扒掉营销外衣:硬核拆解 GPT-5.5 与 DeepSeek V4 底层架构,AI 程序员的饭碗真保不住了?
2026年4月,AI领域迎来重大突破:OpenAI发布GPT-5.5,以72%的Token压榨率提升和零延迟的软硬协同设计,成为高效的"执行专员";中国DeepSeek推出V4,支持100万Token上下文,采用创新的混合注意力机制和国产芯片适配,实现极致算力优化。两大模型各有优势:GPT-5.5擅长智能体编程和电脑操控,而DeepSeek V4更适合大规模代码重构和海量文档分
2026年4月的这24小时,注定是大模型历史上最血雨腥风的一天。OpenAI 带着内部代号 "Spud" 的完全重训练基础模型 GPT-5.5 炸场,而中国开源之光 DeepSeek 也毫不客气,直接掏出了支持 100万 Token 极限上下文的 V4 预览版。
外行看热闹,内行看门道。大模型竞争的下半场,拼的根本不是闲聊能力,而是 Agentic Coding(智能体编程)流水线的工程落地效率 与 算力/内存的极致压榨。这篇文章我们将段落拆碎,直接把最硬核的技术细节和选型逻辑喂到你嘴里。

一、GPT-5.5:极其“功利”的工程怪兽
OpenAI 这次宣称 GPT-5.5 是自 GPT-4.5 以来首个从头重训练的模型。别被“为现实世界工作打造”的套话忽悠了,它本质上是一个极其“功利”的执行机器,核心优势体现在三个维度:
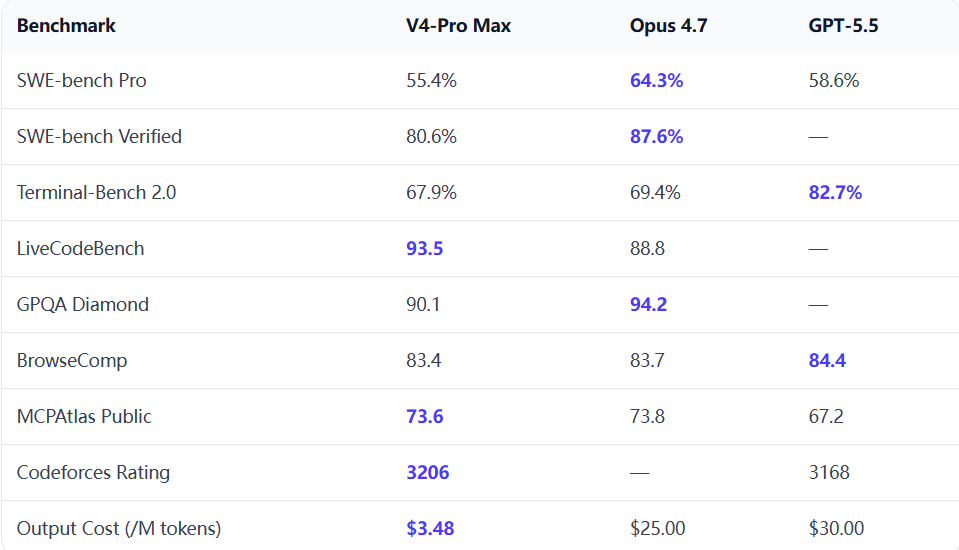
- 令人发指的 Token 压榨率: 在真实的编程评测中,面对同样的代码重构任务,GPT-5.5 的输出 Token 消耗量比 Claude Opus 4.7 整整少了 72%。在全自动的 Agent 循环中,大段的解释完全是浪费钱和 Context。减少 72% 的输出意味着更低的“上下文腐烂(Context Rot)”概率,以及吞吐量的成倍飙升。
