TPAMI 2025 —— 视觉基础大模型综述与展望:定义视觉新时代的基础模型
本综述系统梳理了此类新兴基础模型的研究进展,涵盖多模态融合(视觉、文本、音频等)的典型架构设计、训练目标(对比学习、生成式学习)、预训练数据集、微调机制以及文本、视觉和异构提示范式等核心要素。通过系统性综述基础模型在多个领域的最新应用进展,本文为研究者提供了全面的技术图谱。本综述的独特价值体现在三个方面:首先,突破文本提示VL模型的单一范畴,系统覆盖文本提示(对比式、生成式、混合式、对话式)、视觉

GitHub - awaisrauf/Awesome-CV-Foundational-Models
Vision systems to see and reason about the compositional nature of visual scenes are fundamental to understanding our world. The complex relations between objects and their locations, ambiguities, and variations in the real-world environment can be better described in human language, naturally governed by grammatical rules and other modalities such as audio and depth. The models learned to bridge the gap between such modalities coupled with large-scale training data facilitate contextual reasoning, generalization, and prompt capabilities at test time. These models are referred to as foundational models. The output of such models can be modified through human-provided prompts without retraining, e.g., segmenting a particular object by providing a bounding box, having interactive dialogues by asking questions about an image or video scene or manipulating the robot's behavior through language instructions. In this survey, we provide a comprehensive review of such emerging foundational models, including typical architecture designs to combine different modalities (vision, text, audio, etc), training objectives (contrastive, generative), pre-training datasets, fine-tuning mechanisms, and the common prompting patterns; textual, visual, and heterogeneous. We discuss the open challenges and research directions for foundational models in computer vision, including difficulties in their evaluations and benchmarking, gaps in their real-world understanding, limitations of their contextual understanding, biases, vulnerability to adversarial attacks, and interpretability issues. We review recent developments in this field, covering a wide range of applications of foundation models systematically and comprehensively. A comprehensive list of foundational models studied in this work is available at \url{this https URL}.
