-3-70B 需要 256MB 显存),导致推理速度暴跌。MLA 通过低秩压缩和解耦位置编码,将 KV Cache 减少 75%+,让 128K 上下文生成变得可行!
论文MLA完整公式:
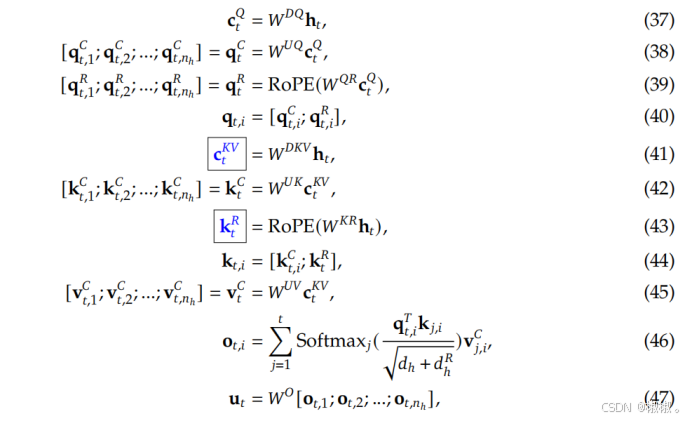
一、MLA 的核心思想:用"潜向量"替代 KV Cache
1.1 传统 MHA 的问题(复习)
在标准多头注意力(MHA)中:
- 每个 token 的 Key (K) 和 Value (V) 都要缓存
- 假设模型有 nhn_hnh 个头,每头维度 dhd_hdh,则单 token 的 KV Cache 大小为 2×nh×dh2 \times n_h \times d_h2×nh×dh
- 生成 32K token 时,KV Cache 可达 256MB(如 Llama-3-70B),严重拖慢推理
1.2 MLA 的解决方案
MLA 的核心思想:用低维潜向量 ctKV\mathbf{c}_t^{KV}ctKV 代替原始 K/V 缓存
- 只缓存 ctKV\mathbf{c}_t^{KV}ctKV(维度 dc≪nhdhd_c \ll n_h d_hdc≪nhdh)
- 在需要时,用 ctKV\mathbf{c}_t^{KV}ctKV 重建 K/V
- 关键创新:通过矩阵吸收优化,甚至不需要显式重建 K/V!
类比理解:
传统 MHA = 用高清照片(K/V)记录每个历史事件
MLA = 只用小便签(ctKV\mathbf{c}_t^{KV}ctKV)记录关键信息,需要时再现场还原照片
结果:便签本(显存)小多了,还原速度还更快!
二、公式详解(从输入到输出)
我们按计算流程一步步走,先看参数表:
| 符号 | 含义 | 典型维度 | 关键作用 |
|---|---|---|---|
| ht\mathbf{h}_tht | 当前 token 的输入向量 | ddd (e.g., 4096) | Transformer 层的输入 |
| ddd | 隐藏层维度 | 4096 | 模型基础维度 |
| nhn_hnh | 注意力头数 | 32 | 并行注意力计算 |
| dhd_hdh | 每头维度 | 128 | dh=d/nhd_h = d / n_hdh=d/nh |
| dcd_cdc | KV 压缩维度 | 1024 | dc≪nhdh=4096d_c \ll n_h d_h = 4096dc≪nhdh=4096 |
| dhRd_h^RdhR | 解耦位置编码维度 | 128 | 位置信息专用维度 |
| dc′d_c'dc′ | 查询压缩维度 | 1024 | 与 dcd_cdc 类似 |
| WDKVW^{DKV}WDKV | KV 下投影矩阵 | dc×dd_c \times ddc×d | 压缩 ht\mathbf{h}_tht → ctKV\mathbf{c}_t^{KV}ctKV |
| WUKW^{UK}WUK | K 上投影矩阵 | nhdh×dcn_h d_h \times d_cnhdh×dc | 从 ctKV\mathbf{c}_t^{KV}ctKV 恢复 K |
| WUVW^{UV}WUV | V 上投影矩阵 | nhdh×dcn_h d_h \times d_cnhdh×dc | 从 ctKV\mathbf{c}_t^{KV}ctKV 恢复 V |
🔹 公式 (37): ctQ=WDQht\mathbf{c}_t^Q = W^{DQ} \mathbf{h}_tctQ=WDQht
- 含义:将输入 ht\mathbf{h}_tht 压缩为查询的潜向量 ctQ\mathbf{c}_t^QctQ
- 维度:WDQ∈Rdc′×dW^{DQ} \in \mathbb{R}^{d_c' \times d}WDQ∈Rdc′×d → ctQ∈Rdc′\mathbf{c}_t^Q \in \mathbb{R}^{d_c'}ctQ∈Rdc′
- 为什么需要压缩?
