从零预训练一个自己的大模型(完整代码)
本文从零开始训练一个大模型
参考:
实验记录:https://swanlab.cn/@ShaohonChen/WikiLLM/overview
安装miniconda (可选)
1)在家目录下建立software文件夹,并进入
cd ~
mkdir software
cd ./software
(2)复制安装包下载链接,在Linux中安装。
Miniconda镜像(清华源):miniconda清华源
wget https://mirrors.tuna.tsinghua.edu.cn/anaconda/miniconda/Miniconda3-py310_24.9.2-0-Linux-x86_64.sh
(3)依然在./software下运行安装脚本
bash Miniconda3-py310_24.9.2-0-Linux-x86_64.sh
(4)安装位置选择默认,按回车即可
Miniconda3 will now be installed into this location:
/home/yxy/miniconda3
- Press ENTER to confirm the location
- Press CTRL-C to abort the installation
- Or specify a different location below
[/home/xinyi/miniconda3] >>>
PREFIX=/home/yxy/miniconda3
(5)下载完成,重启终端。
(6)运行代码,将miniconda添加至环境变量
echo 'export PATH="~/miniconda3/bin:$PATH"' >> ~/.bashrc
(2)运行代码,激活conda
source ~/.bashrc
(3)输入bash重启终端
bash
(4)初始化conda
conda init
链接GPU服务器
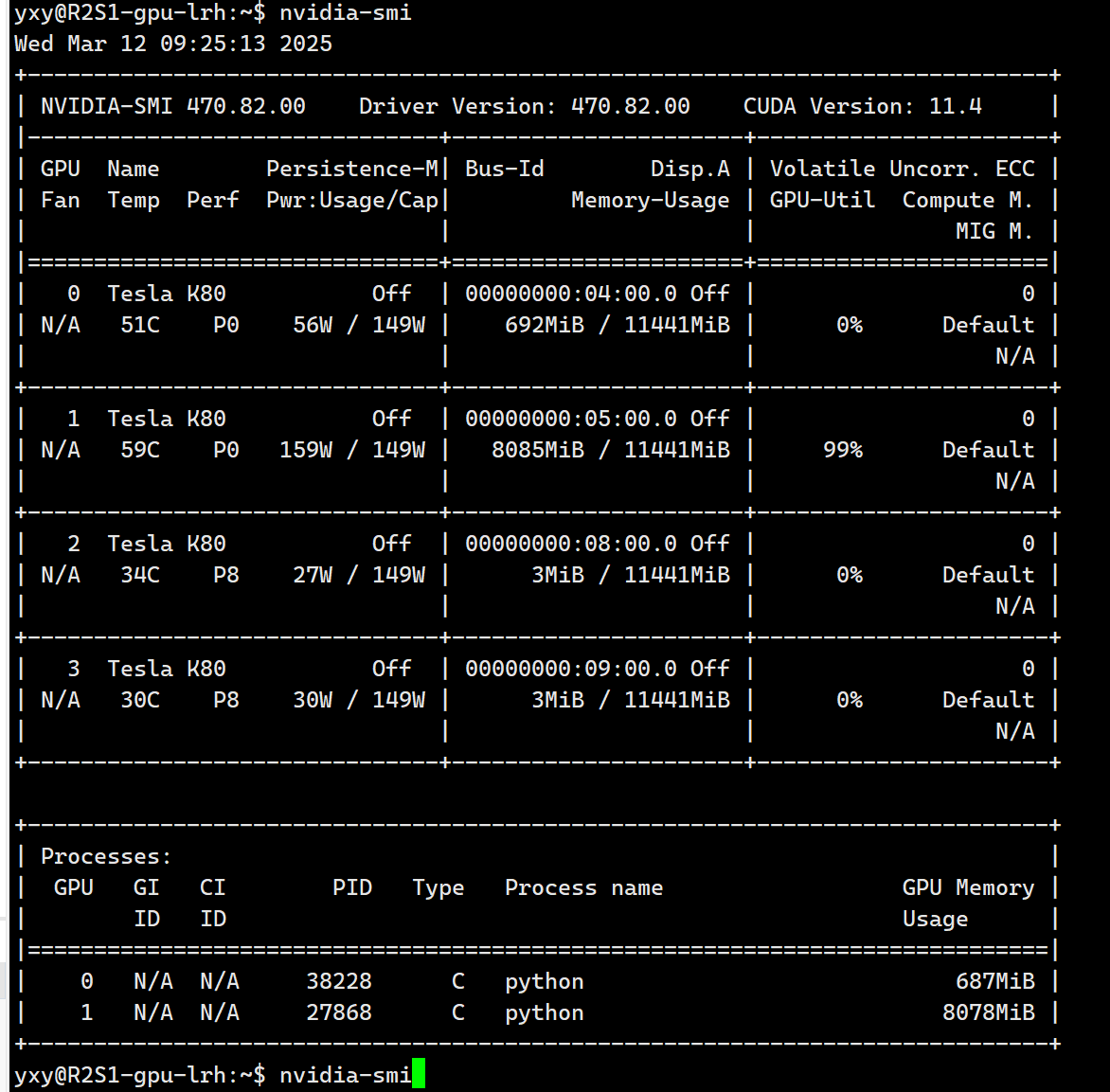
1.访问到GPU服务器
2.访问ip:192.168.9.4:22
3.查看GPU情况
nvidia-smi
丹摩链接
https://www.damodel.com/
打开丹摩 有新手20元代金券,可以选择如下镜像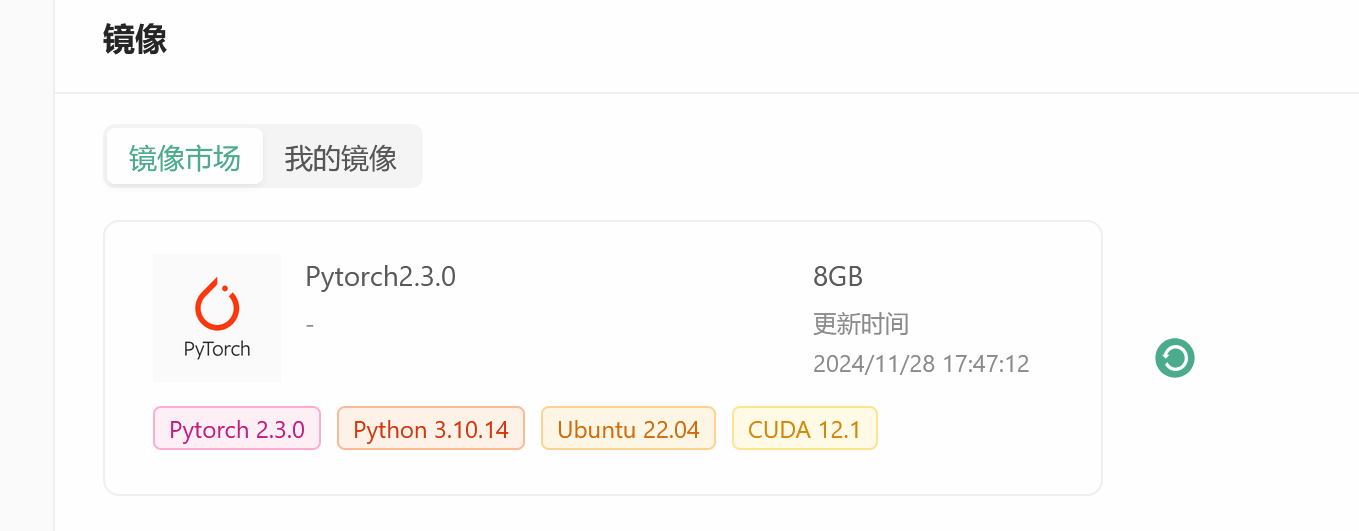
安装依赖
首先,项目推荐使用python3.10。需要安装的python包如下:
datasets==3.3.2
transformers==4.49.0
modelscope==1.23.2
swanlab==0.4.12
accelerate==1.4.0
使用如下命令一键安装:
pip install swanlab==0.4.12 transformers==4.49.0 datasets==3.3.2 accelerate==1.4.0 modelscope==1.23.2 -i https://pypi.tuna.tsinghua.edu.cn/simple
