一种基于MATLAB mobile的抗噪声图像分类与定位算法
型号为ST1000LM048的1TB的机械硬盘,型号为NVIDA GeForce GTX 1060的,显存为6GB的GPU,搭载操作系统为。数类别包含50张图片。与YOLOv1不同,这里我们采用的是YOLOv2的做法,使用K-means聚类方法对边界框进行预测,对训练所使用的训。与Hao Zhang论文中使用的SVM-KNN结果做对比,我们模型在图片分类的结果中,达到了94.97%的正确率,而。K
摘 要
本文针对现代社会对含噪图像分类与定位的需求,使用小波变换去噪并使用机器学习的方法对含噪图像进行分
类与检测,整个实验步骤为,首先,使用软阈值去噪法对图像进行去噪,之后,使用Caltech 101数据集对卷积神经
网络进行训练,使卷积神经网络具有图像分类的特性,并通过实验测试卷积神经网络分类图像的效果,最后使用数
据集对基于YOLO的神经网络进行训练,并测试神经网络的召回率和准确率。本文提供的方法将传统计算机视觉和机
器学习的方法联合起来,使其在应对噪声时有更好的鲁棒性,为未来该项技术的发展提供了可靠经验。
关键词:小波变换;卷积神经网络;YOLO
1研究背景及其意义
随着人工智能及神经网络技术的发展,目标检测将成为下一代自动驾驶技术的关键软件组件。在自动驾驶中,
驾驶协助系统是自动驾驶的关键组件,用于识别和理解周围环境。该系统通过摄像头,雷达等设备收集信息,并通
过CPU识别。相较于其他类型的传感器,摄像头能提供大量细节信息,但也为CPU的处理带来了复杂的挑战。例如,
在复杂天气状况下,复杂的背景,随机出现的物体将使目标识别的问题更加困难。
传统计算机视觉对移动目标的检测技术主要有光流法,帧间差分法和背景差分减法。光流法主要通过计算图片
灰度变化趋势,表示为光流场,判断移动中的物体,此算法抗抗干扰性强,但时效性与精确性较差。帧间差分法多
用于视频,对视频中相邻两帧进行差分运算,通过两帧图像中亮度差的变化,判断有无物体运动。背景差分减法则
是用当前拍摄到的图像与曾经获取的背景图像做减法,得到超过阈值的像素,确定物体位置,轮廓等。但这些方法
大多依靠人工提取特征,与下文的机器学习技术相比,其泛化能力不强。
近年来,机器学习技术发展的极其迅速,而神经网络已成为机器学习中一颗璀璨的明珠。这些年来,基于神经
网络的目标识别算法由于其效果优良,识别速度快,取得了众多研究者的青睐。目标检测一般由三个部分组成,搜
寻目标区域,提取目标,识别目标类型。主要步骤为通过不同尺度的滑动窗口遍历待检测图片,找出合适的目标区
域,然后将目标区域通过神经网络进行特征检测,判断相应的目标类型。主流的目标检测算法主要有两个类型,一
种是单阶段目标检测算法,另一种是双阶段目标检测算法。其中在单阶段目标检测算法中最有代表性的是YOLO[1]和
SSD[2],主要步骤是在图片中利用预设的位置进行抽样,在通过微调后,可以得到不同的尺度,然后使用CNN进行特
征检测,并进行分类,整个过程只有一个阶段,速度快,效果好,但训练较困难。而双阶段目标检测算法最典型的
是R-CNN[3],整个步骤分为两个阶段,第一个阶段为对图片进行局部裁剪,提出可能包含物体的区域,第二个阶段
则把这些区域通过分类网络,如AlexNet[4],再将特征放入SVM进行分类,得到目标所属类别。
在基于神经网络的目标检测算法中,最重要的莫过于其中的卷积神经网络。AlexNet[4]分类网络包含5个卷积层
和3个全连接层,创新性的使用了LRN(Local Resonse Normalization)技术,模拟生物学中的侧抑制,提高了整个
模型的泛化能力。在此基础上,ZF net对Alex Net进行微调,使用反卷积,反池化等技术可视化不同层下的特征
图,使用的图片更少,效果却更好。VGGNet[5]由Simonyan等人提出,在AlexNet[4]的基础上使用更小的卷积核,并
增加卷积层,并且使用了Muti-Scale的方法,增加了训练的数据量,可以有效防止过拟合的出现,提升准确率。
GoogleNet[6]由Christian Szegedy提出,使用与AlexNet[4]完全不同的结构,创新性的使用Inception模块,提取