视觉系统理解场景构成性本质的能力是认知世界的基础。现实环境中物体间复杂的空间关系、语义歧义性及形态多样性,可通过人类语言的语法结构以及音频、深度等多模态信息获得更精准的描述。通过融合多模态信息并借助大规模训练数据学习的基础模型,能够有效弥合跨模态鸿沟,从而在测试阶段展现出卓越的上下文推理、泛化能力和即时响应能力。这类模型无需重新训练即可通过人类指令调整输出结果,例如通过边界框定位特定目标、通过问答实现图像/视频场景的交互式对话,或通过语言指令控制机器人行为。本综述系统梳理了此类新兴基础模型的研究进展,涵盖多模态融合(视觉、文本、音频等)的典型架构设计、训练目标(对比学习、生成式学习)、预训练数据集、微调机制以及文本、视觉和异构提示范式等核心要素。我们深入探讨了计算机视觉基础模型面临的开放性挑战与研究方向,包括评估体系构建难题、现实认知鸿沟、上下文理解局限、数据偏见、对抗攻击脆弱性及可解释性瓶颈等关键问题。通过系统性综述基础模型在多个领域的最新应用进展,本文为研究者提供了全面的技术图谱。
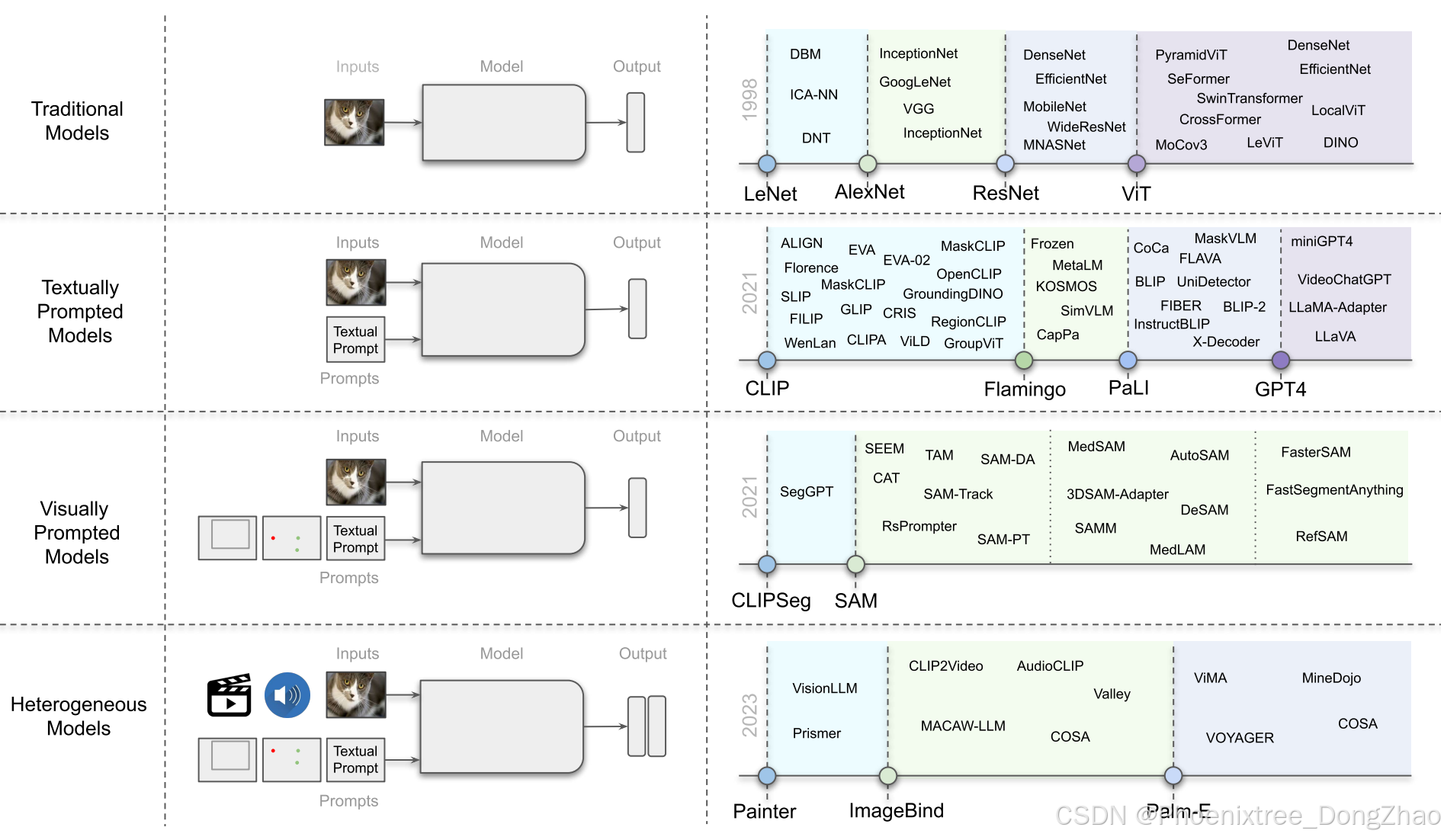
Fig. 1. Overview of the evolution of foundational models in computer vision. (left) We show the progression of models in computer vision. (right) We show the evolution of these models with major milestones reported in the literature shown with dotted lines.
INTRODUCTION
Recent years have witnessed remarkable success towards developing foundation models, that are trained on a large-scale broad data, and once trained, they operate as a basis and can be adapted (e.g., fine-tuned) to a wide range of downstream tasks related to the original trained model [18]. While the basic ingredients of the foundation models, such as deep neural networks and self-supervised learning, have been around for many years, the recent surge, specifically through large language models (LLMs), can be mainly attributed to massively scaling up both data and model size [346]. For instance, recent models with billion parameters such as GPT-3 [20] have been effectively utilized for zero/few-shot learning, achieving impressive performance without requiring large-scale task-specific data or model parameter updating. Similarly, the recent 540-billion parameter Pathways Language Model (PaLM) has demonstrated state-of-the-art capabilities on numerous challenging problems ranging from language understanding and generation to reasoning and code-related tasks [52, 8].
