基于LLM的面向小学学段的AI辅助学习app个人博客(一)
技术选型需建立多维度评估模型(成本、可用性、本地化支持);充分利用生成式AI的辅助决策能力,可突破信息茧房(如之前我仅关注官方AI模型的API到最后发现并使用第三方服务生态。
前言:
为系统规划项目开发路径,本周我重点推进了两项基础性工作:一方面通过需求分析与概要设计锚定项目核心目标,完成功能框架与技术选型的初步规划;另一方面先行完成AI服务接口的预研选型,为后续学习、开发减轻压力。此阶段工作旨在构建清晰的项目实施路线图,通过前端规划有效规避后期开发过程中的方向性偏差与技术风险,确保项目推进效率与落地可行性。
第一部分:简要需求分析与概要设计
一、用户端
1. 主要功能模块
1.1 知识题库模块
-
有效组织、分类语数英各个学科、学段的题库,关联对应的知识点标签。
-
按照一定的算法随机呈现题目,能够根据学习情况动态调整题目出现的概率。
-
题目可通过文本、图片、音频、交互等多模态呈现。
-
允许查看已做题目及解析。
-
对做错的题目自动计入错题本,并提供错误原因及解析。
-
记录用户的做题用时。
1.2 拍照搜题模块
-
支持用户上传图片,提取题目文字。
-
对题目进行分词,并在题目数据库中检索相关内容。
-
提供AI解答及解析,并注明知识点。
-
支持手写体、印刷体识别及多语言识别。
1.3 错题本模块
-
分类别管理记录错题,包括作答情况和用时。
-
提供错题解析,并分析错误的可能原因。
-
根据知识点推荐同类题目。
1.4 个性化发展模块
-
采用Chatbot形式进行交互式对话。
-
根据学习情况、学习时长提供每周学习规划和建议。
-
允许用户通过描述性语言或直接修改方式调整学习计划。
-
根据学习规划提醒用户进行学习。
-
依据用户偏好提供正向激励内容。
2. 辅助功能模块
2.1 用户管理模块
-
支持用户注册、登录,确保账号安全。
-
允许用户设置、修改昵称、头像、学段等个人信息。
-
允许用户设置偏好,以提供正向激励。
2.2 系统设置模块
-
提供多种UI主题,包括护眼模式。
-
统计学习情况,如每周学习时长、做题数等。
-
允许手动设置学习计时,记录线下学习时长。
2.3 留言沟通模块
-
支持接收、查看家长留言。
-
允许用户给家长留言。
-
可对接收、发送的留言追加留言。
