AI 时代 PDF 文档处理新选择:开源 PDF 解析工具粗评,快速找到适合你场景的工具!
TOP5开源PDF工具测试,测试采用人工扫描生成的纯扫描版PDF文档(OCR难度较高),文件包含复杂版式、多表格、公式等及文本内容,所有文档仅用于技术评测。
测试文档说明:
本次测试采用人工扫描生成的纯扫描版PDF文档(OCR难度较高),文件包含复杂版式、多表格、公式等及文本内容,所有文档仅用于技术评测。
一、测试环境
硬件配置:
CPU:Intel W-2275
内存:DDR4 256GB
存储:NVMe SSD 4TB(PCIe 4.0 x2)
GPU:RTX 3090(24GB显存,支持CUDA 12)
二、测试工具详情
Marker:基于PyMuPDF和Tesseract OCR,支持GPU加速(Surya OCR引擎),开源轻量化。
MinerU:集成LayoutLMv3、YOLOv8等模型,支持多模态解析(表格/公式/图像),精度可靠。
Ragflow:RAG知识库开源工具,专注深度文档理解。
olmocr:基于大语言模型的 PDF 处理流程,采用分布式架构,支持单机和多节点并行处理。
Markitdown:微软开源项目,集成GPT - 4等模型实现AI增强处理,支持多文件格式转换。
| 工具 | 版本 |
单页解析速度 |
个人评估安装难度 | Docker支持 | 备注 |
|---|---|---|---|---|---|
| Marker-pdf |
V1.5.5,最新版本 |
12s |
中高,权重文件下载慢,官方无中文教程 |
官方未提供,需自己编写 |
转换为markdown文件 |
| MinerU |
V1.2.0,最新版本 |
25s |
中,有中文教程,喂饭安装 |
官方提供Dockerfile |
|
| ragflow |
V0.16.0 |
20s |
中,有中文教程,喂饭安装 |
官方提供Dockerfile |
知识库分段 |
| olmocr |
官方试用版本 |
15s |
在线版本,暂未本地部署 |
暂未查看 |
线上转换出来的 是LaTeX表达式形式 |
