deepseek3.2 exp注意力优化机制DSA
DeepSeek-V3.2-Exp引入了DSA(DeepSeek Sparse Attention)稀疏注意力机制,在MLA(Multi-head Latent Attention)低秩压缩的基础上进一步优化长序列处理。DSA通过闪电索引器动态计算token相关性,仅选择最相关的k个token进行注意力计算,将复杂度从O(L²)降至O(Lk)。该机制采用两阶段训练:先稠密训练对齐索引器,再稀疏优化
deepseek3.2 exp版本发布了,里面有一项注意力优化机制DSA(DeepSeek Sparse Attention)。DeepSeek Sparse Attention (DSA) 是在 DeepSeek-V3.2-Exp 中引入的一种稀疏注意力机制,而 MLA(Multi-head Latent Attention)是 DeepSeek-V3.1-Terminus 中使用的多头潜在注意力机制。DSA 并不是完全取代 MLA,而是在 MLA 的基础上进行扩展和优化,使其具备稀疏计算的能力,从而在长上下文场景中显著提升效率。为了更好的理解优化机制,先了解MLA。
MLA 全称 Multi-Head Latent Attention,即多头潜在注意力机制。它是 DeepSeek 团队为了优化 Transformer 模型在处理长序列时的效率和性能而提出的一种创新的注意力机制。理解 MLA,我们首先提下传统 Transformer 模型中的多头注意力机制 (Multi-Head Attention, MHA)。MHA 允许模型同时关注输入序列的不同部分,是 Transformer 模型成功的关键。然而,MHA 有一个显著的缺点:随着输入序列长度的增加,一个名为 KV 缓存 (Key-Value Cache) 的东西会线性增长,导致:内存占用巨大:尤其是在处理长文本或多轮对话时,KV 缓存会消耗大量显存。计算效率降低:每次生成新的内容,都需要重新计算和关注整个不断增长的 KV 缓存。为了解决这个问题,业界先后提出了 MQA (Multi-Query Attention) 和 GQA (Grouped-Query Attention) 等技术,它们通过共享一部分“键 (Key)”和“值 (Value)”来减小 KV 缓存。而 DeepSeek 的 MLA 则采用了更进一步的思路。
MLA 的核心思想是低秩联合压缩。它不再存储完整的、高维度的“键”和“值”,而是将它们压缩到一个低维的潜在空间中。将之想象成“抓重点”:传统 MHA:需要记住一篇文章里的每一个字词(完整的 KV 缓存)。
MLA:只记住这篇文章的核心思想和关键信息点(压缩后的潜在变量)。
技术实现步骤:
压缩 K 和 V:将高维度的“键 (Key)”和“值 (Value)”矩阵,通过一个可学习的线性变换,投影(压缩)到一个低维的潜在空间,生成一个紧凑的潜在变量 Z。
缓存潜在变量:在推理过程中,模型只需要缓存这个小得多的潜在变量 Z,而不是庞大的完整 KV 矩阵。
压缩 Q:同样地,对当前的“查询 (Query)”向量也进行类似的压缩处理。
注意力计算:在低维的潜在空间中,计算压缩后的 Q 和潜在变量 Z 之间的注意力权重,并用于最终的计算。
这个优化机制显著减少内存占用:由于 KV 缓存被大幅压缩,使得在有限的硬件资源(如 GPU 显存)下运行更大、更强的模型成为可能。大幅提升推理效率:计算量减少,推理速度显著加快。低成本:更少的硬件需求和更快的推理速度,直接意味着更低的训练和部署成本。
解耦式 RoPE(旋转位置编码):
RoPE 对于保持位置信息非常重要,但直接应用于压缩后的 Key 会与低秩结构产生兼容性问题。MLA 的创新在于将 RoPE 与低秩压缩解耦。
MLA 的解决方案:拆分 Query 和 Key:将原始的 Q 和 K 拆分为与位置无关的部分和专门用于携带 RoPE 位置信息的部分。共享位置键:引入一个共享的 Key 向量 ,并仅对这个共享向量应用 RoPE。分离计算:注意力分数的计算被分为两部分:内容相关性:由未经 RoPE 的 Q1和从潜在向量重构的 K1计算。位置相关性:由经过 RoPE 的 Q2和共享的、经过 RoPE 的 K2计算。
