llama.cpp部署deepseek-r1-8b模型
本文介绍了使用llama.cpp运行GGUF模型的方法:1.下载预编译二进制包并解压;2.获取模型GGUF文件(可通过ollama下载);3.通过cmd窗口或浏览器运行模型,分别使用llama-completion.exe和llama-server.exe命令;4.当模型文件与程序不在同一目录时,可用相对路径指定模型位置。操作步骤包括命令行参数设置和浏览器访问127.0.0.1:8080实现图形化
一、下载llama.cpp
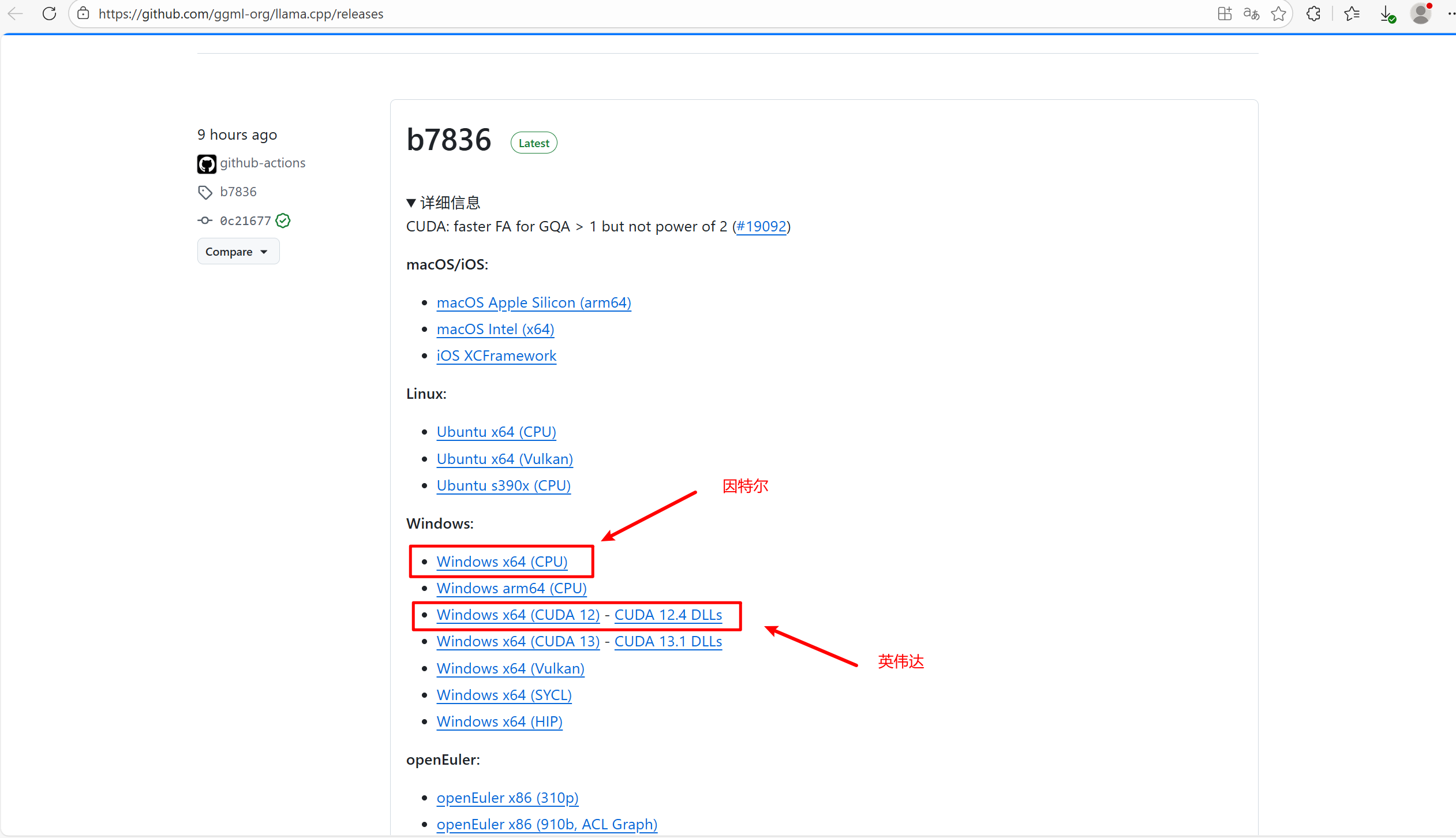
1、下载预编译二进制包:在 llama.cpp 的 GitHub Release 页面,地址如下:https://github.com/ggml-org/llama.cpp/releases
2、查看自己的显卡,英伟达的选CUDA,英特尔的选AVX
补充:打开cmd命令窗口,输入nvidia-smi(NVIDIA 独立显卡专用的命令,其他显卡不认),可以查看驱动支持的最高 CUDA 版本,最好选择比自己版本低的。