更丰富的特征,降低了梯度消失,梯度爆炸等问题发生的概率。深度残差网络(ResNet)[7]提出,随着网络加深,梯
度消失和梯度爆炸问题可能会阻碍网络的收敛,所以作者Kaiming He想到了构建恒等映射来解决这个问题,节省了
计算资源并防止了过拟合,提高了泛化能力。
在极端天气下,复杂的环境可能使传感器拍摄到的图像严重模糊,主要问题在于曝光不足、对比度低,空气中
弥漫的灰尘使图像中出现较大的噪声,由于这些原因的存在,图像质量不可避免的降低。但当今时代,无论是人类
还是机器,都对图像的量质提出了更高的要求。为了解决这些问题,研究人员提出了许多试图降低图像噪点的方
法,其中最具有代表性的是小波分析。
小波分析由傅里叶分析发展而来,传统的傅里叶分析在分析突变信号时,常常存在Gibbs现象,即在信号转折处
存在相对较大的震荡。在现有技术中,我们无法通过传感器采集到无穷长的频谱,也就意味着频率端可能出现截
断,那么当我们从时域观察,信号可能存在着相对较大的震荡。而且对频率随时间变化的模型下,传统的傅里叶变
换很难展示出频率随时间变化的关系。为了解决这些问题,更好的分析信号,小波分析应运而生。
与傅里叶变换不同,小波变换基于能量快速衰减,不断变化的频率和有限的持续时间的小波(wavelet)。1987
年,小波变换被Mallet证明,并一举成为多分辨率分析理论的基础,成为信号处理和分析的有效工具。多分辨率分
析理论统一并整合了信号处理,语音识别,图像处理等多个领域,其主要认为信号或图像在某个分辨率下可能很难
识别到有效特征,但更换为另一个分辨率下进行分析未尝不可。
小波分析去噪主要有以下几种方法。1992年,Mallet提出了通过检测图片奇异点的模极大值去噪,其算法的中
心思想为,对信号进行DWT变换,在不同尺度上通过信号和噪声的不同的传播特性,在所有变换模极大值中选择适当
的模极大值,以此来去除噪声,然后用剩余的小波变换重建信号。Donoh等人提出了小波阈值去噪法,其依据为在得
到包含有噪声的信号后,通过多次小波分解,有效信号控制的小波系数总是回大于噪声的小波系数,最常用 的阈值
一般选择VisuShrink,这种方法是采用的全局统一的阈值。在医学中,沈阳理工大学的李野提出在医学图像预处理
中,利用小波分析去噪时极其重要的步骤[8]。
在过去近100年间,人们存储了大量数据,同时人们处理数据的能力也获得了极大的提升,但我们仍然需要更优
秀的算法,也正因如此,神经网络这一技术也获得了大范围的关注。如今,无论在何种学科,神经网络都成为了重
要的技术源泉。在对图像和语音等多维的对象,进行分析时,神经网络取得极大的优势,由于其模型复杂度高,只
要通过对参数的调节就可以调整训练的性能,虽然神经网络的理论基础仍然比较缺乏,但它在工程实践领域有着极
强的遍历性。在大数据时代,数据的储存和分析都有了巨大的发展,在过去,对数据进行如此大的分析近乎不可
能,在缺乏强力计算设备的情况下,在过去无法有效求解模型。在现如今,随着计算机体系结构的发展,如今的芯
片有着强大的并行计算能力,使对大规模数据的处理与分析成为了可能,现如今,神经网络为很多交叉学科提供了
技术支撑,甚至渐渐通过对社交网络的分析,影响到了人类的政治生活。
随着神经网络的发展和应用,李明、鹿朋等人基于改进YOLO对闸板的阀开度进行检测[9],指出在复杂环境中,
无法使用外部辅助对目标进行检测的情况下,使用神经网络技术,对闸板进行检测。蔡鸿峰等人使用了改进的YOLO
算法对小目标物体进行目标检测[10]。还有向阳等人使用孪生网络对遥感图像进行分析[11]。因为图像识别技术在
无人机智能机器人等凌云的大放异彩,郑州大学的张陶宁等人为了支持在嵌入式设备上进行运转[12],使用了基于
Mobile Net和YOLO的快速目标检测的算法,在减少了网络层次的情况下,在精确度和性能消耗上取得了优异的结
果。今天,各种神经网络技术已融入人类的生活,无论是在环境监测,芯片设计,云计算等领域,神经网络都在发
挥着机器重要的作用。值得一提的是在未来,我们可能通过神经网络技术了解人类如何学习,而人类又是如何产生
视觉和听觉等感受,神经网络对这类有关自我本源的问题的解决无疑是巨大的启发。
问题提出
