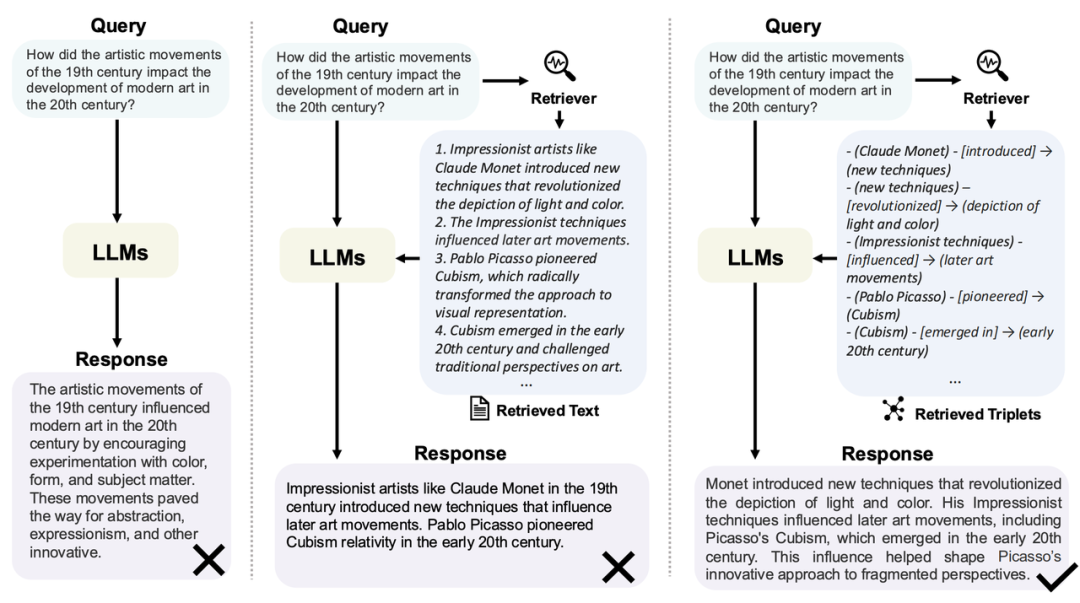
知识图谱融入向量数据库,带来RAG效果飞升,AI大模型零基础入门到精通实战教程建议收藏!
随着大型语言模型(LLMs)在各种应用中的广泛使用,如何提升其回答的准确性和相关性成为一个关键问题。检索增强生成(RAG)技术通过整合外部知识库,为LLMs提供了额外的背景信息,有效地改善了模型的幻觉、领域知识不足等问题。然而,仅依靠简单的 RAG 范式存在一定的局限性,尤其在处理复杂的实体关系和多跳问题时,模型往往难以提供准确的回答。将知识图谱(KG)引入 RAG 系统为解决这一问题提供了新的路

01.前言
随着大型语言模型(LLMs)在各种应用中的广泛使用,如何提升其回答的准确性和相关性成为一个关键问题。检索增强生成(RAG)技术通过整合外部知识库,为LLMs提供了额外的背景信息,有效地改善了模型的幻觉、领域知识不足等问题。然而,仅依靠简单的 RAG 范式存在一定的局限性,尤其在处理复杂的实体关系和多跳问题时,模型往往难以提供准确的回答。
将知识图谱(KG)引入 RAG 系统为解决这一问题提供了新的路径。知识图谱通过结构化的方式呈现实体及其关系,能够在检索过程中提供更为精细的上下文信息。通过利用 KG 的丰富关系性数据,RAG 不仅能够更精准地定位相关知识,还能更好地处理复杂的问答场景,如对比实体间的关系或回答多跳问题。
Comparision between Direct LLM, RAG, and GraphRAG.
