DeepSeek-V4技术报告解读,全适配国产算力
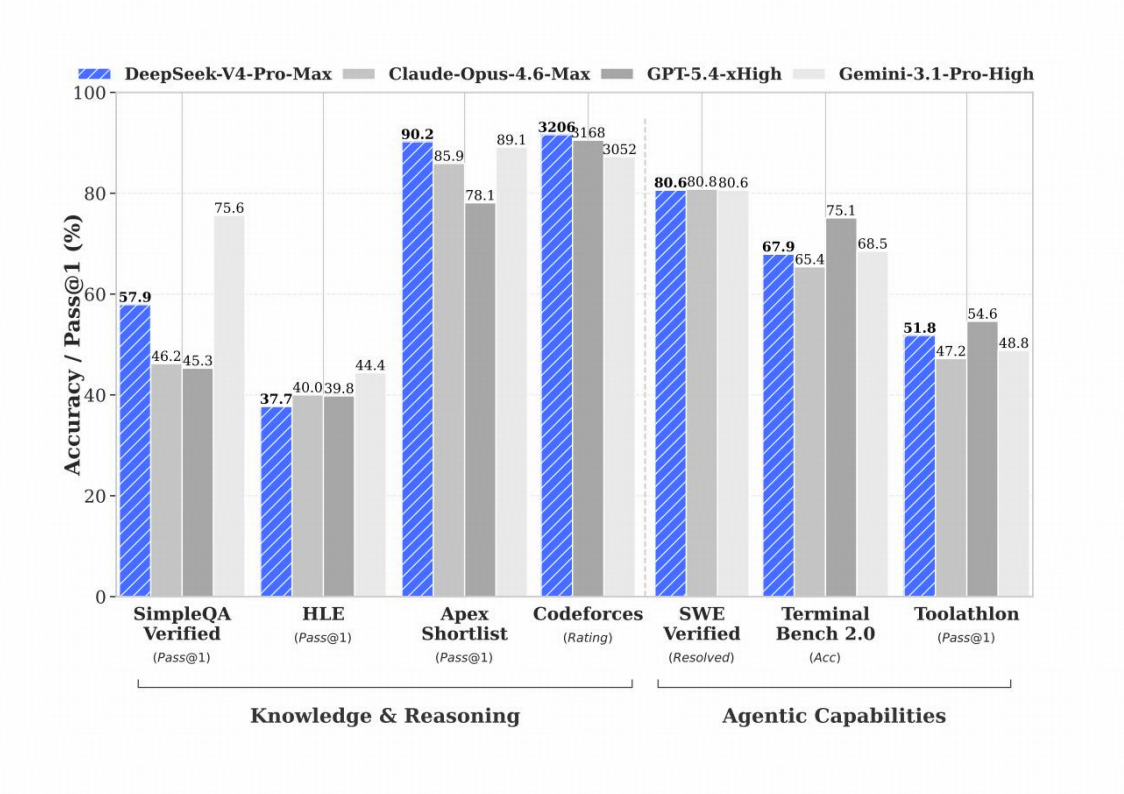
训练流程大体沿用 DeepSeek-V3.2的方案,但在关键方法上做了替换:混合强化学习(RL)阶段被完全替换为 On-Policy Distillation(OPD)。,支持1M上下文,同时在知识、推理、代码、Agent、中文写作上全面登顶开源 SOTA,逼近 GPT-5.4 / Gemini-3.1-Pro 闭源顶级水平。DeepSeek-V3.2-Base、DeepSeek-V4-Flash
一、模型概览
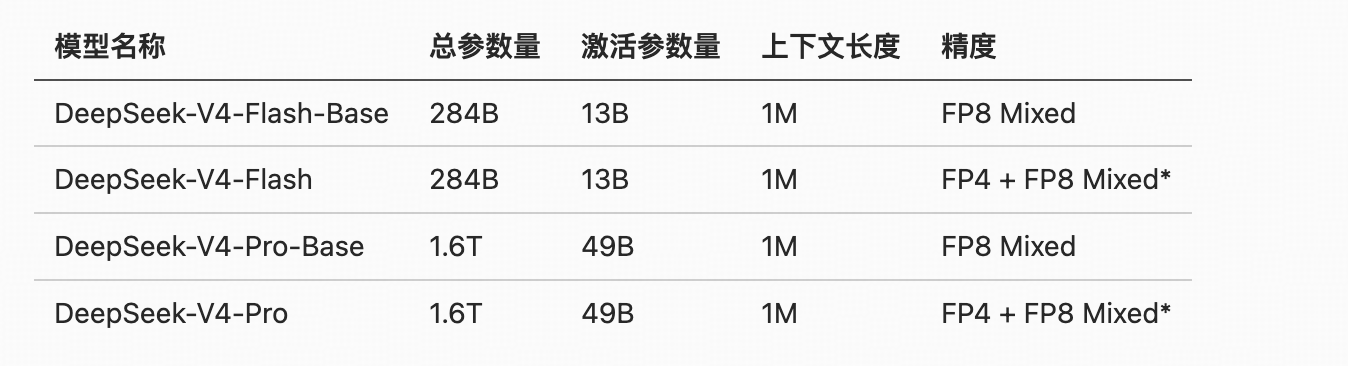
FP4 + FP8 Mixed:MoE 专家参数使用 FP4 精度,其余大部分参数使用 FP8。
同时在 DeepSeek 网页版和 App 中,“非思考”模式采用检索增强(RAG),而“思考”模式则使用智能体搜索。
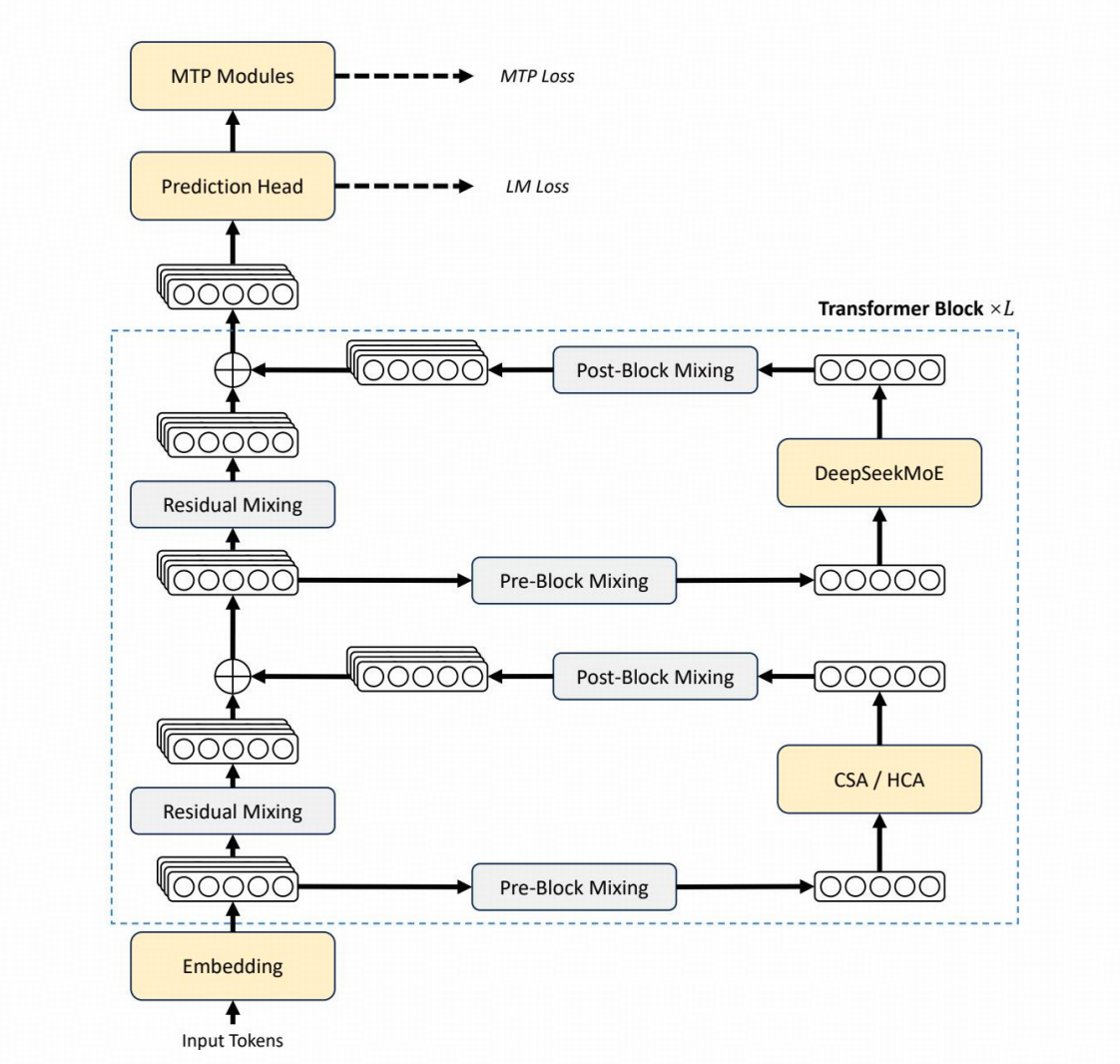
DeepSeek-V4 用 CSA+HCA 混合注意力 + mHC 流形超连接 + Muon 优化器 + 细粒度 MoE 并行,支持1M上下文,同时在知识、推理、代码、Agent、中文写作上全面登顶开源 SOTA,逼近 GPT-5.4 / Gemini-3.1-Pro 闭源顶级水平。
二.核心创新
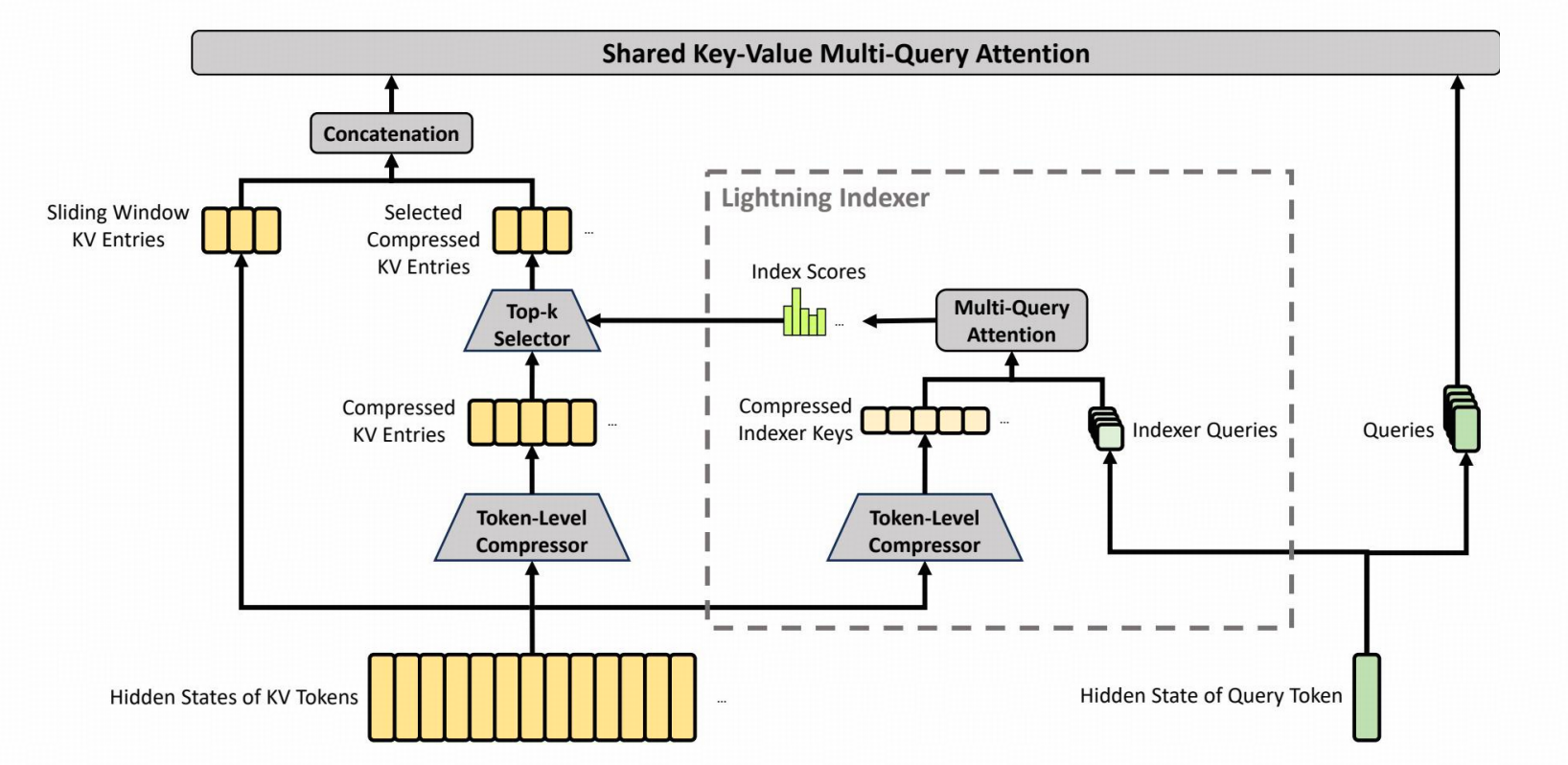
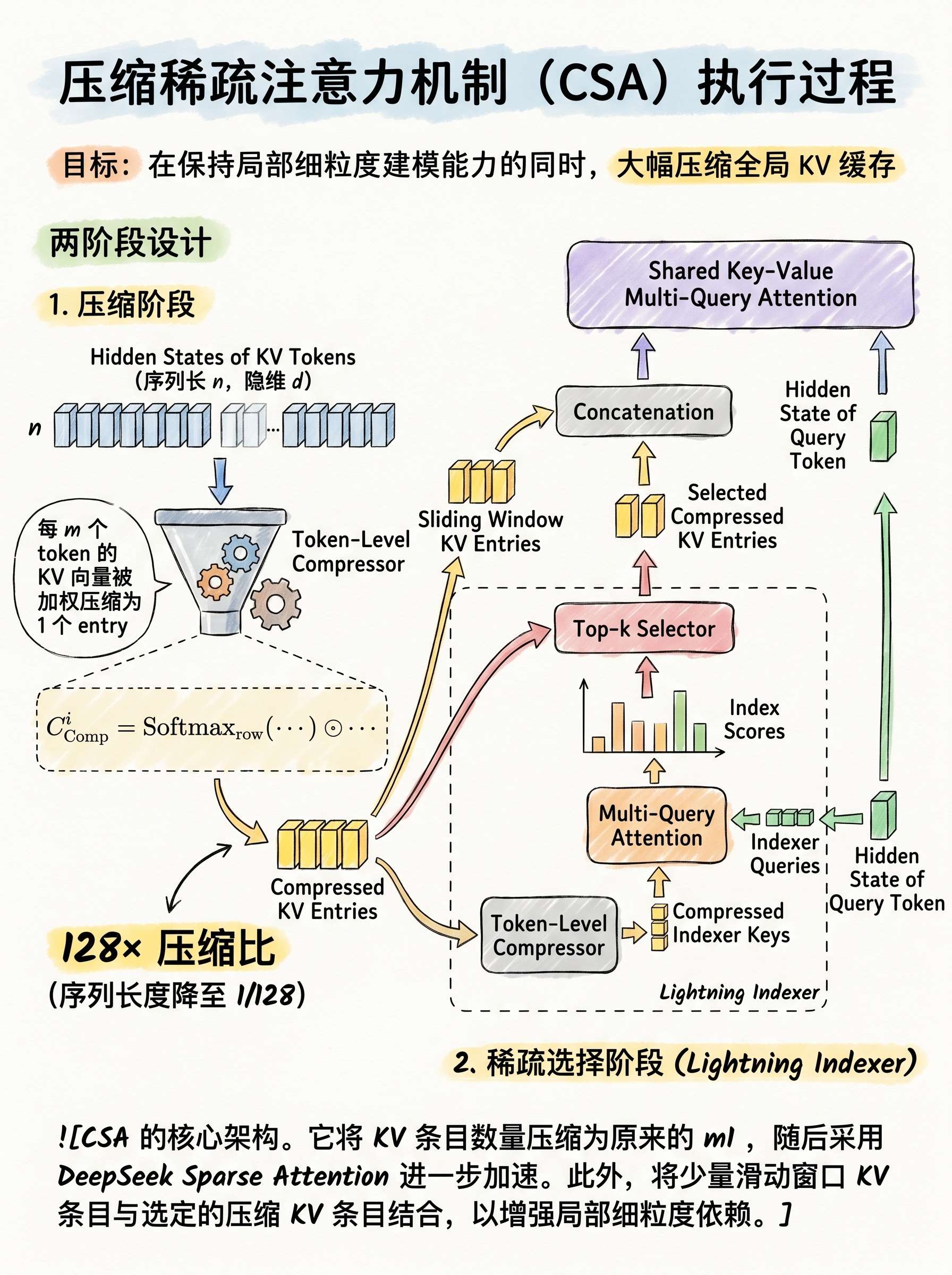
2.1 混合注意力架构:CSA(Compressed Sparse Attention) + HCA(Heavily Compressed Attention)
为突破传统注意力在百万级上下文下的计算与内存瓶颈,DeepSeek‑V4 提出双轨压缩注意力机制,实现计算量与 KV 缓存指数级压缩。