抗噪声的图片分类和定位技术是现代图片处理的重要部分,它集信号处理,图片采集,人工智能,计算机技
术,图片处理等多种现代技术于一体。恶劣的噪声可能会影响图片的分类和定位,对基于神经网络的目标识别技术
的使用观察得,当我们对原本可以识别的图像加入高斯白噪声时,用于模拟复杂环境,神经网络对图片的分类和定
位会降低正确率,难以正确识别出目标。本文将以此为出发点,尝试结合传统计算机视觉技术和恶劣情况下神经网
络的目标识别技术,解决图片在恶劣情况下当今的目标识别技术难以分类并定位目标的问题。为了提高图片在复杂
环境下的识别效果。本文尝试提出一种结合传统计算机视觉技术和基于神经网络的目标识别技术的算法架构,尝试
提高目标识别在复杂环境下的识别准确度。
算法原理与分析
算法整体框架
随着科技水平的不断提高和人们对幸福生活的日益向往,驾驶技术已经成为了人们日常生活中不可分割的一部
分,为了提高驾驶技术的安全性,减少疲劳驾驶和酒后驾驶,进一步提高车俩假设自动化的水平。Google、华为、
小米、奥迪等大量公司为了进一步提高机器对驾驶的辅助投入大量资金对自动驾驶技术进行研发,随着这些大公司
的加入,作为自动假设核心的图像分类与定位技术也发展的越来越快。通过计算机对摄像机采集到的图片作为输
入,把对车辆的控制作为输出,使用神经网络技术对进行分类和定位,使用编程对规则加以设计,考虑所有的情
况,最终转化为车辆的控制,目前,该技术已经成为了目前自动驾驶技术的核心
但如前所述,在极端天气下,通过摄像机传感器得到的图像可能因为环境复杂,关系偏暗,干扰严重等问题,
存在着噪点高,灰度化严重,反光等问题,导致图片的分类和定位的效果不甚理想。为了解决该问题,本文设计了
一种由结合传统计算机视觉技术和基于神经网络的目标识别技术构成的算法架构,该算法由两部分组成,小波变换
去噪和基于YOLO和ResNet的图像分类和定位技术,如图所示。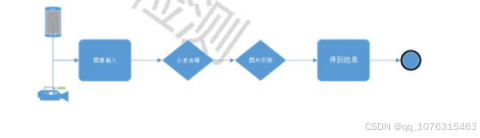
理论依据
小波变换去噪
在极端天气下,我们通过传感器获得的图片可能存在着大量噪声。常见的噪声类型主要有高斯噪声,泊松噪
声,乘性噪声等,而通过观察得知,这些噪声的主要类型为高斯噪声,我们需要使用不同算法对这些图片进行处
理,降低图片噪声并进行图片增强。含有噪声的图像可以如下表示:
其中
表示我们获取到的图片,
表示不含噪声的图片,
则表示噪声。我们要想办法保留
的
同时尽可能分离出
。
理论上,如果知道了噪声
的分布,就可以把原始图片减去输出噪声的方式来消除噪声,但在现实中,除
非明确求出噪声的分布,否则我们很难讲图片理想的还原出来。
为了尽可能保留图片的边缘信息,我们使用小波阈值去噪的方法来在尽可能消除噪声的基础上,尽可能保留图
片边缘的细节信息。小波变换有着出色的时间分辨率和频率分辨率,可以有效获取图片的局部特征。小波变换的公
式如下
其中为尺度,为平移量。
我们将我们获取到的图像使用小波变换可得:
注意到目前得到的小波系数可以通过逆变换得到原始的图像。
以图片的高频部分为例,将传感器得到的图像使用多次的小波变换可以注意到图像的高频部分回包含图片的边
缘部分和噪声信息,但噪声信息的小波系数会在多次变换后变得越来越小,而有效的信号的小波系数则会在多次变
换后变得越来越大。也就是说,在多次小波变换后,噪声和有效信息会渐渐分离。换句话说,噪声在时间上是没有
连续性的,而信号在时间域上有一定的连续性,在多次小波变换后,噪声仍然存着异常高的随机性,也就是说,噪声
在小波域仍然满足高斯分布。我们将尝试不同的阈值去获得图片的高频细节而不是噪声,选择合适的阈值函数将变
得尤为重要,我们一般选择统一由Donoho提出的软阈值函数:
其中,
是传感器所采集图像的在第尺度下的第个小波系数,是我们所选择算法的阈值。
硬阈值去噪的函数如下所示
其中,
是传感器所采集图像的在第尺度下的第个小波系数,是我们所选择算法的阈值。无论是过大的阈
值还是过小的阈值,均会影响到我们图像的去噪,我们阈值的选择使用全局通用阈值,其公式为
其中,为噪声方差,
为图像尺寸。这是应用最广泛的小波去噪方法
我们选择软阈值去噪的原因是,经过其误差相对于硬阈值法相对较大,但其信号有着更好的光滑性,基于卷积
神经网络的目标识别准确率更好,整个小波去噪的算法步骤如下:
1)对图像进行小波分解。先根据图像的噪声情况和现实情况选择小波分解的层次,并根据情况选择一个小波函
数,之后对图像进行小波分解。
2)对图像分解出的高频小波系数进行处理,对 前层的小波系数进行软阈值处理。
3)使用逆小波变换重构图片,由于噪声在多次分解后仍然存在,而有用的信息会在多次分解后,其小波系数则
渐渐趋近于0,在通过阈值去噪后,可以尽最大可能降低噪声。
基于YOLO和神经网络的图像识别技术
YOLO是一种基于坐标框利用回归的检测方法,通过检测图像的像素,定位目标的位置。其核心为利用图像作为
输入,通过卷积网络,识别分类并在输出层回归出边界框的具体位置。
特征提取网络
YOLO由全卷积神经网络和一个对神经网络输出进行后处理的算法组成。
机器学习是根据数据利用回归的方式,对数据进行分类的方法,从数据中计算出回归模型的方法被成为训练。
神经网络就是机器学习算法中非常具有代表性的算法,他将多维的难以提取特征的样本通过多种层次结构,将其根
据特征转换为一维数据并使其与类别对应起来。
神经网络来源于科学家对神经元的研究,在神经网络中,最基本的结构为神经元,与现实中的神经元相似,神
经元存在一个阈值,当输入大于这个阈值时,神经元就会被激活。下图为M-P神经元模型的简略图。
神经元将总输入值和阈值相对比,最后通过激活函数得到输出,公式如下:
其中 为激活函数, 为阈值, 为输入, 为权值。
最普通的神经网络就是将上图的神经元按一定的顺序结构连接起来。常用的神经网络有着如下的层次结构,每
层的神经元会和前一层的神经元完全连接,即多层前馈神经网络,这种结构后来发展为我们常见的全连接层。
神经网络根据反向传播法更新权值,其主要步骤如下,第一步假设神经网络输出层的输出为 ,根据 和真实结
果的误差,然后就可以计算输出层神经元的梯度,之后根据链式法则计算隐藏层神经元的梯度,之后更新隐藏层的
权值和阈值。Hornik在1989年提出,多层神经网络在包含足够多神经元的情况下,可以以任意精度逼近任意复杂度
的连续函数。也正由于神经网络强大的表达能力,在训练过程中,神经网络也常常遭遇过拟合的问题,即在训练过
程中,训练的误差不断降低,但测试的误差不断升高。比较主流的解决方法为将一整个训练集按一定比例随机分为
训练集,验证集和测试集,如果验证集的误差升高而训练集误差降低就停止训练。
总而言之,神经网络通过计算梯度并更新权值的方法使神经网络模型在训练集的误差渐渐减少,整个过程可能
进入局部极小,也就是整个模型没有达到全局最优的状态,业界一般使用模拟退火等启发式算法或者随机梯度下降
等方式避免陷入局部最小的问题。
网络的复杂度随着参数的增加而增加,这能让神经网络能分析更复杂的任务,但同时也会带来训练效果低,易
过拟合的问题。CNN最早由Hubel等人提出,现如今已经广泛用于各个领域,CNN通过反向传播算法(BP)算法进行训
练,并使用了权共享这一重要的策略,其方法为对每一组神经元使用相同的连接权,我们使用卷积层对输入信号加
工并提取特征,然后使用池化层减少无用数据,选择有用的特征。整个网络结构如下所示:
如上图可以看出,相较于多层感知机所构成的神经网络,CNN多了被称为“特征抽取层”的卷积层和池化层。卷
积层由若干个卷积单元构成,其目的为提取前一层的不同特征,卷积层提取的特征随着层数的增加,能提取的特征
的复杂程度也渐渐增加。池化操作分为最大池化和平均池化,其原理为根据卷积层计算得到的特征图和根据局部相
关性原理进行亚采样,减少数据量并保留有用信息。CNN相较于DBN,大量降低了需要训练的数量。CNN这种端对端的
网络,无需依靠人工提取特征,在处理图片等多维数据时,抗干扰性强。
总而言之,CNN这一独特的前馈神经网络,其依据多隐层堆叠的结构,在不同的层级对输入进行处理,对上一个
层级的输出进行加工,把最开始联系并不密切的的输入,处理成与输出目标密切的形式,使原来仅依靠于单独一层
难以处理的问题转换成多层网络能处理的信息,将简单的单层特征表示为高级的多层特征,使之能够胜任复杂的分
类等学习任务,所有机器学习也被称为特征学习。对人类来说,仅依靠现有的工具抽象出可学习的特征是很困难
的,通过机器学习特征,产生并理解特征,是革新化的一步。
