网络安全之信息收集 之完整版
域名(Domain Name),简称域名、网域,是由一串用点分隔的名字组成的Internet上某一台计算机或计算机组的名称,用于在数据传输时标识计算机的电子方位(有时也指地理位置)。DNS(域名系统,Domain Name System)是互联网的一项服务。它作为将域名和IP地址相互映射的一个分布式数据库,能够使人更方便地访问互联网。域名分类顶级域名:.com二级域名: baidu.com三级域名
1.什么是信息收集
1.信息收集是指通过各种方式获取所需要的信息,以便我们在后续的渗透过程更好的进行。比如目标站点IP、中间件、脚本语言、端口、邮箱等等。信息收集包含资产收集但不限于资产收集。
-
信息收集的意义
信息收集是渗透测试成功的保障更多的暴露面 更大的可能性 -
信息收集分类
主动信息收集
通过直接访问网站在网站上进行操作、对网站进行扫描等,这种是有网络流量经过目标服务器的信息收集方式。
被动信息收集
基于公开的渠道,比如搜索引擎等,在不与目标系统直接交互的情况下获取信息,并且尽量避免留下痕迹。
- 收集哪些信息
域名信息(whois、备案信息、子域名)
服务器信息(端口、服务、真实IP)
网站信息(网站架构、操作系统、中间件、数据库、编程语言、指纹信息、
WAF、敏感目录、敏感文件、源码泄露、旁站、C段)
管理员信息(姓名、职务、生日、联系电话、邮件地址)
2.域名介绍
域名(Domain Name),简称域名、网域,是由一串用点分隔的名字组成的Internet上某一台计算机或计算机组的名称,用于在数据传输时标识计算机的电子方位(有时也指地理位置)。
DNS(域名系统,Domain Name System)是互联网的一项服务。它作为将域名和IP地址相互映射的一个分布式数据库,能够使人更方便地访问互联网。
域名分类
顶级域名:.com
二级域名: baidu.com
三级域名: www.baidu.com
政府域名:.gov
商业域名:.com
教育域名: .edu
二级域名是指顶级域名之下的域名,在国际顶级域名下,它是指域名注册人的网上名称,例如 ibm,yahoo,microsoft等;在国家顶级域名下,它是表示注册企业类别的符号,例如com,top,edu,gov,net等
3. whois查询
1.whois解释
whois是用来查询域名的IP以及所有者等信息的传输协议。简单说,whois就是一个用来查询域名是否已经被注册,以及注册域名的详细信息的数据库(如域名所有人、域名注册商)。
- whois收集
在线网站查询 输入相关的域名即可进行查询。
1.站长之家:http://whois.chinaz.com/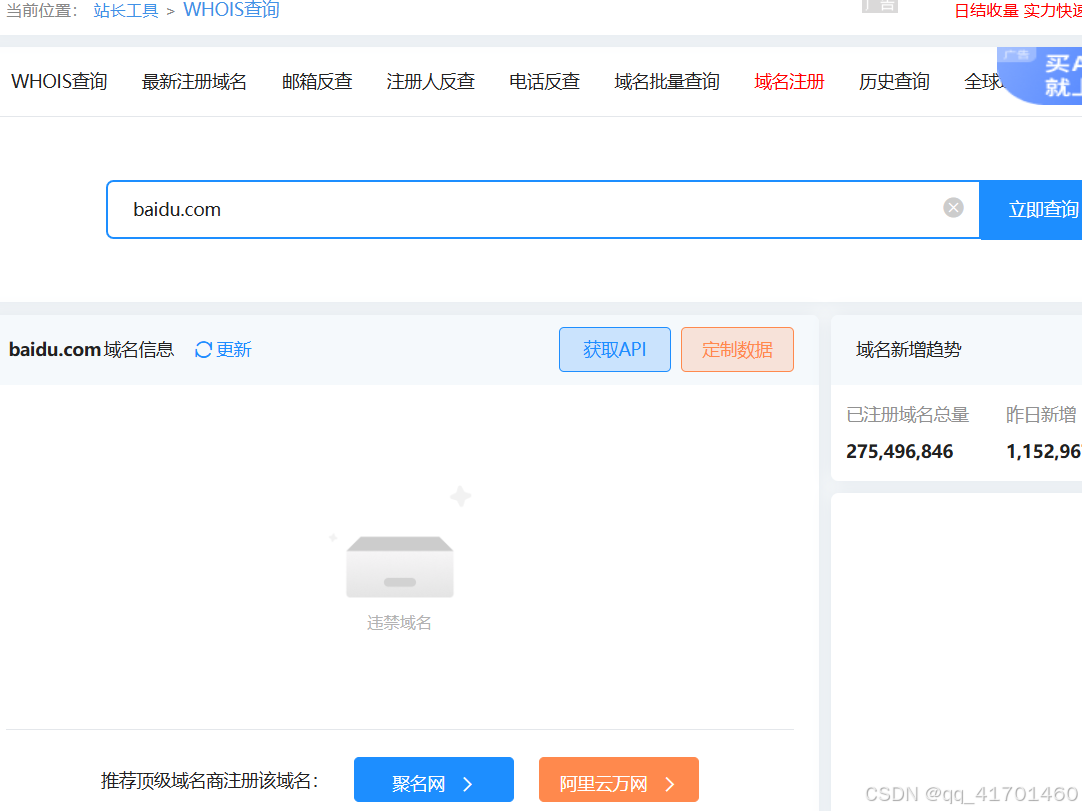
2.爱站工具网:https://whois.aizhan.com/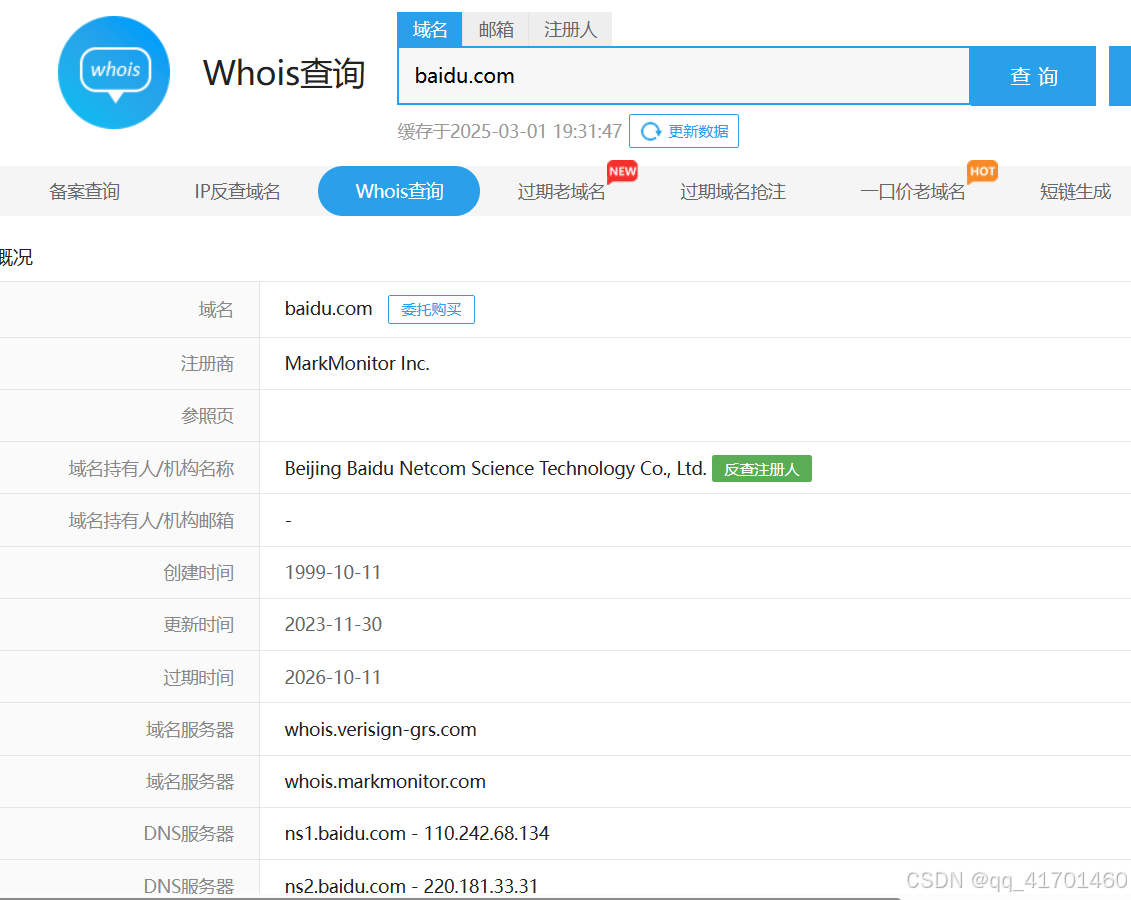
3.阿里云:https://whois.aliyun.com/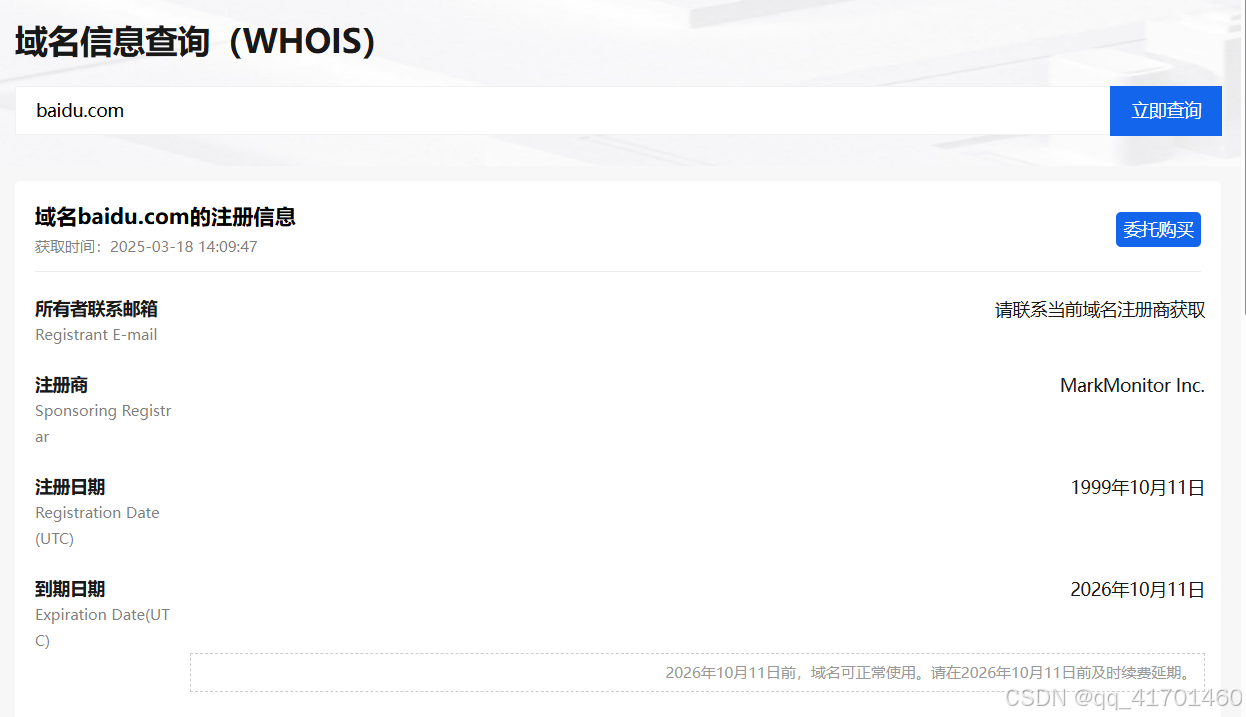
4.kail查询:whois+域名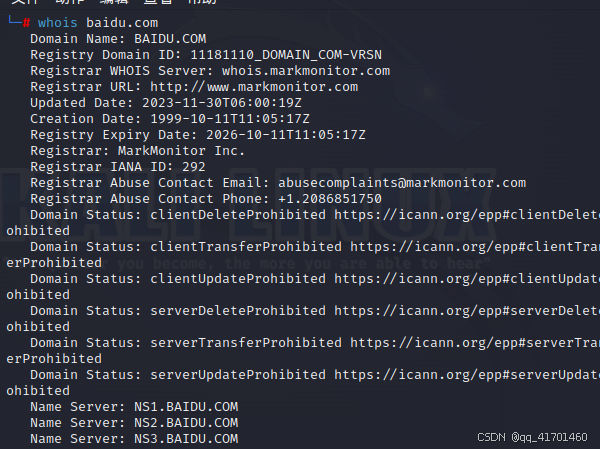
5.kail查询:dnsenum+域名
Dnsenum 是一款用于 DNS 信息收集和枚举的工具。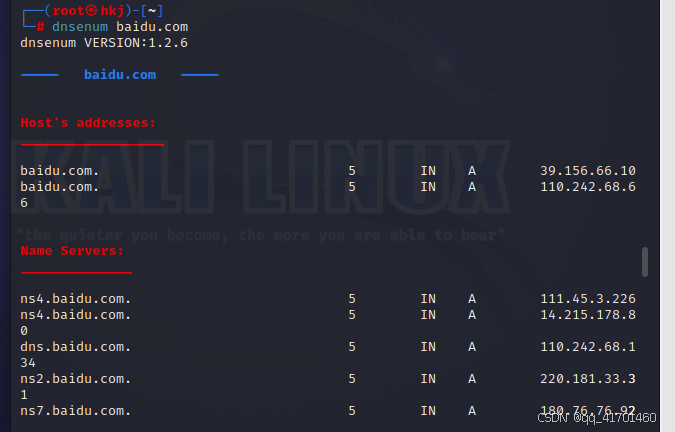
6.Python脚本查询
