DeepSeek-V4 发布:百万级上下文的成本被它打到地板上了
DeepSeek发布V4系列大模型,支持百万Token上下文,采用混合注意力机制显著降低推理成本。旗舰款V4-Pro参数1.6T,在代码能力上超越Claude和Gemini;轻量版V4-Flash主打性价比。创新性地结合压缩稀疏注意力和重度压缩注意力,使长文本处理效率提升70%以上。模型在编程任务表现突出,但在通用知识方面仍有提升空间。支持三种推理模式,并采用混合精度压缩方案降低部署门槛。这一突破
看了刚刚发布的 DeepSeek-V4 的技术报告,我盯着那组数据看了好几遍。
不是我矫情,是真的被一组数字震到了,在百万 Token 上下文的场景下,DeepSeek-V4-Pro 的推理计算量只有上一代 V3.2 的 27%,KV 缓存只占 10%。27% 和 10%。。。
你知道这意味着什么吗?上下文长度从 128K 直接拉到 1M,推理成本反而降了七成以上。这个数字如果经得起考验,整个长上下文部署的经济学都要重写。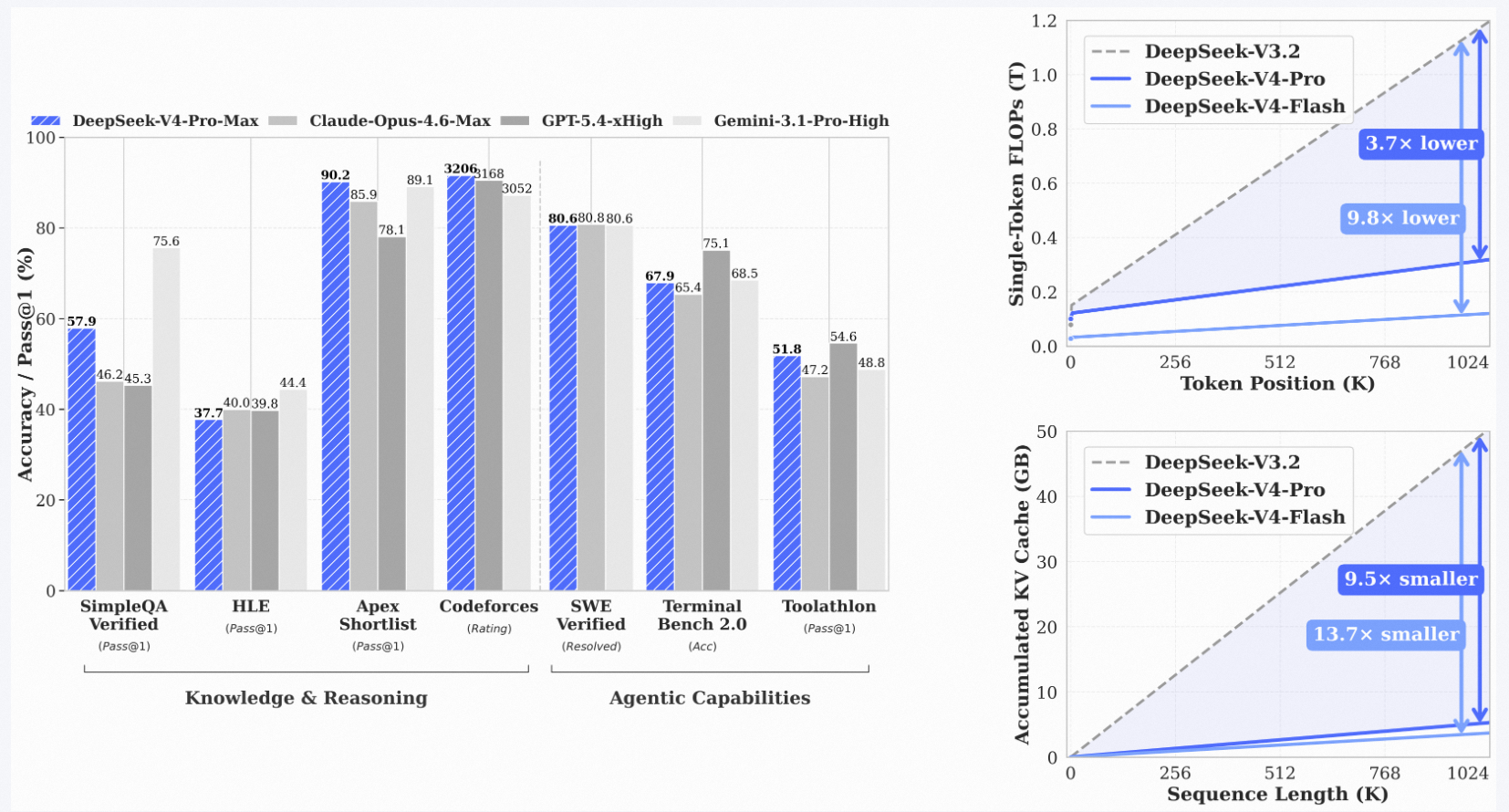
先说发了什么
这次 DeepSeek-V4 系列一口气发了两个模型,都是 MoE 架构,都支持百万 Token 上下文。
DeepSeek-V4-Pro,总参数量 1.6T,激活参数 49B。这是旗舰款,对标的是 Claude Opus 4.6、GPT-5.4、Gemini-3.1-Pro 这批闭源天花板。
DeepSeek-V4-Flash,总参数量 284B,激活参数 13B。轻量版,主打性价比,给那些算力有限但又想用上 DeepSeek 最新能力的团队准备的。
两个模型都在 32T 以上的 token 上做了预训练,MIT 协议完全开源,权重已经放到了 HuggingFace 和 ModelScope 上。
说实话,1.6T 参数的模型,MIT 协议直接放出来,这个格局还是得认的。
混合注意力架构:这次最值得聊的东西
DeepSeek-V4 这次的架构改动里,我个人觉得最值得深挖的不是参数规模,而是他们搞出来的混合注意力机制。
传统的注意力机制在处理长上下文时有一个致命问题,KV 缓存的显存占用会随序列长度线性增长。百万 Token?那显存基本就炸了。之前各家都在想办法解决这个问题,稀疏注意力、滑动窗口、分块缓存,各显神通。
DeepSeek 的方案是搞了两层注意力机制,叠在一起用。
第一层叫 CSA(Compressed Sparse Attention,压缩稀疏注意力),处理常规范围的上下文,保持精度。第二层叫 HCA(Heavily Compressed Attention,重度压缩注意力),专门处理超远距离的上下文信息,通过更激进的压缩来换取效率。
两层叠加之后的效果就是,你需要精度的地方有精度,需要效率的地方有效率。最终在百万 Token 场景下,推理 FLOPs 只需要 V3.2 的 27%,KV 缓存只占 10%。
我之前一直在关注长上下文模型的部署成本问题。Gemini 的百万 Token 确实强,但那是要花钱的,而且不便宜。如果 DeepSeek 这套架构在工程上真的跑通了,那对需要处理超长文档、大代码库的场景来说,部署成本直接从「用不起」变成「可以考虑」了。
