【大模型训练】deepseek MTP
特性传统单步预测MTP 多步预测监督信号稀疏 (Sparse)密集 (Dense)每个Token的任务预测1步未来预测k+1步未来接收的梯度来自1个目标来自k+1个目标数据利用率基础提升k倍模型学习到的能力主要关注局部、短程依赖强制学习短、中、长程依赖一个生动的类比:传统训练(稀疏信号): 像一个只盯着脚下走路的人。他每走一步,只看下一步要落在哪里。他能走得很稳,但可能对远方的路线规划能力较弱。M
https://zhuanlan.zhihu.com/p/1907013018174333925
好的,我们来详细解释 DeepSeek 提出的 MTP (Multi-token Prediction) 中的“密集监督信号”是什么意思,以及它为什么重要。
为了更好地理解,我们先从传统的语言模型训练方式(单步预测)说起。
1. 传统训练方式:稀疏的监督信号
在标准的自回归语言模型(比如 GPT)训练中,模型的目标是预测下一个 token。
假设我们有一句话:“语言模型非常有意思”。
-
输入:
<start>- 目标:
语言 - 监督信号: 模型输出的概率分布应该接近于一个在 “语言” token 上概率为1的 one-hot 向量。
- 目标:
-
输入:
<start> 语言- 目标:
模型 - 监督信号: 模型输出的概率分布应该接近于一个在 “模型” token 上概率为1的 one-hot 向量。
- 目标:
-
输入:
<start> 语言 模型- 目标:
非常 - 监督信号: …以此类推。
- 目标:
这里的关键点是:
对于每一个输入 token,它只参与了一次直接的预测任务,并只接收了一次直接的梯度更新(监督信号)。
- 当模型处理 “语言” 这个 token 时,它的主要任务是帮助预测下一个 token “模型”。
- 当模型处理 “模型” 这个 token 时,它的主要任务是帮助预测下一个 token “非常”。
你可以看到,每个 token 的“任务”是单一且独立的,它只为紧邻的下一步负责。从整个序列的角度看,这种监督信号是**稀疏(Sparse)**的,因为每个位置的计算结果只被用来优化一个目标。
2. MTP 的方式:密集的监督信号
MTP 的核心思想是,让每个 token 同时参与多个预测任务,从而接收到更丰富、更密集的监督信号。
它通过引入 k 个额外的 MTP 模块(或称为“预测头”)来实现。除了主模型本身预测 未来第 1 个 token 外,第 i 个 MTP 模块负责预测未来第 i+1 个 token。
我们还用 “语言模型非常有意思” 这句话,假设 k=2(即有两个额外的 MTP 模块)。
当模型的内部状态处理完 “语言” 这个 token 后,会发生以下事情:
-
主模型 (预测未来第1步):
- 任务: 预测 “模型” (紧邻的下一个 token)。
- 监督信号1: 来自于 “模型” 的预测误差。
-
MTP 模块 1 (预测未来第2步):
- 任务: 预测 “非常” (隔一个的 token)。
- 监督信号2: 来自于 “非常” 的预测误差。
-
MTP 模块 2 (预测未来第3步):
