deepseek r1完全本地部署实战教程09
【代码】deepseek r1完全本地部署实战教程09。
·
一、ollama最常用变量配置
1. OLLAMA_HOST:这个变量定义了Ollama监听的网络接口。通过设置OLLAMA_HOST=0.0.0.0,我们可以让Ollama监听所有可用的网络接口,从而允许外部网络访问。
2. OLLAMA_MODELS:这个变量指定了模型镜像的存储路径。通过设置OLLAMA_MODELS=F:\OllamaCache,我们可以将模型镜像存储在E盘,避免C盘空间不足的问题。
3. OLLAMA_KEEP_ALIVE:这个变量控制模型在内存中的存活时间。设置OLLAMA_KEEP_ALIVE=24h可以让模型在内存中保持24小时,提高访问速度。
4. OLLAMA_PORT:这个变量允许我们更改Ollama的默认端口。例如,设置OLLAMA_PORT=8080可以将服务端口从默认的11434更改为8080。
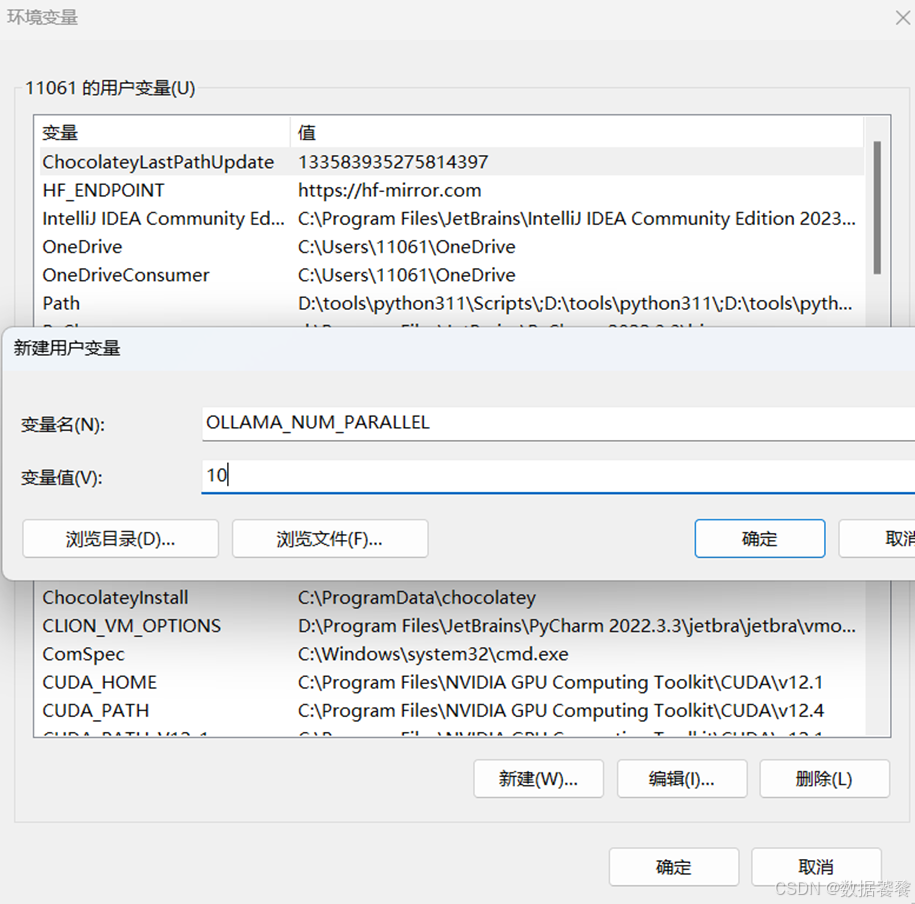
5. OLLAMA_NUM_PARALLEL:这个变量决定了Ollama可以同时处理的用户请求数量。设置OLLAMA_NUM_PARALLEL=4可以让Ollama同时处理两个并发请求。
6. OLLAMA_MAX_LOADED_MODELS:这个变量限制了Ollama可以同时加载的模型数量。设置OLLAMA_MAX_LOADED_MODELS=4可以确保系统资源得到合理分配。
二、配置方法
三、运行效果演示
四、核心内容回顾
-
OLLAMA_API_KEY:
- 作用:用于身份验证和授权,保障API调用的安全性。
- 使用场景:需要保护API访问权限时,设置唯一的密钥以控制访问。
-
OLLAMA_PORT:
- 作用:指定Ollama服务监听的网络端口。
- 使用场景:当默认端口与其他服务冲突或需自定义时,更改此变量值。
-
OLLAMA_MODEL_PATH:
- 作用:指定可用AI模型的位置,便于加载不同的模型以满足各种任务需求。
- 使用场景:需要切换或加载特定的预训练模型来优化性能或资源使用。
-
OLLAMA_GPU_ENABLED:
- 作用:启用或禁用GPU加速计算,提升推理速度。
- 使用场景:在具备GPU支持且需要高性能处理时启用;否则禁用以节省资源。
-
OLLAMA_LOG_LEVEL:
- 作用:控制日志的详细程度,辅助开发和维护工作。
- 使用场景:根据开发阶段或运行环境需求,设置合适的日志级别以便监控服务状态和排查问题。

欢迎加入DeepSeek 技术社区。在这里,你可以找到志同道合的朋友,共同探索AI技术的奥秘。
更多推荐

 9
9 0
0- 0



 已为社区贡献6条内容
已为社区贡献6条内容

所有评论(0)