Manus爆火后的思考:是否可以通过RL微调LLM来获得决策大模型
那回到主题上来,如果让我设计决策式的AI Agent,我可能会设计一些基础的决策任务,类似爬虫,写代码等等,每个子任务由一个垂类决策大模型控制。每个子任务都由LLM模型通过强化学习对其进行微调得到,奖励信号来自于是否完成了任务,而非人类给的监督信号。当然这仅仅只是我的一个构想,我也会在未来尝试一下,看这个思路是否可行。
最近AI领域最引人注目的突破莫过于Manus这样的AI agent涌现。其热度本质映射着行业认知的范式转变:AI Agent实现了从感知智能(语言对话)向决策智能(数据爬取,代码生成,可视化分析)的里程碑式跨越。这一认知层突破带来的震撼,恰似2016年AlphaGo横空出世时强化学习对产业界的颠覆性冲击。
我跟我的小伙伴们也对Manus具体的实现路径进行了激烈的讨论,存在两个典型观点:
-
• 提示工程极致派 :主张通过思维链、树状推理等prompt架构创新,激发LLM原生决策潜能。
-
• 定向微调派 :通过强化学习对大模型进行某项决策能力专项优化。
这有点像当年的自动驾驶,方案1是写一堆固定规则,方案2是通过端到端的训练模型来控制。不认同方案2的原因无非以下几点:
-
• 决策这件事非常要命,一旦出错带来的损失比感知大很多
-
• 人机交互协同的能力很差,很难说AI哪不好,我人来弥补它
-
• bad-case不好修复,因为是神经网络,没办法把bad-case告诉它。
但我觉得方案2不一定不可行,或者说方案1和方案2是有可能结合的。这里介绍一个我们最新的工作。
在去年12月份的时候,我们就想尝试做决策大模型,当然我们一开始也是基于prompt去做,我们首先在星际这个垂直决策领域开刀,也取得了不错的效果,具体可以看这篇文章:一种解决SMAC任务的新方法:让大语言模型写决策树代码[1]
但我们还是想结合强化学习的思路,让LLM Agent通过不断玩星际来提升星际水平。
这里我们仍然是采用之前的思路,我们构建了很多星际的小场景任务,然后通过描述这个任务,来让大模型生成对应的决策树代码。
有兄弟问我,为啥不采用把当前状态描述一下,然后问大模型应该采用什么动作的方式呢?
-
• 首先这种方式做出来的决策模型仍然是个黑盒,上面讲的三点问题都没解决。
-
• 第二我觉得从原理上讲,除非模型告诉MDP整个问题的定义,也就是状态空间、动作空间等等,否则缺乏信息量来判断该状态下应该做什么动作呢。