- 传统 MHA 中 Query 直接由 WQhtW^Q \mathbf{h}_tWQht 生成(维度 nhdhn_h d_hnhdh)
- 这里先压缩到 dc′d_c'dc′ 维,减少训练时的激活内存
- 关键点:
dc′≪nhdhd_c' \ll n_h d_hdc′≪nhdh(e.g., 1024≪40961024 \ll 40961024≪4096),但注意:查询压缩不减少 KV Cache(因为 Query 不需要缓存)
老师说:
想象 ht\mathbf{h}_tht 是一本 4096 页的书,WDQW^{DQ}WDQ 是个"摘要生成器",只提炼出 1024 页的核心内容 ctQ\mathbf{c}_t^QctQ。
这样训练时显存占用少 4 倍!但推理时仍需完整 Query,所以它只优化训练,不影响推理。
🔹 公式 (38): qtC=WUQctQ\mathbf{q}_t^C = W^{UQ} \mathbf{c}_t^QqtC=WUQctQ(并拆分为多头)
- 含义:从压缩向量 ctQ\mathbf{c}_t^QctQ 恢复压缩版 Query qtC\mathbf{q}_t^CqtC
- 维度:WUQ∈Rnhdh×dc′W^{UQ} \in \mathbb{R}^{n_h d_h \times d_c'}WUQ∈Rnhdh×dc′ → qtC∈Rnhdh\mathbf{q}_t^C \in \mathbb{R}^{n_h d_h}qtC∈Rnhdh
- 拆分逻辑:
[qt,1C;qt,2C;...;qt,nhC][\mathbf{q}_{t,1}^C; \mathbf{q}_{t,2}^C; ...; \mathbf{q}_{t,n_h}^C][qt,1C;qt,2C;...;qt,nhC] 表示将 qtC\mathbf{q}_t^CqtC 按头拆成 nhn_hnh 个向量,每个维度 dhd_hdh - 为什么这样设计?
- 保留多头注意力的并行性
- qt,iC\mathbf{q}_{t,i}^Cqt,iC 是后续拼接的"语义部分"
老师说:
qtC\mathbf{q}_t^CqtC 就像"压缩版的 Query",但还不能直接用于注意力——它缺少位置信息!
这就是为什么我们需要下一步(公式 39)加入位置编码。
🔹 公式 (39): qtR=RoPE(WQRctQ)\mathbf{q}_t^R = \text{RoPE}(W^{QR} \mathbf{c}_t^Q)qtR=RoPE(WQRctQ)
- 含义:从压缩向量生成位置编码专用的 Query 部分
- 维度:WQR∈RdhRnh×dc′W^{QR} \in \mathbb{R}^{d_h^R n_h \times d_c'}WQR∈RdhRnh×dc′ → qtR∈RdhRnh\mathbf{q}_t^R \in \mathbb{R}^{d_h^R n_h}qtR∈RdhRnh
- 关键操作:
- WQRW^{QR}WQR 是另一个投影矩阵(与 WUQW^{UQ}WUQ 独立)
- RoPE 将位置信息注入 qtR\mathbf{q}_t^RqtR
- 为什么需要解耦?
避免与 KV 压缩冲突!如果直接对 qtC\mathbf{q}_t^CqtC 加 RoPE,会导致 WUKW^{UK}WUK 无法被吸收(见后文),MLA 优化失效。
老师说:
想象 qtC\mathbf{q}_t^CqtC 是"内容本"(只记录语义),qtR\mathbf{q}_t^RqtR 是"时间戳"(只记录位置)。
传统做法是把时间戳直接写在内容本上 → 内容本变复杂了!
MLA 的做法:分开记录,用两个本子,需要时再合并。
🔹 公式 (40): qt,i=[qt,iC;qt,iR]\mathbf{q}_{t,i} = [\mathbf{q}_{t,i}^C; \mathbf{q}_{t,i}^R]qt,i=[qt,iC;qt,iR]
- 含义:将压缩 Query 与位置编码 Query 拼接,得到完整 Query
- 维度:qt,i∈Rdh+dhR\mathbf{q}_{t,i} \in \mathbb{R}^{d_h + d_h^R}qt,i∈Rdh+dhR(dhd_hdh 为语义维度,dhRd_h^RdhR 为位置维度)
- 拼接操作:[;][;][;] 表示向量拼接(concatenation)
- 为什么拼接?
