AI 大模型的基本原理详细介绍
随着人工智能技术的飞速发展,大模型已成为当前的研究热点和应用前沿。从自然语言处理到计算机视觉,从智能推荐到自动驾驶,大模型展现出了强大的性能和广泛的应用潜力。本文将深入探讨 AI 大模型的基本原理,包括其架构、训练过程、优化技巧以及应用场景等方面。
文章目录
AI 大模型的基本原理详细介绍
一、引言
随着人工智能技术的飞速发展,大模型已成为当前的研究热点和应用前沿。从自然语言处理到计算机视觉,从智能推荐到自动驾驶,大模型展现出了强大的性能和广泛的应用潜力。本文将深入探讨 AI 大模型的基本原理,包括其架构、训练过程、优化技巧以及应用场景等方面。
二、AI 大模型的架构
(一)神经网络基础
AI 大模型通常基于深度神经网络架构,其基本单元是神经元。神经元通过接收输入信号、进行加权求和并经过激活函数处理,产生输出信号。多个神经元按层次连接构成神经网络,包括输入层、隐藏层和输出层。输入层接收原始数据,隐藏层逐层提取特征并进行非线性变换,输出层给出最终结果。
首先我们来看一张图,左边的是生物上的神经网络,右边的是数学版的神经网络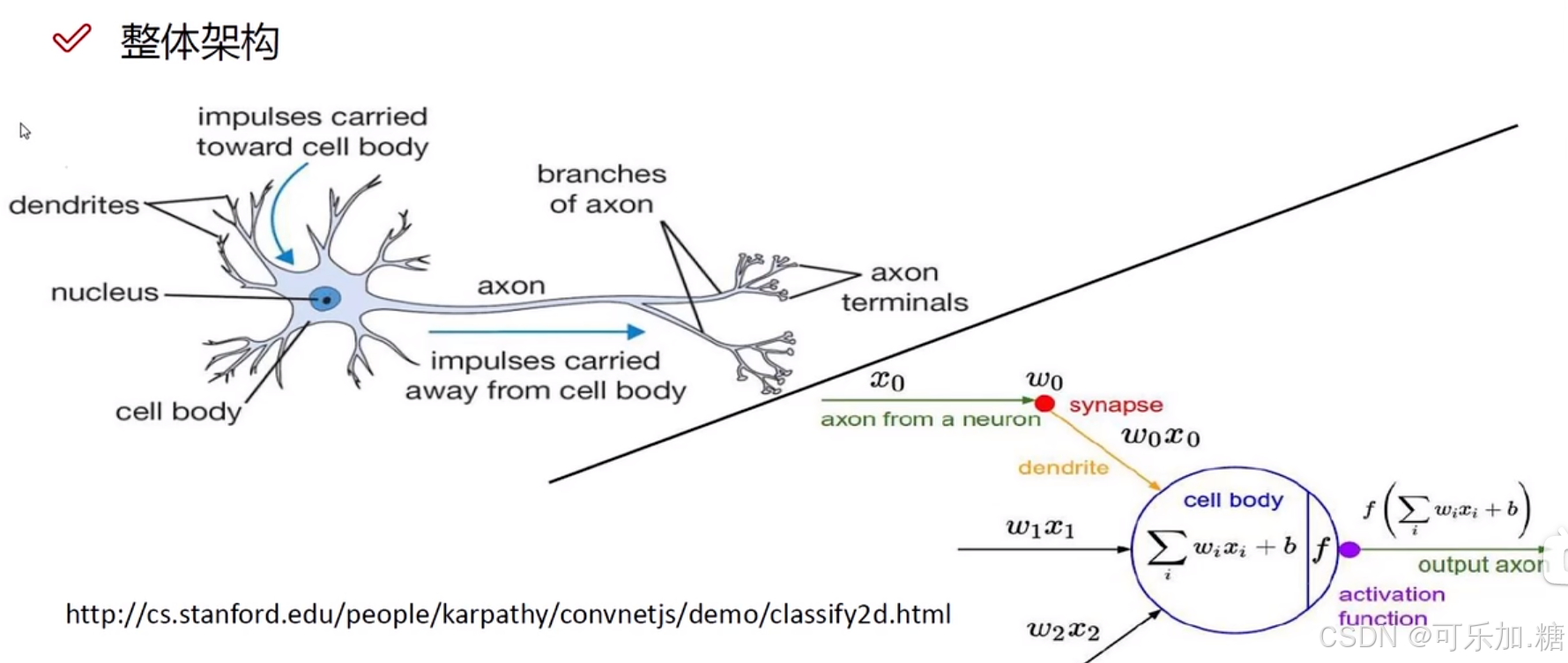
在深度学习中神经网络的基本架构: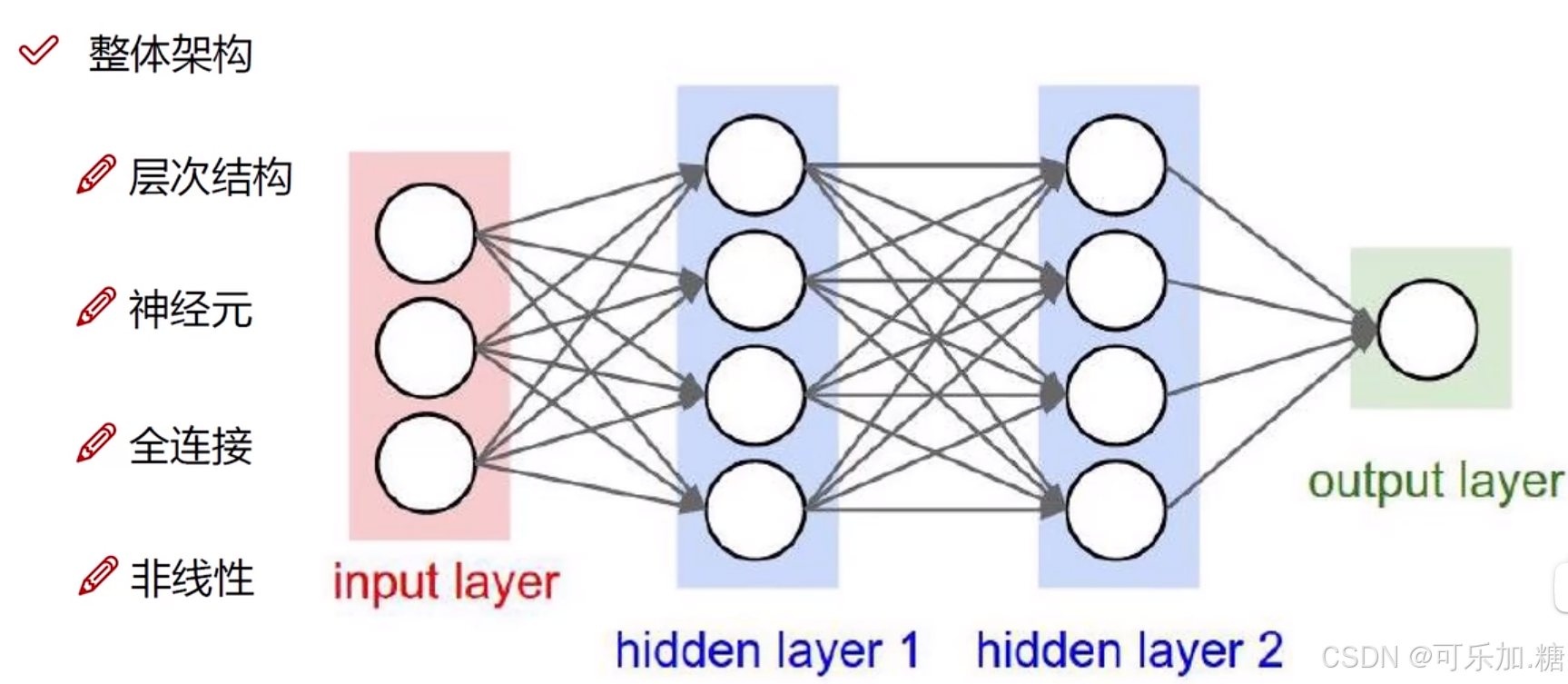
整体架构包括层次结构,神经元,全连接,非线性四个部分
(二)Transformer 架构
- Transformer架构
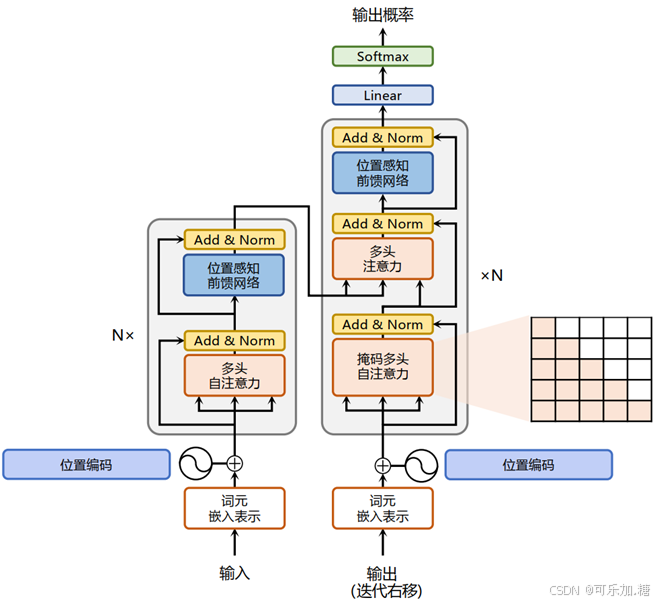
Transformer模型介绍
