【AI论文】VBench-2.0:推动视频生成基准套件发展,聚焦内在真实性评估
视频生成技术已取得显著进展,从生成不真实的输出,发展到能够制作出视觉上令人信服且时间连贯的视频。为了评估这些视频生成模型,已经开发了诸如VBench等基准测试工具来评估其真实性,衡量因素包括每帧的美学效果、时间一致性以及对基本提示的遵循程度。然而,这些方面主要体现的是表面真实性,即关注视频在视觉上是否令人信服,而非其是否遵循现实世界的原则。尽管最近的模型在这些指标上表现越来越好,但它们仍然难以生成
摘要:视频生成技术已取得显著进展,从生成不真实的输出,发展到能够制作出视觉上令人信服且时间连贯的视频。为了评估这些视频生成模型,已经开发了诸如VBench等基准测试工具来评估其真实性,衡量因素包括每帧的美学效果、时间一致性以及对基本提示的遵循程度。然而,这些方面主要体现的是表面真实性,即关注视频在视觉上是否令人信服,而非其是否遵循现实世界的原则。尽管最近的模型在这些指标上表现越来越好,但它们仍然难以生成不仅视觉上合理而且从根本上符合现实的视频。要通过视频生成实现真正的“世界模型”,下一个前沿领域在于确保内在真实性,即确保生成的视频遵循物理定律、常识推理、解剖正确性和构图完整性。实现这一水平的真实性对于人工智能辅助电影制作和模拟世界建模等应用至关重要。为了弥合这一差距,我们推出了VBench-2.0,这是一个下一代基准测试工具,旨在自动评估视频生成模型的内在真实性。VBench-2.0评估五个关键维度:人物真实性、可控性、创造性、物理性和常识性,每个维度又进一步细分为更精细的能力。针对各个维度,我们的评估框架整合了通用型工具,如最先进的视觉语言模型(VLMs)和大型语言模型(LLMs),以及专业型工具,包括为视频生成提出的异常检测方法。我们进行了广泛的标注工作,以确保评估结果与人类判断一致。通过超越表面真实性,追求内在真实性,VBench-2.0旨在为下一代视频生成模型树立新的标准,以追求内在真实性为目标。Huggingface链接:Paper page,论文链接:2503.21755
研究背景和目的
研究背景
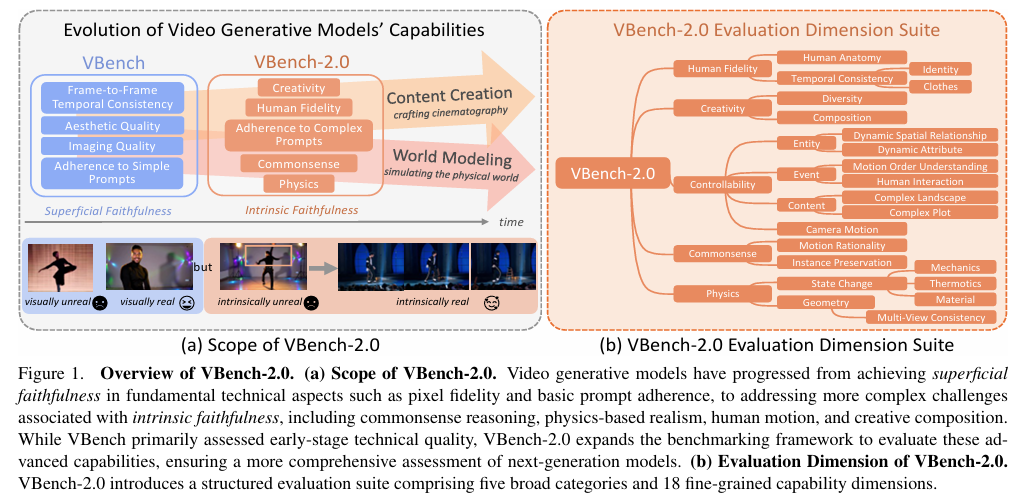
随着深度学习技术的不断发展,视频生成领域取得了显著进步。早期的视频生成模型主要聚焦于生成视觉上合理且时间连贯的短视频片段,强调基础技术能力,如每帧的美学效果、时间平滑性以及基本文本提示的遵循程度。这些方面被统称为表面真实性(Superficial Faithfulness),即视频在视觉上是否令人信服。然而,随着视频生成技术的进一步推进,尤其是在人工智能辅助电影制作和模拟世界建模等应用领域,对生成视频的要求已经远远超出了表面真实性的范畴。
为了更全面地评估视频生成模型的能力,需要引入更深层次的真实性标准,即内在真实性(Intrinsic Faithfulness)。内在真实性要求生成的视频不仅要视觉上合理,而且要遵循现实世界的物理定律、常识推理、解剖正确性和构图完整性。这些更高级别的能力对于开发能够真正理解并模拟世界的视频生成模型至关重要。
研究目的
VBench-2.0基准测试套件的研究目的在于推动视频生成技术的进一步发展,从表面真实性向内在真实性迈进。具体而言,该研究旨在:
- 建立全面的评估框架:开发一个能够评估视频生成模型内在真实性的多维度基准测试套件。
- 细化评估维度:将内在真实性细分为五个关键维度——人物真实性、可控性、创造性、物理性和常识性,并进一步细分为更精细的能力子维度。
- 整合先进评估工具:结合最先进的视觉语言模型(VLMs)和大型语言模型(LLMs)等通用型工具,以及为视频生成提出的异常检测等专业型工具,构建评估框架。
- 确保与人类判断的一致性:通过广泛的人类标注工作,确保评估结果与人类对视频真实性的感知相一致。
- 树立新的评估标准:为下一代视频生成模型树立追求内在真实性的新标准,推动该领域的技术进步。
研究方法
评估维度与细分
VBench-2.0将视频生成模型的内在真实性评估细分为五个关键维度,每个维度又进一步细分为多个子维度:
- 人物真实性(Human Fidelity):评估生成视频中人物结构的正确性和时间一致性,包括人体解剖结构的准确性、身份和衣物的跨帧一致性等。
