20分钟基于华为云 + DeepSeek一键单机部署极速搭建Dify-LLM智能AI客服助手Agent开发
本文介绍如何利用华为云Flexus X实例服务器、DeepSeek-V3/R1大模型和开源平台Dify-LLM快速构建私有知识库问答系统。首先在华为开发者空间提供的Ubuntu云主机上部署Dify平台,通过图形界面或命令行完成环境配置。部署成功后,用户可初始化管理员账户并登录平台,配置DeepSeek大语言模型(包括LLM、Text Embedding等五种类型),获取API Key密钥。该系统整
一、前言:
在AI大模型时代,越来越多的企业开始重视私有化知识库的数据,那么,个人开发者与企业人员如何高效管理、使用私有化的知识库数据。但是自己搭建一套AI系统,需要花费大量的人力、物力,还要会懂AI技术能力。

今天来介绍如何借助华为云Flexus X实例服务器、DeepSeek-V3/R1大模型以及开源平台Dify-LLM应用开发平台,一键构建并运行一个完整的私有知识库问答系统。通过构建一个智能的知识库问答系统,用户不仅能提升信息检索效率,还能实现智能化、结构化的知识服务体验。
二、如何构建Dify AI智能体实战?
首次访问部署完成的 Dify 平台,系统会自动跳转至账号初始化页面,引导用户创建平台管理员,完成账号设置后,用户即可登录后台控制台,开始配置模型和应用。
1.1 华为开发者空间案例介绍:
以在“华为开发者空间”中的云主机为基础搭建Dify-LLM应用平台,为了更好的使用“华为云开通的ModelArts Studio 大模型即服务平台DeepSeek-V3-32K 和 DeepSeek-R1-32K 商用服务的大模型”和Dify功能,本案例中,我们将在华为开发者空间提供的云主机中安装Dify并进行探索相关功能展示。
1.2 华为云空间核心功能演示:
在华为开发者空间,华为云为每个新生态的开发者免费提供一台云主机,每位开发者每年可享有数百小时的云主机使用时长。
云主机预集成CodeArts IDE、代码仓及JDK、Python等运行时插件,解决本地开发环境中配置复杂、稳定性不足和依赖等问题,为开发者提供性能强大、安全、稳定、高效的开发环境,应用场景:
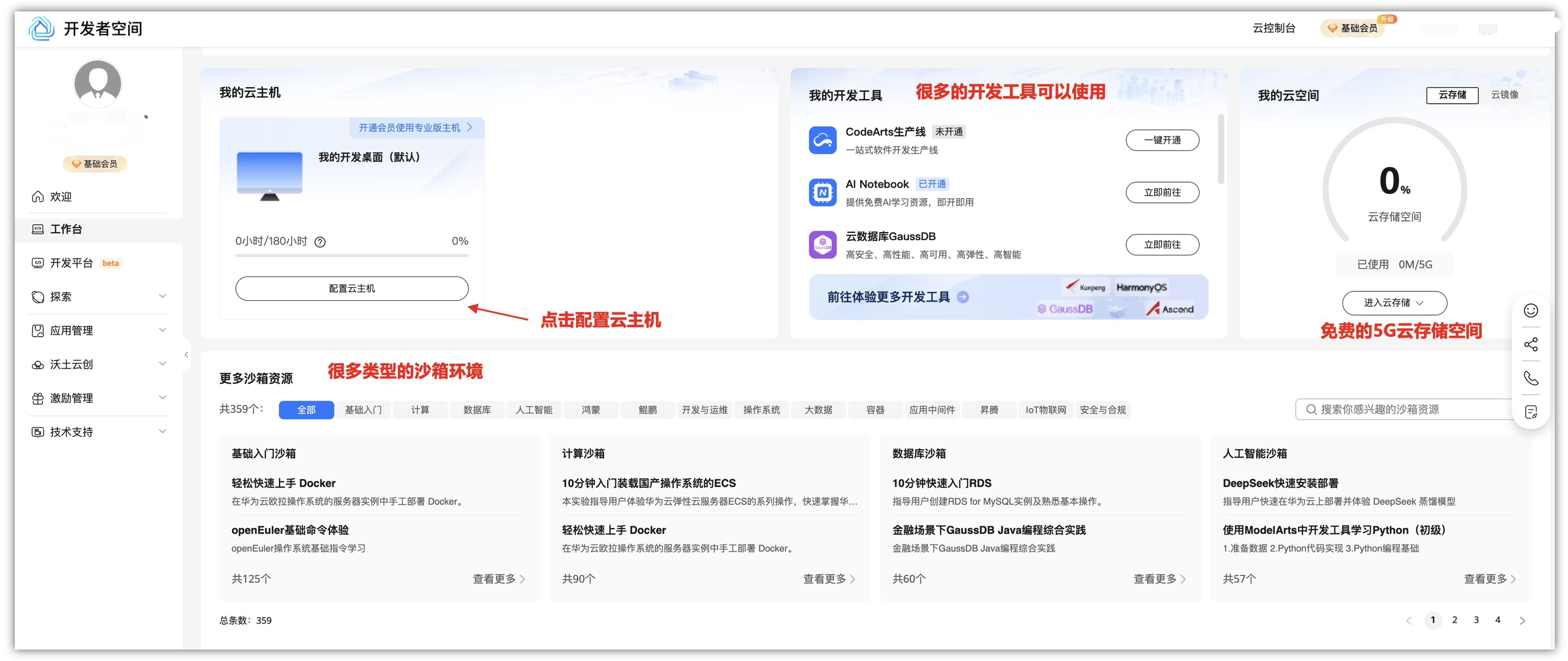
- ①. 个人开发者:为开发者提供丰富的开发工具,支持开发者应用构建;
- ②. 高校师生:支持教师开课、设计实验项目,学生学习课程及开发实践;
- ③. 开源共创:开发者进行开源适配和开发,完成项目并发布开源仓库和云商店,获得开源激励。
默认机器配置是4核8G的配置,这里我们选择安装Ubuntu 24.04的镜像安装包,点击安装成功后,可以通过两种不同的远程访问方式,主要区别体现在连接目的、交互界面、适用场景和技术实现上:
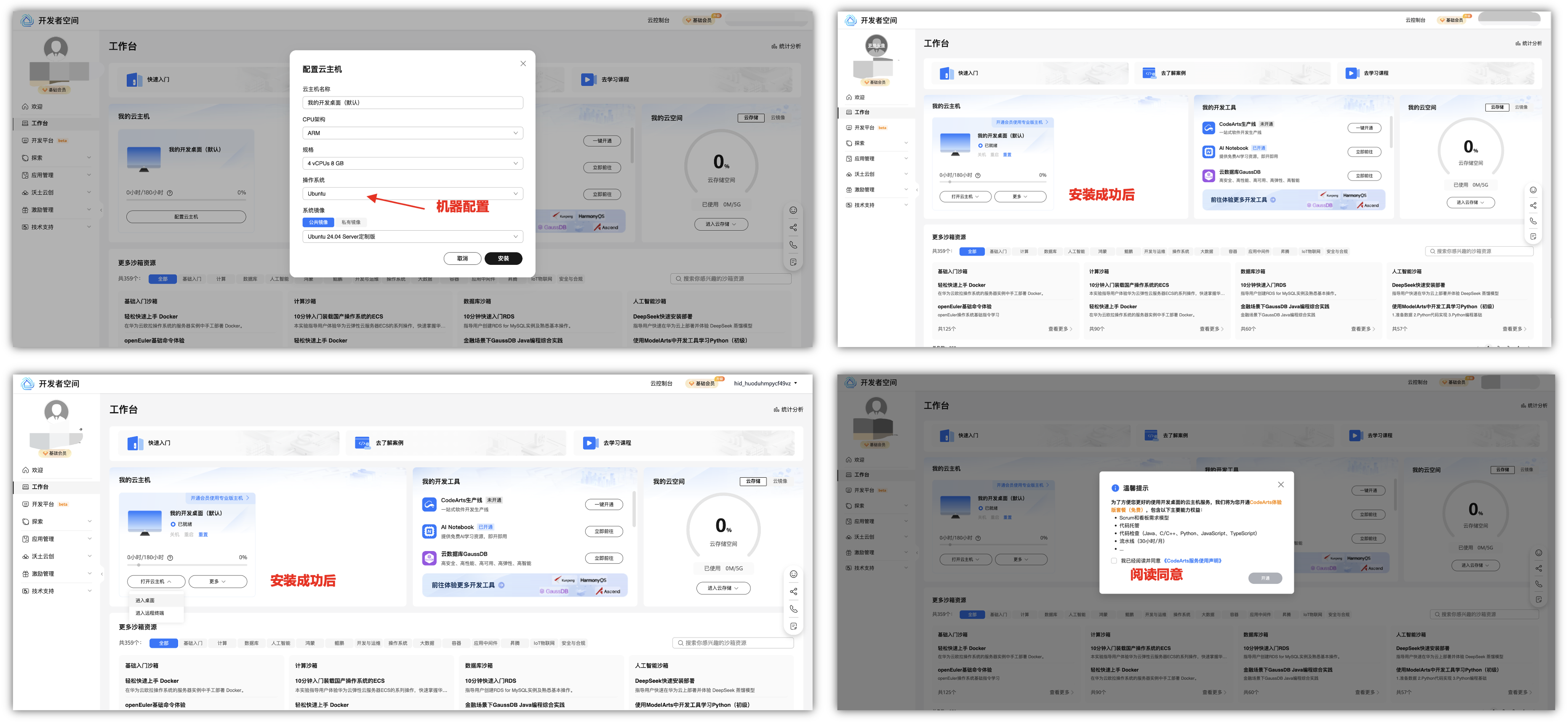
- ①. 进入桌面:为开发者提供丰富的开发工具,支持开发者应用构建。
- 通过图形化界面远程操作目标计算机的完整桌面环境(如Windows、macOS或Linux桌面)。
