沉寂15个月,DeepSeek V4 来了——一个金融程序员的“真香“实测记录
DeepSeek V4震撼发布:金融程序员实测报告 这篇测评详细记录了金融程序员对DeepSeek V4的深度体验。V4系列包含1.6万亿参数的Pro版和284B参数的Flash版,均支持1M token上下文窗口。通过混合注意力机制等技术突破,V4在保持长上下文处理能力的同时显著降低了算力需求。测试显示,V4在量化策略代码生成、财报分析等金融场景表现优异,Pro版的思考模式尤其适合复杂推理任务。
作者:某不想被AI抢饭碗的金融程序员
发布日期:2026-04-28
关键词:DeepSeek V4、模型评测、AI编程、量化金融、大模型对比
写在前面:等了15个月,他来了
说实话,当我4月24日刷到 DeepSeek V4 正式发布的推文时,我第一反应是——这不会又是个"能把九九乘法表说错的PPT大师"吧?
毕竟,从去年1月 R1 爆火之后,DeepSeek 沉寂了整整15个月,中间传过无数次"快了快了"。这段时间里,OpenAI 把 GPT 更新到了 5.5,Anthropic 把 Claude 卷到了 Opus 4.6,Google 推出了 Gemini 3.1 Pro。竞争对手们卷得头皮发麻,DeepSeek 愣是稳如老狗。
然后,某个普通的周五上午,他们把 V4 丢出来了——同步开源、同步上线官网、同步更新 API,顺便还在发布稿里夹带私货说"公司内部员工编程 Agent 已经弃用 Claude"。
行吧,这波操作,稳。
作为一个主业跑量化策略、副业写各种 AI 代码工具的程序员,我这周已经把 V4 薅秃了。下面是我尽量克制"真香"冲动之后的理性测评。
(剧透:真的很香。)
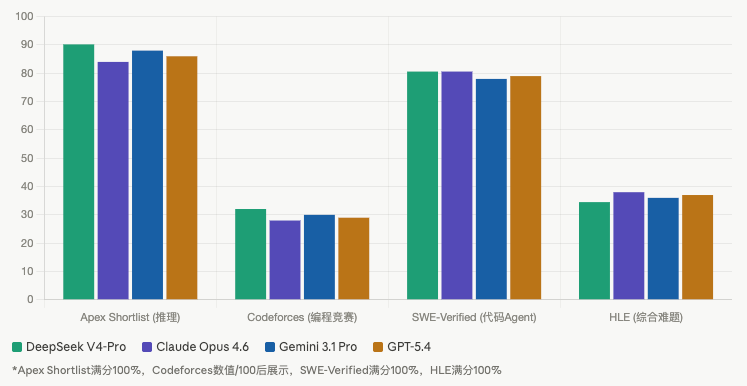
第一章:V4 到底是个啥?先搞清楚身份
在开测之前,我们得先弄清楚 DeepSeek V4 的家庭成员关系,否则下面读起来会一脸懵。
V4 系列包含两个成员:
DeepSeek-V4-Pro(旗舰版)
- 总参数:1.6万亿(1.6T),激活参数49B
- 上下文:原生 1M token(就是百万字,差不多一整部《红楼梦》乘以5)
- 定位:性能比肩顶级闭源模型,面向高端任务
- API 价格:输入¥1/1M tokens(缓存命中)、¥12(未命中),输出¥24
DeepSeek-V4-Flash(经济版)
- 总参数:284B,激活参数13B
- 上下文:同样 1M token
- 定位:快、便宜,适合中等复杂度任务
- API 价格:输入¥0.2/1M tokens(缓存),输出¥2
两款模型均以 MIT 许可证开源,均支持非思考模式(Normal)和思考模式(Think High / Think Max),思考模式下可以通过 reasoning_effort 参数控制推理强度。
调用方式极其简单,把原来的 model 参数换一下就行:
from openai import OpenAI
client = OpenAI(
api_key="你的DeepSeek API Key",
base_url="https://api.deepseek.com"
)
response = client.chat.completions.create(
model="deepseek-v4-pro", # 原来是 deepseek-chat,换这里
messages=[{"role": "user", "content": "帮我分析一下这段量化策略的逻辑"}],
