deepseek大模型私有化部署(0基础,保姆级)
一文学会大模型部署基础,小白一小时速成部署自己的大模型。
本文:可以教你从0开始部署一个属于自己的deepseek-r1大模型(7B版,如果是企业级别的可更换其他版本。)没有废话全是干货直接开始。
第一步:算力准备
tips:有算力的可以用自己的算力
算力云链接:AutoDL算力云 | 弹性、好用、省钱。租GPU就上AutoDL
1.一般来说部署小尺寸的大模型进行测试的话4090算力就足够了。但是满血或者是大尺寸的可能需要具体的计算算力需求了。
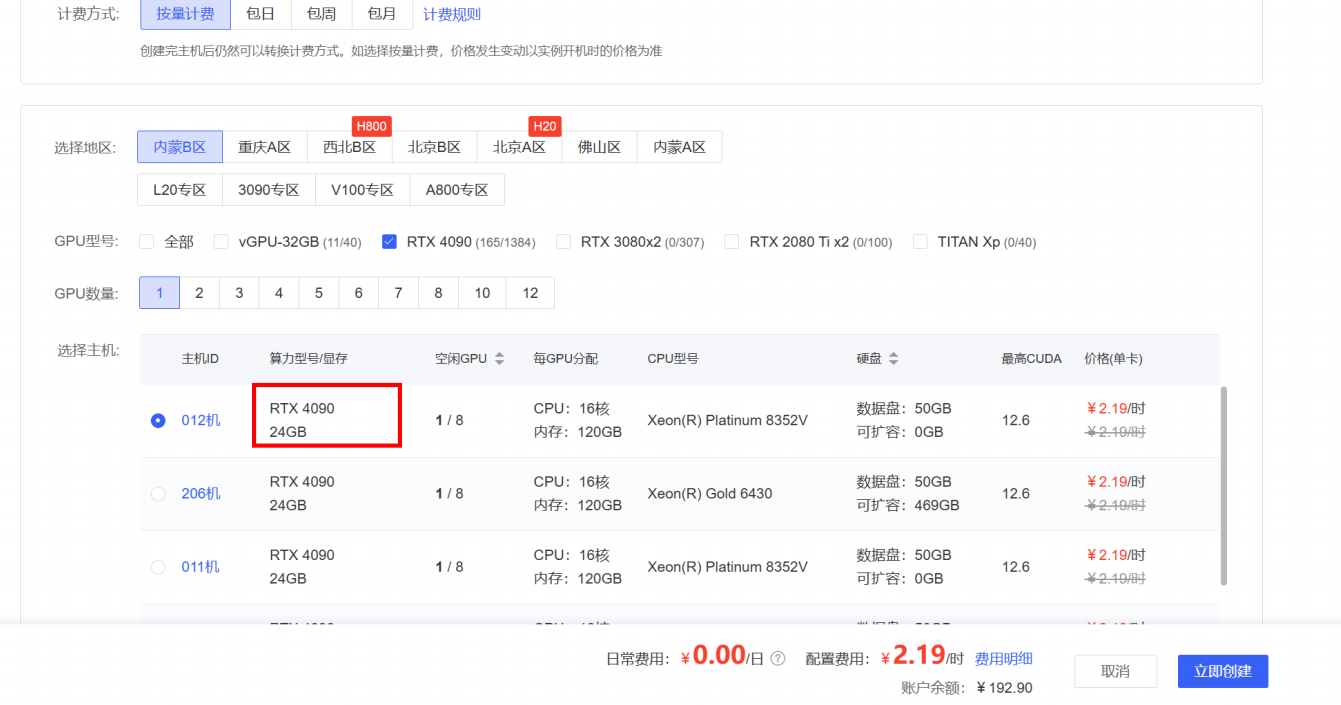
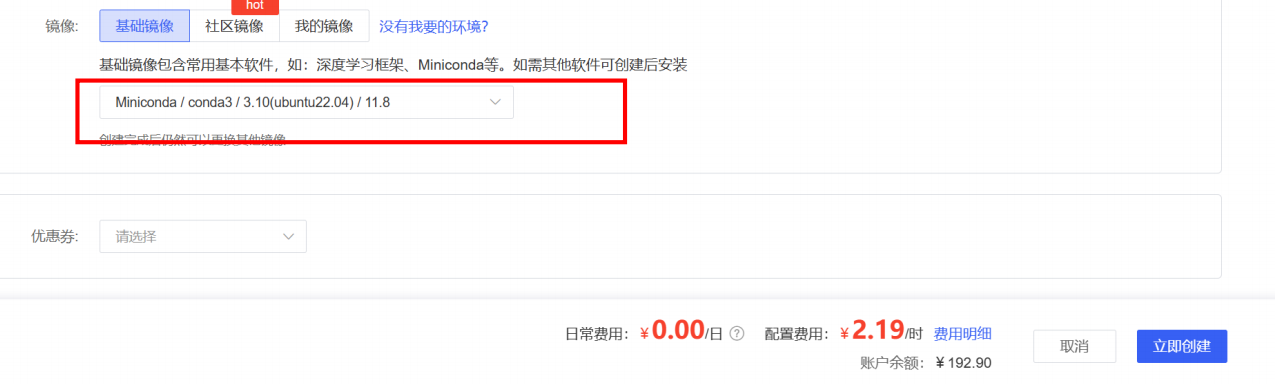
2.然后选择镜像,也可以用别人社区配置好的镜像
3.远程工具连接算力云
nvidia-smi #查看算力情况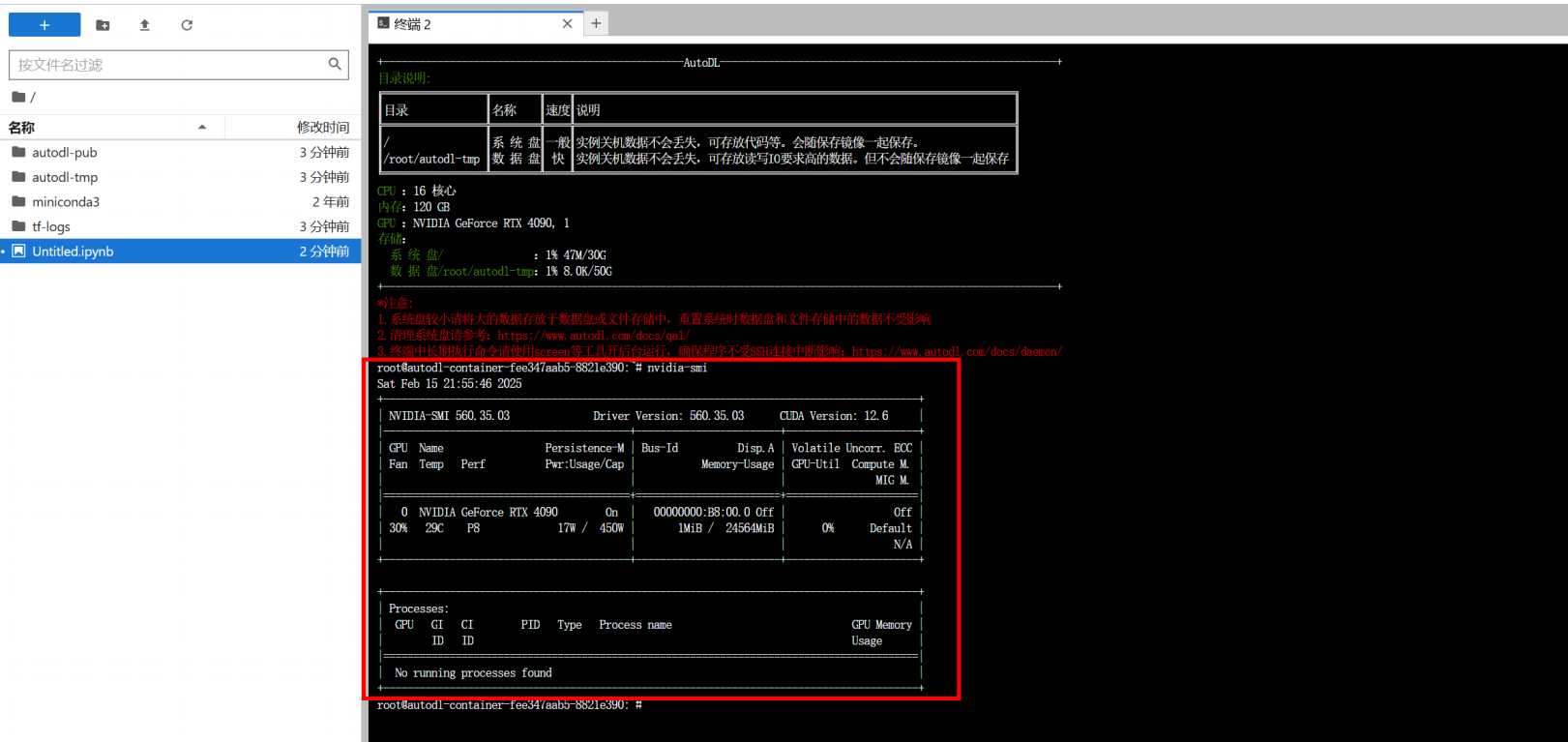
第二步:开始部署
1.由于ollama推理平台有较好的服务,完整的框架,使用起来极为方便所以,我们直接使用这个。
Download Ollama on Linuxollama:平台地址 Download Ollama on Linux
