深度解析:DeepSeek V4 的技术突围与国产 AI 的“普惠时代”
摘要:DeepSeek作为国产开源大模型的标杆,自2023年推出V1模型以来,始终坚持“算法+工程”双轮驱动的创新路线,以普惠AGI为目标,完成了从初版模型到V4的跨越式发展。2026年4月发布的DeepSeek V4,不仅标志着其正式迈入百万上下文时代,更通过架构革新、国产算力深度适配与双版本策略,为不同场景提供了高效、低成本的AI解决方案。
一、从V1到V4:持续创新驱动的技术跃迁
在通用人工智能(AGI)的演进路径中,2026年4月注定是一个值得标记的节点。DeepSeek V4的横空出世,不仅标志着国产大模型正式迈入“百万级上下文”时代,更通过混合注意力架构(Hybrid Attention)与国产算力的深度耦合,在长文本处理、推理成本控制及全链路国产化落地三个维度实现了范式级的突破。这不仅仅是一次简单的参数堆叠,而是一场针对大模型底层算力瓶颈的精准外科手术。
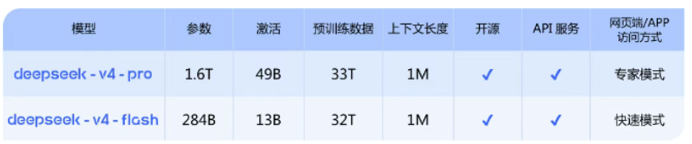
回顾其技术演进历程,每一代模型都聚焦效率与性能的双重突破:V1完成了大模型训练的经验积累,V2引入MoE架构并实现MLA提速,R1-lite与V3在推理效率和集群部署上持续优化,R1则通过无监督强化学习大幅提升了小模型的推理能力。到了V4阶段,混合注意力架构的创新应用,从根本上解决了长上下文场景下的算力与内存瓶颈。其核心的 CSA(压缩稀疏注意力)与 HCA(重度压缩注意力) 组合,将KV缓存压缩至传统方案的2%–10%。具体而言,在100万token场景下,V4-Pro的单token推理算力仅为V3.2的27%,KV缓存仅占10%;V4-Flash更是将算力与缓存需求分别降至10%和7%,让百万上下文处理从“高成本门槛”走向“普惠可用”。
二、模型架构:极致稀疏与双版本策略
| 维度 | DeepSeek V4 Pro | DeepSeek V4 Flash |
|---|---|---|
| 核心定位 | 深度推理、复杂任务 | 高并发、低成本、边缘端 |
| 参数规模 | 总参数1.6万亿 / 激活490亿 | 总参数2840亿 / 激活130亿 |
| 激活比 | 极致稀疏(约3%) | 极致轻量(13B/token) |
| 适用场景 | 科研分析、代码生成、长文档摘要 | 智能客服、API服务、中小企业应用 |
在模型架构上,V4延续并优化了MoE稀疏激活设计。Pro版本总参数量达1.6万亿,激活参数490亿;Flash版本则以2840亿总参数、130亿激活参数实现了极致轻量化部署。从关键指标来看,V4的激活比仅为3%–4.5%,远低于V3的5.5%,这种极致的稀疏性大幅降低了推理成本。 同时,MoE架构天然适配量化优化。DeepSeek已完成FP4量化方案的验证,为边缘端、低算力设备的部署铺平了道路,进一步拓展了大模型的应用边界。
DeepSeek V4最核心的颠覆性在于其对Transformer架构的重构。面对长上下文场景下KVCache(键值缓存)占用显存过大、推理算力成本高昂的行业痛点,V4摒弃了传统的全量注意力机制,创新性地引入了混合注意力架构。
-
CSA(压缩稀疏注意力):效率与精度的平衡
V4采用了“前层CSA + 后层HCA”的混合模式。CSA通过重叠窗口压缩(压缩率1/4)结合稀疏选择机制,在保留局部128-token滑动窗口细节的同时,利用可训练索引器筛选关键信息。这一设计使得单Token的浮点运算量降至V3版本的27%,KVCache占用更是仅为10%。这意味着,在处理百万级Token的超长文档时,V4不再需要天价的显存资源。 -
HCA(重度压缩注意力):全局语义的捕捉