- 用户看到的界面与本地操作相同,可运行图形软件、编辑文件等。
- 典型工具:Windows远程桌面(RDP)、第三方软件(向日葵、TeamViewer)。
- 适用场景:远程办公、技术支持、图形化运维。 - ②. 进入远程终端:支持教师开课、设计实验项目,学生学习课程及开发实践。
- 通过命令行界面(CLI)远程登录目标设备,仅支持文本指令操作(如Linux的SSH、Windows的Telnet)。
- 无图形界面,只能执行命令、查看文本输出。
- 典型协议:SSH(安全)、Telnet(明文传输,不安全)。
- 适用场景:服务器运维、网络设备配置、批量脚本执行。
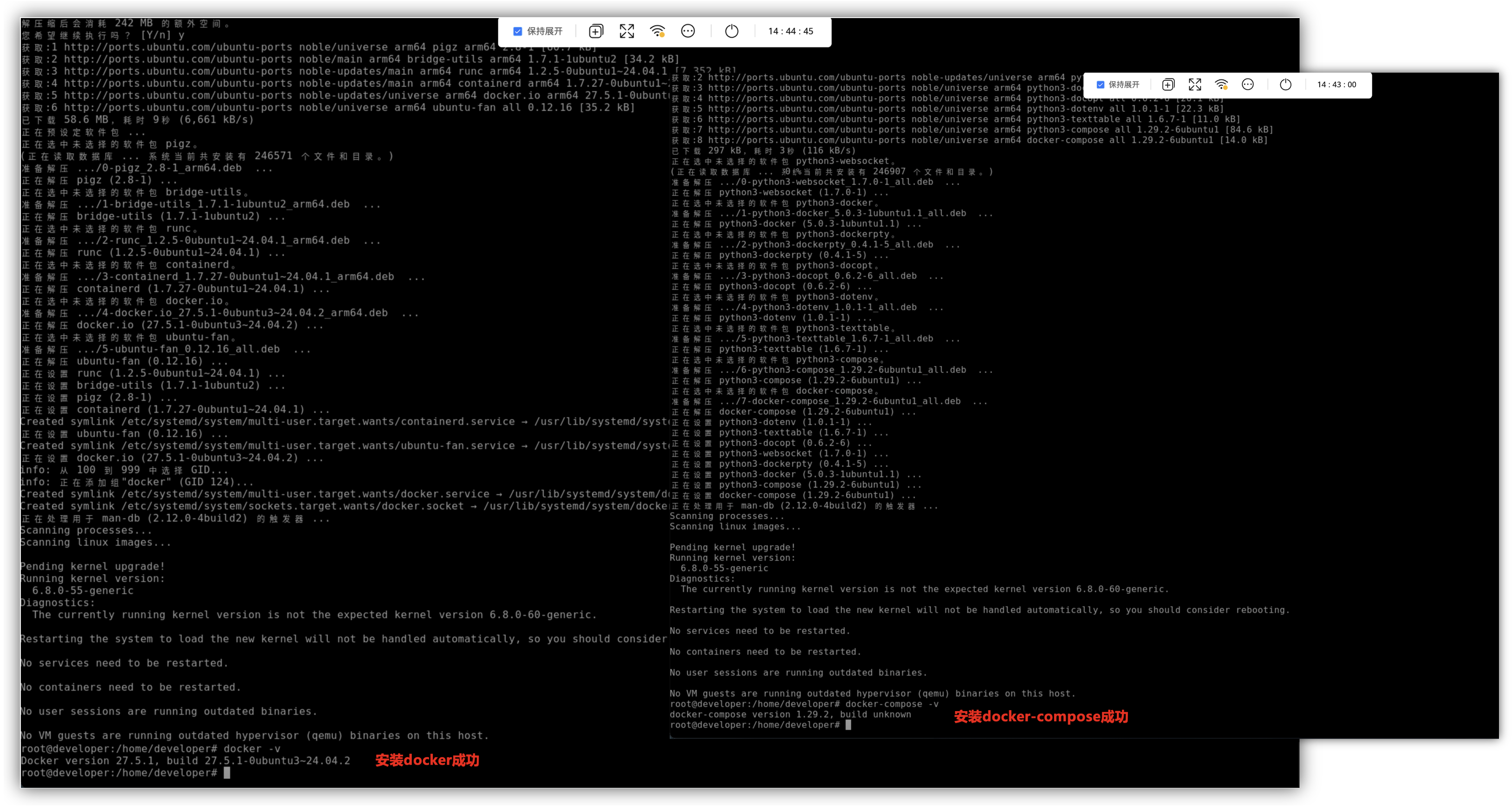
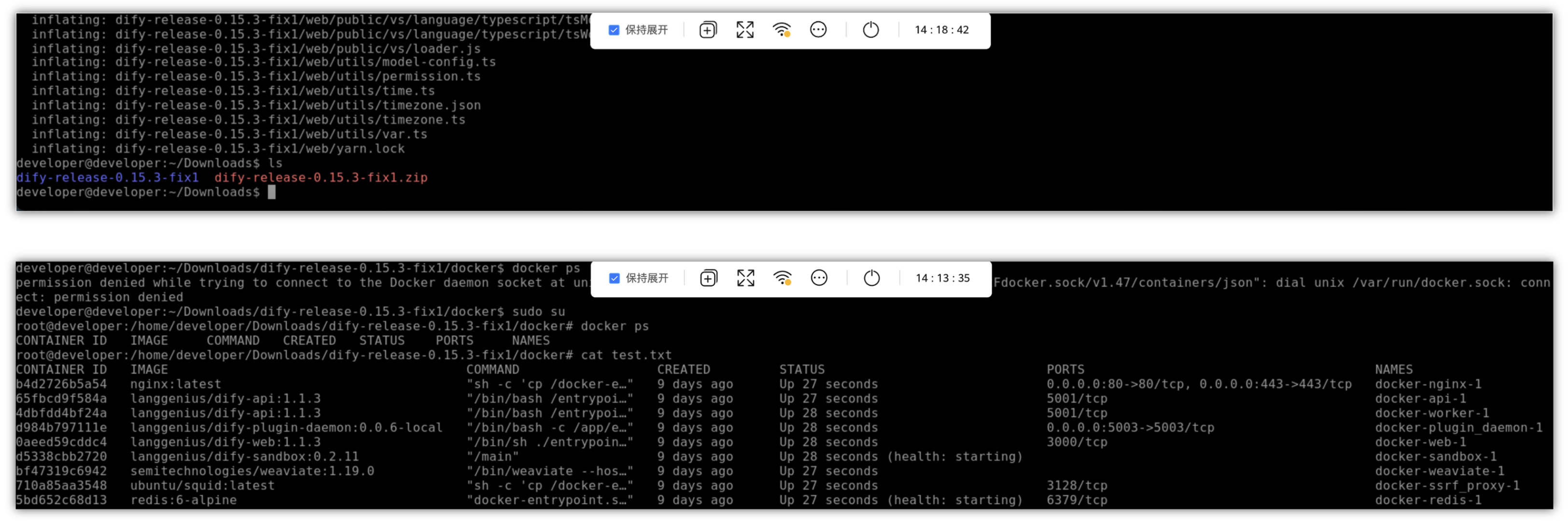
这里可以在Ubuntu系统中,直接安装docker和docker-compose,然后使用-v命令来查看是否安装成功,也可以直接配置一下加速器。
接下来我们下载dify的链接,可以提示fatal无法访问这个连接,提示“Couldn’t connent to server”,试了几次了都没法成功,那我只能在本地下载这个包下来,然后,上传到开发者云空间中,但是使用wget和curl等相关命令都不可以下载这个云空间的连接,我们只能通过“进入桌面”的方式,从火狐浏览器进行下载成功。
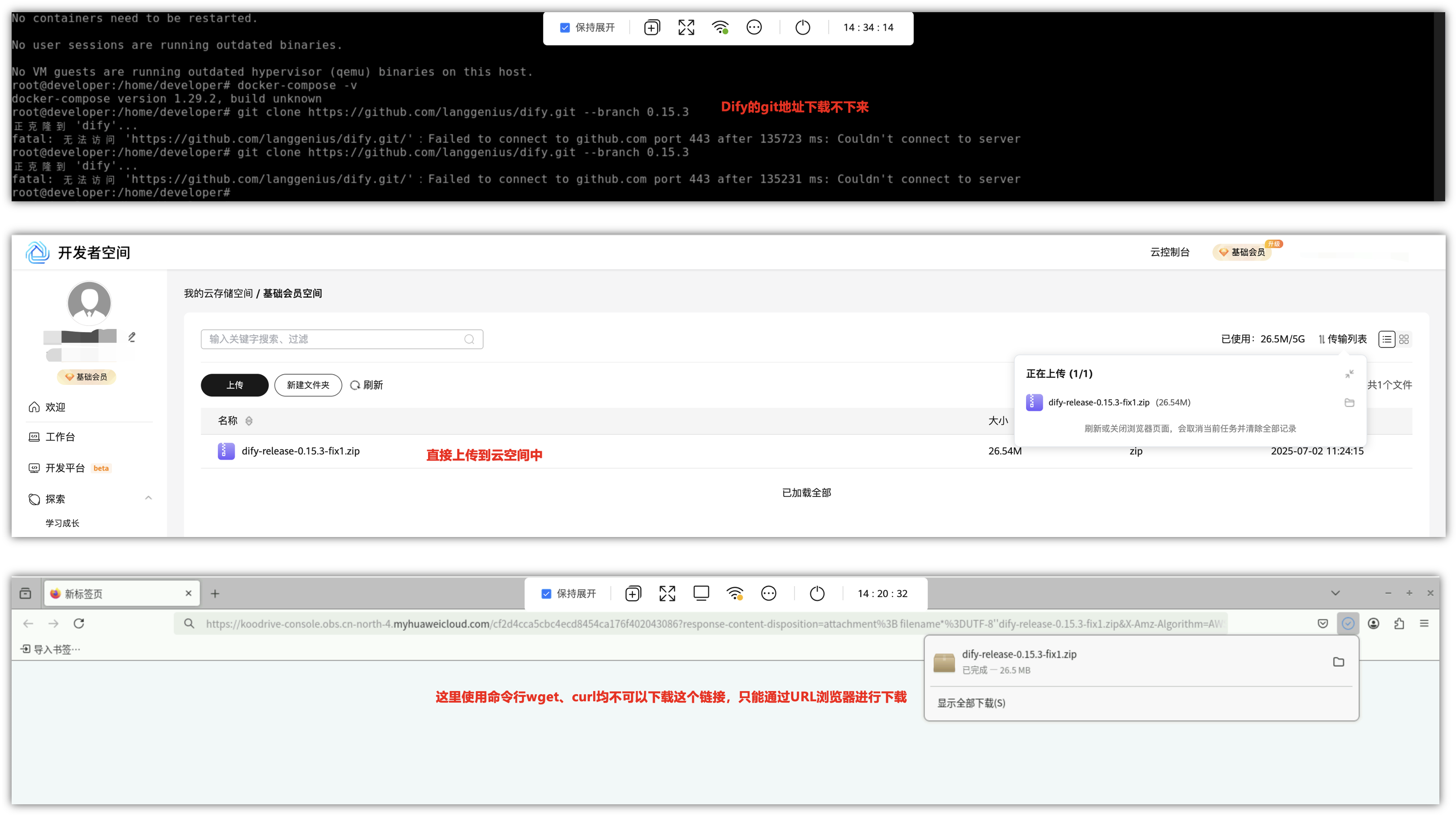
在火狐浏览器下载完成后,我们再切回到远程终端上,在Downloads目录下面进行解压,我们进入解压的目录中,再到docker目录下面执行docker-compose up -d命令即可下载镜像,最后就会全部起来起来,接下来,就可以使用Dify来进行使用了。
2.1 快速部署:一键搭建Dify平台:
使用华为云Flexus X服务器,用户可以通过官方提供的一键部署模板,轻松快速搭建Dify平台。整个部署流程包括模板选择、配置参数、资源栈设置与配置确认、创建计划任务等步骤,均可在可视化图形界面中完成,无需手动配置服务器环境或安装依赖。
Dify 是一个用于构建 AI 应用程序的开源平台。 Dify融合了后端即服务(Backend as Service)和LLMOps理念。它支持多种大型语言模型,如Claude3、OpenAI等,并与多个模型供应商合作,确保开发者能根据需求选择最适合的模型。 Dify通过提供强大的数据集管理功能、可视化的Prompt编排以及应用运营工具,大大降低了AI应用开发的复杂度。
2.2 初始配置与登录:
在上面完成自动化部署后,系统会自动配置并生成一个可访问的Web地址(URL),用户需要通过浏览器打开并访问Dify平台进行初始化,初次(第一次)需要进行管理员初始化登录后,即可开始配置和使用平台。
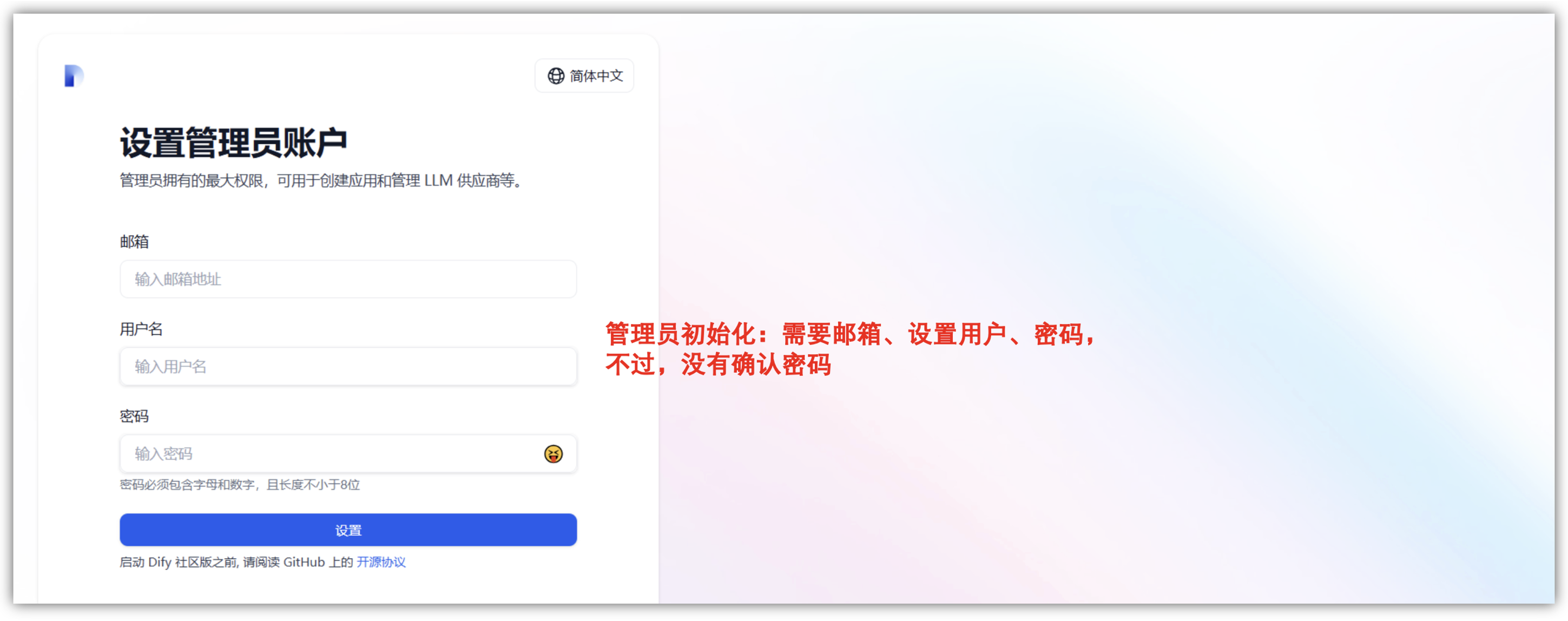
通过浏览器IP提供的Web访问链接来访问Dify - LLM 应用开发平台,第一次进来,需要进行初始化操作,设置管理员账户,需要邮箱、用户名、密码(这里没有确认密码)。
