你真的了解C++ map和multimap吗?一文解锁底层原理与高频考点
/ 定义一个 map,键为 int,值为 string// 插入元素// 使用下标操作符// 使用 insert 方法// 使用 make_pair// 1. 默认构造函数// 创建一个空的 map,键的类型为 int,值的类型为 string// 使用默认的比较函数 less<int> 对键进行排序// 2. 范围构造函数// 从一个包含 pair 的容器的迭代器范围来初始化 map// 3.
map
map 是 C++ STL 中的一种关联容器,用于存储键值对(key-value pairs)。每个键都是唯一的,可以通过键快速查找对应的值。下面是对 map 的详细讲解,包括其特性、用法和常见操作。
1. 基本特性
- 键值对:每个元素由一个键和一个对应的值组成,使用
pair结构存储。 - 唯一性:每个键在
map中是唯一的,如果插入一个已存在的键,则插入操作将无效(更新值)。 - 有序性:
map中的元素是按键的顺序排列的,默认情况下使用键的升序排序。 - 自动平衡:内部使用红黑树实现,保证了查找、插入和删除操作的时间复杂度为 O(log n)。
map的模板参数说明:
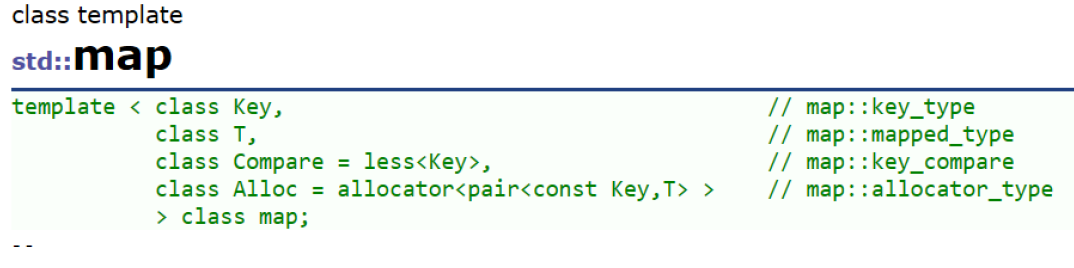
key: 键值对中key的类型
T: 键值对中value的类型
Compare: 比较器的类型,map中的元素是按照key来比较的,缺省情况下按照小于来比
较,一般情况下(内置类型元素)该参数不需要传递,如果无法比较时(自定义类型),需要用户
自己显式传递比较规则(一般情况下按照函数指针或者仿函数来传递)
Alloc:通过空间配置器来申请底层空间,不需要用户传递,除非用户不想使用标准库提供的
空间配置器
注意:在使用map时,需要包含头文件。 #include
2. 定义与初始化
// 定义一个 map,键为 int,值为 string
map<int, string> myMap;
// 插入元素
myMap[1] = "One"; // 使用下标操作符
myMap.insert({2, "Two"}); // 使用 insert 方法
myMap.insert(make_pair(3, "Three")); // 使用 make_pair
// 1. 默认构造函数
// 创建一个空的 map,键的类型为 int,值的类型为 string
// 使用默认的比较函数 less<int> 对键进行排序
map<int, string> defaultMap;
// 2. 范围构造函数
// 从一个包含 pair 的容器的迭代器范围来初始化 map
vector<pair<int, string>> vec = {{1, "apple"}, {2, "banana"}, {3, "cherry"}};
map<int, string> rangeMap(vec.begin(), vec.end());
// 3. 拷贝构造函数
// 创建一个新的 map,它是另一个 map 的副本
map<int, string> copiedMap(rangeMap);
// 4. 移动构造函数
// 从另一个 map 中移动元素到新的 map 中,原 map 会变为空
map<int, string> movedMap(move(copiedMap));
// 5. 初始化列表构造函数
// 使用初始化列表直接初始化 map
map<int, string> initListMap = {{4, "date"}, {5, "elderberry"}};
3. 常见操作
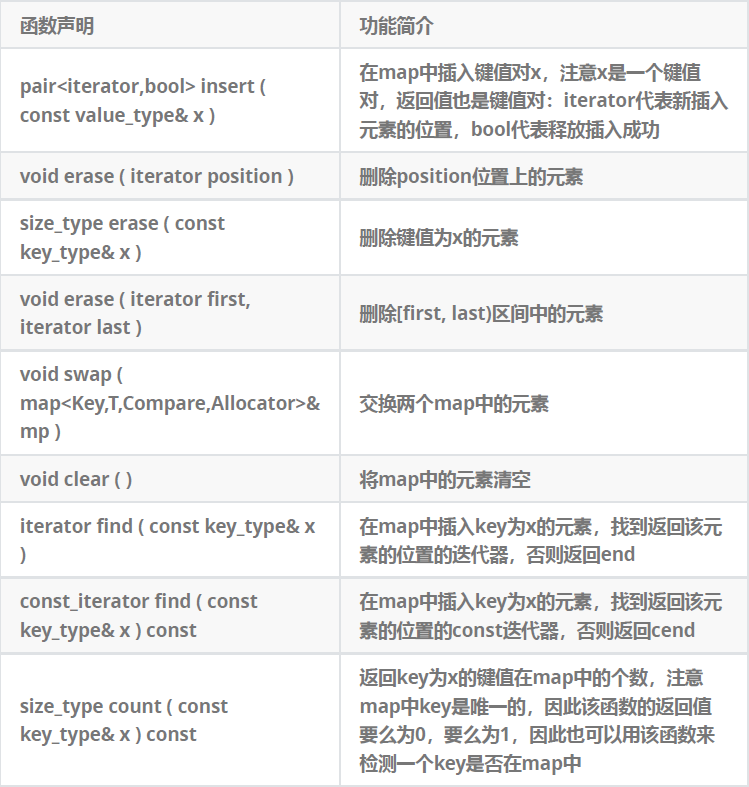
插入元素
myMap[4] = "Four"; // 插入键为 4,值为 "Four"
myMap.insert({5, "Five"}); // 插入键为 5,值为 "Five"
insert()方法:
insert() 方法是 std::map 或 std::set 的成员函数,用于插入元素。它接受一个元素或一个元素对 pair 作为参数,并将其插入到 map 或 set 中。
- 返回值:
insert()方法会返回一个pair,其第一个元素是指向插入位置的迭代器,第二个元素是一个布尔值,表示是否成功插入。- 如果插入成功(即没有重复的键),返回的布尔值为
