1.从零拆解一个 RAG 系统:纯 API 调用、无需 GPU|基于 LangChain + Chroma + DeepSeek 的学习笔记
前言
最近在学习 RAG(Retrieval-Augmented Generation,检索增强生成),网上的教程要么只讲概念不给代码,要么代码跑不起来,要么上来就要你搞一张 GPU 跑本地模型。对于我们这种没有高端显卡的同学来说,门槛太高了。
后来找到一个结构清晰的 Demo 项目,全程纯 API 调用,LLM 用 DeepSeek、Embedding 用硅基流动,不需要本地 GPU,普通笔记本就能跑。花了一些时间把它拆解了一遍,收获不少。
这篇文章把我的学习过程和理解整理出来,希望对同样在学 RAG 的同学有帮助。
🔗 项目地址:GitHub 搜索 daixueyun3377/RAG-demo,这一期对标的是dev-langchain分支噢
1. 前置准备
你只需要准备两个 API Key:
| Key | 用途 | 获取方式 |
|---|---|---|
| LLM API Key | 大模型生成回答 | DeepSeek、OpenAI 或其他 OpenAI 兼容接口 |
| 硅基流动 API Key | Embedding + Reranker | 免费申请,见下方 |
硅基流动 API Key 申请:
- 访问 cloud.siliconflow.cn
- 注册账号并登录
- 进入「账户管理」→「API 密钥」,创建一个 Key
- 新用户赠送免费额度,本项目使用的 bge-large-zh-v1.5(Embedding)和 bge-reranker-v2-m3(Reranker)均为免费模型
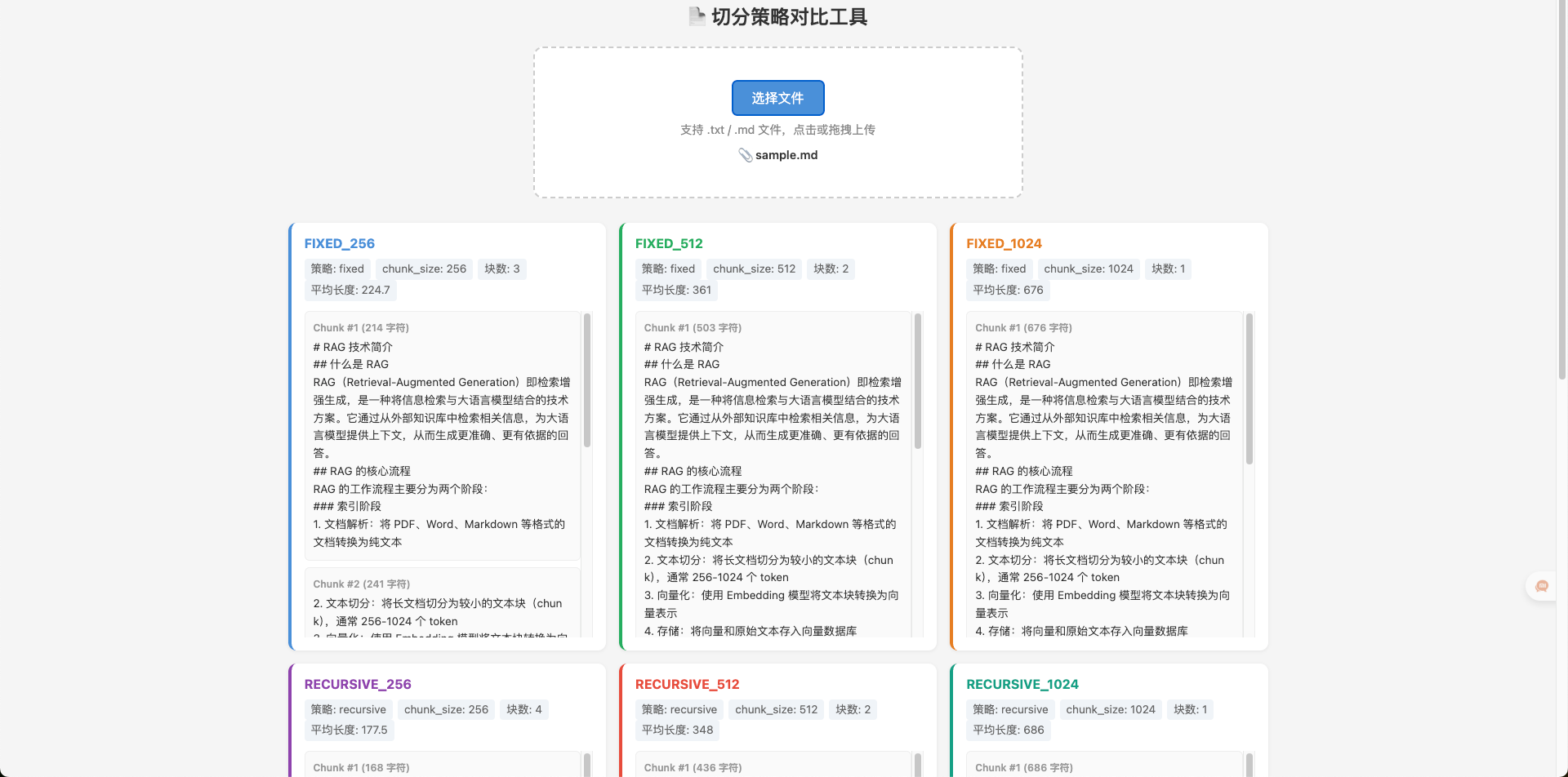
2. 测试结果
为了更好的体现不同切分策略的对比情况,我新增了一个页面,大家在克隆代码
启动命令
python3 -m uvicorn app.main:app --reload --port 8000
url访问 http://localhost:8000/static/chunks.html ,上传doc里的simple文档,就能看到不同的切分策略对比工具啦,欢迎大家下载代码尝试,有问题可以评论区找我~
接下来就是项目剖析啦
项目技术栈一览:
| 组件 | 技术选型 | 说明 |
|---|---|---|
| Web 框架 | FastAPI | 提供 REST API |
| LLM | DeepSeek | 通过 OpenAI 兼容接口调用 |
| Embedding | 硅基流动 bge-large-zh-v1.5 | 中文向量化效果好 |
| 向量数据库 | Chroma | 本地嵌入式,开发阶段轻量 |
| 编排框架 | LangChain | 串联整个 RAG 链路 |
| 可观测性 | Langfuse | 追踪每次查询的完整链路 |
| 基础设施 | Docker Compose | 一键部署 Milvus/Redis/Langfuse |
一、RAG 到底在解决什么问题?
大模型有两个硬伤:
- 训练数据有截止日期,不知道最新的信息
- 不知道你的私有数据,比如公司内部文档、产品手册
直接问大模型,它可能会"一本正经地胡说八道"(幻觉问题)。
RAG 的思路很简单:你问问题的时候,我先从知识库里搜出相关内容,把这些内容当作"参考资料"塞给大模型,它就能基于真实数据回答了。
一句话总结:RAG = 检索 + 生成,先搜后答。
二、项目整体架构
整个系统就两条数据流,理解了这两条线,整个项目就通了。
2.1 入库流程(Indexing)
文档上传 → TextLoader 读取 → TextSplitter 切块 → Embedding 向量化 → 存入 Chroma
2.2 查询流程(Querying)
用户提问 → (可选) Query 变换 → Retriever 检索 → 拼装 Prompt → LLM 生成回答
2.3 项目目录结构
├── app/
│ ├── config.py # 配置管理(环境变量)