import whois
domain = input(“输入查询 Whois 的域名:”)
data = whois.whois(domain)
print(“域名:%s” % data[‘domain_name’])
print(“邮箱:%s” % data[“emails”])
print(“注册人:%s” % data[‘org’])
print(“注册时间:%s” % data[‘creation_date’])
print(“更新时间:%s” % data[‘updated_date’])
3. Whois反查
whois反查,可以通过注册人、注册人邮箱、注册人手机电话反查whois信息
先通过whois获取注册人和邮箱,再通过注册人和邮箱反查域名。
缺点是很多公司都是DNS解析的运营商注册的,查到的是运营商代替个人和公司注册
的网站信息
1.https://whois.chinaz.com/reverse/email
2.http://whois.4.cn/reverse
3.https://whois.aizhan.com/
4.备案信息查询
1.备案信息解释
备案是指向主管机关报告事由存案以备查考。行政法角度看备案,实践中主要是《立法法》和《法规规章备案条例》的规定。根据中华人民共和国信息产业部第十二次部务会议审议通过的《非经营性互联网信息服务备案管理办法》精神,在中华人民共和国境内提供非经营性互联网信息服务,应当办理备案。未经备案,不得在中华人民共和国境内从事非经营性互联网信息服务。而对于没有备案的网站将予以罚款和关闭。
备案号是网站是否合法注册经营的标志,可以用网页的备案号反查出该公司旗下的资产
2.备案信息收集
输入相关的网站域名、备案编号、主办单位等信息。
1.天眼查:https://beian.tianyancha.com/
2.ICP备案查询网:https://www.beianx.cn/
3.https://beian.miit.gov.cn/#/Integrated/index
4.https://beian.mps.gov.cn/#/query/webSearch
5.https://icp.chinaz.com/
6.https://icplishi.com/
5.子域名收集
-
子域名解释
子域名是顶级域名的下一级,子域名主要指的是二级域名。当一个网站比较大的情况下,直接通过顶级域名进行入手可能会比较困难,但是对于比较大的网站都可能会存在相当多的二级域名,并且顶级域名相对来说防范也比较严格,而二级域名可能就会存在防范不是那么严格的情况。 -
子域名收集
在线网站收集
1.子域名在线查询:https://searchdns.netcraft.com/
2.子域名在线查询:https://dnsdumpster.com/
3.子域名在线查询:https://www.dnsgrep.cn/
4.https://docs.virustotal.com/reference/domains-relationships
5.https://tool.chinaz.com/subdomain
6.https://www.nmmapper.com/sys/tools/subdomainfinder/
7.https://fofa.info/
8.https://www.zoomeye.org/
9.https://hunter.qianxin.com/
10.https://www.shodan.io/
11.https://crt.sh/ (SSL证书查询)