https://arxiv.org/pdf/2408.08921
我给大家准备了一份全套的《AI大模型零基础入门+进阶学习资源包》,包括AI大模型入门学习思维导图、精品AI大模型学习书籍手册、视频教程、实战学习等录播视频免费分享出来。😝有需要的小伙伴,可以VX扫描下方二维码免费领取🆓
然而,当前的 KG-RAG 还处在早期的探索阶段,行业对相关技术路线还未达成统一共识。比如,如何有效检索知识图谱中的相关 entities 和 relationships,如何将向量相似性搜索和图结构结合起来,目前没有形成统一的范式。
比如,微软的 From Local to Global 使用大量的 LLM 访问将子图结构以汇总成社区摘要,但这一过程消耗大量的 LLM tokens,使这一方法昂贵且不切实际。HippoRAG 使用 Personalized PageRank 重新更新图节点的权重,以找到重要的 entities,但这种以 entity 为中心的方法很容易受到 NER 遗漏的影响,而忽略了上下文中的其它信息。IRCoT 使用多步LLM 请求来逐步推理得到最终的回答,但这种方法将 LLM 引入多跳查找过程,导致回答问题的时间过长,很难实际应用。
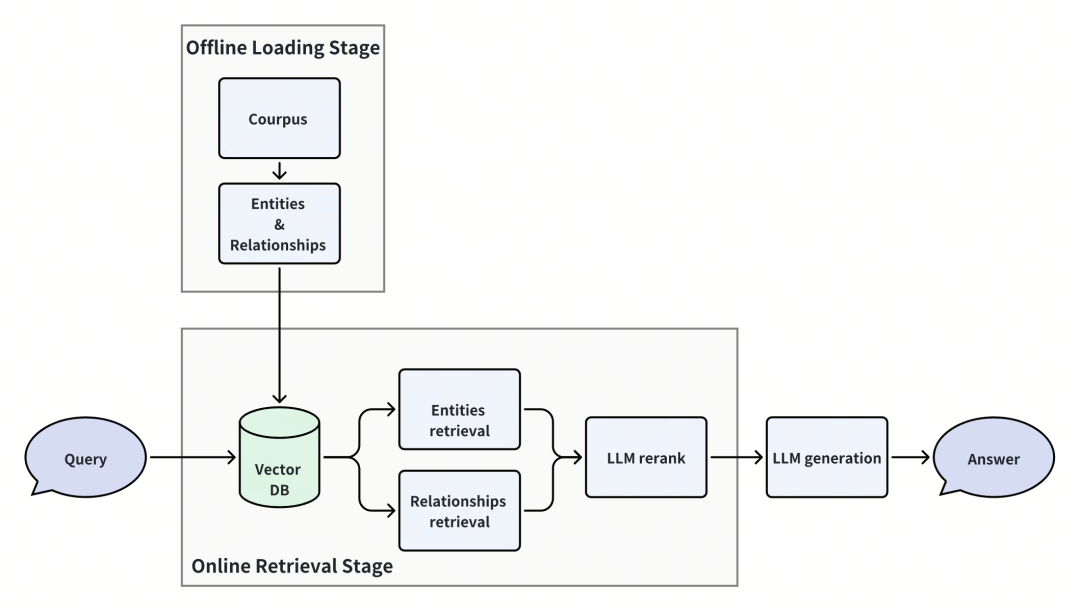
我们发现,实际上用一个简单的多路召回然后 rerank 的 RAG 范式,就能够很好的处理复杂的多跳 KG-RAG 场景,而并不需要过多的 LLM 开销和任何图算法。
Our simple pipeline is not much different from the common multi-way retrieval and rerank architecture, but it can achieve the SoTA performance in the multihop graph RAG scenario.
尽管使用很简单的架构,但我们的方法显著超过目前 state-of-the-art 的解决方案,比如 HippoRAG,并且仅仅需要用到向量存储和少量的 LLM 开销。我们首先引入我们方法的理论基础,然后介绍具体方法过程。
02.理论
我们观察到在实际的 KG-RAG 场景中,存在跳数有限性假设:在 KG-based RAG 中,实际问的 query 问题的查询路由只需要在知识图谱中进行有限的,且很少的跳数(如少于4跳)的查询,而并不需要在其中进行非常多次跳数。
我们的跳数有限性假设基于两点很重要的观察:1. query 复杂度有限性, 2.“捷径”的局部 dense 结构。
- query 复杂度有限性
用户的一个提问 query,不太可能涉及到非常多的 entities,或者引入复杂的 relationships。否则这个问题会显得非常奇怪和不切实际。
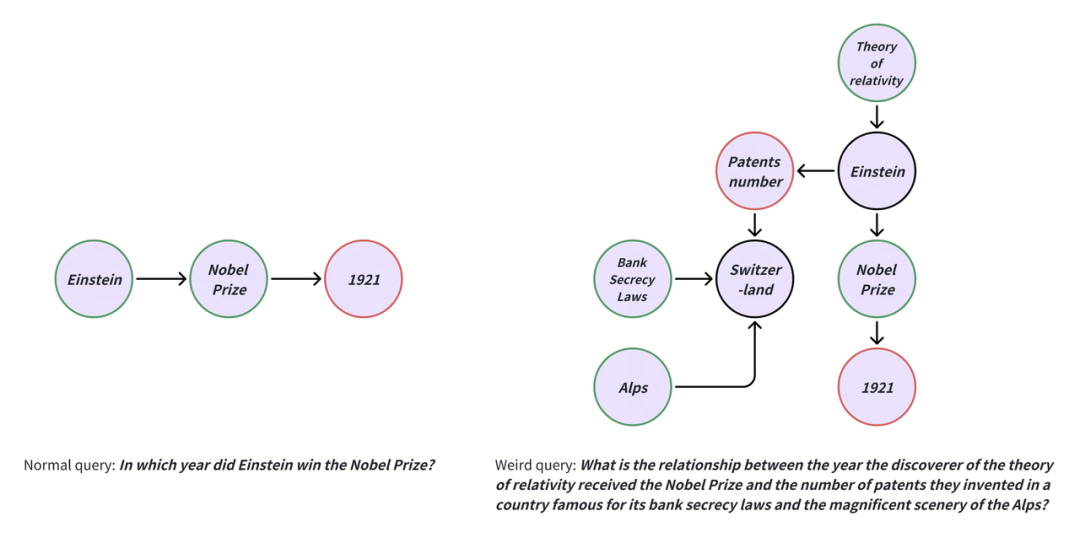
Normal query vs. Weird query
正常的query:“爱因斯坦获得诺贝尔奖的时间是哪一年?”