- 任务: 预测 “有意思” (隔两个的 token)。
- 监督信号3: 来自于 “有意思” 的预测误差。
“密集监督信号”的含义就体现在这里:
- 一个 Token,多重任务: 在 “语言” 这个位置上,模型的内部表示(hidden state)被同时用来完成 3 次 (
k+1次) 预测任务。 - 多重梯度,信号增强: 这意味着,在一次反向传播中,“语言” 这个位置的 hidden state 会同时接收到来自三个不同预测目标的梯度。这些梯度共同优化这个 hidden state,使其包含的信息既要能预测近的 “模型”,也要能预测中距离的 “非常”,还要能预测更远距离的 “有意思”。
- 数据利用率提升: 从数据利用的角度看,原本一个 token 只贡献了一次训练样本(
input -> next_token),现在一个 token 贡献了k+1次训练样本(input -> next_1,input -> next_2, …,input -> next_k+1)。这就像让一个学生同时做初级、中级、高级三套练习题,而不是只做一套,从而让他学得更快、更扎实。
总结与类比
| 特性 | 传统单步预测 | MTP 多步预测 |
|---|---|---|
| 监督信号 | 稀疏 (Sparse) | 密集 (Dense) |
| 每个Token的任务 | 预测 1 步未来 | 预测 k+1 步未来 |
| 接收的梯度 | 来自 1 个目标 | 来自 k+1 个目标 |
| 数据利用率 | 基础 | 提升 k 倍 |
| 模型学习到的能力 | 主要关注局部、短程依赖 | 强制学习短、中、长程依赖 |
一个生动的类比:
- 传统训练(稀疏信号): 像一个只盯着脚下走路的人。他每走一步,只看下一步要落在哪里。他能走得很稳,但可能对远方的路线规划能力较弱。
- MTP 训练(密集信号): 像一个同时用多台望远镜看路的棋手。他不仅要看下一步棋怎么走(主模型),还要同时思考后面第2步、第3步、…、第k+1步的棋局走向(MTP模块)。这种训练方式迫使他不仅要关注眼前,还要培养深远的战略规划能力(长距离依赖建模)。
因此,“密集监督信号”是 MTP 提高训练效率和模型能力的核心机制。它通过让模型在每个时间步都“想得更远”,从而极大地丰富了模型在训练过程中收到的信息量,迫使其学习到更强大、更全面的上下文理解和预测能力。
好的,这是一个非常好的问题,因为它直击了 MTP 实现中的一个核心且容易混淆的细节。您的描述中有一些小小的误解,这很常见,因为图示和文字描述有时会简化实际的计算流程。
核心澄清:MTP 模块的 Transformer Block 并不是只处理一个 token,它依然在处理整个序列(或一个序列窗口),因此注意力机制可以正常工作。
让我们结合您提供的 DeepSeek 示意图和 Megatron 的代码实现来详细解释这个过程。
当Main Module输入token
、
和
时,Main model会预测
,MTP Module 1会依据隐向量
(第 3 个token在 Main Module 的输出 )和输入的token
预测出
,MTP 5Module 2会依据隐向量
