AI训练,目标检测:yolov8之一些项目的目录结构说明
cfg:default.yaml(默认参数,训练时要配置的参数)epochs=100-表示训练100轮。
搭建环境操作步骤:
一、创建虚拟环境
1、点击‘Anaconda Navigator(Anaconda)’、base(root)、Open Terminal,打开一个新的终端
2、通过终端命令进入到【yolov8】项目之中
3、运行
conda create -n demo8 python=3.8.8,,,python版本3.8.8,demo8-自定义命名
需要输入y
4、进入环境
conda activate demo8若是忘记虚拟环境名字了,可以conda env list 查看
二、安装PyCharm
1、下载、安装,还需要激活(可使用‘全家桶’进行激活)
三、配置环境
1、把yolo8项目拖到PyCharm工具之中,即:打开yolo8项目
在PyCharm工具中,右下角点击‘Python3.8’、‘Interpreter Settings’
在‘Python Interpreter’下拉框,点击展示,点击‘Show All...’,
在左下角点击‘+’,
点击‘Conda Environment’、‘Existing environment’,
在Interpreter:,点击下拉框,选择在‘Anaconda Navigator’创建好的‘虚拟环境’,
点击OK、Apply,当右下角出现Python 3.8(demo8)时,表示配置虚拟环境成功
2、以上配置完毕后,接着要安装依赖:打开终端,
安装pip命令:pip install -v -e .
pip install -i -v -e . https://pypi.tuna.tsinghua.edu.cn 指定下载景象地址
3、测试配置环境是否正常
打开demo、record、start_single_detect.py-运行此文件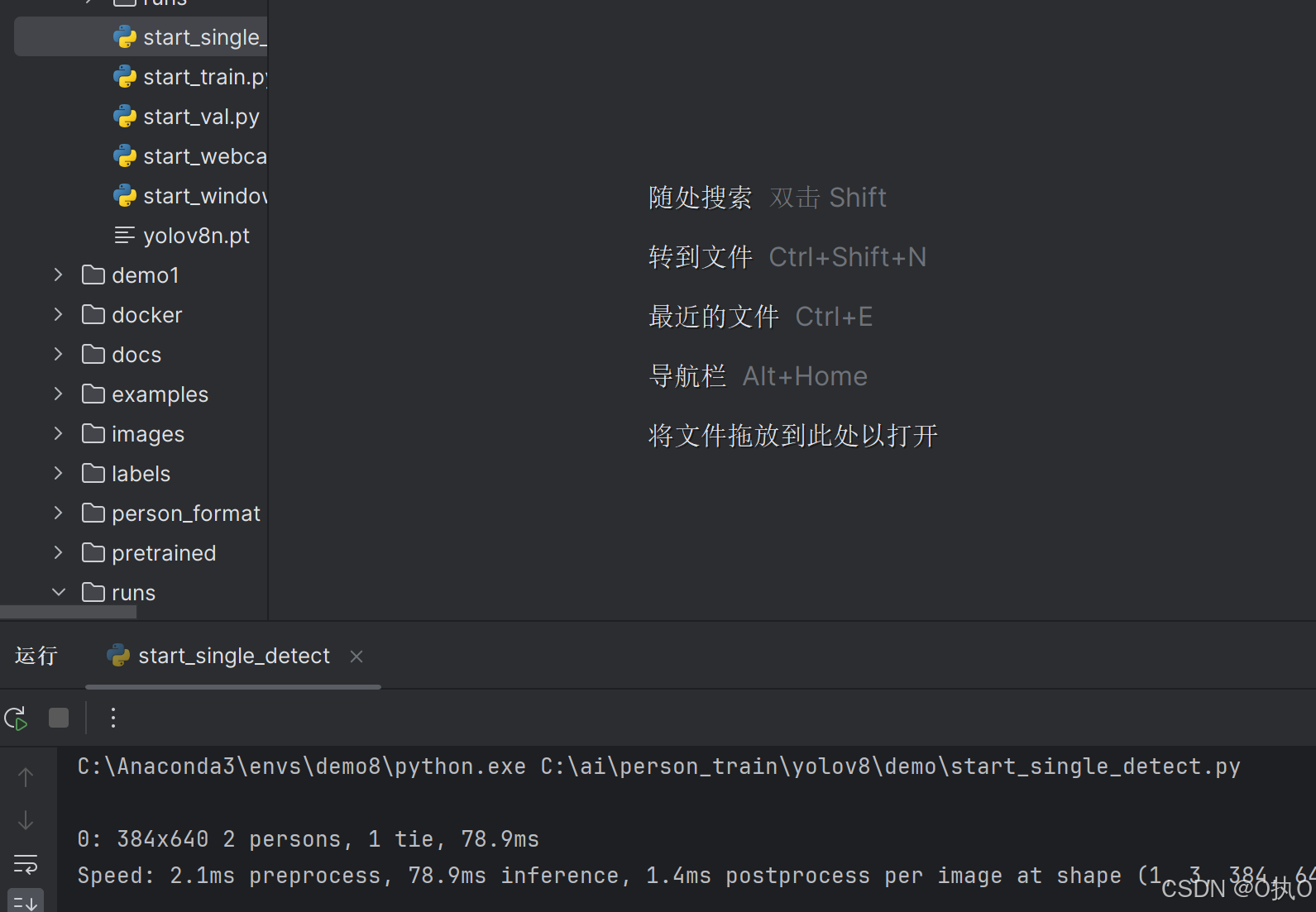
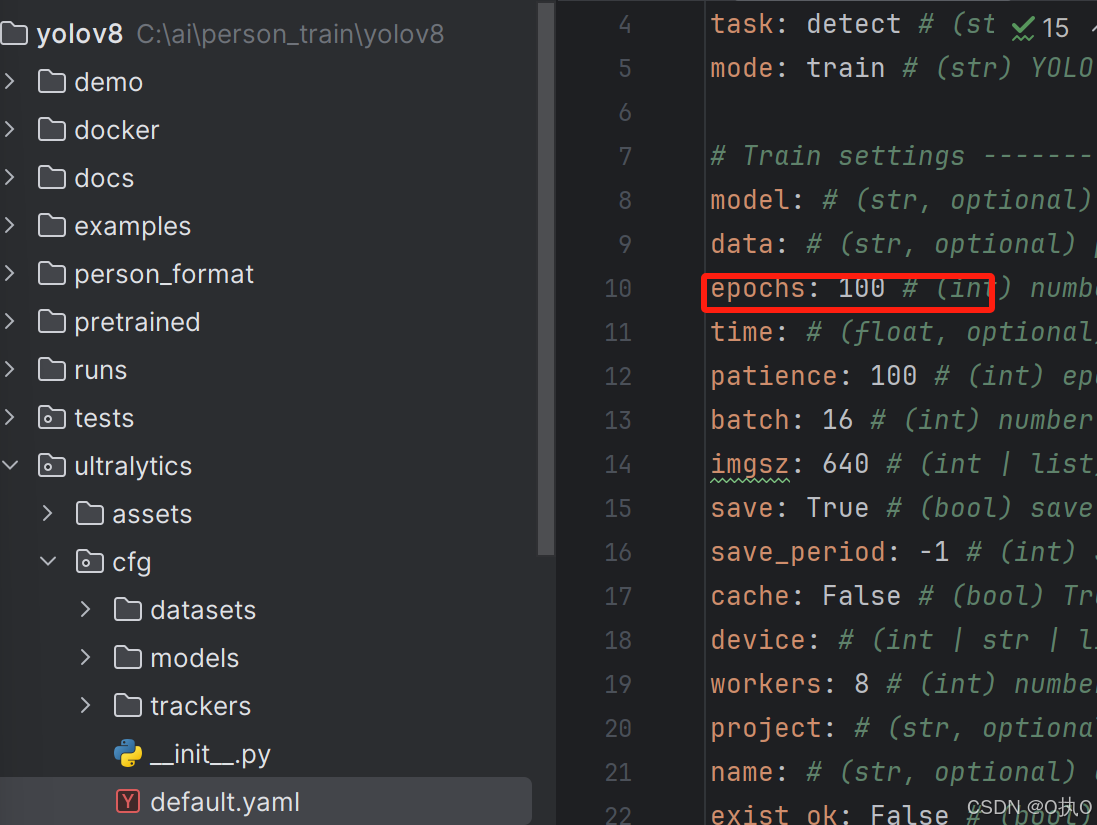
默认参数
ultralytics:
cfg:default.yaml(默认参数,训练时要配置的参数)
epochs=100-表示训练100轮
基础模型
pretrained
xxx.pt文件,模型文件
在此模型下进行训练,交付给自己的模型。
训练集的目录结构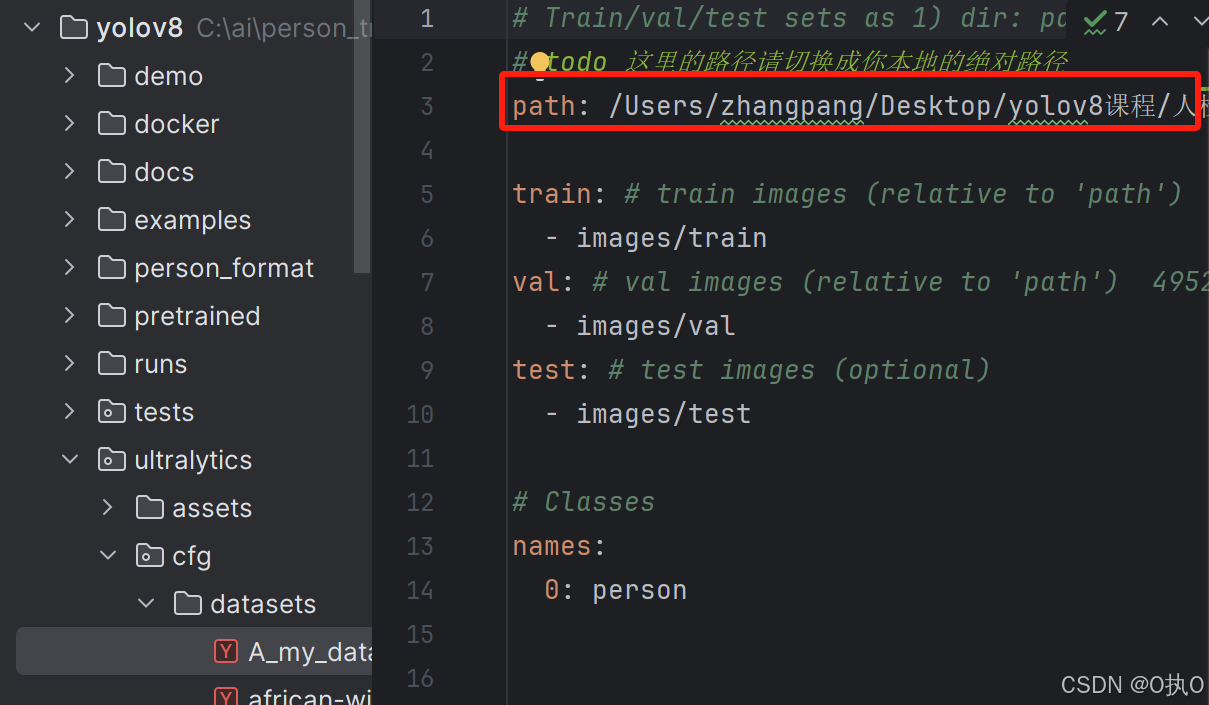
