DeepSeek V4 突然发布,DeepSeek-V4 技术报告深度解读
DeepSeek-V4重磅发布,带来两大版本:旗舰版V4-Pro(1.6万亿参数)和轻量版V4-Flash(2840亿参数),均支持100万token上下文。通过混合注意力机制等三大创新技术,将推理计算量最高降低至前代的10%,显存占用降至7%。模型采用MIT许可证开源,适配国产算力平台,在多项评测中表现优异,虽仍落后顶级闭源模型3-6个月,但通过成本重构使长上下文处理成为标配。同时文章指出,AI
DeepSeek-V4 正式发布。它不只是又一个升级版本,而是一次从架构到成本的结构性重构。

01 前言:两个版本,清晰定位
2026年4月24日,DeepSeek-V4 预览版正式发布并同步开源。
这次发布包含两个 MoE(混合专家)模型,定位完全不同:
DeepSeek-V4-Pro(旗舰版)
- 总参数:1.6 万亿
- 激活参数/Token:490 亿
- 定位:对标顶级闭源模型
- 适用场景:复杂推理、高强度代码、Agent 任务
DeepSeek-V4-Flash(轻量版)
- 总参数:2840 亿
- 激活参数/Token:130 亿
- 定位:极致性价比
- 适用场景:高频通用场景、简单任务
两者均原生支持 100 万 token 上下文,输出长度最大 384K tokens。更值得一提的是,V4 采用 MIT 许可证开源,商用限制极少。
02 核心架构:三大创新驱动效率革命
一、混合注意力机制(CSA + HCA)
V4 最核心的创新,在于结合了压缩稀疏注意力(CSA)和高度压缩注意力(HCA)。
效果有多惊人?以处理 100 万上下文为例,相比前代 V3.2:
V4-Pro
- 推理计算量降至 27%
- KV Cache 显存占用降至 10%
V4-Flash
- 推理计算量降至 10%
- KV Cache 显存占用降至 7%
这意味着什么?过去跑 100 万 token 需要 10 份算力,现在只需 1 份。
DeepSeek 甚至直言:从现在起,1M 上下文将是所有官方服务的“标配”。
二、流形约束超连接(mHC)
这是对传统残差连接的改进。简单理解:传统残差连接像是直通车道,而 mHC 给这条车道加了“导航系统”,让信号在不同层之间传播更稳定,训练更顺畅。
三、Muon 优化器
V4 用 Muon 替代了业界传统的 AdamW 优化器。这一改变显著加速了收敛,并提升了训练稳定性。
两个版本的训练数据规模:
- V4-Pro:33 万亿 tokens
- V4-Flash:32 万亿 tokens
03 后训练策略:“分而治之”再融合
V4 的后训练分为两个阶段:
阶段一:先通过 SFT(监督微调)和 GRPO 强化学习,分别训练不同领域的“专家模块”。
阶段二:通过在线蒸馏,把这些专家模块融合成一个统一模型。
这种策略的优势在于:每个专家可以在自己擅长的领域做到极致,最后融合时不会相互干扰,模型整体性能更强。
04 性能表现:开源最强,逼近闭顶尖峰
推理与代码能力
在 Apex Shortlist(90.2%)和 Codeforces(Rating 3206)两项硬核任务中,V4-Pro-Max 拔得头筹。