- 不讲武德的软硬协同与零延迟惩罚: GPT-5.5 与 NVIDIA GB200/GB300 NVL72 系统进行了深度协同设计。在能力大幅提升的情况下,它居然做到了与 GPT-5.4 完全持平的单 Token 延迟。更恐怖的是,OpenAI 让 Codex 自己分析了生产流量,写出了自定义负载均衡启发式算法,将 Token 生成速度硬生生拉高了 20%。
- 碾压级的 Agentic(智能体)跑分: 在考察真实命令行工作流的 Terminal-Bench 2.0 中,GPT-5.5 跑出 82.7% 的碾压级成绩(Claude Opus 4.7 仅为 69.4%)。在评估独立操控真实电脑界面的 OSWorld-Verified 榜单上,它拿下了 78.7% 的高分(人类平均仅 72.4%)。它不再是“聊天机器人”,而是“执行专员”。
二、多模态新生态:GPT-5.5 与 Image 2 的降维打击
只看文本能力就太狭隘了。对于全栈开发者和前端工程师来说,最具杀伤力的是其背后的视觉多模态生态整合:
- 原生全模态架构: GPT-5.5 原生处理文本、图像、音频和视频,在一个统一架构内完成,而非多个模型拼接。
- GPT-5.4 Image 2 复合模型: OpenAI 推出了整合最新图像生成能力的复合产品。
- Agentic 工作流的视觉闭环: 在智能体工作流中,AI 不仅能读懂需求写出前端代码,还能在同一次交互中自行生成所需的 UI 高保真素材。文本推理、代码生成与视觉生成的无缝融合,直接跨越了以往需要微服务来回调用的痛点。
三、DeepSeek V4:东方算力极客的极限架构压榨