Transformer 是当前许多大模型的核心架构之一,尤其在自然语言处理领域表现出色。它主要由编码器(Encoder)和解码器(Decoder)组成。编码器通过多头自注意力机制(Multi - Head Attention)对输入序列中的每个词进行编码,捕捉词与词之间的依赖关系;解码器则结合编码器的输出和自身的自注意力机制、前馈神经网络,逐步生成输出序列。Transformer 的优势在于能够并行处理序列中的所有位置,大大提高了训练效率,并且能够有效处理长距离依赖关系。
- Transformer模型的提出
在Transformer提出之前,自然语言处理领域的主流模型是循环神经网络RNN,使用递归和卷积神经网络进行语言序列转换。
2017年,谷歌大脑团队在人工智能领域的顶会NeurIPS发表了一篇名为“Attention is all you need”的论文,首次提出了一种新的简单网络架构,即 Transformer,它完全基于注意力机制(attention),完全摒弃了循环递归和卷积。
递归模型通常沿输入和输出序列的符号位置进行计算,来预测后面的值。 但这种固有的顺序性质阻碍了训练样例内的并行化,因为内存约束限制了样例之间的批处理。
而注意力机制允许对依赖项进行建模,而无需考虑它们在输入或输出序列中的距离。
Transformer避开了递归网络的模型体系结构,并且完全依赖于注意力机制来绘制输入和输出之间的全局依存关系。
- Transformer模型
Transformer模型是对编码器和解码器使用堆叠式的自注意力和逐点式、全连接层,分别如图1的左半部分(编码器)和右半部分(解码器)所示。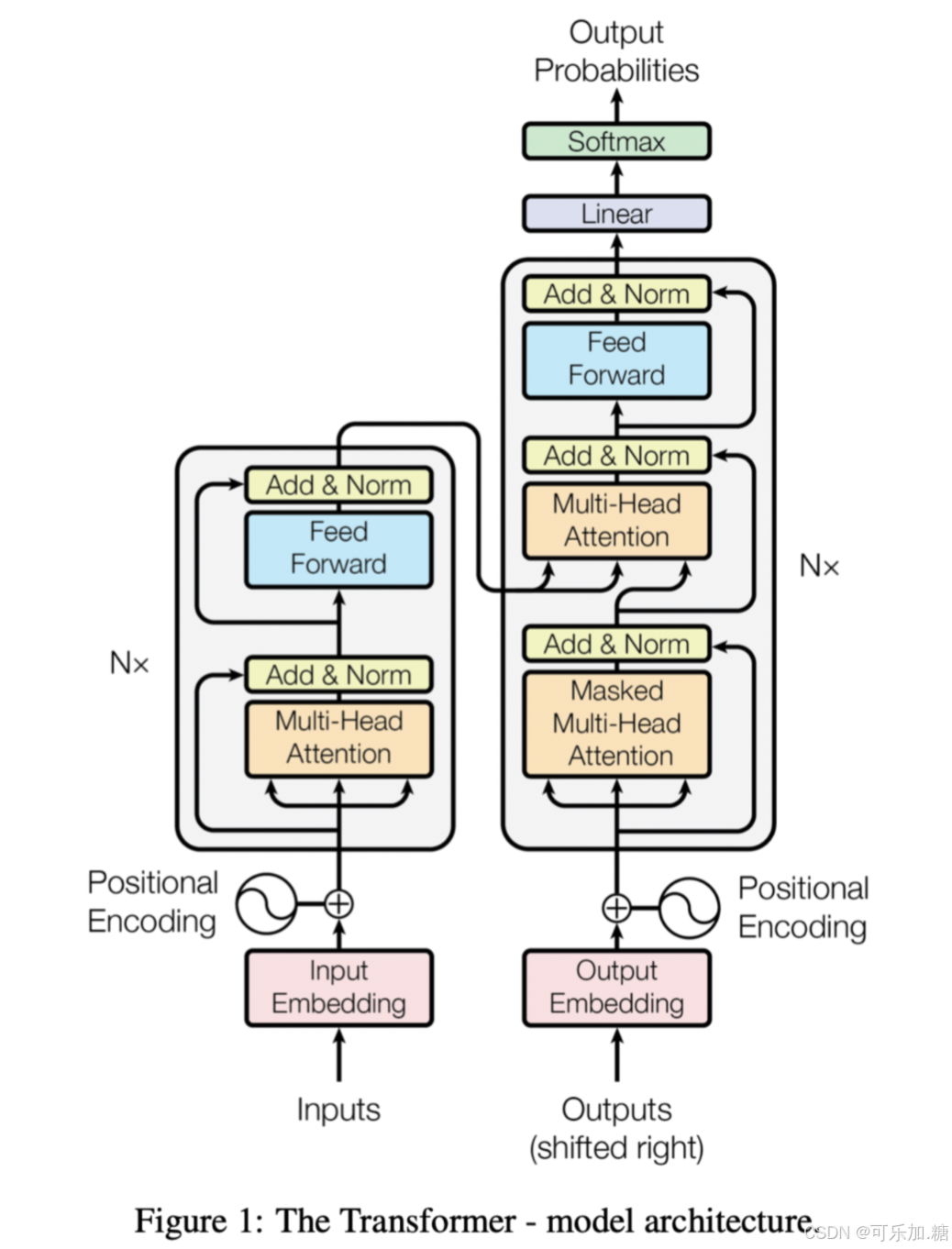
Transformer的基石注意力机制
Transformer的核心在于自注意力机制(Self-Attention),通过动态计算序列中不同位置的关联权重,实现全局语义建模。其数学表达为:
def scaled_dot_product_attention(Q, K, V):
scores = Q @ K.T / sqrt(d_k) # 缩放点积计算