什么是SwanLab
SwanLab(https://swanlab.cn)是一个用于AI模型训练过程可视化的工具。SwanLab的主要功能包括:
跟踪模型指标,如损失和准确性等
同时支持云端和离线使用,支持远程查看训练过程,比如可以在手机上看远程服务器上跑的训练
记录训练超参数,如batch_size和learning_rate等
自动记录训练过程中的日志、硬件环境、Python库以及GPU(支持英伟达显卡)、NPU(支持华为昇腾卡)、内存的硬件信息
支持团队多人协作,很适合打Kaggle等比赛的队伍
SwanLab库来自一个中国团队(情感机器),最早的出发点是其开发团队的内部训练需求,后来逐渐开源并且发展成面向公众的产品。SwanLab库在2024年向公众发布。SwanLab刚出现时只有离线版本(对标Tensorboard),后来经过迭代和努力已经有了云端版和各项功能,并且集成了接近30+个深度学习框架,包括PyTorch、HuggingFace Transformers、Keras、XGBoost等等,其中还包括同样是中国团队开发的LLaMA Factory、Modelscope Swift、PaddleYOLO等框架,具有了很全面的功能。
安装SwanLab
pip install swanlab
登录SwanLab账号(详细)
要使用云端版之前需要先注册一下账号:
在电脑或手机浏览器访问SwanLab官网 https://swanlab.cn
点击右上角的黑色按钮「注册/登录」
填写手机号后,点击「发送短信验证码」按钮
填写你的信息
复制API Key
完成填写后点击「完成」按钮,会进入到下面的页面。在API Key这个地方,点击复制按钮,复制你的API Key:
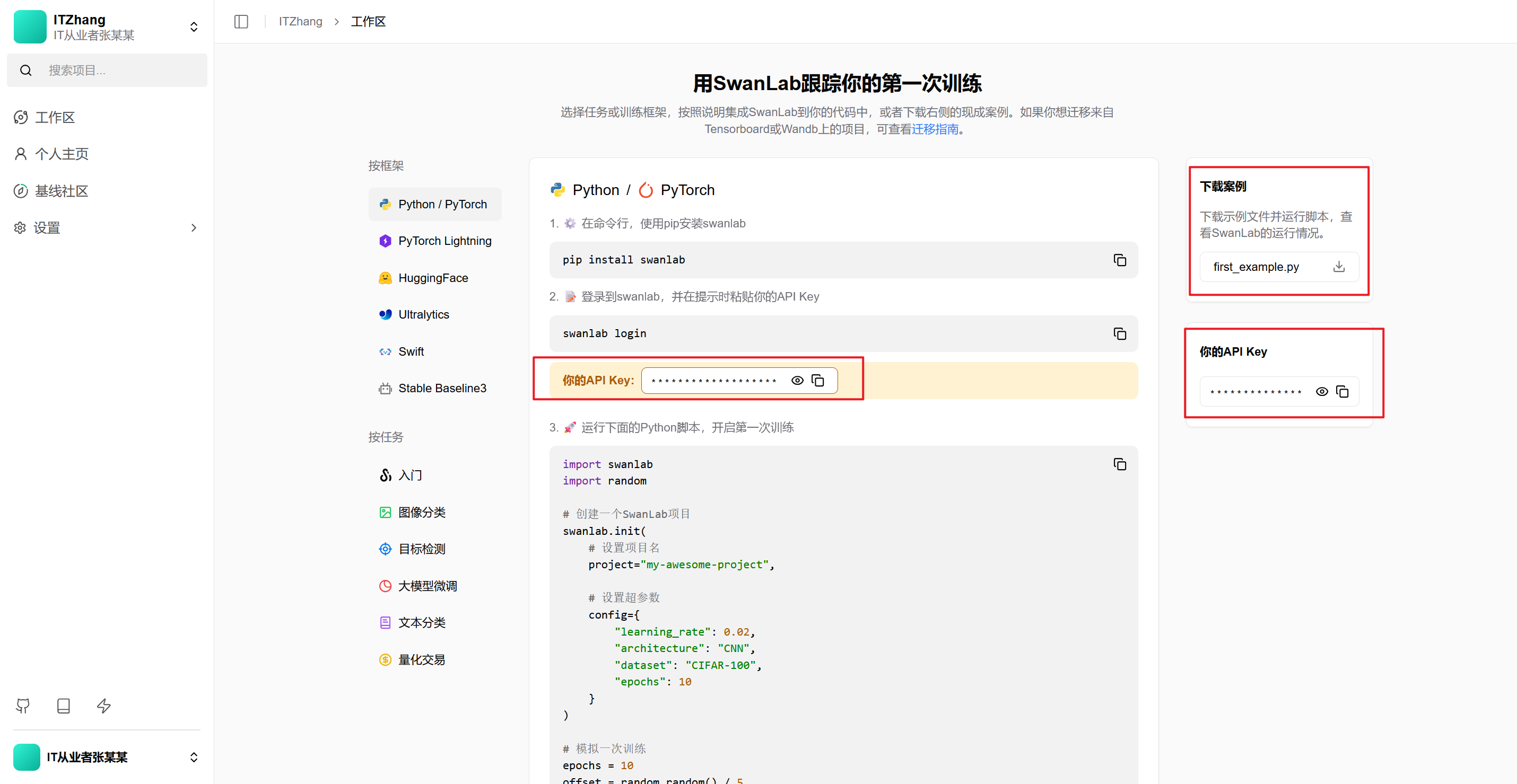
登录(方式一)
打开命令行,输入下面的命令:
swanlab login
登录(方式二)
创建一个Python脚本,输入下面的代码:
import swanlab
swanlab.login(api_key="把API Key粘贴到这里")
把API Key粘贴到对应的位置,然后运行一下这个脚本,完成登录。
登录(方式三)
运行下面代码,然后遇到提升时,手动粘贴api_key: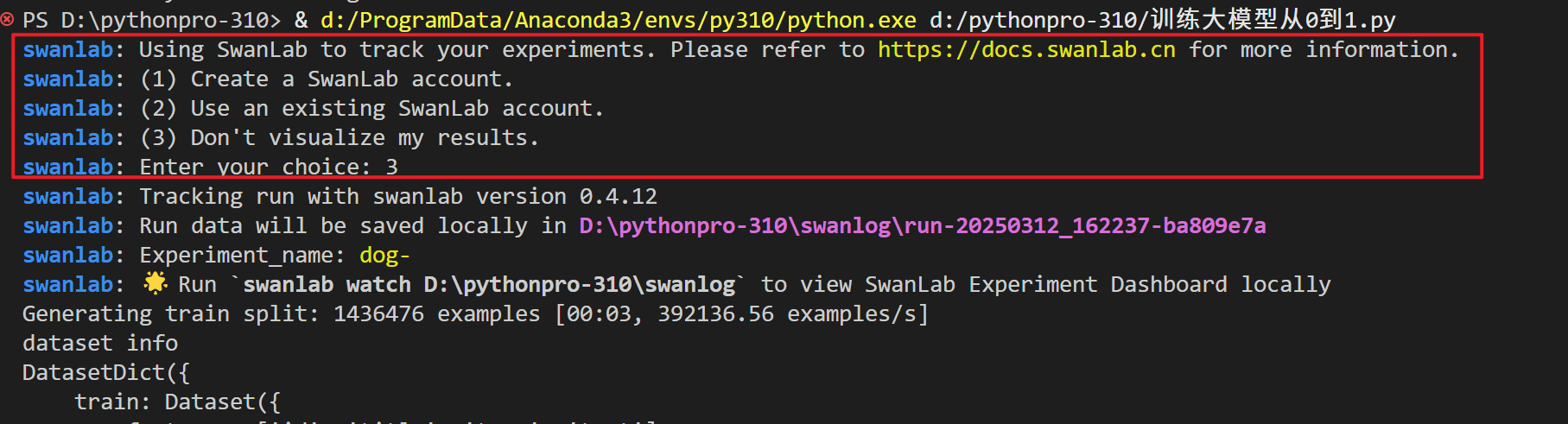
下载数据集
本教程使用的是中文wiki数据,理论上预训练数据集种类越丰富、数据量越大越好,后续会增加别的数据集。
百度网盘数据集下载
数据示例如下:
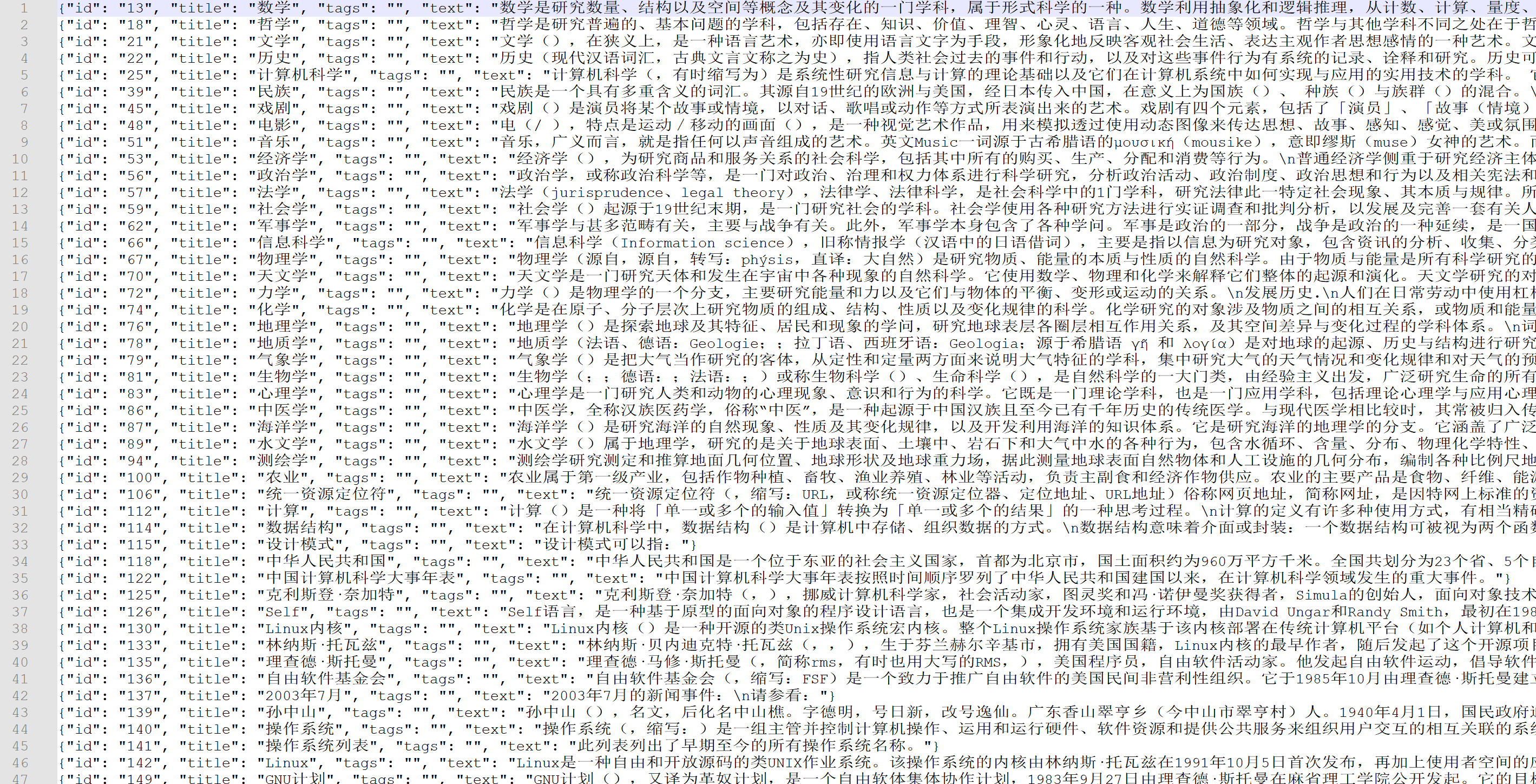

下载wikipedia-zh-cn-20240820.json文件后放到项目目录下./data/WIKI_CN/文件夹中