二、管理员端
1. 主要功能模块
1.1 数据管理模块
-
管理题目数据库,包括增删改查及知识点关联。
-
管理AI访问控制的API。
-
追踪、记录所有外部API调用。
1.2 用户管理模块
-
管理用户账号,支持封禁用户账号。
-
管理家长账号与学生账号的绑定关系。
三、家长端
1. 主要功能模块
1.1 学习情况跟踪模块
-
按学科(语数英)及学段查看学生学习进度、知识点掌握情况。
-
通过可视化图表展示每周/月的学习时长、题目正确率及知识点薄弱项。
-
支持查看学生做题历史记录,包括题目内容、答案解析及用时统计。
-
同步查看学生错题本内容。
1.2 学习规划监督模块
-
查看学生当前学习计划详情(每日任务、完成进度)。
-
提供阶段性学习报告(如周报、月报)。
-
对AI生成的学习计划进行确认或驳回。
1.3 留言沟通模块
-
接收、查看孩子留言。
-
允许家长给孩子留言。
-
可对接收、发送的留言追加留言。
2. 辅助功能模块
2.1 用户管理模块
-
支持用户注册、登录,确保账号安全。
-
允许用户设置、修改昵称、头像等个人信息。
2.2 账号绑定管理模块
-
支持家长账号与多个学生账号绑定(适应多子女家庭)。
-
管理绑定关系权限(如限制查看特定学科数据)。
2.3 系统设置模块
-
自定义接收通知类型(错题预警、学习计划变更、学习完成进度等)。
-
切换家长端界面主题模式(如日间/夜间模式)。
-
管理数据同步频率及存储空间。
四、非功能性需求
1. 性能
-
核心操作响应时间≤1秒,学习报告生成时间≤5秒。
-
学生端与家长端数据同步延迟≤2秒。
2. 安全
-
家长-学生账号绑定需双向验证,解绑操作需输入解绑密码(家长与学生绑定后,仅家长端收到解绑密码)。
第二部分:确定所用AI的API接口的可行性
一、音频生成模型筛选过程
1、初步调研阶段:
优先考察文本转音频(TTS)模型,重点评估ToucanTTS性能表现。实测发现其音频生成质量优异,但其中文官网中的github网站链接失效技术文档获取障碍,且模型部署复杂度超出项目周期承受能力,故暂弃用。
2、替代方案探索:
转向图像转音频技术方案,系统测试Amazon Polly、Colossyan TTS、Descript TTS及Google Cloud TTS等主流API服务。受限于账号注册流程繁琐、服务费用没法缴纳(学生本人没有VISA卡等)、超出预算(如Descript TTS按分钟计费模式)及部分平台国内访问稳定性问题,最终未采纳。经过一整天的寻找后,暂时没有进展,决定先寻找文生图的AI模型。
二、图像生成模型适配方案
1、技术选型阶段:
针对文本转图像(Text-to-Image)需求,建立DALL·E、MidJourney、Stable Diffusion、DeepArt及Google Imagen的对比矩阵。通过生成质量、API调用成本、中文支持度等维度评估,选定Stable Diffusion作为核心模型。
官方方案受限:Stable Diffusion官网服务存在预训练模型调用成本过高(单次生成约$0.25)及国内网络延迟问题。
2、实施障碍突破:
- 技术路径调整:在问询chatGPT有没有其它文生图的AI模型时,它给了我解决思路:转向国内生态,并给我的几个国内平台,经过测试后,也因为一些问题暂时将其暂时搁置:触站AI(生成质量达标但成本过高且试用期较短)、即梦AI(暂不提供API的调用)等平台
- 最终解决方案的得出:在询问其它平台的部署时,chatGPT利用阿里云百炼的API使用文档给我了答复。经过接口验证测试后,确认其可以支持项目运行。
三、方案测试结果
最终,在寻找完图像生成模型后,我在阿里云百炼中顺利找到了音频生成模型,以下为测试音频生成模型API的部分代码(api以XXXXX来表示)
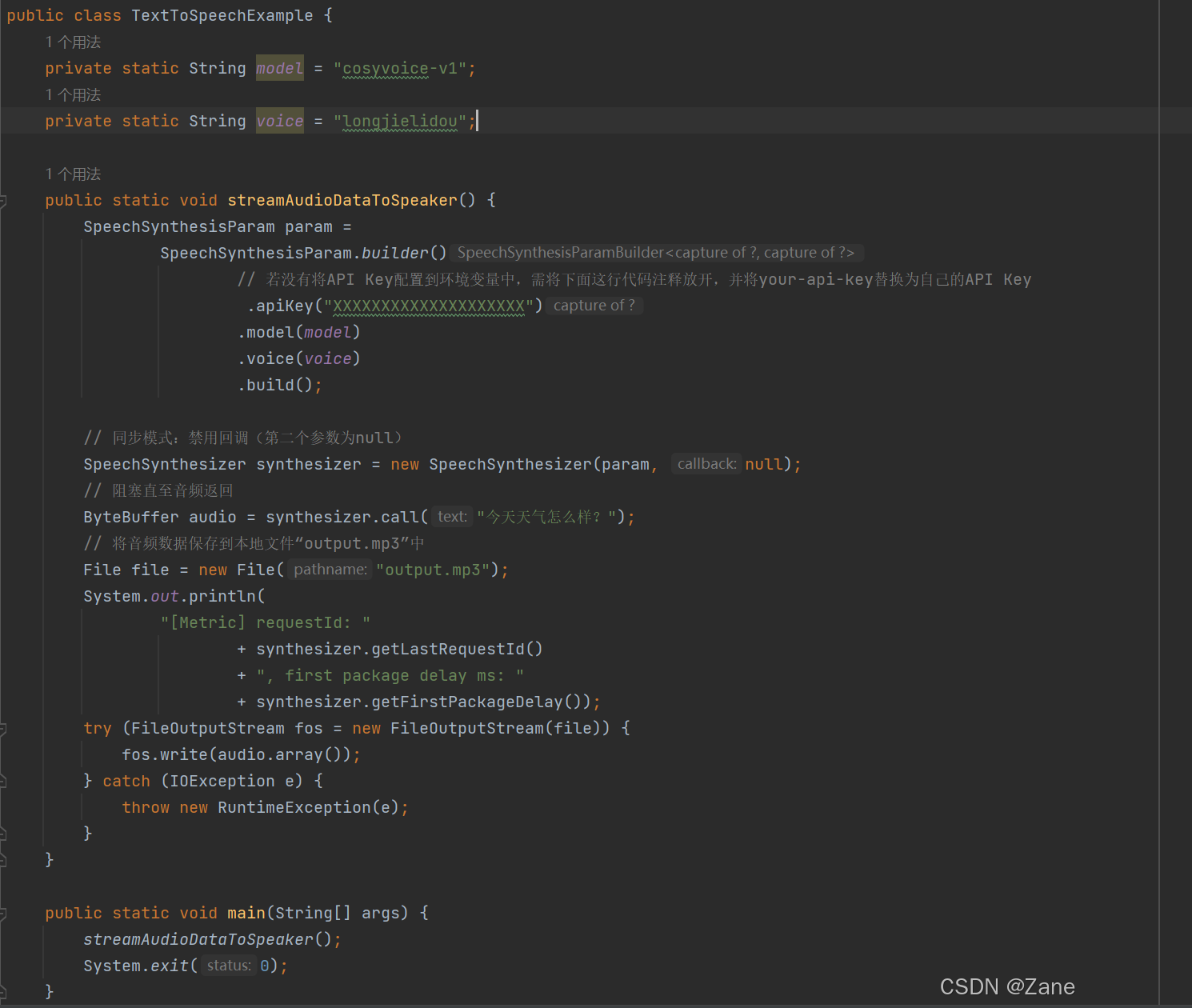
测试图像生成模型API的部分代码(api以XXXXX来表示)
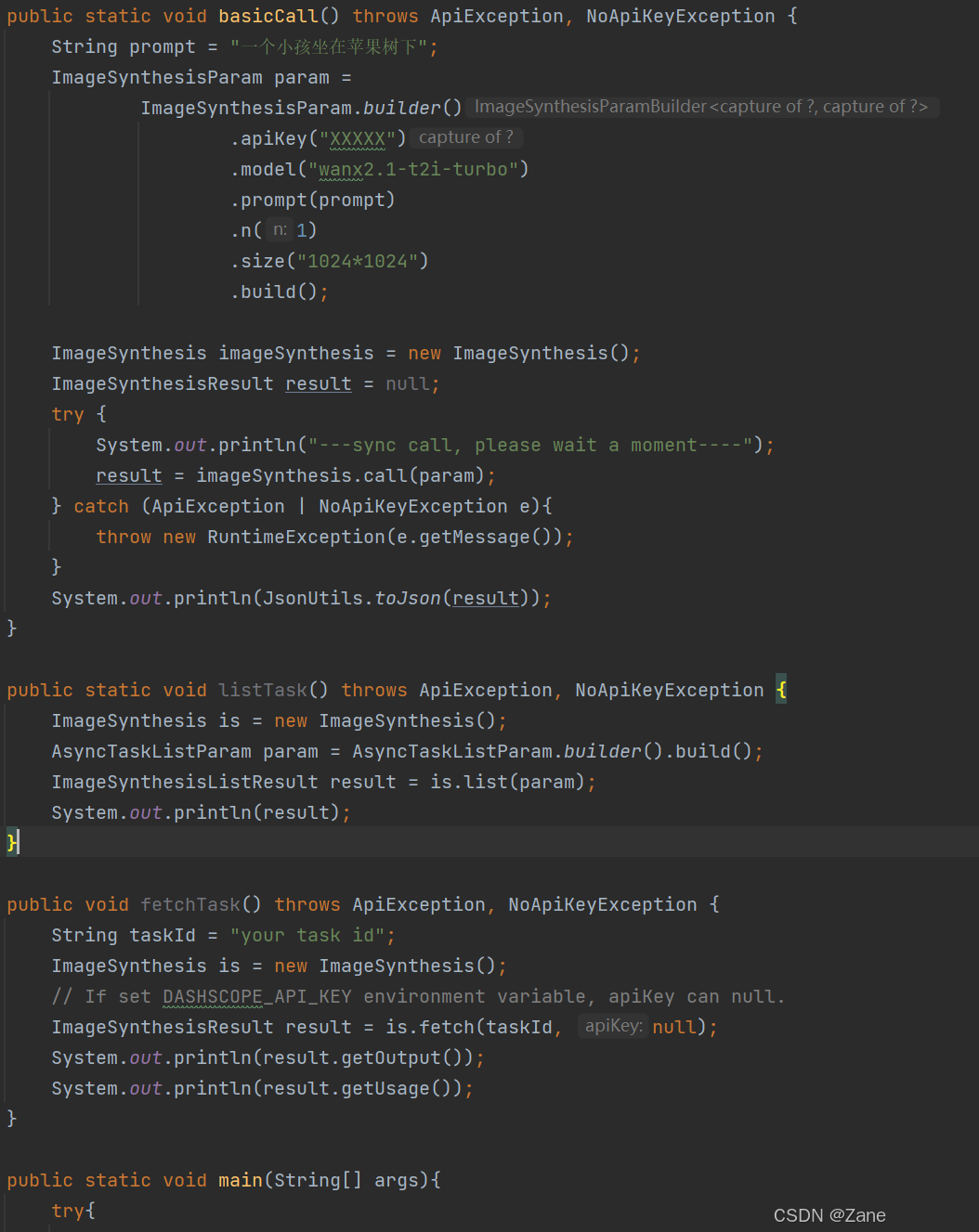
运行结果:返回一个URL,该URL指向生成的图片,如下:
第三部分:总结
通过本次选型过程,我学习到了两条重要经验:
- 技术选型需建立多维度评估模型(成本、可用性、本地化支持);
- 充分利用生成式AI的辅助决策能力,可突破信息茧房(如之前我仅关注官方AI模型的API到最后发现并使用第三方服务生态。

欢迎加入DeepSeek 技术社区。在这里,你可以找到志同道合的朋友,共同探索AI技术的奥秘。
更多推荐


 41
41 0
0- 0



 已为社区贡献2条内容
已为社区贡献2条内容

所有评论(0)