In which year did Einstein win the Nobel Prize?
知识图谱中的查询路径:
找到节点“爱因斯坦”。
跳转到与“爱因斯坦”相关的“诺贝尔奖”节点。
返回奖项颁发的年份信息。
跳数:2 跳
说明:这是一个常见的用户问题,用户想要知道的是与某个具体实体直接相关的单一事实。知识图谱在这种情况下只需要进行少量跳数的查询即可完成任务,因为所有相关信息都直接与爱因斯坦这个中心节点关联。这种查询在实际应用中非常普遍,例如查询名人背景信息、奖项历史、事件时间等。
古怪的query:“相对论的发现者获得诺贝尔奖的年份与他们在一个以银行保密法和阿尔卑斯山壮丽风景而闻名的国家发明的专利数量之间有什么关系?”
What is the relationship between the year the discoverer of the theory of relativity received the Nobel Prize and the number of patents they invented in a country famous for its bank secrecy laws and the magnificent scenery of the Alps?
知识图谱中的查询路径:
找到“相对论”的“发明者”是“爱因斯坦”。
跳转到与“爱因斯坦”相关的“诺贝尔奖”节点。
查找“诺贝尔奖”获奖年份。
通过“银行保密法和阿尔卑斯山”找到“瑞士”
跳转到与“爱因斯坦”相关的“专利”节点。
查找与瑞士期间相关的专利信息。
比较专利数量和获奖年份之间的关系。
跳数:7跳
说明:这个问题较为复杂,要求不仅仅是查询单一的事实,还涉及多个节点之间的复杂关联。这种问题在实际场景中不太常见,因为用户一般不倾向于在一次查询中寻求如此复杂的信息交叉。通常,这类问题会被分解为多个简单查询,以便逐步获取信息。
- “捷径”的局部 dense 结构
知识图谱中是一个存在一些局部 dense 结构,对于有些 query,有一些“捷径”,可以从一个 entity 通过捷径快速连接到多跳之外的 entity。
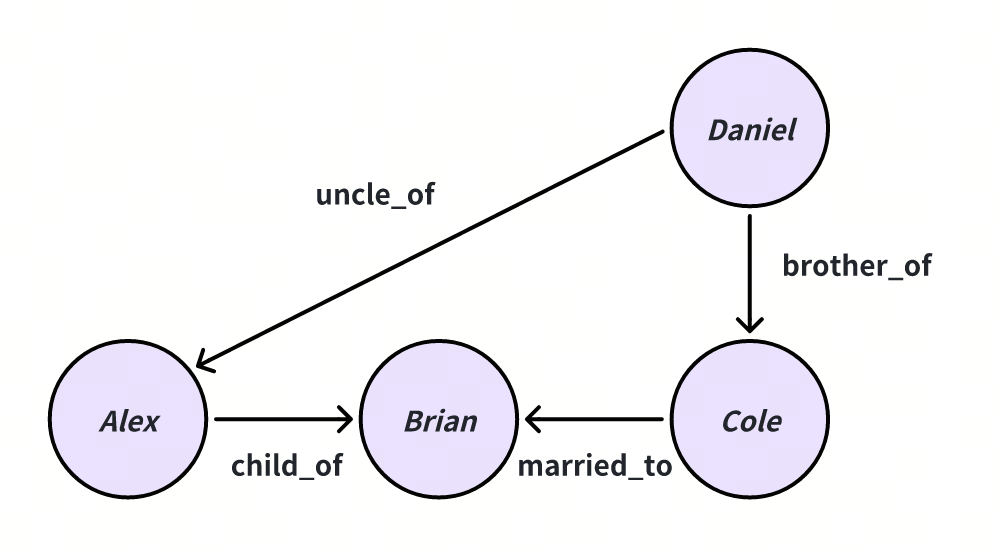
“Shortcuts” structure
假设我们有一个家庭关系的知识图谱,包含以下实体和关系:
Alex 是 Brian 的孩子 (
Alex - child_of - Brian)Cole 嫁给了 Brian (
Cole - married_to - Brian)Daniel 是 Cole 的哥哥 (
Daniel - brother_of - Cole)Daniel 是 Alex 的舅舅 (
Daniel - uncle_of - Alex)这是一个包含冗余信息的密集型的知识图谱。显然,可以通过前三条 relationships 推导出最后一条 relationship。但知识图谱中往往存在一些这种冗余信息的捷径。这些捷径可以减少一些 entities 之间的跳数。