DSA 基于 MLA 实现,DSA 使用了 MLA 的 MQA(Multi-Query Attention)模式,即每个潜在向量(key-value 条目)在查询 token 的所有注意力头之间共享。这种设计使得 DSA 能够利用 MLA 已经具备的低维潜在表示能力,同时通过稀疏选择机制进一步减少计算和内存开销。
DSA 扩展了 MLA 的稀疏能力。虽然 MLA 通过潜在表示压缩了 KV 缓存,但其注意力计算仍然是稠密的,即每个查询仍然需要与序列中所有之前的 token 进行交互。而 DSA 引入了:
闪电索引器(Lightning Indexer):动态计算每个查询 token 与之前 token 的相关性分数,并仅选择最相关的 k 个 token。
细粒度 token 选择机制:仅对被选中的 token 进行注意力计算,从而将注意力复杂度从 O(L²) 降低到 O(Lk),其中 k ≪ L。
因此,DSA 可以视为 MLA 的一个稀疏化扩展,它保留了 MLA 的潜在表示优势,同时通过动态稀疏选择机制进一步提升了长序列下的效率。
DeepSeek Sparse Attention (DSA) 的详细解析 DSA 的核心目标是在长上下文场景中显著降低计算和内存开销,而不会显著损害模型性能。其架构主要由两个部分组成:
- 闪电索引器(Lightning Indexer)
闪电索引器负责计算查询 token ht与之前每个 token hs之间的相关性分数 It,s,其计算公式为:
It,s=j=1∑HIwt,jI⋅ReLU(qt,jI⋅ksI)
其中:
HI是索引器的头数,
qt,jI和 wt,jI是从查询 token ht中提取的,
ksI是从之前 token hs中提取的。
该索引器使用 ReLU 激活函数以提升计算效率,并可以在 FP8 精度下运行,从而在保证效果的同时最大化吞吐。
2. 细粒度 Token 选择机制
基于索引器计算出的分数 {It,s},DSA 仅保留分数最高的 k 个 token 对应的 key-value 条目 {cs},然后在这些稀疏选择的条目上执行注意力计算:
ut=Attention(ht,{cs}s∈Top-k(It,:))
这一机制将注意力计算量从 O(L²) 降至 O(Lk),从而在长序列推理中显著节省内存和计算时间。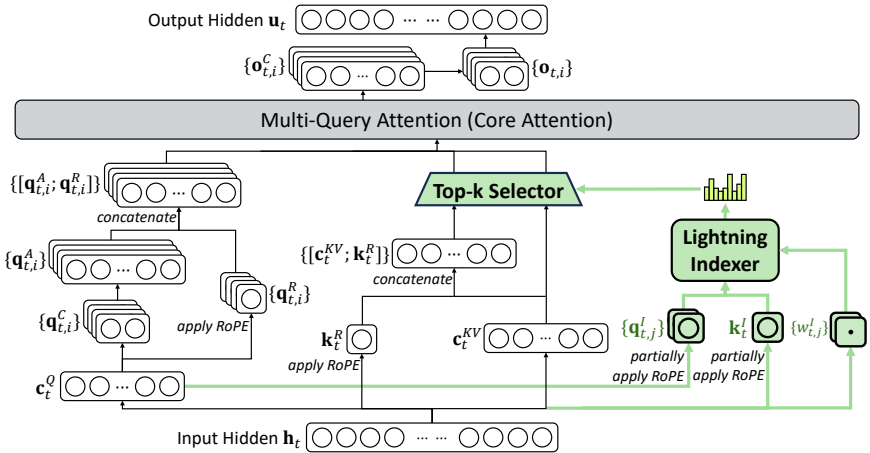
为了让 DSA 有效工作,DeepSeek-V3.2-Exp 采用了两阶段训练策略:
- 稠密预热阶段(Dense Warm-up Stage)
保持稠密注意力,冻结模型参数,仅训练索引器。
使用 KL 散度损失对齐索引器输出和主注意力 - 稀疏训练阶段(Sparse Training Stage)
引入 token 选择机制,优化所有模型参数,使模型适应 DSA 的稀疏模式。
索引器输入被截断(detach),索引器仅通过 LI进行训练,而主模型则通过语言建模损失进行优化。
总结
DSA 是 DeepSeek 团队为了进一步优化长上下文处理而提出的稀疏注意力机制,它构建在 MLA 的基础之上,通过动态 token 选择显著降低了计算和内存开销。其核心创新在于:
1.闪电索引器(高效计算相关性),
1.细粒度 token 选择(仅处理最相关的 token),
1.与 MLA 兼容的稀疏化扩展(保留潜在表示,增强稀疏计算能力)。
这使得 DeepSeek-V3.2-Exp 在长上下文任务中实现了更高的效率,同时保持了与 DeepSeek-V3.1-Terminus 相当的性能。

欢迎加入DeepSeek 技术社区。在这里,你可以找到志同道合的朋友,共同探索AI技术的奥秘。
更多推荐



 7
7 0
0- 0



 已为社区贡献1条内容
已为社区贡献1条内容

所有评论(0)