windows/macos本地部署deepseek 14b模型,并设置共享访问
注:macos当服务器时,在回答问题结束后会自动释放内存。使用pc时,是可以使用GPU的共享内存的,但是由于参数量大小不一致,可能导致大的模型出结果的速度非常慢。3.下载后要保持Ollama在后台运行。点击红色框的复制按钮,进入管理员的powershell,直接粘贴点回车就开始下载了。然后就可以在pc上的ChatBox上配置Tailscale的ip。下载后先安装Ollama,然后安装Chatbox
一、配置、下载模型
1.首先下载组件:Ollama、Chatbox
Ollama下载网站:奥拉马
Chatbox下载网站:https://chatboxai.app/zh#download
下载后先安装Ollama,然后安装Chatbox。
2.打开Ollama,然后进powershell(管理员)
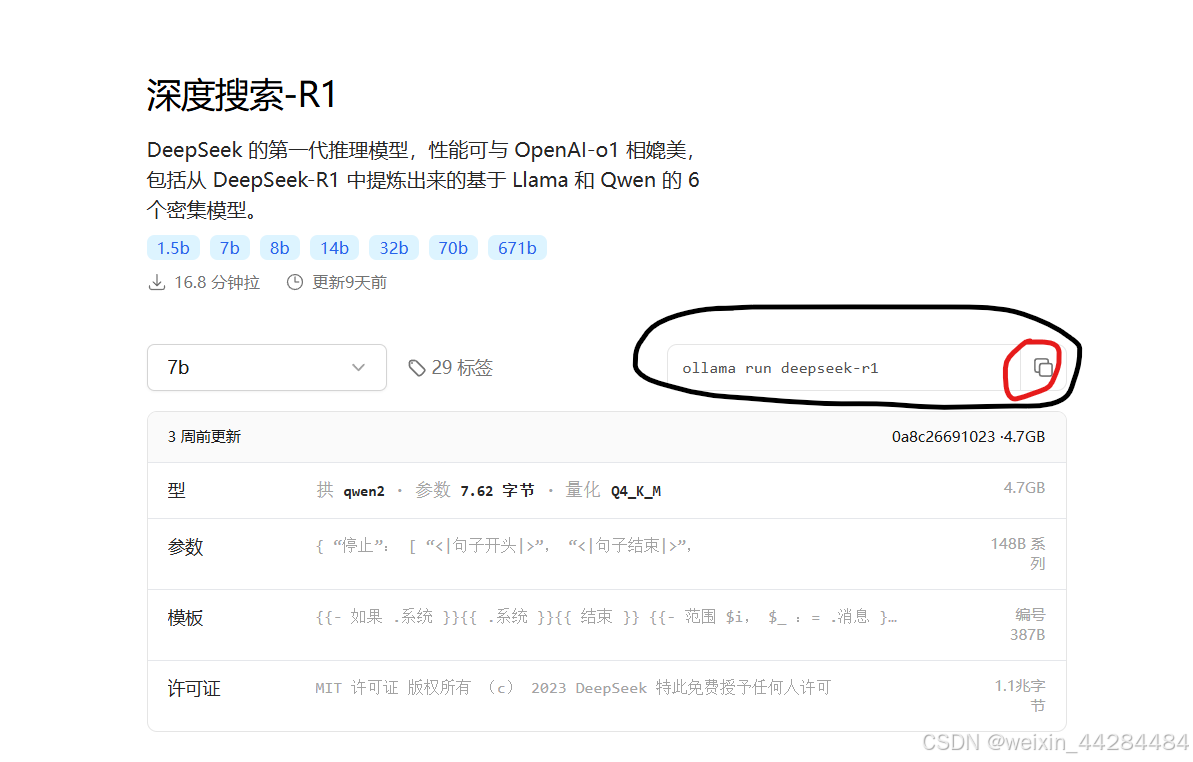