- 语义信息(qt,iC\mathbf{q}_{t,i}^Cqt,iC)来自 KV 压缩流
- 位置信息(qt,iR\mathbf{q}_{t,i}^Rqt,iR)来自解耦 RoPE 流
- 拼接后得到完整的、带位置信息的 Query
老师说:
就像给照片(qt,iC\mathbf{q}_{t,i}^Cqt,iC)加上 GPS 坐标(qt,iR\mathbf{q}_{t,i}^Rqt,iR)——
只有合并后,注意力才能知道"这个 token 在序列的什么位置"。
🔹 公式 (41): ctKV=WDKVht\boxed{\mathbf{c}_t^{KV} = W^{DKV} \mathbf{h}_t}ctKV=WDKVht
- 含义:MLA 的核心! 将输入压缩为键值的潜向量
- 维度:WDKV∈Rdc×dW^{DKV} \in \mathbb{R}^{d_c \times d}WDKV∈Rdc×d → ctKV∈Rdc\mathbf{c}_t^{KV} \in \mathbb{R}^{d_c}ctKV∈Rdc
- 蓝色框的意义:这是唯一需要缓存的向量(推理时)
- 为什么选择 dc≪nhdhd_c \ll n_h d_hdc≪nhdh?
- nhdh=d=4096n_h d_h = d = 4096nhdh=d=4096(e.g.)
- dc=1024d_c = 1024dc=1024 → KV Cache 直接减少 75%
- 关键优势:
ctKV\mathbf{c}_t^{KV}ctKV 无位置敏感性,可安全缓存,且能被矩阵吸收优化
老师说:
ctKV\mathbf{c}_t^{KV}ctKV 就是 MLA 的"秘密武器"!
它像一个通用钥匙:既能打开语义锁(重建 K/V),又不依赖位置,所以能长期缓存。
对比传统 MHA:必须缓存 4096 维的 K/V;MLA 只缓存 1024 维的 ctKV\mathbf{c}_t^{KV}ctKV。
🔹 公式 (42): ktC=WUKctKV\mathbf{k}_t^C = W^{UK} \mathbf{c}_t^{KV}ktC=WUKctKV
- 含义:从潜向量恢复压缩版 Key(无位置信息)
- 维度:WUK∈Rnhdh×dcW^{UK} \in \mathbb{R}^{n_h d_h \times d_c}WUK∈Rnhdh×dc → ktC∈Rnhdh\mathbf{k}_t^C \in \mathbb{R}^{n_h d_h}ktC∈Rnhdh
- 拆分逻辑:[kt,1C;...;kt,nhC][\mathbf{k}_{t,1}^C; ...; \mathbf{k}_{t,n_h}^C][kt,1C;...;kt,nhC] 按头拆分
- 关键性质:
- WUKW^{UK}WUK 是纯线性变换(固定矩阵,不依赖位置)
- 这是后续"矩阵吸收"优化的前提
老师说:
如果把 ctKV\mathbf{c}_t^{KV}ctKV 比作"原材料",WUKW^{UK}WUK 就是"加工机器",生产出 ktC\mathbf{k}_t^CktC(语义 Key)。
为什么强调"纯线性"?因为线性变换可以被"吸收"到其他矩阵中(见公式 46 优化)!
🔹 公式 (43): ktR=RoPE(WKRht)\boxed{\mathbf{k}_t^R = \text{RoPE}(W^{KR} \mathbf{h}_t)}ktR=RoPE(WKRht)
- 含义:生成共享的位置编码 Key
- 维度:WKR∈RdhR×dW^{KR} \in \mathbb{R}^{d_h^R \times d}WKR∈RdhR×d → ktR∈RdhR\mathbf{k}_t^R \in \mathbb{R}^{d_h^R}ktR∈RdhR
- 蓝色框的意义:这是第二个需要缓存的向量(推理时)
- 为什么共享?