基于这两点观察,我们发现,有限次数的在知识图谱内的路由查找过程,只涉及到局部的知识图谱信息。因此,将query 进行知识图谱内信息检索的过程可以用下面这两步来实现:
-
路由的起点,可以通过向量相似性查找来完成。可以涉及到 query 与 entities 或 query 与 relationships 的相似度关系查找。
-
从起点找到其它信息的路由过程,可以用一个 LLM 来代替完成。将这些备选信息放进 prompt 里,依托 LLM 强大的自注意力机制来挑选有价值的路由。由于 prompt 长度有限,所以只能将局部知识图谱的信息放入,比如起点附近限定跳数内的知识图谱信息,这一点是正好可以由跳数有限性来保证。
整个过程不需要其任何它的 KG 存储和复杂的 KG 查询语句,只需要使用 vector database 和一次 LLM 的访问。而 vector retrieval + LLM rerank 才是这个 pipeline 中最关键的部分,这也就解释了我们只用一个传统的两路召回架构,就可以达到远超基于图理论的方法(如 HippoRAG) 的表现。这也说明了,实际上不需要复杂的图算法,我们只需要将图结构的逻辑关系存储在向量数据库里,用一个传统的架构就可以进行逻辑上的子图路由,而现代 LLM 强大的能力帮助做到了这一点。
03.方法概览
我们的方法只涉及在 RAG 流程中检索 passages 的阶段,不涉及 chunking 或 LLM response generation 的创新和优化。我们假设已经得到了一组 corpus 的三元组信息,它包含一系列的 entities 和 relationships 信息。这些信息可以表示一个知识图谱的信息。
我们将 entities, relationships 信息分别进行向量化,并存储在向量存储里,这样存储了一个逻辑上的知识图谱。当进行 query 查询时,会先把相关的 entities 和 relationships 检索出来。通过这些 entities 和 relationships,我们在图结构上进行有限的拓展。将这些 relationships 与 query 问题组装进 prompt 内,使用 LLM 的能力对这些 relationships 进行 reranking。最后得到 topK 个重要的 relationships,在他们的 metadata 信息内获得与他们相关的 passages,作为最终的 retrieved passages。
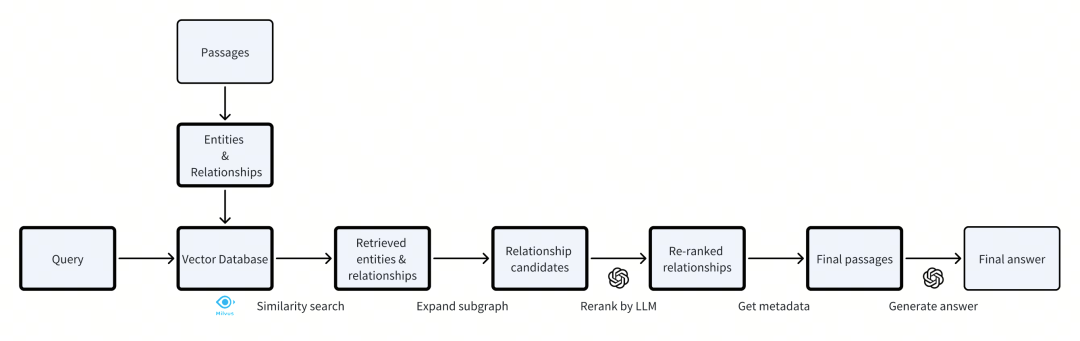
Overall pipeline of our method
我给大家准备了一份全套的《AI大模型零基础入门+进阶学习资源包》,包括AI大模型入门学习思维导图、精品AI大模型学习书籍手册、视频教程、实战学习等录播视频免费分享出来。😝有需要的小伙伴,可以VX扫描下方二维码免费领取🆓
04.方法详解
4.1. 向量入库