true。 - 如果插入失败(即插入的键已经存在),返回的布尔值为
false。
- 如果插入成功(即没有重复的键),返回的布尔值为
- 插入方式: 你可以直接传入一个
pair或{key, value}来插入。示例:
map<int, string> myMap;
myMap.insert({1, "One"}); // 通过初始化列表插入键值对
myMap.insert(make_pair(2, "Two")); // 使用 make_pair 创建并插入键值对
- 特点:
insert()会判断元素是否已经存在,如果键已存在,则不会插入新元素。- 如果插入的键已经存在,
insert()会保持原有的键值对不变,并返回一个指向已存在元素的迭代器。
make_pair()函数:
make_pair() 是一个辅助函数,用于构造一个 pair 对象。它的作用是方便地创建一个 pair,使得你可以将其作为参数传递给其他函数(例如 insert())。
- 功能:
make_pair()不会直接插入任何元素。它只是创建一个pair对象,并返回该pair。- 例如:
make_pair(1, "One")会返回一个pair<int, string>,即{1, "One"}。
- 例如:
- 与
insert()结合使用: 通常在插入时,我们会将make_pair()和insert()配合使用,来创建和插入键值对。示例:
map<int, string> myMap;
myMap.insert(make_pair(1, "One")); // 创建并插入一个键值对
这里,make_pair() 创建了一个 pair<int, string>,然后通过 insert() 插入到 map 中。
- 特点:
make_pair()只是一个工具函数,用于简化pair的创建,它本身不进行插入。- 它的返回值是一个
pair对象,包含了你要插入的键值对。
两者的区别:
insert()** 是插入操作,make_pair()只是创建pair:**insert()负责将元素插入到容器中。make_pair()只是创建一个pair,你可以将它用作insert()的参数,或者其他地方需要pair的地方。
- 使用场景:
insert()用于实际的插入操作,它可以接受一个pair、初始化列表或者其他容器。make_pair()用于方便地创建一个pair,让你更简洁地写出键值对。
例子对比:
假设我们有一个 map<int, string>,并且我们想插入 {1, "One"} 和 {2, "Two"}:
使用 insert():
map<int, string> myMap;
myMap.insert({1, "One"}); // 直接通过初始化列表插入
myMap.insert({2, "Two"});
使用 make_pair():
map<int, string> myMap;
myMap.insert(make_pair(1, "One")); // 使用 make_pair 创建并插入
myMap.insert(make_pair(2, "Two"));
这两种方式的效果是相同的,但 make_pair() 使得我们在某些情况下可以显式地创建 pair,尤其是当需要在函数中动态构造键值对时。
查找元素
- 使用
find()方法查找键是否存在,并获取对应的值。
auto it = myMap.find(2); // 返回指向键为 2 的迭代器
if (it != myMap.end()) {
cout << "Found: " << it->second << endl; // 输出 "Found: Two"
} else {
cout << "Not found" << endl;
}
- 使用下标操作符查找元素:
cout << myMap[1]; // 输出 "One"
注意:如果键不存在,使用下标操作符会插入该键并将其值初始化为默认值。
删除元素
myMap.erase(3); // 删除键为 3 的元素
- 可以使用迭代器删除:
auto it = myMap.find(2);
if (it != myMap.end()) {
myMap.erase(it); // 删除键为 2 的元素
}
遍历元素
for (const auto& pair : myMap) {
cout << pair.first << ": " << pair.second << endl; // 输出每个键值对