Compressed Sparse Attention (CSA)
目标:在保持局部细粒度建模能力的同时,大幅压缩全局 KV 缓存。
两阶段设计:
-
压缩阶段
每 m 个 token 的 KV 向量被加权压缩为 1 个 entry
输入:H∈Rn×dH \in \mathbb{R}^{n \times d}H∈Rn×d,序列长$ n$,隐维 ddd
压缩 KV:Ca,Cb∈Rn×cC_a, C_b \in \mathbb{R}^{n \times c}Ca,Cb∈Rn×c,权重 Za,Zb∈Rn×cZ_a, Z_b \in \mathbb{R}^{n \times c}Za,Zb∈Rn×c
压缩公式(含位置偏置 BBB):CCompi=Softmaxrow([Zam(i−1):mi−1+BaZbm(i−1):mi−1+Bb])⊤⊙[Cam(i−1):mi−1Cbm(i−1):mi−1]C_{\text{Comp}}^i = \text{Softmax}_{\text{row}}\left( \begin{bmatrix} Z_a^{m(i-1):mi-1} + B_a \\ Z_b^{m(i-1):mi-1} + B_b \end{bmatrix} \right)^\top \odot \begin{bmatrix} C_a^{m(i-1):mi-1} \\ C_b^{m(i-1):mi-1} \end{bmatrix}CCompi=Softmaxrow([Zam(i−1):mi−1+BaZbm(i−1):mi−1+Bb])⊤⊙[Cam(i−1):mi−1Cbm(i−1):mi−1]
实际压缩比:128×(序列长度降至 1/128) -
稀疏选择阶段(Lightning Indexer)
对压缩后 KV 进行 top‑k 稀疏检索
引入低秩 indexer query
输出 Index score 用于筛选关键信息
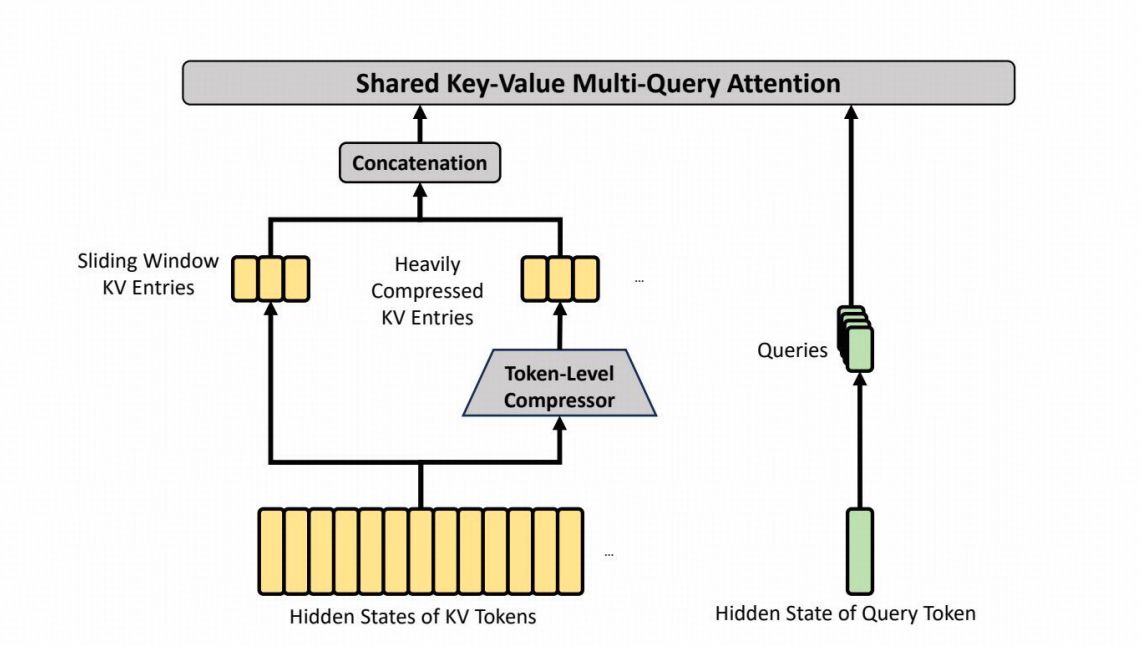