| maritdown |
V0.0.2,最新版本 |
1s |
中,无中文教程 |
官方提供Dockerfile |
这个快是因为只是提取纯文本 |
本次测试,文档都是纯扫描版(图片),markitdow由于我没有配置对应llm接口,所以PDF解析没有对应的内容输出,下面效果就暂时不列出来了
场景一:文本 + 表达式测试
| 原文档 | MinerU | Marker-pdf | olmOCR | ragflow |
|---|---|---|---|---|
 |
 |
 |
 |
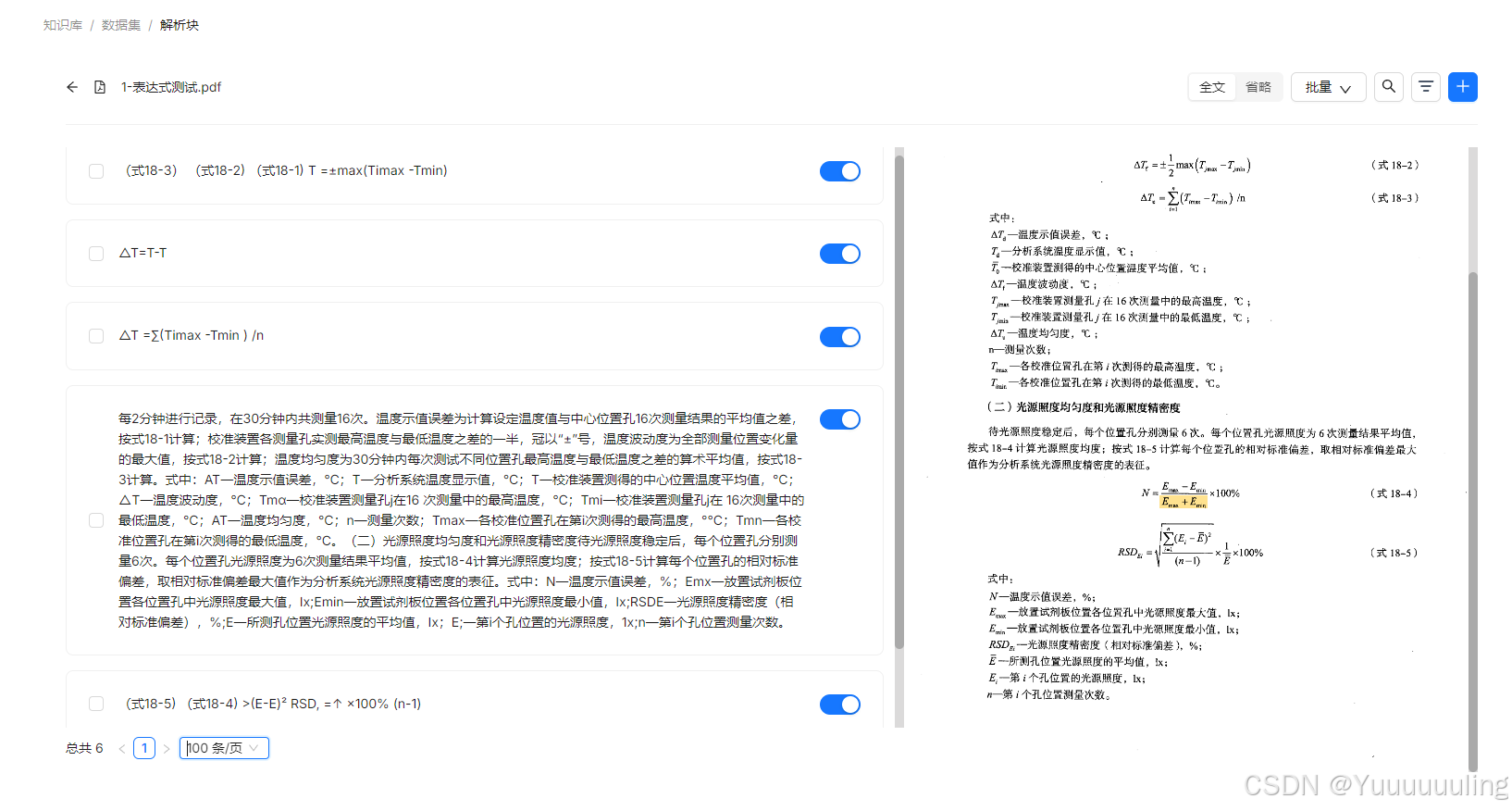 |
场景二:文本 + 表达式 + 表格测试
| 原文档 | MinerU | Marker-pdf | olmOCR | ragflow |
|---|---|---|---|---|
 |
|
|
|
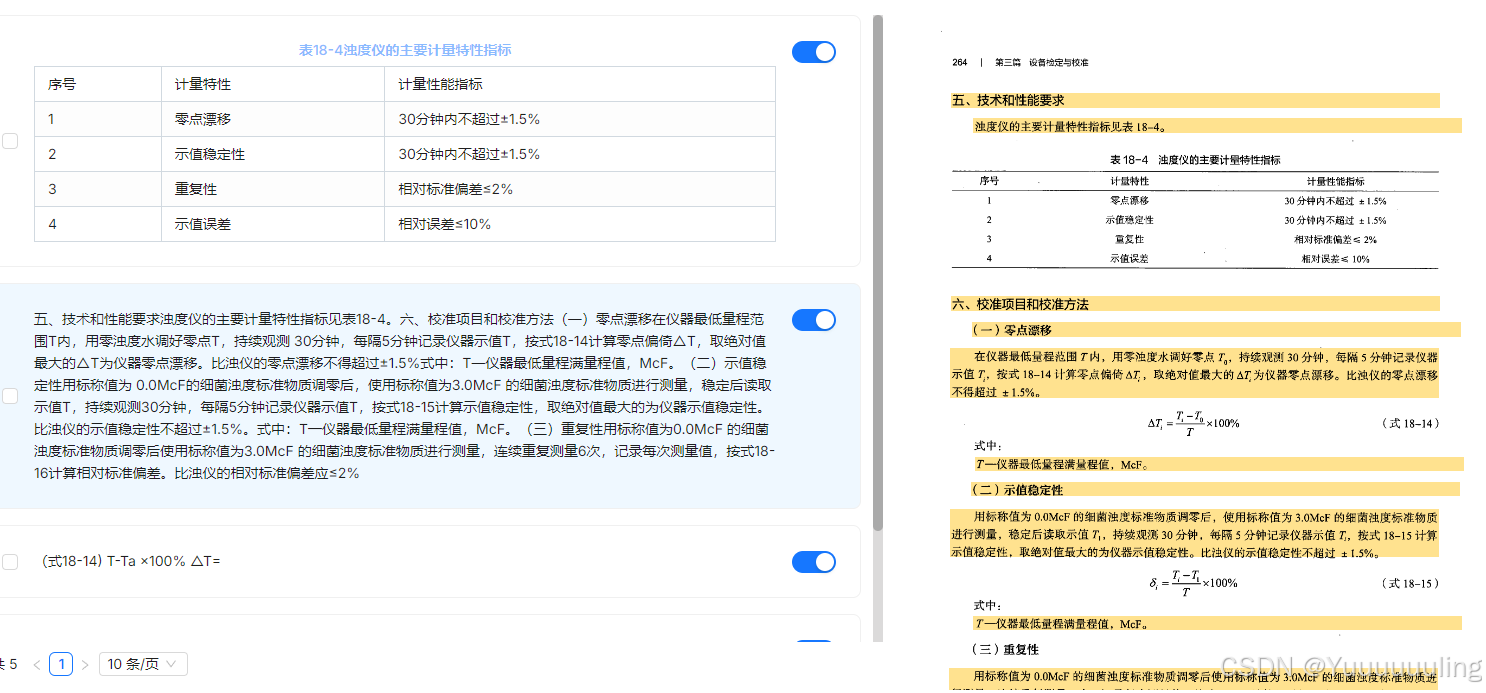 |