我们准备两个向量存储 collections,一个是 entity collection,另一个是 relationship collection。将一系列的 unique entities 信息和 relationships 信息,使用 embedding 模型,转换成向量,存储在向量存储中。对于 entities 信息,直接将他们的字符描述转换成 embedding。对于 relationships 的原始数据形式,它的结构是一个三元组:
(Subject, Predicate, Object)
我们启发性地直接将它们合并成一个句子
“Subject Predicate Object”
比如:
(Alex, child of, Brian) -> “Alex child of Brian”
(Cole, married to, Brian) -> “Cole married to Bria”
然后直接将这个句子转换成 embedding,然后存储在向量数据库里。这种做法方便且直接,虽然这样做可能存在少量的语法问题,但这不影响句子含义的表达,也不影响它在向量空间中的分布。当然,我们同样也鼓励在前期抽取三元组的时候,直接使用 LLM 生成简短的句子描述。
4.2. 向量相似搜索
-
对于输入的 Query,我们遵循常见的 GraphRAG 中的范式(如HippoRAG,MS GraphRAG),将 query 提取 entities,对于每个 query entity,转换成 embedding,分别对 entity collection 进行 vector similarity search。然后将所有 query entities搜索得到的结果进行合并。
-
对于 relationship 的向量搜索,我们直接将 query string,转换成 embedding,对 relationship collection 进行 vector similarity search。
4.3. 扩展子图
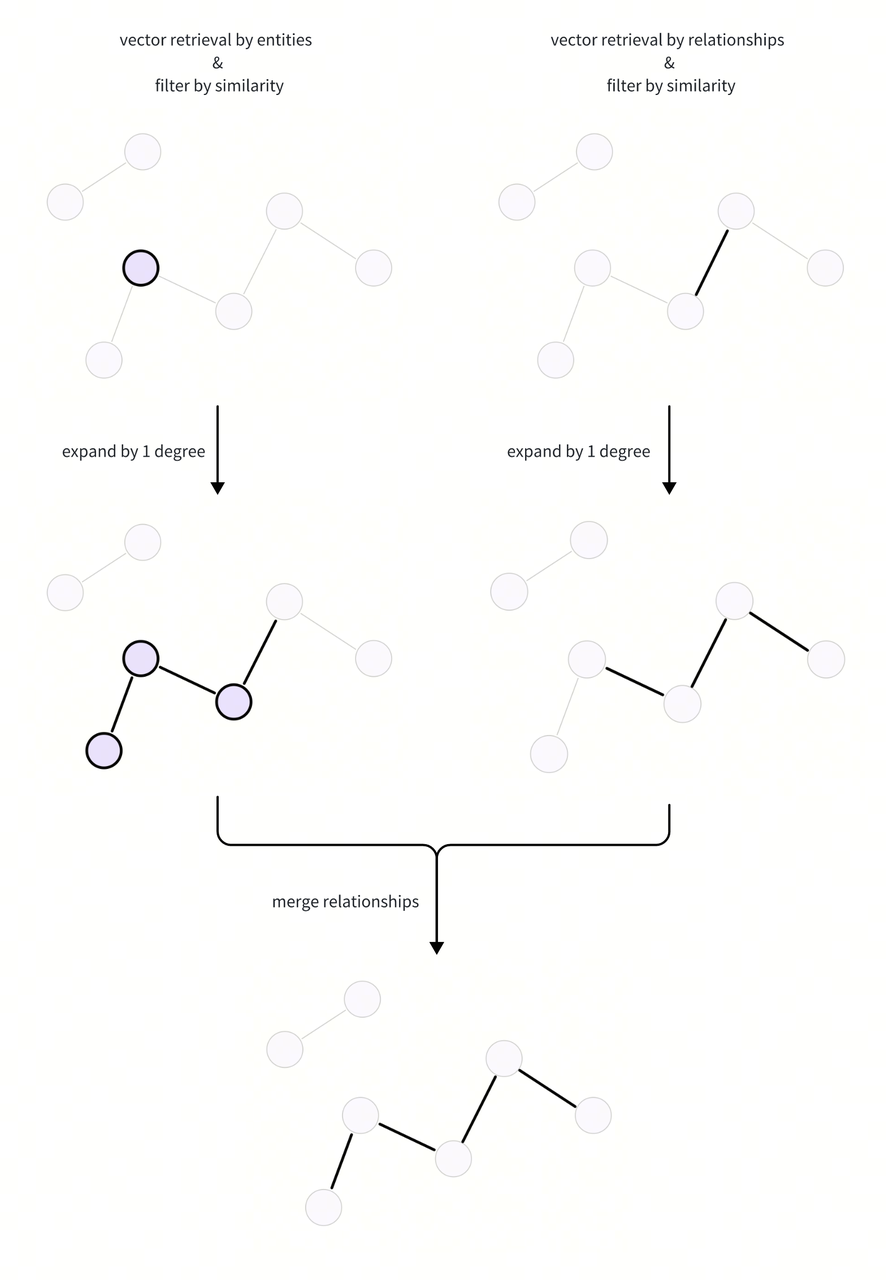
Expanding subgraph from two retrieved ways, then merged them together
我们以搜索到的 entities 和 relationships 为知识图谱里的起始,往外扩大一定的范围。对于起始 entities,我们往外扩大一定的跳数后,取它们邻接的 relationships,记为
对于起始 relationships,我们往外扩大一定跳数,得到
我们将两个 set 取并集,
基于跳数有限性,我们仅需要扩大较小的度数(如1,2等),就能涵盖大部分可能有助回答的 relationships。请注意,这一步扩展的度数的概念和回答问题总共需要的跳度的概念不同。比如,如果回答一个 query 问题涉及两个相差 n 跳的 entities,那么实际上往往只需要扩展 ⌈n / 2⌉ 度就可以,因为这两个 entities 是被向量相似召回后的两个起始端点。如图,向量召回到了两个红色的 entities,只需要从它们开始,相向扩展 2 度,就能覆盖到 4 度的跳数,这足以回答涉及到这两个 entities 的 4 跳问题。
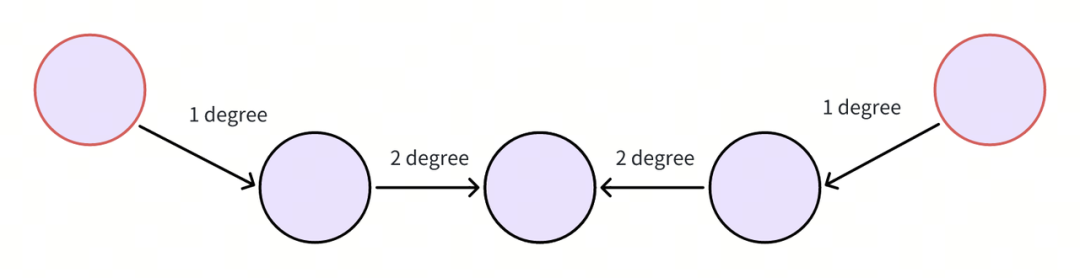