weights = softmax(scores) # 归一化权重
return weights @ V # 加权聚合
该机制使模型能够捕捉长距离依赖关系,解决了传统RNN的梯度消失问题。
Transformer模型结构
编解码组件结构
Transformer 本质上是一个 Encoder-Decoder 架构,包括编码组件和解码组件。
编码组件和解码组件可以有很多层,比如Google刚提出时的论文用的是6层,后面GPT-1是12层,然后到GPT-3是96层。
在这里插入图片描述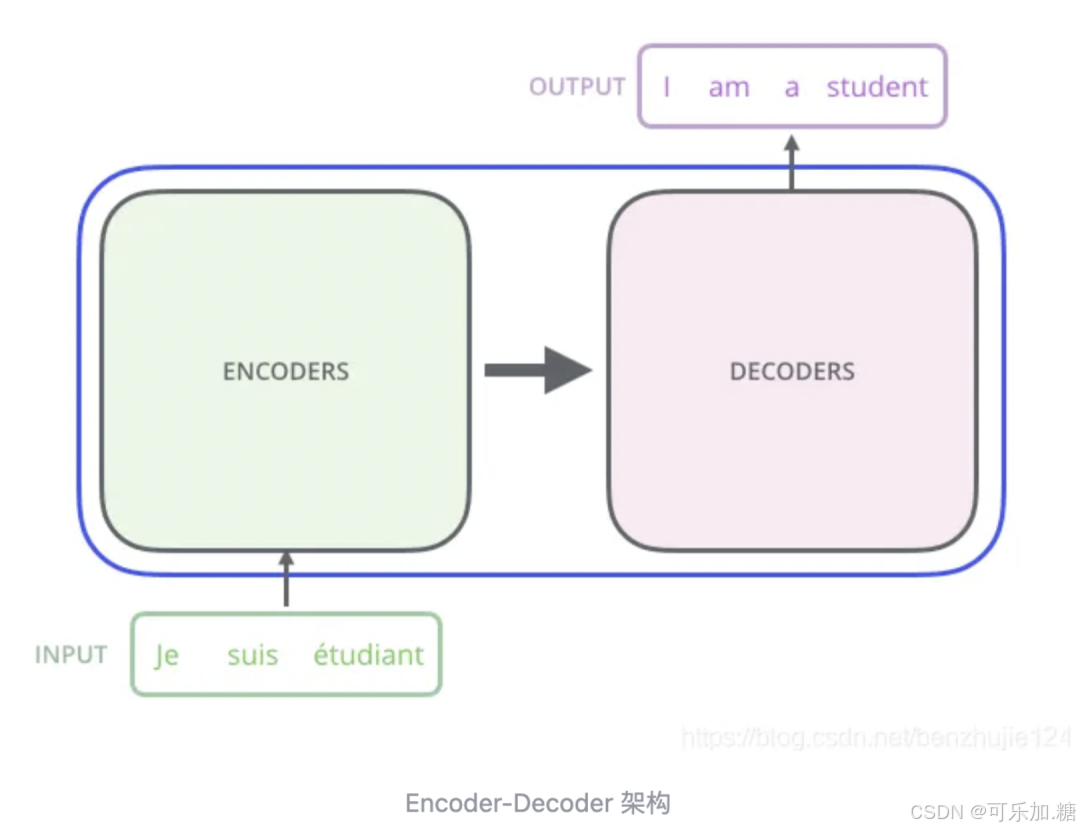
编码器对文本的处理
对文本处理和通常的 NLP 任务一样,首先使用词嵌入算法(Embedding)将每个词转换为一个词向量(vector)。
嵌入仅发生在最底层的编码器中,其他编码器接收的是上一个编码器的输出。
这个列表大小是我们可以设置的参数——基本上这个参数就是训练数据集中最长句子的长度。
对输入序列完成嵌入操作后,每个词都会流经编码器内的两层,然后逐个编码器向上传递。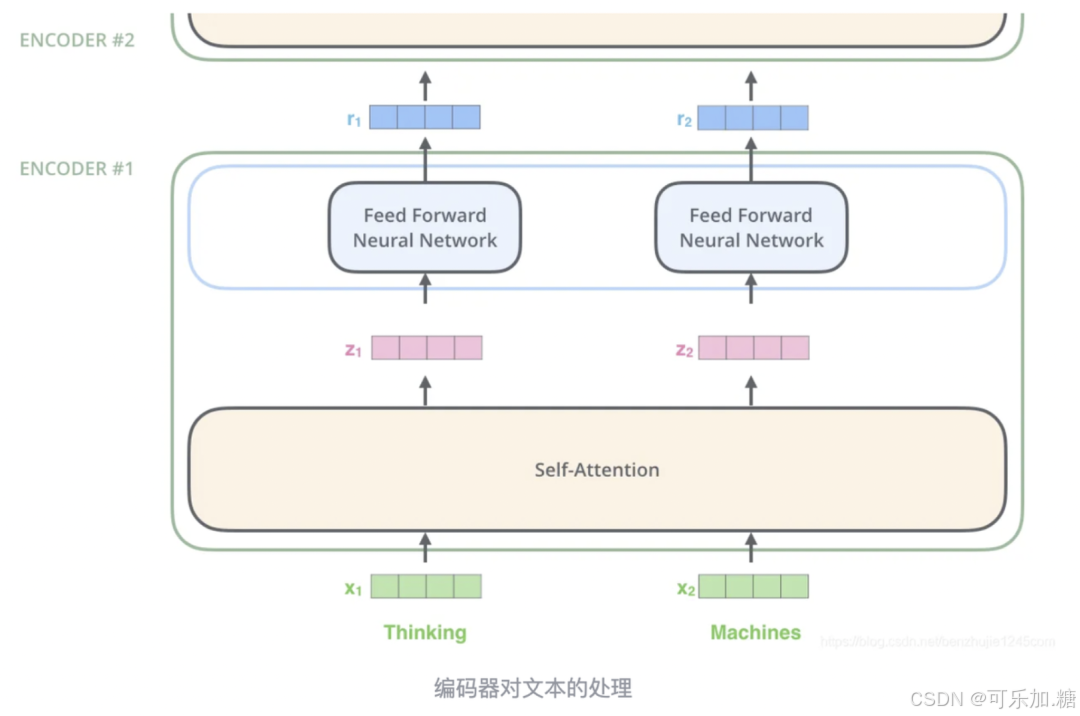
Self-Attention 原理
之前说Transformer的自注意机制突破了文本关注距离的限制,因此非常关键。先看这样一个句子:
_`The animal didn't cross the street because`_
_`it was too tired`_
这个句子中的"it"代表什么意思,是animal,还是street还是其他?这个对人来说很容易,但对模型来说不简单。
self-Attention就是用来解决这个问题,让it指向animal。通过加权之后可以得到类似图8的加权情况,The animal获得最大关注。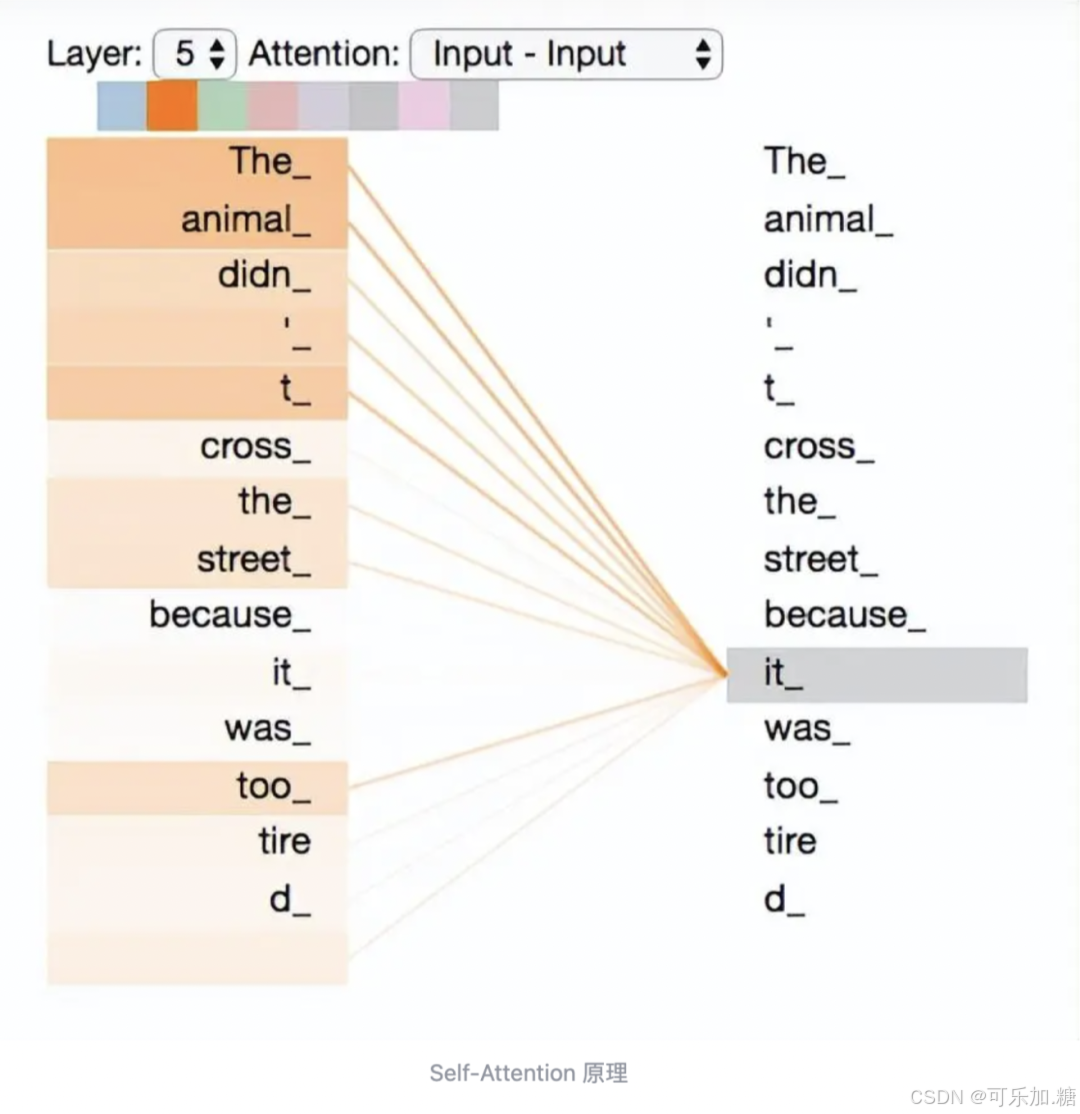