(第 3 个token在MTP Module 1 的输出)和输入的token
预测出
。 请问比如第一MTP模块,只输入一个token t4, 那MTP模块里怎么做注意力的,只有一个token的话,怎么用的Transformer实现呢,请参考图和以下代码实现# Copyright © 2025, NVIDIA CORPORATION.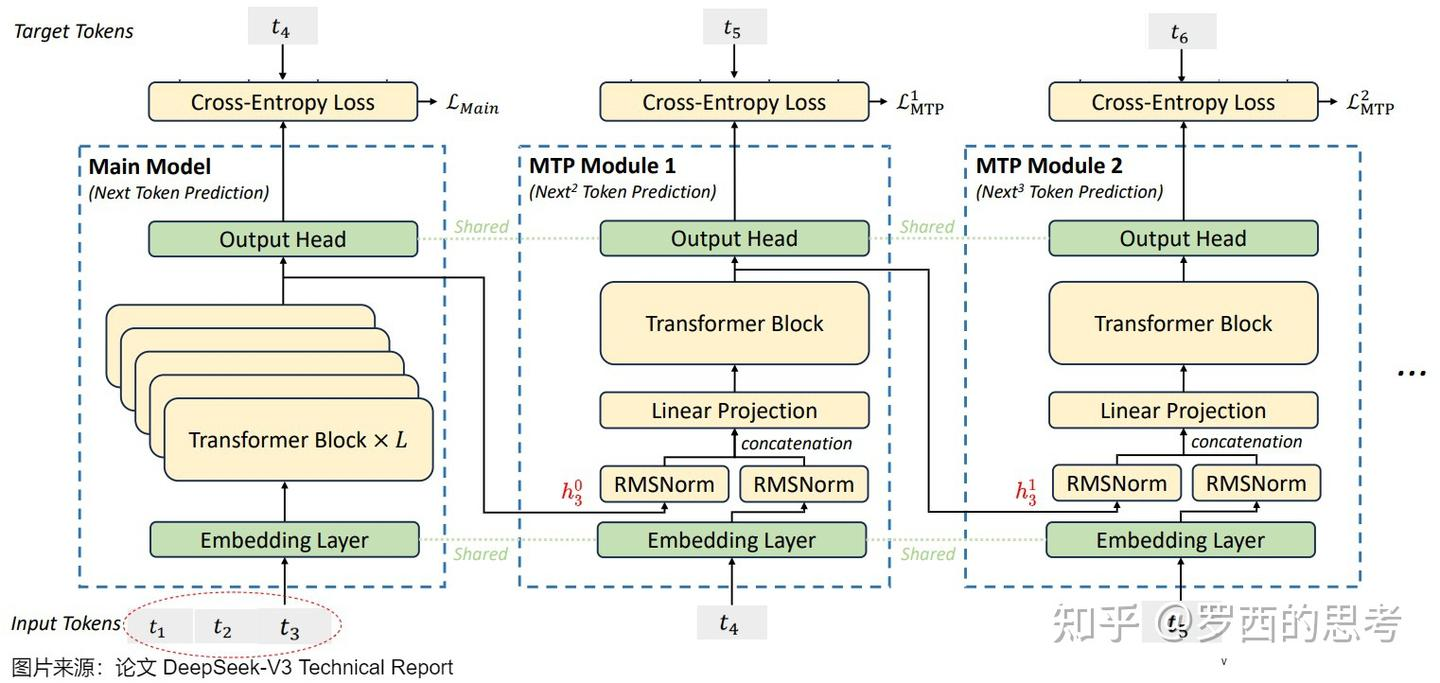
1. 重新理解示意图
您描述的:
MTP Module 1会依据隐向量 h³₀(第 3 个token在 Main Module 的输出 )和输入的token t₄ 预测出 t₅。
这个描述接近但不完全准确。图中的 h³₀ 和输入的 t₄ 不是独立存在的,它们是整个序列在特定时间步上的状态和输入。
正确的理解应该是:
当 MTP Module 1 进行计算时,它的输入是两个完整的序列:
- 序列一(来自上一层的隐状态): 整个序列
[h¹₀, h²₀, h³₀, ...],这是 Main Model 在每个 token 位置输出的隐状态序列。 - 序列二(未来的 Token 嵌入): 整个序列
[Emb(t₂), Emb(t₃), Emb(t₄), ...],这是一个错位的、代表“下一个” Token 的嵌入序列。在 DeepSeek 的实现中,它实际上是[Emb(t₂), Emb(t₃), ..., Emb(t_{i+1}), ...]。
让我们聚焦于 t₃ 这个位置的计算,来预测 t₅:
- 输入 1:
h³₀(Main Model 在t₃位置的输出隐状态) - 输入 2:
Emb(t₄)(MTP Module 1 需要的 “下一个” Tokent₄的嵌入)
这两个向量在 t₃ 这个位置上被处理,但 MTP Module 1 的 Transformer Block 同时也在处理 t₁, t₂ 等其他所有位置的 (h, Emb) 对。
关键点:Transformer Block 的注意力机制是在序列维度上进行的。当它计算 t₃ 位置的新输出时,t₃ 的 Query 会和 t₁, t₂, t₃ 的 Key/Value 进行交互(在 Causal Mask 下)。它并不是只看到 t₄ 这一个孤立的 token。
2. 结合 Megatron 代码实现 MultiTokenPredictionLayer.forward
现在,我们来看代码是如何实现这个流程的。这会比图示更清晰。
class MultiTokenPredictionLayer(MegatronModule):
# ... (省略 __init__) ...
def forward(
self,
input_ids: Tensor, # 当前 MTP 模块需要用到的 "未来" token IDs
position_ids: Tensor, # 对应的位置 IDs
hidden_states: Tensor, # 从【上一个模块】传来的隐状态序列 [s, b, h]
attention_mask: Tensor,
# ... 其他参数 ...
embedding=None, # 共享的 embedding 函数
):