12.JS文件发现子域名 https://github.com/Threezh1/JSFinder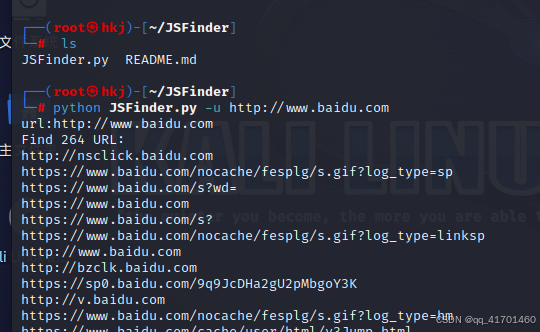
3.工具收集
1.Layer子域名挖掘机
子域名挖掘机,是否能够挖掘到关键不在于工具本身,而在于收到的字典,字典越好,收集到的信息就越多,所以在日常中,需要常收集相关的字典。
2.开源扫描器onlinetools
开源扫描器onlinetools,输入域名即可查询。
开源地址:https://github.com/iceyhexman/onlinetools
有些在git上就需要上去看说明 有教程 或者百度查看
-
OneForAll
https://github.com/shmilylty/OneForAll -
Subdomainsbrute
高并发的DNS暴力枚举工具
https://github.com/lijiejie/subDomainsBrute -
Sublist3r
https://github.com/aboul3la/Sublist3r -
ESD
https://github.com/FeeiCN/ESD -
dnsbrute
https://github.com/Q2h1Cg/dnsbrute -
Anubis
https://github.com/jonluca/Anubis -
subdomain3
https://github.com/yanxiu0614/subdomain3 -
teemo
https://github.com/bit4woo/teemo -
Sudomy
https://github.com/screetsec/Sudomy -
ARL
https://github.com/TophantTechnology/ARL -
SubFinder + KSubdomain + HttpX
SubFinder:用来查询域名的子域名信息的工具,可以使用很多国外安全网站的api接口进行自动化搜索子域名信息。
https://github.com/projectdiscovery/subfinder
HttpX:一款运行速度极快的多功能HTTP安全工具,它可以使用retryablehttp库来运行多种网络探针,并使用了多线程机制来维持运行的稳定性和结果的准确性。
https://github.com/projectdiscovery/httpx
ksubdomain是一款基于无状态子域名爆破工具,支持在Windows/Linux/Mac上使用,它会很快的进行DNS爆破,在Mac和Windows上理论最大发包速度在30w/s,linux上为160w/s的速度。
https://github.com/knownsec/ksubdomain
14.Google语法搜索
site:搜索范围限制在某网站或顶级域名中
inur!:当我们用inurl进行查询的时候,Google会返回那些在URL(网址)里边包含了我们查询关键词的网页。
intext: 当我们用intext进行查询的时候,Google会返回那些在文本正文里边包含了我们查询关键词的网页。
intitle:当我们用intite进行查询的时候,Google会返回那些在网页标题为查询结果
site功能:搜索指定的域名网页内容,子网和网页相关的
site:网站 “想查询的信息”
site:baidu.com
6.IP获取/信息收集
- ping