extra_body={"thinking": {"type": "enabled"}}, # 开思考模式
)
⚠️ 注意:原来的
deepseek-chat和deepseek-reasoner接口名将在2026年7月24日停用,现在分别指向 V4-Flash 非思考模式和思考模式,赶紧迁移别等到最后一天。
第二章:架构黑科技拆解——技术报告越读越上头
我承认,我是那种会把技术报告当睡前读物的人。V4 这份报告,我读完之后的感受是:这帮人真的挺变态的(褒义)。
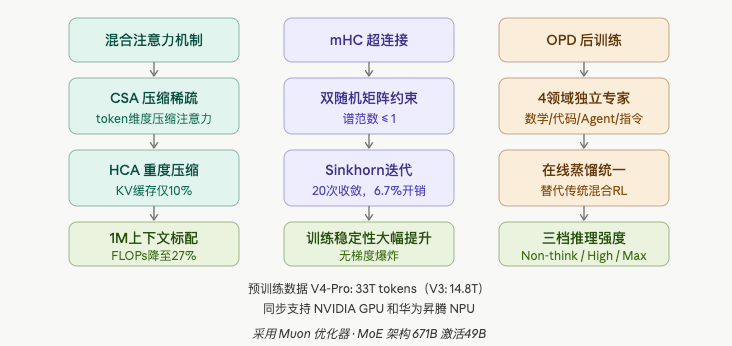
2.1 最大亮点:混合注意力机制,把算力打穿了
过去,长上下文一直是大模型的老大难问题——上下文越长,算力和显存消耗就爆炸式增长,导致 1M 上下文实际上可望而不可及。
V4 的解法是搞了一套全新的混合注意力架构,结合了两种技术:
- CSA(压缩稀疏注意力):在 token 维度进行压缩
- HCA(重度压缩注意力):进一步压缩 KV Cache
效果有多猛?在 1M token 的上下文场景下:
- V4-Pro 的单 token 推理 FLOPs 仅为 V3.2 的 27%
- KV Cache 仅为 V3.2 的 10%
换个人话说:上下文窗口从 128K 扩大到 1M,理论上放大了近8倍,但单 token 算力需求反而大幅下降了。有位亚马逊硬件工程师评价说,这可能意味着 DeepSeek 找到了缓解当前 HBM 内存短缺问题的方法。
这不是优化,这是重构。
 2.2 mHC 超连接:把残差连接玩出花来
2.2 mHC 超连接:把残差连接玩出花来
传统残差连接(Residual Connection)是深度学习的基础组件,用来防止梯度消失。V4 引入了 mHC(流形约束超连接,Manifold-constrained Hyperconnections),本质上是给残差连接加了一个双随机矩阵约束。
说人话就是:用数学手段保证矩阵的谱范数不超过1,让梯度传播变得更稳定,训练过程不会说崩就崩。
实现方式用的是 Sinkhorn-Knopp 迭代,20次收敛,配合专门的 fused kernel,额外开销只有 6.7%。这个优雅程度,我一个写量化策略的人看了都想鼓掌。
2.3 OPD 后训练:告别混合RL,拥抱专家蒸馏
V3 系列用的是传统混合强化学习(Mixed RL),V4 直接把它换成了 OPD(On-Policy Distillation,在线策略蒸馏)。
具体流程是:
- 先对数学、代码、Agent、指令跟随四个领域,各独立训练一个专家模型
- 每个专家先做 SFT 打底,再用 GRPO 做领域专属 RL
- 最后通过在线蒸馏,把十几个专家的能力蒸馏进一个统一的 student 模型
- Student 自己 rollout,最小化 reverse KL,数学任务向数学专家对齐,编程任务向编程专家靠
这套方法的好处是各领域互不干扰,最后整合又能取长补短。结果就是 V4 既能在数学竞赛上拿高分,又能打 Agent 场景。
还顺便引入了 Muon 优化器,同一时期 Kimi 也在用——两家公司同款优化器,解法各不相同,这种开源生态下的技术交流与各自演化,是2026年最有意思的事情之一。
预训练数据量方面,V4-Pro 用了 33T tokens,V4-Flash 用了 32T,而 V3 当年只用了 14.8T——直接翻倍。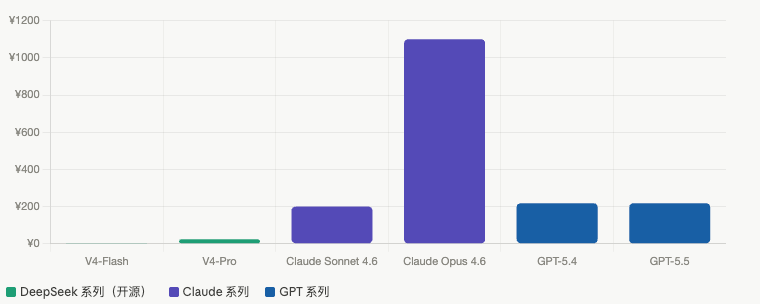