│ ├── main.py # FastAPI 入口,定义 API 接口
│ └── rag_engine.py # RAG 核心引擎(重点)
├── docs/
│ └── sample.md # 示例文档
├── rag-infra/
│ ├── docker-compose.yml # 基础设施一键部署
│ └── README.md
├── .env.example # 环境变量模板
└── requirements.txt # Python 依赖
三、逐层拆解代码
3.1 配置层:config.py
这个文件最简单,就是从环境变量读配置:
# LLM 配置
LLM_API_KEY = os.getenv("LLM_API_KEY", "")
LLM_BASE_URL = os.getenv("LLM_BASE_URL", "https://api.deepseek.com")
LLM_MODEL = os.getenv("LLM_MODEL", "deepseek-chat")
# Embedding 配置(硅基流动)
EMBEDDING_API_KEY = os.getenv("EMBEDDING_API_KEY", "")
EMBEDDING_BASE_URL = os.getenv("EMBEDDING_BASE_URL", "https://api.siliconflow.cn/v1")
EMBEDDING_MODEL = os.getenv("EMBEDDING_MODEL", "BAAI/bge-large-zh-v1.5")
设计亮点:LLM 和 Embedding 都走 OpenAI 兼容接口,换模型只需要改环境变量,代码一行不用动。这在实际项目中很重要,因为模型迭代很快,今天用 DeepSeek 明天可能换 Qwen。
3.2 API 层:main.py
FastAPI 提供了 4 个接口:
@app.post("/upload") # 上传文档并入库
@app.post("/query") # RAG 问答
@app.post("/compare-chunks") # 对比切分策略
@app.get("/health") # 健康检查
重点看 /query 接口的请求参数:
class QueryRequest(BaseModel):
question: str
retrieval_mode: Literal["vector", "bm25", "hybrid"] = "hybrid" # 检索模式
query_transform: Literal["none", "rewrite", "hyde"] = "none" # Query 变换
top_k: int = 5 # 返回条数
这个设计很好——把检索模式和 Query 变换都暴露成参数,方便对比不同策略的效果。
3.3 核心引擎:rag_engine.py(重点)
这是整个项目的灵魂,我按功能模块拆开讲。
3.3.1 文档加载
def load_file(file_path: str) -> list[Document]:
if file_path.endswith(".md"):
loader = TextLoader(file_path, encoding="utf-8")
elif file_path.endswith(".txt"):
loader = TextLoader(file_path, encoding="utf-8")
else:
raise ValueError(f"不支持的文件格式: {file_path}")
return loader.load()
目前只支持 .txt 和 .md,生产环境需要扩展支持 PDF、Word 等格式(可以用 PyPDFLoader、UnstructuredWordDocumentLoader)。
3.3.2 文本切分(两种策略)
这是 RAG 中非常关键的一步。为什么要切分?因为:
- 一篇文档可能几千上万字,整篇做向量化精度会很差
- 检索时需要定位到具体段落,而不是返回整篇文档
- 大模型的上下文窗口有限,塞太多内容反而影响效果