该数据集文件约1.99G大,共有1.44M条数据。虽然数据集中包含文章标题,但是实际上在预训练阶段用不上。正文片段参考:
数学是研究数量、结构以及空间等概念及其变化的一门学科,属于形式科学的一种。数学利用抽象化和逻辑推理,从计数、计算、量度、对物体形状及运动的观察发展而成。数学家们拓展这些概念…
使用 Huggingface Datasets加载数据集的代码如下:
from datasets import load_dataset
ds = load_dataset("fjcanyue/wikipedia-zh-cn")
如果使用百度网盘下载的json文件,可以通过如下代码加载
raw_datasets = datasets.load_dataset(
"json", data_files="data/wikipedia-zh-cn-20240820.json"
)
raw_datasets = raw_datasets["train"].train_test_split(test_size=0.1, seed=2333)
print("dataset info")
print(raw_datasets)
构建自己的大语言模型
本教程使用 huggingface transformers构建自己的大模型。
因为目标是训练一个中文大模型。因此我们参考通义千问2的tokenize和模型架构,仅仅做一些简单的更改让模型更小更好训练。
因为国内无法直接访问到huggingface,推荐使用modelscope先把模型配置文件和checkpoint下载到本地,运行如下代码
import modelscope
modelscope.AutoConfig.from_pretrained("Qwen/Qwen2-0.5B").save_pretrained(
"Qwen2-0.5B"
)
modelscope.AutoTokenizer.from_pretrained("Qwen/Qwen2-0.5B").save_pretrained(
"Qwen2-0.5B"
)
配置参数,并修改模型注意力头数量、模型层数和中间层大小,把模型控制到大概120M参数左右(跟GPT2接近)。
import transformers
tokenizer = transformers.AutoTokenizer.from_pretrained("./Qwen2-0.5B") # 这里使用qwen2的tokenzier
config = transformers.AutoConfig.from_pretrained(
"./Qwen2-0.5B",
vocab_size=len(tokenizer),
hidden_size=512,
intermediate_size=2048,
num_attention_heads=8,
num_hidden_layers=12,