nvidia-smi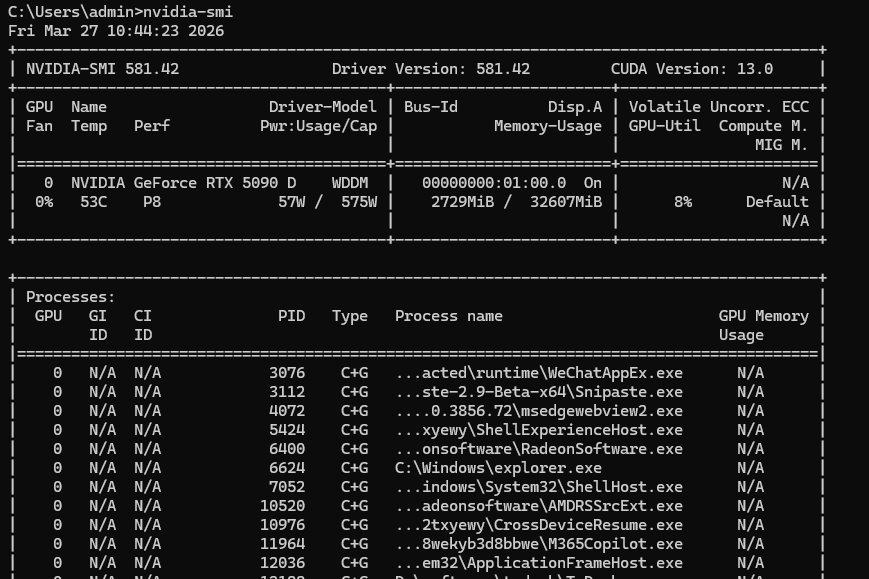
另外,验证自己电脑是否有CUDA工具包,打开cmd命令窗口,输入nvcc --version
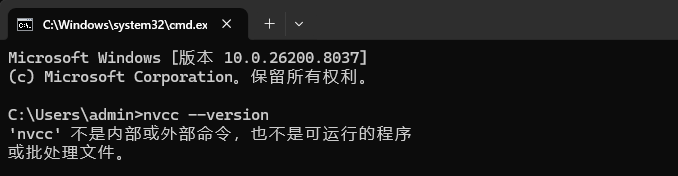
如果显示不是内容命令,需要下载CUDA工具包:
官网:https://developer.nvidia.com/cuda-downloads

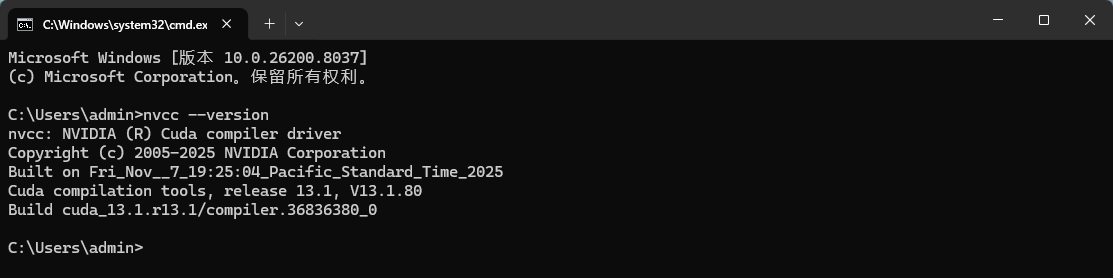
安装完毕后,再次输入:nvcc --version