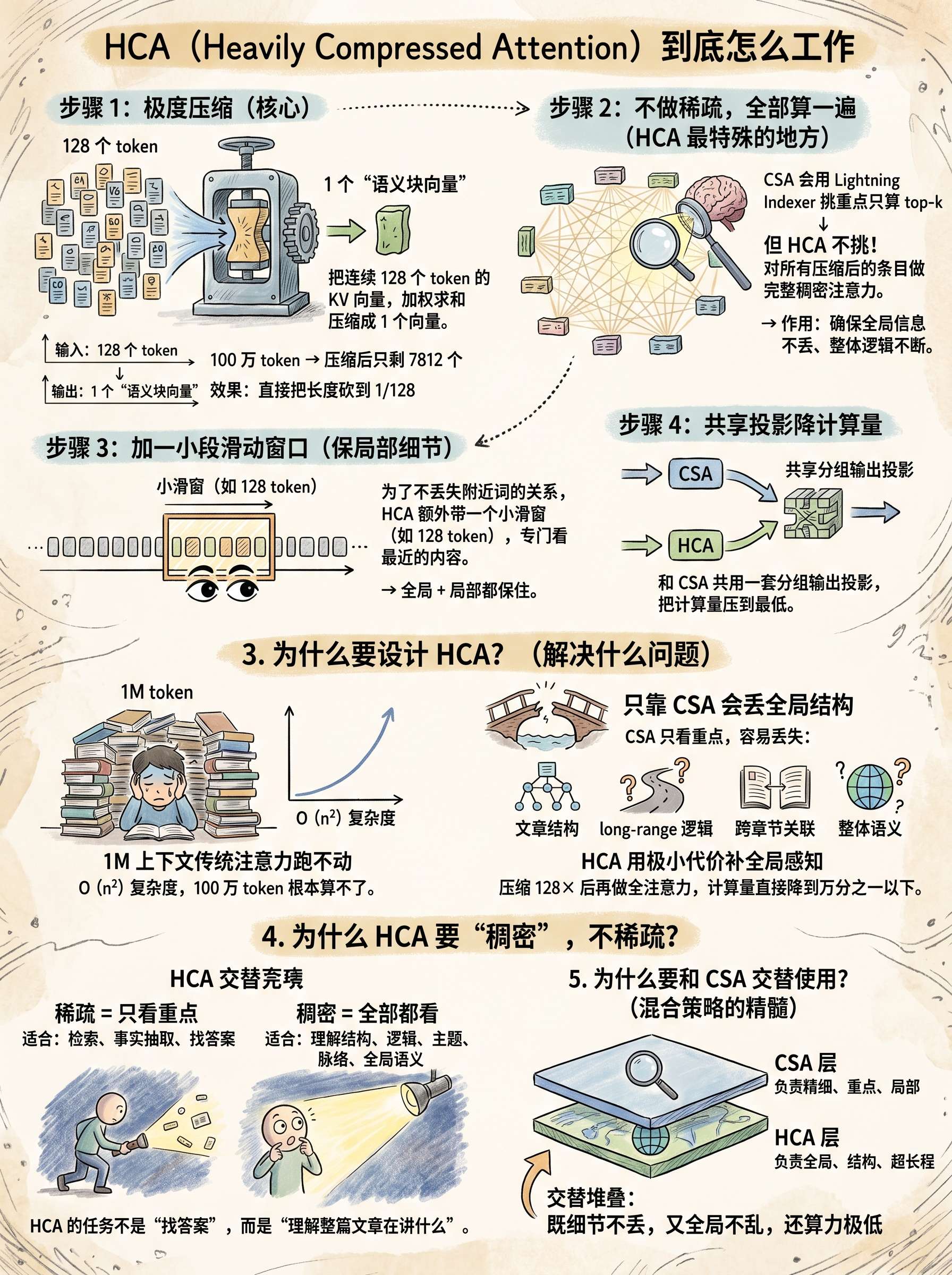
Heavily Compressed Attention (HCA)
目标:进一步压缩长程依赖建模开销,适用于更粗粒度语义聚合。
- 压缩粒度更大:1024×
-
把连续 128 个 token 的 KV 向量,加权求和压缩成 1 个向量。
-
输入:128 个 token 输出:1 个 “语义块向量”
- 与 CSA 共享 Sliding Window KV 分支,增强局部的细粒度依赖关系
效能对比
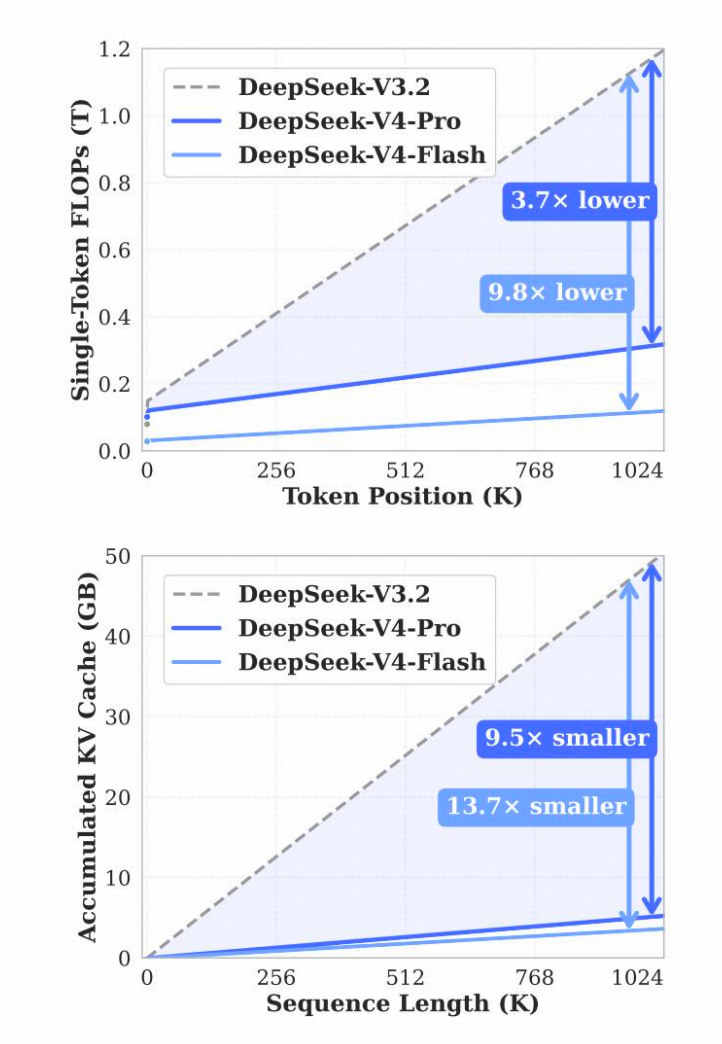
| 指标 | DeepSeek‑V4‑Pro vs V3.2 |
|---|---|
| 单 token 推理 FLOPs | 下降73%(仅需 27%) |
| KV Cache 占用 | 下降90%(仅需 10%) |
可以支持稳定、低成本的 1M‑token 推理服务,为长周期任务(文档分析、多轮 Agent 决策)提供基础设施保障。
2.2 Manifold‑Constrained Hyper‑Connections (mHC)
替代传统残差连接,引入流形约束的非线性映射,提升梯度流动与表征解耦能力。
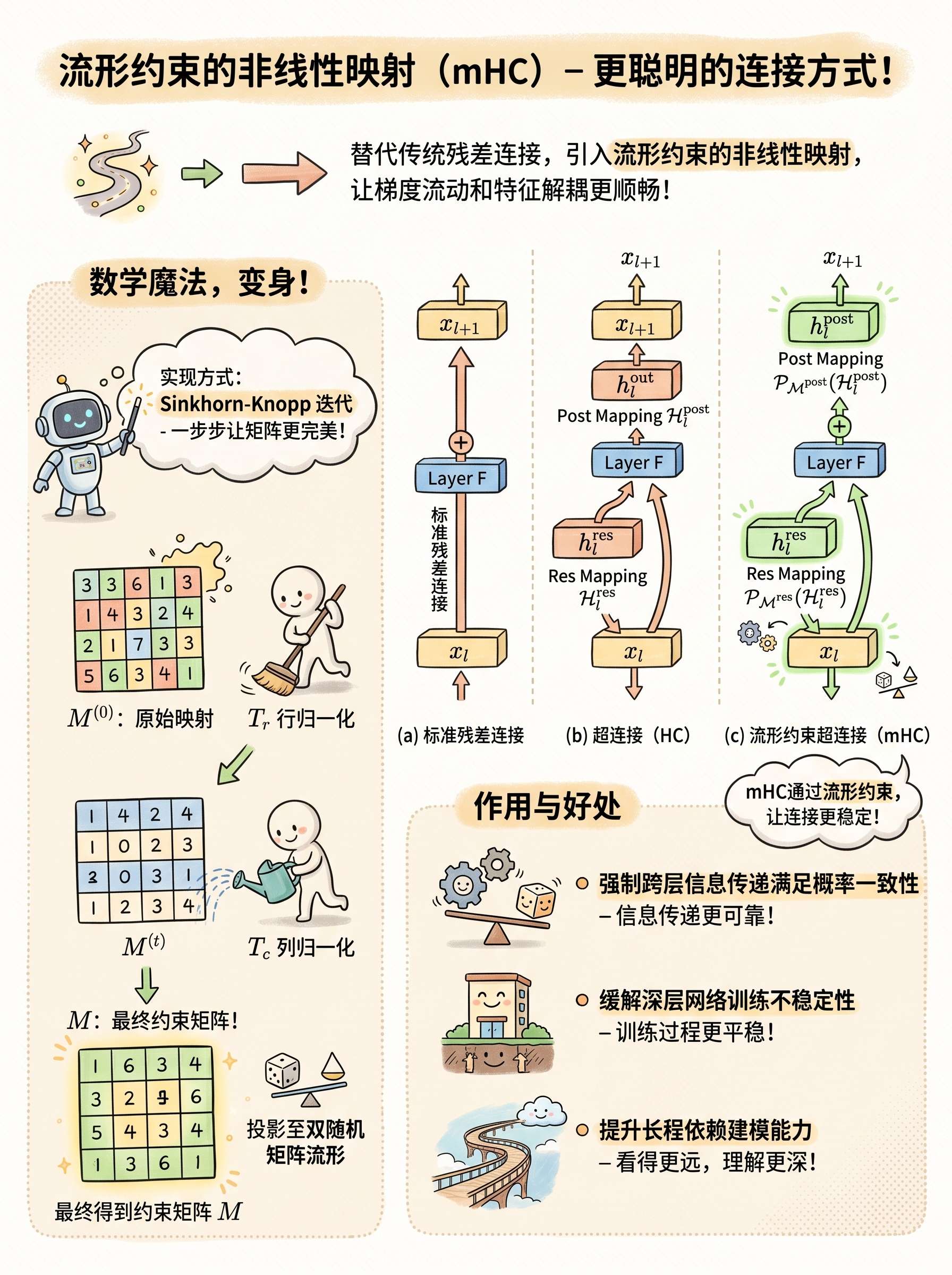
数学定义:将残差映射投影至双随机矩阵流形
实现方式:Sinkhorn‑Knopp 迭代
M(0)=exp(B~l),M(t+1)=Tc(Tr(M(t))) M^{(0)} = \exp(\tilde{B}_l), \quad M^{(t+1)} = T_c(T_r(M^{(t)})) M(0)=exp(B~l),M(t+1)=Tc(Tr(M(t)))
- TrT_rTr:行归一化算子
- TcT_cTc:列归一化算子
- 最终得到约束矩阵 MMM
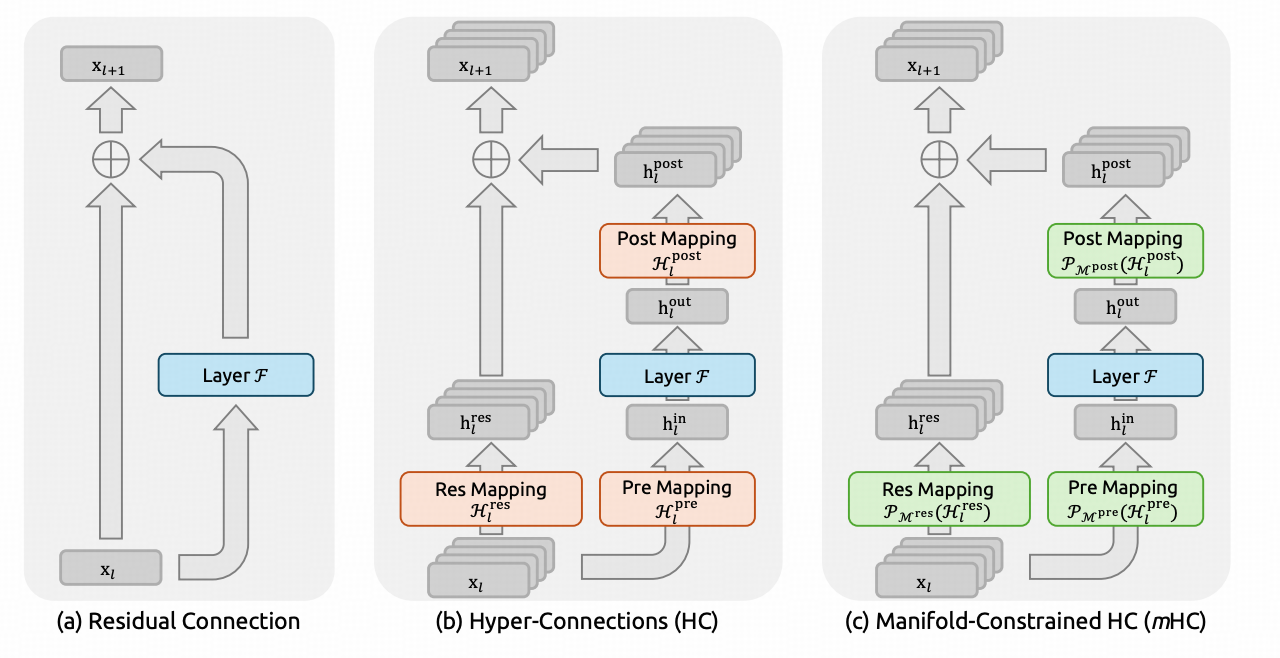
作用:
- 强制跨层信息传递满足概率一致性
