参数少,实力强,QwQ-32B 成大模型新宠!
的卓越性能,凭借强化学习、高效参数利用、智能体集成等创新技术,成为大模型领域的一匹黑马。Hugging Face 提供了便捷的 API,可以快速使用 QwQ-32B 进行推理。随着 AI 技术不断进步,QwQ-32B 的成功也启发我们——参数规模并非唯一衡量标准,QwQ-32B 的成功,离不开强化学习(RL)技术的突破。,类似一支训练有素的精锐部队,虽然规模小,但战斗力极强。的强化学习扩展方法,从
在大模型领域,新模型的发布总能吸引大量关注。而阿里旗下通义千问 Qwen 团队推出的 QwQ-32B,无疑是一颗重磅炸弹。这款 仅 320 亿参数 的推理模型,在性能上展现出惊人实力,甚至可与 6710 亿参数(其中 370 亿被激活)的 DeepSeek-R1 相媲美,被誉为大模型界的“黑马”!
在参数竞赛激烈的大模型时代,人们普遍认为 参数越多,性能越强。然而,QwQ-32B 颠覆了这一认知,以 更少的参数实现卓越性能,堪比“身材小巧却力量惊人的超级英雄”。它在一系列基准测试中的表现更是让人眼前一亮,成为 AI 研究领域的焦点。

QwQ-32B 的技术“内核”:为何能以小博大?
1. 强化学习:性能飞跃的“秘密武器”
QwQ-32B 的成功,离不开强化学习(RL)技术的突破。研发团队采用了一种 基于结果导向奖励(Outcome Based Reward) 的强化学习扩展方法,从冷启动检查点开始,逐步提升模型能力。
-
第一阶段:数学 & 编程能力强化
- 采用 数学问题准确性验证器 确保计算结果正确,类似一位严格的数学老师逐题检查答案。
- 通过 代码执行服务器 验证代码是否通过测试用例,仅合格代码才能获得奖励。
- 训练过程中,数学和编程能力持续增强。
-
第二阶段:通用能力扩展
- 在数学与编程达到高水平后,进一步进行通用任务强化训练。
- 结合 通用奖励模型 和 基于规则的验证器,提升指令遵循、智能推理等综合能力。
- 使 QwQ-32B 在多方面均衡发展,成为“全能型选手”。
2. 小身材,大能量:高效参数利用
通常,大模型的能力往往与参数规模正相关。然而,QwQ-32B 仅 320 亿参数,相比 DeepSeek-R1 的 6710 亿参数(370 亿被激活),仅为其 1/20,却在关键测试中表现出色!
关键在于 创新的强化学习策略,让 每个参数都物尽其用,类似一支训练有素的精锐部队,虽然规模小,但战斗力极强。这不仅 降低训练成本和计算资源需求,也为大模型研究提供了新的方向。
3. 智能体集成:思考与反馈的进化
QwQ-32B 还融入了 智能体(Agent)能力,增强了自主推理与环境适应性:
- 在解决问题时,结合环境信息与已有知识进行 深入思考与分析。
- 依据用户反馈 动态调整推理路径,优化解题过程。
- 在处理复杂任务时,展现出更灵活、智能的决策能力,提高实际应用价值。
实测验证:QwQ-32B 的真实实力
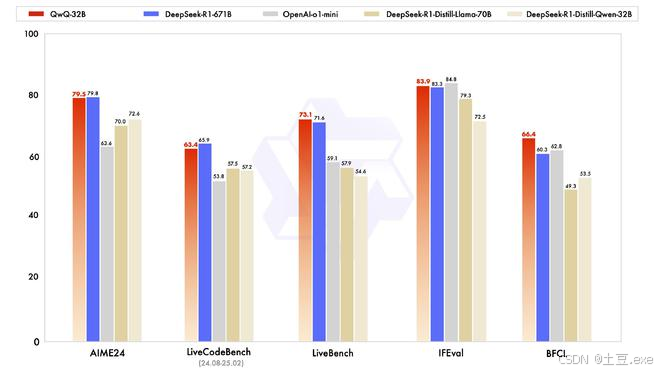
1. 数学 & 编程:与 DeepSeek-R1 旗鼓相当
在 AIME24 数学推理测试 和 LiveCodeBench 编程能力测试 中,QwQ-32B 的表现几乎与 DeepSeek-R1 相当,甚至超越 o1-mini 等模型:
- 数学推理:准确解决代数、几何等复杂问题,解题思路严谨,计算精准。
- 编程能力:能够快速理解需求,生成高质量代码,并通过严格测试用例验证。
2. 通用能力:超越 DeepSeek-R1
在多项权威评测中,QwQ-32B 甚至超越 DeepSeek-R1,展示出更强的通用任务处理能力:
- LiveBench(最难 LLM 评测)
- IFEval(谷歌提出的指令遵循能力评测)
- BFCL(UC 伯克利提出的函数调用评估)
这表明 QwQ-32B 在 指令理解、工具调用、复杂任务处理 方面更加优秀,能更好地适应真实应用场景。
代码示例:手把手教你使用 QwQ-32B
如果你想体验 QwQ-32B,以下是两种最常见的调用方式。
方式一:Hugging Face Transformers 调用
Hugging Face 提供了便捷的 API,可以快速使用 QwQ-32B 进行推理。
from transformers import AutoModelForCausalLM, AutoTokenizer
# 设定模型名称
model_name = "Qwen/QwQ-32B"
# 加载模型与分词器
model = AutoModelForCausalLM.from_pretrained(model_name, torch_dtype="auto", device_map="auto")
tokenizer = AutoTokenizer.from_pretrained(model_name)
# 用户输入
prompt = "How many r's are in the word \"strawberry\""
# 构建对话消息
messages = [{"role": "user", "content": prompt}]
text = tokenizer.apply_chat_template(messages, tokenize=False, add_generation_prompt=True)
# 处理输入并生成回答
model_inputs = tokenizer([text], return_tensors="pt").to(model.device)
generated_ids = model.generate(**model_inputs, max_new_tokens=32768)
# 解析输出
output = tokenizer.decode(generated_ids[0], skip_special_tokens=True)
print(output)
结语:QwQ-32B 开启大模型新篇章
QwQ-32B 以 320 亿参数 实现 媲美 6710 亿参数模型 的卓越性能,凭借强化学习、高效参数利用、智能体集成等创新技术,成为大模型领域的一匹黑马。
随着 AI 技术不断进步,QwQ-32B 的成功也启发我们——参数规模并非唯一衡量标准,更智能的训练策略、更高效的计算方式,才是未来 AI 发展的关键方向!

欢迎加入DeepSeek 技术社区。在这里,你可以找到志同道合的朋友,共同探索AI技术的奥秘。
更多推荐


 16
16 0
0- 0



 已为社区贡献1条内容
已为社区贡献1条内容

所有评论(0)