3、下载后的压缩包如下

4、解压文件
二、下载(获取)模型GGUF文件
1、在ollama下载的模型中获取
①在模型文件夹中找到blobs,根据文件的大小可以找出想要的模型;
②复制一个模型文件到llama.cpp文件夹中(或者自己创建的llama.cpp_models文件夹),并重命名那个模型文件,后缀名为.gguf。
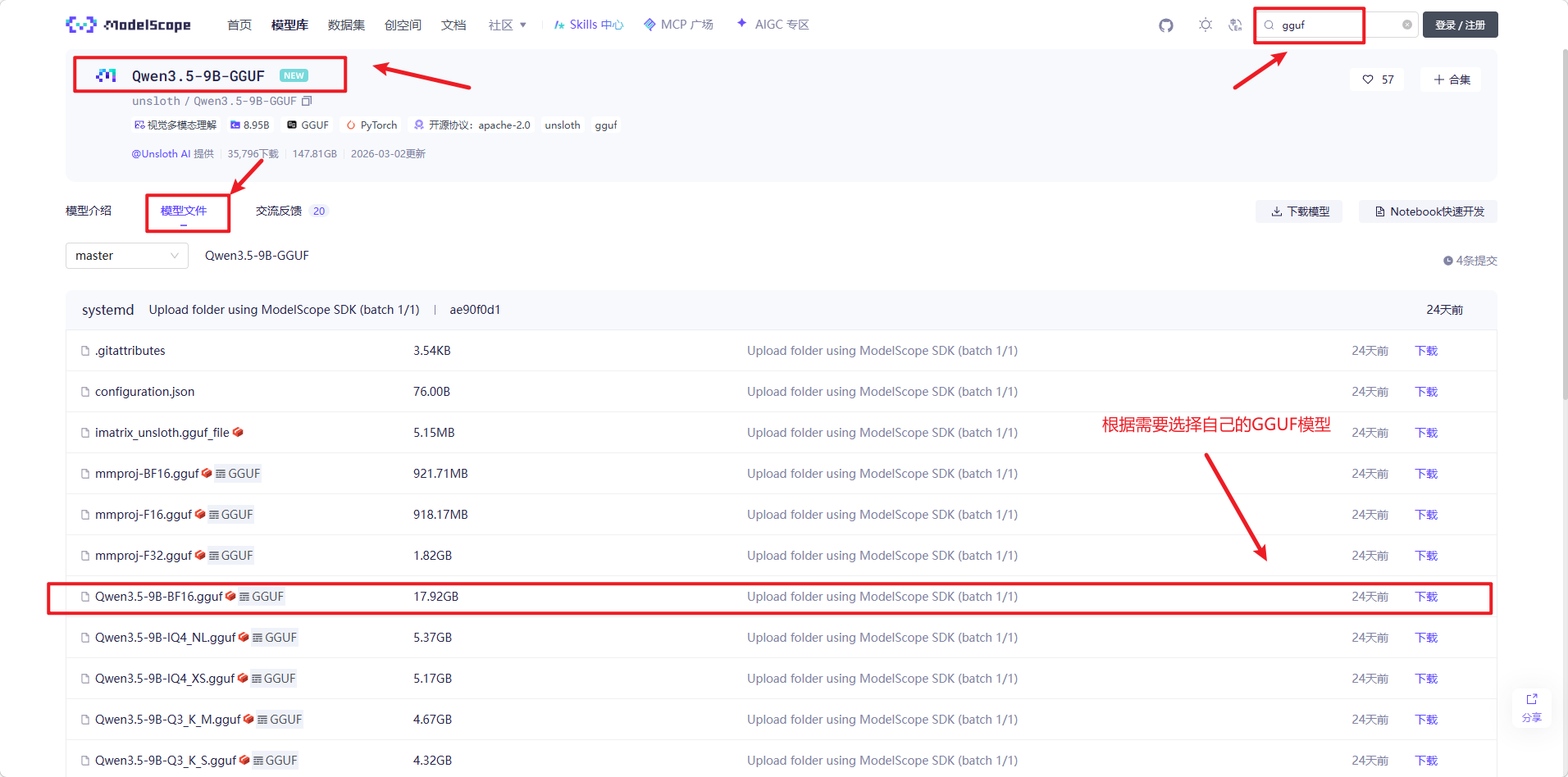
2、在魔搭社区下载,官网:https://www.modelscope.cn/home
①在搜索框搜索GGUF;
