k8s&vllm&ollama部署deepseek-R1模型,内网无坑
内网环境部署deepseek,vllm openwebui、chatbox访问
这是目录
linux下载ollama

下载后可存放其他服务器
curl -L https://ollama.com/download/ollama-linux-amd64.tgz -o ollama-linux-amd64.tgz
解压后将ollama二进制文件放到/usr/bin/下
做成systemd管理方式参考
[Unit]
Description=Ollama Service
After=network-online.target
[Service]
ExecStart=/usr/bin/ollama serve
User=ollama
Group=ollama
Restart=always
RestartSec=3
Environment="PATH=$PATH"
[Install]
WantedBy=default.target
https://github.com/ollama/ollama/blob/main/docs/linux.md
模型文件下载到本地,打包迁移到k8s等无网络环境使用
启动ollama
ollama serve
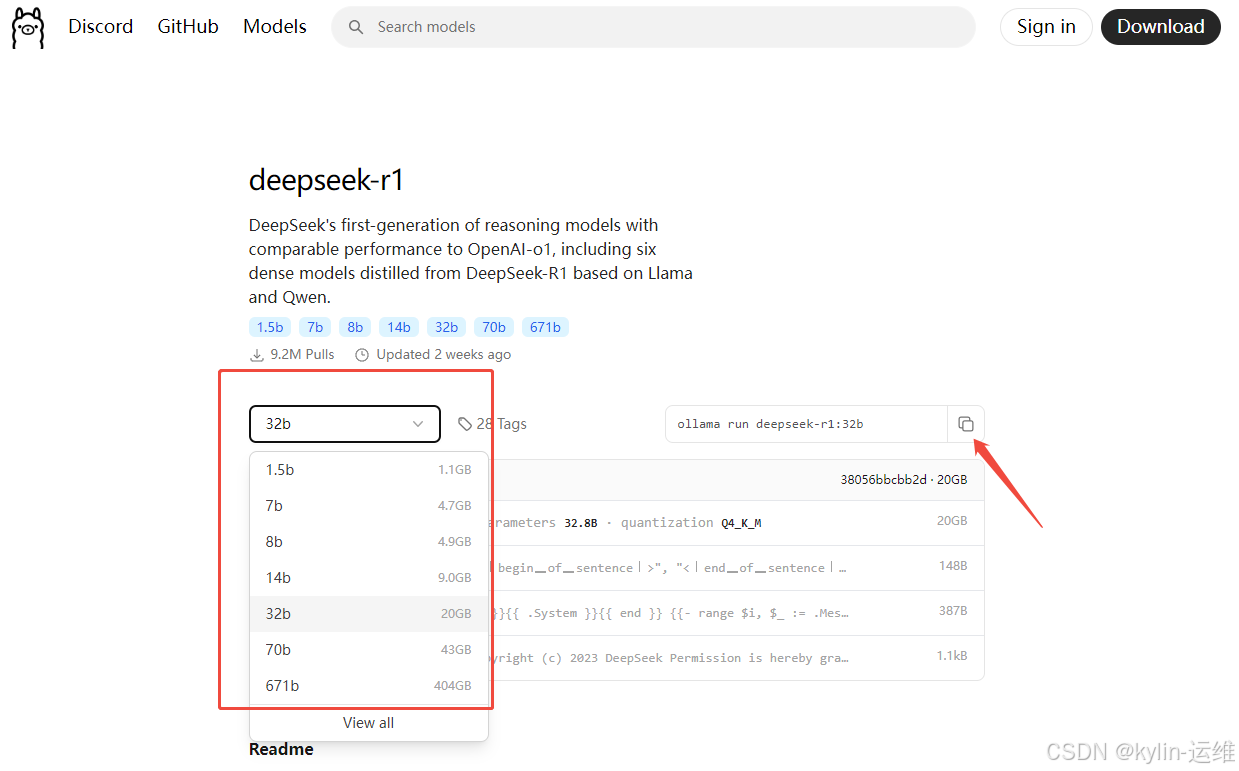
拉取deepseek镜像
ollama pull deepseek-r1:32b
镜像拉取速度变慢为几百kb后可ctrl+c打断重新pull,断点续传
镜像拉取后存放位置为
[root@localhost ~]# ls /root/.ollama/models/
blobs manifests
打包到其他机器或者k8s中使用
[root@localhost ollama]# tar zcf minicpm-v-latest.tar.gz /root/.ollama/models
其他环境解压后将models/blobs/sha256-*文件复制到/root/.ollama/models/blobs/下面
models/manifests/registry.ollama.ai/library/(模型名称)复制到/root/.ollama/models/manifests/registry.ollama.ai/library/