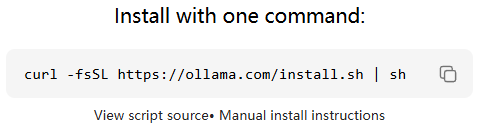
source /etc/network_turbo #设置配置
curl -fsSL https://ollama.com/install.sh | sh #执行下载ollama指令2.可能出现异常waring

3.根据提示装一些库
apt update && apt install -y lshw pciutils #如果有警告啥的要根据提示安装一些库。
lspci | grep -i nvidia # 查看是否正确了4.尝试让ollama跑起来
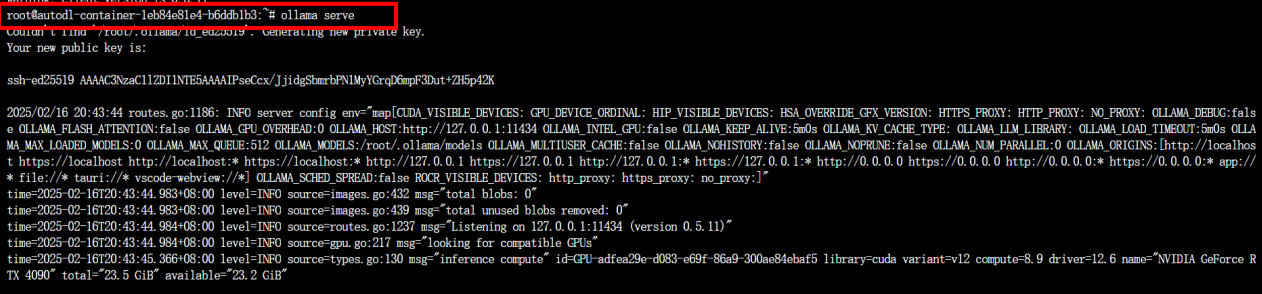
ollama serve #启动
ollama -v #查看版本如果正常跑起来了应该是这样的
5.下载deepseek-r1模型
注意:前面服务器运行的ollama serve不要断,不能停,再打开这个服务器另一个窗口
运行:
source /etc/network_turbo #设置环境
ollama run deepseek-r1 #下载deepseek-r1模型
上面就是说明模型下载了。但是你如果想下载别的尺寸的模型要改参数,具体模型尺寸参考如下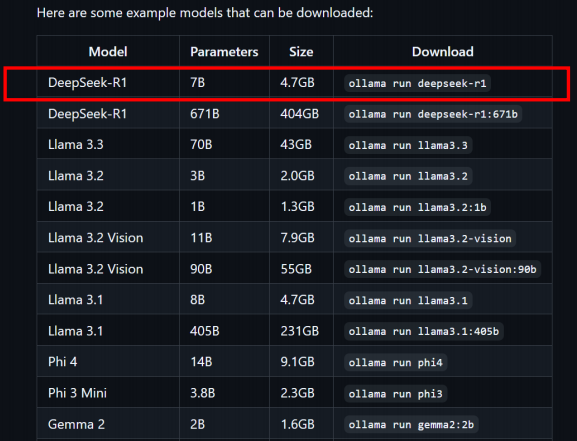