def split_documents(documents, strategy="recursive", chunk_size=512, chunk_overlap=50):
if strategy == "fixed":
# 固定长度硬切,简单但可能切断句子
splitter = CharacterTextSplitter(
chunk_size=chunk_size,
chunk_overlap=chunk_overlap,
separator="\n",
)
elif strategy == "recursive":
# 递归切分:优先按段落 → 句子 → 字符逐级拆分
splitter = RecursiveCharacterTextSplitter(
chunk_size=chunk_size,
chunk_overlap=chunk_overlap,
separators=["\n\n", "\n", "。", "!", "?", ".", " ", ""],
)
我的理解:recursive 几乎是所有场景的首选。它的 separators 列表定义了切分优先级——先尝试按双换行(段落)切,切不动就按单换行切,再切不动就按句号切……这样能最大程度保持语义完整性。
chunk_overlap 是重叠区域,比如设成 50,相邻两个块会有 50 个字符的重叠,防止关键信息刚好被切在边界上丢失。
项目还提供了一个对比工具,可以直观看到不同参数的效果:
def compare_chunk_strategies(file_path: str) -> dict:
for strategy in ["fixed", "recursive"]:
for size in [256, 512, 1024]:
chunks = split_documents(docs, strategy=strategy, chunk_size=size, chunk_overlap=size // 10)
# 记录:切了多少块、平均长度、第一块的内容
3.3.3 向量存储(Chroma)
def get_vectorstore() -> Chroma:
global _vectorstore
if _vectorstore is None:
_vectorstore = Chroma(
collection_name=CHROMA_COLLECTION,
embedding_function=get_embeddings(),
persist_directory=CHROMA_PERSIST_DIR,
)
return _vectorstore
用了单例模式,全局只有一个 Chroma 实例。Chroma 是嵌入式向量数据库,数据直接存在本地磁盘(./chroma_db),不需要额外起服务,开发阶段非常方便。
生产环境建议换成 Milvus 这种分布式方案(项目的 docker-compose 里已经准备好了 Milvus)。
3.3.4 三种检索模式
这是项目最有意思的部分之一。
纯向量检索:把问题转成向量,在向量库里找最相似的文本块。擅长语义匹配,比如"怎么让模型不瞎编"能匹配到"减少幻觉"。
def get_vector_retriever(top_k=5):
vs = get_vectorstore()
return vs.as_retriever(search_kwargs={"k": top_k})
BM25 检索:传统的关键词搜索算法,基于词频和逆文档频率。擅长精确匹配,比如搜"Milvus"就是要找包含这个词的内容。
def get_bm25_retriever(top_k=5):
# 从 Chroma 加载所有文档,构建 BM25 索引
return BM25Retriever.from_documents(_all_docs_for_bm25, k=top_k)
混合检索:向量 + BM25 一起用,通过 EnsembleRetriever 做 RRF(Reciprocal Rank Fusion)融合。
def get_hybrid_retriever(top_k=5):