通过ping收集相关的服务器IP地址,但是通过ping获取到的IP不一定是真实的。
语法:ping+域名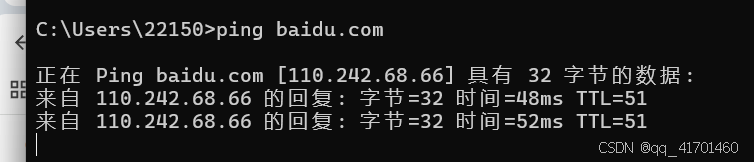
2.1.2. nslookup
通过nslookup收集到的IP地址同样也不一定是真实的。并且命令也提示非权威答应。
语法:nslookup 进入后输入域名。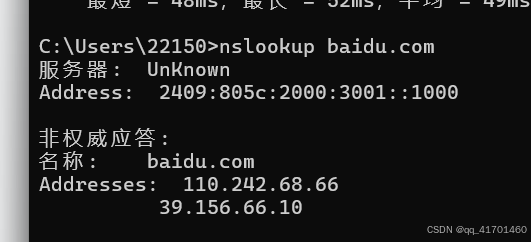
7.CND绕过
- CND解释
CDN的全称Content Delivery Network,即内容分发网络,CDN的基本原理是广泛采用各种缓存服务器,将这些缓存服务器分布到用户访问的网络中,在用户访问网站时,由距离最近的缓存服务器直接响应用户请求。
方法:
1.多地ping,用各种多地 ping 的服务,查看对应 IP 地址是否唯一
2. 国外访问,有些网站设置CDN可能没有把国外的访问包含进去,所以可以这么绕过
3. 查询子域名的IP, CDN 流量收费高,所以很多站长可能只会对主站或者流量大的子站点做了 CDN,而很多小站子站点又跟主站在同一台服务器或者同一个C段内,此时就可以通过查询子域名对应的 IP 来辅助查找网站的真实IP
4. MX记录邮件服务。MX记录是一种常见的查找IP的方式。如果网站在与web相同的服务器和IP上托管自己的邮件服务器,那么原始服务器IP将在MX记录中。
5.查询历史DNS记录。查看 IP 与 域名绑定的历史记录,可能会存在使用 CDN 前的记录;
- 真实IP信息收集
(1)超级ping:https://ping.chinaz.com/
2.http://www.webkaka.com/Ping.aspx
(3)查询网:查询网:https://site.ip138.com/baidu.com/
(4)IP查询:IP查询:https://ipchaxun.com/
3.https://ip.tool.chinaz.com/
4.站长之家 https://ip.chinaz.com/
5.https://www.dnsgrep.cn/
6.https://tools.ipip.net/ipdomain.php
7.https://tool.chinaz.com/same
8.查询历史DNS记录:
域名注册完成后首先需要做域名解析,域名解析就是把域名指向网站所在服务器的IP,让人们通过注册的域名可以访问到网站。
IP地址是网络上标识服务器的数字地址,为了方便记忆,使用域名来代替IP地址。
域名解析就是域名到IP地址的转换过程,域名的解析工作由DNS服务器完成。
DNS服务器会把域名解析到一个IP地址,然后在此IP地址的主机上将一个子目录与域名绑定。
域名解析时会添加解析记录,这些记录有:A记录、AAAA记录、CNAME记录、MX
记录、NS记录、TXT记录。
类型说明:https://developer.aliyun.com/article/331012
A记录
用来指定主机名(或域名)对应的IP地址记录
通俗来说A记录就是服务器的IP,域名绑定A记录就是告诉DNS,当你输入域名的时候给你引导向设置在DNS的A记录所对应的服务器。
NS记录
域名服务器记录,用来指定该域名由哪个DNS服务器来进行解析。
MX记录
邮件交换记录,它指向一个邮件服务器,用于电子邮件系统发邮件时根据收信人的地址后缀来定位邮件服务器。
CNAME记录
别名记录,允许您将多个名字映射到同一台计算机
TXT记录
一般指某个主机名或域名的说明