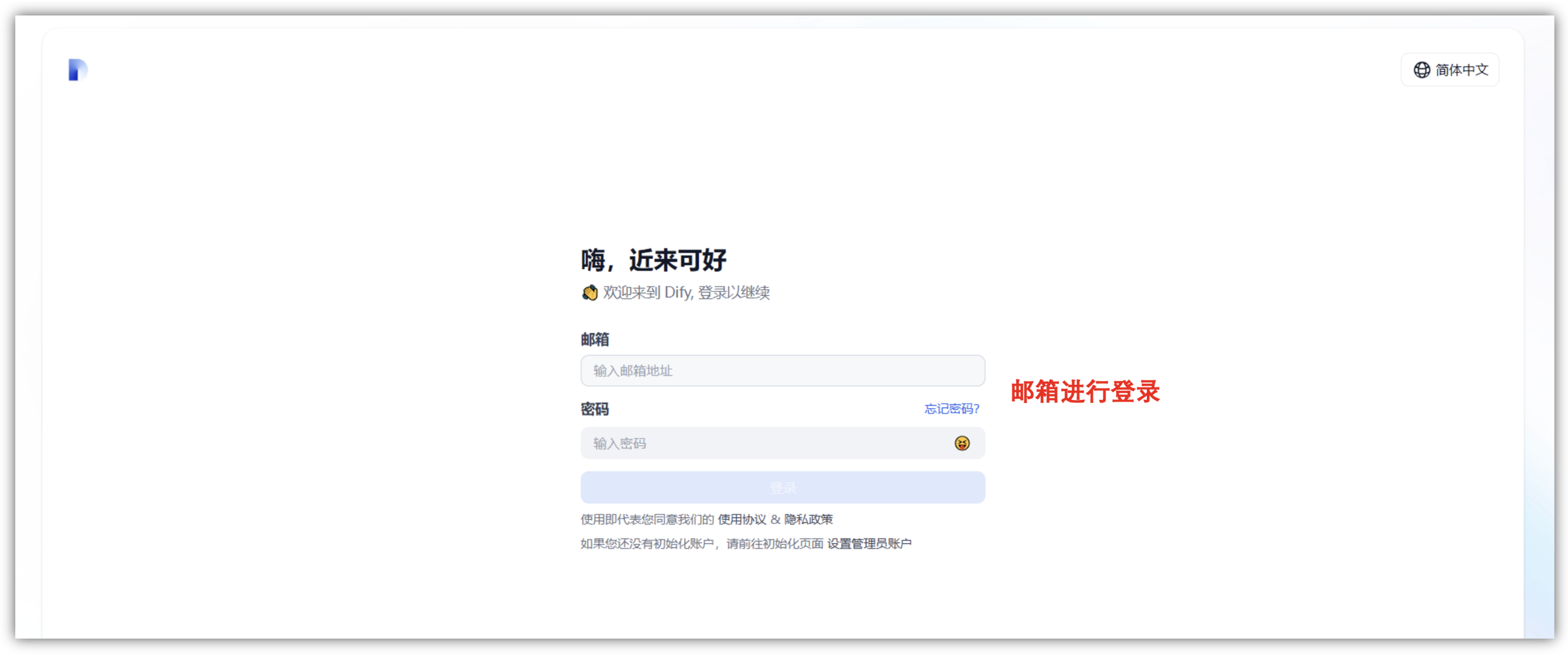
初始化完成后,我们可以使用邮箱和密码进行登录的操作,通过设置的管理员账户信息来登录,成功后会跳到一个首页页面,登录后显示如下页面,代表Dify - LLM 应用开发平台已经部署成功。
-
①. 多种大语言模型集成:
大模型厂商模型:仅需到大模型厂商注册账号,申请鉴权apikey,即可快速体验比较每个大模型厂商的优劣。
ModelArts Studio大模型即服务平台(后续简称为MaaS服务),提供了简单易用的模型开发工具链,支持大模型定制开发,让模型应用与业务系统无缝衔接,降低企业AI落地的成本与难度,这里推荐使用商用的DeepSeek-V3-32K、DeepSeek-R1-32K。 -
②. 丰富工具内置 + 自定义工具支持:
Dify内置了包含搜索引擎、天气预报、维基百科、SD等工具,同时自定义工具的配置化接入,团队成员一人接入,全组复用,高效。 -
③. 工作流:
只需连接各个节点,既能在几分钟内快速完成AI智能体创作,且逻辑非常清晰。 -
④. Agent 编排:
编写提示词,导入知识库,添加工具,选择模型,运行测试,发布为API。
2.3 配置 DeepSeek 大语言模型:
Dify - LLM 应用开发平台模型如何接入DeepSeek V3呢?打开右上角,进入最上面的“模型提供商”模块后,选择“OpenAi-API-compatible”选项。
找到DeepSeek模型供应商配置,打开对应的“OpenAI-API-compatible”供应商,这里需要选择模型的类型。
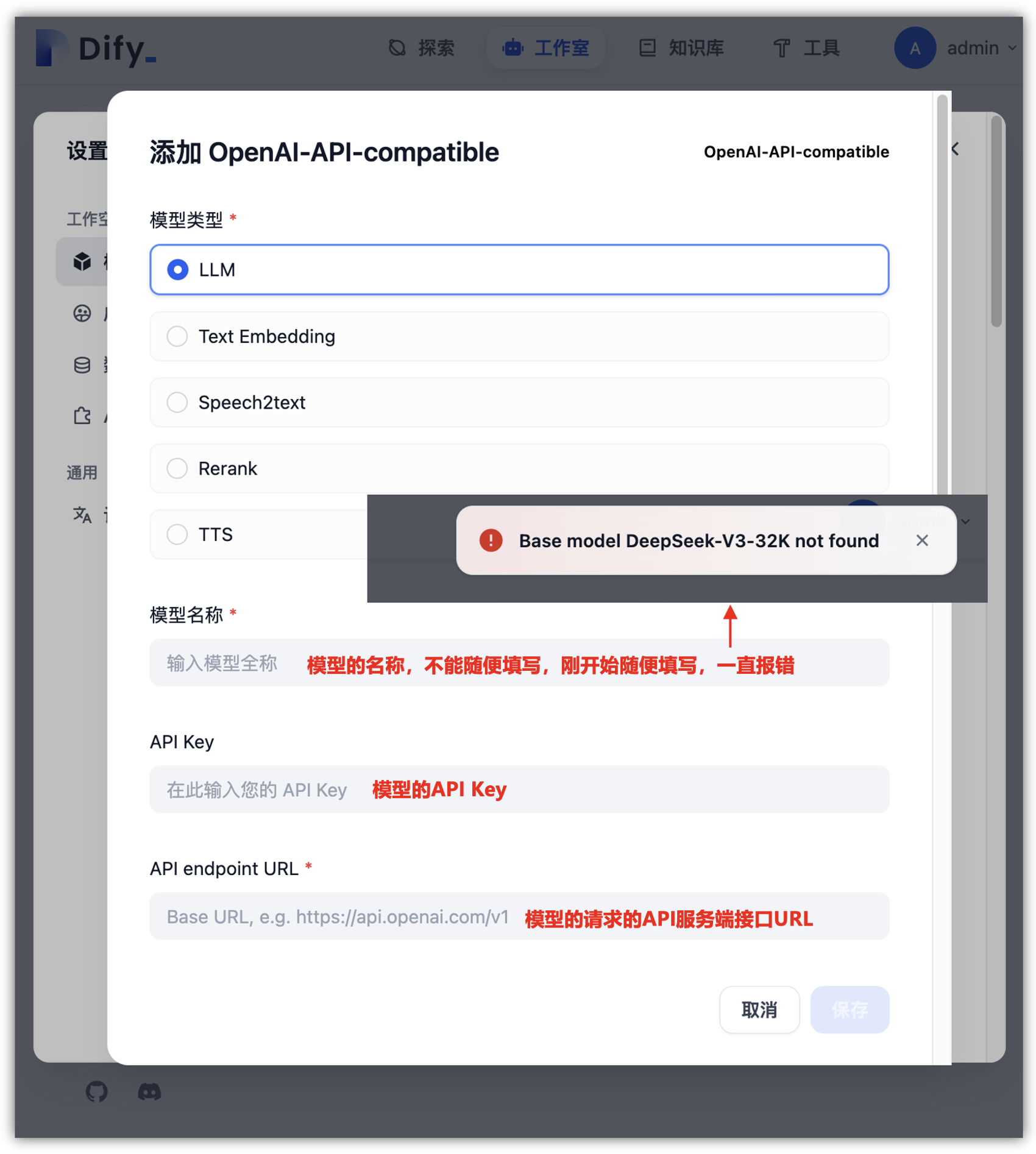
以下是基于查询的五大模型类型(LLM、Text Embedding、Speech2Text、Rerank、TTS)的详细说明,涵盖定义、核心特点和应用场景,综合整理自相关技术资料:
-
①. LLM(大语言模型):
-
定义:通过海量文本数据预训练的大型神经网络模型,具备自然语言理解与生成能力,支持对话、问答、写作等复杂任务。
- 特点:参数量庞大(通常百亿级以上),依赖高质量训练数据;可生成连贯文本,但存在“幻觉”(生成错误内容)风险。
- 应用:构建智能对话系统(如ChatGPT)、内容创作(文章、代码生成)、知识问答(结合RAG技术增强准确性)。 -
②. Text Embedding(文本嵌入模型):
- 定义:将文本转换为高维向量表示,保留语义信息以支持高效计算(如相似度匹配)。
- 特点:向量化处理提升检索速度;支持多语言和跨模态(文本/图像)应用;计算资源需求低于LLM。
- 应用:语义检索(文档相似度计算)、聚类分析与推荐系统、知识库增强检索(RAG流程的核心组件)。 -
③. Speech2Text(语音转文本模型):
- 定义:将语音信号实时转换为文本内容的技术,核心是语音识别。
- 特点:可处理音调、节奏等语音特征;支持离线/在线模式;对噪音环境敏感需优化。
- 应用:语音助手(智能音箱、电话机器人)、会议记录自动化、无障碍辅助工具(帮助听障人士交流)。 -
④. Rerank(重新排序模型):