要使神经网络提取足够丰富的特征,其核心是使网络的层数更深,特征层尽可能的大,使其包含的信息尽可能
的丰富。Kaiming He在ResNet中指出,但随着网络深度的不断增加,模型的错误率也在不断增加,这种错误的增加
不是由过拟合导致的。当网络深度增加至一定程度时,随着网络深度的继续增加,其训练误差也会增大。其原因为
当我们使用BP算法时,,我们很难把梯度更新到前面的层数,而前面的层数很难更新,梯度消失的问题就随之出
现,所以随着网络层数越深,梯度消失的问题也会出现。同理,随着网络层数的增大,如果不同网络层之间的梯度
值大于1,重复相乘将导致梯度的指数级增长,导致Loss出现大范围的震荡,网络也会因此变得不稳定。为解决此问
题,我们使用ResNet作为分类模型,ResNet由Kaiming He等人在2015年提出,使卷积神经网络能更简单的训练的同
时,也能提取更复杂的特征。ResNet最重要的创新点在于残差学习,也就是残差块的构造。每个残差块由两条路构
成,一条路由两个权重层(卷积层)构成,两个卷积层通过relu激活函数相连,另一条路直接连接,两条路的输出
相加然后通过激活函数直接相加,作者认为有了残差块之后学习残差比直接训练快,并且能有效提高网络深度,如
下图所示: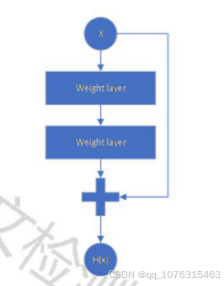
这样,尽管我们增加网络层数,使CNN能够理解更多的特征,却很难出现梯度爆炸或梯度消失的问题,BP算法运
行的十分顺利,使深层网络优化更加简单,而且这种短路连接并没有增加需要学习的参数,也没有增加算法复杂
度,但却优化了网络结构,使需要计算的计算量大大降低,大大方便我们的训练。我们使用的ResNet-50共有50层卷
积层,由于有了残差结构,所以可以更好的避免退化问题,即在卷积神经网络的深度不断增加时,其错误率也会变
得高。
我们使用50层的ResNet(ResNet-50),与ResNet18和ResNet34不同,我们在每个残差块中使用3层卷积核并加入
一个1×1的卷积核,如图所示。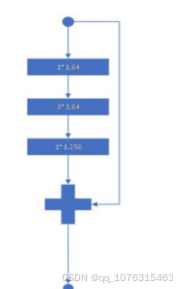
这个网络结果包含以下多个层次,隐藏层第一层为一个77的步长为2 的卷积核,紧跟着的最大池化步长仍然为
2,下一部分类似上图的残差区块,由11,64的卷积核,33,64的卷积核,11,128的卷积核构成的残差区块,共
重复三次,共九层。接下来是11,128的卷积核,33,128的卷积核,11,256的卷积核构成的残差区块,共重复
四次,共十二层。之后是11,256的卷积核,33,256的卷积核,11,512的卷积核构成的残差区块,共重复六
次,共十八层。然后是11,512的卷积核,33,512的卷积核,1*1,1024的卷积核构成的残差区块,共重复三次,
共九层。本文在每个卷积层后面加入Batch Normalization层,以加快模型收敛速度。之后是全连接层、池化层和
softmax函数层。BN层由Sergey Ioffe等人提出,在通常情况下,使用BN层可能会增加层参数,在使用梯度下降法时
可能会导致梯度爆炸问题的发生,而在使用BN层的情况下,BN层并不会影响层参数,使参数的变化更加稳定,所以
BN层可以使用更高的训练速率而且在初始化时不必过于小心。本文在训练后去除ResNet-50最后的全连接层,平均池
化层,和softmax层,保留所有权重层(的参数),连接至YOLO算法上。
基于YOLO的边界框的分类与预测
我们将图片分成13×13的网格,如果待检测目标的中点位于网格中,那么我们就该网格负责预测该目标。每个
单元格通过下面K-means得到的默认边界框预测边界框,并预测边界框和其置信度。其置信度的意义为边界框含有目
标的可能性大小和边界框的准确度。边界框的准确度即下文提到的
和对应目标的类别。
。即将判断边界框相比于网格的位置和大小
YOLOv1使用先验框预测边界框的相对于先验框的偏移,但这种方法是无约束的,边界框可能朝着错误的方向偏
移,在训练时可能需要较长的时间来使边界框落在正确的位置。
与YOLOv1不同,这里我们采用的是YOLOv2的做法,使用K-means聚类方法对边界框进行预测,对训练所使用的训