6.此时你应该同一个服务器有两个窗口,一个在运行ollama serve,另一个如下已经开始可以对话
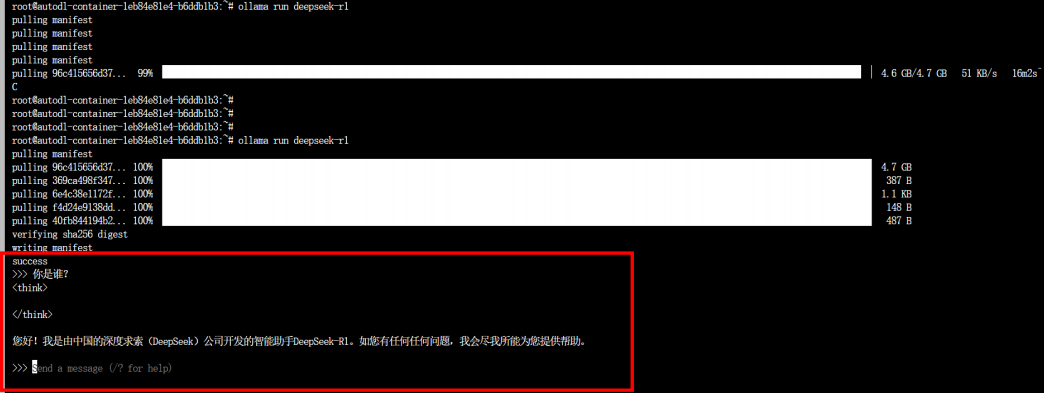
此时本地部署测试已经完成了,约等于你有了大模型的服务端。
第三步:大模型客户端部署:
tips:此处只展示简单demo,跑通链路。
1.本地pycharm新建一个项目服务端(如果这个不会就乖乖学下python基础)
2.创建deepseek_local_client.py
import requests
SERVER_IP = "localhost"
PORT = 6006
MODEL = "deepseek-r1"
def chat_with_ollama(prompt, system_prompt=None, messages=None):
if messages is None:
messages = []
# 添加 system prompt
if system_prompt:
messages.append({"role": "system", "content": system_prompt})