Concurrent to LLMs in natural language processing, large foundation models for different perception tasks have also been explored in the literature recently. For instance, pre-trained vision-language models (VL) such as CLIP [214] have demonstrated promising zero-shot performance on different downstream vision tasks, including image classification and object detection. These VL foundation models are typically trained using millions of image-text pairs collected from the web and provide representations with generalization and transfer capabilities. These pre-trained VL foundation models can then be adapted to a downstream task by presenting it with a natural language description of the given task and prompts. For instance, the seminal CLIP model utilizes carefully designed prompts to operate on different downstream tasks, including zero-shot classification, where the text encoder dynamically constructs the classifiers via class names or other free-form texts. Here, the textual prompts are handcrafted templates, e.g., “A photo of a {label}”, that aid in specifying the text as corresponding to the visual image content. Recently, numerous works have also explored adding conversational capabilities to the VL models by fine-tuning them on a specific instruction set [169, 360, 57, 190, 314].
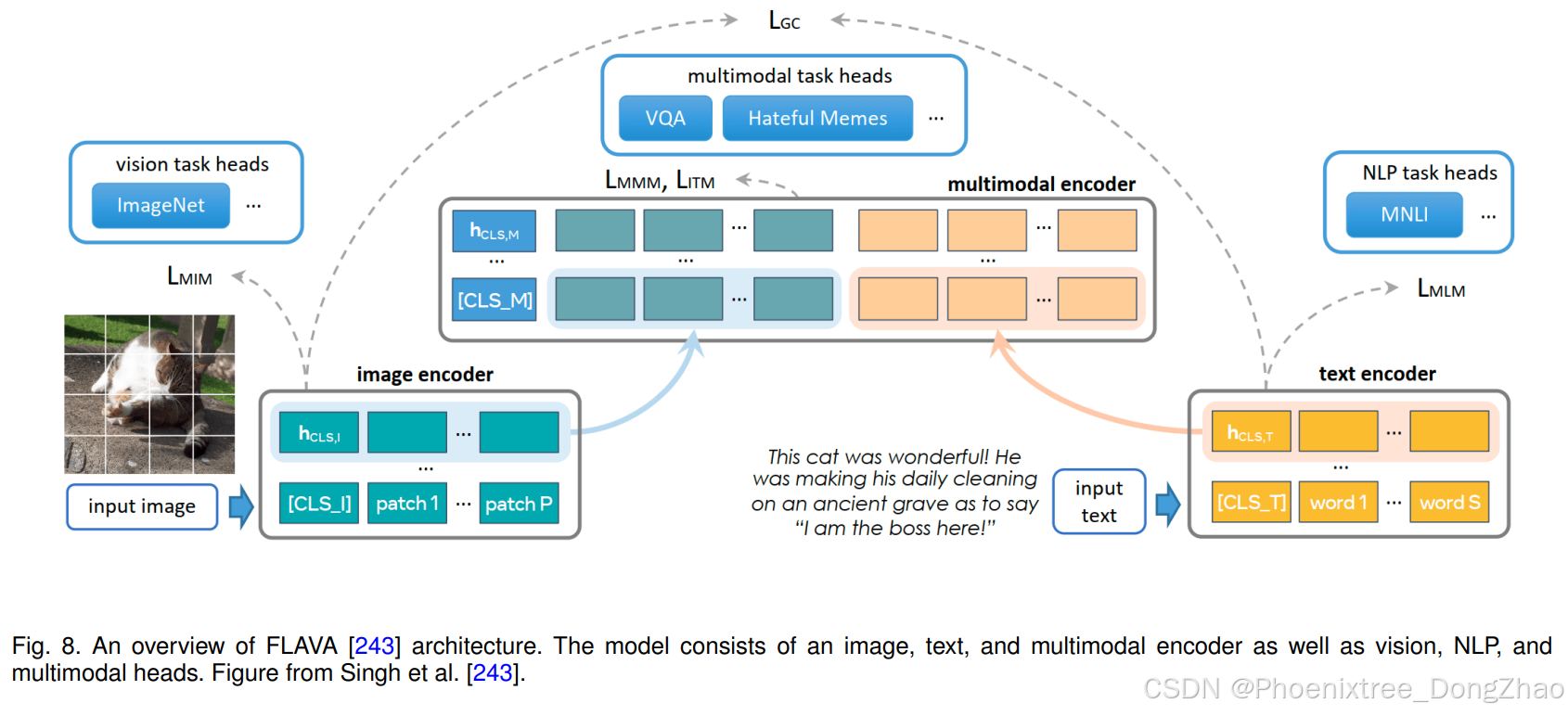
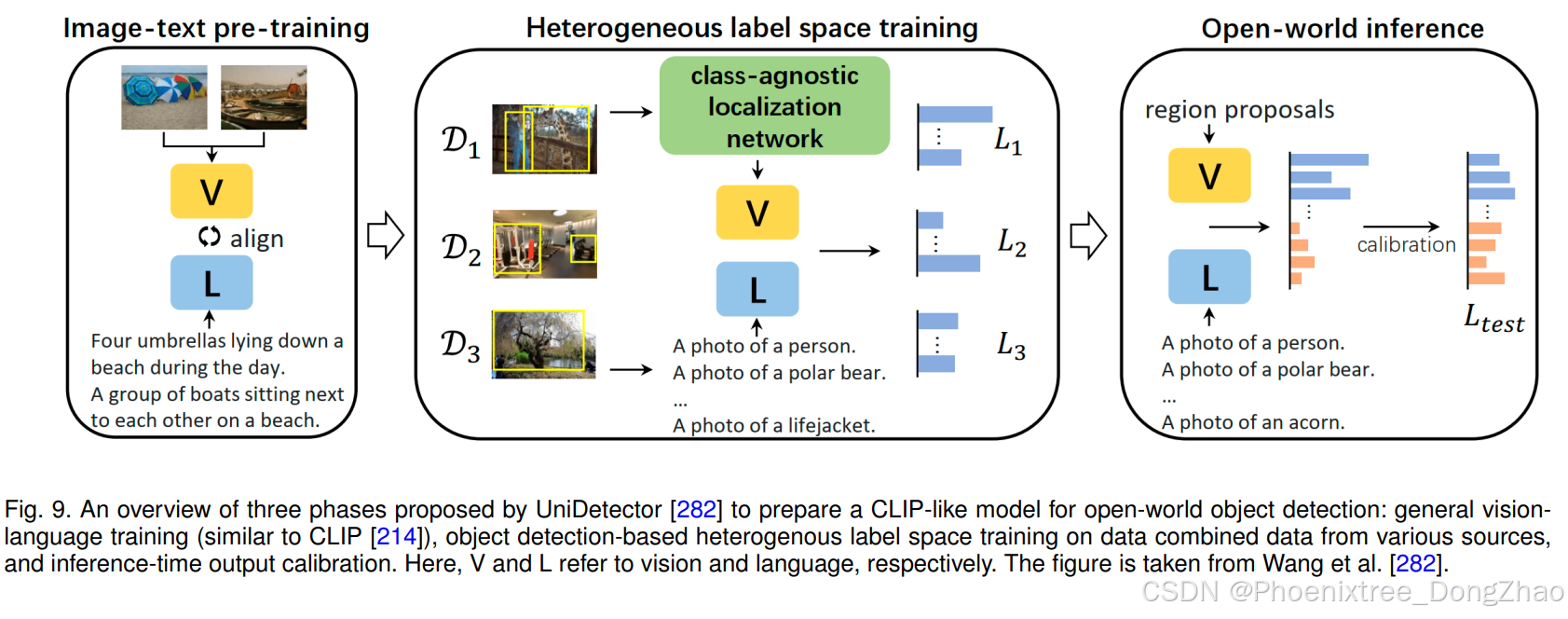
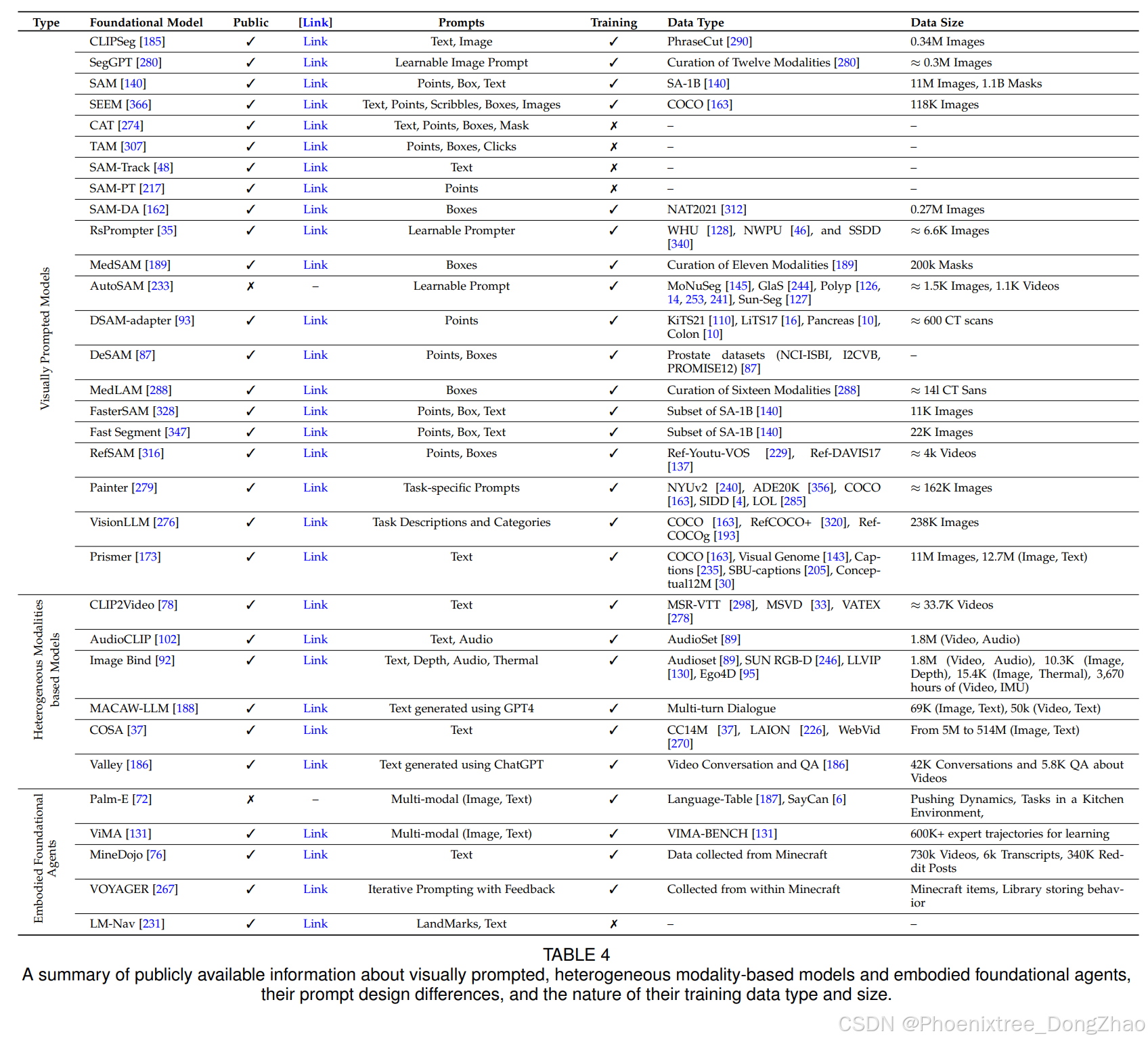
Besides large VL foundation models, several research efforts have been devoted to developing large foundation models that visual inputs can prompt. For instance, the recently introduced SAM [140] performs a class-agnostic segmentation given an image and a visual prompt such as box, point, or mask, which specifies what to segment in an image. Such a model is trained on billions of object masks following a model-in-the-loop (semi-automated) dataset annotation setting. Further, such a generic visual prompt-based segmentation model can be adapted for specific downstream tasks such as medical image segmentation [189, 292], video object segmentation [316], robotics [303], and remote sensing [35]. In addition to textual and visual prompt-based foundation models, research works have explored developing models that strive to align multiple paired modalities (e.g., image-text, video-audio, or image-depth) to learn meaningful representations helpful for different downstream tasks [92, 102, 188].