- 定义:对初步检索结果进行上下文重排序,优化结果相关性及精度。
- 特点:结合用户意图与上下文;显著提升检索系统准确性;通常部署于LLM或搜索引擎后端。
- 应用:搜索引擎结果优化、问答系统答案排序(减少无关响应)、推荐系统个性化推送。 -
⑤. TTS(文本转语音模型):
- 定义:将文本输入转换为自然流畅的语音输出,模拟人类发音和情感。
- 特点:支持语调与情感控制;需平衡生成速度与音质;深度伪造风险需伦理约束。
- 应用:导航系统语音播报、有声读物与虚拟主播、客服机器人语音交互。
注:模型选择需结合实际需求——LLM侧重生成能力,Embedding/Rerank优化检索效率,Speech2Text/TTS赋能语音场景。
那在哪里可以获得这些模型的类型、 API 地址与API Key呢?
2.4 获取DeepSeek V3商用模型API Key密钥:
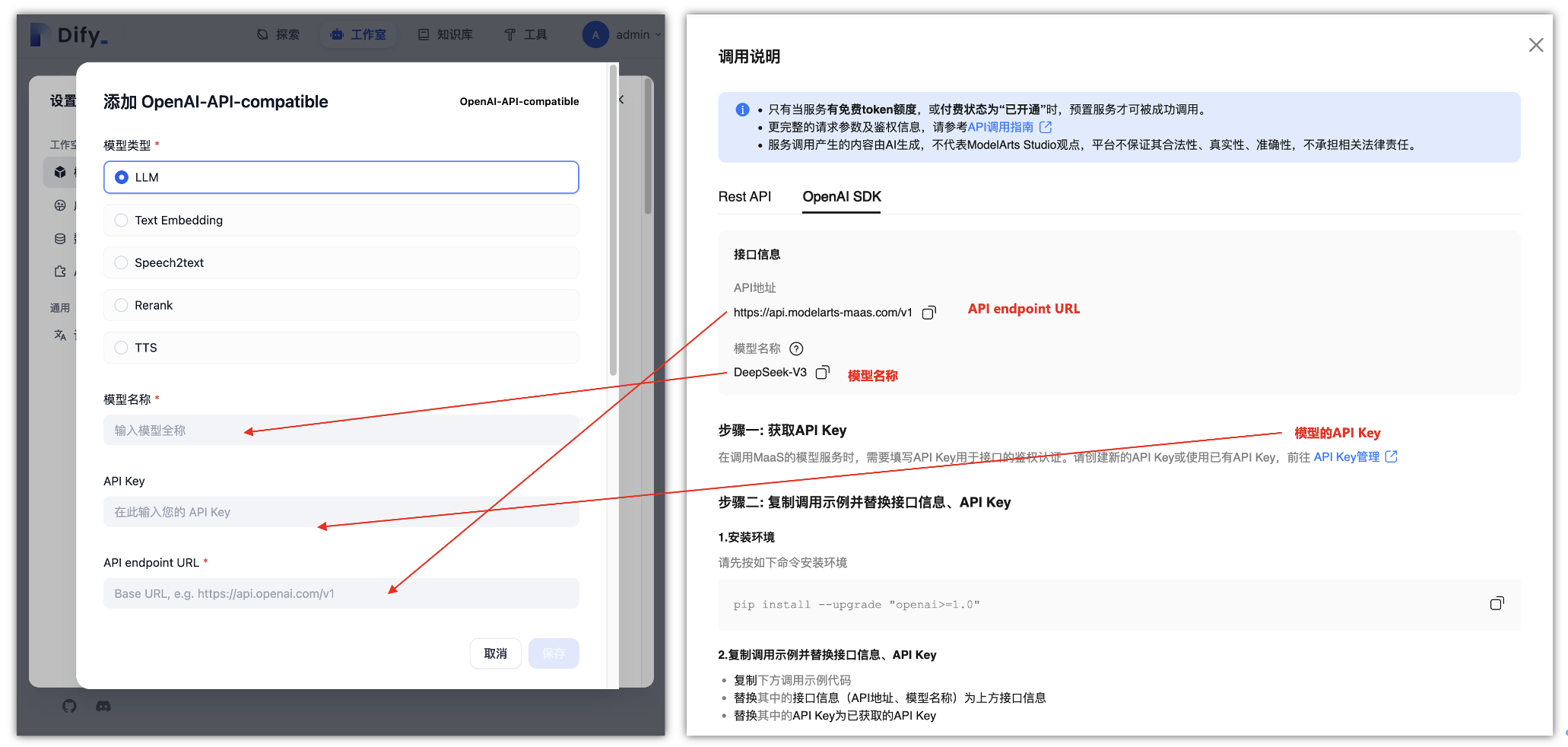
在“ModelArts Studio控制台”中,我们找到之前“在线推理”页面中开通的“DeepSeek V3商用模型”,在后面点击“调用说明”里面,找到“OpenAI SDK”选项卡中,找到下面有一个“API Key管理”,点击即可跳转到“API Key管理”页面。
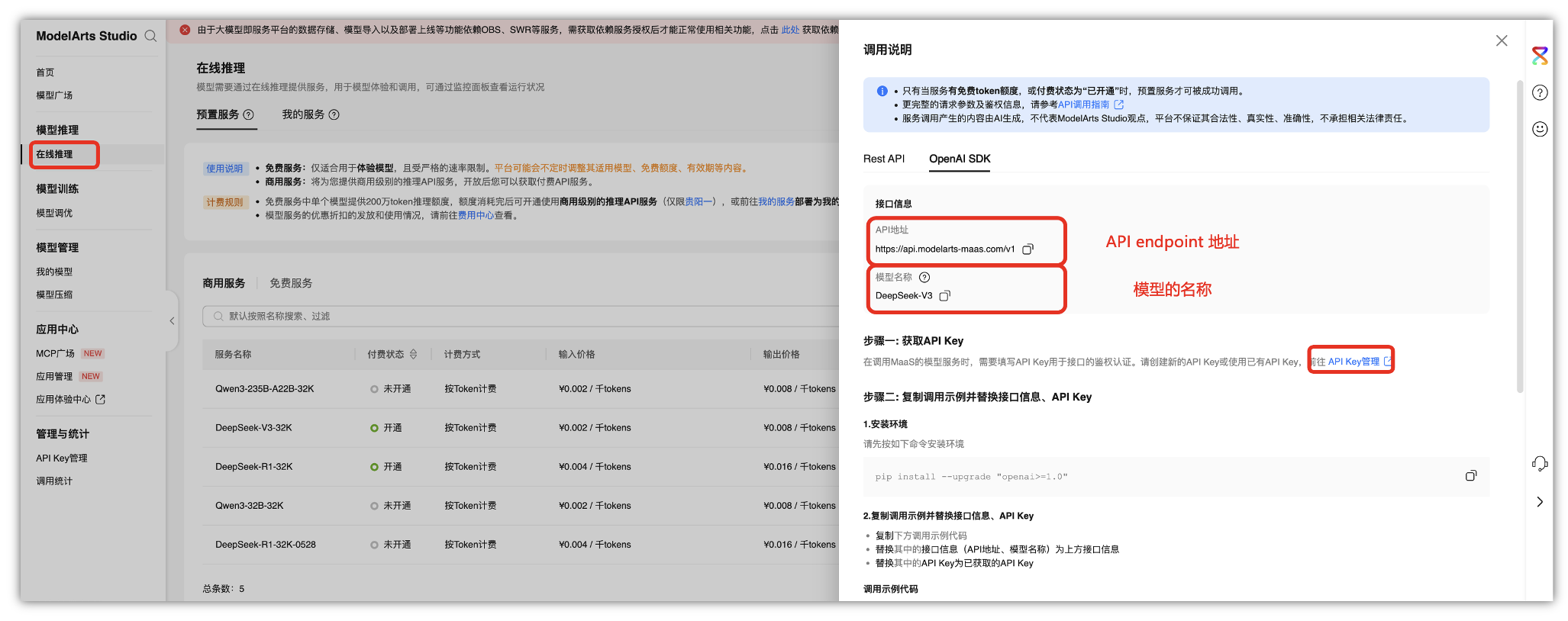
API endpoint 地址在上面打开“ModelArts Studio控制台”,点击在线推理,找到“OpenAI SDK”选项卡中,里面的接口信息即是获取自定义API endpoint 地址,点击OpenAI SDK复制API接口信息,这个就是API endpoint 地址,而下面的那个就是模型的名称。
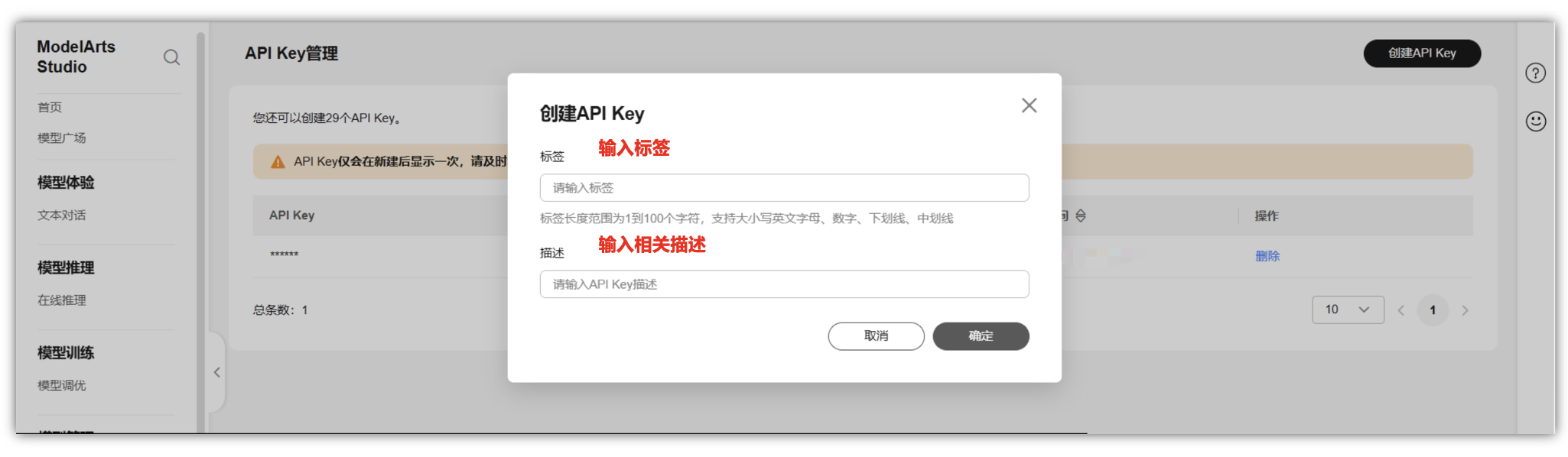
在“API Key管理”页面中,我们可以点击“创建API Key”进行添加API Key,这里需要注意一下,API Key仅在新建后显示一次,后面就不显示,只能重新创建一个。
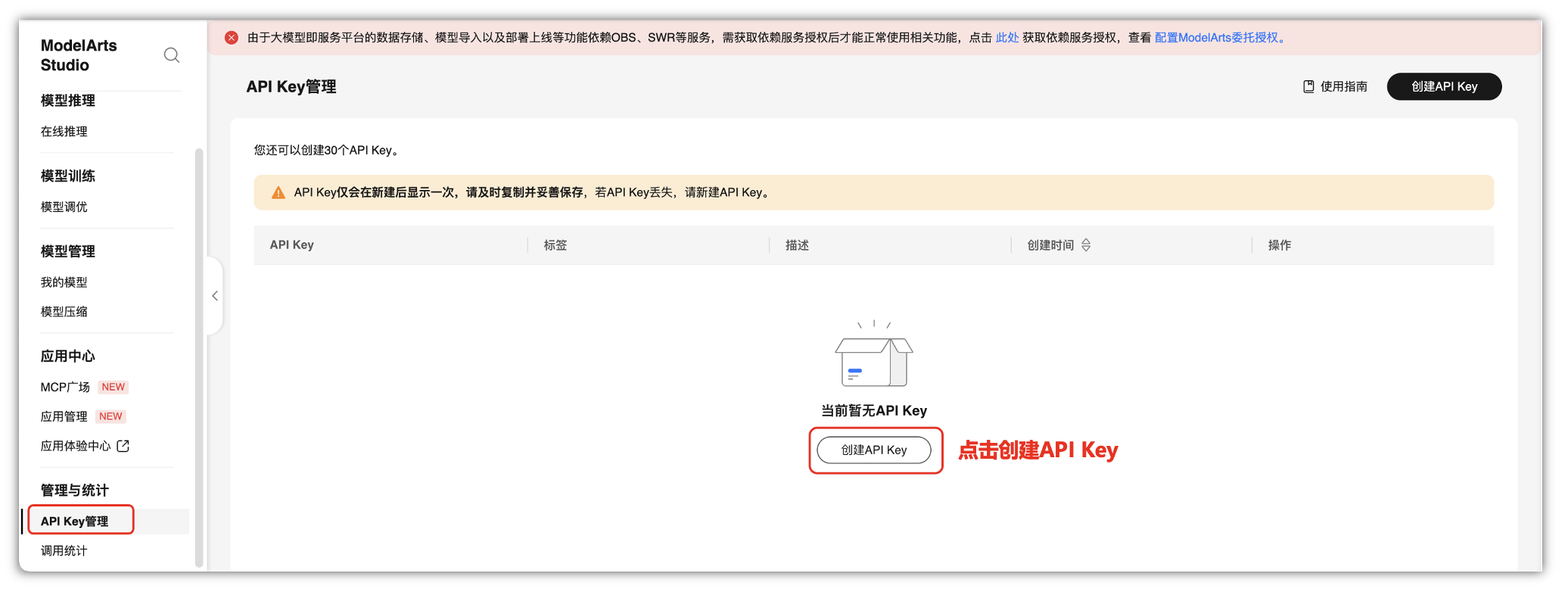
在弹出的创建弹框中,创建自己的API KEY,标签和描述根据自己的要求填写即可,这里只会显示一次自己的API KEY,所以,获取到自己的API KEY请注意保存好。
用户需要填写 DeepSeek V3 模型的类型、 API 地址与API Key,完成后保存配置,即可将该模型集成到 Dify 的应用工作流中,实现问答、摘要、生成等多种语言模型能力,Dify - LLM 应用开发平台填写获取到的API KEY和自定义 API endpoint 地址和模型名称。
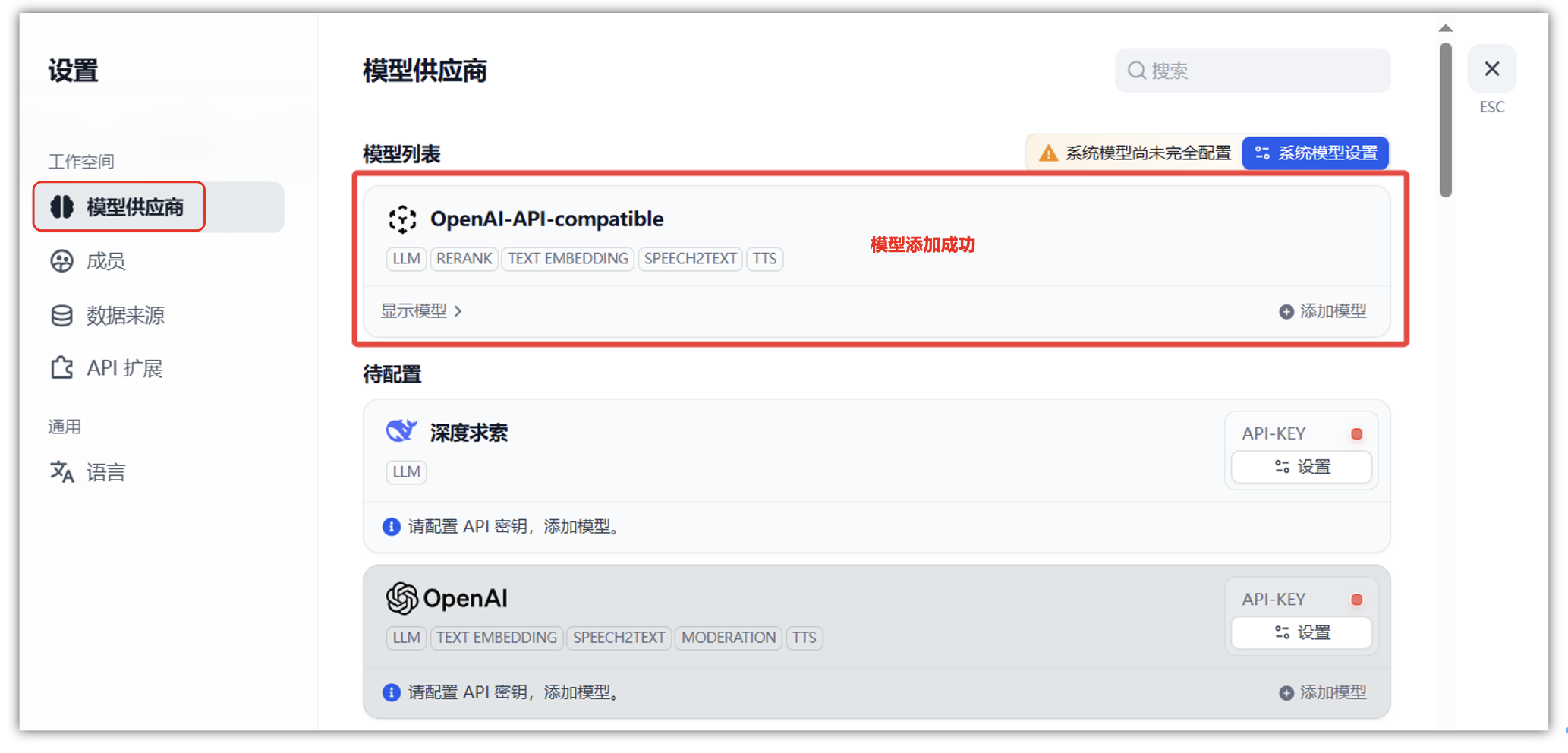
这里可以看到除 DeepSeek 外,平台还支持其它很多的主流大型的商用服务,比如: OpenAI、Azure、百川智能、通义千问等主流大模型服务,可以满足不同企业与个人开发者的个性化的接入需求。
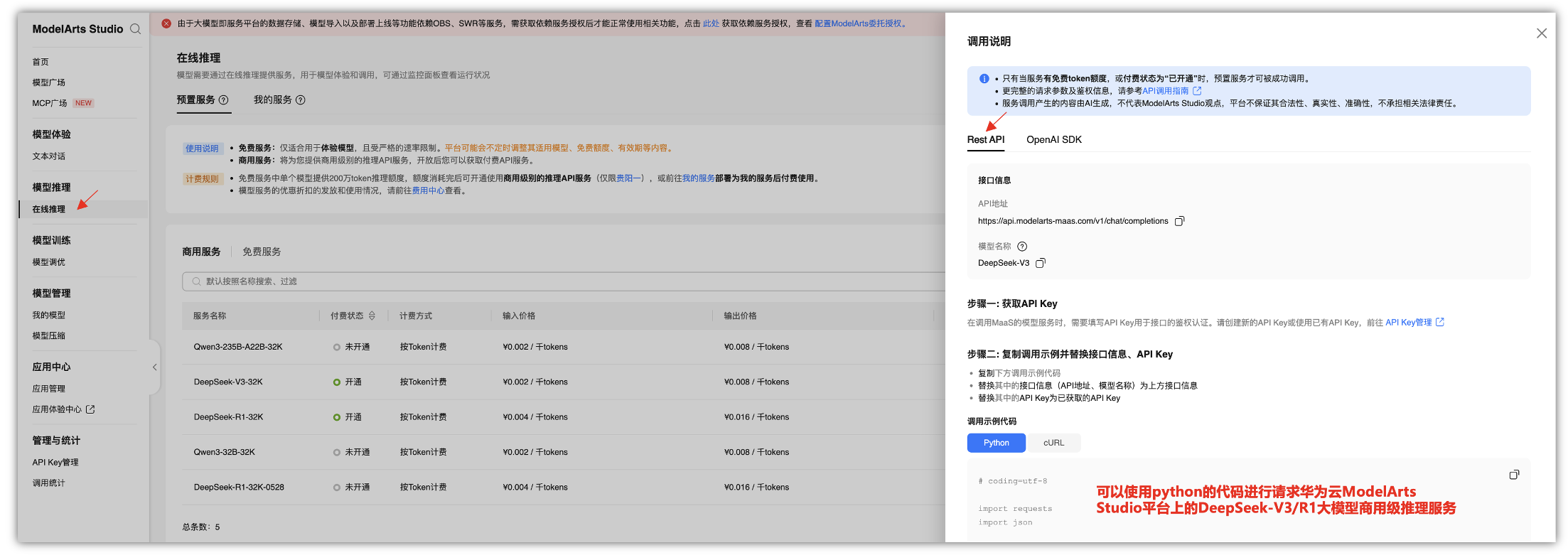
2.5 如何在自己的业务系统中进行使用呢?