下,即可完成模型文件迁移
root@deepseek32b-599cb74846-l9d25:/# ollama ls
NAME ID SIZE MODIFIED
llama3.1:latest 46e0c10c039e 4.9 GB 51 minutes ago
llama3.2:latest a80c4f17acd5 2.0 GB 51 minutes ago
deepseek-r1:1.5b a42b25d8c10a 1.1 GB 3 hours ago
deepseek-r1:32b 38056bbcbb2d 19 GB 14 hours ago
下载打包ollama镜像
docker pull swr.cn-north-4.myhuaweicloud.com/ddn-k8s/docker.io/ollama/ollama:latest
docker save swr.cn-north-4.myhuaweicloud.com/ddn-k8s/docker.io/ollama/ollama:latest >ollama_latest.tar
非k8s环境使用
(需要有基础环境,显卡驱动,cuda等依赖)
直接ollama serve启动服务,运行模型可在黑屏交互
可以部署open-webui或者安装chatbox应用程序访问 (参考后面介绍)
k8s部署
deployment自行准备,无特殊要求,把模型文件持久化方式pvc或者nfs挂载到pod中
image: swr.cn-north-4.myhuaweicloud.com/ddn-k8s/docker.io/ollama/ollama:latest
创建svc,映射容器内端口11434,按需求可选NodePort暴露端口访问
(不通过chatbox访问可以不建ingress或者NodePort)
访问方式
1. chatbox
安装chatbox,全程下一步即可
https://download.chatboxai.app/releases/Chatbox-1.9.7-Setup.exe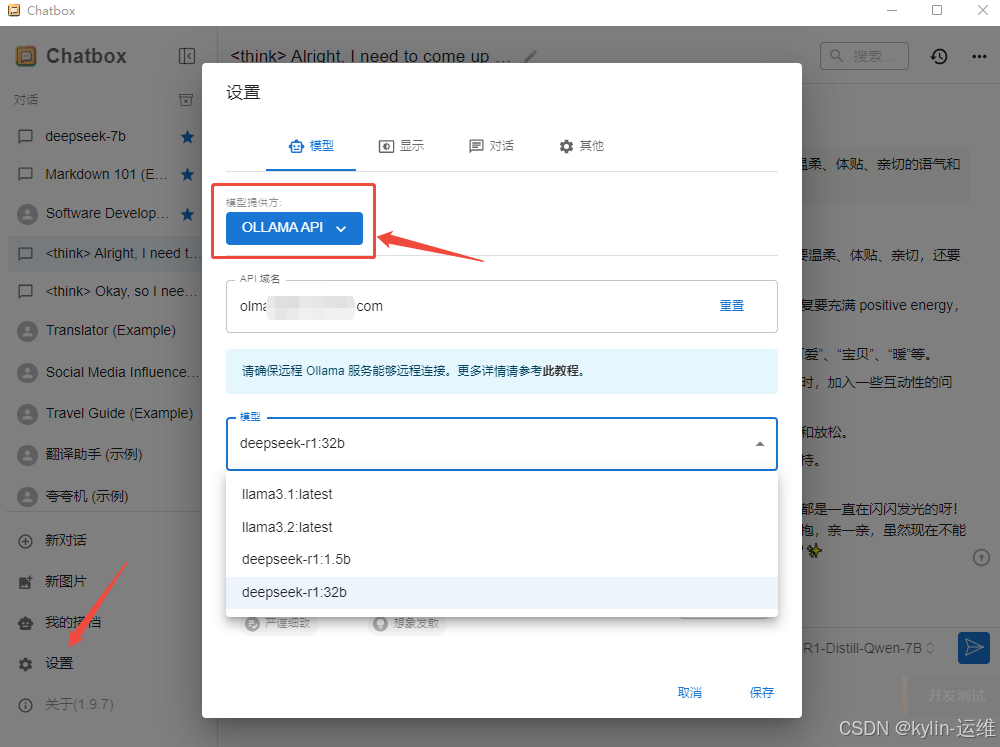