# 添加当前用户输入
messages.append({"role": "user", "content": prompt})
url = f"http://{SERVER_IP}:{PORT}/api/chat"
payload = {
"model": MODEL,
"messages": messages,
"stream": False,
"options": {
"temperature": 0.7,
"num_predict": 512
}
}
headers = {"Content-Type": "application/json"}
try:
response = requests.post(url, json=payload, headers=headers, timeout=60)
response.raise_for_status()
data = response.json()
if "error" in data:
print(f"Ollama 错误: {data['error']}")
return None
if "message" in data and "content" in data["message"]:
return data["message"]["content"]
else:
print("响应格式异常:", data)
return None
except requests.exceptions.RequestException as e:
print(f"请求失败: {e}")
return None
# 主程序入口
if __name__ == "__main__":
conversation_history = [] # 初始化对话历史
print("欢迎使用 DeepSeek 模型!输入 'exit' 或 '退出' 结束对话。")
while True:
user_input = input("\n用户: ").strip()
# 处理退出指令
if user_input.lower() in ["exit", "退出", "quit"]:
print("对话已结束。")
break
if not user_input:
print("请输入内容后再发送。")
continue
# 调用模型并获取回复
model_response = chat_with_ollama(prompt=user_input, messages=conversation_history)
if model_response:
print(f"模型: {model_response}")
# 更新对话历史
conversation_history.append({"role": "user", "content": user_input})
conversation_history.append({"role": "assistant", "content": model_response})
else:
print("未能获取模型回复,请重试。")当前运行,是会请求失败的,因为算力云的ip端口什么的都有限制,但是如果你是公司服务器,设置好ip端口等应该是已经可以服务端成功对话了。(如果是小白可以完全跟着我的教程继续往下做)
3,算力云造成的其余配置
![]()
找到云服务器的对应位置:
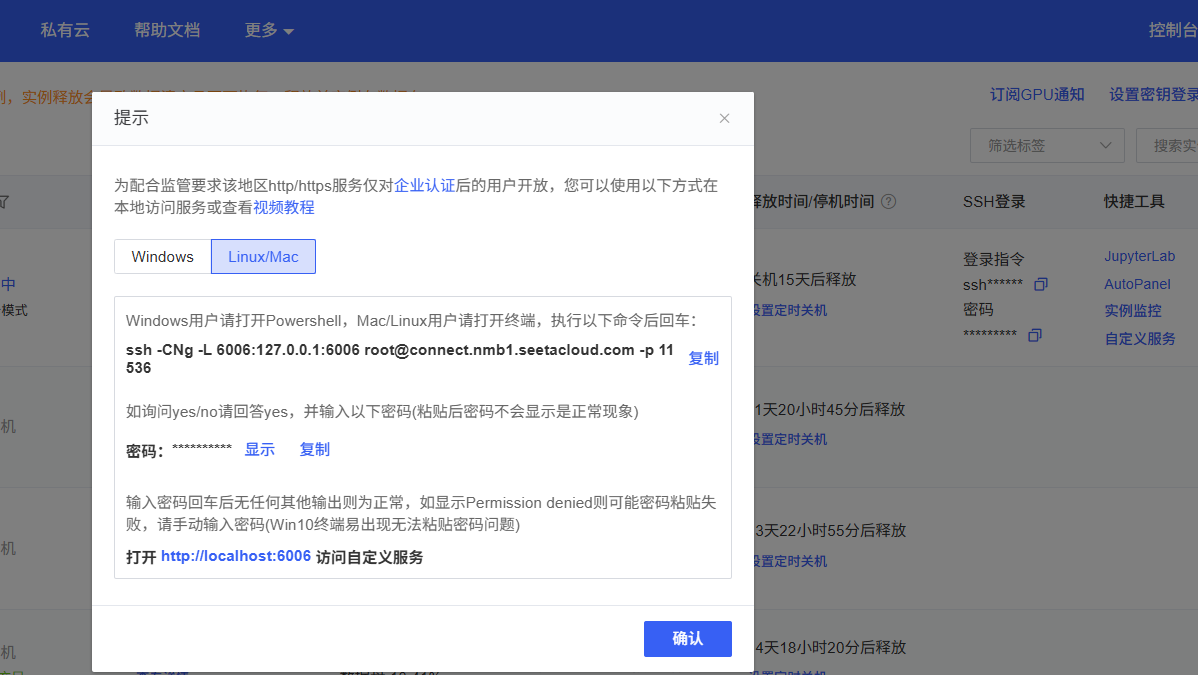
进行下面的连接
# 这里要换成你自己算力云的地址对应的指令
ssh -CNg -L 6006:127.0.0.1:6006 root@connect.nmb1.seetacloud.com -p 11536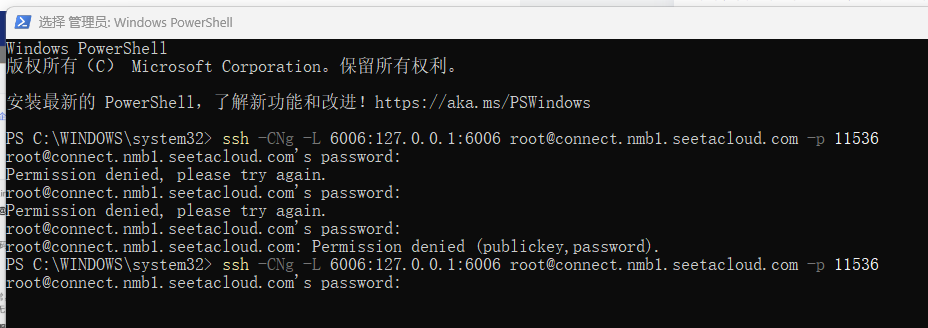
然后连接好你就可以在本地python项目中进行对话了。
