帝国理工携手KAIST:BHaRNet用跨注意力优化骨骼动作识别精度
提出将身体和手部作为两个互补数据模态的跨模态架构,身体流提取全局身体动态(如走路、跳跃),手部流专注于手指关节的细粒度运动(如捏、握),以跨模态方式整合详细的手部姿态信息和全身姿态,使模型能同时捕捉全局身体动态和精细的手部关节运动。2.特征模糊:统一图表示(如SkeleT)整合全身、手部和足部关键点时,但由于身体和手部动作特征差异以及空间池化时细微特征的丢失,导致手部细节模糊,限制精确识别手部动作
本次分享论文来自KAIST和帝国理工,通过跨注意力优化骨骼动作识别精度。

论文解读:Body-Hand Modality Expertized Networks with Cross-attention for Fine-grained Skeleton Action Recognition
论文地址:https://arxiv.org/abs/2503.14960
研究动机
基于骨架的动作识别(HAR)方法存在以下局限性:
1.忽略手部细节:多数方法专注于全身运动,而忽视手部细微动作(如“OK手势”与“胜利手势”的区分)。
2.特征模糊:统一图表示(如SkeleT)整合全身、手部和足部关键点时,但由于身体和手部动作特征差异以及空间池化时细微特征的丢失,导致手部细节模糊,限制精确识别手部动作的任务的性能。
3.计算效率低:现有融合方法计算复杂度高,难以实时应用。
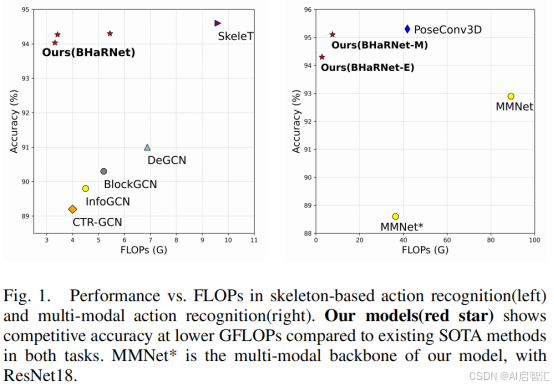
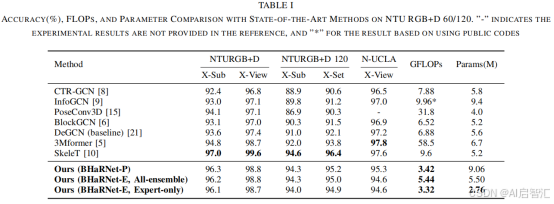
表1显示,在NTU RGB+D 120数据集上,SOTA方法SkeleT的准确率为94.6%,但计算量达9.6 GFLOPs。现有方法在“手部密集”动作(如手势识别)上的准确率仅86.4%,而BHaRNet提升至93.0%。
创新点
双流网络(Body-Hand Dual Streams)
提出将身体和手部作为两个互补数据模态的跨模态架构,身体流提取全局身体动态(如走路、跳跃),手部流专注于手指关节的细粒度运动(如捏、握),以跨模态方式整合详细的手部姿态信息和全身姿态,使模型能同时捕捉全局身体动态和精细的手部关节运动。
交叉注意力与池化模块
-交叉注意力:在中间层交换身体与手部特征,增强上下文交互。
-池化注意力模块:沿不同轴(时间T、空间V)部分池化,减少计算量。
联合训练与协同专业化
双模态框架通过联合损失和个体分类损失进行联合训练,使模型展现出身体和手部两种独特的专业能力,同时在混合类别上也有性能提升。
多模态扩展
利用身体骨架特征指导RGB特征学习,使RGB流能够聚焦于互补的上下文信息,捕捉物体交互和环境线索(如手持物体识别),提升整体识别性能。
方法
整体架构:
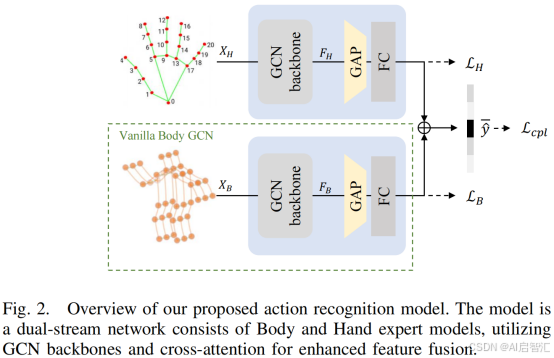
