DeepSeek V4:1M 上下文之后,Agent 的瓶颈变了
摘要: DeepSeek V4 的发布标志着大模型从参数竞赛转向工程化落地,聚焦长上下文 Agent 的实际应用。其核心创新在于整合 1M 上下文、任务连续性与成本优化,形成“双模型底座”:V4-Pro 处理复杂推理与代码任务,V4-Flash 负责高频低成本调用。1M 上下文的意义在于避免任务碎片化,让模型直接理解完整项目现场,而稀疏注意力等技术则确保长上下文的高效与低成本执行。这一升级并非单纯

——
正文
开头
这两年,大模型发布会越来越像参数竞赛。
更大的模型、更长的上下文、更高的 benchmark,听起来都很强,但真正落到产品里,工程师最关心的不是“强不强”,而是:
| 它能不能稳定做事?能不能便宜地做事?能不能接进现有系统里做事? |
|---|
DeepSeek V4 Preview 这次真正值得看的地方,不是单个指标,而是它把三个东西放到了一起:
👉 1M 上下文、Agent 能力、低迁移成本。
这意味着,大模型正在从“回答问题的接口”,变成“可以进入工程现场的执行层”。
本质是什么
| 先说结论:DeepSeek V4 不是一次单纯的模型升级,而是一次面向长上下文 Agent 的成本结构升级。 |
|---|
人话说,就是以前我们让模型干复杂活,最大的问题不是它不会,而是它记不住、接不住、算不起。
文档太长,要切。代码仓太大,要截。任务链路太长,要反复提醒。工具一多,状态就乱。
V4 的重点,是试图把这些工程问题压到模型底层和 API 体验里:上下文更长,推理更强,调用更便宜,迁移更平滑。
| 一句话定义:V4 是面向 Agent 工作流的“长上下文双模型底座”。 |
|---|

[插图:V4-Pro 与 V4-Flash 的产品分层]
它解决什么问题
| 先说结论:它解决的不是“聊天更聪明”,而是“复杂任务能不能连续完成”。 |
|---|
① 长文档不再只能靠切片拼接。
1M 上下文的意义,不是让你一次塞更多文字,而是让模型更接近真实工作现场。
项目文档、历史对话、代码片段、接口规范,可以在一次任务链路里保持连续性。
② Agent 不再只适合做演示。
很多 Agent Demo 看起来惊艳,真正接入工程流程就会暴露问题:状态丢失、工具调用不稳、任务拆解不连续。
如果模型本身对长任务、代码、工具链有更强适配,Agent 才有机会从“玩具”变成“流程组件”。
③ 高频调用开始有了更清晰的成本分层。
Pro 负责难题,Flash 负责日常。
这不是简单的高低配,而是给 AI 产品设计者一个更现实的选择:哪些请求需要最强模型,哪些请求只需要快速、稳定、便宜。
| 这一段你可以记住:模型能力是上限,成本结构决定能不能规模化。 |
|---|