练集进行计算,提高整个模型的训练速度,并使我们所得到的边界框与真实目标的边界框有更高的交并比,其定义
如下:
本文在训练前对训练集中的边界框做聚类,意图得到更好的边界框。聚类是一种无监督的学习方法,一般用于
将数据点分类至不同的互不相交的组中,主流对聚类性能进行评估的方法主要为两种,其一是将结果和参考模型进
行比较,另一种方法是直接考察聚类结果,本文将直接考察聚类的结果。
本文在所有边界框中选取k个边界框作为默认边界框,计算每个边界框与这些默认边界框的距离,我们使用的K-
means聚类方法的搭配的距离为:
选取距离默认边界框最近的边界框,将其分至该默认边界框的组中,不断重复这个操作,最够就能知道哪些边
界框属于哪个组,之后按照组中的边界框的中高宽的平均值更新默认的边界框。在训练时在卷积层更新权值,得到
正确的边界框,该种提取获取默认边界框的聚类算法能显著提高训练速度,提高检测性能。
本文在训练中每隔一定的迭代周期就改变输入大小,这样就可以使算法适应不同大小的图片,更好的适应现实
的需要。
相较于其他主流目标分类与定位算法,YOLO的流程相对简单而且有着非常快的检测速率,且YOLO根据全图进行
预测,有着非常高的检测速率。
损失函数基于YOLO
本文使用的是YOLO的损失函数,如下所示:
在该式中,
表示为边界框相对于网格位置所发生的偏移,
考虑到边界框面积相对于真实目标边界框面积的偏移,注意到面积的计算方法为平方,但当目标较小时,在不
开方的情况下,损失函数无法正确反映出正确的偏移。
表示网格无目标时的偏移,
表示当前检测目标类别检测正确的偏移。
实际过程中,很有可能大部分的网格中并不存在目标,导致其无置信度。由于YOLO根据边界框交并比会尝试找
更大的物体进行检测,导致其对较大物体的分类和定位效果更好,但对情况较为复杂的,个体较小的物体进行图像
分类和定位的效果差强人意。但也正因为YOLO通过对整张图片进行检测,然后将边界框输出,所以对大目标检测的
效果较好,相较于其他图像分类和定位算法的检测快得多。
实验步骤
基于MATLAB mobile的抗噪声图像分类与定位算法,其算法步骤如下
1)通过传感器采集真实场景下的图像样本,将其转换为计算机能识别的数字信号。
2)使用小波变换,对采集到的图像进行分析,使用软阈值法对图像进行降噪处理。
3)使用图像分类数据集对残差网络进行训练,使神经网络有分析图像特征的能力,使网络到达图像分类的最优
状态。
4)使用训练好的网络对样本进行测试,该部分结果在实验结果部分给出。
5)将残差网络最后的全连接层,平均池化层,和softmax层去除,并保留所有权重层(的参数),连接至YOLO
算法上。
6)使用不同的训练参数对整个网络进行训练,但要注意,尽量使网络靠前的权值尽可能更新的慢于网络靠后的
权值。
7)训练后对神经网络进行测试,将测试数据输入网络,并与实际结果进行对比,该部分结果将在后文给出。
8)将训练好的模型部署于MATLAB mobile。
实验过程与分析
实验条件
本文使用Intel Core i5-6300的CPU,频率为2133M的双通道16GB内存,型号为Samsung 850的256GB固态硬盘,
型号为ST1000LM048的1TB的机械硬盘,型号为NVIDA GeForce GTX 1060的,显存为6GB的GPU,搭载操作系统为
windows 10专业版x64系统的电脑。所搭配CUDA版本为v11.1,运行平台为MATLAB,所使用的编程语言为MATLAB。
图像分类数据集
Caltech 101数据集由Fei-Fei Li等人收集而成,包含101种类别图片,每个类别大约有40到800张图像,大部分
类别图像有50张,每张图片像素大小约为300×200。将图片放入模型之前,由于输入层大小为224×224,所以我们
将图片全部调整为224×224,在数据集中,部分图片为灰度图,颜色通道仅为1,我们需将其调整为RGB图像(三通
道)才能放入模型中训练,我们对输入图片使用颜色变化、平移、缩放等操作,但不改变图片类别,最后对图像按
照随机角度进行旋转以模拟摄像头在不同体态下的采集到图像的变化。
目标检测数据集
本文使用的目标检测数据集为coco数据集,由于本文使用的测试机配置限制和时间限制,选取其中部分作为测