几个不那么显眼但很重要的改进
除了混合注意力,V4 还有几个技术细节值得提一下。
流形约束超连接(mHC)。传统 Transformer 的残差连接用了这么多年,一直没什么大的改动。DeepSeek 在残差连接的基础上引入了流形约束,让跨层信号传播更稳定。这个改动看着不起眼,但对一个 1.6T 参数的模型来说,训练稳定性就是命根子。训练一旦崩了,那都是几百万美元级别的损失。
Muon 优化器。DeepSeek 把训练优化器换成了 Muon,收敛更快,训练更稳。说实话,大型 MoE 模型的优化器选择一直是个很玄学的事,DeepSeek 敢在这个量级上换优化器,说明他们在基础设施上确实有底气。
后训练的「先分后合」范式。这个思路我觉得挺巧妙的。不是简单地把所有领域的数据混在一起训练,而是先用 SFT + GRPO 强化学习独立培养各领域的专家能力,然后再用在线策略蒸馏(on-policy distillation)把这些专家能力统一整合成一个通用模型。
先专后通。有点像一个公司先让各部门各自修炼内功,再做内部知识共享,最后形成组织能力。比一上来就搞大杂烩的训练方式要高效得多。
跑分:代码能力真的炸了,但也不是没短板
直接看跟闭源旗舰的对比数据。
代码能力是 DeepSeek-V4 最强的杀手锏。
LiveCodeBench 上 V4-Pro-Max 跑到了 93.5%,全场第一。作为对比,Claude Opus 4.6 是 88.8%,Gemini-3.1-Pro 是 91.7%。Codeforces 评分 3206,超过 GPT-5.4 的 3168,也是第一。Apex Shortlist 90.2%,同样第一。
在 SWE Verified(实际软件工程能力测试)上,V4-Pro-Max 跟 Opus 4.6 打了个平手,都是 80.6% 左右。
如果你是做编程助手、代码 Agent、或者 SWE 相关产品的,这组数据应该能让你兴奋起来。一个开源模型在代码能力上全面碾压一众闭源旗舰,这个事情放在一年前是不可想象的。
但得客观说,不是所有维度都领先。
通用知识方面,MMLU-Pro 上 V4-Pro-Max 是 87.5%,Gemini-3.1-Pro 是 91.0%,差距还是很明显的。SimpleQA 事实准确性测试,Gemini 是 75.6%,DeepSeek 是 57.9%,差了一大截。数学推理的最前沿指标 HLE,Gemini 44.4%,DeepSeek 37.7%。
长上下文方面,MRCR 1M 测试 Opus 4.6 以 92.9% 遥遥领先,DeepSeek 是 83.5%,虽然也不差,但跟 Claude 比还有距离。
所以结论很清晰,DeepSeek-V4 是一个偏科生,代码和 Agent 能力极强,通用知识和极限推理还有追赶空间。
三档推理模式
V4 支持三种推理模式,Non-think、Think High、Think Max。
Non-think 就是快速直觉式回答,不经过深度推理,适合日常简单任务。Think High 会展开逻辑分析,适合复杂问题。Think Max 则是把推理能力拉满,专门用来挑战极限。