}
访问元素
1. **operator[]**(下标运算符)访问:
- 功能:** 使用
**operator[]**访问时,可以通过键来获取与之对应的值。** - 行为:
示例:
map<int, string> myMap;
myMap[1] = "One"; // 插入 {1, "One"}
myMap[2] = "Two"; // 插入 {2, "Two"}
// 访问元素
cout << myMap[1]; // 输出 "One"
// 使用下标访问并修改值
myMap[1] = "New One"; // 修改键为1的值
cout << myMap[1]; // 输出 "New One"
// 如果键不存在,则会插入新键值对 {3, ""}
cout << myMap[3]; // 输出 ""
- 如果键存在,返回对应的值,并且你可以修改这个值。
- 如果键不存在,会 **自动插入一个新的键值对**,其中键是你提供的键,而值会使用该类型的默认构造函数来创建。对于内置类型(如 `int`),默认值是 `0`,对于类类型,则会调用默认构造函数(例如,`string` 类型会初始化为 `""`,`vector<int>` 类型会初始化为空的 `vector`)。
- 优点: 使用简单方便,适用于已知键存在或者可以接受自动插入默认值的情况。
- 缺点: 如果访问一个不存在的键,
operator[]会 自动插入 一个新的键值对,这可能会导致不希望的修改或插入。
2. **at()** 函数访问:
- 功能:
at()函数也是用于通过键访问值,它与operator[]类似,区别在于它会抛出异常。 - 行为:
示例:
map<int, string> myMap;
myMap[1] = "One"; // 插入 {1, "One"}
// 访问元素
cout << myMap.at(1); // 输出 "One"
try {
cout << myMap.at(2); // 访问不存在的键,抛出异常
} catch (const out_of_range& e) {
cout << "Exception: " << e.what(); // 输出异常信息
}
- 如果键存在,返回对应的值,并且你可以修改这个值。
- 如果键 不存在,`at()` 会 抛出 `out_of_range` 异常,因此你需要使用 `try-catch` 来捕获这个异常。
- 优点: 如果你不希望无意间插入新的键值对,
at()提供了更安全的访问方式,因为它会在键不存在时抛出异常。 - 缺点: 需要处理异常(
try-catch),如果你不处理异常,程序会崩溃。
区别总结:
| 特性 | **operator[]** |
**at()** |
|---|---|---|
| 返回值 | 返回对应键的值(引用),可以修改 | 返回对应键的值(引用),可以修改 |
| 键存在时 | 返回对应的值,并可以修改 | 返回对应的值,并可以修改 |
| 键不存在时 | 自动插入一个新键值对,值为该类型的默认值 | 抛出 **out_of_range** 异常 |
| 插入行为 | 会插入新元素(如果键不存在) | 不会插入新元素 |
| 异常 | 无 | 会抛出 **out_of_range** 异常 |
4. 特殊用法
- 默认比较:
map默认使用<运算符进行比较,可以自定义比较规则。
map<string, int, greater<string>> myMap; // 按字母降序排序
- 多重值:如果需要一个键对应多个值,可以使用
multimap。
5.代码示例
map<string, string> m;
// 向map中插入元素的方式:
// 用pair直接来构造键值对
m.insert(pair<string, string>("peach", "桃子"));
// 用make_pair函数来构造键值对
m.insert(make_pair("banan", "香蕉"));
// 借用operator[]向map中插入元素
/*
operator[]的原理是:
用<key, T()>构造一个键值对,然后调用insert()函数将该键值对插入到map中
如果key已经存在,插入失败,insert函数返回该key所在位置的迭代器
如果key不存在,插入成功,insert函数返回新插入元素所在位置的迭代器
operator[]函数最后将insert返回值键值对中的value返回