- 缓解深层网络训练不稳定性
- 提升长程依赖建模能力
2.3 Muon 优化器
专为 MoE 模型大规模训练设计的自适应优化器,兼具快速收敛性与训练鲁棒性。
- 基于 AdamW 改进,动态调节各专家子网络学习率
- 在 32T 高质量 token 预训练中显著降低 loss 波动
- 与 mHC、混合注意力协同,构成 V4 训练稳定性三支柱
DeepSeek-V4 系列的注意力架构直接在注意力 query 和 KV 上执行RMSNorm,有效防止注意力 logits 爆炸。因此,在 Muon 优化器中未采用 QK-Clip 技术
2.4 细粒度专家并行(Fine‑grained EP)
背景知识
在MoE EP 需要复杂的节点间通信,并对互连带宽和延迟提出极高要求。解决 MoE 中 Expert Parallelism(EP)通信瓶颈,提出计算‑通信重叠流水线内核。
EP 的计算与通信过程
MoE EP 的基本过程,考虑最常见的DP+EP(且DP=EP)的情形:
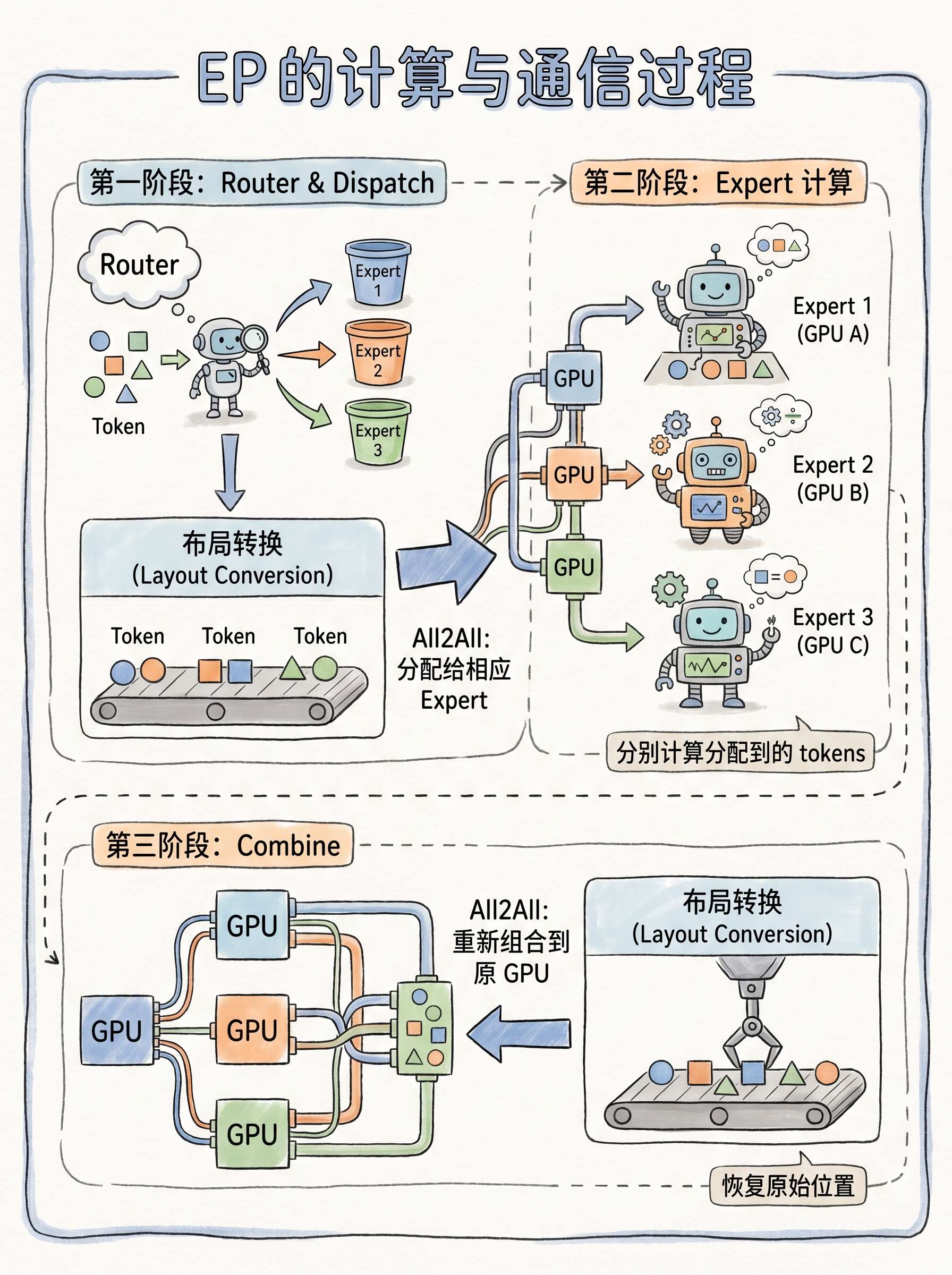
router 为每一个 token 决定其目标的 expert
- dispatch 阶段
- 布局转换:针对同一目标专家的标记被分组在连续的内存缓冲区中
- all2all: 将 token 分配给相应的 expert
- expert 分别计算分配到的 tokens
- combine 阶段
- all2all: 将处理过的 token 重新组合到它们的GPU上
- 布局转换:将 token 恢复到其原始位置
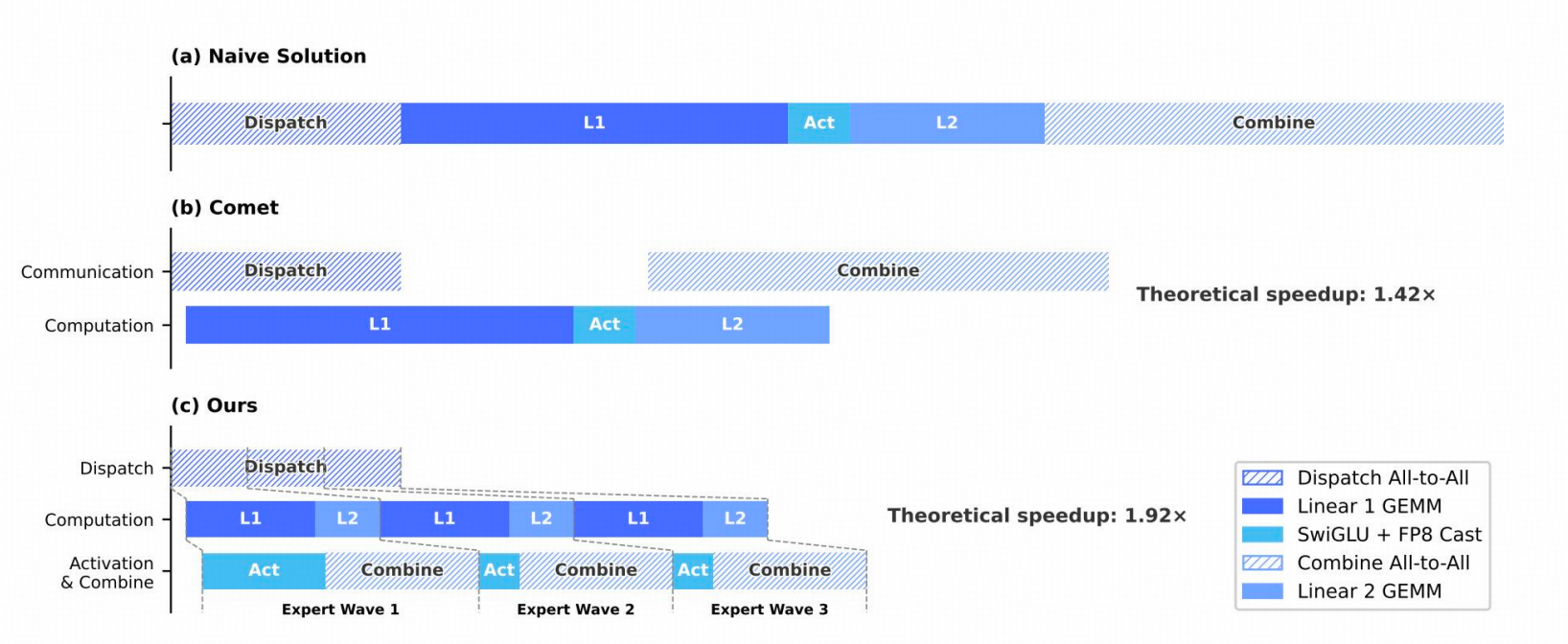
在 DeepSeek-V4 系列中,每个 MoE 层主要可分解为四个阶段:
- 两个受通信限制的阶段(Dispatch 和Combine)
- 两个受计算限制的阶段(Linear-1 和 Linear-2)。
在单个 MoE 层内,通信总时间少于计算总时间。