n_ctx=context_length,
bos_token_id=tokenizer.bos_token_id,
eos_token_id=tokenizer.eos_token_id,
)
print("Model Config:")
print(config)
使用transformers库初始化模型
model = transformers.Qwen2ForCausalLM(config)
model_size = sum(t.numel() for t in model.parameters())
print(f"Model Size: {model_size/1000**2:.1f}M parameters")
设置训练参数
设置预训练超参数:
args = transformers.TrainingArguments(
output_dir="checkpoints",
per_device_train_batch_size=24, # 每个GPU的训练batch数
per_device_eval_batch_size=24, # 每个GPU的测试batch数
eval_strategy="steps",
eval_steps=5_000,
logging_steps=500,
gradient_accumulation_steps=12, # 梯度累计总数
num_train_epochs=2, # 训练epoch数
weight_decay=0.1,
warmup_steps=1_000,
optim="adamw_torch", # 优化器使用adamw
lr_scheduler_type="cosine", # 学习率衰减策略
learning_rate=5e-4, # 基础学习率,
save_steps=5_000,
save_total_limit=10,
bf16=True, # 开启bf16训练, 对于Amper架构以下的显卡建议替换为fp16=True
)
print("Train Args:")
print(args)
初始化训练+使用swanlab进行记录
使用transformers自带的train开始训练,并且引入swanlab作为可视化日志记录
from swanlab.integration.huggingface import SwanLabCallback
trainer = transformers.Trainer(
model=model,
tokenizer=tokenizer,
args=args,
data_collator=data_collator,
train_dataset=tokenized_datasets["train"],
eval_dataset=tokenized_datasets["test"],
callbacks=[SwanLabCallback()],
)