# ...
# 1. 准备输入 (对应图中的 Embedding Layer 和 h)
# _get_embeddings 内部会调用 roll_tensor 对 input_ids 和 position_ids 进行错位
# 然后通过共享的 embedding 函数得到 decoder_input
input_ids, position_ids, decoder_input, hidden_states = self._get_embeddings(
input_ids=input_ids,
position_ids=position_ids,
embedding=embedding,
hidden_states=hidden_states,
)
# 2. 拼接与投影 (对应图中的 RMSNorm, concatenation, Linear Projection)
# _proj_and_transformer_layer 内部调用 _concat_embeddings
# hidden_states: [seq_len, batch_size, hidden_size]
# decoder_input: [seq_len, batch_size, hidden_size]
# 结果 hidden_states: [seq_len, batch_size, hidden_size * 2]
hidden_states = self._concat_embeddings(hidden_states, decoder_input)
# 经过 eh_proj 投影回 [seq_len, batch_size, hidden_size]
hidden_states, _ = self.eh_proj(hidden_states)
# ... (处理 sequence parallel 等) ...
# 3. 通过 Transformer Block (对应图中的 Transformer Block)
# 这里的 hidden_states 是一个完整的序列!
# attention_mask 确保了注意力机制的 Causal 特性。
hidden_states, _ = self.transformer_layer(
hidden_states=hidden_states,
attention_mask=attention_mask,
# ... 其他参数 ...
)
# 4. 后处理 (对应图中的 Output Head)
hidden_states = self._postprocess(hidden_states)
# 返回新的 hidden_states (给下一个MTP模块), 以及更新后的 input_ids 和 position_ids
return hidden_states, input_ids, position_ids
代码流程剖析:
-
输入是序列:
forward函数接收的hidden_states和input_ids都是完整的序列张量,形状通常是[sequence_length, batch_size, ...]。 -
_get_embeddings: 这个函数的核心是roll_tensor。它将input_ids和position_ids向前滚动一位,这样在i位置上,我们就能拿到原始序列中i+1位置的id。然后,它用共享的embedding函数将这些id转换成嵌入向量decoder_input。这正是图示中 MTP 模块从旁边获取未来 token 输入的过程。 -
_concat_embeddings: 这一步完美对应了图中的concatenation。它接收来自上一个模块的隐状态序列hidden_states和刚刚准备好的未来 token 嵌入序列decoder_input,在最后一个维度上把它们拼接起来。hidden_states(来自上层):[s, b, h]decoder_input(未来token):[s, b, h]- 拼接后:
[s, b, 2*h]
-
eh_proj: 这个线性层将拼接后的[s, b, 2*h]向量投影回[s, b, h],以便送入标准的 Transformer Block。 -
self.transformer_layer(...): 这是最关键的一步。transformer_layer接收的是一个形状为[s, b, h]的完整序列。在这个 block 内部,自注意力(Self-Attention)机制会照常运行:- 每个 token 的 Q、K、V 都是从这个