因此,将通信与计算融合为统一流水线后,计算仍是主要瓶颈,这意味着系统可以在不降低端到端性能的前提下容忍更低的互连带宽
细粒度 EP 方案
Wave‑based 专家调度:将专家分为多组 Wave,实现三级流水并发:
- 每个 wave 仅包含少量专家;一旦该 wave 内所有专家完成通信,计算可立即启动
- 完成当前 wave 的计算、下一wave 的 token 传输
- 已完成 Wave 结果回传
三、工程系统创新
3.1 面临的问题
混合注意力(CSA/HCA/SWA)导致 KV 缓存呈现四重异构性:
-
- 不同压缩比(128× vs 1024×)→ 不同逻辑长度
-
- SWA 有独立滑窗策略与缓存淘汰规则
-
- 压缩分支存在“未就绪尾部 token”缓冲区
-
- 高性能 kernel 要求内存对齐(cache line)
传统 PagedAttention 无法统一管理。
3.2 解决方案:异构 KV 缓存管理
| 组件 | 构成 | 管理策略 | 说明 |
|---|---|---|---|
| Classical KV Cache | CSA/HCA 压缩 KV | 多块/请求,每块覆盖 128 原始 token | 生成 1 个 CSA entry,1 个 HCA entry |
| State Cache | SWA KV + 未压缩尾部 token | 固定大小池化分配,每请求独占 | SWA 存最近 4096 token;CSA/HCA 存待压缩缓冲区 |
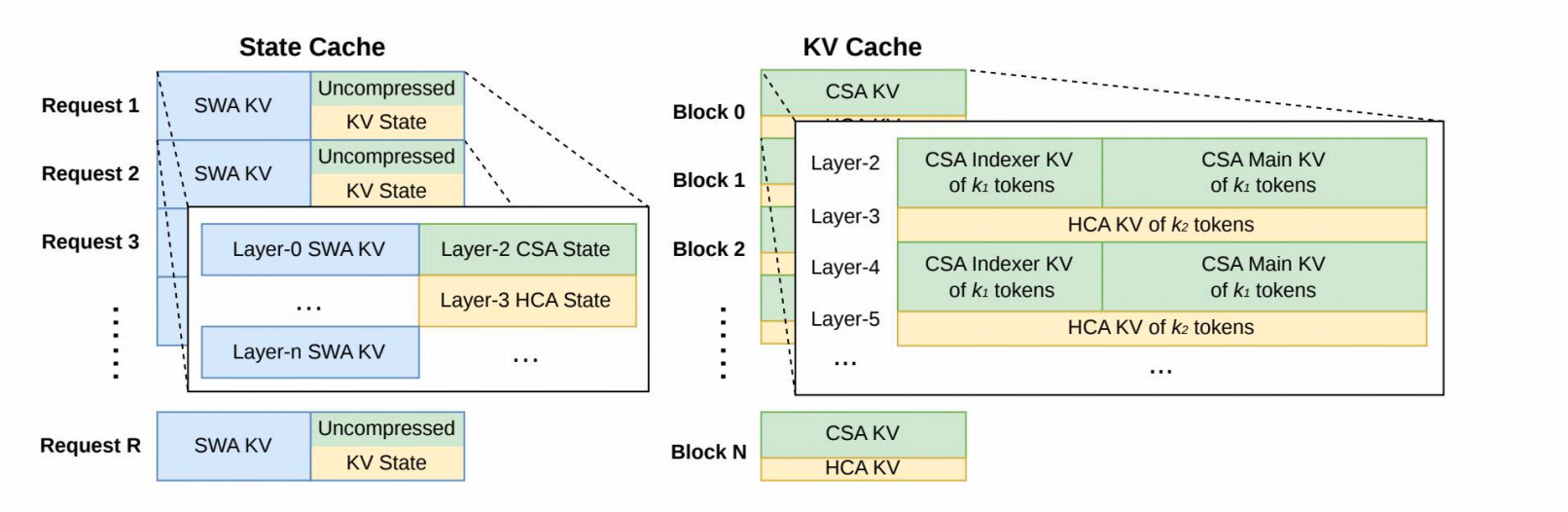
作用:
- 支持任意注意力组合下无碎片内存分配
- 为 1M‑context 推理提供确定性低延迟保障
四、预训练
-
数据:32T~33T 高质量 Token
-
在分词方面,在 DeepSeek-V3 词表的基础上引入少量特殊 token 以构建上下文,同时仍将词表大小保持在 128K。继承了 DeepSeek-V3 的 token-splitting