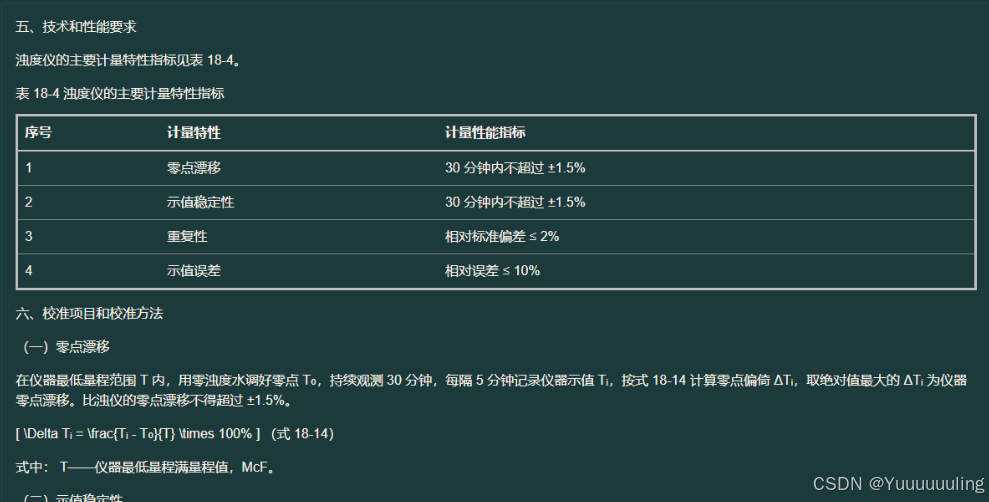
场景三:文本 + 单表格测试
|
原文档 |
MinerU |
Marker-pdf |
olmOCR |
ragflow |
|---|---|---|---|---|
 |
|
|
 |
 |




场景四:文本 + 多表格测试
|
原文档 |
MinerU |
Marker-pdf |
olmOCR |
ragflow |
|---|---|---|---|---|
 |
|
|
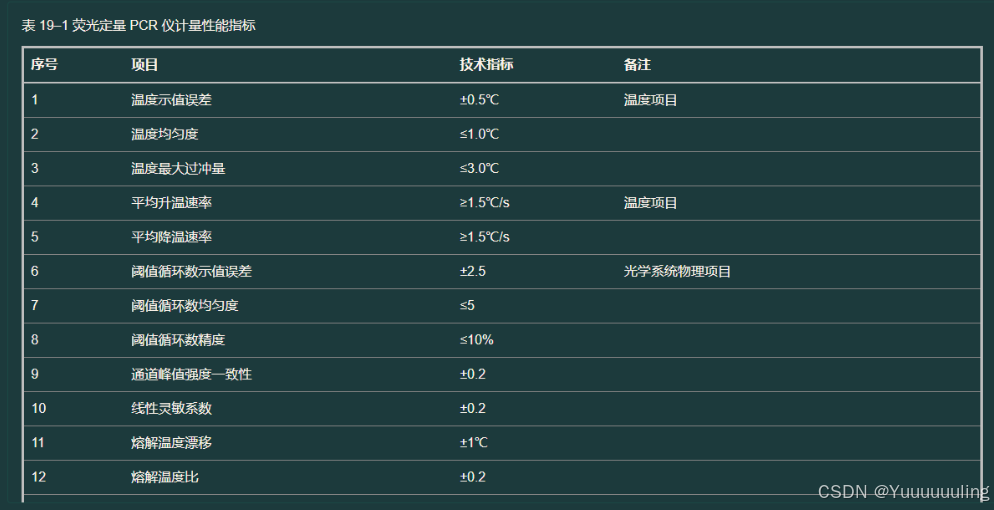 |
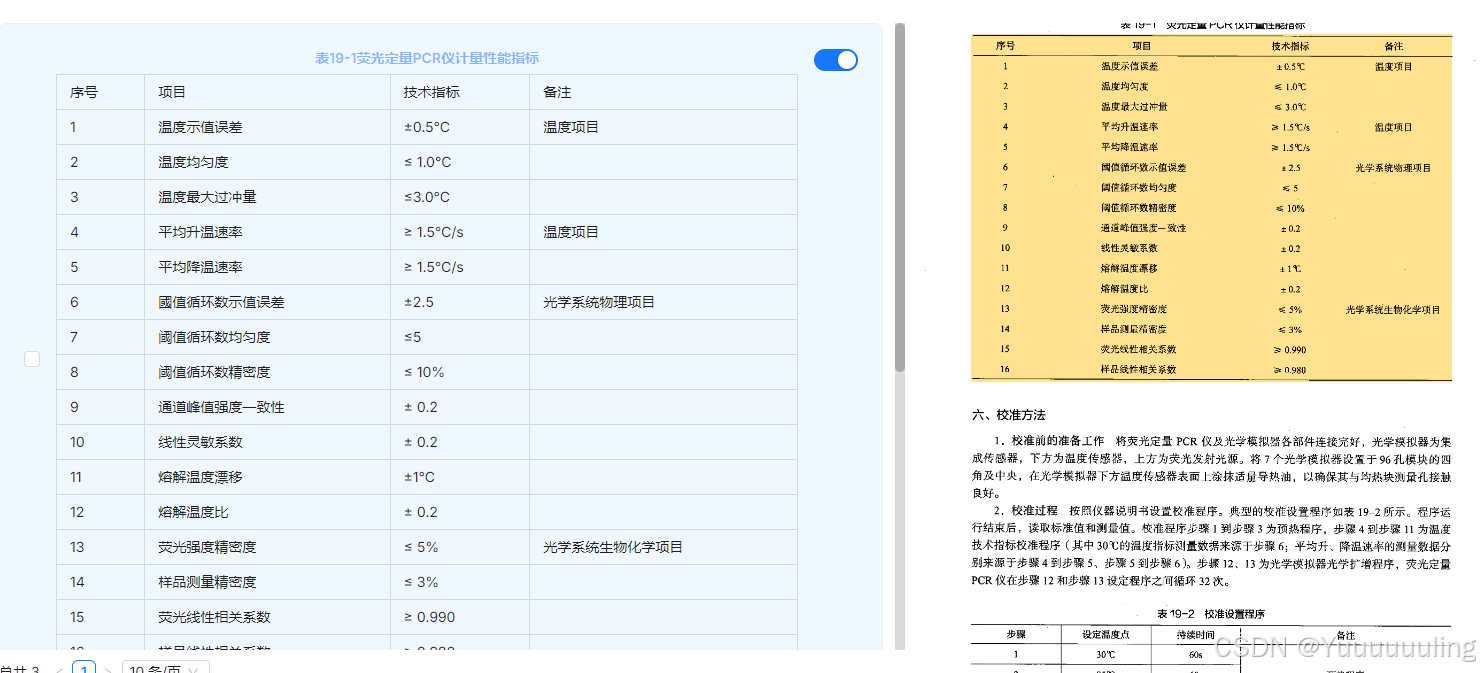 |
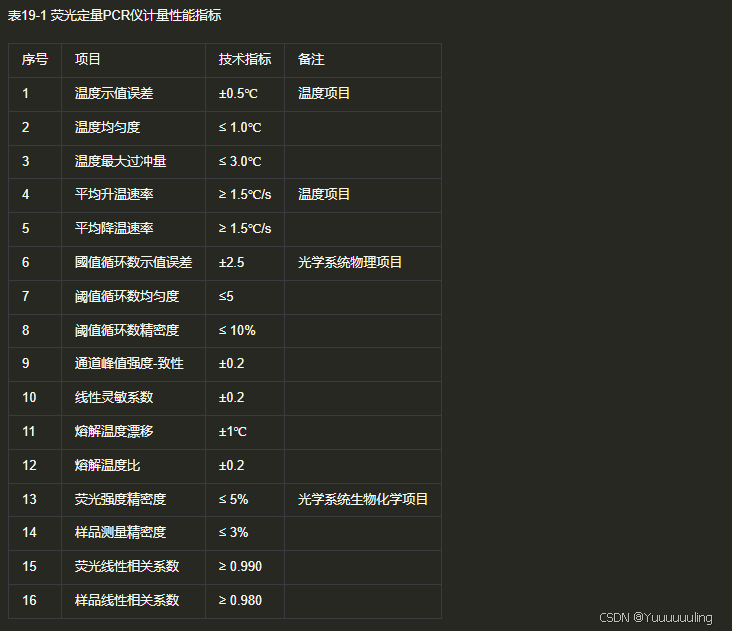

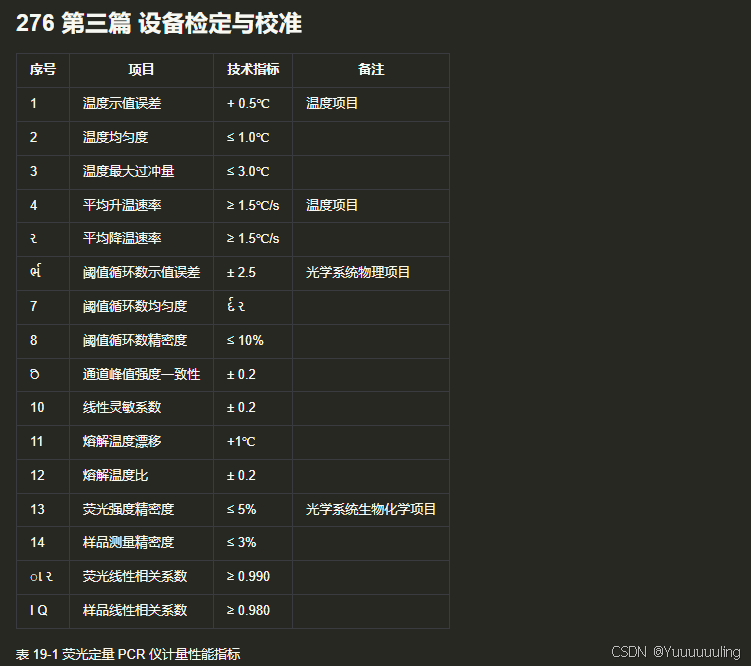
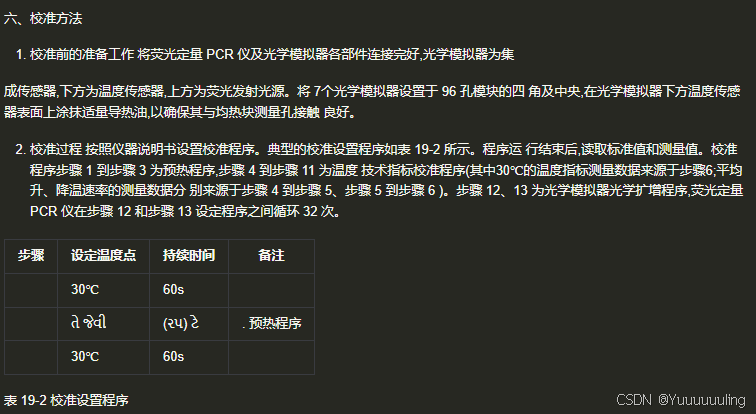
场景五:文本 + 折线图测试