泛域名与泛解析
泛域名是指在一个域名根下,以 .Domain.com的形式表示这个域名根所有未建立
的子域名。 泛解析是把*.Domain.com的A记录解析到某个IP 地址上,通过访问任
意的前缀.domain.com都能访问到你解析的站点上。
域名绑定
域名绑定是指将域名指向服务器IP的操作
1.https://securitytrails.com/
2.https://viewdns.info/iphistory/
3.https://www.ip138.com/
C段旁注
- C段旁注解释
C段旁注就是在对目标主机无计可施的时候,另辟蹊径从C段或旁注下手,C段也就是拿下同一C段也就是同一网段内其它服务器,然后从这台服务器对目标主机进行测试,
旁注同服务器上的其它站点入手,进行相关的渗透获取权限,然后把服务器拿下,同理自然也就将目标主机拿下。
两者有着不同的区别,C段是同网段不同服务器,旁注是同服务器不同站点。
93.2. C段旁注收集
3.2.1. 在线查询
1.C段旁注:同IP网站查询:https://www.webscan.cc/
- 工具查询
(1)开源扫描器onlinetools
开源扫描器onlinetools,输入域名即可查询,至于怎么安装可以查询文档或者百度搜索。
开源地址:https://github.com/iceyhexman/onlinetools
9. 网站架构
- 网站架构解释
针对整个网站架构进行信息收集:服务器操作系统、网站服务组件、脚本类型、CMS类型、WAF等信息。
操作系统
1.ping判断:windows的TTL值一般为128,Linux则为64。
TTL大于100的一般为windows,几十的一般为linux。
2.nmap -O参数
2. windows大小写不敏感,linux则区分大小写
网站服务、容器类型
3. F12查看响应头Server字段
2… whatweb https://www.whatweb.net/
4. wappalyzer插件
5.
apache ,nginx ,tomcat,IIS
通过容器类型、版本可考虑对应容器存在的漏洞(解析漏洞)
114.2. 网站架构收集
4.2.1. 工具收集
(1)kail收集:nmap -sV ip地址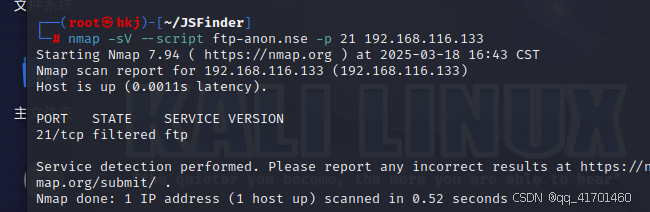
(2)kail收集:whatweb+域名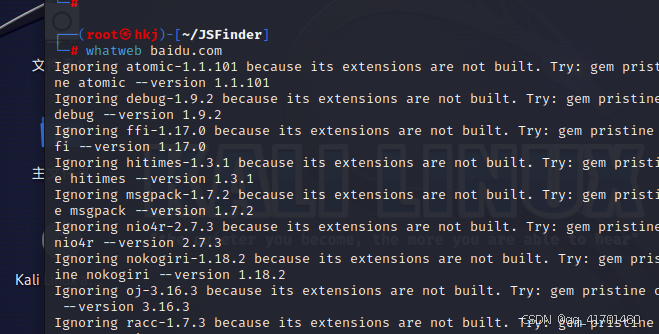
(3)御剑WEB指纹识别系统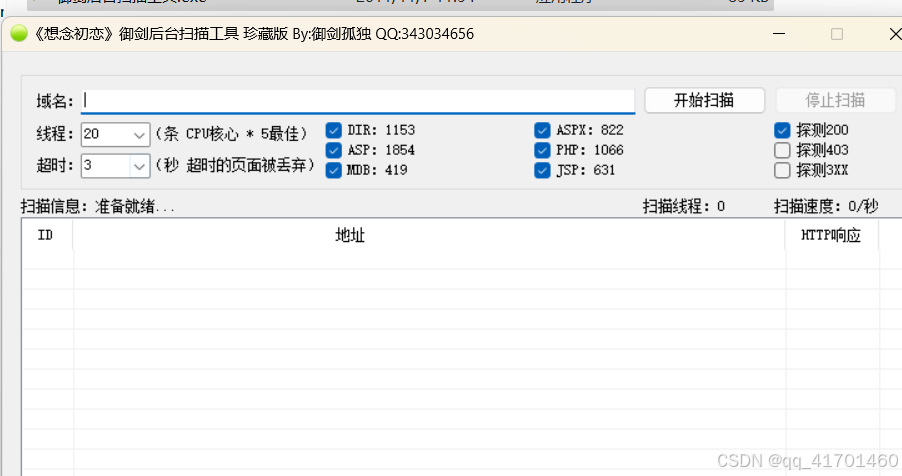
4.2.2. 插件收集
(1)Wappalyzer
4.2.3. 在线查询
(1)在线查询:在线cms指纹识别:http://whatweb.bugscaner.com/look/
(2)云悉:在线指纹识别:https://www.yunsee.cn/
(3)潮汐:在线指纹识别:http://finger.tidesec.net/
10. 端口
- 端口解释
一个网站可能会开放多个不通的端口,而对一个网站进行测试的时候,一个端口不行可以换一个端口进行测试,多个端口就存在多个可能。
在Internet上,各主机间通过TCP/IP协议发送和接受数据包,各个数据包根据其目的主机的IP地址来进行互联网络中的路由选择,从而顺利的将数据包顺利的传送给目标主机
但当目的主机运行多个程序时,目的主机该把接受到的数据传给多个程序进程中的哪
一个呢?
