DeepSeek v4 Compressor kv cache压缩模块
背景
DeepSeek V4采用了4种kv cache压缩相关的技术:
- Compressed Sparse Attention (CSA)
- Heavily Compressed Attention (HCA)
- (Sliding Window Attention) SWA
- DSA,在DeepSeek V3.2中已经开始使用。
CSA就是c4a结合DSA。
HCA就是c128a,不会再使用DSA。
c4a和c128a都会再结合SWA,把1/N的kv cache与SWA的128 token kv cache进行拼接。
某些压缩比例为0的层只使用SWA。
这里介绍c4a和c128a共享的1/N倍kv cache压缩模块Compressor。
其他参考
https://vllm.ai/blog/deepseek-v4
https://www.lmsys.org/blog/2026-04-25-deepseek-v4/
DeepSeek V4的KV cache压缩策略
采用了2种压缩策略(CSA, HCA)以及DSA和SWA,模型层总共分为3种
CSA层
每个4个token为一组压缩为1个token。
压缩的时候,会结合当前4 token和前4 token分组的kv cache进行加权求和得到压缩后的1个token。
因为超长上下文,1/4压缩仍然上下文很长,因此采用topk的方式,采用了一个indexer模块来选择最相关的topk个token。
同时采用window size的SWA层,把最近的前N个token也纳入attention计算。
HCA层
每128个token为一组为1个token。
压缩的时候,只结合当前分组的128个token压缩,不会看前面一个窗口的信息。
不再使用indexer模块进行topk选择。
也使用window size的SWA层。
不压缩层
不使用token压缩,只使用SWA层。
Compressor功能详解
prefill阶段流程图
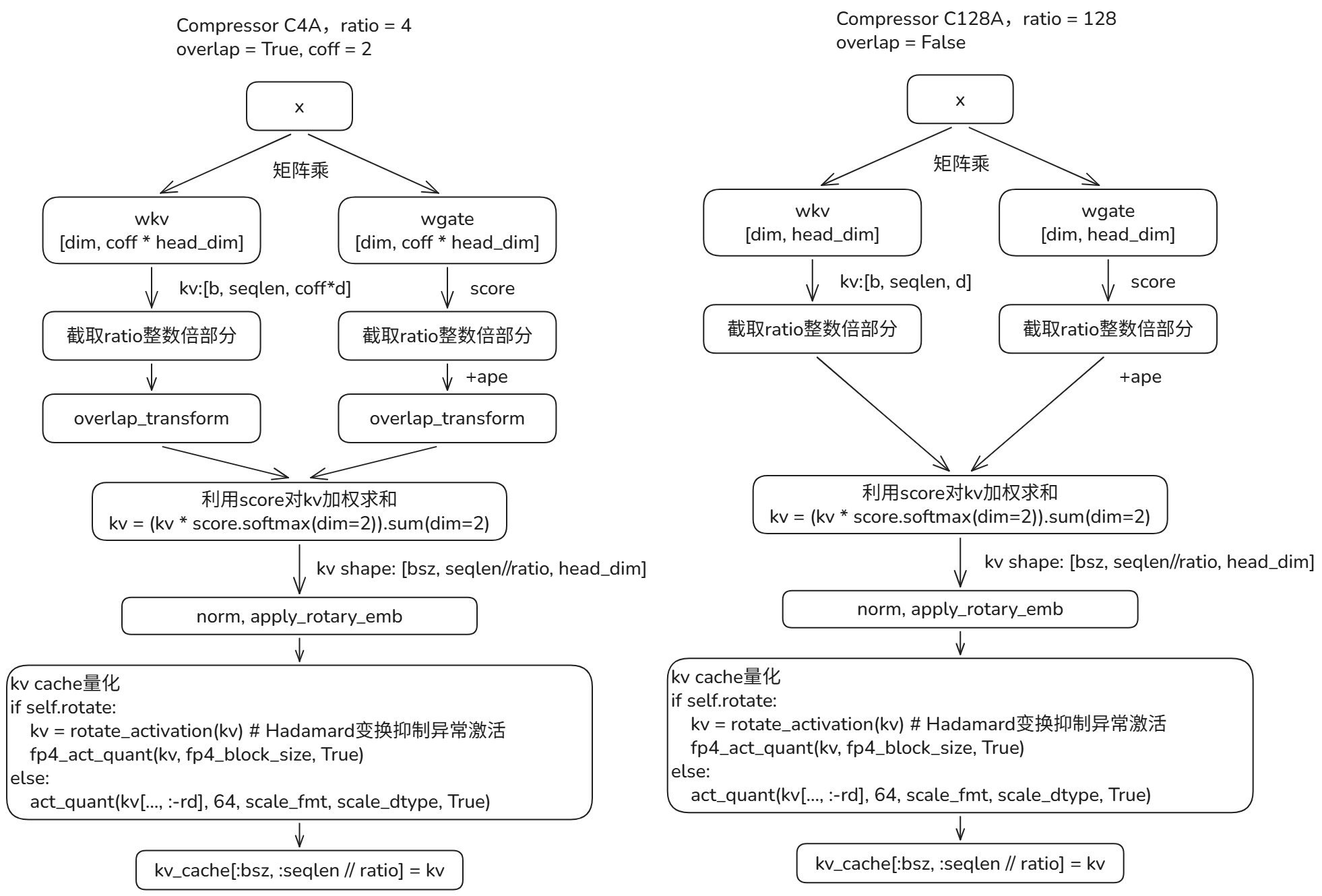
对于c128a也就是compress_ratio=128时,没有overlap处理相对比较简单:
先通过两个矩阵乘分别得到kv和store部分,然后截取compress_ratio整数倍的长度kv和score部分。
然后通过score对kv进行加权求和,得到压缩后的kv cache。
kv cache从压缩前的[b, seqlen, coff*d]变为[bsz, seqlen//ratio, head_dim]。
对于输入sequence末尾非整数倍长度的处理:
采用了kv_state和score_state两个状态buffer来保存压缩前的kv和store在compress_ratio整数倍截断后的剩余部分。
当decode不断迭代,当前长度达到compress_ratio整数倍后,直接基于kv_state和score_state得到这个新的压缩块的kv cache。