在self-attention中,每个单词有3个不同的向量,它们分别是Query向量( Q ),Key向量( K )和Value向量( V ),长度均是64。
它们是通过3个不同的权值矩阵由嵌入向量 X 乘以三个不同的权值矩阵 W^Q , W^K ,W^V 得到,其中三个矩阵的尺寸也是相同的。均是 512×64 。
Query,Key,Value的概念取自于信息检索系统,举个简单的搜索的例子来说。
当你在某电商平台搜索某件商品(年轻女士冬季穿的红色薄款羽绒服)时,你在搜索引擎上输入的内容便是Query,然后搜索引擎根据Query为你匹配Key(例如商品的种类,颜色,描述等),然后根据Query和Key的相似度得到匹配的内容(Value)。
self-attention中的Q,K,V也是起着类似的作用,在矩阵计算中,点积是计算两个矩阵相似度的方法之一,因此式1中使用了QK^T进行相似度的计算。
接着便是根据相似度进行输出的匹配,这里使用了加权匹配的方式,而权值就是query与key的相似度。
多注意头机制
Multi-headed attention增强了自注意能力,其一是扩展了关注的位置,使之同时关注多个不同位置,其二是它为注意力层提供了多个“表示子空间”,如论文用了8个注意头,那就有8组不同的Q/K/V矩阵,每个输入的词向量都被投影到8个表示子空间中进行计算。
具体流程如下图: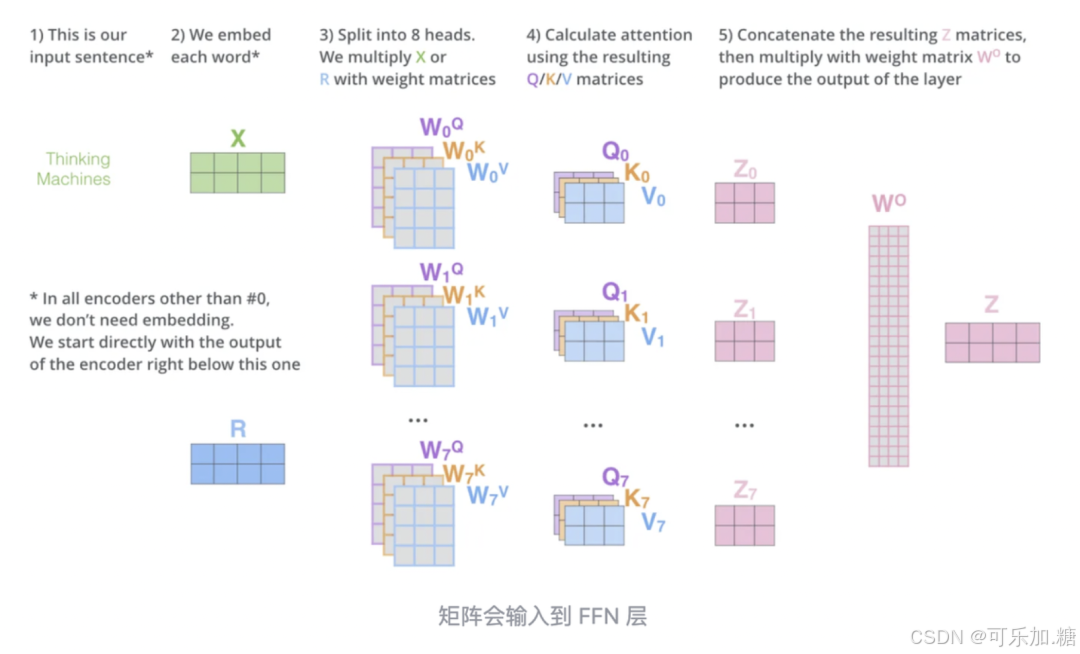
因此多注意头本质上是用更多个角度进行注意力计算再统一起来,能够增强对句子上下文的完整理解。
Transformer架构扩展与优化
- 多头注意力:并行多个注意力头(如8-128个),分别学习语法、语义等不同层面的特征关联。