-
将训练序列长度长度:从 4K → 16K → 64K → 1M
-
MoE:共享专家 + 路由专家,无辅助损失均衡,所有 Transformer 块均使用 MoE 层,但前 3层 MoE 采用 Hash 路由策略。每层 MoE 包含 1 个共享专家和 256 个路由专家,每个专家的中间隐藏维度为 2048,其中每次激活 6 个路由专家
-
优化器:采用 Muon 优化器更新绝大多数参数,但 embedding 模块、预测头模块以及所有 RMSNorm 模块的权重仍使用AdamW 优化器,超参数保持一致
缓解训练不稳定性
- 预路由 Pre-routing:打破路由引发的恶性循环,以及直接抑制异常值,将主干网络与路由网络的同步更新解耦,可显著提升训练稳定性。
- SwiGLU 截断:可有效消除异常值并显著帮助稳定训练流程,且不会损害性能。将 SwiGLU的线性分量截断至 [−10, 10] 区间,同时将门控分量的上限设为 10
五、后训练
训练流程大体沿用 DeepSeek-V3.2的方案,但在关键方法上做了替换:混合强化学习(RL)阶段被完全替换为 On-Policy Distillation(OPD)。
多教师 On‑Policy Distillation(OPD)
目标:融合 10+ 领域专家(数学/代码/法律等)能力至单一模型
损失函数(反向 KL):
LOPD=∑i=1Nwi⋅DKL(πθ(y∣x)∥πEi(y∣x)) \mathcal{L}_{\text{OPD}} = \sum_{i=1}^N w_i \cdot D_{\text{KL}}\big(\pi_\theta(y|x) \parallel \pi_{E_i}(y|x)\big) LOPD=i=1∑Nwi⋅DKL(πθ(y∣x)∥πEi(y∣x))
-
πθ\pi_\thetaπθ 和 πEi\pi_{E_i}πEi:分别代表教师(Teacher)和学生(Student)模型。