- 可控性(Controllability):评估模型遵循复杂提示和模拟动态变化的能力,包括实体、事件、内容和相机运动的准确渲染。
- 创造性(Creativity):评估模型生成多样化输出和复杂构图的能力,超越现实世界的约束。
- 物理性(Physics):评估模型模拟物理状态变化的能力,包括力学、热力学和材料转换等。
- 常识性(Commonsense):评估模型在常识推理方面的能力,包括运动合理性和实例保持等。
评估方法
针对每个评估维度,VBench-2.0采用了多种评估方法:
- 文本描述对齐:适用于复杂或微妙的场景,如涉及微妙人物互动或多步骤情节的情况。通过视觉语言模型(VLM)生成描述性字幕,并使用大型语言模型(LLM)判断字幕与参考文本的一致性。
- 基于视频的多问题回答:适用于显著概念突出且可直接通过视频问题回答(VQA)评估的维度。通过构建一系列互补和冗余的问题来减少偶然错误的风险。
- 异常检测:针对人物真实性等维度,使用预训练的异常检测模型来检测视频中的人物结构异常。
基准测试套件设计
VBench-2.0基准测试套件精心设计了针对每个评估维度的提示集,每个维度包含约70个提示,以系统地分析模型在该维度的核心能力。提示集的设计遵循结构化原则,确保评估的聚焦性和鲁棒性。
研究结果
基准测试结果
VBench-2.0对四个最新的视频生成模型(Kling 1.6、Sora-480p、Hunyuan-Video和CogVideoX-1.5)进行了评估。评估结果显示,这些模型在不同维度上表现出不同的优势和局限性:
- Sora-480p:在人物真实性和创造性维度上表现突出,但在可控性、物理性和常识性维度上表现较差。
- Kling 1.6:在常识性、可控性以及与相机相关的维度(如多视角一致性和相机运动)上表现出色,但在人物真实性维度上表现较弱。
- CogVideoX-1.5:在复杂提示遵循(如复杂景观和复杂情节)和物理性维度上表现良好,但在人物相关维度(如人物真实性和运动合理性)上表现不佳。
- Hunyuan-Video:在人物相关维度上表现出色,但在复杂情节和动态属性捕捉方面存在不足。
人类对齐验证
为了确保VBench-2.0的评估结果与人类判断相一致,研究团队进行了大规模的人类偏好标注工作。结果显示,VBench-2.0的评估结果与人类偏好在大多数维度上高度相关,验证了评估框架的有效性和可靠性。
研究局限
尽管VBench-2.0在评估视频生成模型的内在真实性方面取得了显著进展,但仍存在一些局限性:
- 评估维度的局限性:尽管VBench-2.0涵盖了五个关键维度,但视频生成技术的内在真实性可能涉及更多方面,如情感表达、文化敏感性和社会常识等,这些方面尚未纳入评估框架。
- 模型依赖:评估结果高度依赖于所选择的视频生成模型。随着新模型的不断涌现,评估框架需要不断更新和扩展,以涵盖更广泛的模型能力。
- 数据质量:评估结果受到训练数据质量的影响。高质量、多样化的训练数据对于提高视频生成模型的内在真实性至关重要。
- 评估成本:生成和评估长视频片段的计算成本较高,限制了评估框架的广泛应用。
未来研究方向
针对VBench-2.0的局限性,未来研究可以从以下几个方面展开:
- 扩展评估维度:将更多内在真实性相关的方面纳入评估框架,如情感表达、文化敏感性和社会常识等。
- 持续更新评估框架:随着新模型的涌现,不断更新和扩展评估框架,以涵盖更广泛的模型能力。
- 提高数据质量:收集和整理高质量、多样化的训练数据,以提高视频生成模型的内在真实性。
- 降低评估成本:开发更高效的评估方法和工具,降低生成和评估长视频片段的计算成本。
- 结合人类反馈:将人类反馈融入评估框架,以更准确地模拟人类对视频真实性的感知。
- 探索跨学科合作:结合物理学、心理学、社会学等多学科的知识和方法,共同推动视频生成技术的发展。
通过持续的研究和探索,VBench-2.0有望不断完善和发展,为视频生成技术的内在真实性评估树立新的标准,推动该领域的技术进步和应用拓展。

欢迎加入DeepSeek 技术社区。在这里,你可以找到志同道合的朋友,共同探索AI技术的奥秘。
更多推荐


 34
34 0
0- 0



 已为社区贡献76条内容
已为社区贡献76条内容

所有评论(0)