第三章:真实测评——金融程序员的日常场景
光看论文不够,得干活。我用了一周时间,把以下场景都跑了一遍。
3.1 场景一:Python 量化策略代码生成
我的真实需求:给我写一个基于双均线交叉的回测框架,需要支持自定义手续费率、滑点模型,并输出夏普比率、最大回撤、年化收益。
V4-Pro Think High 模式的表现:
代码一次生成,结构清晰,注释完整,连边界条件(如空仓期间如何计算收益)都考虑到了。更关键的是,它主动提示我:"当前的滑点模型采用固定值,实盘中建议改用成交量加权的动态滑点。"
这种主动补充的专业意见,是以前用 V3 时没怎么见过的。对比之前的 V3.2,V4 在 Agent Coding 场景下的提升是肉眼可见的。
与 Claude Opus 4.6(非思考模式)对比:
Opus 4.6 生成的代码同样高质量,但在策略逻辑的主动延伸方面稍弱一点。不过 Opus 4.6 的思考模式依然是目前我用过体验最佳的,V4 在这一点上坦承还有差距——DeepSeek 自己在发布稿里也说了,V4 已接近 Opus 4.6 非思考模式,但与思考模式仍有差距。诚实,加分。
3.2 场景二:长文档分析——财报处理
我把某上市公司的年报(大概15万字,带附注)直接塞给 V4-Pro,让它总结核心财务风险、计算同比变化并给出投资角度的关键提示。
结果:跑通了,没有截断,关键数字引用准确,对财务风险的描述有一定洞察力。
过去用 GPT-4o 处理这类长文档经常需要分段切割,现在直接喂进去就行。1M 上下文这个特性,对于金融这个天天和长报告打交道的行业,实实在在有用。
3.3 场景三:数学推理——衍生品定价
用 Black-Scholes 期权定价的扩展问题测试,加入了随机波动率的 Heston 模型求解。
V4 在 Think Max 模式下,推导过程比我预期的完整,边界条件处理正确,最后给出了 Python 实现并做了数值验证。Codeforces Rating 3206 这个成绩不是白给的。
3.4 小结:踩到的坑
- Pro 版本当前吞吐量有限:高峰期明显感觉到延迟,DeepSeek 自己也承认了这一点,预计下半年华为昇腾950超节点大规模部署后会改善
- 中英文混杂问题:偶尔还会出现,V3 时代的老毛病,V4 有改善但未根治
- Think Max 模式消耗 token 翻倍:用于日常开发有点奢侈,建议仅在关键推理任务开 Max,普通任务用 High 或不开
第四章:API 接入实战——把 V4 塞进你的开发工作流
4.1 最简接入(5分钟搞定)
V4 同时支持 OpenAI 和 Anthropic 两套接口标准,如果你原来的代码用的是 OpenAI SDK,只需要改两行:
# 改之前(OpenAI)
client = OpenAI(api_key="sk-...", base_url="https://api.openai.com/v1")
model = "gpt-4o"
# 改之后(DeepSeek V4)
client = OpenAI(api_key="你的DeepSeek Key", base_url="https://api.deepseek.com")
model = "deepseek-v4-pro"
就这样,其他代码一行不动。
4.2 思考模式的正确打开方式
# 适合复杂推理任务:Think Max
response = client.chat.completions.create(
model="deepseek-v4-pro",
