deepseek r1从零搭建本地知识库11:嵌入模型-跟着榜单去选型
2.1 MTEB 是什么?定位:权威的文本嵌入模型性能评测基准,覆盖检索(Retrieval)、分类(Classification)、聚类(Clustering)、语义相似度(Semantic Similarity)等 8 大类任务、58 个子任务。数据:涵盖 112 种语言,支持多语言模型横向对比。更新频率:排行榜定期更新,收录最新开源和商业模型。2.2 如何使用该排行榜?查看模型排名:默认按综
一、引言
-
嵌入模型是一种将文本、图像、音频等非结构化数据转化为**低维稠密向量(Dense Vector)**的算法模型,这些向量(通常几百到几千维)能够捕捉数据的语义信息。
-
核心目标:将抽象内容转化为计算机可理解的数值形式,同时保留其语义关联性。
-
本地知识库通常指企业或组织内部构建的结构化/半结构化数据仓库(如文档、FAQ、产品资料),嵌入模型是其实现智能化的核心技术之一
-
工作实践中,如何选择嵌入模型,我们提出了一种评测基准榜单的进行嵌入模型选型的工作思路和方法。
二、MTEB概述
2.1 MTEB 是什么?
-
定位:权威的文本嵌入模型性能评测基准,覆盖 检索(Retrieval)、分类(Classification)、聚类(Clustering)、语义相似度(Semantic Similarity) 等 8 大类任务、58 个子任务。
-
数据:涵盖 112 种语言,支持多语言模型横向对比。
-
更新频率:排行榜定期更新,收录最新开源和商业模型。
2.2 如何使用该排行榜?
-
查看模型排名:默认按综合得分(Average Score)排序,可点击表头按特定任务(如检索)排序。