对于c4a,主要的区别是overlap,把前后两个压缩块的信息结合起来进行压缩kv。
在overlap场景下,kv_state和score_state保存的是两个窗口长度的kv cache信息:
remainder = seqlen % ratio
cutoff = seqlen - remainder
# second half for normal when overlap
offset = ratio if overlap else 0
if overlap and cutoff >= ratio:
# 前一个窗口的 token 从 cutoff-ratio 开始,到 cutoff 结束,共 ratio 个 token
# 前一个窗口的 score 从 cutoff-ratio 开始,到 cutoff 结束,共 ratio 个 token
self.kv_state[:bsz, :ratio] = kv[:, cutoff-ratio : cutoff]
self.score_state[:bsz, :ratio] = score[:, cutoff-ratio : cutoff] + self.ape
if remainder > 0:
# 当前窗口的 token 从 cutoff 开始,到 seqlen 结束,共 remainder 个 token
# 当前窗口的 score 从 cutoff 开始,到 seqlen 结束,共 remainder 个 token
kv, self.kv_state[:bsz, offset : offset+remainder] = kv.split([cutoff, remainder], dim=1)
self.score_state[:bsz, offset : offset+remainder] = score[:, cutoff:] + self.ape[:remainder]当overlap场景,kv_state和score_state存储的是2个窗口的信息。decode阶段达到compress_ratio整数倍后,压缩kv后,把后一个窗口的信息移动到之前的窗口,为下一个窗口计算腾出位置。
压缩之前使用overlap_transform流程进行处理:把前一个窗口的前半部分head_dim和当前窗口的后半部分head_dim进行拼接。然后再进行加强求和。
这里为何要把head_dim翻倍,并且前后窗口各取前后半部分拼接,也许是算法的trick吧,不太清楚为啥要这么做。
Compressor代码注释版
原始代码:https://huggingface.co/deepseek-ai/DeepSeek-V4-Pro/tree/main/inference
class Compressor(nn.Module):
"""Compresses KV cache via learned gated pooling over `compress_ratio` consecutive tokens.