- 混合专家系统(MoE):如GPT-4采用16个专家模型动态路由输入,提升模型容量与效率,参数利用率提升3倍以上。
- 多模态融合:智谱的GLM-4V-Plus模型结合视觉编码器与文本解码器,支持图像理解和视频分析,实现跨模态语义对齐。
(三)其他架构
除了 Transformer,还有一些其他类型的架构用于构建大模型。例如,在计算机视觉领域,卷积神经网络(CNN)及其变体如残差网络(ResNet)、Transformer 与 CNN 结合的架构等被广泛应用。这些架构通过卷积层、池化层等操作提取图像的局部特征和全局特征,并进行层次化的特征表示。
三、AI 大模型的训练过程
(一)数据准备
高质量的数据是训练大模型的基础。数据准备包括数据收集、清洗、标注和预处理等步骤。数据收集要尽可能广泛地覆盖目标任务的各类场景和情况;数据清洗用于去除噪声、错误数据和重复数据;标注则是为监督学习提供标签信息,如在自然语言处理中对文本进行分类、命名实体识别等标注;预处理包括归一化、词向量转换等操作,使数据适合模型输入。
(二)模型初始化
在训练开始前,需要对模型的参数进行初始化。常见的初始化方法有随机初始化、 Xavier 初始化和 He 初始化等。随机初始化是简单地给参数赋予随机小数值;Xavier 初始化考虑了神经元的输入连接数,使参数初始化更合理地分布在一定范围内;He 初始化则针对 ReLU 激活函数进行了优化,以更好地保持信号的传播。
(三)前向传播
前向传播是将输入数据通过神经网络的各层计算,得到输出结果的过程。在每一步计算中,神经元接收来自前一层的输入信号,进行加权求和并经过激活函数处理,将结果传递给下一层。这一过程按照网络的层次结构依次进行,直到得到最终输出。
(四)损失计算
损失函数用于衡量模型输出与真实标签之间的差异。常见的损失函数有均方误差(MSE)用于回归任务,交叉熵损失用于分类任务等。通过计算损失函数的值,可以了解模型在当前参数下的性能表现。