return EnsembleRetriever(
retrievers=[vector_retriever, bm25_retriever],
weights=[0.6, 0.4], # 向量 60%,BM25 40%
)
为什么权重是 6:4? 向量检索在大多数场景下效果更好(能理解语义),但关键词检索在精确匹配场景不可替代,所以给向量更高权重,同时保留 BM25 的补充能力。
3.3.5 Query 变换(两种策略)
用户的提问往往不是最适合检索的形式,Query 变换就是在检索前优化问题。
Query Rewrite(改写):
def rewrite_query(query: str) -> str:
prompt = ChatPromptTemplate.from_template(
"你是一个搜索查询优化助手。请将用户的问题改写为更适合在知识库中检索的查询语句。"
"只输出改写后的查询,不要解释。\n\n用户问题:{question}"
)
比如用户问"RAG 咋用啊",改写后可能变成"RAG 的使用方法和核心流程",更适合检索。
HyDE(假设性文档嵌入):
def hyde_query(query: str) -> str:
prompt = ChatPromptTemplate.from_template(
"请针对以下问题写一段简短的回答(约100字),即使你不确定也请尝试回答。"
"这段回答将用于检索相关文档。\n\n问题:{question}"
)
这个思路很巧妙:不用问题去搜,而是先让 LLM 猜一个答案,用这个答案去搜。为什么?因为答案和知识库里的内容在表述上更接近(都是陈述句),向量相似度会更高。这个方法来自论文 “Precise Zero-Shot Dense Retrieval without Relevance Labels”。
3.3.6 RAG 主链路
def query_rag(question, retrieval_mode="hybrid", query_transform="none", top_k=5):
# 1. Query 变换(可选)
search_query = question
if query_transform == "rewrite":
search_query = rewrite_query(question)
elif query_transform == "hyde":
search_query = hyde_query(question)
# 2. 检索
retrieved_docs = retriever.invoke(search_query)
# 3. 拼装 Prompt + 生成回答
chain = RAG_PROMPT | llm | StrOutputParser()
answer = chain.invoke(
{"context": format_docs(retrieved_docs), "question": question},
config={"callbacks": callbacks}, # Langfuse 追踪
)
注意一个细节:Query 变换只影响检索用的 query,最终给 LLM 的还是用户原始问题。这很重要,因为改写/HyDE 是为了提高检索精度,但回答应该针对用户的原始意图。
Prompt 模板也值得看:
RAG_PROMPT = ChatPromptTemplate.from_template(
"""你是一个知识库问答助手。请基于以下检索到的内容回答用户问题。
如果检索内容中没有相关信息,请诚实说明。回答时标注信息来源。
检索到的内容:
{context}
用户问题:{question}"""
)
两个关键指令:没有相关信息要诚实说明(减少幻觉)、标注信息来源(增强可信度)。
四、基础设施:Docker Compose 一键部署
rag-infra/docker-compose.yml 包含三个服务:
4.1 Milvus(向量数据库)