在ModelArts Studio大模型即服务平台(后续简称为MaaS服务),提供了简单易用的模型开发工具链,支持大模型定制开发,让模型应用与业务系统无缝衔接,创建并部署一个模型服务,实现对话问答。可以快速了解如何在MaaS服务上与自己的业务系统进行快速对接。
# coding=utf-8
import requests
import json
if __name__ == '__main__':
url = "https://api.modelarts-maas.com/v1/chat/completions" # API地址
api_key = "yourApiKey" # 把yourApiKey替换成已获取的API Key
# Send request.
headers = {
'Content-Type': 'application/json',
'Authorization': f'Bearer {api_key}'
}
data = {
"model":"DeepSeek-V3", # 模型名称
"messages": [
{"role": "system", "content": "You are a helpful assistant."},
{"role": "user", "content": "你好"}
],
# 是否开启流式推理, 默认为False, 表示不开启流式推理
"stream": True,
# 在流式输出时是否展示使用的token数目。只有当stream为True时改参数才会生效。
# "stream_options": { "include_usage": True },
# 控制采样随机性的浮点数,值较低时模型更具确定性,值较高时模型更具创造性。"0"表示贪婪取样。默认为0.6。
"temperature": 0.6
}
response = requests.post(url, headers=headers, data=json.dumps(data), verify=False)
# Print result.
print(response.status_code)
print(response.text)
首先本地进行安装一下python环境,这里就不进行演示了,可以自行问一下DeepSeek,刚好可以使用“华为云ModelArts Studio平台上的DeepSeek-V3/R1大模型商用级推理服务”的在线体验功能再来学以致用。
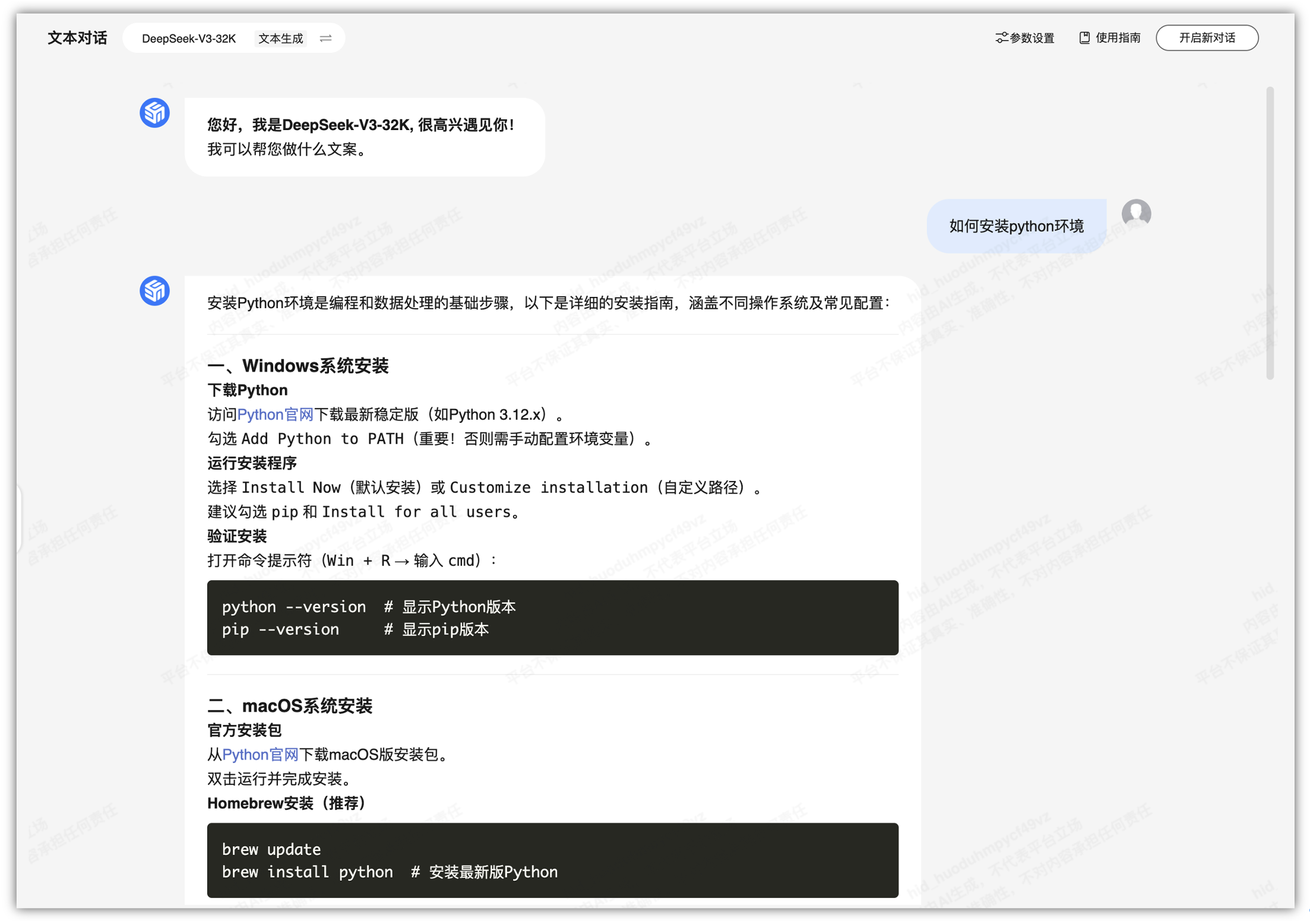
不过在执行的过程中,提示我有一个python错误,我也不太明白是啥意思,还是使用“华为云ModelArts Studio平台上的DeepSeek-V3/R1大模型商用级推理服务”的在线体验来搜索一下。