*/
// 将<"apple", "">插入map中,插入成功,返回value的引用,将“苹果”赋值给该引
//用结果,
m["apple"] = "苹果";
// key不存在时抛异常
//m.at("waterme") = "水蜜桃";
// map中的键值对key一定是唯一的,如果key存在将插入失败
auto ret = m.insert(make_pair("peach", "桃色"));
if (ret.second)
cout << "<peach, 桃色>不在map中, 已经插入" << endl;
else
cout << "键值为peach的元素已经存在:" << ret.first->first << "--->"
<< ret.first->second << " 插入失败" << endl;
// 删除key为"apple"的元素
m.erase("apple");
if (1 == m.count("apple"))
cout << "apple还在" << endl;
else
cout << "apple被吃了" << endl;
multimap
- Multimaps是关联式容器,它按照特定的顺序,存储由key和value映射成的键值对<key,
value>,其中多个键值对之间的key是可以重复的。
- 在multimap中,通常按照key排序和惟一地标识元素,而映射的value存储与key关联的内
容。key和value的类型可能不同,通过multimap内部的成员类型value_type组合在一起,
value_type是组合key和value的键值对:
typedef pair<const Key, T> value_type;
- 在内部,multimap中的元素总是通过其内部比较对象,按照指定的特定严格弱排序标准对
key进行排序的。
- multimap通过key访问单个元素的速度通常比unordered_multimap容器慢,但是使用迭代
器直接遍历multimap中的元素可以得到关于key有序的序列。
- multimap在底层用**二叉搜索树(红黑树)**来实现。
注意:multimap和map的唯一不同就是:map中的key是唯一的,而multimap中key是可以
重复的。
- multimap的使用
multimap中的接口可以参考map,功能都是类似的。
注意:
-
multimap中的key是可以重复的。
-
multimap中的元素默认将key按照小于来比较
-
multimap中没有重载operator[]操作(同学们可思考下为什么?)。
-
使用时与map包含的头文件相同:
与map的不同
- 是否允许键重复
map: 不允许键重复。每个键只能对应一个值。如果尝试插入具有相同键的键值对,插入操作会失败。multimap: 允许键重复。可以存储多个具有相同键的键值对。
2. 插入元素的行为
map:- 如果插入一个已存在的键,则不会插入新值,而是保留原有值。
- 使用下标运算符
operator[]可以方便地插入或修改键值对。
multimap:- 每次插入都会创建一个新的键值对,即使键已存在。
- 不支持下标运算符
operator[],只能使用insert等方法插入数据。
示例:
3. 查找元素的行为
map:find(key)返回一个指向 唯一键值对 的迭代器。- 如果键不存在,返回
end()。
multimap:find(key)返回指向第一个匹配键的迭代器。- 如果键不存在,返回
end()。 - 可以使用
equal_range(key)获取所有具有相同键的范围。
示例:
#include <iostream>
#include <map>
using namespace std;
int main() {
multimap<int, string> myMultiMap;
myMultiMap.insert({1, "One"});
myMultiMap.insert({1, "Another One"});
auto range = myMultiMap.equal_range(1); // 获取键为1的范围
for (auto it = range.first; it != range.second; ++it) {
cout << it->first << ": " << it->second << endl;