trainer.train()
如果是第一次使用SwanLab,需要登陆SwanLab官网https://swanlab.cn/,注册,并且在如下位置找到和复制自己的key。
完整代码
项目目录结构:
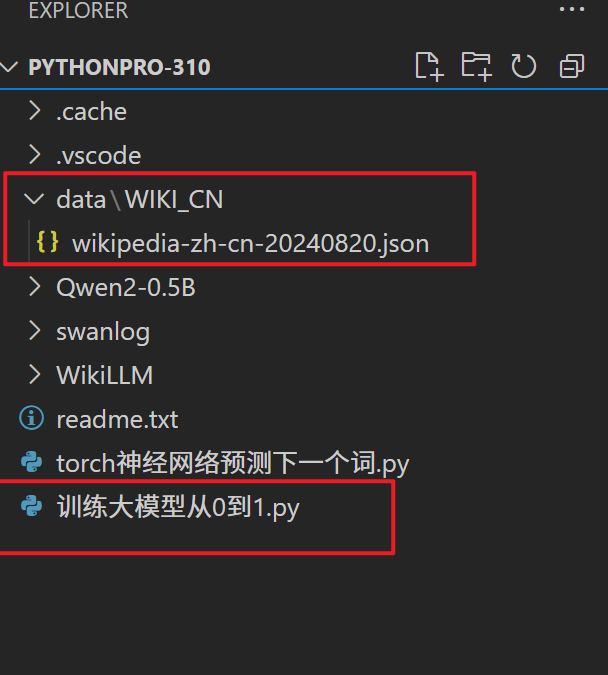
import datasets # 作用是加载数据集
from datasets import load_dataset
import transformers # 作用是加载模型
import swanlab # 作用是将训练过程中的日志上传到魔搭平台
from swanlab.integration.huggingface import SwanLabCallback #
import modelscope # 作用是加载模型
"""
datasets==3.3.2
transformers==4.49.2
modelscope==1.23.2
swanlab==0.4.12
accelerate==1.4.0
"""
"""
链接:https://pan.baidu.com/s/1jlZoCyD3yjdj8SI2wf4-BA?pwd=u8dp 提取码:u8dp 复制这段内容后打开百度网盘手机App,操作更方便哦
"""
def main():
# using swanlab to save log
# 初始化swanlab,传入项目名称
swanlab.init("WikiLLM")
# load dataset·
#raw_datasets = load_dataset("fjcanyue/wikipedia-zh-cn")
# load dataset
raw_datasets = datasets.load_dataset(
"json", data_files="./data/WIKI_CN/wikipedia-zh-cn-20240820.json"
)
# split dataset
raw_datasets = raw_datasets["train"].train_test_split(test_size=0.1, seed=2333)
print("dataset info")
print(raw_datasets)
# load tokenizers
# 因为国内无法直接访问HuggingFace,因此使用魔搭将模型的配置文件和Tokenizer下载下来
# 配置文件包括模型的结构、参数等信息,Tokenizer用于将文本转换为模型可以处理的输入格式
modelscope.AutoConfig.from_pretrained("Qwen/Qwen2-0.5B").save_pretrained(
"Qwen2-0.5B"
)
modelscope.AutoTokenizer.from_pretrained("Qwen/Qwen2-0.5B").save_pretrained(