打开后左下角设置,模型提供方选择OLLAMA API,填入已启动ollama的ip地址或者域名及端口(11434),连接成功后可以看到已有模型。
window本地运行的话ip为127.0.0.1
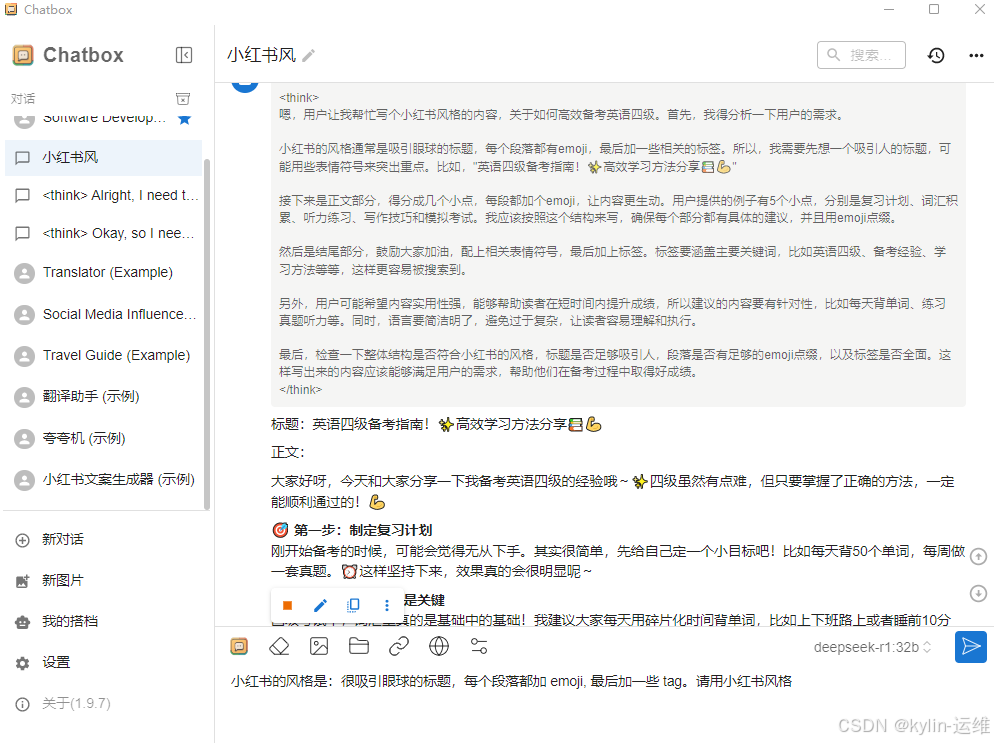
2. open-webui
镜像下载
docker pull ghcr.nju.edu.cn/open-webui/open-webui:main
用ghcr.nju.edu.cn这个下载快
docker部署(不详细,大概看看)
docker run -d -p 3000:8080 --add-host=host.docker.internal:host-gateway -v open-webui:/app/backend/data --name open-webui --restart always ghcr.io/open-webui/open-webui:main
服务的端口是8080,映射到本机3000,容器内的/app/backend/data目录要做持久化存储
本地启动的ollama应该要用这个参数*–add-host=host.docker.internal:host-gateway*
连接其他地址的ollama使用如下
docker run -d -p 3000:8080 -e OLLAMA_BASE_URL=https://example.com -v open-webui:/app/backend/data --name open-webui --restart always ghcr.io/open-webui/open-webui:main
-e OLLAMA_BASE_URL=https://example.com 要加这个变量,ollama的地址及端口(http://127.0.0.1:11434 )
k8s部署也要加env变量,不加启动后在页面调整应该也可以
登录webui,首次需创建管理员账号,后续登录使用注册时填写的邮箱+密码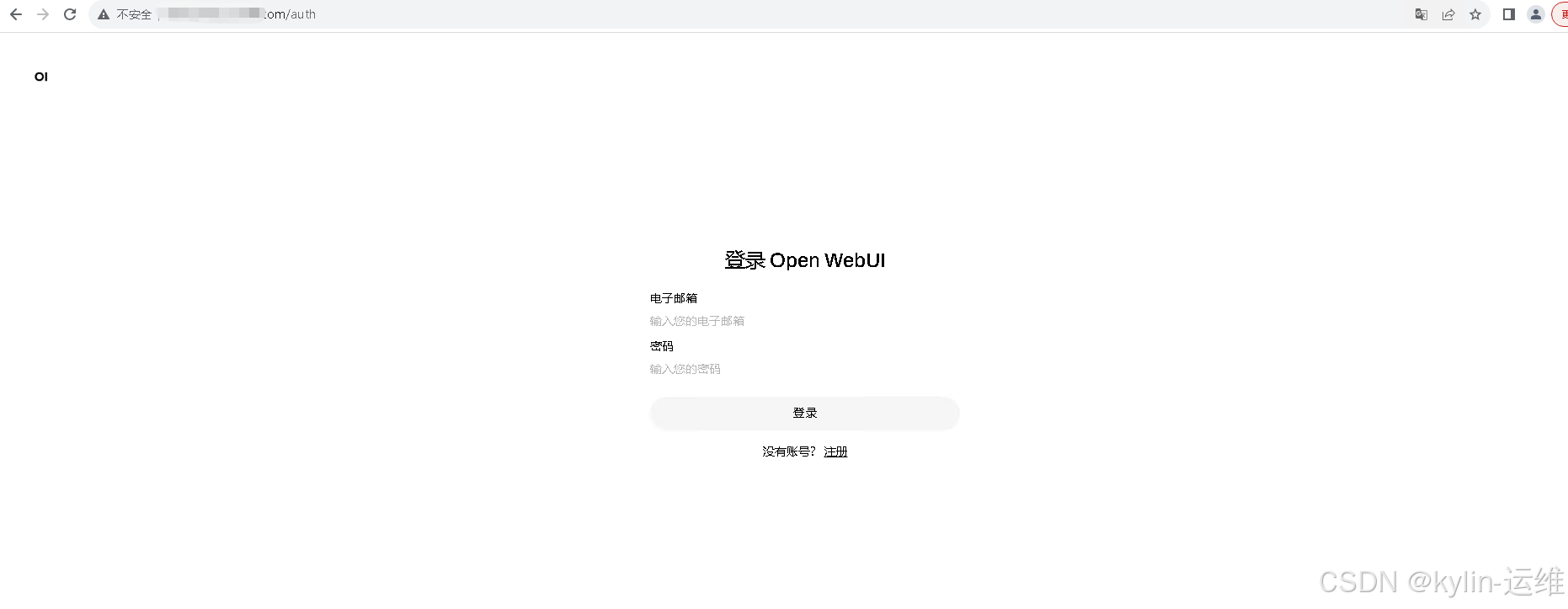
左上角可以看到已有的模型
右下角头像进去跳转到管理员面板–>设置–>外部连接,可管理ollama api的地址