②选择模型文件,GGUF各版本模型都在这个文件里,然后选择下载。
三、运行模型GGUF文件
(一)cmd窗口对话
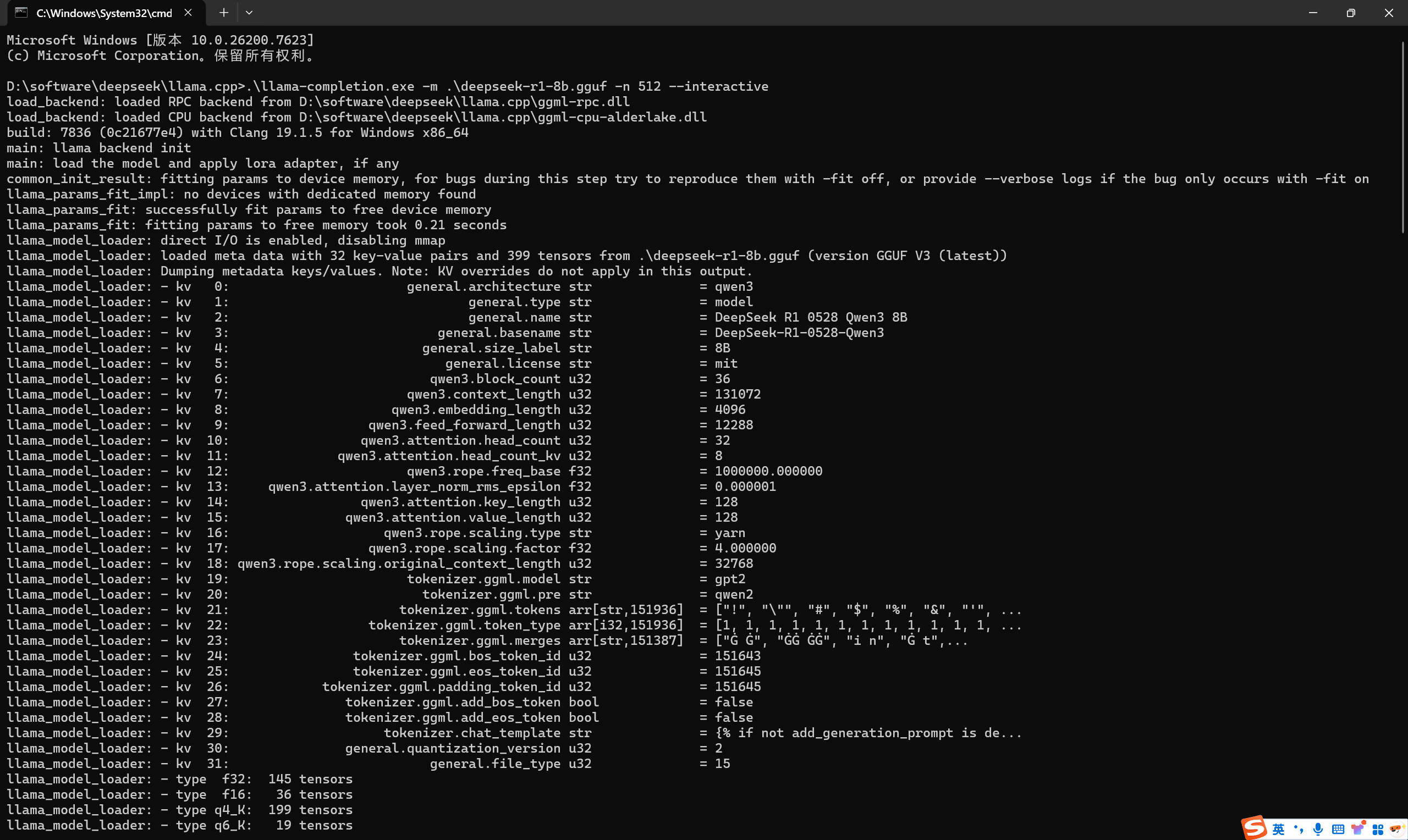
1、在llama.cpp文件夹中打开cmd命令,输入下面命令行:
.\llama-completion.exe -m .\deepseek-r1-8b.gguf -n 512 --interactive(注:deepseek-r1-8b.gguf是自己的模型文件,且gguf模型必须在llama.cpp文件夹中,interactive是在cmd窗口对话)