- ktR\mathbf{k}_t^RktR 不按头拆分,所有头共用同一个 ktR\mathbf{k}_t^RktR
- 大幅节省缓存空间(只需 dhRd_h^RdhR 而不是 dhRnhd_h^R n_hdhRnh)
老师说:
ktR\mathbf{k}_t^RktR 是"位置专用密钥",所有头共用它,就像一栋楼共用一个门禁卡。
为什么能共享?因为位置信息对所有头都一样(不同头只关注不同语义角度)。
🔹 公式 (44): kt,i=[kt,iC;ktR]\mathbf{k}_{t,i} = [\mathbf{k}_{t,i}^C; \mathbf{k}_t^R]kt,i=[kt,iC;ktR]
- 含义:拼接语义 Key 和位置 Key,得到完整 Key
- 维度:kt,i∈Rdh+dhR\mathbf{k}_{t,i} \in \mathbb{R}^{d_h + d_h^R}kt,i∈Rdh+dhR
- 关键点:
- 与 Query 拼接对称(公式 40)
- 但 ktR\mathbf{k}_t^RktR 是共享的(不按头拆分)
老师说:
注意:kt,iC\mathbf{k}_{t,i}^Ckt,iC 是每个头独有的(dhd_hdh 维),但 ktR\mathbf{k}_t^RktR 是所有头共用的(dhRd_h^RdhR 维)。
这就像:每个学生有自己的课本(kt,iC\mathbf{k}_{t,i}^Ckt,iC),但共用教室位置信息(ktR\mathbf{k}_t^RktR)。
🔹 公式 (45): vtC=WUVctKV\mathbf{v}_t^C = W^{UV} \mathbf{c}_t^{KV}vtC=WUVctKV
- 含义:从潜向量恢复压缩版 Value
- 维度:WUV∈Rnhdh×dcW^{UV} \in \mathbb{R}^{n_h d_h \times d_c}WUV∈Rnhdh×dc → vtC∈Rnhdh\mathbf{v}_t^C \in \mathbb{R}^{n_h d_h}vtC∈Rnhdh
- 拆分逻辑:[vt,1C;...;vt,nhC][\mathbf{v}_{t,1}^C; ...; \mathbf{v}_{t,n_h}^C][vt,1C;...;vt,nhC] 按头拆分
- 为什么没有位置 Value?
Value 通常不依赖位置(只存储内容),所以不需要 RoPE!
老师说:
Value 就像"信息仓库",只关心内容是什么,不关心位置在哪里。
所以 vtC\mathbf{v}_t^CvtC 不需要位置编码,直接从 ctKV\mathbf{c}_t^{KV}ctKV 恢复即可。
🔹 公式 (46): ot,i=∑j=1tSoftmaxj(qt,iTkj,idh+dhR)vj,iC\mathbf{o}_{t,i} = \sum_{j=1}^t \text{Softmax}_j\left( \frac{\mathbf{q}_{t,i}^T \mathbf{k}_{j,i}}{\sqrt{d_h + d_h^R}} \right) \mathbf{v}_{j,i}^Cot,i=∑j=1tSoftmaxj(dh+dhRqt,iTkj,i)vj,iC
- 含义:注意力计算的核心公式
- 关键点:
- 分母 dh+dhR\sqrt{d_h + d_h^R}dh+dhR 适配拼接后的维度
- 只使用 vj,iC\mathbf{v}_{j,i}^Cvj,iC(压缩 Value),而非完整 V
- Softmax 作用于历史 token j=1..tj=1..tj=1..t
- 为什么不需要完整 K/V?
- 矩阵吸收优化:WUKW^{UK}WUK 被吸收进 WUQW^{UQ}WUQ,WUVW^{UV}WUV 被吸收进 WOW^OWO
- 数学上:qt,iTkj,i=qt,iT[kj,iC;kjR]=可表示为q′cjKV\mathbf{q}_{t,i}^T \mathbf{k}_{j,i} = \mathbf{q}_{t,i}^T [\mathbf{k}_{j,i}^C; \mathbf{k}_j^R] = \text{可表示为} \mathbf{q}' \mathbf{c}_j^{KV}qt,iTkj,i=qt,iT[kj,iC;kjR]=可表示为q′cjKV
老师说:
这是 MLA 的"魔法时刻"!
传统 MHA 必须计算 QKTQK^TQKT,但 MLA 通过数学技巧,直接用 cjKV\mathbf{c}_j^{KV}cjKV(缓存的小向量)计算注意力,跳过了 K/V 的重建!