端口机制的引入就是为了解决这个问题。端口在网络技术中,
端口有两层意思:一个是物理端口,即物理存在的端口,如:集线器、路由器、交换机、ADSL
Modem等用于连接其他设备的端口;
另一个就是逻辑端口,用于区分服务的端口,
一般用于TCP/IP中的端口,其范围是0~65535,,0为保留端口,一共允许有65535个
端口比如用于网页浏览服务的端口是80端口,用于FTP服务的是21端口。
这里我们所指的不是物理意义上的端口,而是特指TCP/IP协议中的端口,是逻辑意义上的端口
协议端口
根据提供服务类型的不同,端口可分为以下两种:
TCP端口:TCP是一种面向连接的可靠的传输层通信协议
UDP端口:UDP是一种无连接的不可靠的传输层协议
TCP协议和UDP协议是独立的,因此各自的端口号也互相独立。
TCP:给目标主机发送信息之后,通过返回的应答确认信息是否到达
UDP:给目标主机放信息之后,不会去确认信息是否到达
而由于物理端口和逻辑端口数量较多,为了对端口进行区分,将每个端口进行了编号,即就是端口号。那么看到这里我们会好奇,有那么多的端口,他们到底是怎么分类的?
端口类型
周知端口:众所周知的端口号,范围:0-1023,如80端口是WWW服务
动态端口:一般不固定分配某种服务,范围:49152-65535
注册端口:范围:1024-49151,用于分配给用户进程或程序
渗透端口
https://www.cnblogs.com/bmjoker/p/8833316.html
常见端口介绍
FTP-21
FTP:文件传输协议,使用TCP端口20、21,20用于传输数据,21用于传输控制信息
(1)ftp基础爆破:owasp的Bruter,hydra以及msf中的ftp爆破模块。
(2) ftp匿名访问:用户名:anonymous 密码:为空或者任意邮箱
(3)vsftpd后门 :vsftpd 2到2.3.4版本存在后门漏洞,通过该漏洞获取root权限。
(4)嗅探:ftp使用明文传输,使用Cain进行渗透。(但是嗅探需要在局域网并需要欺骗或监听网关)
(5)ftp远程代码溢出。
(6)ftp跳转攻击。
漏洞复现-vsftpd-v2.3.4: https://www.freebuf.com/column/143480.html
ProFTPD 1.3.3c远程命令执行:https://blog.csdn.net/weixin_42214273/article/details/82892282
FTP跳转攻击: https://blog.csdn.net/mgxcool/article/details/48249473
SSH-22
SSH:(secure shell)是目前较可靠,专为远程登录会话和其他网络服务提供安全性的协议。
(1)弱口令,可使用工具hydra,msf中的ssh爆破模块。
(2)SSH后门 (https://www.secpulse.com/archives/69093.html)
(3)openssh 用户枚举 CVE-2018-15473。(https://www.anquanke.com/post/id/157607)
WWW-80为超文本传输协议(HTTP)开放的端口,主要用于万维网传输信息的协议
(1)中间件漏洞,如IIS、apache、nginx等
(2)80端口一般通过web应用程序的常见漏洞进行攻击
NetBIOS SessionService–139/445
139用于提供windows文件和打印机共享及UNIX中的Samba服务。
445用于提供windows文件和打印机共享。
(1)对于开放139/445端口,尝试利用MS17010溢出漏洞进行攻击;
(2)对于只开放445端口,尝试利用MS06040、MS08067溢出漏洞攻击;
(3)利用IPC$连接进行渗透
MySQL-3306
3306是MYSQL数据库默认的监听端口
(1)mysql弱口令破解