"Qwen2-0.5B"
)
context_length = 512 # use a small context length
# tokenizer = transformers.AutoTokenizer.from_pretrained("Qwen/Qwen2-0.5B")
tokenizer = transformers.AutoTokenizer.from_pretrained(
"./Qwen2-0.5B"
) # download from local
# preprocess dataset
def tokenize(element):
# 对数据集进行预处理,将文本转换为模型可以处理的输入格式
# 这里使用的是Qwen2-0.5B的Tokenizer,将文本转换为模型可以处理的输入格式
# truncation=True表示如果文本长度超过了context_length,就截断
# max_length=context_length表示文本的最大长度为context_length
# return_overflowing_tokens=True表示返回溢出的tokens
outputs = tokenizer(
element["text"],
truncation=True,
max_length=context_length,
return_overflowing_tokens=True,
return_length=True,
)
input_batch = []
# 作用是将溢出的tokens转换为模型可以处理的输入格式
# 这里使用的是Qwen2-0.5B的Tokenizer,将文本转换为模型可以处理的输入格式
# 这里的input_ids是一个二维数组,每一行表示一个文本的输入格式
# 这里的length是一个一维数组,每一个元素表示一个文本的长度
# 这里的input_batch是一个二维数组,每一行表示一个文本的输入格式
# 这里的context_length是一个整数,表示文本的最大长度
for length, input_ids in zip(outputs["length"], outputs["input_ids"]):
if length == context_length:
input_batch.append(input_ids)
return {"input_ids": input_batch}
# map函数的作用是将tokenize函数应用到数据集的每一个元素上
# batched=True表示将数据集分成batch进行处理
# remove_columns=raw_datasets["train"].column_names表示删除原始数据集的列名
tokenized_datasets = raw_datasets.map(
tokenize, batched=True, remove_columns=raw_datasets["train"].column_names