这里跟之前用常规强化学习训练不同,加了两个不一样的奖励。
-
• 如果大模型未按要求生成代码,奖励给-1
-
• 如果大模型生成的决策树代码,报错了给0
-
• 其他情况就按星际任务的胜率来进行归一化,归一化到0-1
以此就达到了通过环境交互训练大模型的功能。
当然由于算力资源有限,还要做很多准备,我们实际的流程是这样的。
-
• 先deepseek v2.5-236B(做这个工作的时候还没有v3和r1)的API模式,生成一些星际的决策树代码
-
• 用本地部署的Qwen-coder-7b做数据增强。
-
• 然后数据先蒸馏了Qwen-base-7b,基本保证代码API调用正确。过程中用了SFT和DPO。
-
• 最后才是上文讲的通过GRPO算法来进行模型微调。
具体实验细节
reward和环境是我们整个框架的核心,而且和大家现在疯狂做的math,reasoning 的问题不同,smac是真的需要起一个星际争霸2游戏跑的,cpu端和游戏本身的运行速度也是一个瓶颈。我们的主要优化都在于如何设置game evaluation work,提升并行运行速度,以及设置合适的正则表达式正确的提取代码并执行。至于具体的超参数层面,verl 库本身的配置就已经足够好了,基本不需要任何修改。
令我们意外的是,模型训练过程中,在MMM2,8m_vs_9m,10m_vs_11m 都取得了不错的胜率,要知道LLM实际上是用行为树粗犷的编写代码实现策略,而非MARL里面一个个精确操作实现的。 这个胜率相较于dpo 模型有了质的飞跃。
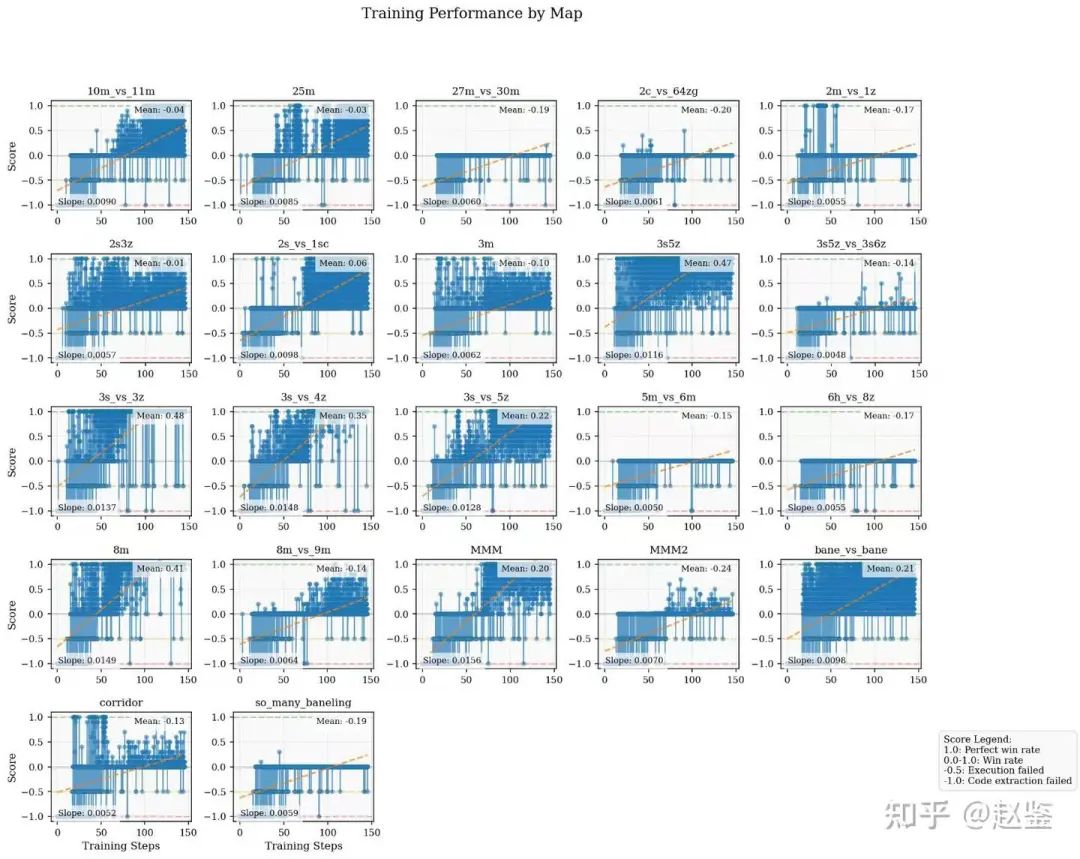
相比于这两个月来R1复现时大家经常讨论的aha moment 和cot 不断增加,我们的实验效果截然不同。 三次训练均显示response length 不断变短, reward 不停增加,而且训练到最后,我们的 language reasoning 部分,也就是策略分析<strategy>......</strategy>竟然训没了。要知道很多人复现的时候都说,他们的<think> token甚至可以涌现出来。 这说明smac这样的微操策略可能很难用语言表述,拿我们打游戏常用的话说,人越菜话越多,真正的高手看一眼就知道怎么打了,根本不需要分析,只有越菜的人才越清晰于找各种理由和借口。错误的分析还不如不分析!
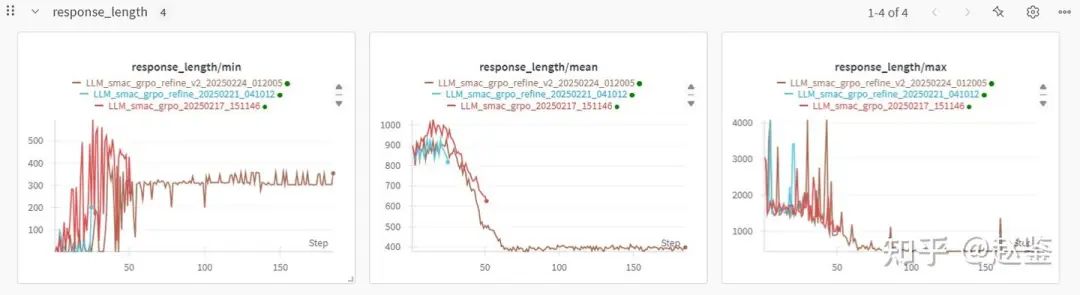