2、下面是运行成功的对话界面
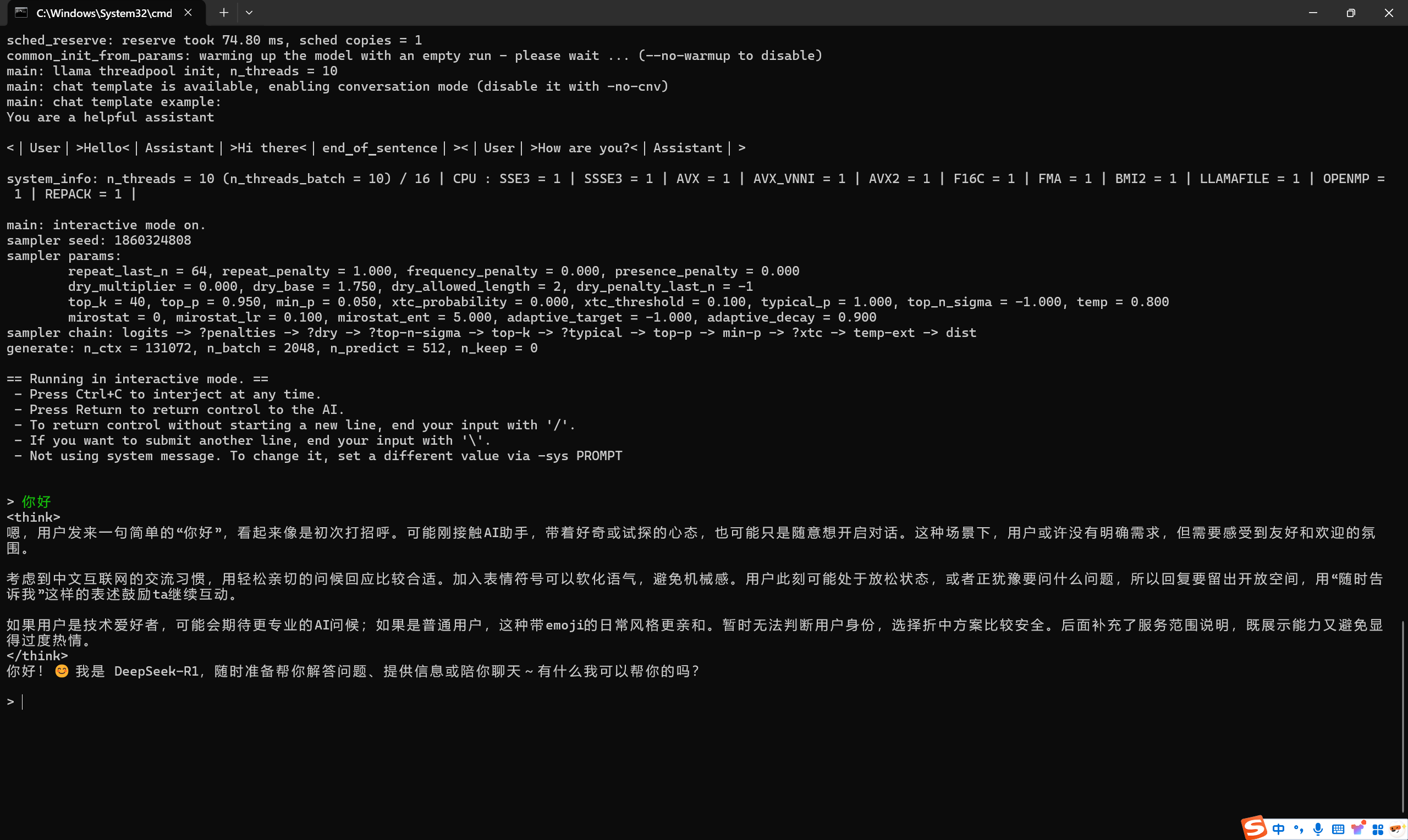
(二)浏览器对话
1、在llama.cpp文件夹中打开cmd命令,输入下面命令行:
.\llama-server.exe -m .\deepseek-r1-8b.gguf2、运行成功后的cmd界面
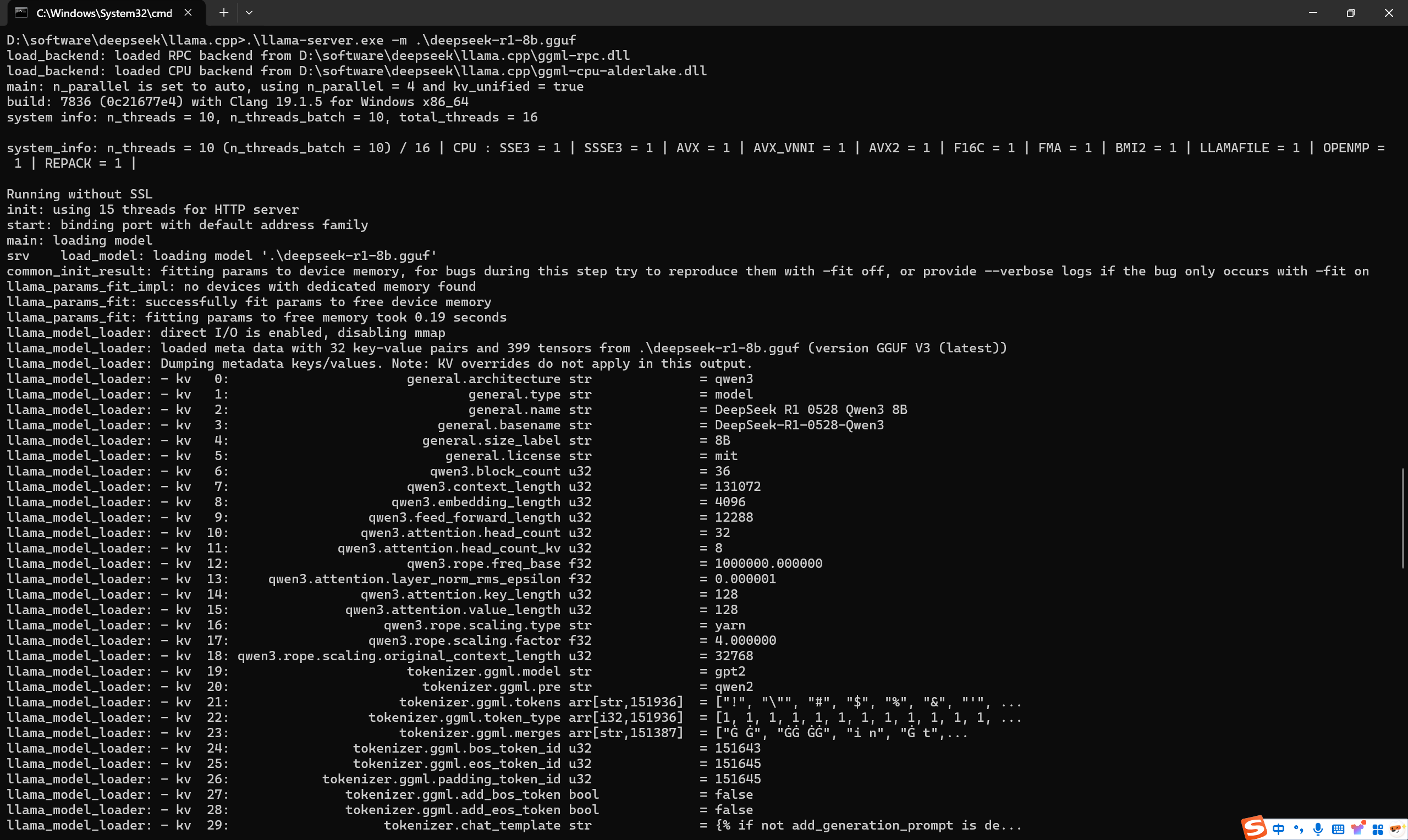
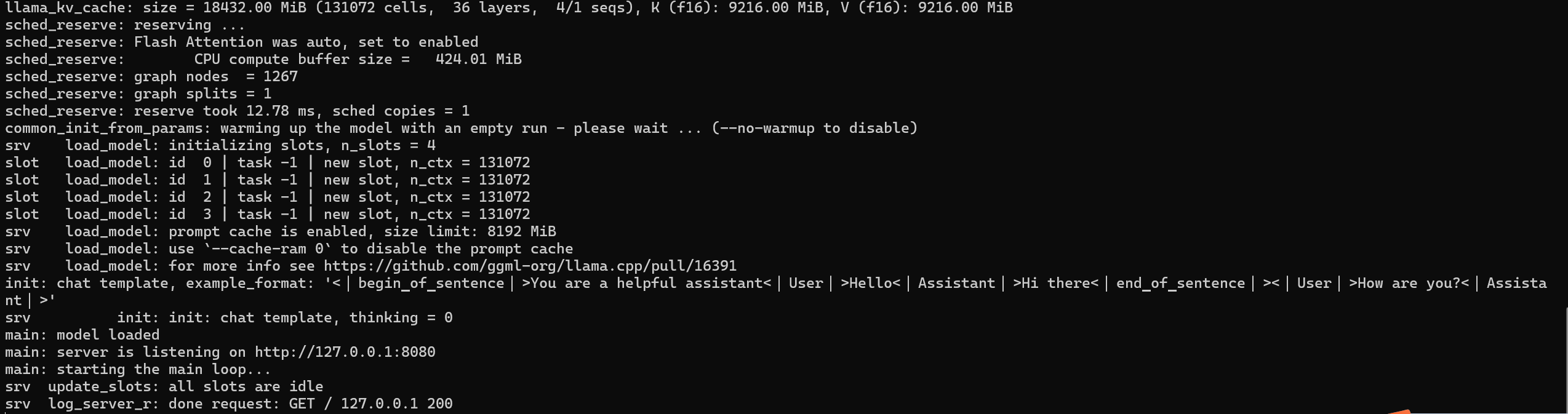