(五)反向传播与优化
反向传播是根据损失函数的梯度,从输出层向输入层依次更新模型参数的过程。通过链式法则计算每个参数对损失的贡献,即梯度值。然后,使用优化算法如随机梯度下降(SGD)、Adam 等,根据梯度信息调整参数,以最小化损失函数。这一过程不断迭代,直到模型收敛,即损失函数达到一个相对稳定的较小值。
四、AI 大模型的优化技巧
(一)分布式训练
由于大模型的参数量巨大,单机训练往往难以满足时间和资源需求。分布式训练通过将模型和数据分布在多个计算节点上,如多 GPU 或多服务器,实现并行计算。常见的分布式训练策略有数据并行、模型并行和混合并行等。数据并行是将数据分割成多个子集,在不同节点上同时进行前向传播和反向传播,然后聚合梯度更新参数;模型并行是将模型的不同部分分配到不同节点上,适合处理超大模型;混合并行则是结合数据并行和模型并行的优点。
预训练阶段
-
数据规模与质量:商汤开源的OmniCorpus数据集包含86亿图像与16,960亿文本标记,规模为传统数据集的15倍,覆盖多语言与多领域内容,为模型提供丰富知识基础。
-
训练目标:
- 语言建模(如GPT系列):预测下一个token,生成连贯文本;
- 对比学习(如CLIP):对齐图文表示空间,支持跨模态检索。
-
分布式训练技术:
混合并行策略可将万亿参数模型分布在数千张显卡上,训练效率提升超1倍(如腾讯混元大模型)。
微调与对齐技术
- 指令微调:通过人工标注指令集优化任务适配性,例如讯飞“Her”语音助手通过端到端训练实现拟人化交互。
- RLHF强化学习:
- 训练奖励模型评估生成质量;
- 使用PPO算法迭代优化策略,减少幻觉输出。
- 参数高效微调:
- LoRA:低秩矩阵适配,仅更新1%参数即可适配新任务;
- Prompt Tuning:学习可优化的提示前缀,降低训练成本。# (二)混合精度训练