训练刚开始,模型废话一大堆。分析了一堆根本没啥关系的策略

训练到 187步,模型直接开始写代码,根本不多说一句话,。胜率也直接100%
最后
那回到主题上来,如果让我设计决策式的AI Agent,我可能会设计一些基础的决策任务,类似爬虫,写代码等等,每个子任务由一个垂类决策大模型控制。每个子任务都由LLM模型通过强化学习对其进行微调得到,奖励信号来自于是否完成了任务,而非人类给的监督信号。当然这仅仅只是我的一个构想,我也会在未来尝试一下,看这个思路是否可行。

大模型&AI产品经理如何学习
求大家的点赞和收藏,我花2万买的大模型学习资料免费共享给你们,来看看有哪些东西。
1.学习路线图

第一阶段: 从大模型系统设计入手,讲解大模型的主要方法;
第二阶段: 在通过大模型提示词工程从Prompts角度入手更好发挥模型的作用;
第三阶段: 大模型平台应用开发借助阿里云PAI平台构建电商领域虚拟试衣系统;
第四阶段: 大模型知识库应用开发以LangChain框架为例,构建物流行业咨询智能问答系统;
第五阶段: 大模型微调开发借助以大健康、新零售、新媒体领域构建适合当前领域大模型;
第六阶段: 以SD多模态大模型为主,搭建了文生图小程序案例;
第七阶段: 以大模型平台应用与开发为主,通过星火大模型,文心大模型等成熟大模型构建大模型行业应用。
2.视频教程
网上虽然也有很多的学习资源,但基本上都残缺不全的,这是我自己整理的大模型视频教程,上面路线图的每一个知识点,我都有配套的视频讲解。


(都打包成一块的了,不能一一展开,总共300多集)
因篇幅有限,仅展示部分资料,需要点击下方图片前往获取
3.技术文档和电子书
这里主要整理了大模型相关PDF书籍、行业报告、文档,有几百本,都是目前行业最新的。

4.LLM面试题和面经合集
这里主要整理了行业目前最新的大模型面试题和各种大厂offer面经合集。

👉学会后的收获:👈
• 基于大模型全栈工程实现(前端、后端、产品经理、设计、数据分析等),通过这门课可获得不同能力;
• 能够利用大模型解决相关实际项目需求: 大数据时代,越来越多的企业和机构需要处理海量数据,利用大模型技术可以更好地处理这些数据,提高数据分析和决策的准确性。因此,掌握大模型应用开发技能,可以让程序员更好地应对实际项目需求;
• 基于大模型和企业数据AI应用开发,实现大模型理论、掌握GPU算力、硬件、LangChain开发框架和项目实战技能, 学会Fine-tuning垂直训练大模型(数据准备、数据蒸馏、大模型部署)一站式掌握;
• 能够完成时下热门大模型垂直领域模型训练能力,提高程序员的编码能力: 大模型应用开发需要掌握机器学习算法、深度学习框架等技术,这些技术的掌握可以提高程序员的编码能力和分析能力,让程序员更加熟练地编写高质量的代码。

1.AI大模型学习路线图
2.100套AI大模型商业化落地方案
3.100集大模型视频教程
4.200本大模型PDF书籍
5.LLM面试题合集
6.AI产品经理资源合集***
👉获取方式:
😝有需要的小伙伴,可以保存图片到wx扫描二v码免费领取【保证100%免费】🆓


欢迎加入DeepSeek 技术社区。在这里,你可以找到志同道合的朋友,共同探索AI技术的奥秘。
更多推荐



 26
26 0
0- 0



 已为社区贡献279条内容
已为社区贡献279条内容

所有评论(0)