-
DKLD_{KL}DKL (KL散度):用来衡量两个概率分布之间差异的数学工具。目标是最小化这个散度,迫使学生的输出分布无限逼近教师的输出分布。
在 OPD 中采用全词表 logits 蒸馏。在计算反向 KL 损失时保留完整的 logit 分布,可获得更稳定的梯度估计,避免 reward hacking并确保教师知识被蒸馏到。
领域专家训练
每个模型依次经历初始微调阶段,在领域特定prompt和奖励信号引导下进行强化学习(RL)优化。在 RL 阶段通过GRPO训练。
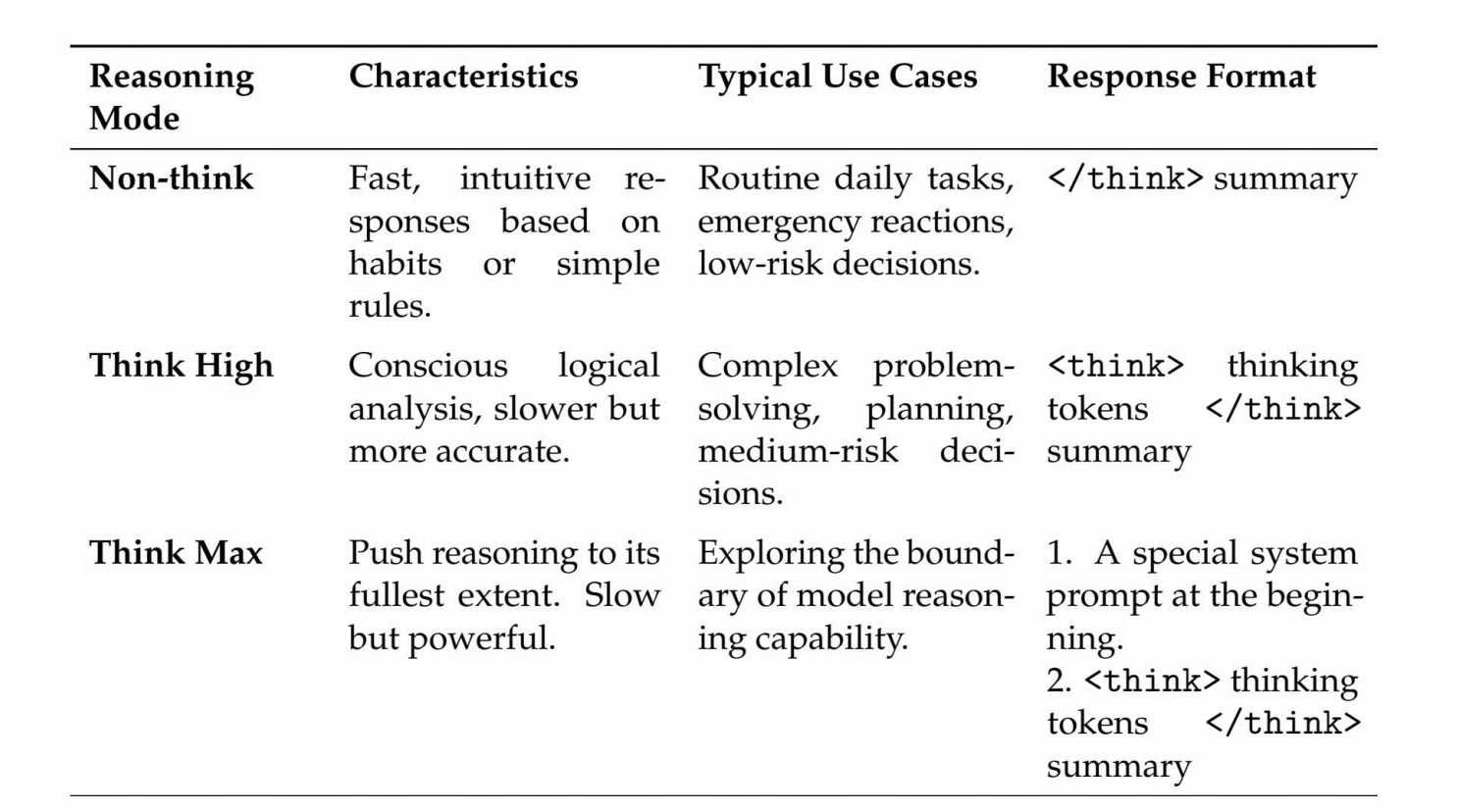
不同的推理强度
在强化学习训练阶段采用不同的长度惩罚和上下文窗口,从而生成不同长度的推理输出,用由token区分不同的回复格式

工具调用模式
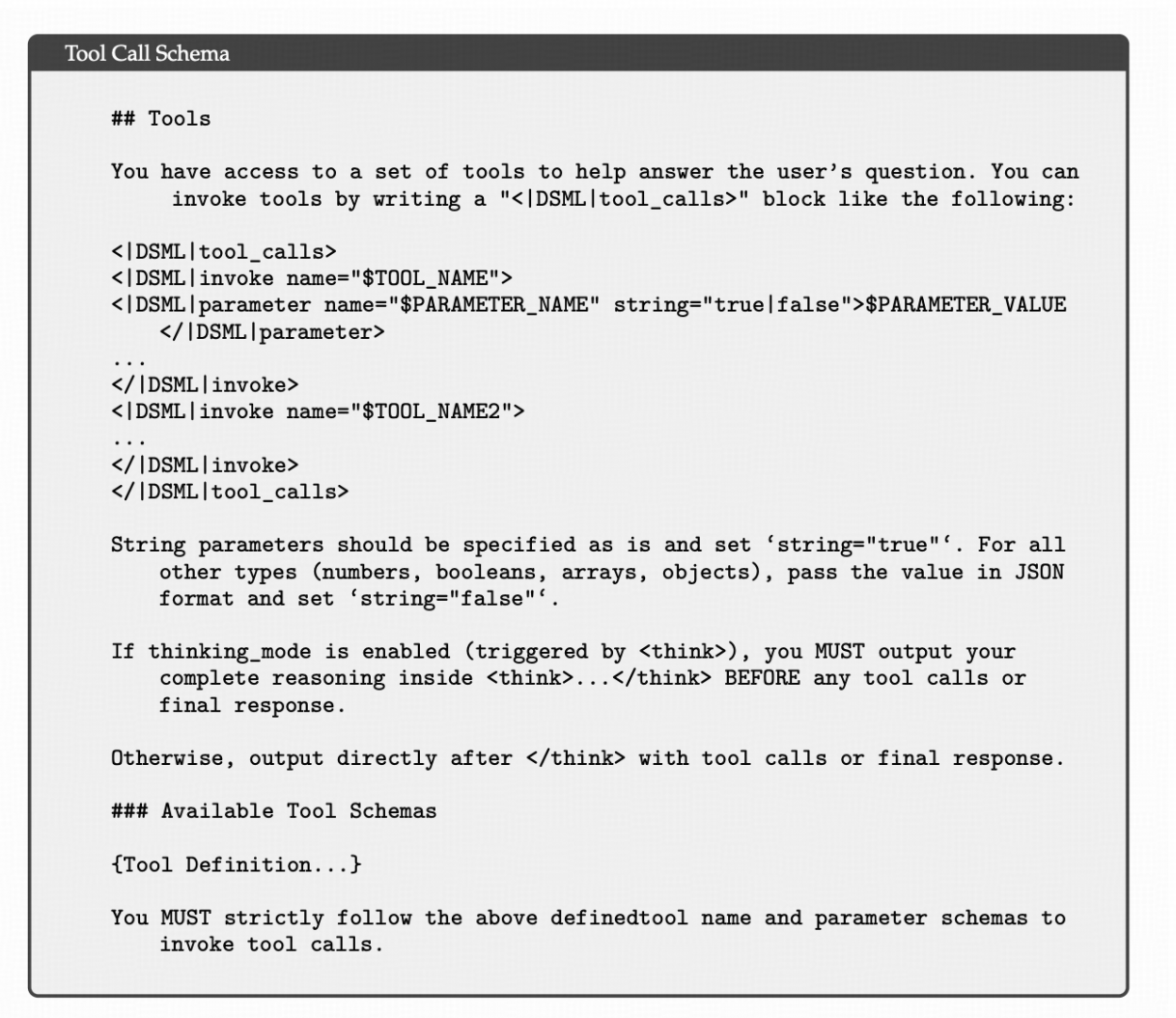
采用了一种新的工具调用模式,采用特殊标记” | DSML | ”,并以 XML 格式进行工具调用。
引入交错思考。DeepSeek-V3.2 引入了一种上下文管理策略:在工具-结果轮次之间保留推理痕迹,但在新用户消息到达时将其丢弃
DeepSeek-V4 系列的thinking管理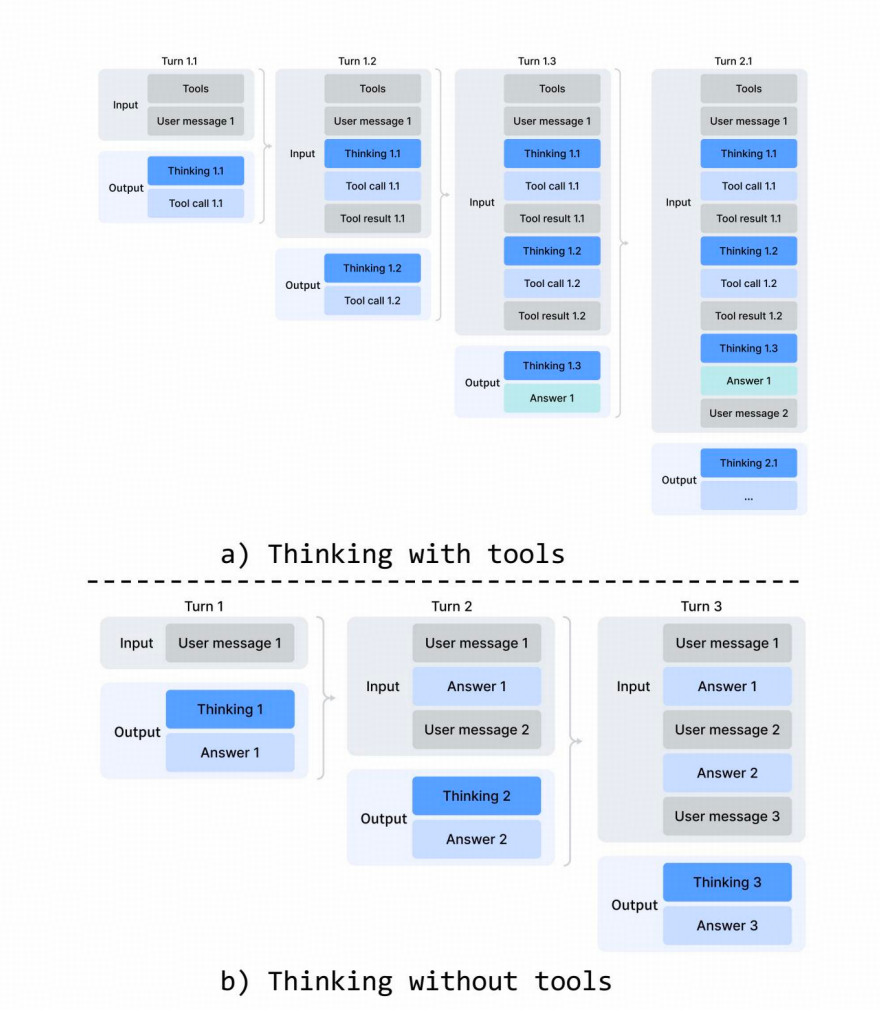
XML 格式有效缓解了转义失败问题,减少了工具调用错误,为模型与工具的交互提供了更稳健的接口。
生成式奖励模型(Generative Reward Model, GRM)
弃用scalar reward model,针对难验证任务,采用生成式奖励模型 GRM。让 actor 自身作为 reward judge
- 直接对 GRM 进行 RL 优化
- 推理能力与评判能力联合进化
- 数据效率高:少量标注即可泛化至复杂任务
实验结果
DeepSeek-V3.2-Base、DeepSeek-V4-Flash-Base 与 DeepSeek-V4-Pro-Base 的对比。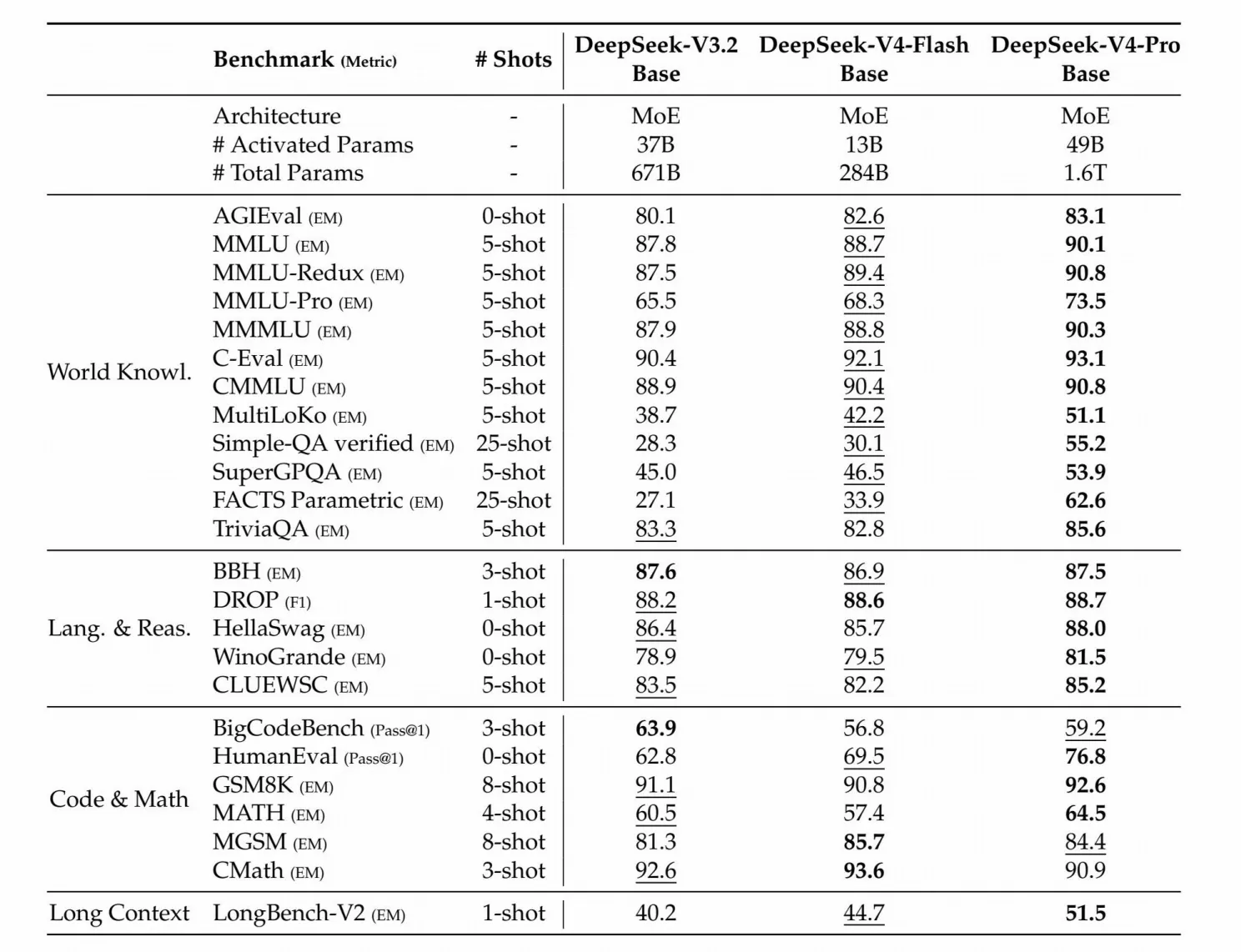