混合精度训练利用不同精度的数据类型(如 FP32 和 FP16)来加速训练过程并减少内存占用。在训练中,关键计算如梯度更新使用 FP32 以保持精度,而大部分前向和反向传播计算使用 FP16,从而提高计算效率和内存利用率。
(三)梯度累积
当批量大小受限于内存时,梯度累积技术可以在小批量数据上进行多次前向和反向传播,累积梯度后再进行参数更新。这样既能保持较大的有效批量大小,又不会因内存不足而中断训练。
五、AI 大模型的应用场景
(一)自然语言处理
在自然语言处理领域,大模型被广泛应用于文本生成、机器翻译、问答系统、情感分析等任务。例如,GPT 系列模型能够生成高质量的文本内容,如新闻报道、故事创作等;在机器翻译中,大模型可以提供更准确、流畅的翻译结果;问答系统利用大模型的理解和推理能力,快速准确地回答用户的问题。
(二)计算机视觉
计算机视觉方面,大模型用于图像分类、目标检测、图像分割、图像生成等任务。例如,在自动驾驶中,大模型可以准确识别道路、车辆、行人等目标,为决策提供依据;在医学影像分析中,大模型能够辅助医生进行疾病诊断,提高诊断准确率。
(三)智能推荐
智能推荐系统借助大模型对用户行为、兴趣和物品特征的深度理解,为用户提供个性化推荐。例如,在电商平台,大模型根据用户的浏览和购买历史,推荐符合用户兴趣的商品;在视频平台,为用户推荐感兴趣的视频内容,提升用户体验和平台粘性。
六、知识涌现与推理能力突破
当模型参数量超过百亿级时,涌现出超越传统模型的特性:
- 上下文学习:通过少量示例理解新任务,如OpenCity交通预测模型在零样本条件下实现跨城市泛化;
- 思维链推理:分步骤解决复杂问题,如AlphaFold 3通过多阶段预测提升蛋白质结构准确性;
- 跨模态迁移:英伟达Eagle模型处理1024×1024像素图像,结合多专家编码器实现医疗影像分析;