messages=[{"role": "user", "content": "推导Heston模型的特征函数"}],
extra_body={
"thinking": {"type": "enabled"},
"reasoning_effort": "max" # 三档: high / max
},
)
# 思考过程在 reasoning_content 里
thinking_process = response.choices[0].message.reasoning_content
final_answer = response.choices[0].message.content
提醒:多轮对话时,
reasoning_content会被 API 自动忽略,不会占用上下文 token,放心用。
4.3 长文档场景:1M 上下文实战
with open("annual_report.txt", "r") as f:
report = f.read()
response = client.chat.completions.create(
model="deepseek-v4-pro",
messages=[
{"role": "user", "content": f"以下是公司年报全文,请提取核心财务风险并计算关键比率:\n\n{report}"}
]
)
V4 支持最长 1M token 的上下文,普通年报直接塞,基本不用担心截断。
第五章:一些个人想法
关于开源这件事
2026年,还在坚定选择 MIT 开源路线,DeepSeek 的勇气值得敬佩。技术报告里那句"训练过程中出现了 loss spike,我们用了两个 trick 解决,但底层机理仍是 open question"——一个训练了1.6万亿参数模型的团队,公开承认"我们不知道为什么这有效",这种诚实在2026年已经相当稀罕。
关于华为这件事
技术报告第3.1节明确写了同时支持 NVIDIA GPU 和华为昇腾 NPU,FP4 精度刚好对应华为昇腾950PR的原生支持精度。下半年昇腾950超节点大规模上线之后,Pro 版本的价格还会大幅下调。国产算力生态的重要一步。
关于"AI会抢走我工作"这件事
我每次看到新模型发布,都会想这个问题。结论每次都一样:不会,但会抢走不愿意学会用 AI 的同行的工作。V4 让我写量化策略的效率又提升了30%左右,省出来的时间我用来做更复杂的风险建模——饭碗还在,只是换了个端法。
结语:该来的终于来了
DeepSeek V4 确实值得这15个月的等待。
百万上下文、开源 MIT、性能比肩顶级闭源模型、价格低一个数量级——这些标签堆在一起,确实重新定义了开源模型能做到什么。
对于我们这些每天需要处理长文档、写代码、做数据分析的工程师来说,V4 已经完全具备作为主力 API 的资格。Flash 版本日常开发,Pro 版本关键任务,Think Max 模式复杂推理——这套组合拳,性价比无解。
DeepSeek 引用了荀子的那句话作为结尾:"不诱于誉,不恐于诽,率道而行,端然正己。"
不评价这句话说得对不对,但我知道的是——V4 出来,我的 API 账单要重新算了。
关于作者: 日常在量化金融和 AI 工程之间反复横跳,CSDN 博主,主要写大模型落地实践和金融科技相关内容。欢迎评论区聊聊你用 V4 的场景。

欢迎加入DeepSeek 技术社区。在这里,你可以找到志同道合的朋友,共同探索AI技术的奥秘。
更多推荐


 12
12 0
0- 0



 已为社区贡献15条内容
已为社区贡献15条内容

所有评论(0)