近年来,基础模型研究取得显著突破。这类模型通过大规模广域数据训练后,可作为通用基底通过适配(如微调)迁移到各类下游任务。尽管基础模型的核心组件(如深度神经网络和自监督学习)已存在多年,但近期突破——尤其是通过大型语言模型(LLMs)实现的——主要归功于数据规模和模型参数量的指数级扩展。例如,具有百亿级参数的GPT-3已成功应用于零样本/少样本学习,在无需任务专用数据或参数更新的情况下展现出卓越性能。最新5400亿参数的Pathways语言模型(PaLM)更是在语言理解、生成、推理及代码任务等复杂问题上达到最先进水平。
在自然语言处理领域LLMs快速发展的同时,计算机视觉领域也涌现出面向感知任务的基础模型。预训练视觉-语言模型(如CLIP)通过数百万网络图像-文本对训练,展现出强大的零样本迁移能力,可有效处理图像分类、目标检测等下游任务。这类模型通过自然语言描述和提示工程即可适配具体任务,如CLIP通过精心设计的文本模板(如"A photo of a {label}")动态构建分类器,实现零样本分类。近期研究更通过指令微调赋予VL模型对话交互能力。
除文本提示模型外,基于视觉提示的基础模型研究也取得重要进展。SAM模型通过边界框、点或掩码等视觉提示实现类别无关的图像分割,其训练数据包含数十亿个通过"模型参与"半自动标注的物体掩码。该模型已成功应用于医学图像分割、视频目标分割、机器人技术和遥感分析等专用领域。此外,多模态对齐模型通过联合学习图像-文本、视频-音频、图像-深度等跨模态关联,为下游任务提供更具泛化性的表征]。
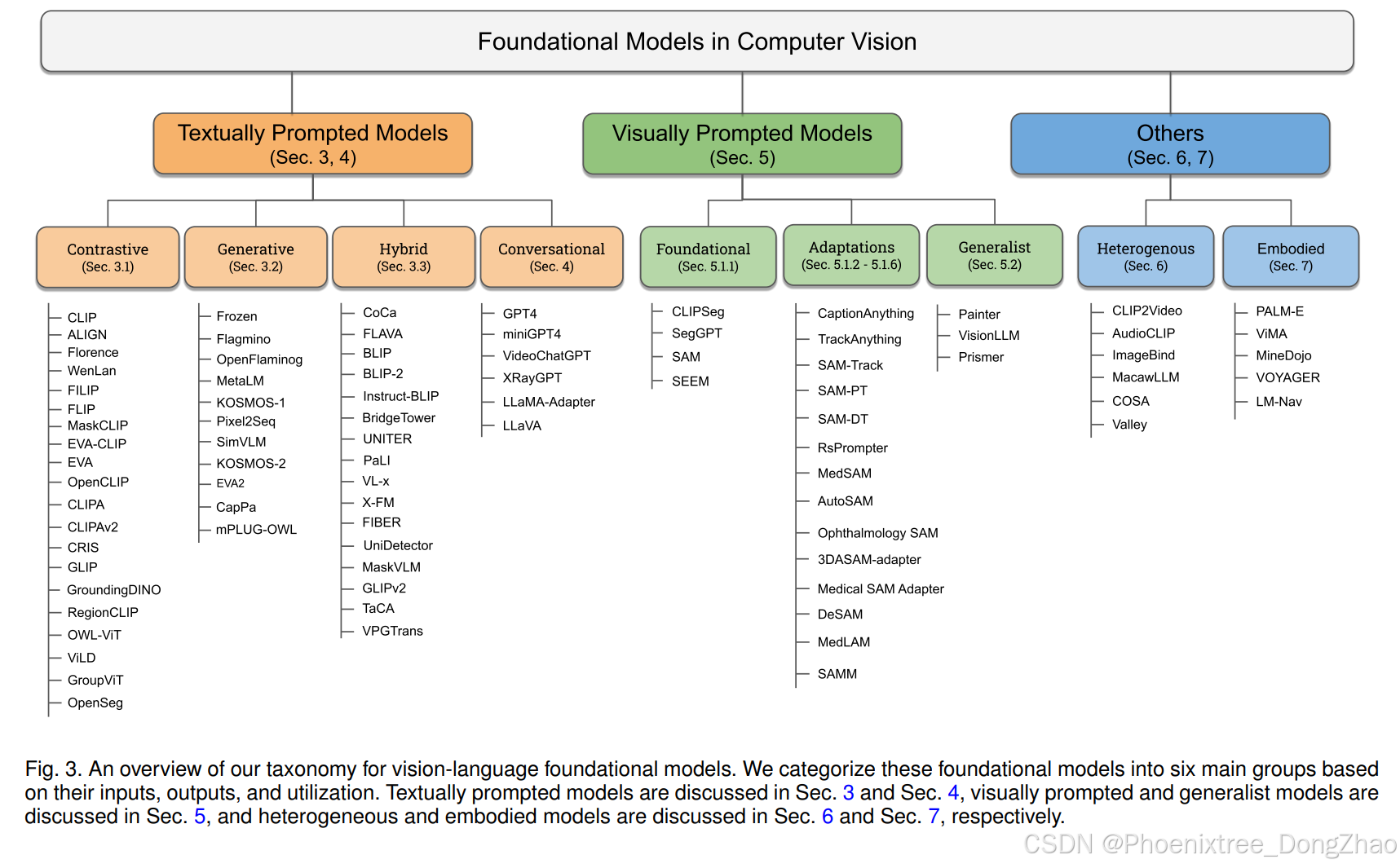
In this work, we present a systematic review of foundation models in computer vision. First, we present the background and preliminaries for foundation models briefly covering common architecture types, self-supervised learning objectives, large-scale training, and prompt engineering (Sec. 2). Then, we distinguish existing works into textually prompted (Sec. 3-4), visually prompted (Sec. 5), heterogeneous modality-based (Sec. 6) and embodied foundation models (Sec. 7). Within the textually prompted foundation models, we further distinguish them into contrastive, generative, hybrid (contrastive and generative), and conversational VL models. Finally, we discuss open challenges and research directions based on our analysis (Sec. 8). Next, we review other surveys related to ours and discuss the differences and uniqueness.