比如,我准备了一些标注后的数据,那么我需要将标注完的数据拿到我的模型里面去训练,即需要在A_my_data.yaml文件下的路径下填写自己标注完的数据的路径。
模型预测命令(目的:感觉上、初步判断是否符合)
yolo task=detect mode=predict model=pretrained/yolov8l.pt source=ultralytics/assets device=CPU模型训练命令
yolo task=detect mode=train model=pretrained/yolov8l.pt data=ultralytics/cfg/datasets/A_my_data.yaml batch=32 epochs=100 imgsz=100 workers=0 device=CPU cache=True
model=pretrained/yolov8l.pt:基于yolov8l.pt模型
data=ultralytics/cfg/datasets/A_my_data.yaml:表示训练的数据在‘A_my_data.yaml’文件
batch=32:表示图片数量,32张图合成一个图片
epochs=100:训练100轮(大概需5-6个小时)
imgsz=100:图片像素,高、宽都100
workers=0:
device=CPU:使用CPU
cache=True:会生成缓存文件
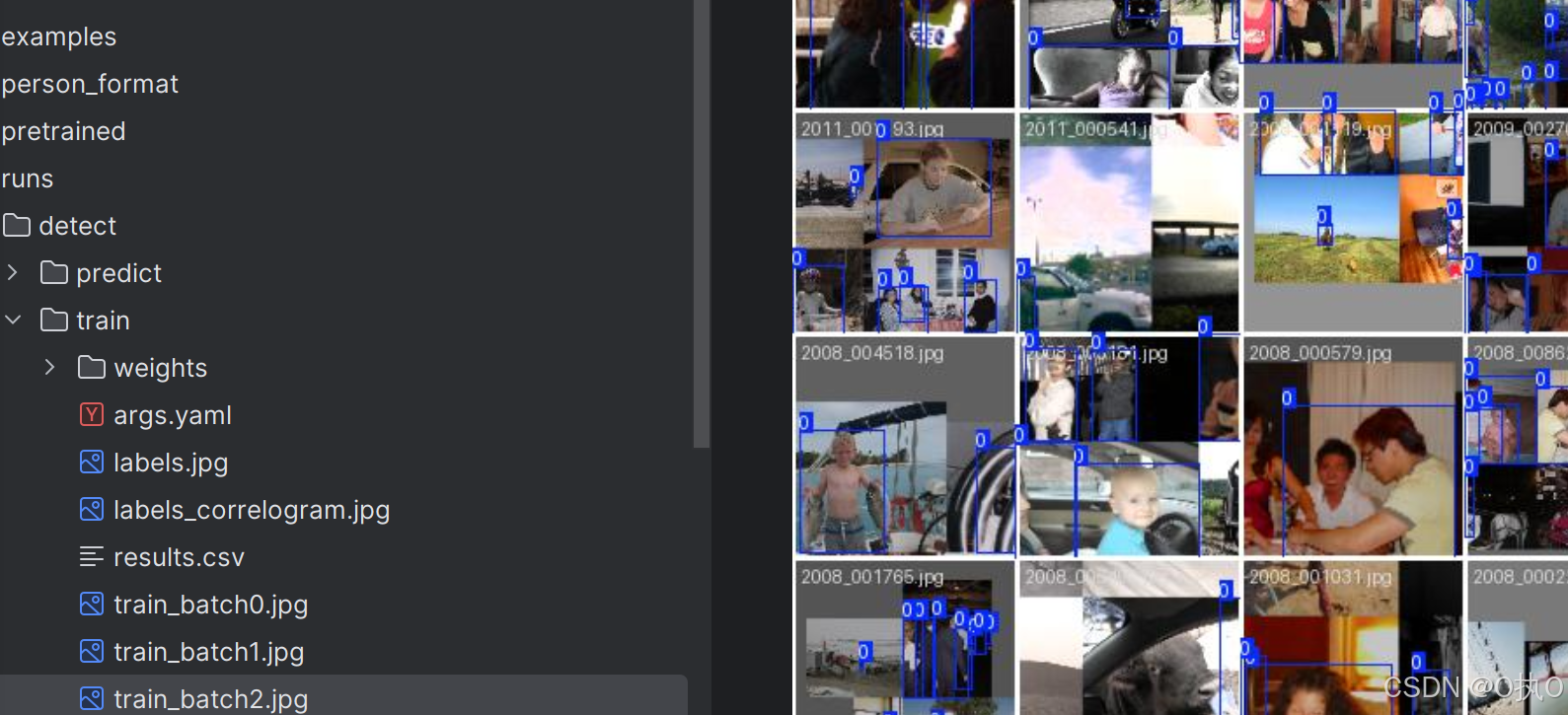
训练命令跑完后,会生成一个文件夹‘runs’、train文件夹下,会生成一些数据的报告,
包括最后一次模型和最完美的一次模型
模型验证
yolo task=detect mode=val model=pretrained/yolov8l.pt data=path/to/your/dataset.yaml device=CPU模型测试
yolo task=detect mode=predict model=pretrained/yolov8l.pt source=path/to/your/testset device=CPU
训练结果
模型训练完后,训练命令跑完后,会生成一个文件夹‘runs’、detect、train文件夹下,会生成一些数据的报告
一、weights文件夹:模型权重文件(有两个训练好的模型文件best.pt、last.pt)
best.pt-是整个训练过程中,性能最好的模型权重文件,
最终我们要的就是这个文件,可以拿它进行实际业务的AI预测继续微调
last.pt-是最后一次训练的模型权重文件。
results.csv文件:展示的是训练轮数,包括轮次、损失率等详细数据