(2)弱口令登录mysql,上传构造的恶意UDF自定义函数代码,通过调用注册的恶意函数执行系统命令
(3)SQL注入获取数据库敏感信息,load_file()函数读取系统文件,导出恶意代码到指定路径
RDP-3389
3389是windows远程桌面服务默认监听的端口
(1)RDP暴力破解攻击
(2)MS12_020死亡蓝屏攻击
(3)RDP远程桌面漏洞(CVE-2019-0708)
(4)MSF开启RDP、注册表开启RDP
Redis-6379 开源的可基于内存的可持久化的日志型数据库。
(1)爆破弱口令
(2)redis未授权访问结合ssh key提权
(3)主从复制rce
http://hetianlab.com/expc.do?ec=ECID9f92-ff93-4a94-a821-f0b968ef4985
Weblogic-7001
WebLogic是美国Oracle公司出品的一个application server,确切的说是一个基于JAVAEE架构的中间件,WebLogic是用于开发、集成、部署和管理大型分布式Web应用、网络应用和数据库应用的Java应用服务器
(1)弱口令、爆破,弱密码一般为weblogic/Oracle@123 or weblogic
(2)管理后台部署 war包后门
(3)weblogic SSRF
(4)反序列化漏洞https://fuping.site/2017/06/05/Weblogic-Vulnerability-Verification/
Weblogic_ssrf实例: http://hetianlab.com/expc.doec=ECID9d6c0ca797abec2017021014312200001
CNVD-C-2019-48814 WebLogic反序列化远程命令执行:
http://hetianlab.com/expc.do?ec=ECID3f28-5c9a-4f95-999d-68fa2fa7b7aa
Tomcat-8080
Tomcat 服务器是一个开源的轻量级Web应用服务器,在中小型系统和并发量小的场合下被普遍使用,是开发和调试Servlet、JSP 程序的首选
(1)Tomcat远程代码执行漏洞(CVE-2019-0232)
(2)Tomcat任意文件上传(CVE-2017-12615)
(3)tomcat 管理页面弱口令getshell
CVE-2019-0232 Tomcat远程代码执行漏洞:
http://hetianlab.com/expc.do?ec=ECIDefcf-3af2-438f-848f-8dc0f9e6b821
- 端口收集
- 在线收集
(1)端口收集:在线检测:http://coolaf.com/tool/port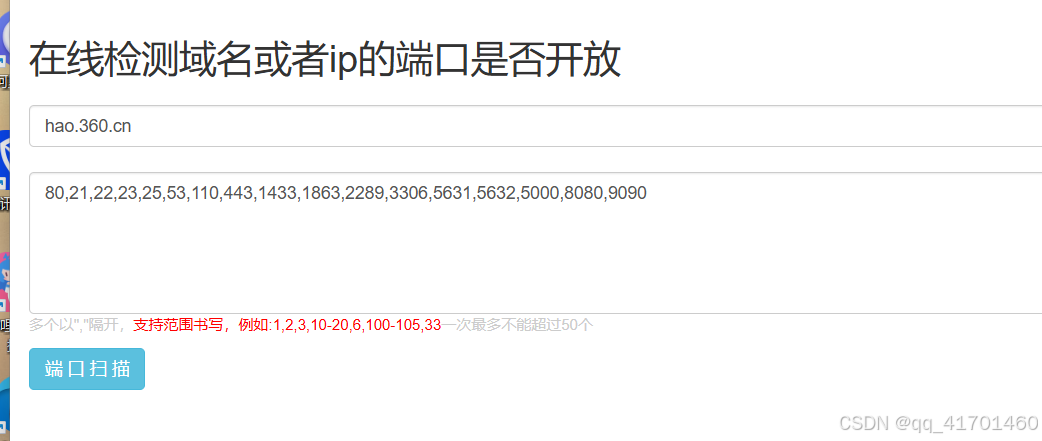
5.2.2. 工具收集
(1)kail收集:nmap -sS 域名/ip
(2)kail收集:masscan ip地址 -p 端口(1-1000)
Masscan 是一款快速的端口扫描工具
(3)御剑端口扫描
12. 敏感目录收集
-
敏感目录类型
数据文件、配置信息、上传目录、后台登录目录、安装页面、数据库版本、PHP版本、后台压缩包、未授权访问等。一般都是靠工具、脚本来找,比如御剑、BBscan,当然大佬手工也能找得到 -
敏感目录收集
6.2.1. 在线查询
Google语法
1)site:查找与指定的网站有联系的URL。
用法:site:网站名称
案例:site:baidu.com //查找和baidu.com网站相关的URL。
2)filetype:搜索指定类型的文件。
用法:filetype:文件类型
案例:site:baidu.com filetype:pdf //在百度中寻找pdf文件。
3)intitle:搜索网页正文内容中的指定字符。
用法:intitle:关键字