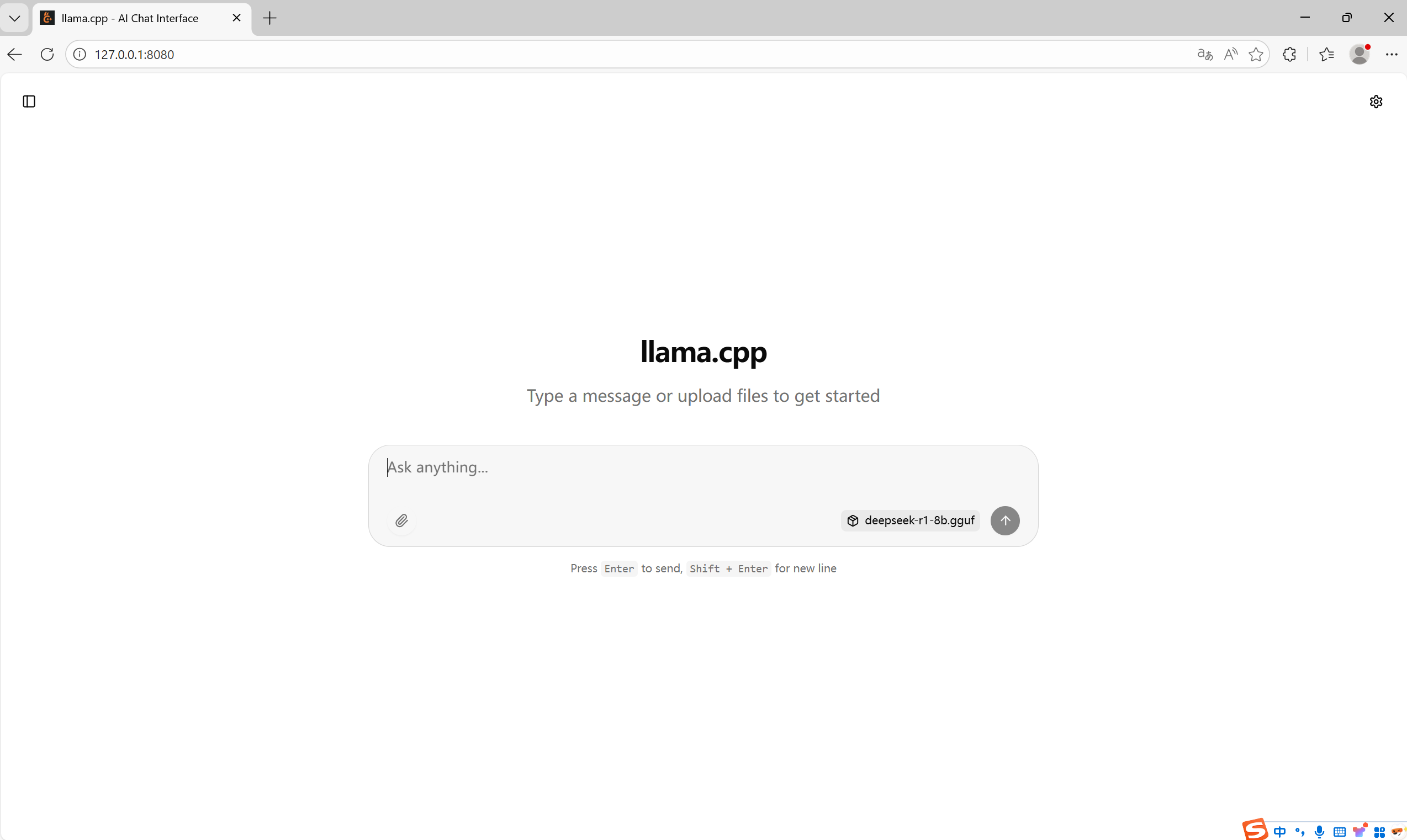
3、在浏览器输入127.0.0.1:8080即可打开图形化界面
四、补充说明
1、当GGUF文件的模型和llama.cpp里面的文件不在同一个文件夹时,可以用../返回上一目录去查找模型文件
2、比如,我的文件夹目录如下:
①llama-server.exe文件在llama.cpp文件夹中
②deepseek-r1-8b.gguf模型文件在llama.cpp_models文件夹中

3、我要在cmd中输入下面的命令:
①cmd对话窗口
.\llama-completion.exe -m ..\llama.cpp_models\deepseek-r1-8b.gguf -n 512 --interactive②浏览器图形化界面
.\llama-server.exe -m ..\llama.cpp_models\deepseek-r1-8b.gguf
欢迎加入DeepSeek 技术社区。在这里,你可以找到志同道合的朋友,共同探索AI技术的奥秘。
更多推荐


 5
5 0
0- 0



 已为社区贡献3条内容
已为社区贡献3条内容

所有评论(0)