|
原文档 |
MinerU |
Marker-pdf |
olmOCR |
ragflow |
|---|---|---|---|---|
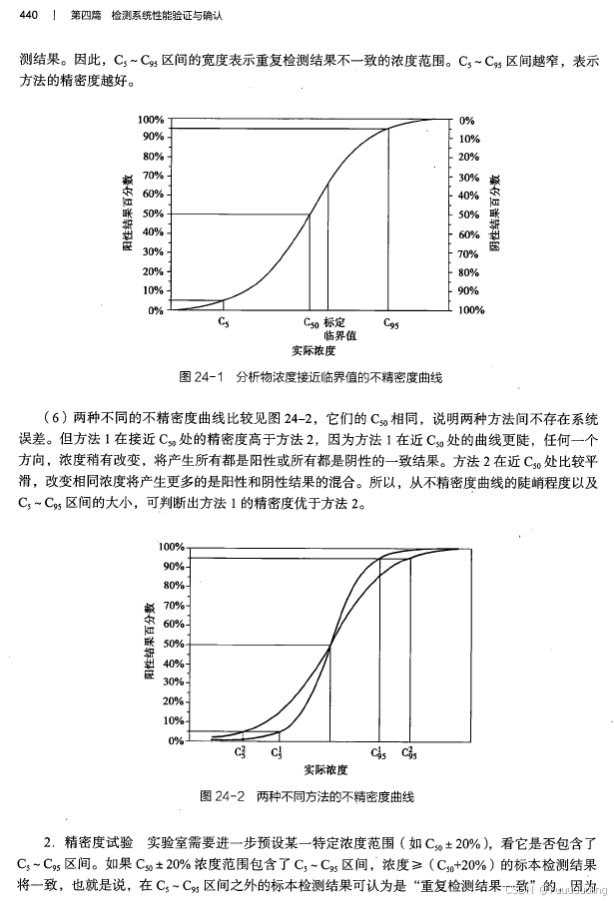 |
|
|
 |
 |
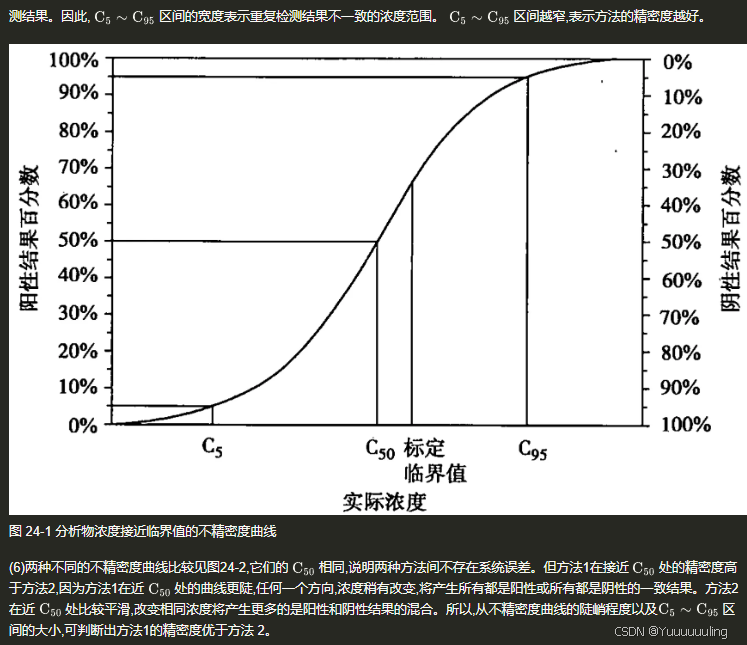
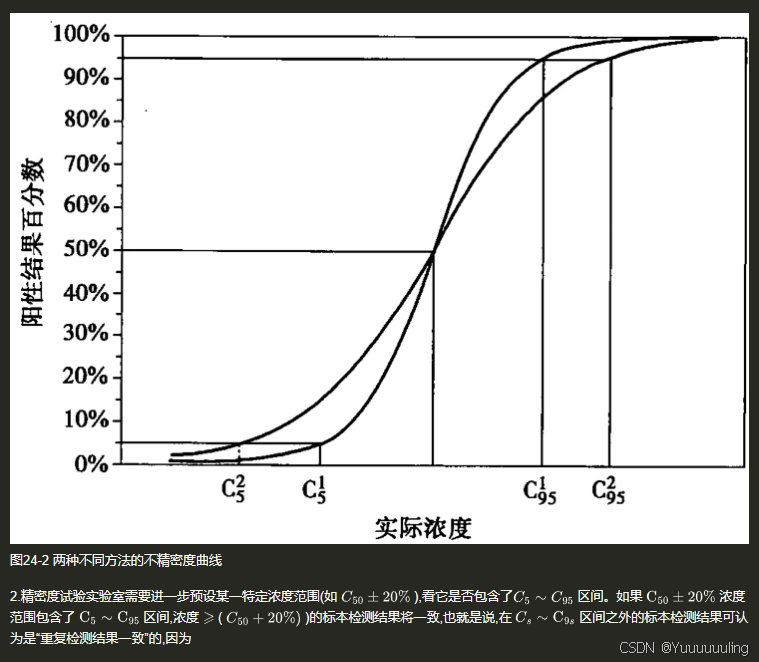
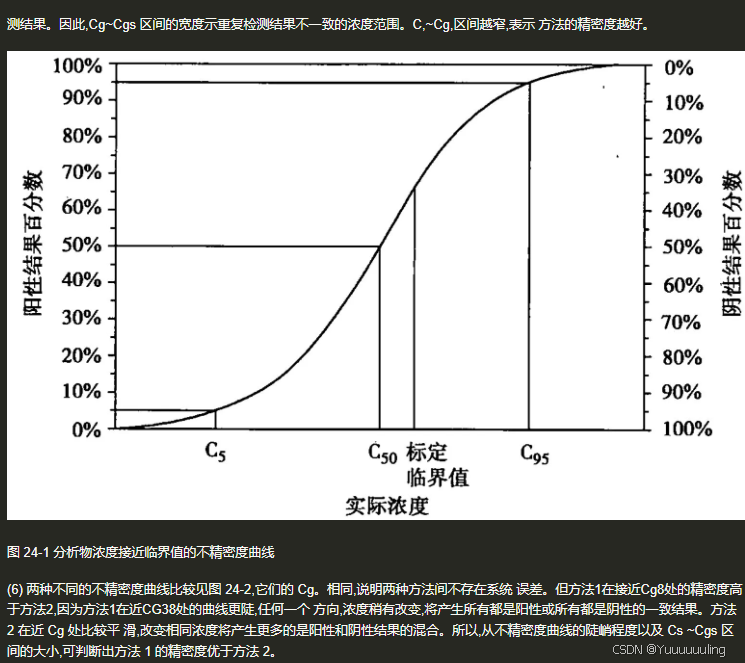
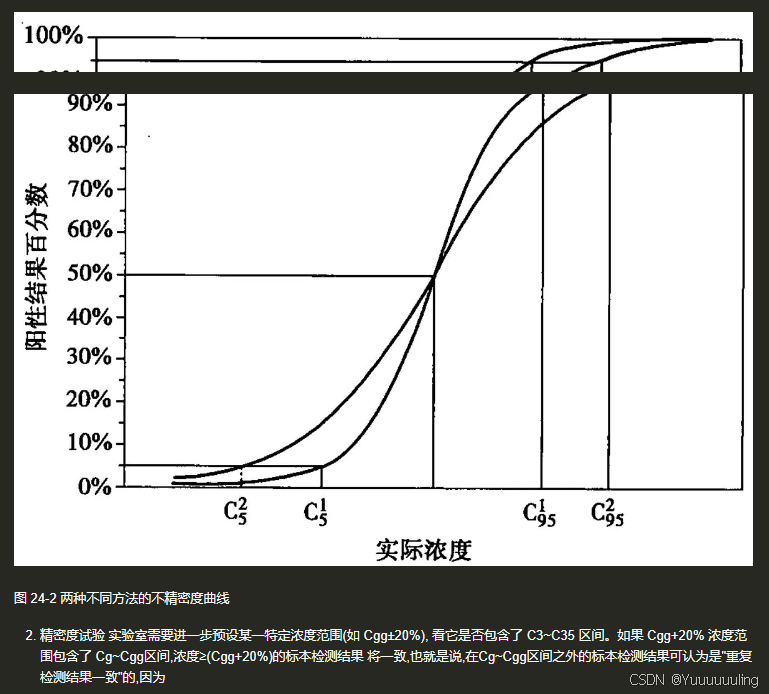
场景六:文本 + 流程图测试
|
原文档 |
MinerU |
Marker-pdf |
olmOCR |
ragflow |
|---|---|---|---|---|
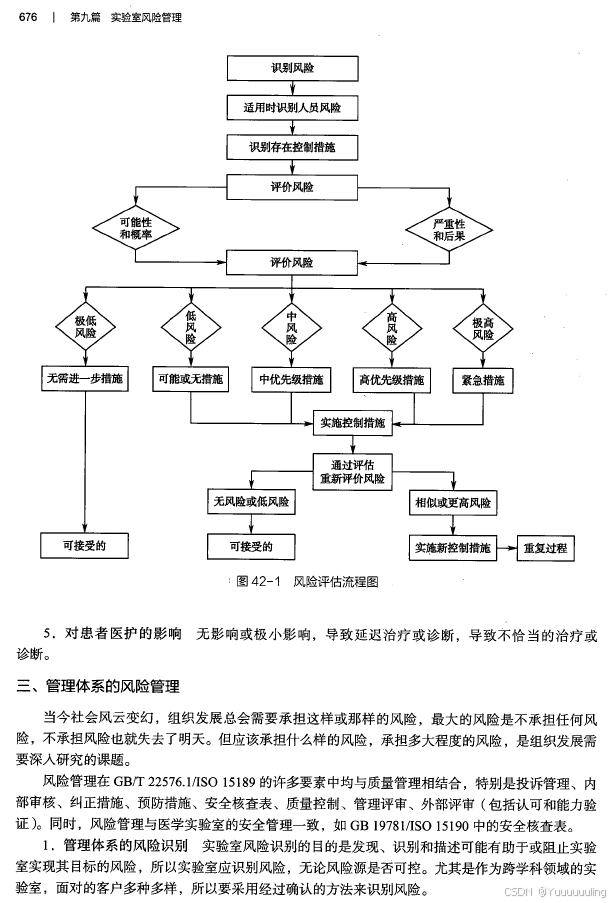 |
|
|
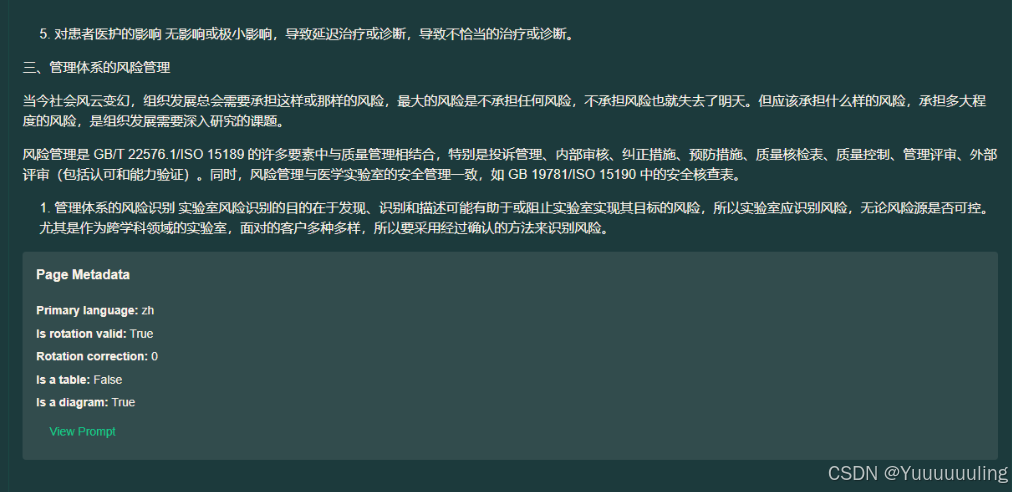 |