}
return 0;
}
输出:
1: One
1: Another One
4. 性能差异
- 在大多数操作(如插入、删除、查找)中,
map和multimap的性能相似,因为它们都基于 红黑树 实现,时间复杂度为 O(log n)。 - 注意:
map在插入重复键时会额外检查键是否已存在,因此插入操作可能略慢于multimap。multimap由于允许重复键,无需进行唯一性检查,插入操作可能稍快。
5. 下标运算符
map: 支持下标运算符operator[],不仅可以用于访问,还可以用于插入数据。multimap: 不支持下标运算符,必须使用insert来插入数据。
6. 使用场景
map: 适合用在键值唯一的场景,例如学生 ID 和姓名的对应关系。multimap: 适合用在键值可以重复的场景,例如学生分数和姓名的对应关系(可能有多个学生有相同分数)。
7. 总结对比表
| 特性 | map |
multimap |
|---|---|---|
| 是否允许键重复 | 否 | 是 |
| 插入行为 | 相同键覆盖旧值 | 每次插入新键值对 |
下标运算符 ([]) |
支持 | 不支持 |
| 查找行为 | 返回唯一键值对 | 返回第一个匹配键,并支持范围查找 |
| 性能 | 插入稍慢(需检查唯一性) | 插入稍快(无唯一性检查) |
| 适用场景 | 键唯一的场景 | 键重复的场景 |
multimap,multiset为何都都不提供[]
multimap 和 multiset 都不提供 operator[] 操作符,主要原因在于它们的特性和设计目的。
multimap不提供operator[]的原因
map 中的 operator[] 允许通过键来访问值,并在键不存在时自动插入一个具有默认值的键值对。这是基于 map 的单一键值映射的设计原则:每个键都唯一,只映射到一个值。这种语法对 map 很自然,但对 multimap 不适用。
在 multimap 中,每个键可以对应多个值(即允许重复键)。因此,如果 multimap 提供 operator[],就会产生以下问题:
- 不明确的语义:
operator[]应该返回哪个值?因为同一个键可能映射到多个值,直接通过operator[]查找不具有确定性。 - 违背设计逻辑:
operator[]通常在键不存在时会插入默认值,但multimap不希望如此,因为它的设计初衷是支持键的多对一映射,而不是默认的单一键值对。
因此,为了避免模糊性,multimap 只提供了插入和查找方法(如 insert 和 equal_range 等),而没有 operator[] 的支持。
multiset不提供operator[]的原因
multiset 是一个不允许重复键的集合,且元素本身没有任何“值”可以通过 operator[] 修改。multiset 中的每个元素都是独立的,不像 map 中的键值对那样具备“键-值”结构,因此使用 operator[] 并无意义。
在 multiset 中,元素可以多次插入,并且插入的只是一个值(没有键对应的映射值),因此:
- 无键-值结构:
operator[]在multiset中不适用,因为没有“键”可以进行查找,也没有“值”可以访问或修改。 - 不支持默认插入:
operator[]通常会在键不存在时插入默认值,这与multiset的集合概念不符。
因此,multiset 和 multimap 都没有实现 operator[],而是提供了插入、查找、删除等符合集合语义的方法,以更好地符合它们的设计初衷。
在OJ题中的使用
138. 随机链表的复制
(https://leetcode.cn/problems/copy-list-with-random-pointer/)
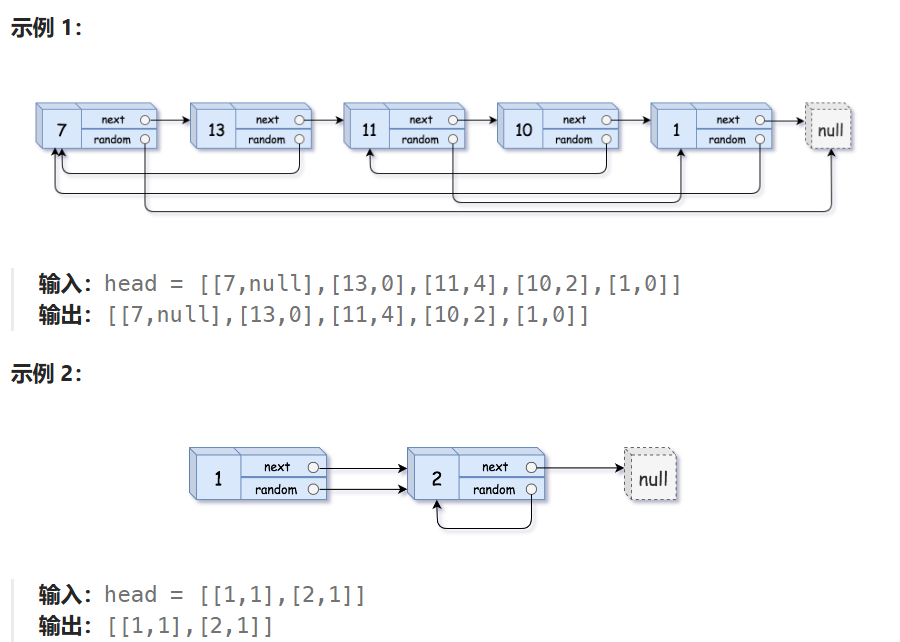
解法1
这段代码的主要思路是利用哈希表来建立原节点与新节点的映射关系,进而完成链表的深拷贝。整个流程分为两步:
- 创建拷贝链表的节点及其
next指针:遍历原链表,创建每个节点的新拷贝节点,将新节点插入拷贝链表中。并使用一个哈希表nodeMap来存储原节点和新节点之间的对应关系。 - 复制
random指针:再次遍历链表,对于每个节点,利用nodeMap映射找到其random指针指向的新节点,并完成新链表中的random指针的设置。
代码解读与注释
// Definition for a Node.