Related Reviews and Differences. In the literature, few recent works have reviewed large language models (LLMs) in natural language processing [346, 77, 119, 65, 357]. The work of Zhao et al. [346] reviews recent advances in LLMs, distinguishing different aspects of LLMs such as pre-training, adaptation tuning, LLM utilization, and evaluation. This survey also summarizes resources available to develop LLMs and discusses potential future directions. The work of [119] discusses LLMs in terms of their reasoning capabilities in performing a benchmark evaluation. A practical guide for practitioners using LLMs is presented in [306], where a detailed discussion and insights are provided regarding the usage of LLMs from the viewpoint of downstream tasks. This work also analyzes the impact of pre-training, training, and testing data on LLMs. Furthermore, the work also discusses different limitations of LLMs in real-world scenarios. In the context of VLMs, the work of [180] performs a preliminary review of vision-language pre-trained models regarding task definition and general architecture. Similarly, [73] discusses different techniques to encode images and texts to embeddings before the pretraining step and reviews different pre-training architectures. The work of [299] reviews transformers techniques for multimodal data with a survey of vanilla transformers, vision transformers, and multimodal transformers from a geometrically topological perspective. In the context of multimodal learning, the recent review [364] focuses on self-supervised multimodal learning techniques to effectively utilize supervision from raw multimodal data. The survey distinguishes existing approaches based on objective functions, data alignment, and architectures. The work of [132, 84] summarizes different vision-language pre-training network architectures, objectives, and downstream tasks and categorizes vision-language pre-training frameworks. Recently, the work of [331] reviews the visually prompted foundation segmentation model, segmenting anything, and discusses its potential downstream tasks.
The main differences between this survey and the aforementioned works are as follows. Unlike previous surveys that primarily focus on textual prompt-based vision-language models, our work focuses on the three different classes of foundation models: textually prompted models (contrastive, generative, hybrid, and conversational), visually prompted models (e.g., SegGPT [280], SAM [140]) and heterogeneous modalities-based models (e.g., ImageBind [92], Valley [186]). We present the background theory behind foundation models, briefly covering from architectures to prompt engineering (Sec. 2). Our work provides an extensive and up-to-date overview of the recent vision foundation models (Sec. 3, 5, 6, and 7). Finally, we present a detailed discussion on open challenges and potential research directions of foundation models in computer vision (Sec. 8).