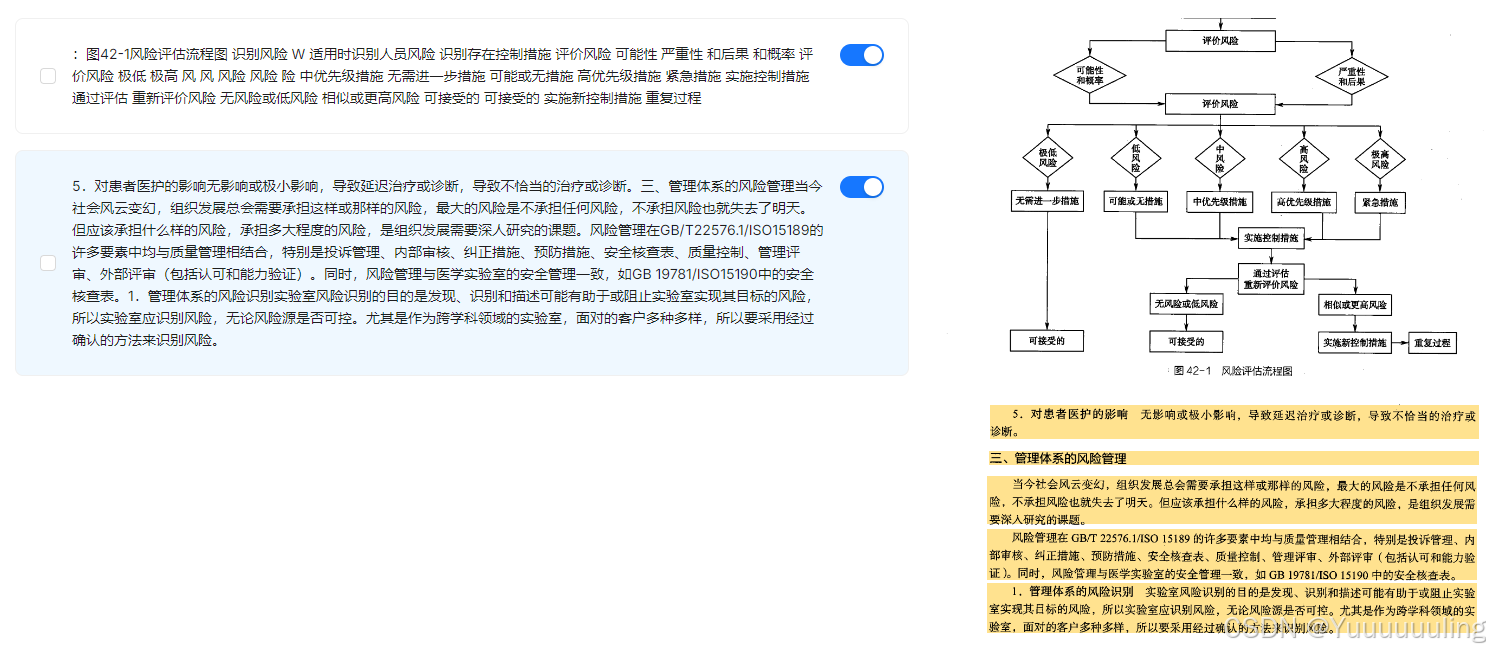 |
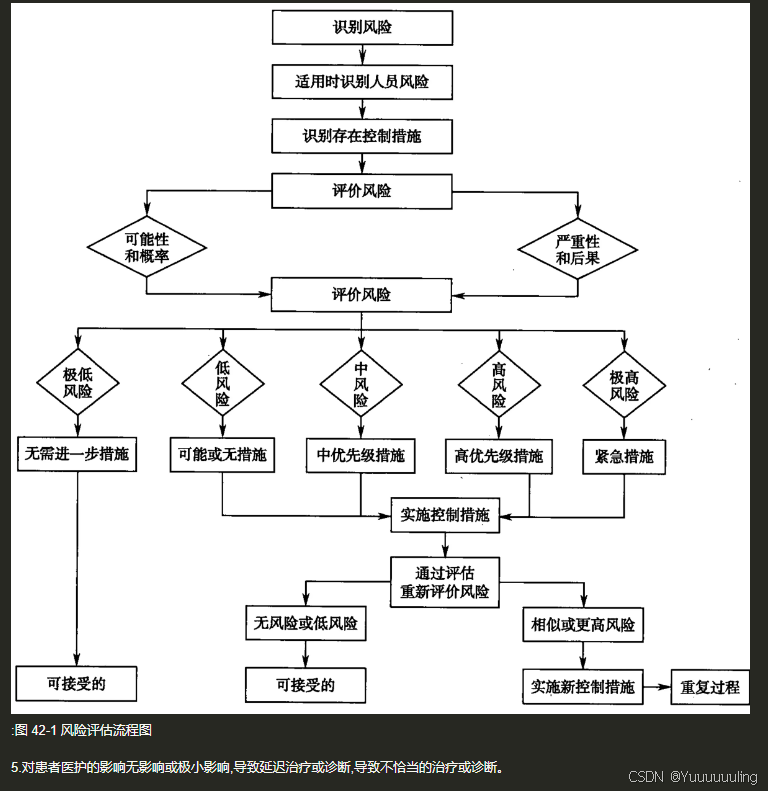

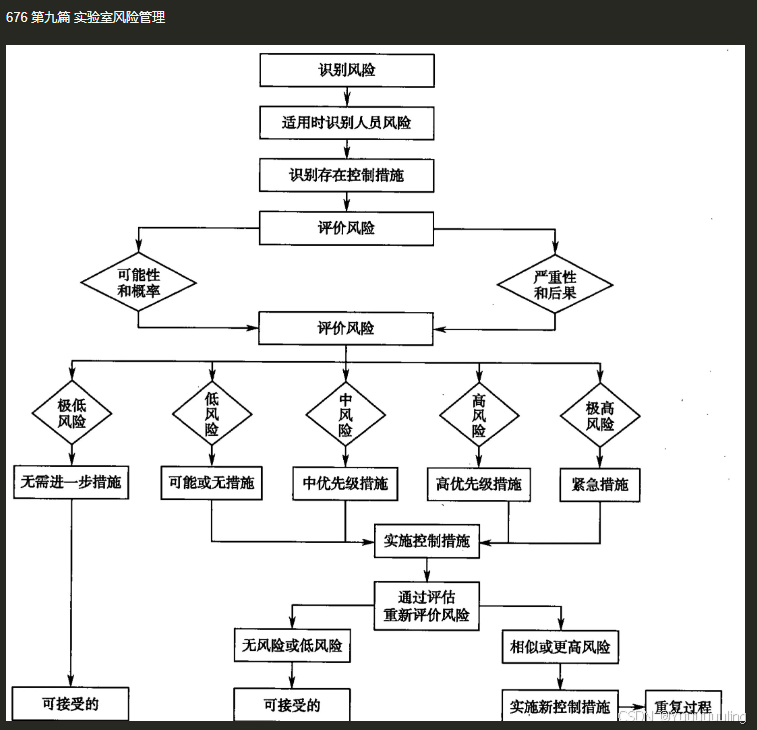

场景七:简单思维导图测试
|
原文档 |
MinerU |
Marker-pdf |
olmOCR |
ragflow |
|---|---|---|---|---|
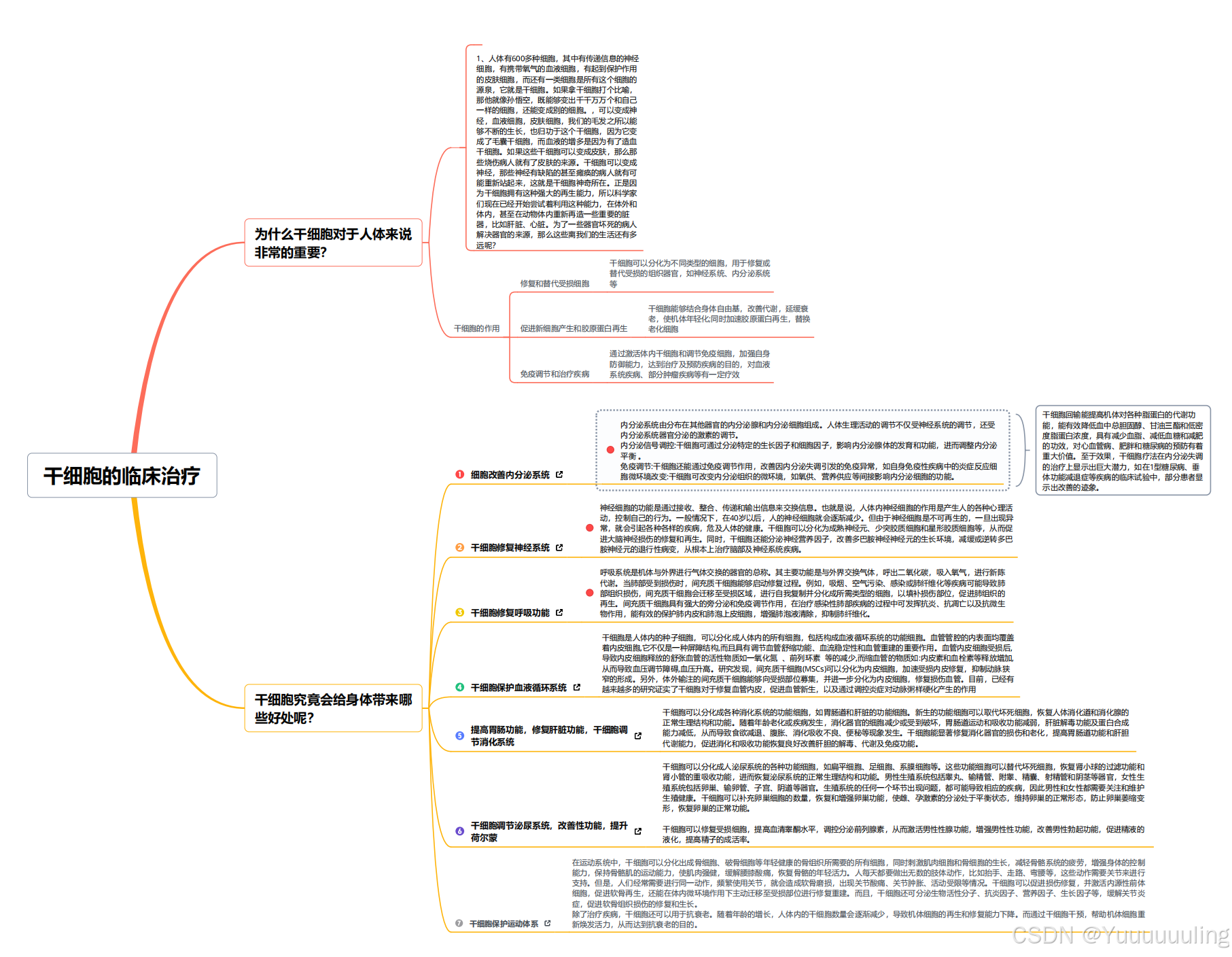 |
|
|
|
 |
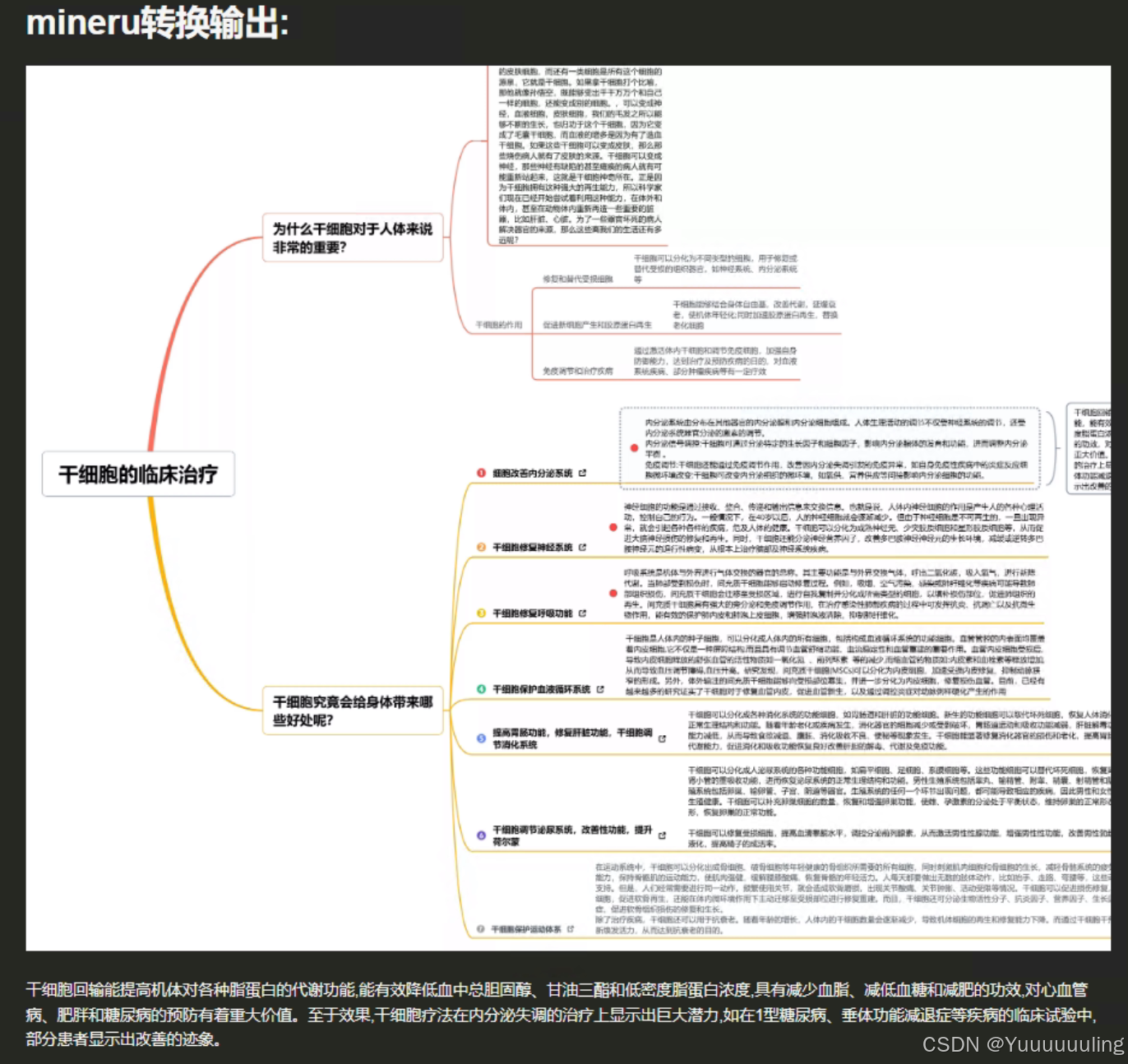





场景八:简单文本数字纯表格PDF(图片版)
|
原文档 |
MinerU |
Marker-pdf |
olmOCR |
ragflow |
|---|---|---|---|---|
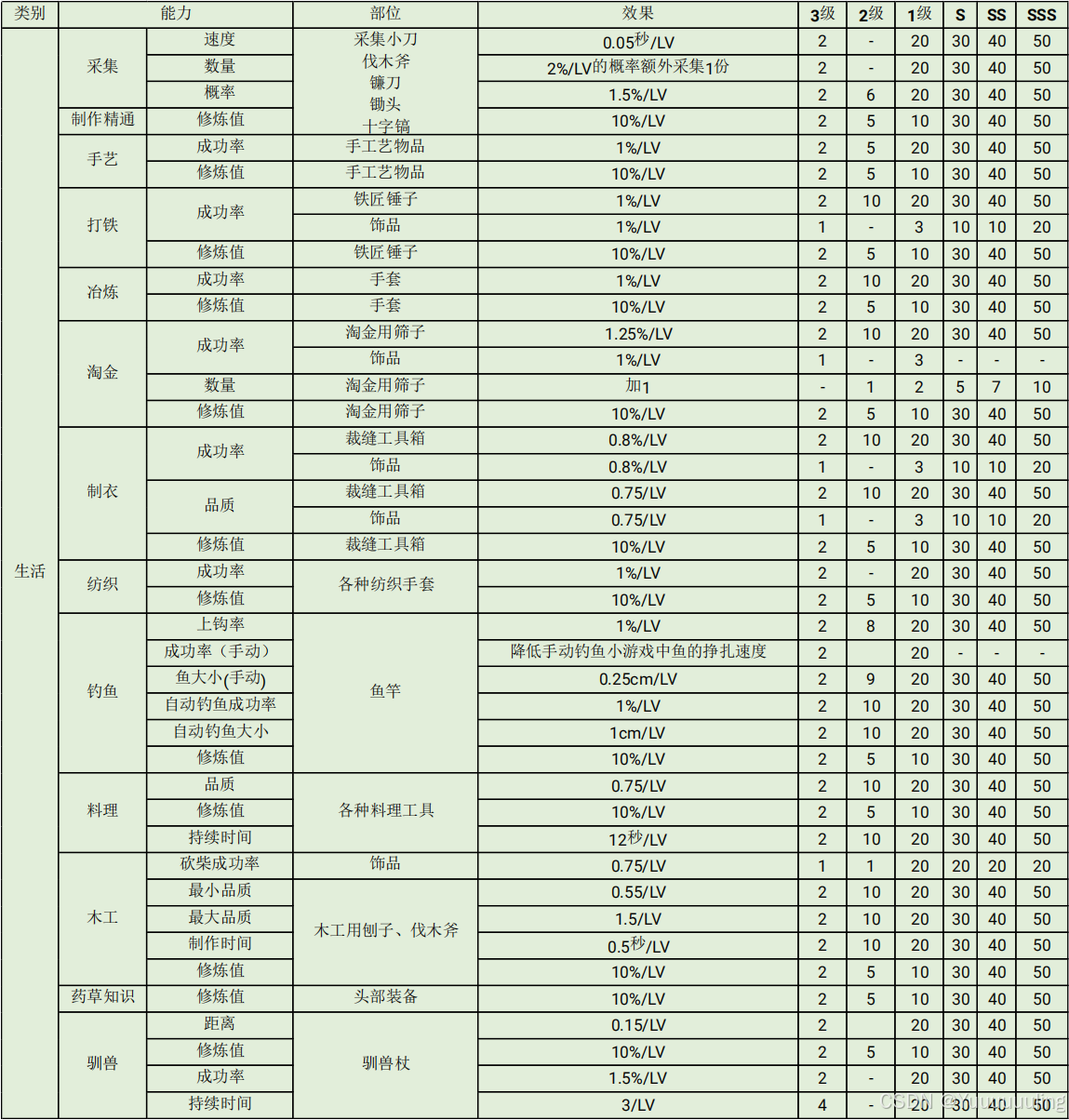 |