案例:intitle:后台搜索 //搜索网址中有后台搜索关键字的网页
4)inurl:搜索包含有特定字符的URL
用法:inurl:关键词URL
案例: inurl:.php?id //搜索网址中有php?id的网页
6.2.2. 工具查询
(1)kail查询:dirb+URL链接
Dirb 是一款用于网站目录和文件扫描的工具,它主要用于在 Web 应用程序中发现隐藏的目录和文件
(2)御剑目录收集工具
下载链接:https://pan.baidu.com/s/1H-499UU_QiHQWhMIDj_VMg?pwd=q1q3 提取码:q1q3
(3)7KBwebpathBurute
https://gitcode.com/7kbstorm/7kbscan-WebPathBrute/overview?utm_source=artical_gitcode&isLogin=1
4.dirsearch:
https://github.com/maurosoria/dirsearch
5.dirmap:
https://github.com/H4ckForJob/dirma
12. 社会工程学
社会工程学(Social Engineering,又被翻译为:社交工程学)在上世纪60年代左右作为正式的学科出现,广义社会工程学的定义是:建立理论并通过利用自然的、社会的和制度上的途径来逐步地解决各种复杂的社会问题,经过多年的应用发展,社会工程学逐渐产生出了分支学科,如公安社会工程学(简称公安社工学)和网络社会工程学。
167.1. 获取方式
7.1.1. 聊天工具
QQ、微信,通过添加对方好友,查看 QQ空间、朋友圈获取一些相关信息,比如核酸截图名字等。
同时在部分类似销售岗位都会将自己的手机号显示出来,以便比如方便联系,同时我们也方便了我们收集手机号。
7.1.2. 转账
支付宝或者微信在初级添加好友就进行转账时候会出现姓名验证,通过这种方式获取真实姓名。
7.1.3. 钓鱼
利用用户的好奇心、弱点、信任进行获取相关的资源对其进行获取相关信息,或者利用交谈中有意无意的导向进行套取相关信息。
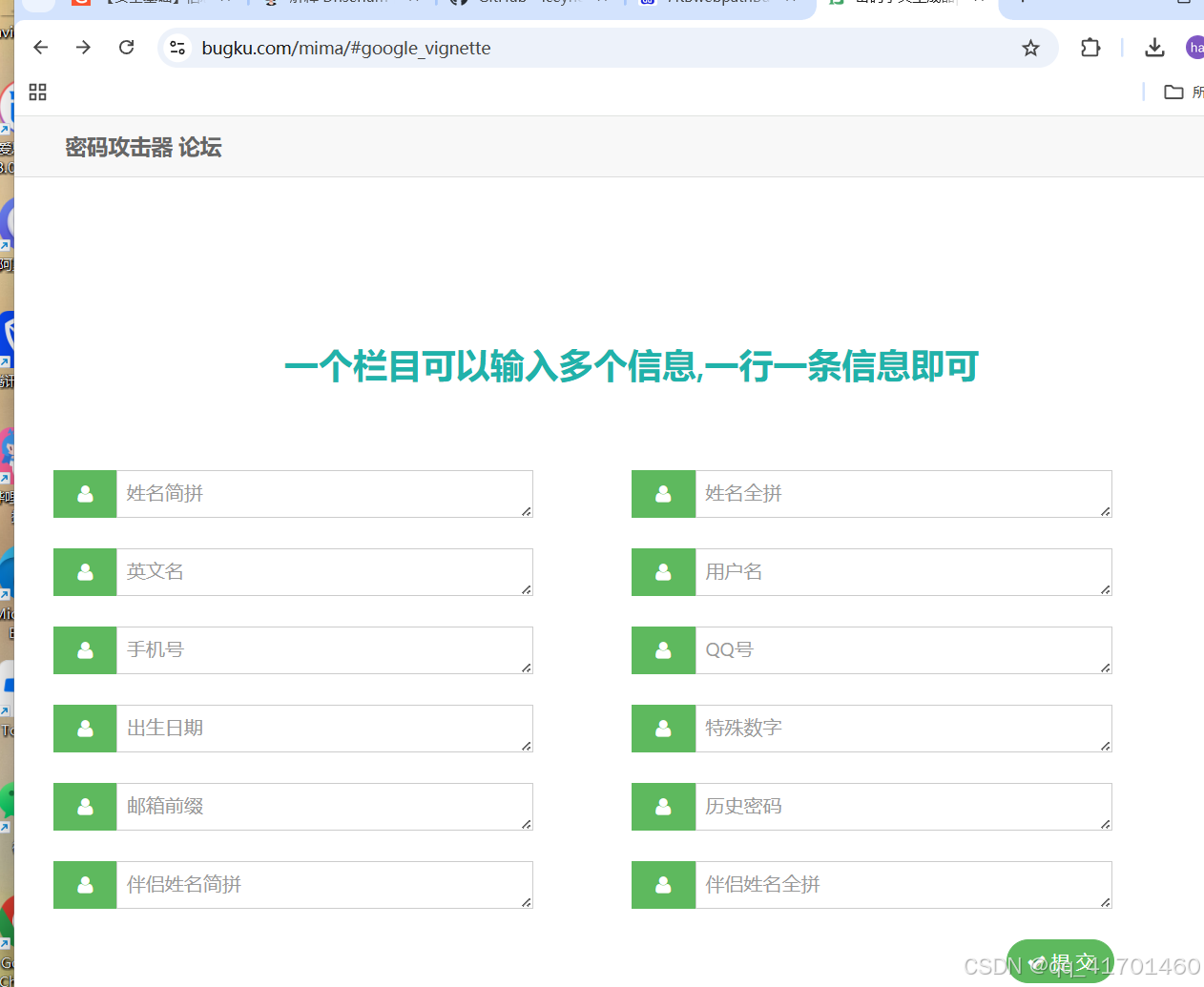
177.2. 密码字典生成
通过获取到的内容进行密码字典的生成。
网站:https://www.bugku.com/mima/
网站WAF识别
WAF定义
WAF,即:Web Application FireWall(Web应用防火墙)。可以通俗的理解为:用于保护网站,防黑客、防网络攻击的安全防护系统;是最有效、最直接的Web安全防护产品。
WAF功能
- 防止常见的各类网络攻击,如:SQL注入、XSS跨站、CSRF、网页后门等;
- 防止各类自动化攻击,如:暴力破解、撞库、批量注册、自动发贴等;
- 阻止其它常见威胁,如:爬虫、0 DAY攻击、代码分析、嗅探、数据篡改、越权访问、敏感信息泄漏、应用层DDOS、远程恶意包含、盗链、越权、扫描等。
WAF识别
wafw00f
https://github.com/EnableSecurity/wafw00f
nmap –p80,443 --script http-waf-detect ip
nmap –p80,443 --script http-waf-fingerprint ip
看图识waf,常见WAF拦截页面总结:
https://mp.weixin.qq.com/s/PWkqNsygi-c_S7tW1y_Hxw
总结:一般大的企业都有WAF防护,不要乱操作,后台会有记录
可参考:https://cloud.tencent.com/developer/article/2433195

欢迎加入DeepSeek 技术社区。在这里,你可以找到志同道合的朋友,共同探索AI技术的奥秘。
更多推荐


 13
13 0
0- 0



 已为社区贡献1条内容
已为社区贡献1条内容

所有评论(0)