【人工智能之大模型】简述大模型GPT和BERT的区别...
【人工智能之大模型】简述大模型GPT和BERT的区别...
·
【人工智能之大模型】简述大模型GPT和BERT的区别…
【人工智能之大模型】简述大模型GPT和BERT的区别…
文章目录
欢迎宝子们点赞、关注、收藏!欢迎宝子们批评指正!
祝所有的硕博生都能遇到好的导师!好的审稿人!好的同门!顺利毕业!
大多数高校硕博生毕业要求需要参加学术会议,发表EI或者SCI检索的学术论文会议论文。详细信息可关注VX “
学术会议小灵通”或参考学术信息专栏:https://blog.csdn.net/gaoxiaoxiao1209/article/details/146181864
1. 模型内部运行机制
架构设计
GPT(Generative Pre-trained Transformer)
- 解码器结构:GPT 采用的是“decoder-only”架构,即只使用 Transformer 的解码器部分。
- 自回归建模:模型基于前文预测下一个词,输出是条件概率分布 P ( x t ∣ x 1 , x 2 , . . . , x t − 1 ) P(x_t|x_1,x_2,...,x_{t-1}) P(xt∣x1,x2,...,xt−1)。
- 训练目标:主要使用下一个词预测(Next Token Prediction),这使得 GPT 在生成连贯长文本时非常擅长。
BERT(Bidirectional Encoder Representations from Transformers)
- 编码器结构:BERT 采用的是“encoder-only”架构,利用 Transformer 的编码器部分进行全局双向注意力建模。
- 双向上下文:模型在每个位置上都能利用左右两侧的上下文信息。
- 训练目标:主要采用 Masked Language Modeling(MLM,即随机遮挡部分词汇,然后预测被遮挡的词)和 Next Sentence Prediction(NSP)来进行预训练,专注于文本理解和表示学习。
计算过程与信息流
- GPT:在生成过程中,GPT 依次生成每个词,输出依赖于先前所有生成的词,这种自回归的过程保证了生成文本的连贯性;但这种单向依赖也使得它在捕捉全局信息时受到限制,必须在每个时间步累积上下文。
- BERT:通过双向自注意力机制,BERT 能够同时参考上下文中所有的信息,这使得它在理解句子结构、关系和语义信息上表现优异。但因为训练目标不涉及生成,BERT 本身不具备文本生成能力。
2. 使用场景与用户体验
使用场景
GPT:
- 主要用于生成任务,如对话系统(例如 ChatGPT)、文章创作、代码生成和翻译等。
- 用户体验上,GPT 的优势在于能够生成流畅、连贯和多样化的文本,适合交互式对话和创意写作。
BERT:
- 主要用于理解类任务,如文本分类、命名实体识别、问答系统、文本匹配等。
- 通常作为特征提取器或预训练模型,通过微调适应特定任务。用户体验上,BERT 更多体现在后台支持搜索、推荐等任务中,而不是直接生成文本。
用户体验
GPT 用户体验:
- 提供交互式、自然的对话体验,生成的文本通常富有创意和语义连贯性,但有时也可能出现重复、偏题或逻辑不连贯的情况。
BERT 用户体验:
- 在问答和检索系统中表现出色,能够准确捕捉文本细节和语义关系,提升系统准确率和用户满意度,但不适用于直接生成内容。
3. 总结对比
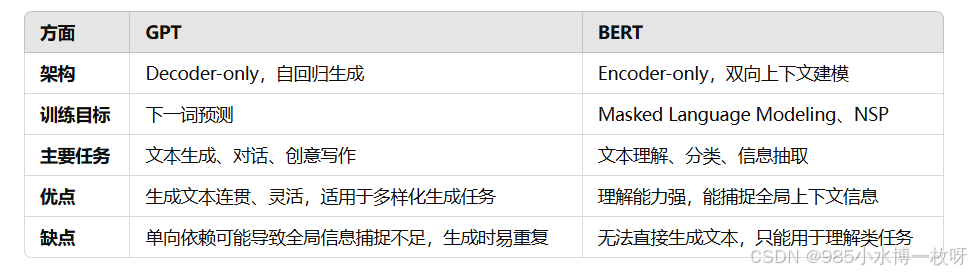
4. 小结
- 内部运行机制:GPT 基于解码器自回归生成,BERT 则通过双向编码捕捉上下文信息;两者的训练目标和信息流方式决定了各自的优势领域。
- 使用场景:GPT 更适合需要生成内容的应用,而 BERT 更适用于需要深度理解的任务。
- 用户体验:基于 GPT 的应用(如 ChatGPT)能提供自然对话体验,而基于 BERT 的系统则在搜索、问答等任务中提供高准确率的结果。
这就是 GPT 和 BERT 在模型内部运行、使用场景以及用户体验方面的主要区别。

欢迎加入DeepSeek 技术社区。在这里,你可以找到志同道合的朋友,共同探索AI技术的奥秘。
更多推荐


 30
30 0
0- 0



 已为社区贡献2条内容
已为社区贡献2条内容

所有评论(0)