从跑分数据看,Non-think 到 Think Max 之间的提升幅度非常大。比如 LiveCodeBench,Non-think 只有 56.8%,Think High 跳到 89.8%,Think Max 再拉到 93.5%。HLE 测试更夸张,Non-think 只有 7.7%,Think Max 能到 37.7%,翻了将近五倍。
这个设计思路跟 Claude 的延伸思考、o3 的推理等级类似,把推理深度变成了一个可调节的旋钮。不同的是 DeepSeek 把三档的区分度做得更大,用户可以根据实际场景灵活选择。
不过有个细节需要注意,官方建议 Think Max 模式下上下文窗口至少设 384K tokens,这说明深度推理确实需要更长的上下文空间来展开思考链。
模型规格和部署
量化方案这次也比较务实,MoE 专家参数用 FP4 精度,其余大部分参数用 FP8,混合精度压缩。这种策略的好处是在精度损失可控的前提下,尽可能压缩模型体积。
对于想本地部署的团队,Flash 版本(284B/13B)应该是最现实的选择。13B 的激活参数,意味着实际推理时的计算量并不大,配合 FP8 量化,单张高端 GPU 可能就有机会跑起来。Pro 版本(1.6T/49B)就是另一回事了,49B 激活参数,部署门槛依然很高,大概率需要多卡方案。
采样参数官方建议 temperature 1.0、top_p 1.0,比较激进的设置。另外这次没有提供标准的 Jinja 聊天模板,而是给了个 Python 编码脚本自己处理,对部署工具链来说要多做一步适配。
我怎么看
我觉得 DeepSeek-V4 最大的贡献不是「参数更大」或者「跑分更高」,而是证明了百万级上下文可以做得又便宜又快。
CSA + HCA 的混合注意力架构,把长上下文的推理成本压到了之前的零头。如果这个效率优势能在实际部署中复现,那对整个行业的影响是深远的。之前大家聊百万 Token 上下文,更像是在聊一个技术展示,成本高到没几个团队能真正用上。DeepSeek 把这个门槛往下拉了一大截。
代码能力全面碾压闭源旗舰这事,也值得单独说一说。一个 MIT 协议开源的模型,在编程能力上干翻 Claude Opus 和 Gemini,这对做代码 Agent、IDE 插件、自动化编程工具的团队来说,简直是天降福利。终于不用在「能力强但闭源」和「开源但能力差」之间做痛苦抉择了。
当然,如果你需要的是通用知识问答、事实准确性、或者极限数学推理,那目前 Gemini-3.1-Pro 和 Claude Opus 4.6 依然是更稳的选择。DeepSeek-V4 还没有到六边形战士的程度。
但话说回来,一个开源模型能在代码这个最实用的维度上站到最高点,这本身就说明开源和闭源的差距正在以肉眼可见的速度缩小。DeepSeek 每一代都在缩短这个距离,V4 又往前迈了一大步。
如果你也关注 AI 模型的最新动态,强烈建议去 ModelScope 或 HuggingFace 下载权重自己试一下。有问题欢迎评论区交流。
以上,既然看到这里了,如果觉得不错,随手点个赞、在看、转发三连吧,如果想第一时间收到推送,也可以给我个星标⭐~
谢谢你看我的文章,我们,下次再见。

欢迎加入DeepSeek 技术社区。在这里,你可以找到志同道合的朋友,共同探索AI技术的奥秘。
更多推荐
 7
7 0
0- 0



 已为社区贡献2条内容
已为社区贡献2条内容

所有评论(0)