以上的步骤都是由于算力云限制随意访问造成的,搞过服务端开发的老哥应该能根据自己的需求进行修改了。
第四步:将大模型定制化部署在open-webui上
tips:当然deepseek的页面美观又好看肯定不能让用户使用python对话框,所以我们也可以在自己公司的网页上部署,并且要写提示词让大模型熟悉公司的业务,此处就展示部署在open-webui。
1,先展示一下,部署好后的最终效果
主页: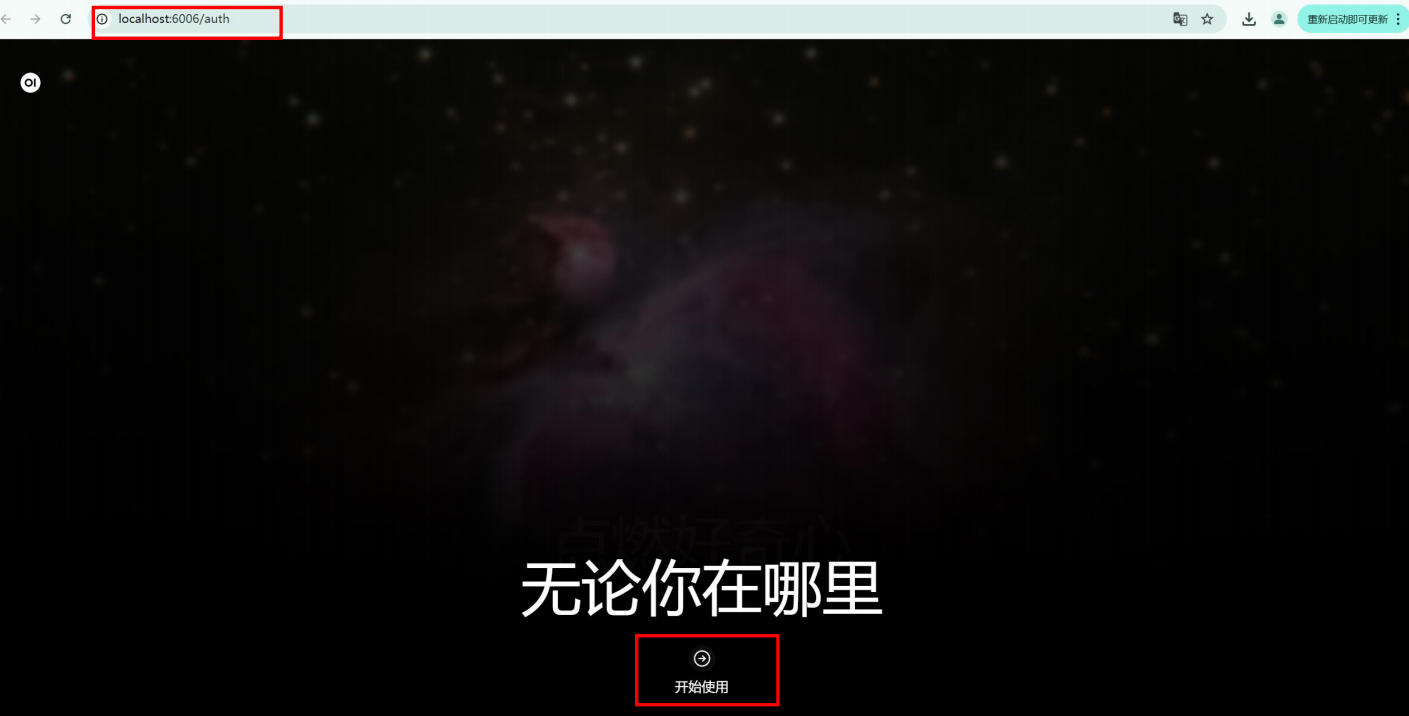
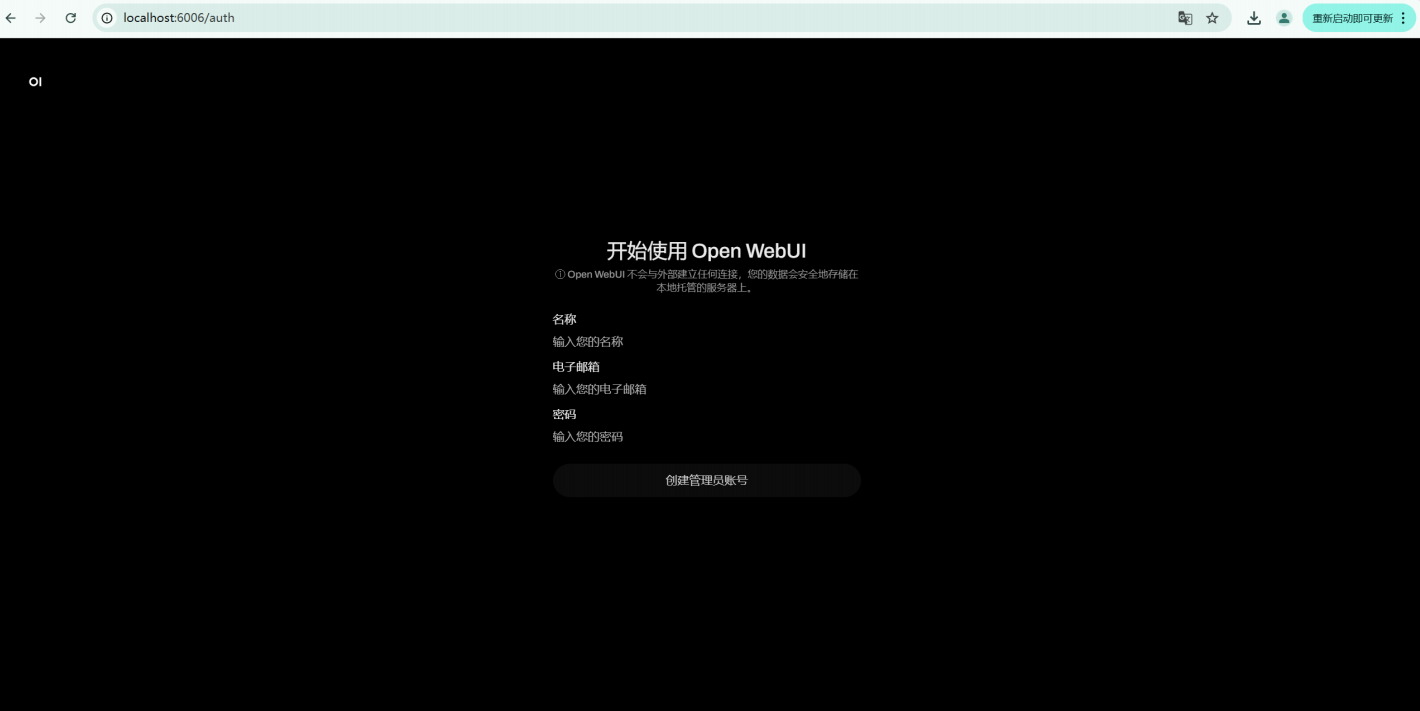
注册页:
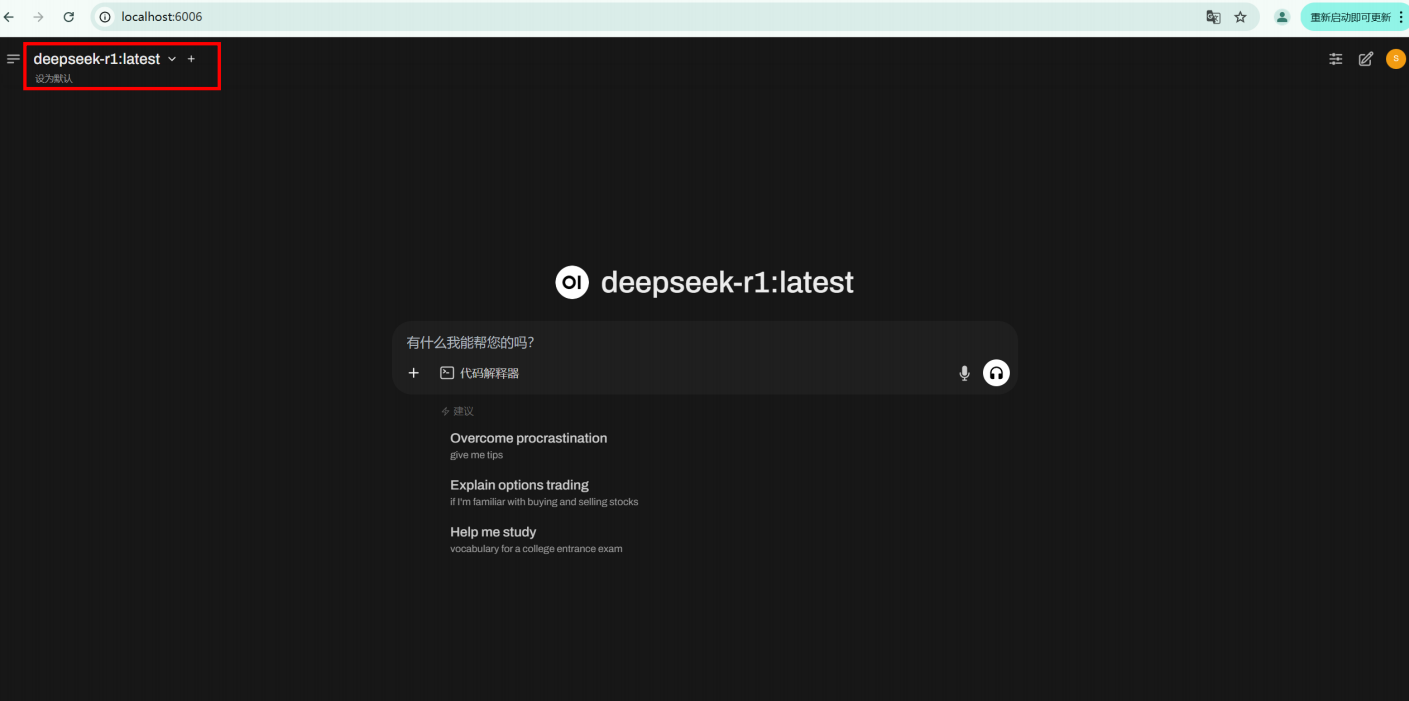
对话页:
2,在服务器端执行创建open-webui环境
conda create -n open-webui python=3.11 #先创建一个环境:
conda activate open-webui #激活环境:
3, 下载open-webui
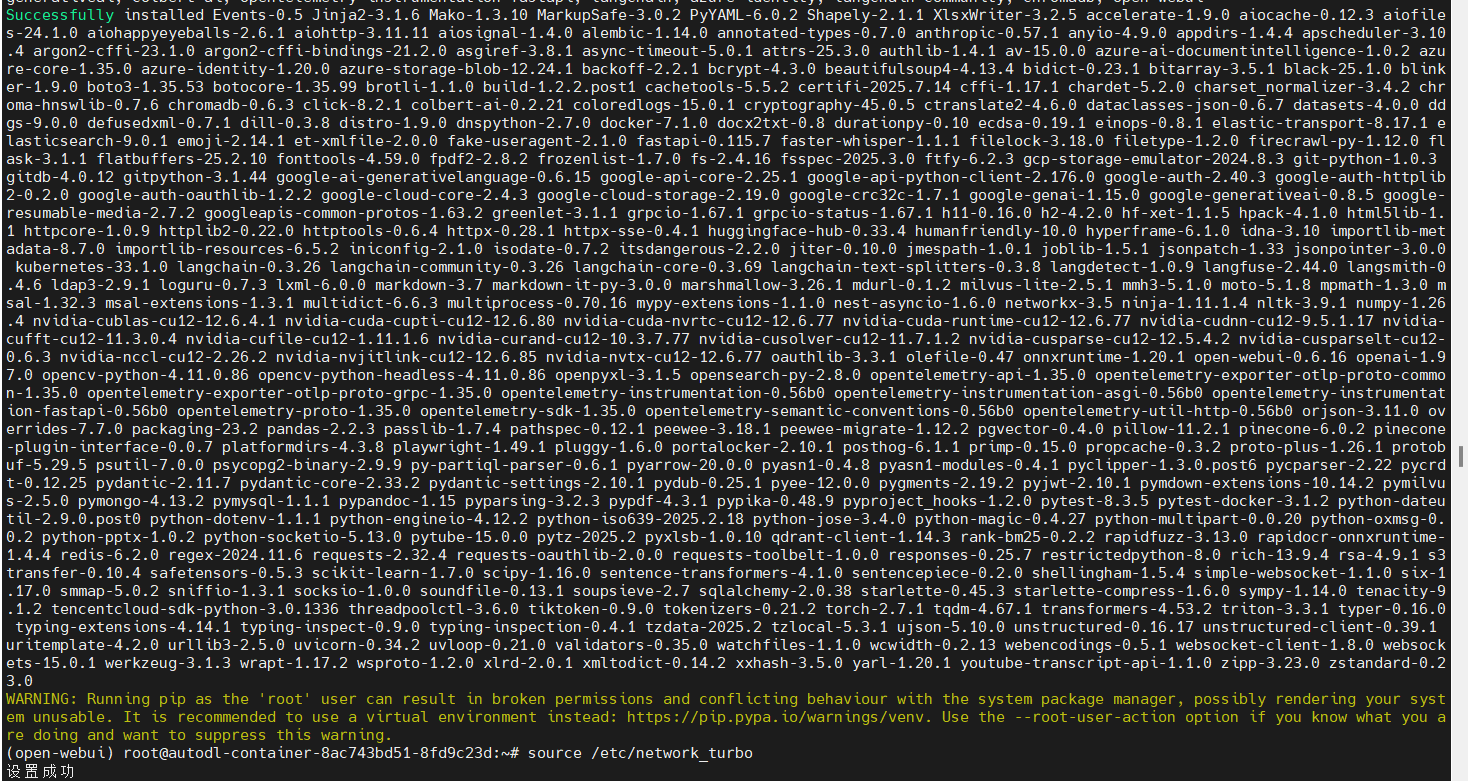
pip install open-webui #下载open-webui下载好应该是这样的(注意左上角绿色的succeefully)