如果说 GPT-5.5 是美金算力的结晶,DeepSeek V4 则向全世界展示了什么叫作“极限架构压榨”。在算力受限的客观现实下,V4 祭出了令人拍案叫绝的底层创新:
- 1.6万亿参数的极致“瘦身”: DeepSeek V4-Pro 总参数量高达 1.6 万亿,但在 MoE 架构加持下,每个 Token 仅激活 490 亿参数。主打性价比的 Flash 版本,总参数 284B,激活参数仅区区 13B。
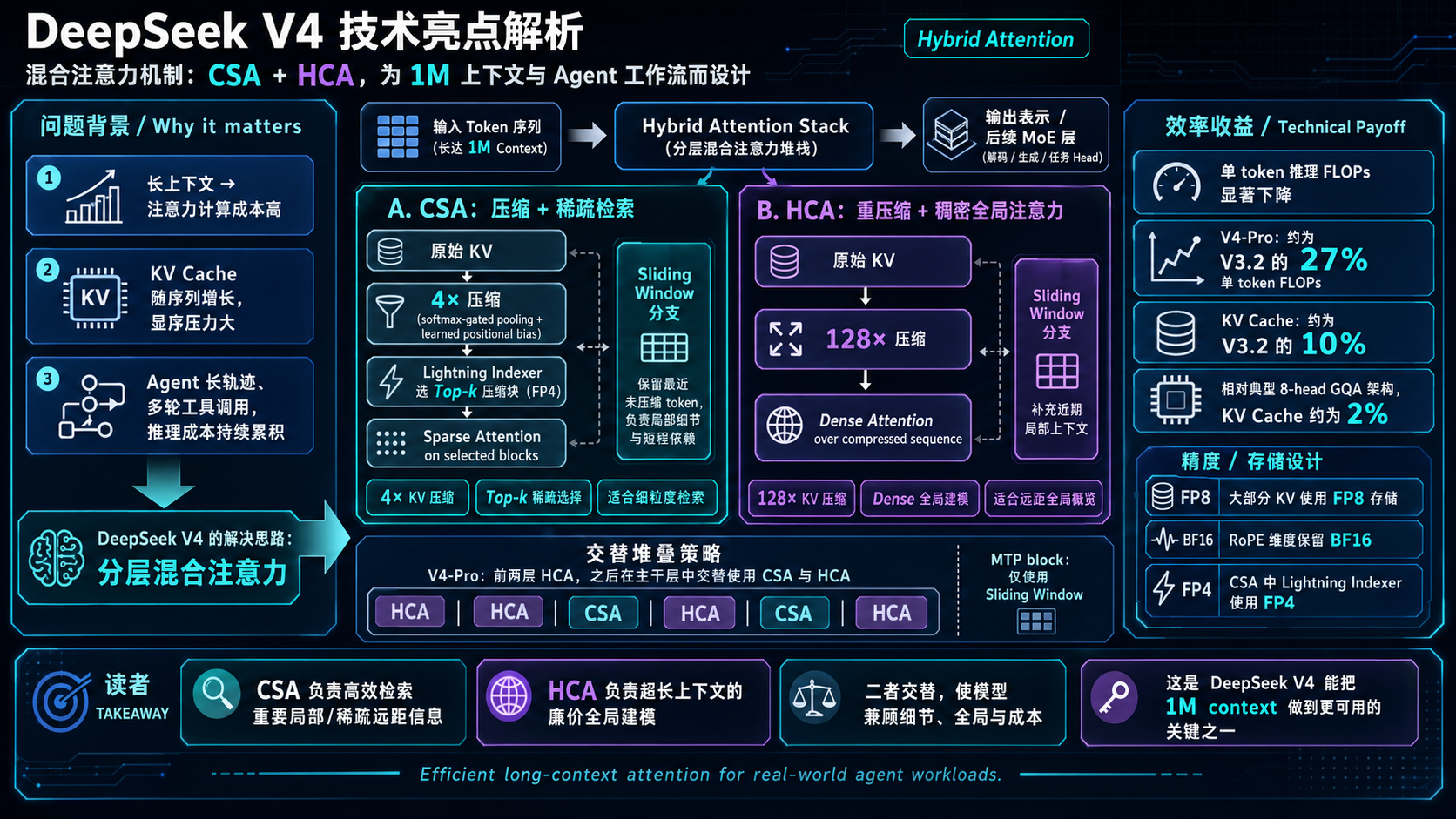
- 黑科技揭秘:CSA 与 HCA 混合注意力机制: 让 100万 Token 成为业界标配,V4 抛弃了传统架构,首创混合机制:
- CSA(压缩稀疏注意力): 将每 $m$ 个 Token 的 KV 缓存压缩成一个条目,结合动态稀疏注意力(DSA),只挑选最相关的 block 进行计算。
- HCA(重度压缩注意力): 采用 $m'=128$ 的极端压缩率,直接将长序列压缩到极致后执行密集注意力计算。
- 能效飞跃: 在 1M 上下文场景下,V4-Pro 单 Token 推理 FLOPs 仅为上一代 V3.2 的 27%,KV 缓存暴降至 10%。
- 击穿底线的 API 价格与国产算力闭环: V4 Flash 的输入 API 价格仅为 $0.14/M Tokens,Pro 版也只有 $1.74/M。底层更是完全适配国产芯片,据悉在华为最新的昇腾 950PR 芯片上,单卡算力达到竞品 H20 的近 3 倍,并且是国内唯一支持 FP4 低精度的推理产品。
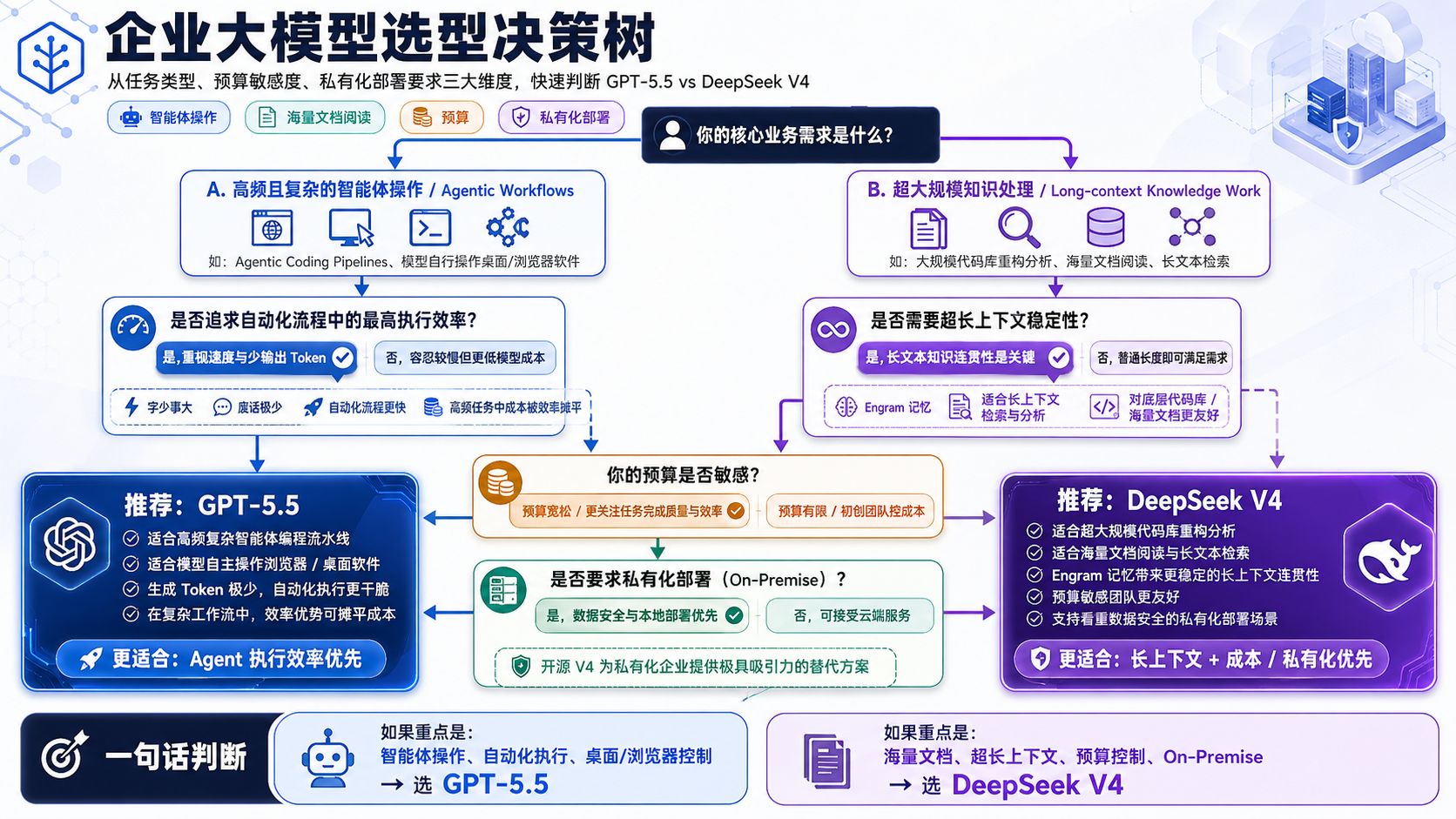
四、CTO 与架构师的选型决策树
作为技术决策者,模型只是工具,搞清业务场景才是王道。面对这两大地表最强模型,请参考以下选型逻辑:
👉 必须上 GPT-5.5 的场景:
- 高频、复杂的全自动智能体编程(Agentic Coding): 以及黑盒 CLI 运维自动化。它“惜字如金”、速度极快,在 Terminal-Bench 2.0 的表现无人能敌。
- 原生电脑操控(Computer Use): OSWorld-Verified 高达 78.7%,适合桌面 RPA 自动化。
- 成本注记: 虽然单价高达 $5/$30 (输入/输出),但由于消耗 Output Token 极少(减少72%),综合任务成本实际上得到了对冲。
👉 无脑冲 DeepSeek V4 的场景:
- 超大规模底层代码库通读与重构: SWE-bench Verified 上的表现(80.6%)极其惊艳,直接碾压 GPT-5.5 的 58.6%。
- 海量跨文档(百万 Token 级别)的检索分析: V4 的 Engram 记忆机制保障了 1M 上下文高达 97% 的大海捞针准确率。
- 私有化企业级部署(On-Premise): 对于需要 100% 数据主权的企业,结合 ZStack AIOS 或 vLLM+Docker 本地拉起,支持 INT4/FP4 量化的 V4 是当下唯一的版本答案。
结语
2026年,OpenAI GPT-5.5 用软硬协同和极端 Token 压缩诠释了“工业级收割机”,而 DeepSeek V4 用惊世骇俗的混合注意力和低精度量化证明了“开源架构无极限”。当 AI 工具链的重构速度超过了人类的学习速度,你的下一个不可替代的竞争力在哪里?欢迎在评论区探讨!

欢迎加入DeepSeek 技术社区。在这里,你可以找到志同道合的朋友,共同探索AI技术的奥秘。
更多推荐



 8
8 0
0- 0



 已为社区贡献1条内容
已为社区贡献1条内容

所有评论(0)