In fact, to answer the question with 4 degree hops, you only need to expand it by 2 degrees from both end points in the setting.
4.4. LLM Rerank
这一步中,我们使用 LLM 强大的自注意力机制,完成对 relationships 候选集的进一步筛选。我们使用 one-shot prompt,将 query 和 relationships 候选集放入 prompt 里,要求 LLM 从中选择出可能对回答这个 query 有帮助的 relationships。考虑到有些 query 可能存在一定的复杂性,我们采用 Chain-of-Thought 的思想,让 LLM 的回答里写下思考过程,我们观察到,这一方法对一些偏弱的模型有一些帮助。我们规定 LLM 的返回为 json 格式,以便于解析格式。具体的 prompt 参考如下:
One shot input prompt
I will provide you with a list of relationship descriptions. Your task is to select 3 relationships that may be useful to answer the given question. Please return a JSON object containing your thought process and a list of the selected relationships in order of their relevance.
**Question:**
When was the mother of the leader of the Third Crusade born?
**Relationship descriptions:**
[1] Eleanor was born in 1122.
[2] Eleanor married King Louis VII of France.
[3] Eleanor was the Duchess of Aquitaine.
[4] Eleanor participated in the Second Crusade.
[5] Eleanor had eight children.
[6] Eleanor was married to Henry II of England.
[7] Eleanor was the mother of Richard the Lionheart.
[8] Richard the Lionheart was the King of England.
[9] Henry II was the father of Richard the Lionheart.
[10] Henry II was the King of England.
[11] Richard the Lionheart led the Third Crusade.