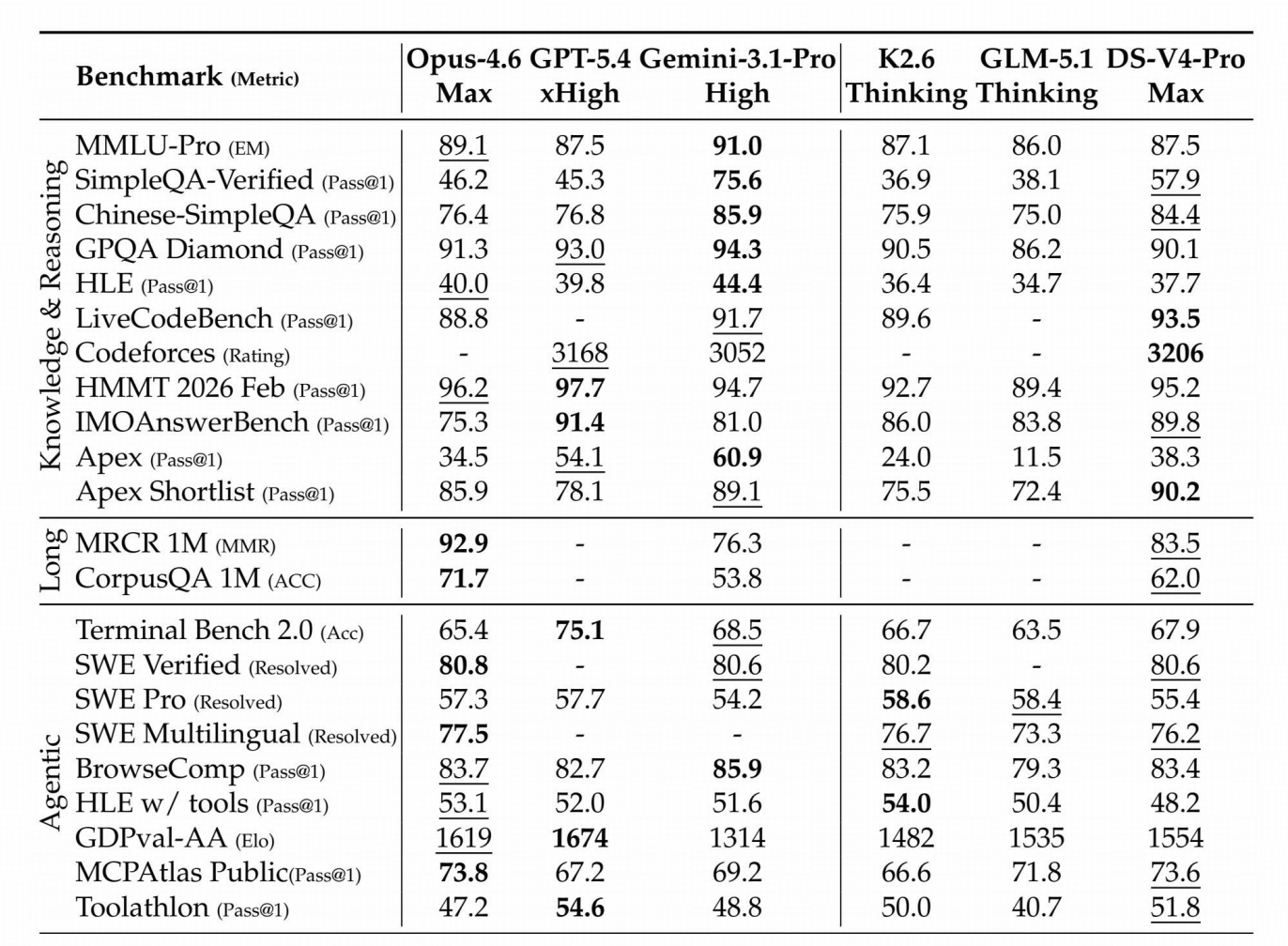
DeepSeek-V4-Pro-Max 与闭源/开源模型的对比。“Max”“xHigh”“High”表示推理强度。最佳结果以粗体标示,次佳结果
以下划线标示
DeepSeek-V4 系列不同规模与模式的对比。“Non-Think”“High”“Max”表示推理强度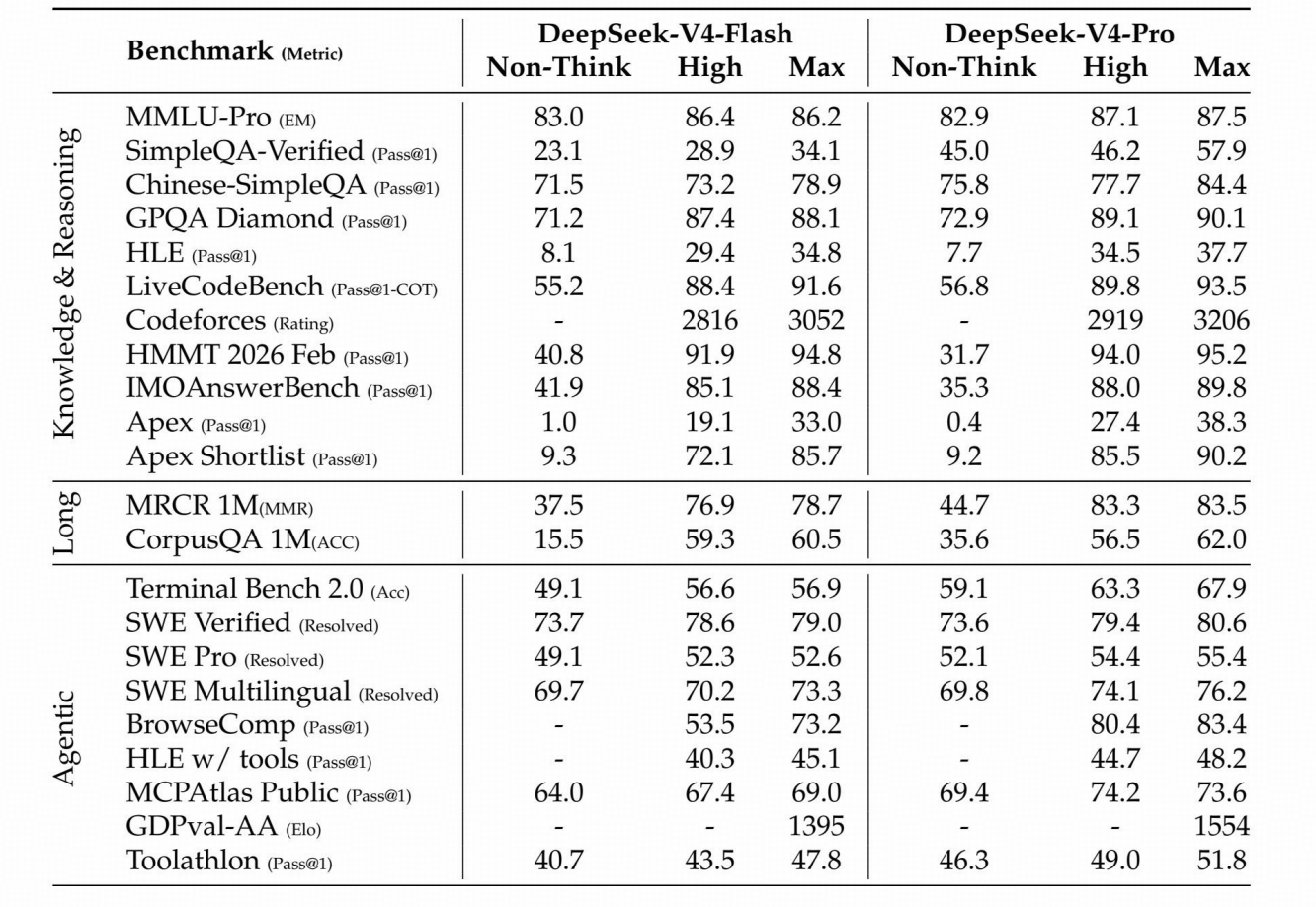
详细维度评分,包括任务完成度、内容质量、格式美观度和指令遵循度
一项任务示例输出,该任务要求为一家知名奶茶品牌与北京地铁共同起草一份营销提案
收集了来自 50 多位内部工程师的约 200 个具有挑战性的任务,涵盖功能开发、错误修复、重构和诊断,技术栈包括 PyTorch、CUDA、Rust 和 C++等。codin方面DeepSeek-V4-Pro 显著优于 Claude Sonnet 4.5,并接近 Claude Opus 4.5 的水平
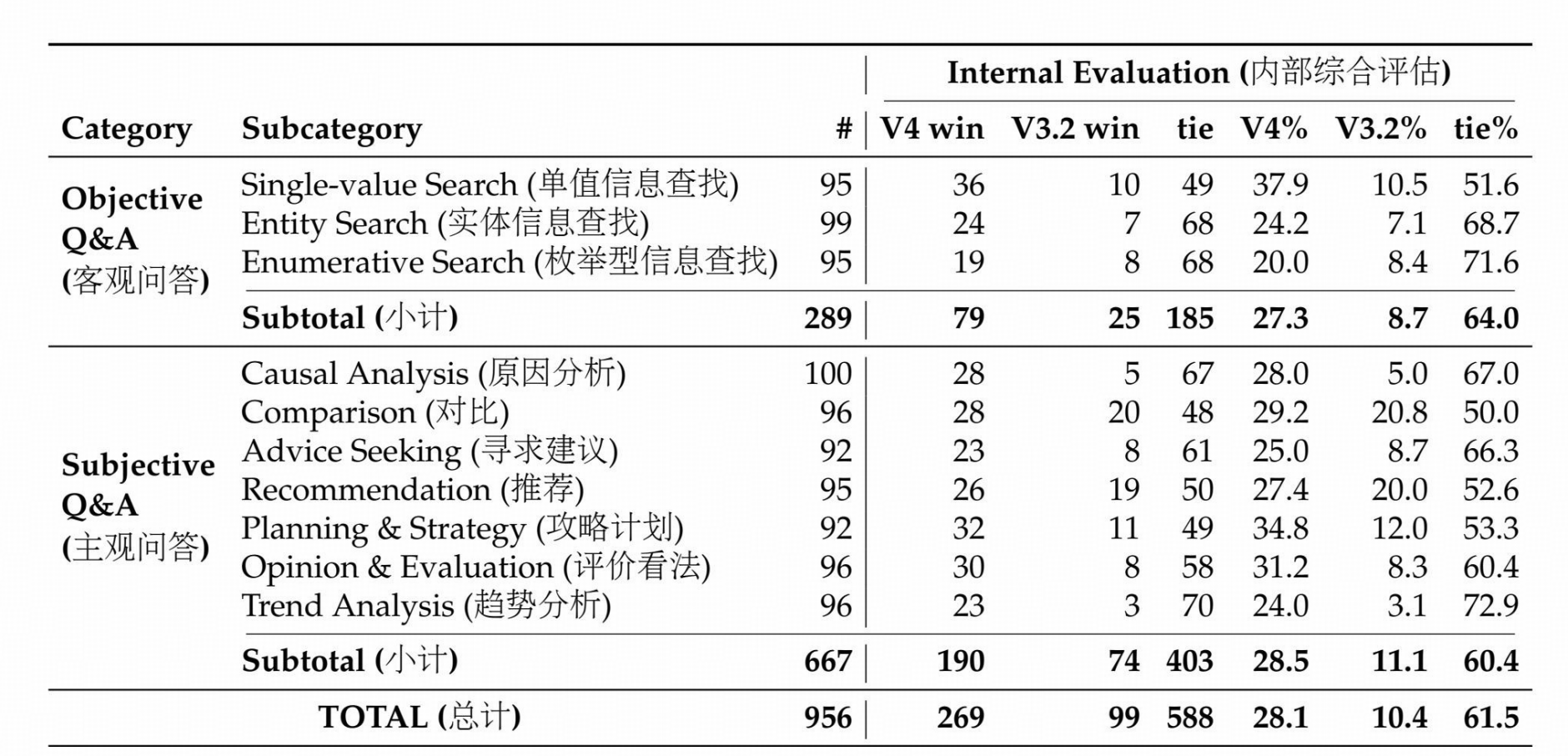
DeepSeek-V4-Pro 与 DeepSeek-V3.2 在搜索问答任务上的对比评估
DeepSeek-V4-Pro 与 Gemini-3.1-Pro 在中文创意写作中的对比分析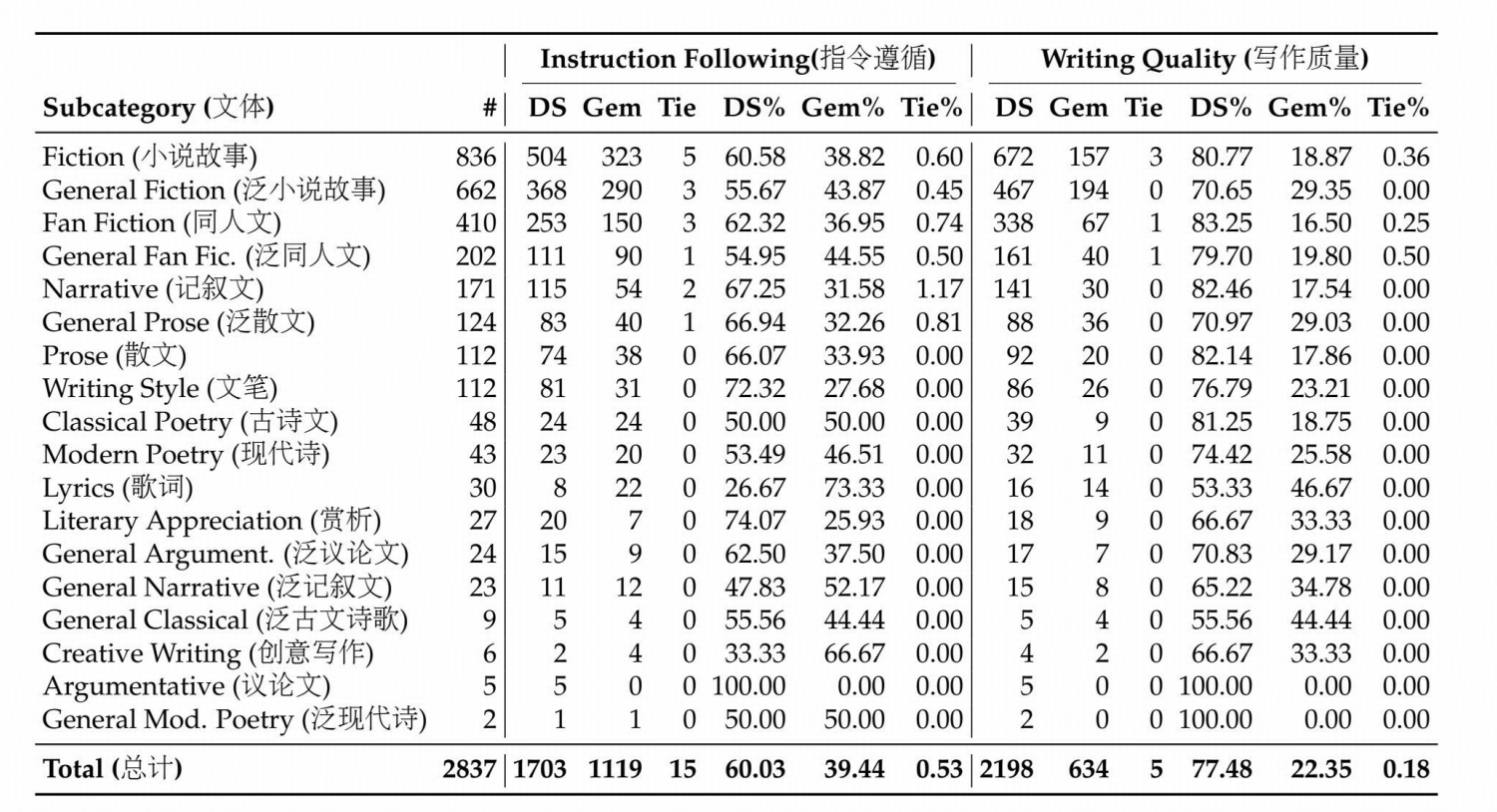
更多ai笔记同步更新在红薯

参考
https://huggingface.co/deepseek-ai/DeepSeek-V4-Pro/blob/main/DeepSeek_V4.pdf

欢迎加入DeepSeek 技术社区。在这里,你可以找到志同道合的朋友,共同探索AI技术的奥秘。
更多推荐



 9
9 0
0- 0



 已为社区贡献1条内容
已为社区贡献1条内容

所有评论(0)