)
print("tokenize dataset info")
#
print(tokenized_datasets)
# eos_token的作用是表示文本的结束
# pad_token的作用是表示填充的token
tokenizer.pad_token = tokenizer.eos_token
# DataCollatorForLanguageModeling的作用是将数据集转换为模型可以处理的输入格式
# 这里使用的是Qwen2-0.5B的Tokenizer,将文本转换为模型可以处理的输入格式
# mlm=False表示不进行masked language modeling
data_collator = transformers.DataCollatorForLanguageModeling(tokenizer, mlm=False)
# prepare a model from scratch
config = transformers.AutoConfig.from_pretrained(
"./Qwen2-0.5B",
vocab_size=len(tokenizer), # tokenizer的长度
hidden_size=512, # 模型的隐藏层大小
intermediate_size=2048,# 模型的中间层大小
num_attention_heads=8,# 模型的注意力头数
num_hidden_layers=12, # 模型的隐藏层数
n_ctx=context_length, # 模型的上下文长度
bos_token_id=tokenizer.bos_token_id,
eos_token_id=tokenizer.eos_token_id,
)
# 初始化模型
model = transformers.Qwen2ForCausalLM(config)
model_size = sum(t.numel() for t in model.parameters())
print("Model Config:")
print(config)
print(f"Model Size: {model_size/1000**2:.1f}M parameters")
# train TrainingArguments
args = transformers.TrainingArguments(
output_dir="WikiLLM",
per_device_train_batch_size=32, # 每个GPU的训练batch数
per_device_eval_batch_size=32, # 每个GPU的测试batch数
eval_strategy="steps", # 测试策略,这里是每500步测试一次
eval_steps=5_00,
logging_steps=50,