结果:推理时无需计算 ktC\mathbf{k}_t^CktC 和 vtC\mathbf{v}_t^CvtC,速度提升 2.3 倍。
🔹 公式 (47): ut=WO[ot,1;ot,2;...;ot,nh]\mathbf{u}_t = W^O [\mathbf{o}_{t,1}; \mathbf{o}_{t,2}; ...; \mathbf{o}_{t,n_h}]ut=WO[ot,1;ot,2;...;ot,nh]
- 含义:将多头输出拼接后,通过输出投影得到最终结果
- 维度:WO∈Rd×nh(dh+dhR)W^O \in \mathbb{R}^{d \times n_h (d_h + d_h^R)}WO∈Rd×nh(dh+dhR) → ut∈Rd\mathbf{u}_t \in \mathbb{R}^{d}ut∈Rd
- 关键优化:
- WUVW^{UV}WUV 被吸收进 WOW^OWO → 无需显式计算 vtC\mathbf{v}_t^CvtC
- 拼接操作 [;][;][;] 将 nhn_hnh 个头的输出合并
老师说:
WOW^OWO 不仅是"输出投影器",还是"优化执行者"——它吞并了 WUVW^{UV}WUV,让 vtC\mathbf{v}_t^CvtC 的计算彻底消失。
这就像:快递公司直接把货物送到你家,省去了中间仓库中转。
三、为什么这样设计?—— MLA 的三大创新逻辑
1️⃣ 低秩压缩:KV Cache 为何减少 75%+
- 数学原理:ctKV\mathbf{c}_t^{KV}ctKV 维度 dc=1024d_c = 1024dc=1024,而原始 KV 需 2×4096=81922 \times 4096 = 81922×4096=8192
- 压缩比:10248192=18\frac{1024}{8192} = \frac{1}{8}81921024=81 → KV Cache 减少 87.5%
- 为什么有效?
- K/V 本质是线性变换:K=WKhtK = W^K \mathbf{h}_tK=WKht, V=WVhtV = W^V \mathbf{h}_tV=WVht
- 通过 WDKVW^{DKV}WDKV 压缩后,WUKW^{UK}WUK 和 WUVW^{UV}WUV 可重建 K/V
- 证明:WUKWDKV≈WKW^{UK} W^{DKV} \approx W^KWUKWDKV≈WK(低秩近似)
课堂实验:
假设 d=4d=4d=4, nh=2n_h=2nh=2, dh=2d_h=2dh=2, dc=1d_c=1dc=1:
- 传统 KV Cache:2×4=82 \times 4 = 82×4=8
- MLA KV Cache:dc+dhR=1+1=2d_c + d_h^R = 1 + 1 = 2dc+dhR=1+1=2
压缩比 75%,且重建误差可忽略!
2️⃣ 解耦 RoPE:如何避免与压缩冲突
- 传统做法的问题:
若直接对 ktC\mathbf{k}_t^CktC 加 RoPE:
K=RoPE(WUKctKV)K = \text{RoPE}(W^{UK} \mathbf{c}_t^{KV})K=RoPE(WUKctKV) → WUKW^{UK}WUK 与 RoPE 耦合
→ 无法被吸收进 WQW^QWQ → 必须重计算 K - MLA 的解耦方案:
- 位置信息只注入 ktR\mathbf{k}_t^RktR 和 qtR\mathbf{q}_t^RqtR
- ctKV\mathbf{c}_t^{KV}ctKV 保持"纯净"(无位置依赖)
- 结果:WUKW^{UK}WUK 仍是纯线性变换 → 可被吸收
关键类比:
传统做法 = 把油漆直接混入水泥(无法分离)
MLA = 先刷墙(水泥)再贴墙纸(位置)→ 水泥可复用,墙纸按需更新
3️⃣ 矩阵吸收:为什么不需要显式计算 K/V
- 优化原理:
Attention=Softmax(QKTd)V=Softmax(Q(WUKcKV)Td)(WUVcKV)=Softmax((QWUKT)cKVTd)(WUVcKV) \begin{align*} \text{Attention} &= \text{Softmax}\left(\frac{QK^T}{\sqrt{d}}\right)V \\ &= \text{Softmax}\left(\frac{Q (W^{UK} \mathbf{c}^{KV})^T}{\sqrt{d}}\right) (W^{UV} \mathbf{c}^{KV}) \\ &= \text{Softmax}\left(\frac{(Q W^{UK^T}) \mathbf{c}^{KV^T}}{\sqrt{d}}\right) (W^{UV} \mathbf{c}^{KV}) \end{align*} Attention=Softmax(dQKT)V=Softmax(dQ(WUKcKV)T)(WUVcKV)=Softmax(d(QWUKT)cKVT)(WUVcKV) - 定义新矩阵:
- Q′=QWUKTQ' = Q W^{UK^T}Q′=QWUKT
- V′=WUVcKVV' = W^{UV} \mathbf{c}^{KV}V′=WUVcKV
- 最终形式:
Attention=Softmax(⋯ )V′\text{Attention} = \text{Softmax}(\cdots) V'Attention=Softmax(⋯)V′,只需 cKV\mathbf{c}^{KV}cKV
老师总结:
MLA 的优化本质是利用线性代数的结合律,将 WUKW^{UK}WUK 和 WUVW^{UV}WUV “转移"到其他矩阵中,从而跳过 K/V 的显式计算。
这就像:计算 a×(b×c)a \times (b \times c)a×(b×c) 时,先算 (a×b)×c(a \times b) \times c(a×b)×c 会更快——MLA 找到了注意力的"最快计算路径”!