When overlap=True (ratio==4), uses overlapping windows for smoother compression boundaries."""
def __init__(self, args: ModelArgs, compress_ratio: int = 4, head_dim: int = 512, rotate: bool = False):
super().__init__()
self.dim = args.dim
self.head_dim = head_dim
self.rope_head_dim = args.rope_head_dim
self.nope_head_dim = head_dim - args.rope_head_dim
self.compress_ratio = compress_ratio
self.overlap = compress_ratio == 4
self.rotate = rotate
# overlap 时,需要保留前一个窗口的 token,所以 coff = 1 + compress_ratio
coff = 1 + self.overlap
# ape 是 Absolute Position Embedding (绝对位置编码)的缩写,它是一个 可学习的门控位置偏置 (learned gating positional bias),
# 在 KV cache 压缩时用于给不同位置的 token 分配不同的重要性权重。
self.ape = nn.Parameter(torch.empty(compress_ratio, coff * self.head_dim, dtype=torch.float32))
# wkv and wgate in the checkpoint is stored in bf16, while the parameter here is stored in fp32 for convenient.
# When overlap, the first half of dims is for overlapping compression, second half for normal.
self.wkv = Linear(self.dim, coff * self.head_dim, dtype=torch.float32)
self.wgate = Linear(self.dim, coff * self.head_dim, dtype=torch.float32)
self.norm = RMSNorm(self.head_dim, args.norm_eps)
self.kv_cache: torch.Tensor = None # assigned lazily from Attention.kv_cache
# State buffers for decode-phase incremental compression. prefill阶段只是填充相关信息
# With overlap: state[:, :ratio] = overlapping window, state[:, ratio:] = current window.
self.register_buffer("kv_state", torch.zeros(args.max_batch_size, coff * compress_ratio, coff * self.head_dim, dtype=torch.float32), persistent=False)
self.register_buffer("score_state", torch.full((args.max_batch_size, coff * compress_ratio, coff * self.head_dim), float("-inf"), dtype=torch.float32), persistent=False)
self.freqs_cis: torch.Tensor = None
def overlap_transform(self, tensor: torch.Tensor, value=0):
# tensor: [bsz, seqlen//ratio, ratio, 2 * head_dim]
b, s, _, _ = tensor.size()
ratio, d = self.compress_ratio, self.head_dim
new_tensor = tensor.new_full((b, s, 2 * ratio, d), value)
# 当前窗口的head后半部分
new_tensor[:, :, ratio:] = tensor[:, :, :, d:]
# 前一个窗口的head前半部分
new_tensor[:, 1:, :ratio] = tensor[:, :-1, :, :d]
# 完成后的shape: [bsz, seqlen//ratio, 2 * ratio, head_dim]
return new_tensor
def forward(self, x: torch.Tensor, start_pos: int):
assert self.kv_cache is not None
bsz, seqlen, _ = x.size()
ratio, overlap, d, rd = self.compress_ratio, self.overlap, self.head_dim, self.rope_head_dim
dtype = x.dtype
# compression need fp32
x = x.float()
# kv shape: [b, seqlen, coff*d]
kv = self.wkv(x)
score = self.wgate(x)
if start_pos == 0:
# start_pos == 0为prefill阶段,一次性处理[0, seqlen)范围的token
should_compress = seqlen >= ratio
remainder = seqlen % ratio
cutoff = seqlen - remainder
# second half for normal when overlap
offset = ratio if overlap else 0
if overlap and cutoff >= ratio:
# 前一个窗口的 token 从 cutoff-ratio 开始,到 cutoff 结束,共 ratio 个 token
# 前一个窗口的 score 从 cutoff-ratio 开始,到 cutoff 结束,共 ratio 个 token
self.kv_state[:bsz, :ratio] = kv[:, cutoff-ratio : cutoff]