-
筛选模型:
-
通过左侧筛选器选择语言(如中文)、任务类型或模型规模。
-
输入模型名称(如
mxbai-embed-large)直接搜索。
-
-
查看细节:点击模型名称,跳转到模型卡(Model Card),了解训练方法、参数量等详细信息。
2.3 关键指标解读
-
Average Score:模型在所有任务中的平均得分(0~100),分数越高越好。
-
Tasks:模型支持的任务类型(如
Retrieval,Clustering)。 -
Languages:支持的语言列表(如
en, zh, multi)。
2.4 注意事项
-
部分模型可能未完全提交所有任务结果,需结合具体场景判断。
-
访问可能需要科学上网(部分区域网络限制)。
三、MTEB排行榜
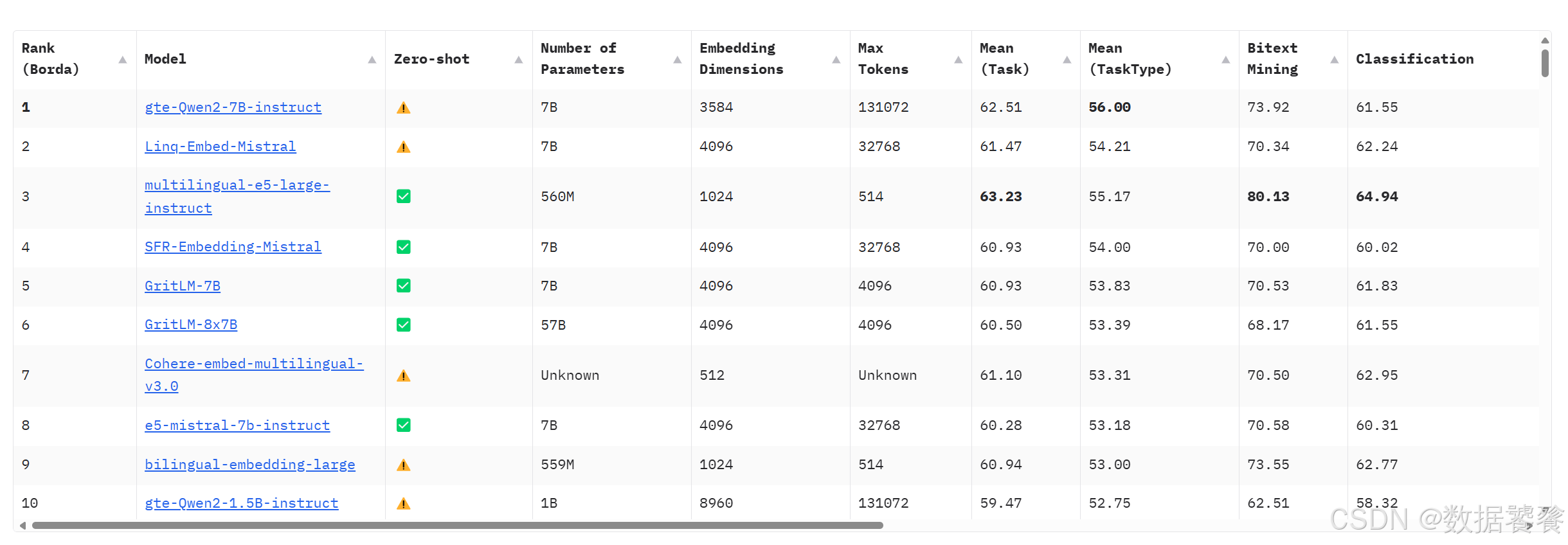
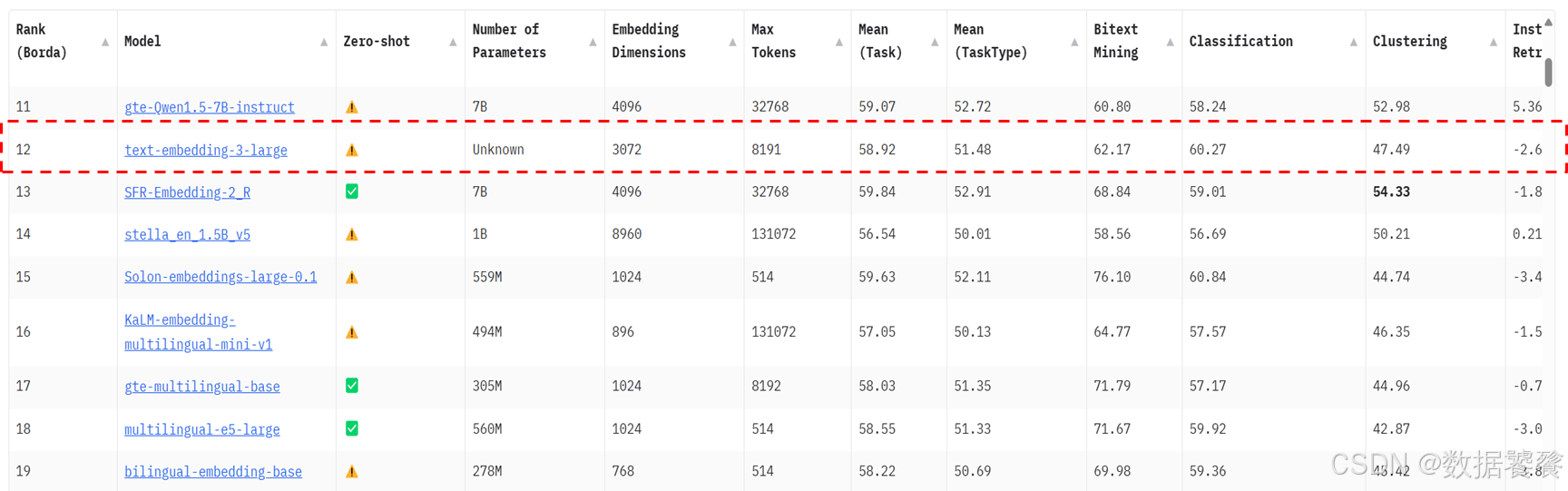
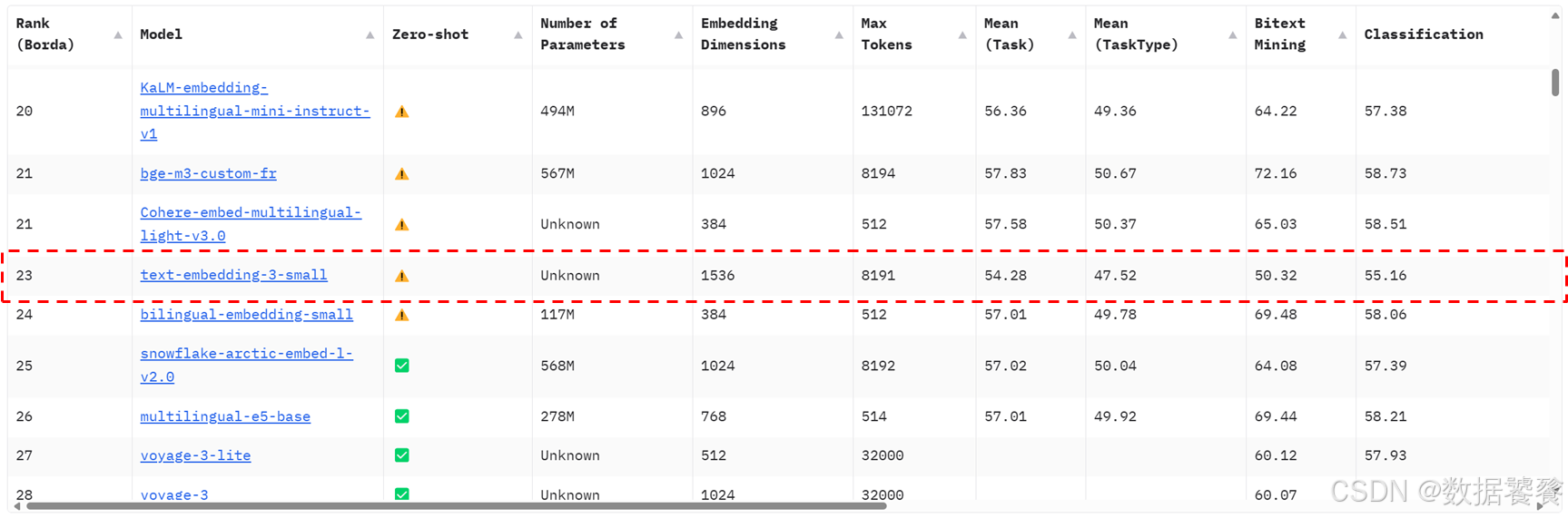
四、商业API嵌入模型
-
OpenAI Text Embedding 系列【最广泛】
-
模型名:
text-embedding-3-small/text-embedding-3-large
开发者: OpenAI
特点: 支持长上下文(最高8192 tokens),性价比高,适合通用文本嵌入。 -
经典版本:
text-embedding-ada-002(较旧但广泛使用)。
-
-
Cohere Embed 系列
-
模型名:
embed-english-v3.0/embed-multilingual-v3.0