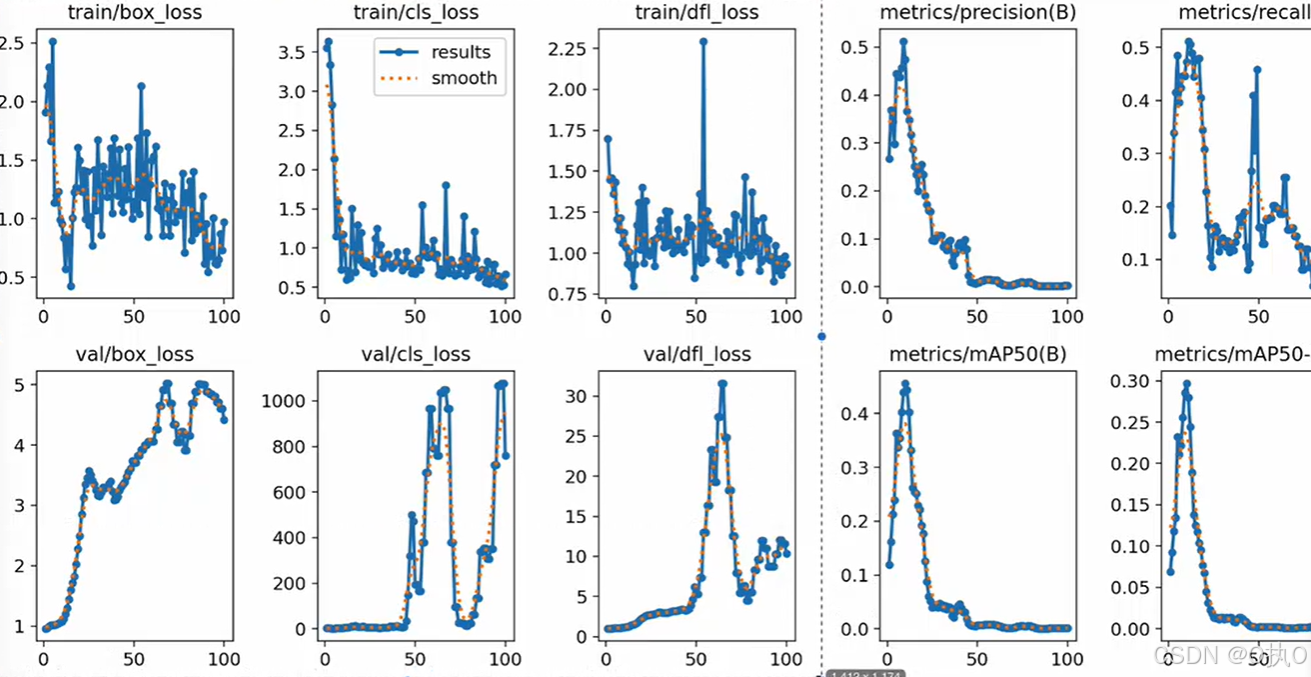
results.png图片-总预览图,训练集和验证集结果的分析,上边5个是‘训练集’、下边5个是‘验证集’
train/box_loss边界框损失:衡量画框
标注时要拉一框,预测时也有一个框,两个框一对比,就可算出损失率,如何计算?, 损失越低,代表的是双方面更精准。
train/cls_loss分类损失:判断框里面的物体,衡量的是预测类别和真实类别之间的差异
一张图片里面既有人、狗,如果把狗标成person,是不对的,即判断我们框内的这个物体,标的对不对,在一张图片中对物体分类的对不对。
train/dfl_loss分布式焦点损失
精益求精,train/dfl_loss分布式焦点损失和train/box_loss边界框损失是相辅相成的。辅助box_loss,提供额外的信息,通过对边界框位置的概率分布进行优化,进一步提高模型对边界框位置的细化和准确度。
metrics/precision(B)精度
又准又全的考量, 精准度肯定是越往上越好。

欢迎加入DeepSeek 技术社区。在这里,你可以找到志同道合的朋友,共同探索AI技术的奥秘。
更多推荐



 12
12 0
0- 0



 已为社区贡献1条内容
已为社区贡献1条内容

所有评论(0)