class Node {
public:
int val;
Node* next;
Node* random;
Node(int _val) {
val = _val;
next = nullptr;
random = nullptr;
}
};
class Solution {
public:
Node* copyRandomList(Node* head) {
// 哈希表用于存储原节点和新节点的映射
map<Node*, Node*> nodeMap;
// 初始化拷贝链表的头和尾指针
Node* copyhead = nullptr;
Node* copytail = nullptr;
// 遍历原链表,复制节点并建立节点映射
Node* cur = head;
while (cur) {
// 如果拷贝链表为空,初始化头节点
if (copytail == nullptr) {
copyhead = copytail = new Node(cur->val);
} else { // 如果不为空,创建新节点并接到拷贝链表末尾
copytail->next = new Node(cur->val);
copytail = copytail->next;
}
// 将原节点和新节点存储到哈希表中
nodeMap[cur] = copytail;
cur = cur->next; // 移动到下一个原链表节点
}
// 第二次遍历原链表,复制 random 指针
cur = head;
Node* copy = copyhead; // copy 用于遍历拷贝链表
while (cur) {
// 若 cur 的 random 指针为空,则 copy 的 random 也为空
if (cur->random == nullptr) {
copy->random = nullptr;
} else {
// 若 cur 的 random 指向某个节点,则通过 nodeMap 获取对应的拷贝节点
copy->random = nodeMap[cur->random];
}
// 继续遍历原链表和拷贝链表
cur = cur->next;
copy = copy->next;
}
// 返回拷贝链表的头节点
return copyhead;
}
};
解法评价
- 优点:此方法利用哈希表来存储原链表节点与新节点的对应关系,简单明了,适合理解和调试。通过两次遍历链表,能够准确地复制所有的
next和random指针。 - 时间复杂度:
O(n),其中n是链表节点数。两次遍历的总时间复杂度是线性的。 - 空间复杂度:
O(n),主要是用来存储nodeMap哈希表,该表的大小和链表的节点数成正比。
注意点
- 使用
nodeMap保存原链表节点与拷贝链表节点的映射,确保random指针指向的是新链表的对应节点,而不是原链表节点。 nodeMap[cur->random]可以直接访问到对应的拷贝节点,大大简化了查找random指针的复杂度。
解法2: 回溯 + 哈希表
这个解法通过 回溯 + 哈希表 的方式进行链表深拷贝,使用了递归的思路,将原链表中的每一个节点都独立地复制。因为链表中存在随机指针(random),导致在复制某节点时,可能指向的节点还没有被创建,所以需要特别处理。这个方法的核心是利用 递归回溯 和 哈希表,以确保所有节点都只被创建一次。
解法思路
具体流程如下:
- 哈希表保存映射关系:为了保证每个节点只被复制一次,定义一个哈希表
cachedNode,其中key是原链表中的节点,value是对应的复制节点。这样就可以快速查询一个节点是否已经复制过。 - 递归创建复制节点:
- 如果传入的节点为空,返回
nullptr,表示递归到达链表尾部,结束递归。 - 否则,检查哈希表
cachedNode中是否存在这个节点:- 未复制过:说明当前节点没有被创建,那么就创建一个新节点,将其值设为原节点的值,将其保存到
cachedNode中,并继续递归创建当前节点的next和random指针指向的节点。 - 已复制过:直接从哈希表
cachedNode中返回该节点的引用,避免重复创建。
- 未复制过:说明当前节点没有被创建,那么就创建一个新节点,将其值设为原节点的值,将其保存到
- 如果传入的节点为空,返回
- 回溯并赋值:递归调用返回时,将
next和random指针设置为新链表中的对应节点。通过回溯的方式,逐层构造链表并完成指针的连接。 - 最终返回头节点:返回深拷贝链表的头节点即可。
代码分析与注释
class Solution {
public:
unordered_map<Node*, Node*> cachedNode; // 哈希表:存储原节点到新节点的映射
Node* copyRandomList(Node* head) {
// 如果当前节点为空,直接返回空指针
if (head == nullptr) {
return nullptr;
}
// 检查哈希表中是否已经存在该节点的拷贝
if (!cachedNode.count(head)) {
// 如果当前节点没有被拷贝过,创建一个新节点
Node* headNew = new Node(head->val);
cachedNode[head] = headNew; // 将新节点存入哈希表中
// 递归拷贝当前节点的 next 和 random 指针
headNew->next = copyRandomList(head->next);
headNew->random = copyRandomList(head->random);
}
// 如果当前节点已经被拷贝过,直接返回该节点的拷贝
return cachedNode[head];
}
};
具体例子分析
假设链表中有三个节点 A、B、C,链表结构如下:
- A 指向 B,B 指向 C
- A 的
random指针指向 C,B 的random指针指向 A,C 的random指针为空。
在调用 copyRandomList(A) 时的递归过程:
A未被复制过,创建A',并将A -> A'映射存入cachedNode。- 开始递归创建
A的next节点B的拷贝,调用copyRandomList(B)。 B未被复制过,创建B',并将B -> B'映射存入cachedNode。- 开始递归创建
B的next节点C的拷贝,调用copyRandomList(C)。 C未被复制过,创建C',并将C -> C'映射存入cachedNode。C的next为nullptr,因此C'的next也设为nullptr,同时C.random为nullptr,所以C'.random也设为nullptr。- 回溯到
B,将B'的next设为C',并递归B.random指向的A,返回A'作为B'.random。 - 回溯到
A,将A'的next设为B',并递归A.random指向的C,返回C'作为A'.random。
最终返回 A',构造出的链表为拷贝的链表。
评价
- 优点:通过哈希表来记录原节点与新节点的映射关系,有效防止了重复创建节点,且借助回溯的思路使得指针的拷贝逻辑非常清晰。
- 时间复杂度:
O(n),需要遍历整个链表一次,并创建n个节点。 - 空间复杂度:
O(n),主要是哈希表cachedNode所占用的空间。
总结
这种方法简洁且具有通用性,通过回溯实现了深拷贝,适合处理链表中复杂指针关系的深拷贝问题。
这个代码中的递归过程其实并没有显式地表现出“回溯”的操作,它主要是递归地调用自身来构建新链表。在这里,回溯体现在递归函数的“逐层返回”上。
代码中的“回溯”原理
让我们从递归调用的角度来解释这个代码的执行过程。在链表的每一层递归调用中,代码会递归地构建当前节点的 next 和 random 指针指向的节点,然后逐层返回,把构建好的节点组装成一个完整的链表。
在递归调用时,当前函数会等待 copyRandomList(head->next) 和 copyRandomList(head->random) 递归调用完成,才能继续执行剩下的代码。由于每层递归都创建新节点并把它放入 cachedNode 中,当回到上层时,可以直接从 cachedNode 中取出新节点,避免重复创建。
示例解析
假设链表结构如下:
head -> Node1 (val = 1, random -> Node3)
|
v
Node2 (val = 2, random -> Node1)
|
v
Node3 (val = 3, random -> Node2)
执行步骤如下:
- **第一个节点 **
Node1:调用copyRandomList(Node1)。Node1未拷贝过,创建新节点Node1_copy。- 对
Node1->next调用copyRandomList(Node2),递归进入Node2的拷贝。
- **第二个节点 **
Node2:递归进入copyRandomList(Node2)。Node2未拷贝过,创建新节点Node2_copy。- 对
Node2->next调用copyRandomList(Node3),递归进入Node3的拷贝。
- **第三个节点 **
Node3:递归进入copyRandomList(Node3)。Node3未拷贝过,创建新节点Node3_copy。Node3->next为空,返回nullptr。- 对