开发者: Cohere
特点: 多语言支持,提供针对检索或分类优化的嵌入模式。
-
五、开源嵌入模型
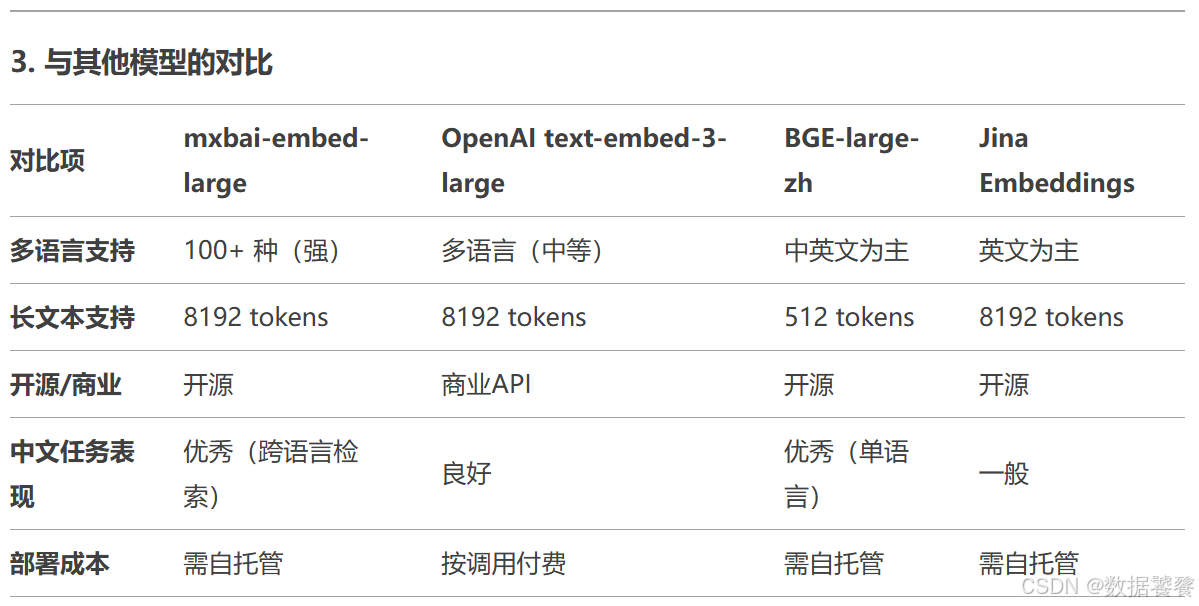
5.1 mxbai-embed-large
1. 模型背景
-
开发者: Mixed Bread AI(专注于多语言嵌入模型的团队)
-
发布时间: 2024年(较新的开源模型)
-
定位: 高性能、多语言通用嵌入模型,特别强调在多语言检索任务中的表现。
2. 核心特点
(1)多语言支持
-
支持 100+ 种语言(包括中、英、德、日等),尤其对中文优化较好。
-
在跨语言检索(例如用中文查询英文文档)任务中表现突出。
(2)长上下文支持
-
最大输入长度 8192 tokens,适合处理长文本(如文档、文章)。
(3)性能表现
-
在权威的 MTEB(Massive Text Embedding Benchmark) 排行榜中综合得分靠前(截至2024年,排名前5%)。
-
关键任务表现:
-
检索(Retrieval): 在跨语言检索任务中接近商用模型(如OpenAI)。
-
分类(Classification) 和 聚类(Clustering): 优于多数开源模型(如BGE、E5)。
-
(4)开源与免费
-
模型权重完全开源,可本地部署或云托管,无调用成本。
-
支持通过Hugging Face Transformers库直接调用。

欢迎加入DeepSeek 技术社区。在这里,你可以找到志同道合的朋友,共同探索AI技术的奥秘。
更多推荐


 0
0 0
0- 0



 已为社区贡献6条内容
已为社区贡献6条内容

所有评论(0)