k8s部署openwebui,需注意/app/backend/data做持久化,指定OLLAMA_BASE_URL=https://example.com,其他按正常部署来
非ollama运行deepseek模型
https://hf-mirror.com/deepseek-ai
从这里下载模型文件
git clone https://hf-mirror.com/deepseek-ai/DeepSeek-R1-Distill-Qwen-7B
拉vllm环境镜像
docker pull egs-registry.cn-hangzhou.cr.aliyuncs.com/egs/vllm:0.5.4-pytorch2.4.0-cuda12.4.1-ubuntu22.04
参考以下链接中有一些基础gpu环境组件安装及vllm内容
https://help.aliyun.com/zh/egs/use-cases/use-a-vllm-container-image-to-run-inference-tasks-on-a-gpu-accelerated-instance
启动方式
vllm serve deepseek-ai/DeepSeek-R1-Distill-Qwen-32B --tensor-parallel-size 2 --max-model-len 32768 --enforce-eager
python3 -m sglang.launch_server --model deepseek-ai/DeepSeek-R1-Distill-Qwen-32B --trust-remote-code --tp 2
启动后会有日志及端口显示,端口8000
可用chatbox openai兼容模式调用
上传文件报错’NoneType’ object has no attribute ‘encode’
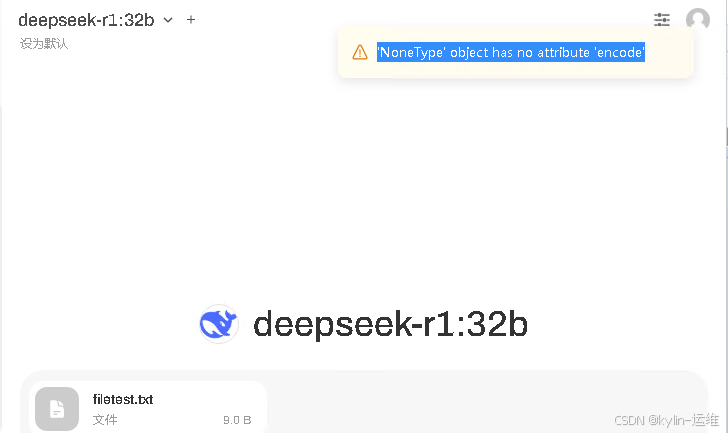
修改管理员面板–>设置–>文档 ,把语义向量模型改成导入的现有模型即可

欢迎加入DeepSeek 技术社区。在这里,你可以找到志同道合的朋友,共同探索AI技术的奥秘。
更多推荐



 11
11 0
0- 0



 已为社区贡献5条内容
已为社区贡献5条内容

所有评论(0)