试集,使用MATLAB对所有照片加入方差为0.1的高斯白噪声和位置随机的方差为0.2的高频噪声并使用小波变换对这
些照片进行去噪,并由人工通过MATLAB中的Image Labeler进行数据集标注,每幅图像中所需识别的物体均与coco中
包含的类别一致。之后按照训练数据集、验证数据集、测试数据集,按照6:1:3的比例对数据集进行完全随机的划
分,之后对图像按照随机角度进行旋转以模拟摄像头在不同体态下的采集到图像的变化。
图像预处理过程
图像可能会由于复杂环境和恶劣传输条件的的影响,产生不同种的噪声,这些噪声会使对图片的处理产生复杂
且恶劣的影响,更可能对现实生活造成不可估量的损失,所以,本文先对噪声进行处理,以图尽可能还原图片,使
噪声对后期的处理造成更加巨大的损失。但由于图片在出现噪声时即丢失了部分信息,我们只能尽可能的还原出图
片原本的样子。由于现实生活中噪声呈现来源广,高度复杂等特性,所以我们使用高斯加性白噪声对图片进行加
噪,以图更好的模拟现实。
对传感器在天气良好情况下拍摄到的图片进行处理,原片如下:
对原片加入均值为0,方差为0.2的高斯白噪声,经过处理后,图片的信噪比为9.8895。经过处理后的图片如
下。该图在使用无噪声处理的图片分类与定位算法时,无法被神经网络分类并定位。推测原因可能为可以被神经网
络识别的特征已经被噪声掩盖,难以识别。

使用软阈值去噪,双正交小波(Biorthogonal wavelet),全局固定阈值,最终得到的图片信噪比为20.5795,图
片如下,经过后文的模型检验,可以识别出正确物体,结果如下:
使用MATLAB对Caltech 101数据集进行训练
本文使用Matlab的imageDatastore对象处理数据集,本次训练样本类别共101类,每类共40到800张图片,大多
数类别包含50张图片。我们将Batch Size设定为10,学习速率为0.0001,在训练过程中每3次迭代验证一次网络。本
次学习共6轮迭代,每轮迭代次数640,共3840次迭代。
下图为训练过程,最终验证集到达最后一次迭代准确率为94.97%,共用时13小时13分钟12秒,注意到模型在第
一轮训练中准确度快速上升,当到达第一轮迭代结尾数据集准确率已逼近90%,之后准确度缓慢上升,最终到达
94.97%。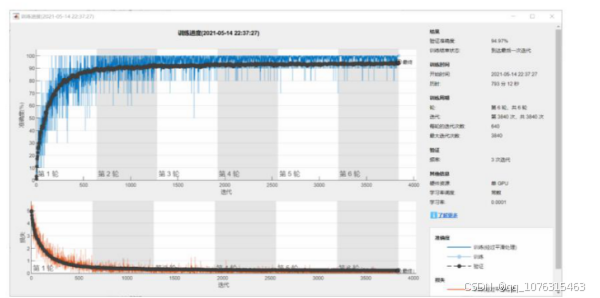
未来,在进一步提高数据量后,模型的正确识别率可能可以达到近乎100%的正确率,在下文,我们与使用了同
数据集的KNN-SVM模型进行对比,证明了神经网络对图片分类的优越性。
使用MATLAB对目标识别数据集进行训练
本次训练样本数量为177张,验证集样本数量为30张,剩余用于检测检测器的正确性。训练使用的batch size为
5,学习率为0.01,共20轮训练,每50次迭代进行一次验证,共迭代次数为700。最终达到的验证集均方根误差
(RMSE)为0.46758,该值越小证明模型训练越好。
下图为整个训练过程,注意到RMSE与损失值在前50次迭代发生了快速下降,说明模型快速拟合,注意到从300次
迭代起,损失与RMSE基本不变,仅有小幅震荡,说明模型拟合正在渐渐完成。
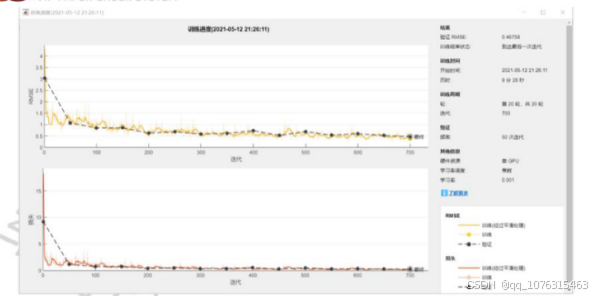
在完成训练后,其验证集均方根误差(RMSE)最终值为0.46758,其公式定义如下:
当均方根误差趋近于0,则表明模型的拟合效果很好,图像可以被正确的分类和定位。相较于误差和平方和,均
方根误差能更好的在样本方差较大时体现出模型的拟合程度,更好的描述数据。
模型检验
图片分类结果
我们可以看出在完成第一轮迭代时,ResNet基本学习到了图像的全部特征,而在损失函数曲线,注意到模型在
完成第一轮迭代后渐渐停止收敛。
与Hao Zhang论文中使用的SVM-KNN结果做对比,我们模型在图片分类的结果中,达到了94.97%的正确率,而
Hao Zhang使用的SVM-KNN模型结果仅仅达到65.6%的正确率,其准确率较低。可见目前,传统图片分类技术已难以和
基于神经网络的结果相比,其准确度目前有较大差距已无法适应目前社会发展的需要。
由以上得知,在识别率上,我们使用的残差神经网络的准确率非常高,而且无需人工提取特征,充分体现出神