One shot input prompt
{
"thought_process": "To answer the question about the birth of the mother of the leader of the Third Crusade, I first need to identify who led the Third Crusade and then determine who his mother was. After identifying his mother, I can look for the relationship that mentions her birth.",
"useful_relationships": [
"[11] Richard the Lionheart led the Third Crusade",
"[7] Eleanor was the mother of Richard the Lionheart",
"[1] Eleanor was born in 1122"
]
}
这个 prompt 是一个展示的参考,实际上,如何把 relationships 中的三元组转成一个通顺的短句,是一个棘手的问题。但是,你完全可以用上文提到的启发性的方法,把三元组直接拼在一起。如:
(Eleanor, born in, 1122) 可以直接转成 Eleanor born in 1122
这种方式有时会带来一定的语法问题,但它是最快,最直接的方式,也不会对 LLM 带来误解。
4.5. 获得最终 passages
对于上面的例子,实际上可以在 LLM rerank 这个阶段直接返回最终的回答,比如在 One shot output prompt 的 json 字段里加上比如 “final answer”的字段。但是,这一步的 prompt 里只有 relationship 的信息,不一定所有问题都可以在这个阶段返回最终答案,所以其它具体的信息应该要在原始的 passsage 里获得。
LLM 返回精确排序后的 relationships。我们只需要取出先前在存储中的对应 relationship 信息,从中获取相应的 metadata,在那里有对应的 passage ids。这些 passages 信息就是最终被 retrieved 到的 passages。后续生成回答的过程和 naive RAG 一样,就是将它们放入 prompt 的 context 中,让 LLM 给出最后的回答。
05.结果
我们使用与 HippoRAG 中一致的 dense embedding,facebook/contriever,来作为我们的 embedding 模型,可以看到,在三个 multi-hop 的数据集上结果比较上,我们的方法大幅超过 naive RAG 和 HippoRAG 的结果。所有的方法使用相同的 embedding 模型设置。我们使用 Recall@2 作为我们的衡量指标,它表示,
Recall(召回率) = 检索到的相关文档总数/数据存储中相关文档总数
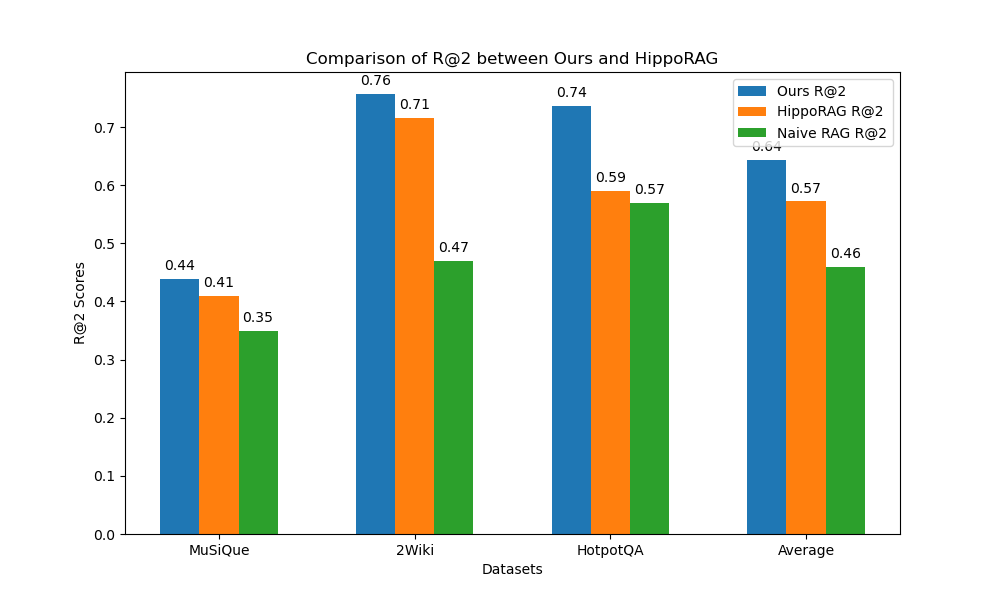
On the multi-hop datasets, our method outperforms naive RAG and HippoRAG in all datasets, all of them are compared using the same facebook/contriever embedding model.
这一结果说明了,即使是最简单的多路召回然后 rerank 的 RAG 范式,应用在 graph RAG 的场景上,也能得到 state-of-the-art 的 performance。这一结果也说明了,合理的向量召回和 LLM 设置,是应用在 multi-hop QA 场景中的关键。
回顾我们的方法,把 entities 和 relationships 转成向量,并进行搜索的作用就是寻找子图的起点,它像是破解刑侦案件中的现场发现的“线索”。而后面扩展子图和 LLM rerank 的过程像是具体通过这些“线索”进行分析的过程,LLM 拥有“上帝视角”,可以在一众的候选 relationships 中,聪明地选择对破案有用的 relationships。这两个阶段,回归本质,也就是对应朴素的 vector retrieval + LLM reranking 范式。
在实践中,我们推荐大家使用开源 Milvus,或它的全托管版本 Zilliz Cloud,来存储并搜索 graph 结构中大量的 entities 和 relationships。而 LLM 可以选择开源模型如 Llama-3.1-70B 或闭源的 GPT-4o mini,中等以上规模的模型都能胜任这些任务。你也可以参考我们的 notebook 代码示例https://milvus.io/docs/graph_rag_with_milvus.md,以获得更多实现的细节。
如何学习AI大模型 ?