|
|
|
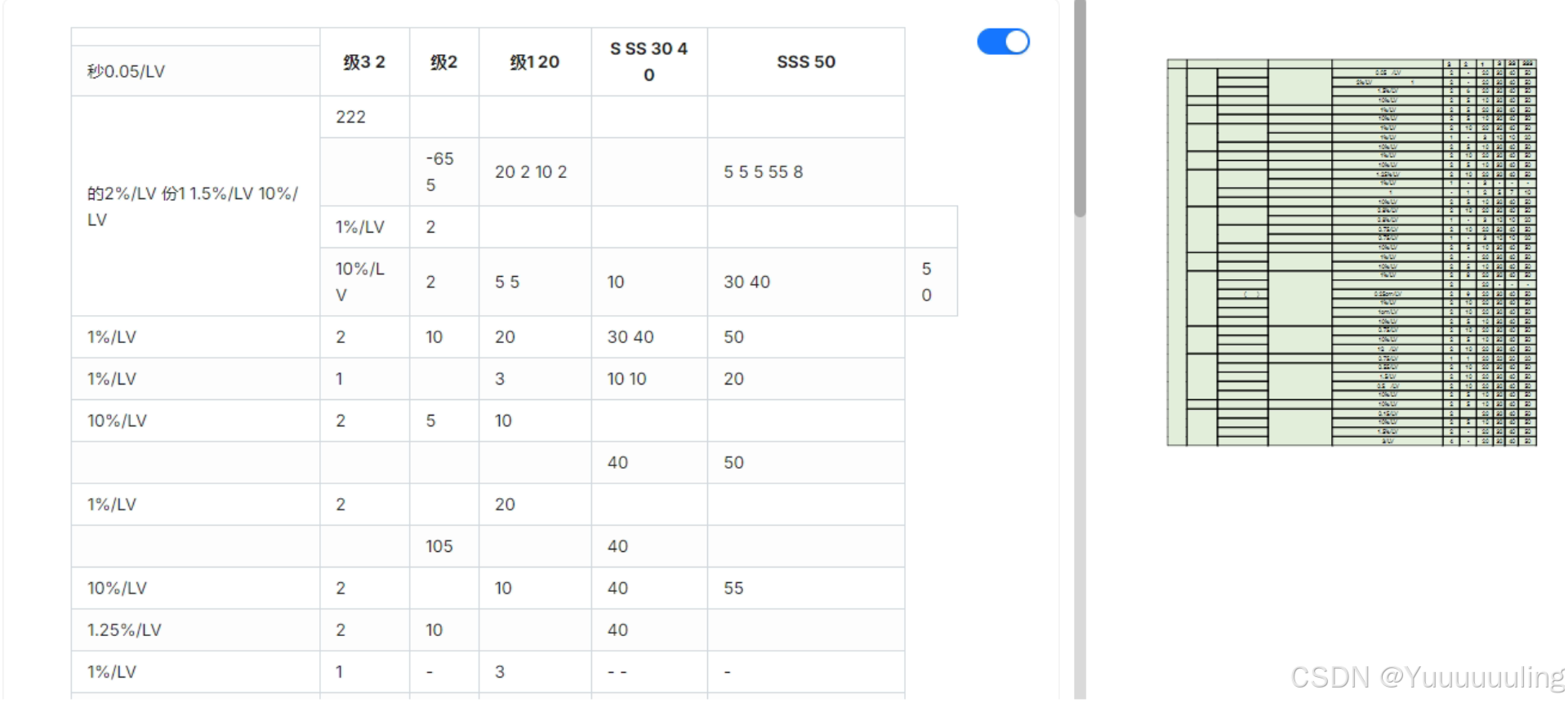 |
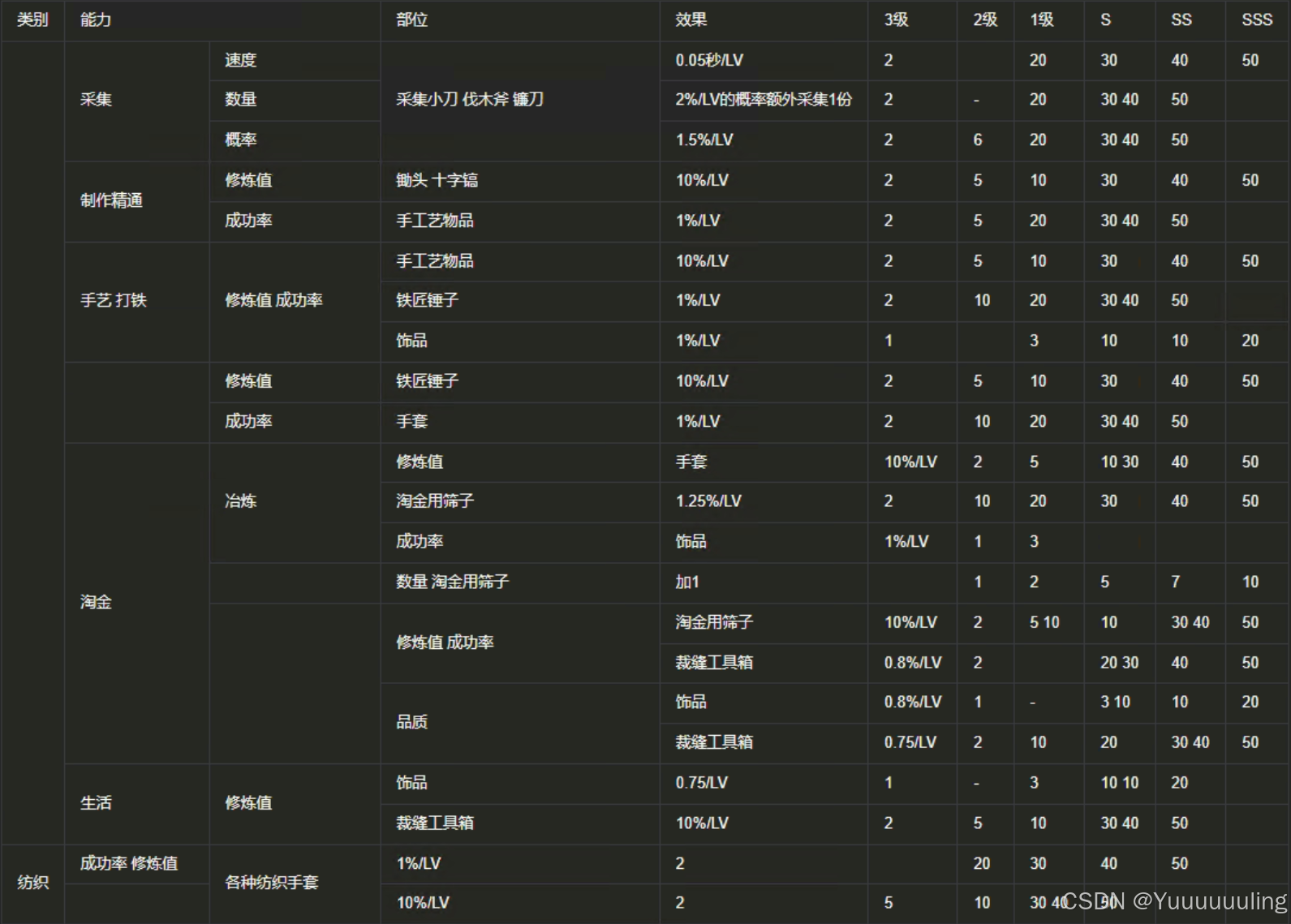
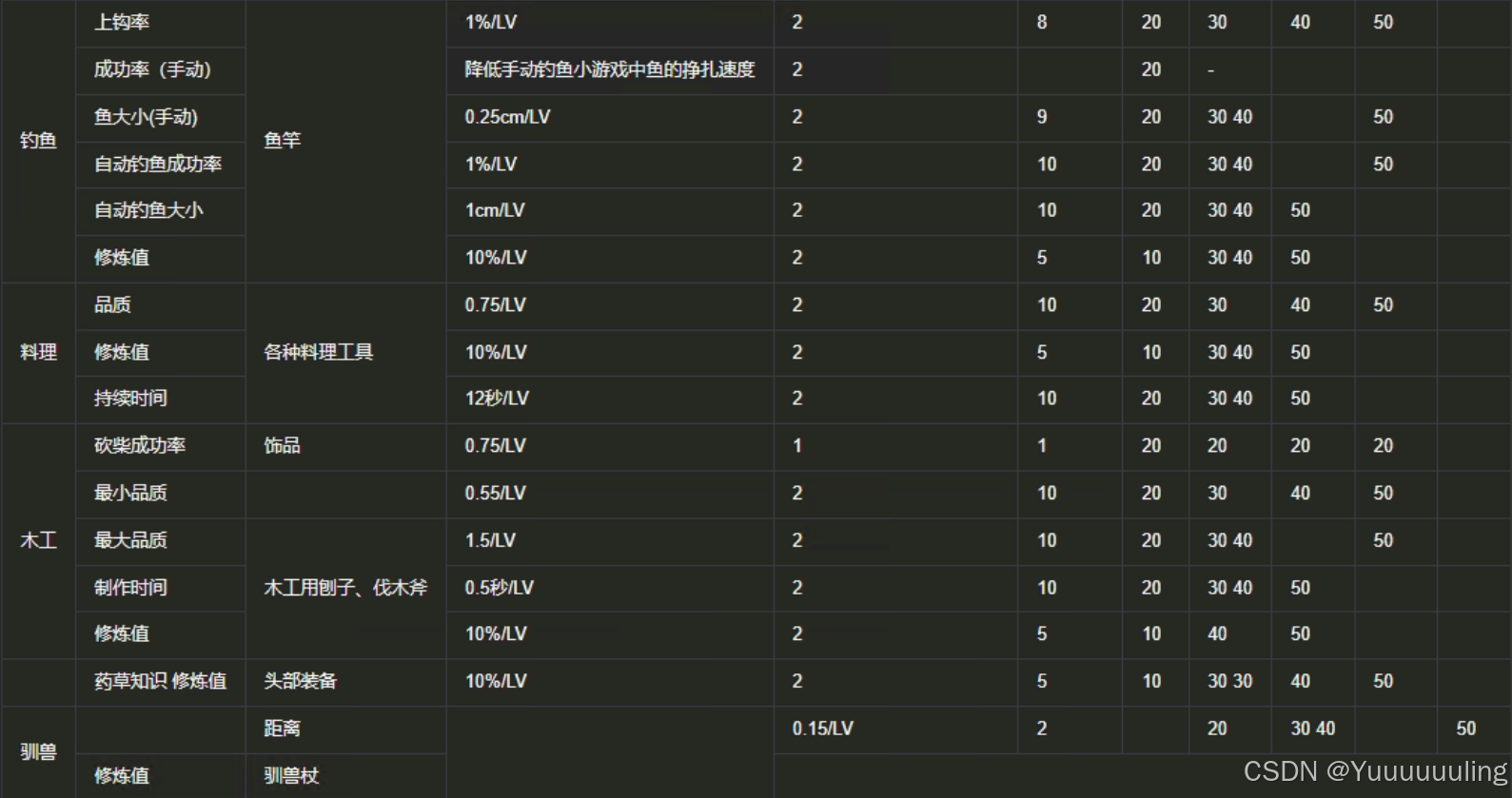
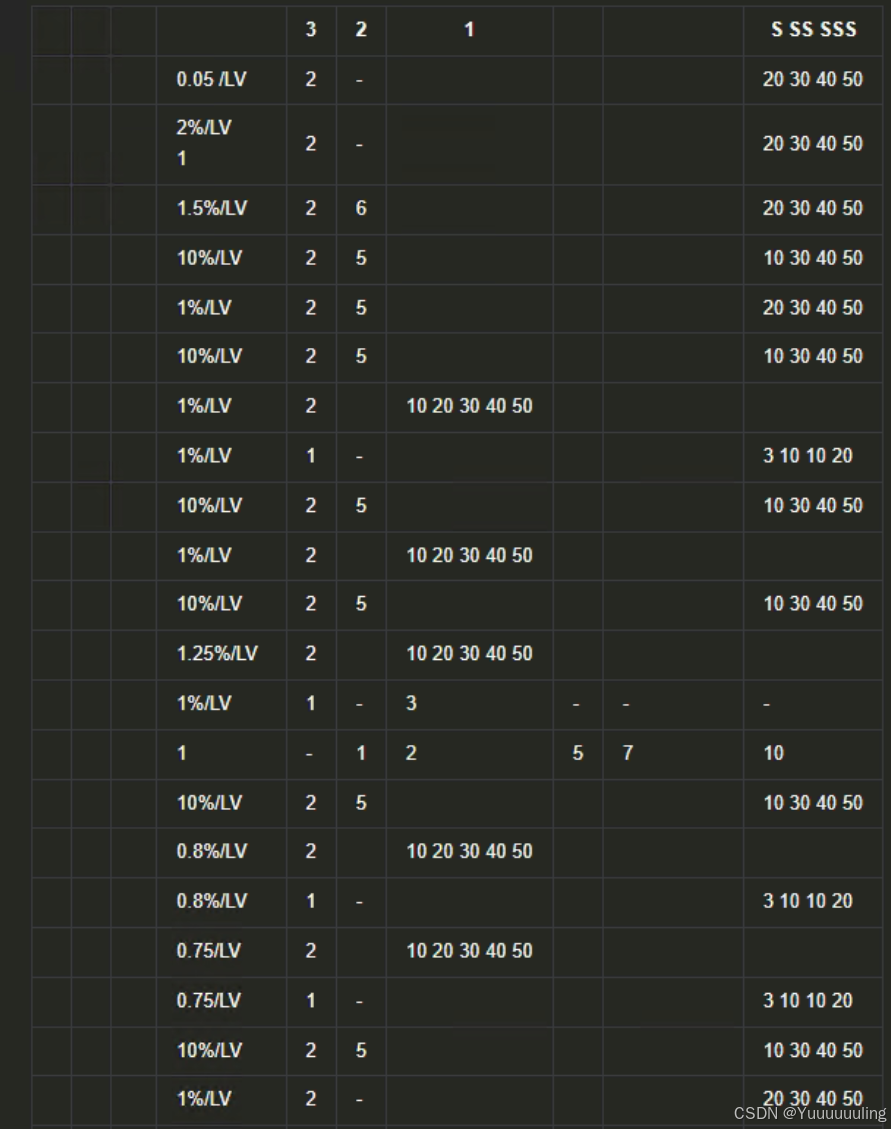
具体谁的效果最好,我在这里不做评价,各位看官自己评价,我这就简单总结一下我个人认为的每个工具的特点:
总结 (这里的顺序不代表排名) :
| 工具 | 官方介绍 | 个人评价 | 适用场景 |
|---|---|---|---|
|
Marker |
|
1、速度快,可以结合llm模型(本次没测试); 2、准确提取文档中的各种数学、化学表达式; 3、流程图类似的版面,存为图片保存在markdown; 4、保留了部分版面的其他信息,例如标头、图片旁的提示语等。 |
轻量级pdf 文档转换 |
|
MinerU |
 |
1、速度中等; 2、精准提取文档中的各种数学、化学表达式; 3、流程图类似的版面,转存为图片保存在markdown; 4、自动去除了部分版面的其他信息,例如标头、图片旁的提示语等。 |
高精度pdf 文档转换 |
|
ragflow |
 |
RAG文档解析,企业知识库可视化操作的最佳工具 |
RAG知识库 私有化建设 |
|
olmocr |
|
未深度使用,不做评价 |
大规模pdf 文档转换 |
|
maritdown |
 |
如果是纯文本、office类文件、HTML等结构化文件,需要快速提取文本并转换为markdown形式的文件,选它,可以将图片和链接转为markdown格式,并且在上下文中保留原来的位置(需稍稍该一点点代码,原代码中是直接把图片过滤掉了) |
文本类pdf 快速提取 |



欢迎加入DeepSeek 技术社区。在这里,你可以找到志同道合的朋友,共同探索AI技术的奥秘。
更多推荐



 31
31 0
0- 0



 已为社区贡献1条内容
已为社区贡献1条内容

所有评论(0)