作为CSA的互补,HCA以极低的计算开销(压缩率1/128)对全局KV进行稠密计算,不做稀疏选择,直接保留上下文的全局依赖关系。这种“局部精细、全局粗放”的策略,完美解决了长文本任务中“只见树木不见森林”的难题。 -
算法层面的深度优化
配合Muon优化器(基于矩阵正交化的优化算法,替代传统AdamW)与mHC超连接(流形约束),V4在训练稳定性与收敛速度上也实现了质的飞跃。特别是对于MoE(混合专家)架构的适配,Muon优化器有效缓解了梯度爆炸问题,确保了万亿级参数下的模型稳定性。
三、 算力突围:打破“卡脖子”的国产化实践
如果说算法是大脑,算力就是躯体。DeepSeek V4的另一大亮点在于其对华为昇腾(Ascend)等国产算力的深度适配,这标志着国产AI生态从“可用”走向了“好用”。官方已完成华为昇腾NPU的MoE推理验证(fine-grained Expert Parallelism mega-kernel),在常规推理场景中实现1.50–1.73倍加速,在延迟敏感场景(如RL推理、Agent服务)最高提速至1.96倍。昇腾950、A3超节点系列通过融合kernel与多流并行技术,实现了V4-Pro 20ms、V4-Flash 10ms的低时延推理。这意味着国产万亿参数MoE大模型真正实现了从芯片、框架到模型的全链路国产化落地,打破了高端算力依赖的行业痛点,为政务、电信等关键领域提供了自主可控的智能化基座。
四、V3/V4 核心差异对比
DeepSeek V4在V3的基础上,实现了架构、性能、适配与成本的全面升级,核心差异体现在以下方面:
-
架构与容量升级:V4在MoE架构基础上引入混合注意力与mHC超连接技术,优化长上下文处理能力。Pro版总参数提升至V3的2.4倍,模型能力显著增强;Flash版通过极致轻量设计,激活参数仅13B/token,更适配高并发、低成本场景。
-
长文本能力飞跃:上下文窗口从128K tokens扩展至1M tokens,提升8倍,可一次性处理超长文本。通过架构优化,处理长文本的算力仅为V3的27%、显存仅为10%,大幅降低了长文本应用的门槛。
-
国产算力深度适配:从英伟达CUDA架构迁移至华为昇腾CANN架构,在国产芯片上的推理速度提升显著,单卡吞吐最高达4700 TPS,解码时延低至10–20ms,完美适配国产智算基础设施。
-
成本与生态优化:Flash版API输出价格较V3降低75%,并提供缓存命中优惠。同时延续MIT开源协议,权重与代码可自由使用,为客户提供更具性价比、更可控的升级路径。
-
定位清晰互补:V4聚焦语言能力优化,未新增多模态功能。Pro版主打深度推理,Flash版主打高并发场景,形成“高低搭配”的模型矩阵,可满足政务、工业、中小微企业等不同层级客户的差异化需求。
五、行业启示:从“技术追赶”到“架构引领”
DeepSeek V4的发布,不仅是技术参数的刷新,更是国产AI技术路线的一次自信宣言。
它证明了在无法获得顶尖海外算力的背景下,通过算法创新(如CSA/HCA)与工程优化,我们依然能够实现算力的“软性增益”,解决长上下文处理这一世界级难题。这种“软硬协同”的思路,为行业提供了从“高成本门槛”走向“普惠AGI”的可行路径。
随着V4系列模型权重、推理代码及核心算子的完全开源,一个基于国产算力、自主可控的AI开发生态正在加速成型。未来,DeepSeek V4有望成为驱动千行百业智能化转型的核心引擎,为政务、工业、教育、医疗等领域注入强大的AI动能。

欢迎加入DeepSeek 技术社区。在这里,你可以找到志同道合的朋友,共同探索AI技术的奥秘。
更多推荐


 5
5 0
0- 0



 已为社区贡献1条内容
已为社区贡献1条内容

所有评论(0)