[插图:1M 上下文把“项目现场”放进一次对话]
核心内容拆解
一、双模型不是参数炫技,而是产品分层
| 先说结论:V4-Pro 和 V4-Flash 的价值,不是互相替代,而是形成一套可调度的模型组合。 |
|---|
V4-Pro 面向复杂推理、代码任务和更重的 Agent 场景。
V4-Flash 则更像高频入口:参数规模更小,响应更快,成本更适合日常调用。
这对产品设计很重要。
因为真正的 AI 应用,不会永远把所有请求都丢给最强模型。
搜索改写、简单问答、短指令执行、常规代码补全,可以走 Flash。
复杂 Debug、架构分析、长文档推理、多工具执行,再升级到 Pro。
| 说白了:未来 AI 产品的竞争,不只是选什么模型,而是怎么调度模型。 |
|---|
二、1M 上下文不是更长窗口,而是新的工程边界
| 先说结论:1M 上下文真正改变的是任务组织方式。 |
|---|
过去做长任务,我们会先把资料切块,再做召回,再拼上下文,最后让模型回答。
这个流程能用,但很容易出现一个问题:模型看到的是碎片,不是现场。
长上下文把问题往前推了一步。
它让模型可以在更完整的资料范围内做判断,尤其适合代码仓分析、合同审阅、长报告生成、项目复盘、跨文件任务执行。
当然,长上下文不是万能药。
如果没有良好的结构化输入、任务拆解和结果校验,塞得越多,反而越容易乱。
| 真正该升级的不是 prompt 长度,而是上下文管理能力。 |
|---|
三、稀疏注意力的意义,是让长上下文不只停留在指标上
| 先说结论:长上下文能不能落地,核心看成本。 |
|---|
DeepSeek V4 把 token-wise compression 和 DSA 放到结构创新里,本质是在处理一个老问题:上下文越长,计算和显存压力越大。
如果 1M 上下文只是“可以用”,但每次调用都慢得无法接受、贵得无法规模化,那它就只能成为展示能力。
所以这次更值得关注的,不是“支持 1M”这句话本身。
而是它试图把长上下文做成默认能力,并通过结构设计降低长期使用成本。
| 这才是工程化的关键:能力要强,但也要能被高频调用。 |
|---|
四、Agent 优化的核心,是让模型更像一个工程协作者
| 先说结论:Agent 能力不是让模型多说几句推理过程,而是让它能稳定进入工作流。 |
|---|
一个真正可用的 Agent,至少要处理四件事:
① 理解任务目标。
② 读取足够上下文。
③ 调用外部工具。
④ 产出可验证结果。
这也是为什么 V4 强调 Agentic Coding、工具链适配和长任务能力。
代码不是一次问答,工程也不是一次回答。
它需要持续读、持续改、持续验证。
| Agent 的本质,不是“帮你想”,而是“帮你把任务推进到下一步”。 |
|---|
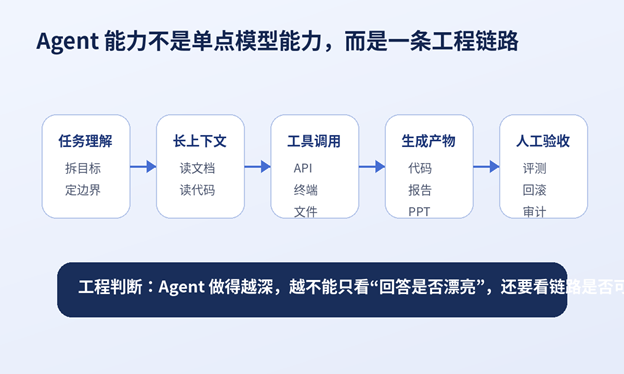
[插图:Agent 工程链路不是单点模型能力]
五、API 兼容,是最容易被低估的产品设计
| 先说结论:真正优秀的模型升级,不应该让开发者重写系统。 |
|---|
这次 API 层的一个关键点,是迁移路径比较直接:保持 base_url,更新模型名即可接入新模型。
同时,V4 还兼容 OpenAI ChatCompletions 与 Anthropic API 风格,并支持 Thinking / Non-Thinking 双模式。
这对工程团队很重要。
因为很多公司不是不能用新模型,而是不敢频繁改底层调用。
一旦接入层不稳定,业务层、日志层、评测层、成本统计都会跟着受影响。
还有一个提醒:旧模型名不能永远依赖。
如果线上系统还把模型名写死在业务代码里,现在就该做一次模型配置治理。
[插图:V4 API 迁移的工程治理思路]
和传统方案区别
| 先说结论:旧逻辑是“模型回答问题”,新逻辑是“模型进入流程”。 |
|---|
旧逻辑:
① 用户提出问题。
② 系统拼一段上下文。
③ 模型给出答案。
④ 用户自己判断能不能用。
新逻辑:
① 系统把任务、资料、历史和工具组织好。
② 模型在长上下文里理解现场。
③ Agent 调用工具推进任务。
④ 结果进入评测、审查、回滚和交付流程。
| 区别就在这里:以前模型是一个“问答接口”,现在模型开始变成“执行链路的一部分”。 |
|---|
这也是为什么我更愿意把 V4 看成工程底座,而不是单纯的新模型。
值不值得做
| 先给判断:值得试,但不值得盲目全量替换。 |
|---|
值得做的场景很明确。
如果你的产品正在做代码助手、知识库问答、企业文档分析、长报告生成、研发 Agent、自动化运营,那 V4 这类长上下文双模型方案非常值得接入评测。
因为这些场景的瓶颈,往往不是“模型不会说”,而是“上下文不完整、链路不连续、成本不可控”。
但如果你的场景只是简单客服、短文本改写、普通闲聊,就没有必要因为新模型发布而立刻重构。
高频、简单、低风险任务,优先看稳定性、延迟和成本。
| 这一段你可以记住:越接近工作流,越值得升级;越接近简单问答,越要谨慎替换。 |
|---|
如果是我来做
| 先说结论:我不会直接“换模型”,我会先做一层模型能力治理。 |
|---|
① 默认 Flash,关键任务升级 Pro。
不要把 Pro 当成所有请求的默认入口。
更合理的方式,是先用 Flash 承接大部分高频请求,再通过任务复杂度、上下文长度、失败重试、用户等级等策略升级到 Pro。
② 把上下文管理做成产品能力。
1M 上下文不是让你无脑塞资料。
我会把文档、代码、历史记录、工具结果分层组织,并明确哪些内容必须进上下文,哪些内容只做检索备份。
③ 建立统一模型适配层。
业务代码不直接写模型名。
模型、模式、温度、最大输出、超时、重试、成本统计,都应该通过配置中心或模型网关管理。
④ 先评测,再替换。
不要拿主观体验判断模型好坏。
至少要准备一组真实任务集:代码任务、文档任务、工具调用任务、异常任务、成本样本。
只有在任务成功率、延迟、成本、稳定性都过线之后,才进入灰度。
| 工程上最危险的不是模型不够强,而是你不知道它什么时候会失控。 |
|---|
总结
DeepSeek V4 这次最重要的信号,不是又多了一个强模型。
而是大模型正在往三个方向收敛:
更长的上下文。
更明确的 Agent 能力。
更低的工程迁移成本。
这三件事合在一起,才会真正影响 AI 应用的形态。
| 未来的 AI 产品,不会只比谁的模型更强,而会比谁更会组织上下文、调度模型、约束 Agent。 |
|---|
模型只是起点。
工程化之后,才是产品。
金句
长上下文不是塞更多文字,而是让模型进入真实工作现场。
模型能力是上限,成本结构决定能不能规模化。
Agent 的本质不是帮你想,而是帮你把任务推进到下一步。
未来 AI 产品的竞争,不只是选什么模型,而是怎么调度模型。
工程上最危险的不是模型不够强,而是你不知道它什么时候会失控。

欢迎加入DeepSeek 技术社区。在这里,你可以找到志同道合的朋友,共同探索AI技术的奥秘。
更多推荐


 8
8 0
0- 0



 已为社区贡献3条内容
已为社区贡献3条内容

所有评论(0)