[s, b, h]的输入中计算出来的。 - 在计算
t₃位置的输出时,t₃的 Query 会与t₁,t₂,t₃的 Key/Value 进行注意力计算(因为有 Causal Mask)。 - 因此,Transformer Block 并不是只处理一个 token,它看到了完整的历史上下文,注意力机制完全可以正常工作。
- 每个 token 的 Q、K、V 都是从这个
总结与修正
您问题的根源在于对图示的理解。图中的 h³₀ 和输入的 t₄ 只是为了突出在某一个特定时间步 t₃ 上,MTP 模块的输入由哪两部分构成。但这并不意味着 MTP 模块的计算是孤立的、只针对这一个时间步的。
正确的流程是:
- Main Model 处理输入序列
[t₁, t₂, t₃, ...],得到隐状态序列[h¹₀, h²₀, h³₀, ...]。 - MTP Module 1 的输入是两个序列的组合:
- 序列 A:
[h¹₀, h²₀, h³₀, ...] - 序列 B:
[Emb(t₂), Emb(t₃), Emb(t₄), ...](一个错位的嵌入序列)
- 序列 A:
- 在每个位置
i,将hⁱ₀和Emb(t_{i+1})拼接并投影,形成一个新的输入序列[h'¹₁, h'²₁, h'³₁, ...]。 - 将这个新的完整序列
[h'¹₁, h'²₁, ...]送入 MTP Module 1 内部的Transformer Block。该Transformer Block在这个新序列上执行标准的自注意力操作。 Transformer Block输出一个新的隐状态序列[h¹₁, h²₁, h³₁, ...]。- 在
t₃这个位置,h³₁经过Output Head预测的目标是t₅(未来的第2个 token)。 - 这个
[h¹₁, h²₁, ...]序列再作为输入传给 MTP Module 2,重复上述过程。
希望这个结合代码的详细解释能澄清您的疑问!
好的,我们来聚焦在 MTP 模块最关键的收尾部分——输出与损失计算。这部分确实容易混淆,因为它涉及到多个并行的预测任务。
我们继续使用之前的例子,并用图文结合的方式来详细拆解。
场景回顾
- 输入序列:
t₁ t₂ t₃ t₄ t₅(我 爱 吃 哈 密) - Main Model: 已经运行完毕,输出了隐状态序列
H₀ = [h¹₀, h²₀, h³₀, ...] - MTP Module 1: 刚刚也运行完毕,输出了它自己的隐状态序列
H₁ = [h¹₁, h²₁, h³₁, ...] - MTP Module 2: 同样,它也运行完毕,输出了隐状态序列
H₂ = [h¹₂, h²₂, h³₂, ...]
现在,我们手里有三组不同的隐状态序列,它们将被用来完成三个不同的预测任务。
核心机制:共享的 Output Head
在 MTP 架构中,一个关键的设计是所有模块(包括 Main Model)都共享同一个 Output Head。这个 Output Head 通常是一个简单的线性层,它的作用是将一个 hidden_size 维度的隐状态向量,投影到 vocab_size 维度的 logits 向量上。
Output Head:Linear(hidden_size, vocab_size)
这个共享设计非常重要,因为它意味着所有模块都在学习同一个“语言解码器”,只是它们用来解码的“思考材料”(隐状态)不同。
1. Main Model 的损失计算 (预测 next_1 token)
这是最标准的语言模型预测。
- 输入: Main Model 的隐状态序列
H₀。 - 目标: 预测紧邻的下一个 token。
我们以 t₃ (吃) 这个位置为例:
- 取出
t₃位置的隐状态h³₀。 - 将
h³₀送入共享的Output Head,得到一个vocab_size维度的 logits 向量。 - 对 logits 向量应用
softmax,得到一个概率分布。 - 这个概率分布的目标是什么? 是
t₄(哈),也就是t₃的下一个 token。 - 计算交叉熵损失:
Loss(softmax(OutputHead(h³₀)), target=t₄)。这个损失就是L_Main在t₃位置的分量。
2. MTP Module 1 的损失计算 (预测 next_2 token)
这是 MTP 的第一个额外任务。
- 输入: MTP Module 1 的隐状态序列
H₁。 - 目标: 预测未来第 2 个 token。