4,运行
source /etc/network_turbo #设置
open-webui serve --port 6006 #运行运行成功
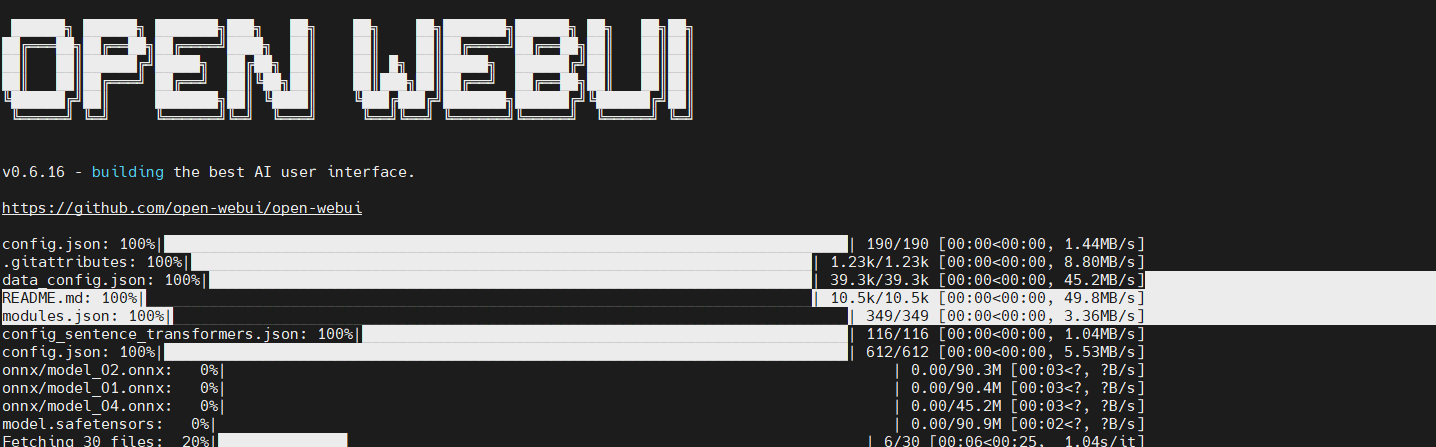
5,此时你的open-webui已经完全启动了。
现在需要你检查三部分
1,powershell与远程成功连接。

2,你的服务器窗口1: ollama serve服务端在线。

3,服务器窗口2: open-webui客户端在线。
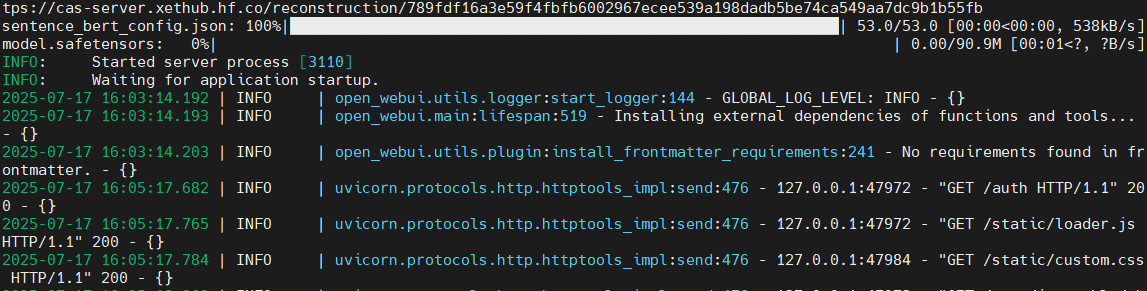
此时就可以打开:一个网页输入localhost:6006/auth,打开你部署的模型进行对话了。
预计后续更新:
1,基于原型的,高质量知识库构建与向量化。
2,Embedding 模型选择与提示词工程处理。
3,大模型的监督微调
4,模型量化与优化
5,高并发与缓存处理策略

欢迎加入DeepSeek 技术社区。在这里,你可以找到志同道合的朋友,共同探索AI技术的奥秘。
更多推荐



 23
23 0
0- 0



 已为社区贡献2条内容
已为社区贡献2条内容

所有评论(0)