Milvus 是分布式向量数据库,依赖 etcd(元数据存储)和 MinIO(对象存储)。虽然当前代码用的是 Chroma,但 Milvus 已经为生产环境准备好了。
milvus:
image: milvusdb/milvus:v2.4.0
ports:
- "19530:19530" # API 端口
- "9091:9091" # 健康检查
depends_on:
etcd:
condition: service_healthy
minio:
condition: service_healthy
4.2 Redis(缓存/对话记忆)
redis:
image: redis:7-alpine
command: redis-server --appendonly yes --maxmemory 512mb --maxmemory-policy allkeys-lru
配置了 AOF 持久化和 LRU 淘汰策略。目前代码还没接 Redis,但架构上已经预留了对话记忆的能力。
4.3 Langfuse(可观测性)
langfuse:
image: langfuse/langfuse:2
ports:
- "3000:3000" # Web UI
Langfuse 可以追踪每次 RAG 查询的完整链路:用了哪个检索器、检索到了什么、LLM 的输入输出、耗时多少。对于调优 RAG 效果非常有用。
五、快速上手
# 1. 克隆项目并安装依赖
git clone https://github.com/daixueyun3377/RAG-demo.git
cd RAG-demo
pip install -r requirements.txt
# 2. 配置环境变量
cp .env.example .env
# 编辑 .env,填入 DeepSeek 和硅基流动的 API Key
# 3. 启动服务
uvicorn app.main:app --reload --port 8000
# 4. 打开浏览器访问 http://localhost:8000/docs
# FastAPI 自带 Swagger UI,可以直接测试接口
测试流程:
- 调用
/upload上传docs/sample.md - 调用
/query,问"RAG 有什么优势" - 对比不同
retrieval_mode和query_transform的效果 - 调用
/compare-chunks看不同切分策略的差异
六、我的思考:这个项目还可以怎么改进?
学完之后我也想了一些可以优化的方向:
- 加 Reranker:检索出来的 top_k 结果,用一个交叉编码器(如 bge-reranker)做二次排序,精度会有明显提升
- 支持更多文档格式:PDF(PyPDFLoader)、Word(UnstructuredWordDocumentLoader)、HTML 等
- 接入对话记忆:Redis 已经部署了,可以用 LangChain 的
ConversationBufferMemory实现多轮对话 - 向量库切换到 Milvus:Chroma 适合开发,Milvus 适合生产,支持分布式和更大规模的数据
- 流式输出:当前是等 LLM 生成完才返回,可以改成 SSE 流式输出,用户体验更好
- 评估体系:接入 RAGAS 等评估框架,量化检索和生成的质量
总结
RAG 的核心思路并不复杂——先搜后答。但要做好,每个环节都有讲究:
- 切分决定了知识库的"颗粒度"
- 检索决定了能不能找到对的内容
- Prompt决定了大模型能不能好好利用这些内容
这个项目的价值在于,它把这些环节都做成了可配置、可对比的,非常适合用来学习和实验。
如果你也在学 RAG,建议把项目跑起来,多试几种参数组合,看看效果的变化,比光看文档理解深刻得多。
📌 本文为个人学习笔记,如有错误欢迎指正。
后续计划继续学习 RAG 进阶内容(Reranker、多轮对话、评估体系等),有兴趣的同学可以关注。

欢迎加入DeepSeek 技术社区。在这里,你可以找到志同道合的朋友,共同探索AI技术的奥秘。
更多推荐


 11
11 0
0- 0



 已为社区贡献3条内容
已为社区贡献3条内容

所有评论(0)