“最先掌握AI的人,将会比较晚掌握AI的人有竞争优势”。
这句话,放在计算机、互联网、移动互联网的开局时期,都是一样的道理。
我在一线互联网企业工作十余年里,指导过不少同行后辈。帮助很多人得到了学习和成长。
我意识到有很多经验和知识值得分享给大家,故此将并将重要的AI大模型资料。包括AI大模型入门学习思维导图、精品AI大模型学习书籍手册、视频教程、实战学习等录播视频免费分享出来。【保证100%免费】🆓
对于0基础小白入门:
如果你是零基础小白,想快速入门大模型是可以考虑的。
一方面是学习时间相对较短,学习内容更全面更集中。
二方面是可以根据这些资料规划好学习计划和方向。
😝有需要的小伙伴,可以VX扫描下方二维码免费领取🆓
👉1.大模型入门学习思维导图👈
要学习一门新的技术,作为新手一定要先学习成长路线图,方向不对,努力白费。
对于从来没有接触过AI大模型的同学,我们帮你准备了详细的学习成长路线图&学习规划。可以说是最科学最系统的学习路线,大家跟着这个大的方向学习准没问题。(全套教程扫描领取哈)
👉2.AGI大模型配套视频👈
很多朋友都不喜欢晦涩的文字,我也为大家准备了视频教程,每个章节都是当前板块的精华浓缩。

👉3.大模型实际应用报告合集👈
这套包含640份报告的合集,涵盖了AI大模型的理论研究、技术实现、行业应用等多个方面。无论您是科研人员、工程师,还是对AI大模型感兴趣的爱好者,这套报告合集都将为您提供宝贵的信息和启示。(全套教程扫描领取哈)
👉4.大模型落地应用案例PPT👈
光学理论是没用的,要学会跟着一起做,要动手实操,才能将自己的所学运用到实际当中去,这时候可以搞点实战案例来学习。(全套教程扫描领取哈)
👉5.大模型经典学习电子书👈
随着人工智能技术的飞速发展,AI大模型已经成为了当今科技领域的一大热点。这些大型预训练模型,如GPT-3、BERT、XLNet等,以其强大的语言理解和生成能力,正在改变我们对人工智能的认识。 那以下这些PDF籍就是非常不错的学习资源。(全套教程扫描领取哈)

👉6.大模型面试题&答案👈
截至目前大模型已经超过200个,在大模型纵横的时代,不仅大模型技术越来越卷,就连大模型相关的岗位和面试也开始越来越卷了。为了让大家更容易上车大模型算法赛道,我总结了大模型常考的面试题。(全套教程扫描领取哈)
👉学会后的收获:👈
• 基于大模型全栈工程实现(前端、后端、产品经理、设计、数据分析等),通过这门课可获得不同能力;
• 能够利用大模型解决相关实际项目需求: 大数据时代,越来越多的企业和机构需要处理海量数据,利用大模型技术可以更好地处理这些数据,提高数据分析和决策的准确性。因此,掌握大模型应用开发技能,可以让程序员更好地应对实际项目需求;
• 基于大模型和企业数据AI应用开发,实现大模型理论、掌握GPU算力、硬件、LangChain开发框架和项目实战技能, 学会Fine-tuning垂直训练大模型(数据准备、数据蒸馏、大模型部署)一站式掌握;
• 能够完成时下热门大模型垂直领域模型训练能力,提高程序员的编码能力: 大模型应用开发需要掌握机器学习算法、深度学习
这份完整版的 AI 大模型学习资料已经上传CSDN,朋友们如果需要可以微信扫描下方CSDN官方认证二维码免费领取【保证100%免费】
😝有需要的小伙伴,可以Vx扫描下方二维码免费领取🆓

欢迎加入DeepSeek 技术社区。在这里,你可以找到志同道合的朋友,共同探索AI技术的奥秘。
更多推荐


 25
25 0
0- 0



 已为社区贡献16条内容
已为社区贡献16条内容

所有评论(0)