RAG及使用LangChain实现RAG应用开发示例
比如,对检索的结果借助更专业的排序模型与算法进行重排序或者过滤掉一些不符合条件的知识块等,使得最需要、最合规的知识块处于上下文的最前端,这有助于提高大模型的输出质量。(2)生成(Generation):生成的核心是大模型,可以是本地部署的大模型,也可以是基于 API 访问的远程大模型。(1)检索(Retrieval):检索的作用是借助数据索引(比如向量存储索引),从存储库(比如向量库)中检索出相关
RAG
RAG 既可以是一种独立的应用形态,也可以是在开发更复杂的 AI 智能体时所依赖的一种常见的设计范式或架构。
大模型的底层技术原理决定了其在自然语言理解与处理能力上带来了革命性提升,但也带来了一些天然存在,甚至“很难根治的疾病”。大模型不是无所不能的,还需要进行提升和优化。知识的时效性问题,输出难以解释的“黑盒子”问题,输出的不确定性问题,著名的“幻觉”问题。
RAG(知识检索增强)允许大模型在生成内容时可以依赖实时与个性化的数据和知识,而不只是依赖训练知识
在通常情况下,可以把开发一个简单的 RAG 应用从整体上分为数据索引(Indexing)与数据查询(Query)两个大的阶段
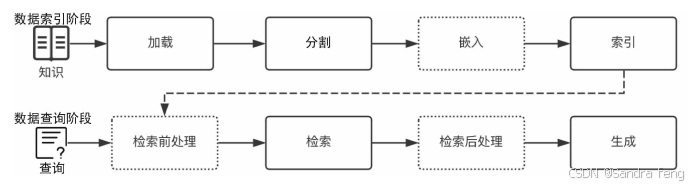
1. 数据索引阶段通常使用向量存储索引,数据索引通常包括以下几个阶段:
(1)加载(Loading):RAG 应用需要的知识可能以不同的形式与模态存在,可以是结构化的、半结构化的、非结构化的、存在于互联网上或者企业内部的、普通文档或者问答对。因此,对这些知识,需要能够连接与读取内容。
(2)分割(Splitting):为了更好地进行检索,需要把较大的知识内容Word/PDF 文档、一个 Excel 文档、一个网页或者数据库中的表等)进行分割,然后对这些分割的知识块(通常称为 Chunk)进行索引。当然,这就会涉及一系列的分割规则,比如知识块分割成多大最合适?在文档中用什么标记一个段落的结尾?
(3)嵌入(Embedding):如果你需要开发 RAG 应用中最常见的向量存储索引,那么需要对分割后的知识块做嵌入。简单地说,就是把分割后的知识块转换为一个高维(比如 1024 维等)的向量。嵌入的过程需要借助商业或者开源的嵌入模型(Embedding Model)来完成,比如 OpenAI 的 text-embedding-3-small 模型。
(4)索引(Indexing):对于向量存储索引来说,需要将嵌入阶段生成的向量存储到内存或者磁盘中做持久化存储。在实际应用中,通常建议使用功能全面的向量数据库(简称向量库)进行存储与索引。向量库会提供强大的向量检索算法与管理接口,这样可以很方便地对输入问题进行语义检索。注意:在高级的 RAG 应用中,索引形式往往并不只有向量存储索引这一种。因此,在这个阶段,很多应用会根据自身的需要来构造其他形式的索引,比如知识图谱索引、关键词表索引等。
2.数据查询阶段
在数据索引准备完成后,RAG 应用在数据查询阶段的两大核心阶段是检索与生成(也称为合成)。
(1)检索(Retrieval):检索的作用是借助数据索引(比如向量存储索引),从存储库(比如向量库)中检索出相关知识块,并按照相关性进行排序,经过排序后的知识块将作为参考上下文用于后面的生成。
检索前处理(Pre-Retrieval):顾名思义,这是检索之前的步骤。在一些优化的 RAG 应用流程中,检索前处理通常用于完成诸如查询转换、查询扩充、检索路由等处理工作,其目的是为后面的检索与检索后处理做必要准备,以提高检索阶段召回知识的精确度与最终生成的质量。
检索后处理(Post-Retrieval):与检索前处理相对应,这是在完成检索后对检索出的相关知识块做必要补充处理的阶段。比如,对检索的结果借助更专业的排序模型与算法进行重排序或者过滤掉一些不符合条件的知识块等,使得最需要、最合规的知识块处于上下文的最前端,这有助于提高大模型的输出质量。
(2)生成(Generation):生成的核心是大模型,可以是本地部署的大模型,也可以是基于 API 访问的远程大模型。生成器根据检索阶段输出的相关知识块与用户原始的查询问题,借助精心设计的 Prompt,生成内容并输出结果。
RAG的挑战
检索找回的精确度、大模型自身抗干扰能力、大模型存在输入和输出上下文窗口的限制(最大 token 数量)?RAG 与微调,应该如何选择、配合、协调以便最大限度地提高大模型的输出能力呢?如何兼顾最终输出的质量与较短的响应延迟时间?
RAG应用开发框架-LangChain 框架
https://docs.langchain.com.cn/docs/introduction/框架的自我介绍
提供了聊天模型,检索器,工具包,文档加载器,嵌入模型等
LangChain 框架开发RAG应用
import chromadb
from langchain_community.llms import Ollama
from langchain_community.embeddings import OllamaEmbeddings
from langchain import hub
from langchain_community.vectorstores import Chroma
from langchain_core.output_parsers import StrOutputParser
from langchain_core.runnables import RunnablePassthrough
from langchain_text_splitters import RecursiveCharacterTextSplitter
from langchain_community.document_loaders import DirectoryLoader
from langchain_community.document_loaders import TextLoader
#模型
llm = Ollama(model="qwen:14b")
embed_model =
OllamaEmbeddings(model="milkey/dmeta-embedding-zh:f16")
#加载与读取文档
loader = DirectoryLoader('../../data/',
glob="*.txt",exclude="*tips*.txt",loader_cls=TextLoader)
documents = loader.load()
#分割文档
text_splitter = RecursiveCharacterTextSplitter(chunk_size=500,
chunk_overlap=20)
splits = text_splitter.split_documents(documents)
#准备向量存储
chroma = chromadb.HttpClient(host="localhost", port=8000)
chroma.delete_collection(name="ragdb")
collection = chroma.get_or_create_collection(name="ragdb",
metadata={"hnsw:space": "cosine"})
db =\
Chroma(client=chroma,collection_name="ragdb",embedding_function=e
mbed_model)
#存储到向量库中,构造索引
db.add_documents(splits)
#使用检索器
retriever = db.as_retriever()
#构造一个 RAG“链”(使用 LangChain 框架特有的组件与表达语言)
prompt = hub.pull("rlm/rag-prompt")
rag_chain = (
{"context": retriever | (lambda docs:
"\n\n".join(doc.page_content for doc in docs)), "question":
RunnablePassthrough()}
| prompt
| llm
| StrOutputParser()
)
while True:
user_input = input("问题:")
if user_input.lower() == "exit":
break
response = rag_chain.invoke(user_input)
print("AI 助手:", response)
Chroma 是一款强大的、高性能的开源嵌入式向量库,提供了方便的接口用于存储与检索向量和相关的元数据。

欢迎加入DeepSeek 技术社区。在这里,你可以找到志同道合的朋友,共同探索AI技术的奥秘。
更多推荐



 9
9 0
0- 0



 已为社区贡献1条内容
已为社区贡献1条内容

所有评论(0)