官方称其“超越所有已公开评测的开源模型,取得比肩世界顶级闭源模型的优异成绩。”
Agent 能力
这是 V4 重点发力的方向:
- 在 SWE Verified(软件工程任务)上,四款顶级模型打成平手(80.6%)
- V4-Pro 在 Terminal Bench 2.0(67.9%)和 Toolathlon(51.8%)上表现突出
官方内部评测:使用体验优于 Sonnet 4.5,交付质量接近 Opus 4.6 非思考模式(但与 Opus 4.6 思考模式仍有差距)。
V4 还针对 Claude Code、OpenClaw、CodeBuddy 等主流 Agent 框架进行了专项适配优化。
客观差距:官方坦诚承认
技术报告中最值得尊敬的一点——DeepSeek 明确承认:
V4 的能力水平仍落后 GPT-5.4 和 Gemini-3.1-Pro,发展轨迹大约滞后前沿闭源模型 3 至 6 个月。
这不是一次能力“越级”,而是一次**“把长上下文成本重构”的基础设施发布**。
05 思考模式:可调节的“脑力投入”
V4 支持 reasoning_effort 参数,可设置思考强度(high / max):
| 场景 | 建议 |
|---|---|
| 复杂 Agent 任务 | 开启思考模式,强度设为 max |
| 简单问答 | 非思考模式 |
这个设计让开发者可以根据任务复杂度灵活调节“脑力投入”,避免杀鸡用牛刀。
06 国产算力适配
一个值得关注的信息:V4 已适配 华为昇腾平台,昇腾 CANN 在发布当日进行直播首发。
同时,寒武纪已完成对 V4 两个版本的 Day 0 适配,适配代码已开源到 GitHub。
这意味着国内用户可以在国产算力平台上部署 V4,这是对自主可控生态的明确支持。
07 对开发者的实际影响
价格体系(单位:元/百万 Token)
| 模型 | 输入(缓存命中) | 输入(缓存未命中) | 输出 |
|---|---|---|---|
| V4-Flash | 0.2 元 | 1 元 | 2 元 |
| V4-Pro | 1 元 | 12 元 | 24 元 |
缓存命中的价格极低,鼓励开发者通过缓存优化降低调用成本。
重要:迁移提醒
原有的 deepseek-chat 和 deepseek-reasoner 模型名将于 2026年7月24日 停止使用,开发者需在此之前完成迁移。
可用渠道
- Web/App:chat.deepseek.com
- API:兼容 OpenAI ChatCompletions 和 Anthropic 接口
- 开源:Hugging Face + 魔搭社区
08 总结:V4 的核心价值
| 维度 | 结论 |
|---|---|
| 技术定位 | 不是能力越级,而是效率重构 |
| 最大突破 | 让 1M 上下文从“奢侈”变“标配” |
| 竞争位置 | 开源最强,闭源暂有差距(3-6个月) |
| 生态意义 | 国产算力适配 + MIT 开源 + Agent 专项优化 |