- 知识内化:模型存储数万亿事实性知识,如GPT-4在专业考试中的表现接近人类专家。
性能扩展定律:
loss ∝ (N^-0.34)(D^-0.28)
其中N为参数量,D为数据量,表明模型性能随规模呈幂律提升。
七、技术挑战与前沿方向
核心挑战
- 算力与能耗:GPT-4训练耗电达50万千瓦时,亟需量子化压缩(如4-bit量化降低75%显存占用);
- 长上下文处理:超过32K Token的文本理解仍存在信息衰减,需优化位置编码与记忆机制;
- 伦理与安全:AI生成内容的法律责任(如美国警方使用GPT-4撰写犯罪报告引发争议)。
前沿探索
- 生物启发架构:如菌丝体电接口控制机器人运动,探索低功耗仿生计算;
- 小参数模型:李飞飞倡导通过空间智能优化,使10亿参数模型在特定领域媲美大模型;
- 联邦学习:分布式隐私保护框架,解决数据孤岛与合规性问题。
八、结论
- AI大模型的发展标志着从“数据驱动”到“知识涌现”的范式转变。未来趋势将聚焦多模态具身智能(如NEO机器人实现家务操作)9与可解释推理,而技术突破需依赖算法创新(如神经符号结合)、硬件升级与社会治理的协同。理解其原理不仅是技术需求,更是把握智能时代变革的关键。
- AI 大模型作为人工智能领域的重大突破,凭借其强大的表示能力和泛化能力,在众多领域展现出了巨大的应用潜力。从神经网络架构到训练优化技巧,再到广泛的应用场景,大模型的研究和应用不断推动着人工智能技术的发展。然而,大模型也面临着计算资源消耗大、模型解释性差、数据依赖性强等挑战。未来,随着技术的不断进步和创新,AI 大模型有望在更广泛的领域发挥更大的作用,为人类社会带来更多的便利和福祉。

欢迎加入DeepSeek 技术社区。在这里,你可以找到志同道合的朋友,共同探索AI技术的奥秘。
更多推荐

 24
24 0
0- 0



 已为社区贡献1条内容
已为社区贡献1条内容

所有评论(0)