/Library/Python/3.8/site-packages/urllib3/__init__.py:35: NotOpenSSLWarning: urllib3 v2 only supports OpenSSL 1.1.1+, currently the 'ssl' module is compiled with 'LibreSSL 2.8.3'. See: https://github.com/urllib3/urllib3/issues/3020
warnings.warn(
/Library/Python/3.8/site-packages/urllib3/connectionpool.py:1099: InsecureRequestWarning: Unverified HTTPS request is being made to host 'api.modelarts-maas.com'. Adding certificate verification is strongly advised. See: https://urllib3.readthedocs.io/en/latest/advanced-usage.html#tls-warnings
warnings.warn(
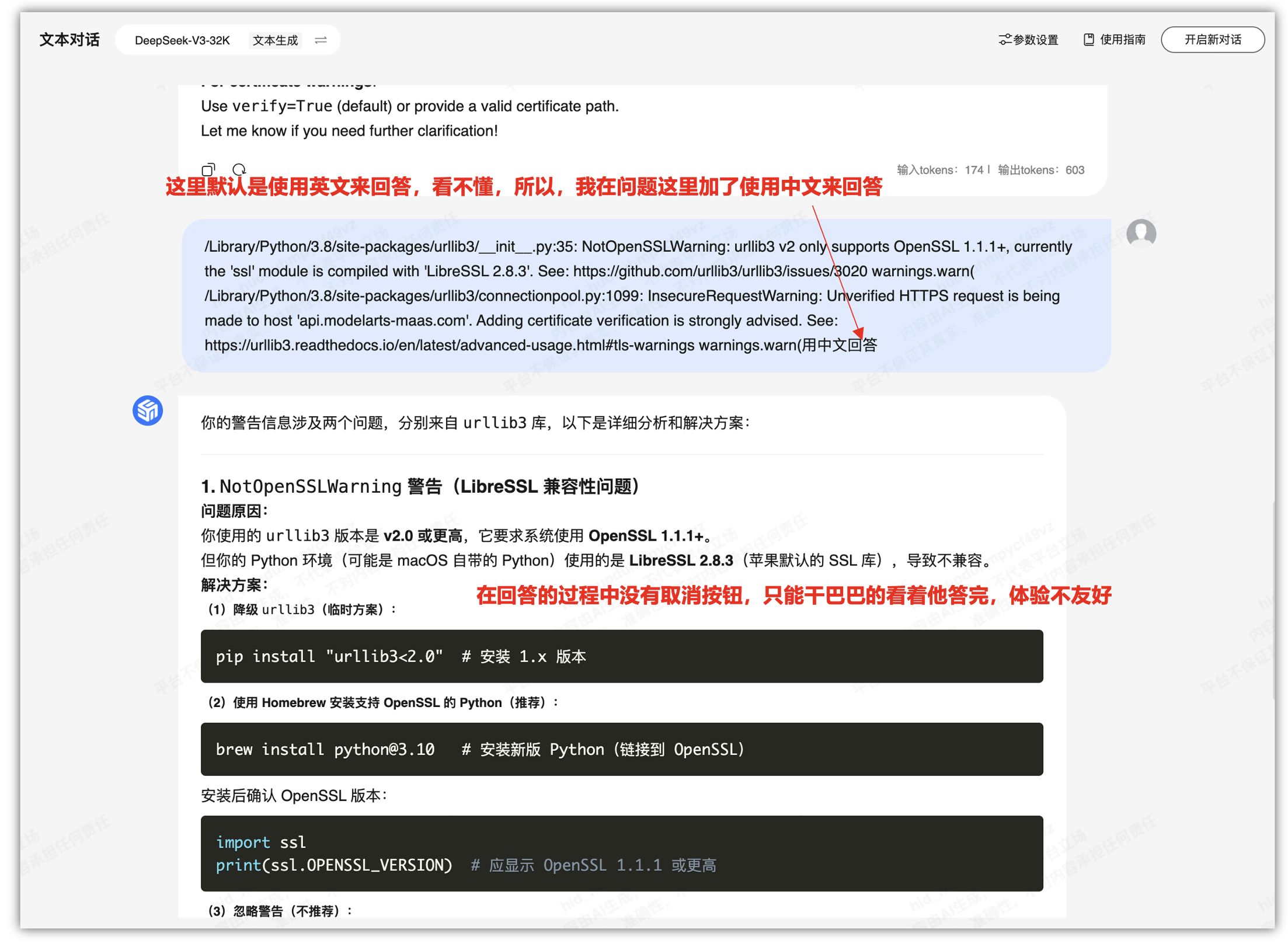
这里默认是使用英文来回答,看不懂,所以,我在问题这里加了使用中文来回答,另外在在回答的过程中没有取消按钮,只能干巴巴的看着他答完,体验不友好。
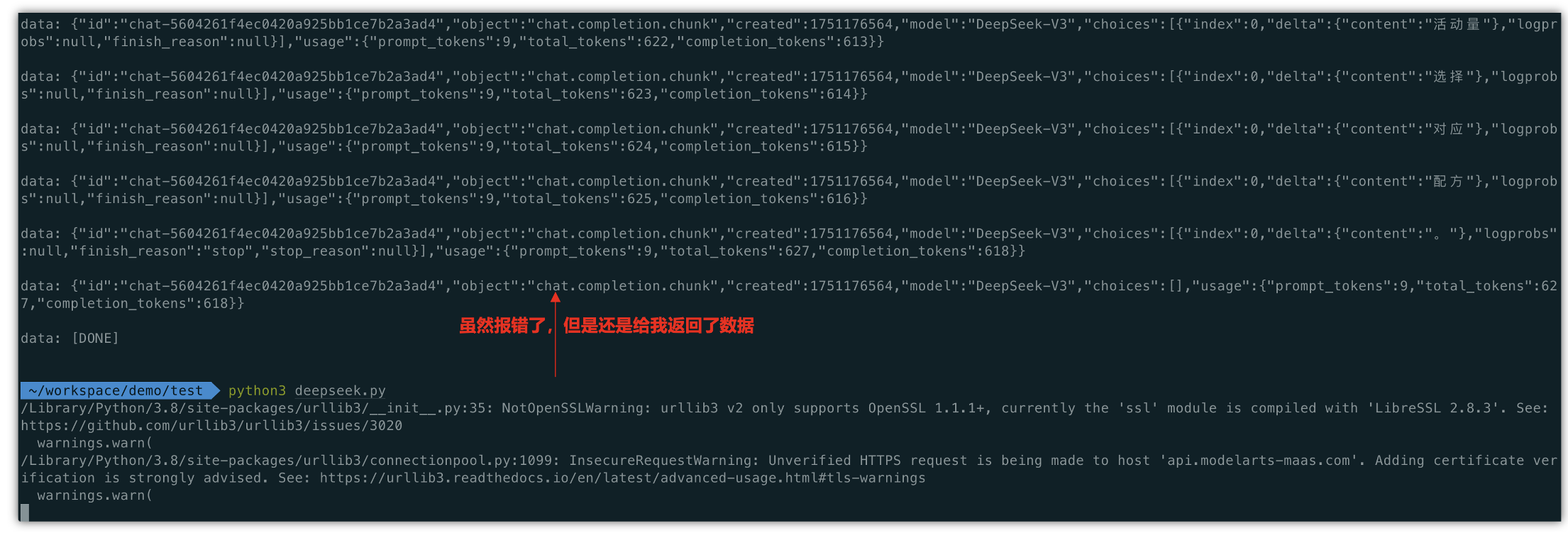
三、基于Dify平台如何进行构建知识库 + RAG:
dify提供了一套完整的使用工具,包括LLM大语言模型,RAG,以及自定义工具,就类似一个超级大脑,可以整合各个功能,同时LLM充当了大脑的核心,用于调度各个资源。
如何将文档上传到Dify知识库构建RAG?将文档上传到Dify知识库的过程涉及多个步骤,从文件选择、预处理、索引模式选择到检索设置,旨在构建一个高效、智能的知识检索系统。
首先,在“知识库”选项卡中,创建知识库时,即可导入自己的文本数据或通过webhook实时写入数据以增强LLM的上下文,这里我们可以通过上传文档的方式添加内容。
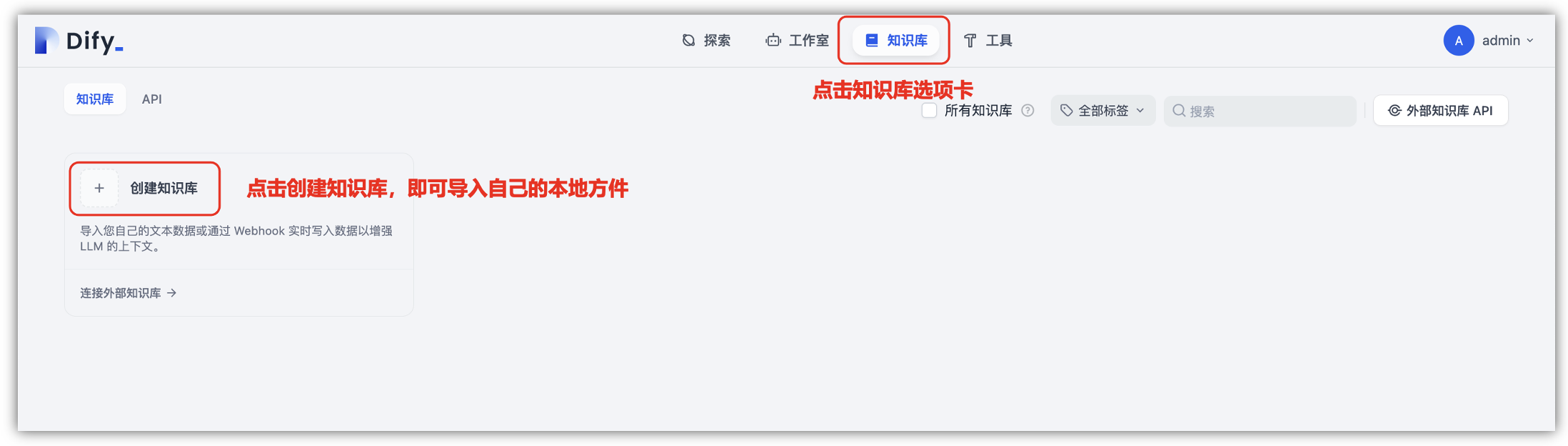
- ①. 创建新知识库:拖放或选择要上传的文件,支持批量上传,单个文件大小限制在15M。
- ②. 空知识库选项:如果尚未准备文档,可选择创建空知识库。