图2展示了论文所提出双流网络,主要由身体专家模型和手部专家模型构成,借助图卷积网络(GCN)骨干和跨注意力机制来强化特征融合,具体介绍如下:
双分支网络
双分支网络包含身体模型(身体流)和手部模型(手部流)。其中,身体模型基于身体骨架数据进行特征提取,用于捕捉全局姿态动态,Body GCN 专门用于处理全身动力学相关的特征学习,关注更广泛的姿态变化;在手部模型(手部流)中,Hand GCN则聚焦于手指等精细运动的特征提取,针对手部姿态数据进行处理,专注于学习手部的细微关节活动。公式:
![]()
分别表示身体和手部GCN的输出。这一设计使得模型能够分别保留身体和手部各自模态的特定特征,避免在统一处理过程中手部细节特征的丢失。
-身体流:输入25个关节(NTU数据集)。
-手部流:输入21×2手部关键点(Mediapipe提取)。
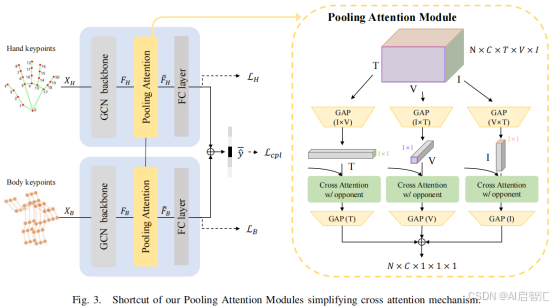
交叉注意力机制
通过池化注意力模块和专家化分支实现特征级信息交换。池化注意力模块沿不同轴进行结构化池化,再计算注意力,在计算效率和丰富特征融合之间取得平衡。专家化分支模型将GCN 输出分为专家化分支和交互分支,分别保留模态特定特征和进行交叉注意力融合,最后综合四个分支的 logits 得到最终预测。
损失函数
结合身体和手部的单独分类损失以及考虑融合预测的联合损失,公式:
![]()
确保身体流保留全局姿态知识,手部流专注于复杂手势,同时防止单个流在所有动作类别上过度学习。其中个体损失为:
![]()
、集成损失:
![]()
。集成损失通过平均logit使两流互补,类似混合专家(MoE)。
多模态融合
受MMNet(MMNet: A model-based multimodal network for human action recognition in RGB-D videos)启发,将身体专家特征作为单独视觉流的指导,整合RGB信息。通过这种方式,框架能够突出RGB帧中相关的时空区域,与骨架数据互补,适应广泛的动作识别任务。
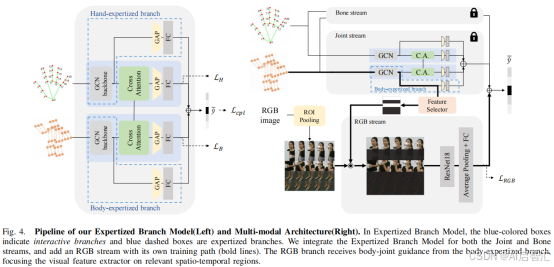
图4展示了专家化分支模型的流程(左图)和多模态架构(右图),介绍在特征处理和多模态融合方面的设计。
专家化分支模型(左图):蓝色方框代表交互分支,蓝色虚线框代表专家化分支。这种设计针对关节(Joint)和骨骼(Bone)流,将GCN输出分成两条路径。在专家化分支中,直接将原始GCN特征传递给全局平均池化(GAP)和全连接层(FC),以保留模态特定特征。而交互分支则接收来自互补模态的跨注意力信号,进行特征融合后再进行GAP和分类操作。通过这种方式,既保留了模态固有特性,又实现了特征间的交互融合。