self.score_state[:bsz, :ratio] = score[:, cutoff-ratio : cutoff] + self.ape
if remainder > 0:
# 当前窗口的 token 从 cutoff 开始,到 seqlen 结束,共 remainder 个 token
# 当前窗口的 score 从 cutoff 开始,到 seqlen 结束,共 remainder 个 token
kv, self.kv_state[:bsz, offset : offset+remainder] = kv.split([cutoff, remainder], dim=1)
self.score_state[:bsz, offset : offset+remainder] = score[:, cutoff:] + self.ape[:remainder]
score = score[:, :cutoff]
# 完成后kv和score shape: [bsz, seqlen//ratio, ratio, coff * head_dim]
kv = kv.unflatten(1, (-1, ratio))
score = score.unflatten(1, (-1, ratio)) + self.ape
if overlap:
# 完成后kv和score shape: [bsz, seqlen//ratio, 2*ratio, head_dim]
kv = self.overlap_transform(kv, 0)
score = self.overlap_transform(score, float("-inf"))
# 利用score进行softmax得到概率分布,对kv进行加权,在compress_ratio维度上进行求和
# 完成后kv shape: [bsz, seqlen//ratio, head_dim]
kv = (kv * score.softmax(dim=2)).sum(dim=2)
else:
# start_pos != 0为decode阶段,每次处理start_pos=seqlen-1的一个token
# 当当前token是压缩窗口的最后一个token时,进行压缩
should_compress = (start_pos + 1) % self.compress_ratio == 0
score += self.ape[start_pos % ratio]
if overlap:
self.kv_state[:bsz, ratio + start_pos % ratio] = kv.squeeze(1)
self.score_state[:bsz, ratio + start_pos % ratio] = score.squeeze(1)
if should_compress:
# 与overlap_transform变化一样,拼接前一个窗口和当前窗口的信息,不过前后窗口各拿取一半信息
# 前一个窗口取了前半部分head部分,当前窗口取了后半部分head
kv_state = torch.cat([self.kv_state[:bsz, :ratio, :d], self.kv_state[:bsz, ratio:, d:]], dim=1)
score_state = torch.cat([self.score_state[:bsz, :ratio, :d], self.score_state[:bsz, ratio:, d:]], dim=1)
# 利用score进行softmax得到概率分布,对kv进行加权,在compress_ratio维度上进行求和
kv = (kv_state * score_state.softmax(dim=1)).sum(dim=1, keepdim=True)
# 压缩kv后,把后一个窗口的信息移动到之前的窗口,为下一个窗口计算腾出位置
self.kv_state[:bsz, :ratio] = self.kv_state[:bsz, ratio:]
self.score_state[:bsz, :ratio] = self.score_state[:bsz, ratio:]
else:
self.kv_state[:bsz, start_pos % ratio] = kv.squeeze(1)
self.score_state[:bsz, start_pos % ratio] = score.squeeze(1)
if should_compress:
# 利用score进行softmax得到概率分布,对kv进行加权,在compress_ratio维度上进行求和
kv = (self.kv_state[:bsz] * self.score_state[:bsz].softmax(dim=1)).sum(dim=1, keepdim=True)
if not should_compress:
return
kv = self.norm(kv.to(dtype))
if start_pos == 0:
freqs_cis = self.freqs_cis[:cutoff:ratio]
else:
freqs_cis = self.freqs_cis[start_pos + 1 - self.compress_ratio].unsqueeze(0)
apply_rotary_emb(kv[..., -rd:], freqs_cis)
if self.rotate:
# hadamard rotation抑制异常激活值
kv = rotate_activation(kv)
# FP4量化
fp4_act_quant(kv, fp4_block_size, True)
else:
# FP8量化
act_quant(kv[..., :-rd], 64, scale_fmt, scale_dtype, True)
if start_pos == 0:
self.kv_cache[:bsz, :seqlen // ratio] = kv
else:
self.kv_cache[:bsz, start_pos // ratio] = kv.squeeze(1)
return kv量化
rotate参数表明是否进行hadamard rotation抑制异常激活值,并且使用FP4 kv cache量化和attention计算。可以参考:https://blog.csdn.net/u013701860/article/details/139407355
在indexer模块中的compressor采用了FP4量化,而attention层的compressor模块则采用FP8量化和计算。

欢迎加入DeepSeek 技术社区。在这里,你可以找到志同道合的朋友,共同探索AI技术的奥秘。
更多推荐



 6
6 0
0- 0



 已为社区贡献1条内容
已为社区贡献1条内容

所有评论(0)