本综述系统性梳理计算机视觉基础模型研究进展:首先阐述基础模型的理论基础,涵盖典型架构、自监督学习目标、大规模训练及提示工程(第2节);继而将现有工作划分为文本提示模型(第3-4节)、视觉提示模型(第5节)、异构模态模型(第6节)和具身基础模型(第7节),其中文本提示模型进一步细分为对比式、生成式、混合式及对话式VL模型;最后深入探讨领域开放挑战与研究方向(第8节)。下文将对比相关综述,阐明本研究的特色与创新。
相关综述对比。现有文献中,多篇综述聚焦自然语言处理领域的LLMs研究:Zhao等[346]从预训练、适配调优、模型应用及评估等维度系统回顾LLMs进展;[119]重点分析LLMs的推理能力基准测试;[306]则从实践角度提供LLMs应用指南,探讨数据分布对模型性能的影响及现实应用局限。在视觉-语言模型(VLMs)领域,[180]初步总结预训练模型的任务定义与架构;[73]分析图像文本编码技术及预训练架构;[299]从几何拓扑视角综述多模态Transformer技术;[364]专注自监督多模态学习方法。近期[331]专门评述视觉提示分割模型SAM及其应用。
本综述的独特价值体现在三个方面:首先,突破文本提示VL模型的单一范畴,系统覆盖文本提示(对比式、生成式、混合式、对话式)、视觉提示(如SegGPT、SAM)及异构模态(如ImageBind、Valley)三大类基础模型;其次,完整呈现基础模型的理论框架,从架构设计到提示工程(第2节);最后,提供截至最新的视觉基础模型全景图(第3、5、6、7节),并深入剖析计算机视觉基础模型面临的开放挑战(第8节)。
IMPORTANT FIGURES & TABLES
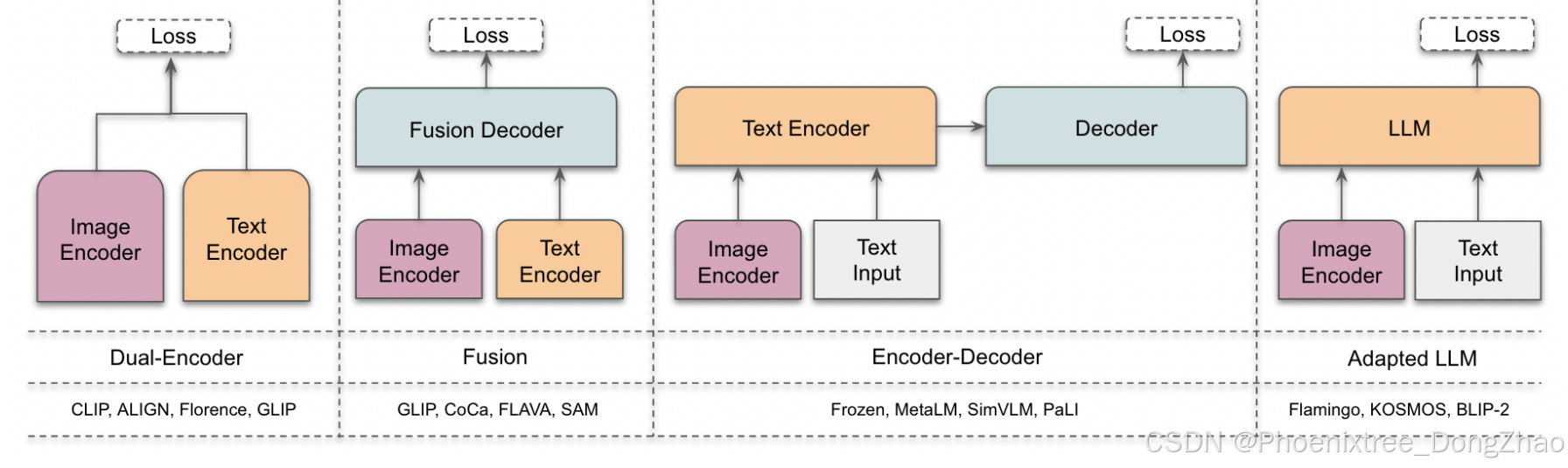
Fig. 2. Overview of four different architecture styles described in this survey. Left to right: a) Dual-encoder designs use a parallel visual and language encoder with aligned representations. b) Fusion designs jointly process both image and text representations via a decoder. Here the image encoder can also process visual prompts (e.g., points and boxes in the case of SAM [140]). c) Encoder-decoder designs apply joint feature encoding and decoding sequentially. d) Adapter LLM designs input visual and text prompts to the LLMs to leverage their superior generalization ability. Examples for each category are shown in the bottom row. More detail about these architectures is discussed in Sec. 2.2.

欢迎加入DeepSeek 技术社区。在这里,你可以找到志同道合的朋友,共同探索AI技术的奥秘。
更多推荐


 7
7 0
0- 0



 已为社区贡献6条内容
已为社区贡献6条内容

所有评论(0)