多模态架构(右图):在专家化分支模型基础上加入了RGB流。RGB流有自己独立的训练路径(加粗线条表示) ,它接收来自身体专家化分支的身体关节引导信息。这使得RGB流的视觉特征提取器能够聚焦于相关的时空区域,例如根据身体关节的位置和运动,关注场景中与动作相关的物体或背景等上下文线索。这种设计将骨架数据的动态信息与RGB图像的视觉信息相结合,通过跨注意力机制实现多模态数据的互补,增强了模型对动作识别的能力,适用于更广泛的动作识别任务场景。
轻量化推理
仅使用专家分支(BHaRNet-E Expert-only)时,GFLOPs降至3.32,参数量2.76M(表1),适合实时场景。
实验
实验设置
采用开源DeGCN框架作为骨架基线,将其单流架构改为双流架构。通过在同一数据集上微调预训练的专家化模型进行联合训练,推理时对骨架动作识别的关节和骨骼模型进行集成,多模态动作识别时对关节、骨骼和RGB模态进行集成。
骨架动作识别
-NTU RGB+D 60:BHaRNet-P达96.3%准确率(X-Sub),接近SOTA的SkeleT(97.0%),但计算量仅为后者的35%。
-手部密集动作:准确率从86.4%(基线)提升至93.0%。
-效率优势:参数量5.5M(BHaRNet-E All-ensemble),显著低于3Mformer(6.7M)。
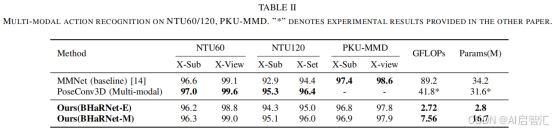
多模态任务
-PKU-MMD:BHaRNet-M达96.9%(X-Sub),优于MMNet(97.4%)且计算量更低(7.56 vs. 89.2 GFLOPs)。
- RGB引导:身体特征动态加权RGB流,提升背景与物体交互的捕捉能力。
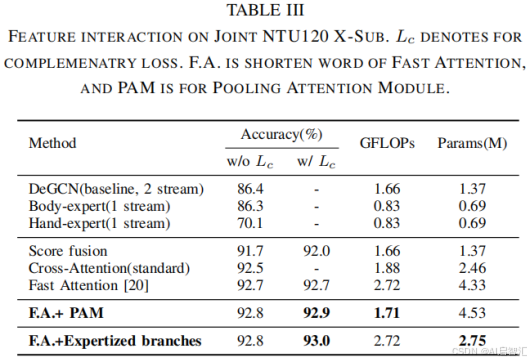
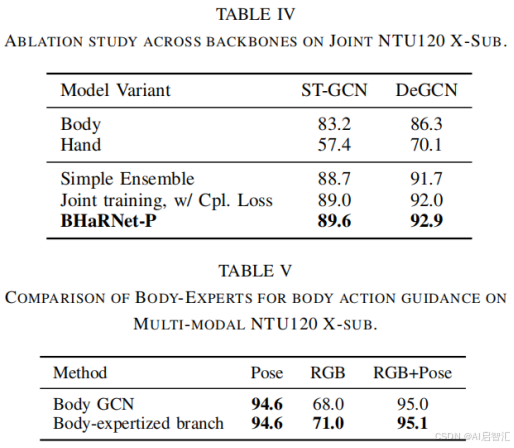
消融实验
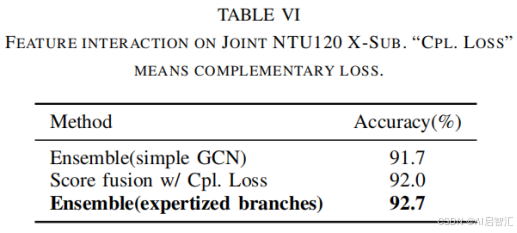
-交叉注意力:贡献约2.1%准确率提升。
-专家分支:单独使用手部专家分支时,手部动作准确率提升4.3%。
总结
本文提出BHaRNet,通过双流专家网络与交叉注意力机制,在细粒度动作识别中实现精度与效率的平衡。整篇文章总结下来就是:
动机明确:解决手部细节丢失与计算效率问题。
方法创新:双流分离、交叉注意力、轻量化池化模块。
应用扩展:支持多模态(RGB+骨架),为机器人交互提供实用解决方案。
未来方向:探索更多模态(如语音)融合,进一步压缩模型以适应边缘计算场景。
可微信搜索公众号【AI启智汇】,获取最新AI分享,感谢阅读。
AI启智汇 | PASSION FOR SHARING


欢迎加入DeepSeek 技术社区。在这里,你可以找到志同道合的朋友,共同探索AI技术的奥秘。
更多推荐



 18
18 0
0- 0



 已为社区贡献2条内容
已为社区贡献2条内容

所有评论(0)