gradient_accumulation_steps=8, # 梯度累计总数
num_train_epochs=2, # 训练epoch数
weight_decay=0.1, # 权重衰减系数
warmup_steps=2_00, # 预热步数
optim="adamw_torch", # 优化器使用adamw
lr_scheduler_type="cosine", # 学习率衰减策略
learning_rate=5e-4, # 基础学习率,
save_steps=5_00, # 保存模型的步数
save_total_limit=10, # 保存的模型数
bf16=True, # 开启bf16训练, 对于Amper架构以下的显卡建议替换为fp16=True
)
print("Train Args:")
print(args)
# enjoy training
trainer = transformers.Trainer(
model=model,
tokenizer=tokenizer,
args=args,
data_collator=data_collator,
train_dataset=tokenized_datasets["train"],
eval_dataset=tokenized_datasets["test"],
callbacks=[SwanLabCallback()], # 上传训练日志到魔搭平台
)
trainer.train() # 开始训练
# save model
model.save_pretrained("./WikiLLM/Weight") # 保存模型的路径
# generate
pipe = transformers.pipeline("text-generation", model=model, tokenizer=tokenizer)
print("GENERATE:", pipe("人工智能", num_return_sequences=1)[0]["generated_text"])
prompts = ["牛顿", "北京市", "亚洲历史"]
examples = []
for i in range(3):
# 根据提示词生成数据
text = pipe(prompts[i], num_return_sequences=1)[0]["generated_text"]
text = swanlab.Text(text)
examples.append(text)
swanlab.log({"Generate": examples})
if __name__ == "__main__":
main()

欢迎加入DeepSeek 技术社区。在这里,你可以找到志同道合的朋友,共同探索AI技术的奥秘。
更多推荐



 12
12 0
0- 0



 已为社区贡献7条内容
已为社区贡献7条内容

所有评论(0)