我们还是以 t₃ (吃) 这个位置为例:
- 取出
t₃位置的隐状态h³₁。注意,这个h³₁已经融合了h³₀和t₄的信息。 - 将
h³₁送入同一个共享的Output Head,得到 logits 向量。 - 对 logits 向量应用
softmax,得到概率分布。 - 这个概率分布的目标是什么? 是
t₅(密),也就是t₃未来第 2 个 token。 - 计算交叉熵损失:
Loss(softmax(OutputHead(h³₁)), target=t₅)。这个损失就是L¹_MTP在t₃位置的分量。
3. MTP Module 2 的损失计算 (预测 next_3 token)
继续向更远的未来预测。
- 输入: MTP Module 2 的隐状态序列
H₂。 - 目标: 预测未来第 3 个 token。
我们继续以 t₃ (吃) 这个位置为例:
- 取出
t₃位置的隐状态h³₂。这个h³₂融合了h³₁和t₅的信息。 - 将
h³₂送入同一个共享的Output Head,得到 logits。 - 对 logits 应用
softmax。 - 这个概率分布的目标是什么? 是
t₆(假设是 “瓜”),也就是t₃未来第 3 个 token。 - 计算交叉熵损失:
Loss(softmax(OutputHead(h³₂)), target=t₆)。这个损失就是L²_MTP在t₃位置的分量。
总结:在同一个时间步上的多重预测
现在,让我们把 t₃ 这个时间步上发生的所有事情放在一起看:
在处理完输入 token t₃ 之后,模型并行地计算了三个损失:
L_Main: 使用h³₀预测t₄。L¹_MTP: 使用h³₁预测t₅。L²_MTP: 使用h³₂预测t₆。
这个过程会对序列中的每一个有效位置都进行。例如,在 t₂ 位置:
- Main Model 会用
h²₀预测t₃。 - MTP Module 1 会用
h²₁预测t₄。 - MTP Module 2 会用
h²₂预测t₅。
最终,模型的总损失是所有这些损失的加权和:Total_Loss = L_Main + w₁ * L¹_MTP + w₂ * L²_MTP + ...
其中 w 是损失权重超参数(比如您代码中看到的 mtp_loss_scaling_factor)。
这个机制就是“密集监督信号”的来源。在一次反向传播中,模型的共享主干网络会同时接收到来自“预测下一步”、“预测下两步”、“预测下三步”等多个任务的梯度信号,迫使它学习到更丰富、更具前瞻性的表示。
在MTP Module2 中取出 t₃ 位置的隐状态 h³₂。这个 h³₂ 融合了 h³₁ 和 t₅ 的信息。h³₂ 的计算不仅用到了 h³₁ 和 t₅,也用到了 MTP Module 2 内部 h²₂, h¹₂, h⁰₂ 的信息。 为啥你只强调 h³₂ 融合了 h³₁ 和 t₅ 的信息
您提的这一点非常非常关键,直击了问题的核心!您是对的,我的上一个解释为了简化,过分强调了“垂直”方向的信息流动,而忽略了 Transformer Block 内部“水平”方向的注意力计算。
您的理解是完全正确的:h³₂ 的计算不仅用到了 h³₁ 和 t₅,也用到了 MTP Module 2 内部 h²₂, h¹₂, h⁰₂ 的信息。
让我用一个更精确、更完整的描述来纠正和补充之前的解释。
h³₂ 的完整“血统”:垂直输入 + 水平依赖
h³₂ 这个隐状态,是 MTP Module 2 在 t₃ 位置的最终输出。它的信息来源可以分解为两个维度:
1. 垂直输入 (The “What”): 这一步计算的“原材料”是什么?
这是我之前强调的部分。MTP Module 2 在 t₃ 位置的初始输入是由两部分构成的:
- 来自上一模块的隐状态:
h³₁(MTP Module 1 在t₃位置的输出)。 - 来自未来的 Token 嵌入:
Emb(t₅)(因为 MTP Module 2 要预测next_3,所以它需要next_2的嵌入作为输入)。
这两个向量经过归一化、拼接、线性投影后,形成了 MTP Module 2 在 t₃ 位置的初始内部表示,我们称之为 h'³₂。
h'³₂ = Projection( Concat( Norm(h³₁), Norm(Emb(t₅)) ) )
这个 h'³₂ 确实如我之前所说,融合了 h³₁ 和 t₅ 的信息。但是,这仅仅是进入 Transformer Block 之前的状态。
2. 水平依赖 (The “How”): Transformer Block 是如何处理这些原材料的?