- ③. 外部数据源:使用外部数据源(如Notion、Webhook页面内容)时,建议为每个数据源创建单独知识库。
Dify平台自带知识库模块,这里一共有3种方式来进行导入,在“知识库”模块中,支持上传TXT、MARKDOWN、PDF、HTML、XLSX、XLS、DOCX、CSV等10多种常见的主流文档格式,另外可以通过网页的URL来进行获取上下文信息。
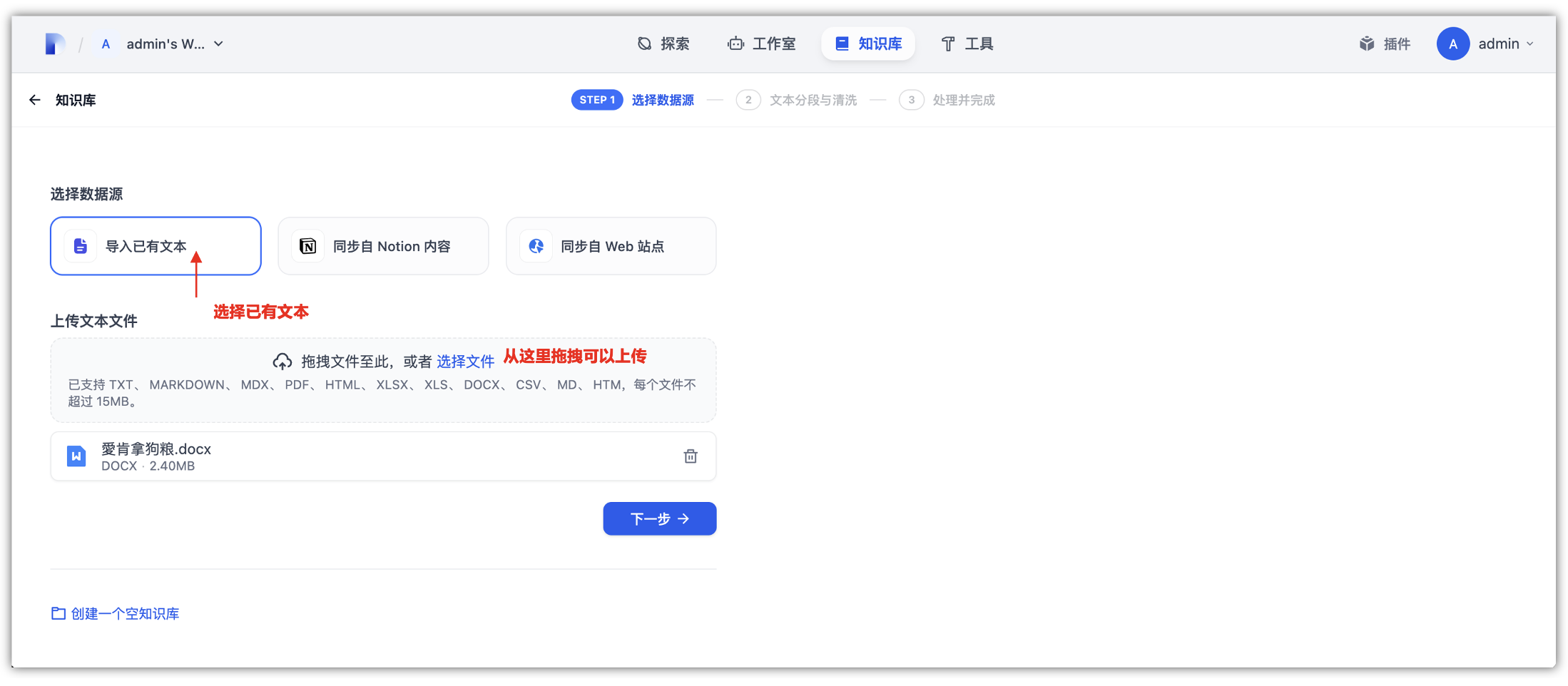
如果是本地上传的文件都会上传到之前部署在华为云挂载的OBS 对象存储桶中,这样就可以实现华为云云端文档集中管理,方便后续数据迁移、或者多节点环境中的文件同步与调用。
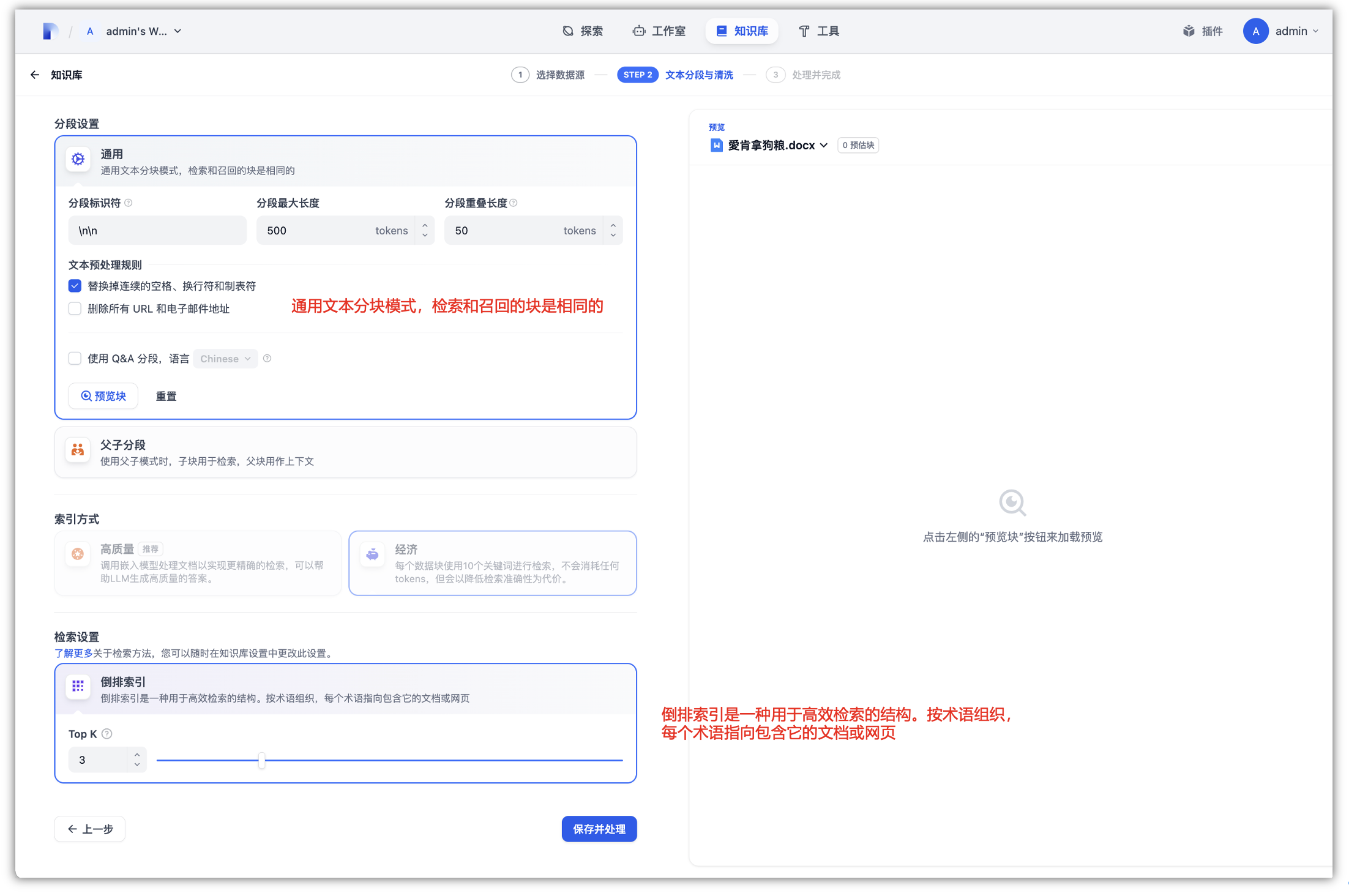
内容上传到知识库之后,会经过文本预处理与清理,需要进行分块和数据清洗,这个阶段可以理解为内容的预处理和结构化。平台将自动完成文本提取、内容切分、向量化处理,并展示文档嵌入与索引状态,以便后续在对话过程中可以进行精确检索上下文内容。
- ①. 自动模式:Dify自动分割和清理内容,简化文档准备流程。
- ②. 自定义模式:对于需要更精细控制的情况,可选择自定义模式进行手动调整。
索引模式:根据应用场景选择合适的索引模式,如高质量模式、经济模式或问答模式:
- ①. 高质量模式:利用Embedding模型将文本转换为数值向量,支持向量检索、全文检索和混合检索。
- ②. 经济模式:采用离线向量引擎和关键字索引,准确率会有所降低,但是会省去了额外的 token 消耗和相关成本。
- ③. 问答模式:系统会进行文本分词,并通过摘要的方式,为每段生成QA问答对。
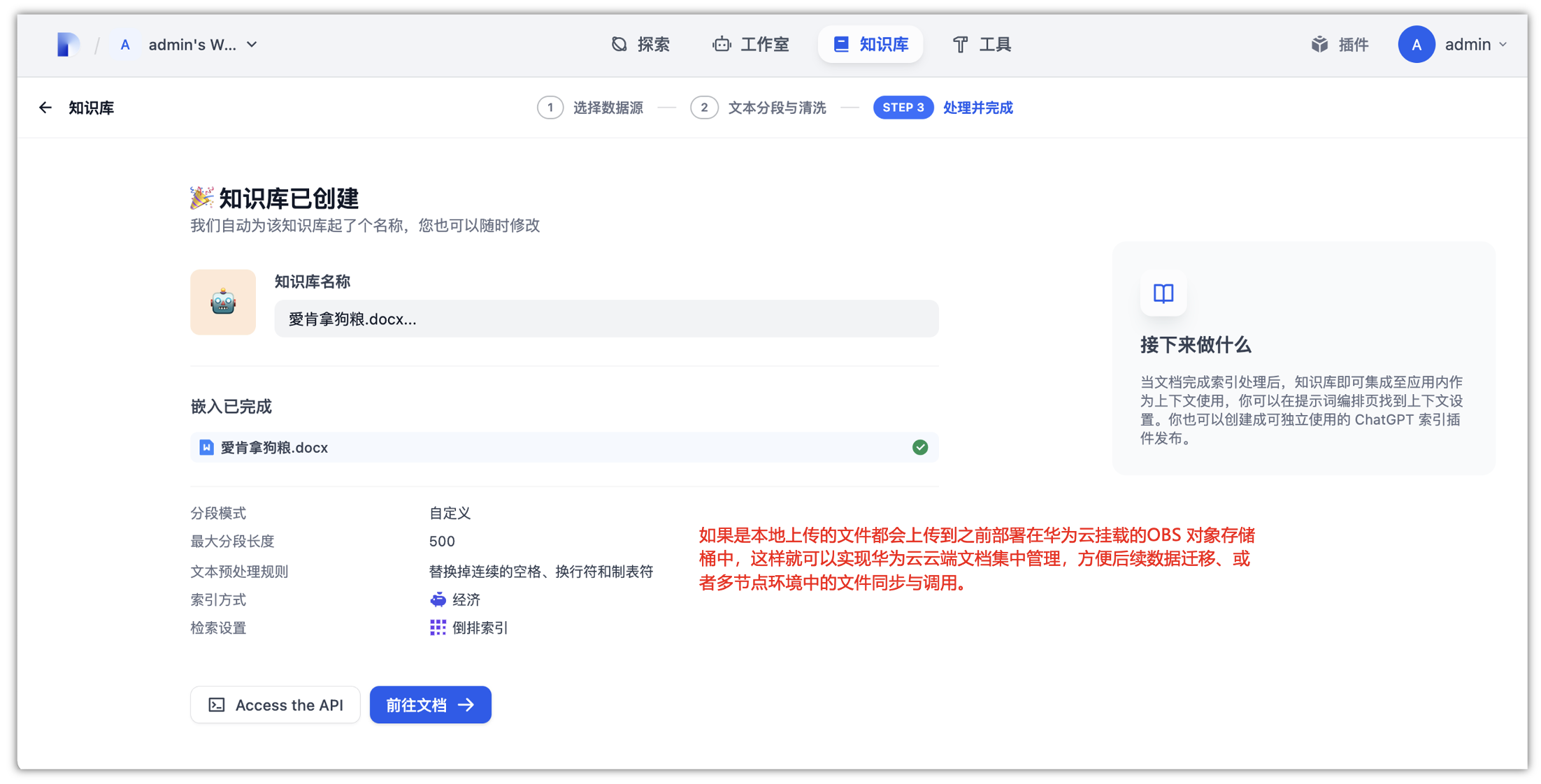
当文档完成索引处理后,知识库即可集成至应用内作为上下文使用,你可以在提示词编排页找到上下文设置。你也可以创建成可独立使用的 ChatGPT 索引插件发布。
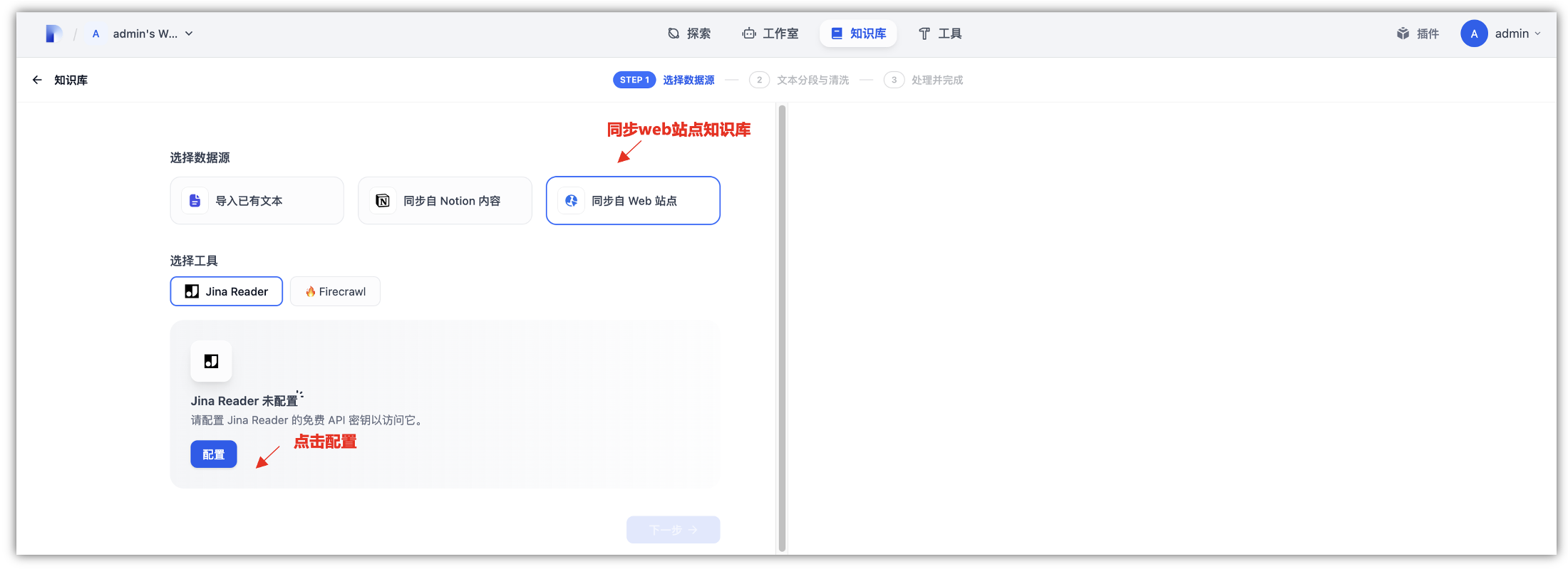
4.2 Jina Reader知识库集成:
知识库可以作为外部知识提供给大语言模型用于精确回复用户问题,可以在 Dify 的所有应用类型内关联已创建的知识库。
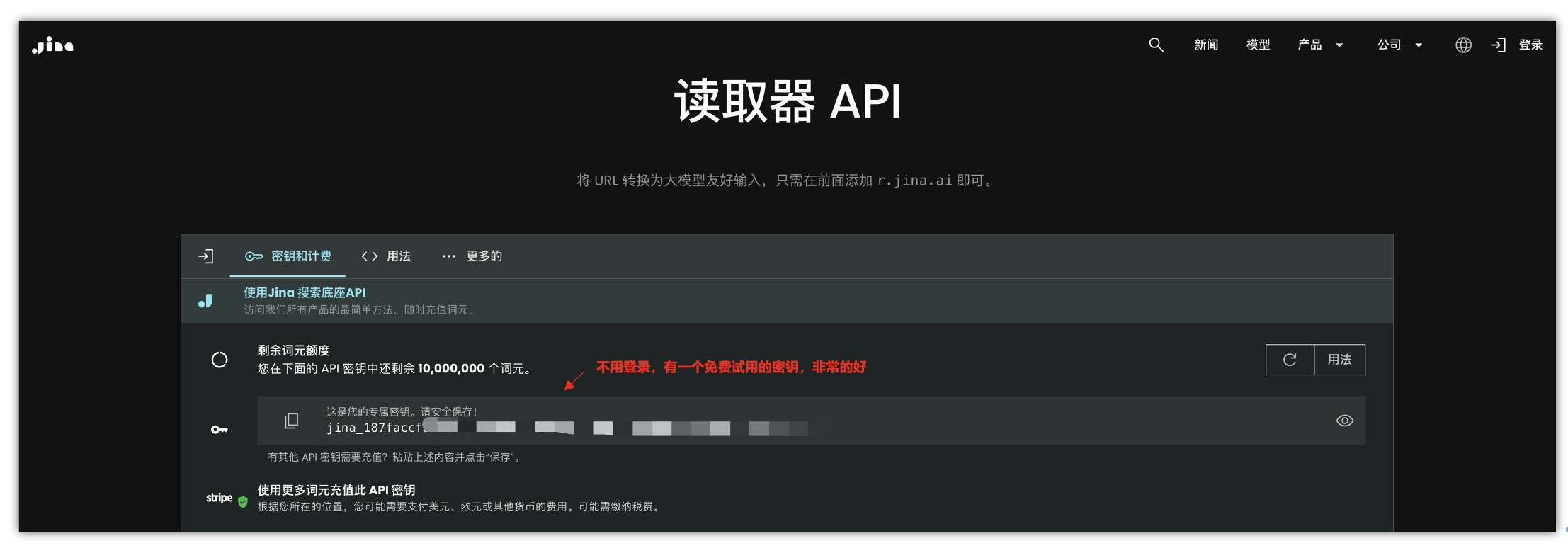
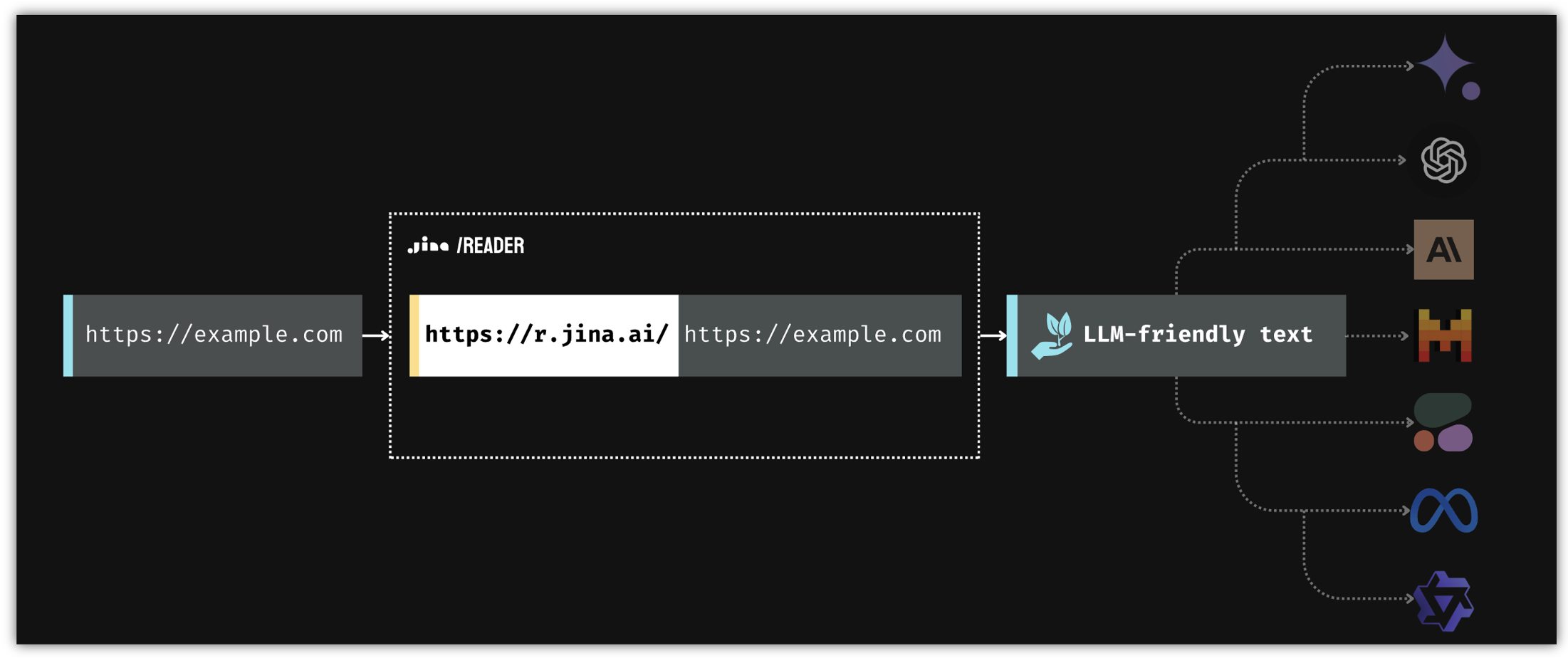
Jina ReaderLM v2是从 HTML 到 Markdown 和 JSON 的小型语言模型,ReaderLM-v2 是一个 1.5B 参数语言模型,专门用于 HTML 到 Markdown 的转换和 HTML 到 JSON 的提取。它支持 29 种语言中多达 512K 个词元的文档,准确率比其前身高 20%。