点击红色框的复制按钮,进入管理员的powershell,直接粘贴点回车就开始下载了。
3.下载后要保持Ollama在后台运行。现在运行Chatbox,配置我们刚下载好的模型:
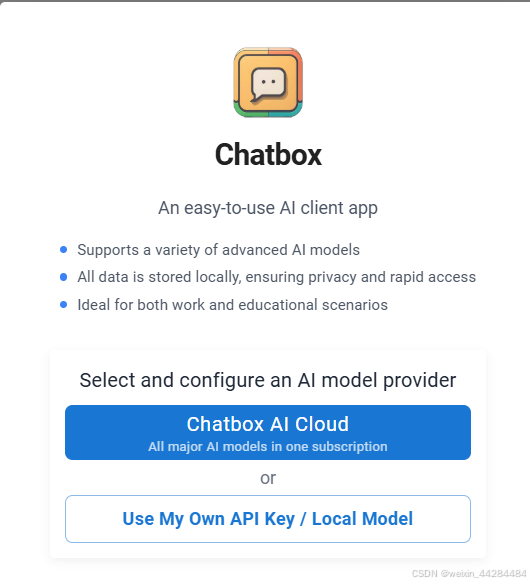
点击 use my Own API Key
选择Ollama API
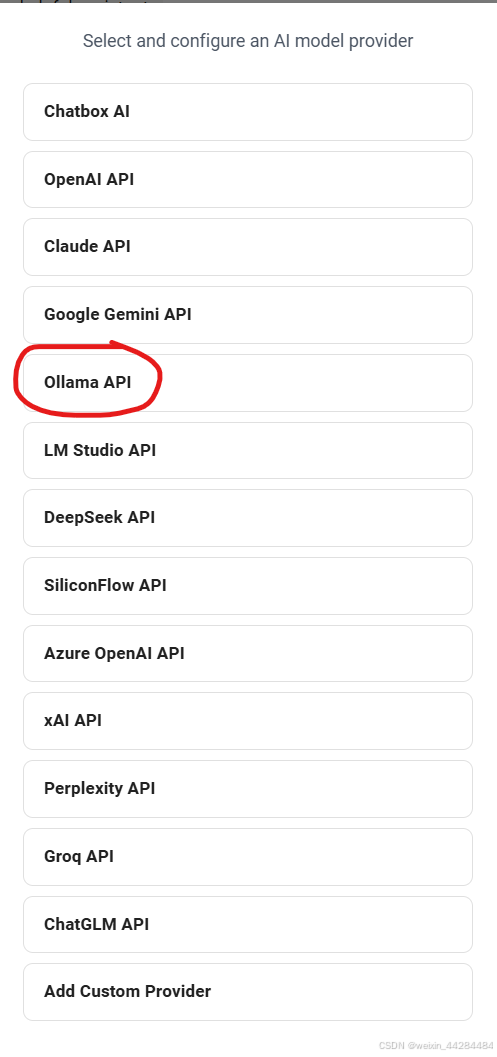
这个地方选择自己的模型
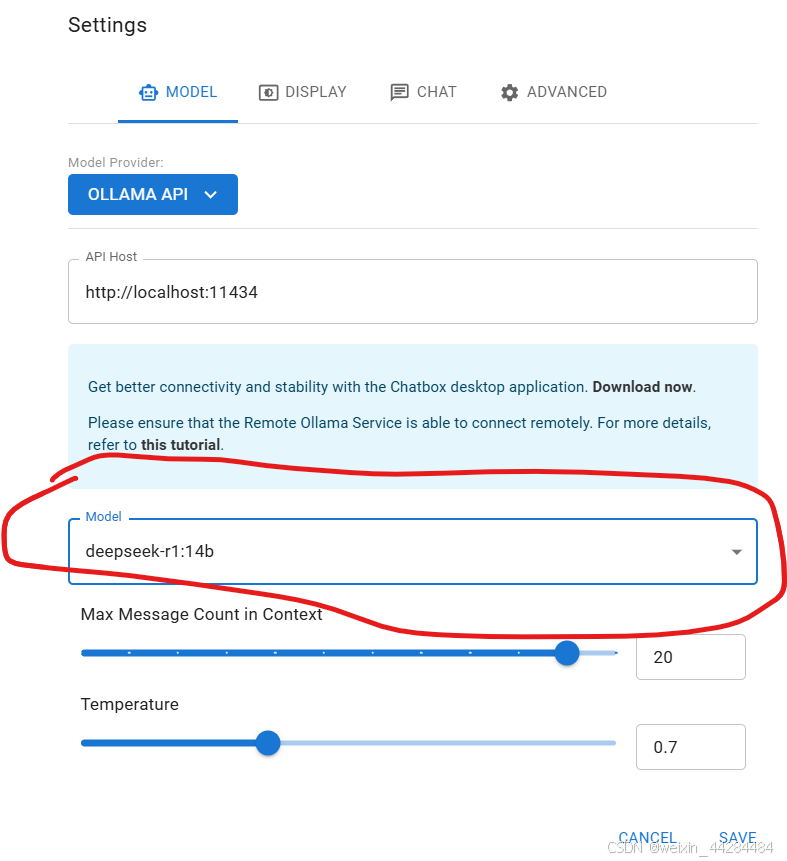
然后就可以使用了。
二、在局域网使用(跨设备使用)
首先配置一下Windows的环境变量:
变量 OLLAMA_HOST,值:0.0.0.0
变量 OLLAMA_ORIGINS,值: *
macos上配置:
launchctl setenv OLLAMA_HOST "0.0.0.0"
launchctl setenv OLLAMA_ORIGINS "*"
配置完成后重启Ollama。