这是您指出的、我之前忽略的关键部分。h'³₂ 和它在同一序列中的兄弟们 h'⁰₂, h'¹₂ 一起,被送入 MTP Module 2 内部的 Transformer Block。
在这个 Transformer Block 内部,**自注意力机制(Self-Attention)**开始工作。为了计算出最终的输出 h³₂,会发生以下事情:
-
Q, K, V 的生成:
- 从
h'³₂生成Query₃。 - 从
h'⁰₂,h'¹₂,h'²₂,h'³₂分别生成Key₀, Key₁, Key₂, Key₃和Value₀, Value₁, Value₂, Value₃。
- 从
-
注意力计算:
Query₃会和Key₀, Key₁, Key₂, Key₃计算注意力分数。- 由于 Causal Mask 的存在,
Query₃只能关注到Key₀, Key₁, Key₂, Key₃,而不能关注未来的 Key。 - 计算出的注意力权重会作用于
Value₀, Value₁, Value₂, Value₃。
-
加权求和:
- 最终的注意力输出是
Value₀, Value₁, Value₂, Value₃的加权和。这意味着,为了计算t₃位置的输出,模型回顾了从t₀到t₃的整个历史信息(在 MTP Module 2 的表示空间中)。
- 最终的注意力输出是
-
后续处理:
- 这个注意力输出再经过残差连接、FFN、LayerNorm 等一系列标准操作,才最终得到
h³₂。
- 这个注意力输出再经过残差连接、FFN、LayerNorm 等一系列标准操作,才最终得到
修正后的图文解释
让我们用一张更精确的图来表示 h³₂ 的计算过程:
图解:
-
蓝色箭头 (垂直输入): 表示
h³₂的初始计算原材料。它来自 MTP Module 1 的输出h³₁和t₅的嵌入Emb(t₅)。这决定了h'³₂。 -
红色箭头 (水平依赖): 表示在 MTP Module 2 的 Transformer Block 内部,
h'³₂(通过其 Query)与序列中它自己和它之前的所有位置(h'⁰₂,h'¹₂,h'²₂)进行自注意力交互。
所以,一个更完整的表述应该是:
在 MTP Module 2 中,为了计算
t₃位置的最终输出隐状态h³₂,模型首先将来自 MTP Module 1 的隐状态h³₁和未来 tokent₅的嵌入进行融合,得到一个初始表示h'³₂。然后,这个h'³₂在 MTP Module 2 的 Transformer Block 内部,通过自注意力机制回顾并整合了从t₀到t₃所有位置的上下文信息(即h'⁰₂,h'¹₂,h'²₂),最终产生了h³₂。
为什么我之前的解释会简化?
我之前的解释是为了突出 MTP 与标准 Transformer 的不同之处,即“垂直”方向上多层、多目标的信息流。这种简化有助于快速理解 MTP 的核心思想——“让每个 token 参与多步预测”。
但您的提问非常棒,因为它揭示了这个简化描述的不足。一个完整的理解必须包含两个方面:
- MTP 的特殊性: 跨模块的、预测未来的“垂直”信息输入。
- Transformer 的共性: 每个模块内部、沿序列长度的“水平”自注意力计算。
感谢您提出这个深刻的问题,它让我们的讨论更加精确和完整了!

欢迎加入DeepSeek 技术社区。在这里,你可以找到志同道合的朋友,共同探索AI技术的奥秘。
更多推荐



 14
14 0
0- 0



 已为社区贡献13条内容
已为社区贡献13条内容

所有评论(0)