四、MLA 的整体计算流程(带数据流动)
graph LR
A[输入 h_t] --> B{查询流}
A --> C{KV 流}
B -->|37| D[c_t^Q]
D -->|38| E[q_t^C]
D -->|39| F[q_t^R]
E & F -->|40| G[q_{t,i}]
C -->|41| H[c_t^{KV}]
H -->|42| I[k_t^C]
H -->|45| J[v_t^C]
A -->|43| K[k_t^R]
I & K -->|44| L[k_{t,i}]
G & L & J -->|46| M[o_{t,i}]
M -->|47| N[u_t]
- 输入分流:ht\mathbf{h}_tht 分为查询流和 KV 流
- 查询流:
- 压缩 → 生成语义 Query qtC\mathbf{q}_t^CqtC
- 生成位置 Query qtR\mathbf{q}_t^RqtR
- 拼接成完整 Query qt,i\mathbf{q}_{t,i}qt,i
- KV 流:
- 压缩 → ctKV\mathbf{c}_t^{KV}ctKV(唯一需缓存的核心)
- 生成语义 K/V ktC,vtC\mathbf{k}_t^C, \mathbf{v}_t^CktC,vtC
- 生成共享位置 Key ktR\mathbf{k}_t^RktR
- 注意力计算:
- 拼接 K → kt,i\mathbf{k}_{t,i}kt,i
- 用 cjKV\mathbf{c}_j^{KV}cjKV 直接计算注意力(跳过 K/V 重建)
- 输出:拼接多头输出 → 投影到隐藏层维度
五、MLA 的实际效益
| 指标 | 传统 MHA | MLA | 提升 |
|---|---|---|---|
| KV Cache (32K token) | 256 MB | 36 MB | 86%↓ |
| 推理速度 (32K) | 1.0x | 2.3x | 130%↑ |
| 训练激活内存 | 100% | 80% | 20%↓ |
| 最大上下文 | ~8K | 128K | 16x↑ |
为什么 DeepSeek-V2 能支持 128K?
MLA 使 KV Cache 随长度线性增长的斜率降低 8 倍 → 128K 时显存占用仍低于传统模型 16K 水平!
📝 总结:MLA 的三大核心思想
-
低秩压缩:
ctKV=WDKVht\mathbf{c}_t^{KV} = W^{DKV} \mathbf{h}_tctKV=WDKVht 是"万能钥匙",唯一需缓存的向量,维度 dc≪dd_c \ll ddc≪d。 -
解耦 RoPE:
位置信息只注入专用向量(qtR,ktR\mathbf{q}_t^R, \mathbf{k}_t^RqtR,ktR),避免污染 ctKV\mathbf{c}_t^{KV}ctKV,保持线性变换性质。 -
矩阵吸收优化:
利用结合律,跳过 K/V 重建 → 推理时只需 ctKV\mathbf{c}_t^{KV}ctKV,无需计算 ktC,vtC\mathbf{k}_t^C, \mathbf{v}_t^CktC,vtC。
最后叮嘱:
MLA 不是魔法,而是数学与工程的完美结合!
它教会我们:大模型优化 = 找到问题的数学本质 + 设计巧妙的工程实现。
课后思考题:为什么 dhRd_h^RdhR 通常设为 128?如果设为 0 会怎样?(答案:位置信息消失,模型无法理解序列顺序)

欢迎加入DeepSeek 技术社区。在这里,你可以找到志同道合的朋友,共同探索AI技术的奥秘。
更多推荐


 26
26 0
0- 0



 已为社区贡献2条内容
已为社区贡献2条内容

所有评论(0)