此时我们在另一台设备上打开Chatbox(见下面跨局域网使用的章节的图),此时我们输入的ip地址为我们服务器在局域网中的ip地址,端口不变。
三、跨局域网使用:
在Windows上配置Tailscale实现ssh远程开发-CSDN博客
配置上Tailscale(服务器与pc都要配置)
然后就可以在pc上的ChatBox上配置Tailscale的ip
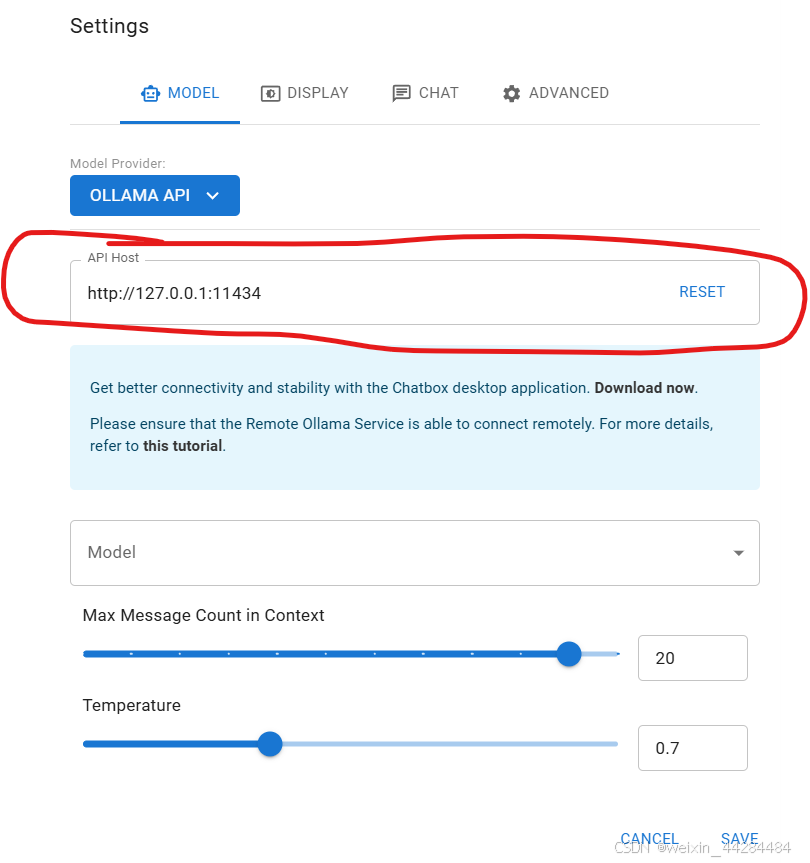
注意,端口号不需要修改,只需要修改前面的ip地址。
使用pc时,是可以使用GPU的共享内存的,但是由于参数量大小不一致,可能导致大的模型出结果的速度非常慢。按需选择。
注:macos当服务器时,在回答问题结束后会立即释放内存。但是Windows做服务器时,5分钟左右才会进行释放。

欢迎加入DeepSeek 技术社区。在这里,你可以找到志同道合的朋友,共同探索AI技术的奥秘。
更多推荐



 7
7 0
0- 0



 已为社区贡献2条内容
已为社区贡献2条内容

所有评论(0)