DeepSeek 没有选择在能力上硬碰硬地追赶 GPT-5.4,而是走了一条更务实的路——把长上下文的门槛打下来,为下一阶段的复杂任务铺好基础设施。
说真的,这两年看着身边一个个搞Java、C++、前端、数据、架构的开始卷大模型,挺唏嘘的。大家最开始都是写接口、搞Spring Boot、连数据库、配Redis,稳稳当当过日子。
结果GPT、DeepSeek火了之后,整条线上的人都开始有点慌了,大家都在想:“我是不是要学大模型,不然这饭碗还能保多久?”
我先给出最直接的答案:一定要把现有的技术和大模型结合起来,而不是抛弃你们现有技术!掌握AI能力的Java工程师比纯Java岗要吃香的多。
即使现在裁员、降薪、团队解散的比比皆是……但后续的趋势一定是AI应用落地!大模型方向才是实现职业升级、提升薪资待遇的绝佳机遇!
这绝非空谈。数据说话
2025年的最后一个月,脉脉高聘发布了《2025年度人才迁徙报告》,披露了2025年前10个月的招聘市场现状。
AI领域的人才需求呈现出极为迫切的“井喷”态势
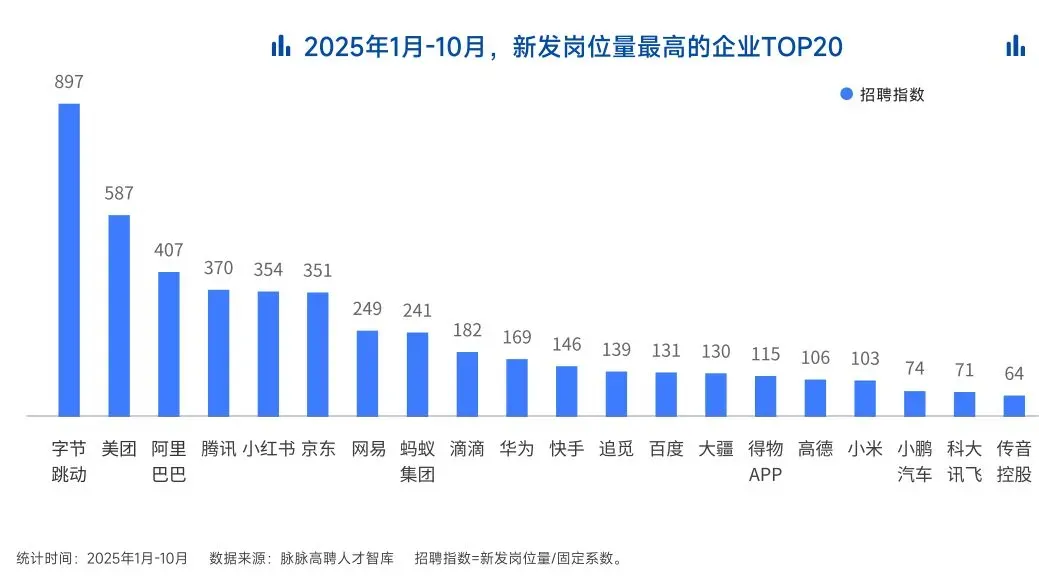
2025年前10个月,新发AI岗位量同比增长543%,9月单月同比增幅超11倍。同时,在薪资方面,AI领域也显著领先。其中,月薪排名前20的高薪岗位平均月薪均超过6万元,而这些席位大部分被AI研发岗占据。
与此相对应,市场为AI人才支付了显著的溢价:算法工程师中,专攻AIGC方向的岗位平均薪资较普通算法工程师高出近18%;产品经理岗位中,AI方向的产品经理薪资也领先约20%。
当你意识到“技术+AI”是个人突围的最佳路径时,整个就业市场的数据也印证了同一个事实:AI大模型正成为高薪机会的最大源头。
最后
我在一线科技企业深耕十二载,见证过太多因技术卡位而跃迁的案例。那些率先拥抱 AI 的同事,早已在效率与薪资上形成代际优势,我意识到有很多经验和知识值得分享给大家,也可以通过我们的能力和经验解答大家在大模型的学习中的很多困惑。
我整理出这套 AI 大模型突围资料包【允许白嫖】:
- ✅从入门到精通的全套视频教程
- ✅AI大模型学习路线图(0基础到项目实战仅需90天)
- ✅大模型书籍与技术文档PDF
- ✅各大厂大模型面试题目详解
- ✅640套AI大模型报告合集
- ✅大模型入门实战训练
这份完整版的大模型 AI 学习和面试资料已经上传CSDN,朋友们如果需要可以微信扫描下方CSDN官方认证二维码免费领取【保证100%免费】

①从入门到精通的全套视频教程
包含提示词工程、RAG、Agent等技术点

② AI大模型学习路线图(0基础到项目实战仅需90天)
全过程AI大模型学习路线
③学习电子书籍和技术文档
市面上的大模型书籍确实太多了,这些是我精选出来的

④各大厂大模型面试题目详解

⑤640套AI大模型报告合集

⑥大模型入门实战训练

👉获取方式:
有需要的小伙伴,可以保存图片到wx扫描二v码免费领取【保证100%免费】🆓


欢迎加入DeepSeek 技术社区。在这里,你可以找到志同道合的朋友,共同探索AI技术的奥秘。
更多推荐



 8
8 0
0- 0



 已为社区贡献10条内容
已为社区贡献10条内容

所有评论(0)