经网络技术的优越性。
目标定位检测结果
最终,使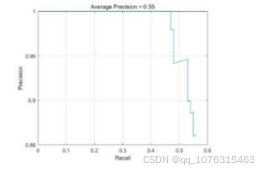
用该模型对测试集进行检验,测试集共88张,模型性能指标如下:
精确率和召回率的公式可由下式定义:
其中TP为算法正确识别的正样本的样本数,NP为算法错误识别为正样本的负样本数,FN为误识别为负样本的正
样本数。简单来说,召回率的真正意义为,在图片中提取了多少的目标。精确率的意义为,在这些被找出的样本中
有多少是正确的。
注意上图,当召回率上升时,其精确度会下降。在召回率大约为0.45使,精确度开始下降。相较于YOLOv1,本
文使用的模型在提高训练速度的同时,在准确度和召回率上也有些许提升。在未来,如何进一步改进算法,提高对
图片识别和定位的准确度将成为未来研究的方向。
部署于Matlab Mobile
在模型训练完成之后,我们将模型部署于MATLAB Mobile上。
MATLAB mobile是MathWorks提出的新一代软件,我们可以在任何地点从IPHONE,iPad,安卓等移动终端通过互
联网连接至自己的MATLAB Cloud。MATLAB支持在手机上编辑并运行脚本,帮助开发者更有效的编写程序。
MATLAB mobile 更支持通过手机的传感器获取类似GPS,摄像头等数据,并在云端进行分析。MATLAB Mobile可
以将传感器流式传输至MATLAB云端上,并随时下载他们。MATLAB根据手机的支持,提供三轴加速度传感器,三周角
速度传感器,三周磁场传感器,方位角和俯仰角控制器,还有经纬度和高度、速度等传感器。
我们将模型上传至MATLAB cloud上,编写脚本。具体步骤如下:
1)调用手机后置摄像头
2)等待用户拍照
3)在用户拍完照之后加载图像分类和定位模型
4)将用户拍完的照片进行处理。使用小波变换去噪
5)将图片输入图片分类和定位模型,并等待结果
6)根据结果生成矩形框,将图片分类和定位到的结果展示出来
实验讨论
由于时间和测试机配置关系,本次实验仍有很多不足之处,包括但不仅限于:
1)在使用聚类方法中,并没有使用学习向量化、高斯混合等聚类算法预测默认边界框,没有比对这些算法是否
能继续提高训练速率。
2)本文并没有比对更多对图片分类和定位的主流模型在该数据集上的表现,如R-CNN。该种算法由于使用了滑
动窗口,所以在图片的分类和定位上有着更加优秀的准确率,但也对训练机提出了更高的要求,本文使用的测试训
练机并没有达到这种模型能被训练的最低标准。
3)虽然小波去噪的效果与传统的去噪方法相比,其效果更为优秀,但如果把他们结合起来,其效果可能由于单
纯的小波去噪。
4)本文使用的对图像去噪方法由于时间的限制,并没有使用如压缩感知去噪等更有效的手段,更没有使用深度
学习对图像进行去噪,未来可发展的方向应为,使用自洽生成对抗网络(SCGAN)对图片进行去噪后,使用更加优秀的
神经网络对目标进行分类和定位,以获得更好的准确率。
5)噪声是复杂的,在现实生活中,我们观察到的噪声很难被单纯理解为加性白噪声,对其他种类的噪声,使用
该种去噪方法可能不尽如人意。
结束语
近年来,对图像进行分类和定位已成为具有吸引力和极大发展潜力的课题,而本文提供的抗噪声的对图像进行
分类和定位已成为了极具吸引力前景的重要问题。本文展示了基于小波变换的图像去噪方法,对加性白噪声进行了
尝试性的消除,提高了图片信噪比,之后我们介绍了基于ResNet的图片分类方法,在YOLO的帮助下,我们可以更进
一步的对图像进行有效的分类和定位,但仍然存在着非常大的局限性,可能导致其应用被限制于具体的领域。最终
我们将模型部署于具有潜力的MATLAB mobile上,使其能够在日常生活中用于对随手拍到的图片进行分类和定位。
致谢
感谢两江国际学院对我的培养,四年来,两江国际学院教师们严谨工作的作风一直是我学习的榜样,尤其感谢
我的论文指导老师杨如民教授对我的悉心指导,协助我完成了此次毕业设计。

欢迎加入DeepSeek 技术社区。在这里,你可以找到志同道合的朋友,共同探索AI技术的奥秘。
更多推荐


 32
32 0
0- 0



 已为社区贡献1条内容
已为社区贡献1条内容

所有评论(0)