将网络信息输入大模型是打好基础的重要一步,但这可能很有挑战性。最简单的方法是抓取网页并输入原始 HTML。但是,抓取可能很复杂且经常受阻,而且原始 HTML 中充斥着标记和脚本等无关元素。
读取器 API 通过从 URL 中提取核心内容并将其转换为干净的、大模型友好的文本来解决这些问题,从而确保为您的Agent和 RAG 系统提供高质量的输入。
Reader 可用作 SERP API。它允许您将搜索结果引擎页面背后的内容提供给您的 LLM,Reader 就会搜索网络并返回前五个结果及其 URL 和内容,每个结果都以干净、LLM 友好的文本显示,在数据来源中,添加Jina Reader提供的密钥文件添加。
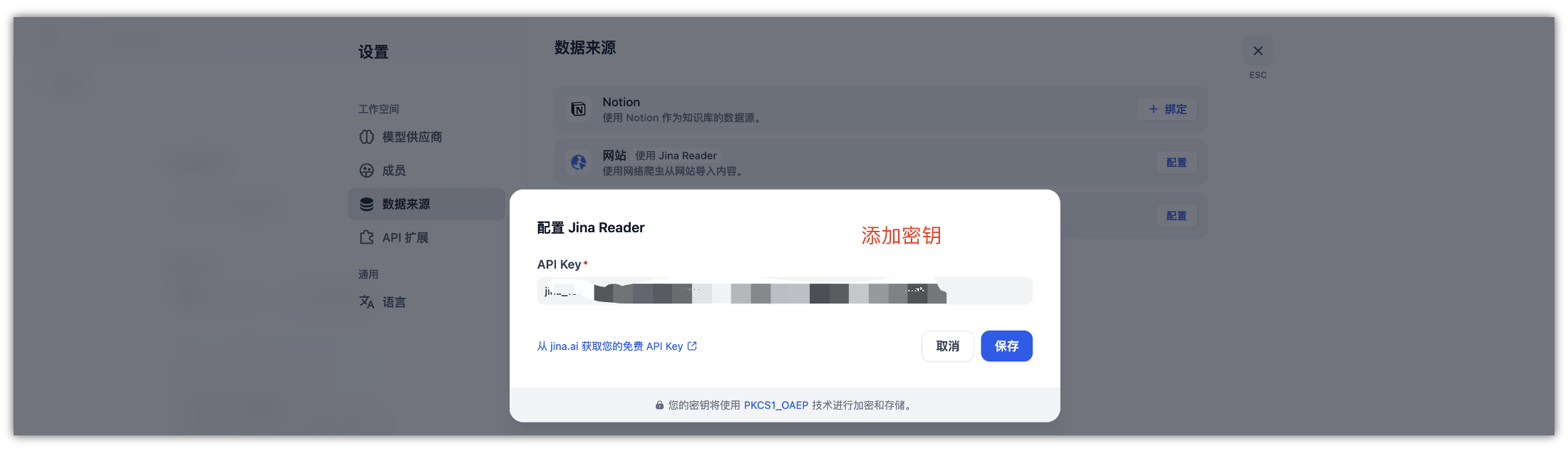
网页上的图片会使用读取器中的视觉语言模型自动添加标题,并在输出中格式化为图片 alt 标签。这为下游大模型提供了足够的提示,以将这些图片纳入其推理和总结过程,添加成功Jian Reader后,我们就可以进行同步来自web站点的知识库了,将网页的链接放到下面,运行即可得到需要查询的页面。
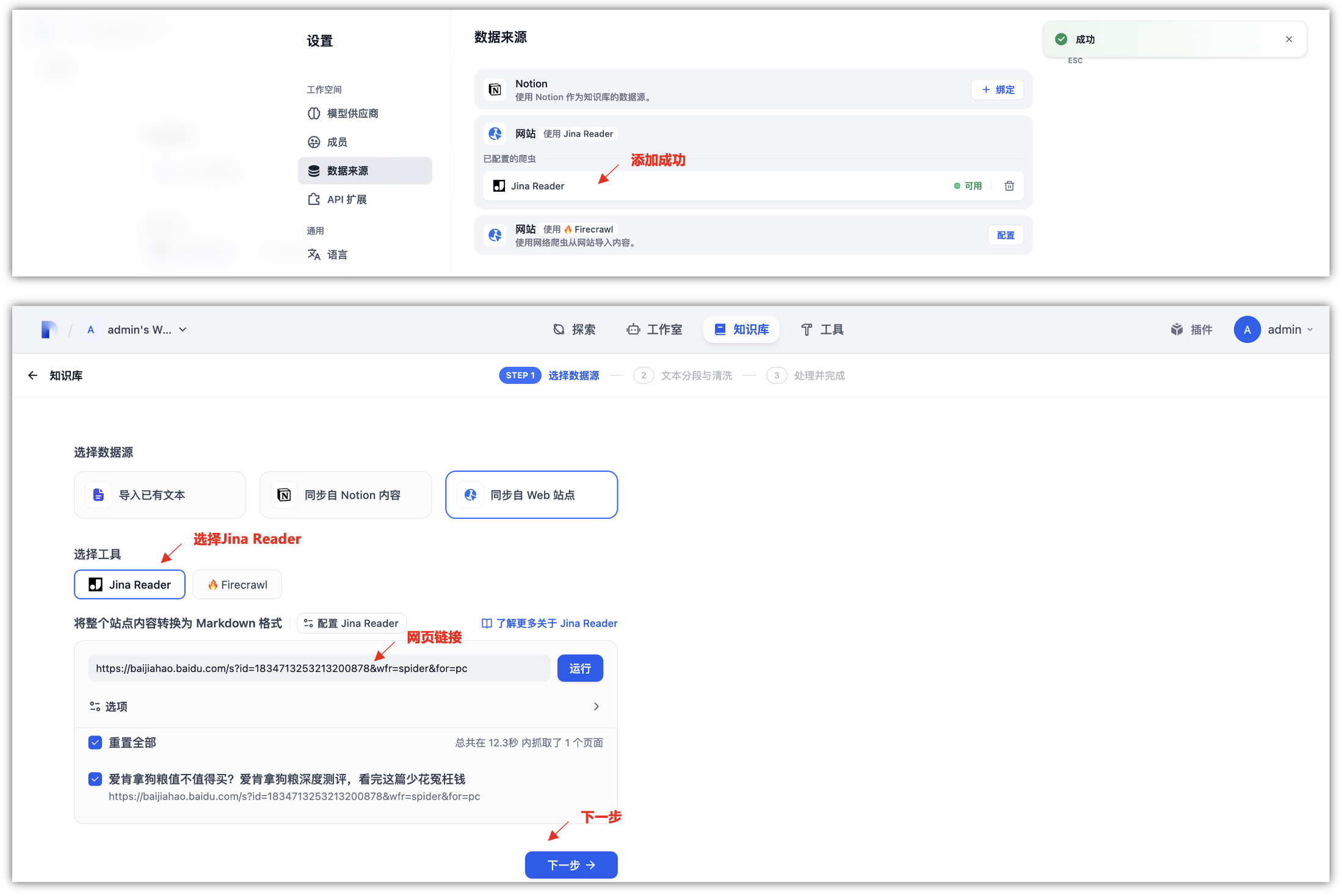
上面可以选择是否关键子页面,如果有这样的需求可以勾选,只是这一个页面的话,就进行下一步,可以看到几秒钟后,就会把这个网页的内容解析成功,并加入到知识库中,当然,知识库名称可以自己修改一下,默认是这个网页面的链接地址。
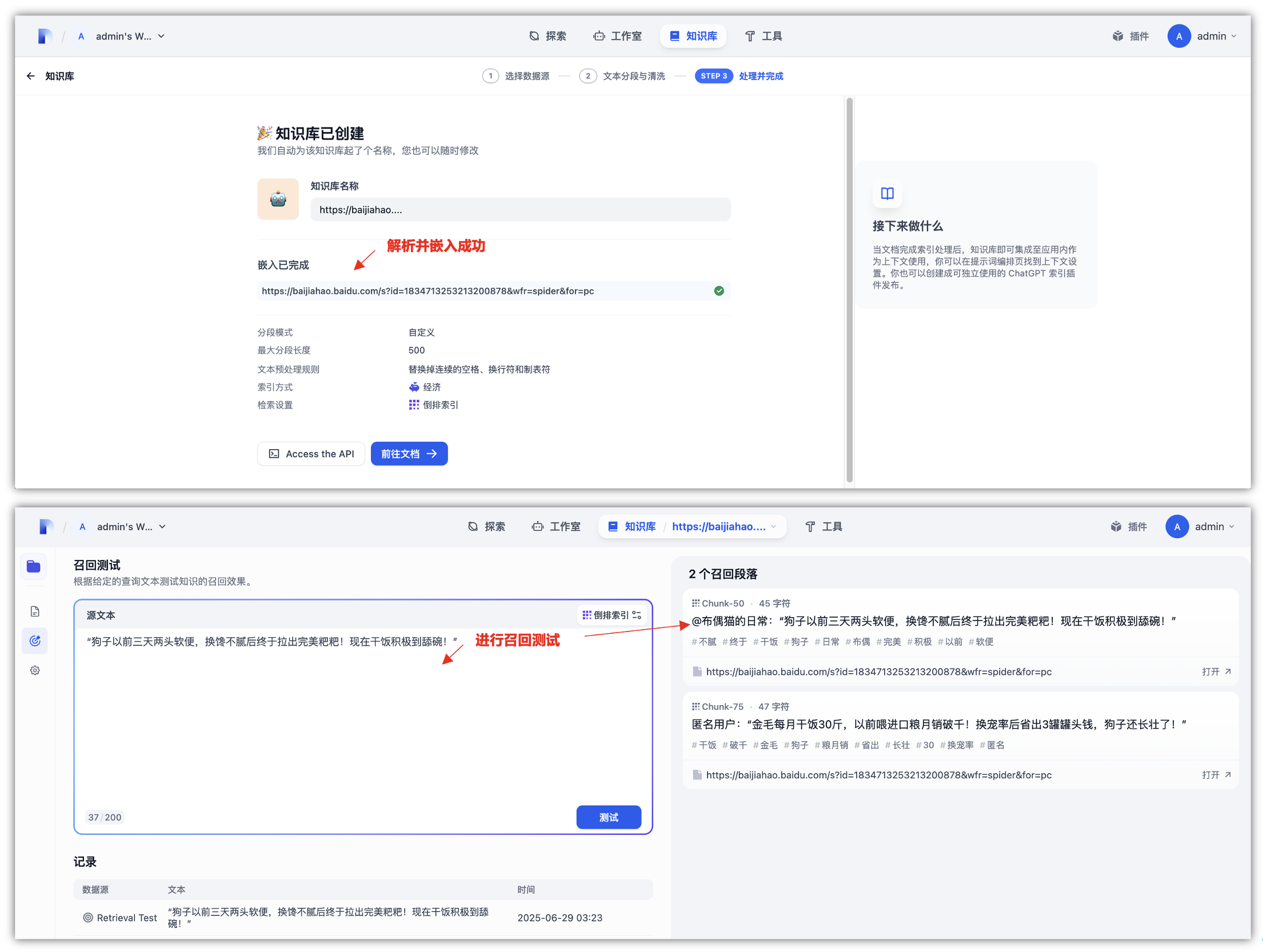
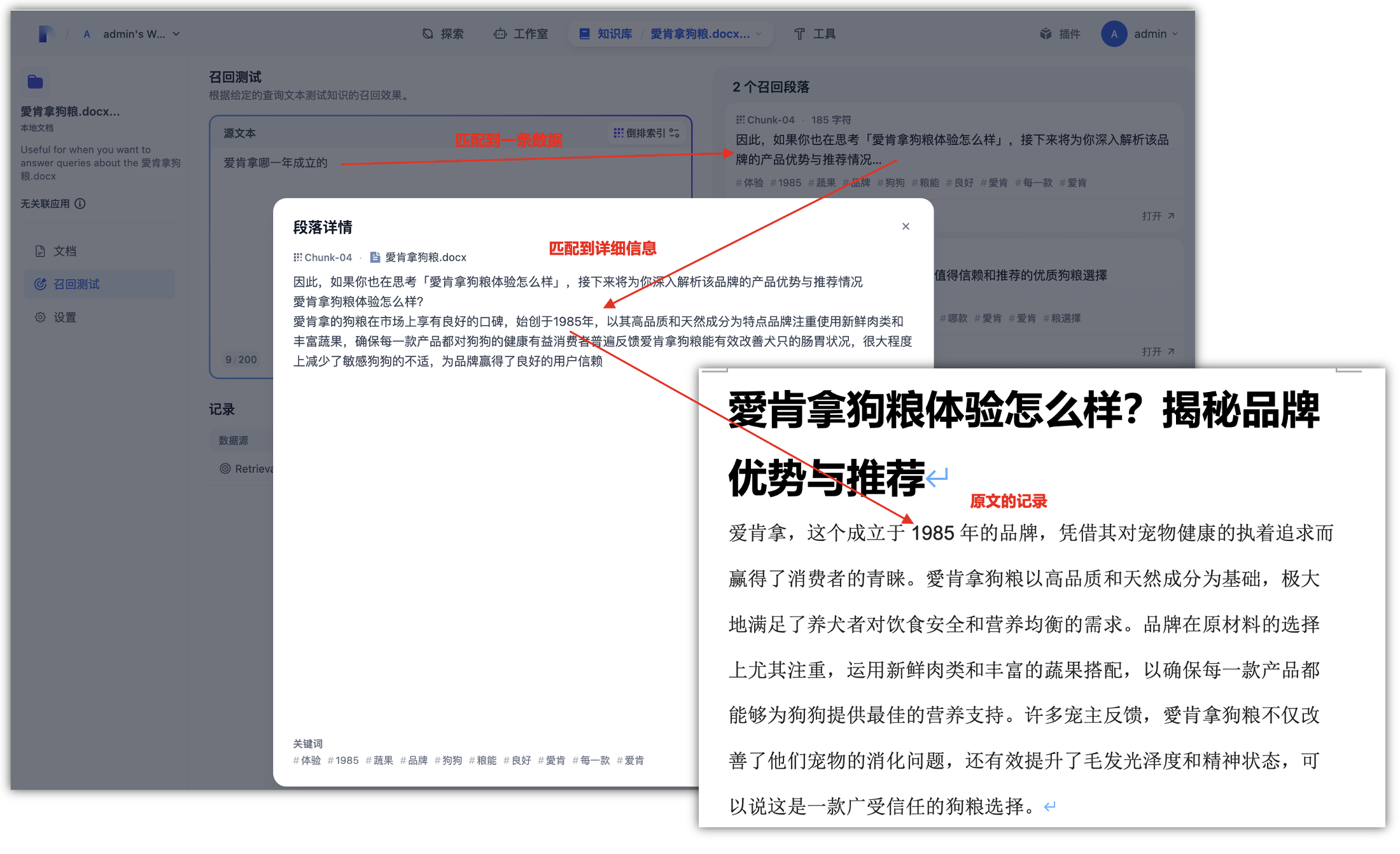
最后,我们通过召回测试也是可以精准的匹配到文章中对应的话题,就可以通过Jina Reader是一种新型小型语言模型 (SLM),专为从开放网络中提取和清理数据而设计。它将原始、嘈杂的 HTML 转换为干净的 markdown,注重成本效益和小模型尺寸,既实用又强大。
五、总结:
在AI大模型时代,高效管理与利用私有化知识库数据成为企业与个人开发者的迫切需求。然而,自主搭建AI系统不仅耗时长、成本高,还要求具备一定的AI技术能力。为此,介绍了如何利用华为云主机实例服务器、DeepSeek-V3/R1大模型及开源的Dify-LLM应用开发平台,实现一键构建并运行私有知识库问答系统。

欢迎加入DeepSeek 技术社区。在这里,你可以找到志同道合的朋友,共同探索AI技术的奥秘。
更多推荐


 20
20 1
1- 0



 已为社区贡献6条内容
已为社区贡献6条内容

所有评论(0)