Node3->random调用copyRandomList(Node2),检查发现Node2_copy已存在于cachedNode中,直接返回。
- **返回 **
Node3_copy:从Node3_copy返回上一层递归。- 此时
Node2_copy->next = Node3_copy。 - 对
Node2->random调用copyRandomList(Node1),检查发现Node1_copy已存在,直接返回。
- 此时
- **返回 **
Node2_copy:从Node2_copy返回上一层递归。- 此时
Node1_copy->next = Node2_copy。 - 对
Node1->random调用copyRandomList(Node3),检查发现Node3_copy已存在,直接返回。
- 此时
- **返回 **
Node1_copy:所有递归完成,返回Node1_copy,即为复制链表的头节点。
为什么这体现了回溯
在每一层递归中,函数会处理当前节点并尝试向下构建 next 和 random 指针的节点。递归调用完成后,代码会逐层返回,逐步完成链表节点的组装。所以,“回溯”体现在递归调用完成后逐层返回并把结果逐层组装的过程,它不是显式的“返回上一步”操作,而是递归逐层完成的自然返回。
回溯和递归的区别
回溯和递归是两个相关但有区别的概念。
- 递归:是一种编程技巧,指的是函数调用自身的过程。在解决问题时,如果问题可以分解为相似的子问题,我们可以用递归来简化代码。递归的核心是不断分解问题,直到达到基准条件(或称递归终止条件),然后逐层返回结果。例如,阶乘、斐波那契数列计算等都可以使用递归来实现。
- 回溯:是一种算法策略,常用于搜索问题的解空间,比如求解排列、组合、图的路径、迷宫等问题。回溯也用到了递归,但它的核心在于试探和撤回,即尝试去求解一个问题,如果当前路径行不通就返回上一步,尝试其他路径,直到找到一个解或所有路径都尝试完为止。它的关键是“回头走”——如果当前选择不满足条件,就回退一步选择新的分支。
区别
- 递归是技术,用来实现算法逻辑中的逐层调用。
- 回溯是一种算法策略,通常使用递归来实现。回溯是递归的一种应用,但不仅限于递归,也可以用迭代实现。
举个例子
在复制随机链表这类问题中,使用递归的过程只是在链表中逐层递归创建节点;而在组合、排列等问题中使用回溯时,通常需要尝试多条分支路径并在不满足条件时返回,这就是回溯的过程。
692. 前K个高频单词

仿函数(Functor)
仿函数(Functor)是指可以像普通函数一样调用的对象。在C++中,仿函数是通过重载 operator() 来实现的,即将类或结构体的对象变成“可调用”的对象,使得该对象可以像函数一样被使用。
在传统的面向对象编程中,类的对象不能像函数那样直接调用,而仿函数通过实现一个特殊的成员函数 operator(),使得类的对象具有类似函数的行为。
仿函数的定义与使用
1. 定义仿函数:
仿函数是通过定义一个包含 operator() 操作符的类或结构体来实现的。这个 operator() 可以有零个或多个参数,甚至返回值。我们可以在仿函数中实现任何想要的功能。
#include <iostream>
using namespace std;
// 定义一个仿函数类
class Adder {
public:
// 仿函数:重载了 operator()
int operator()(int a, int b) {
return a + b; // 返回两个整数之和
}
};
int main() {
Adder add; // 创建仿函数对象
cout << add(3, 4) << endl; // 使用仿函数,像调用函数一样
return 0;
}
输出:
7
在上面的例子中,Adder 类定义了 operator(),使得 add 对象能够像一个普通函数一样被调用,add(3, 4) 实际上是调用了 Adder 类中的 operator()(int a, int b)。
2. 使用仿函数:
仿函数常见的应用场景包括:
- 算法中的自定义操作:在STL算法(如
std::sort,std::for_each等)中,我们可以使用仿函数传递给算法进行自定义操作。 - 回调函数:仿函数可以作为回调函数,在执行一些操作时执行用户定义的功能。
- 函数对象代替函数指针:仿函数比普通的函数指针更灵活,因为它不仅能传递行为,还能包含状态信息。
仿函数的优势
- 封装了行为:仿函数是一个类或结构体,可以拥有成员变量和成员函数。可以封装和存储状态信息。相比之下,普通函数只能接受参数并返回结果,不能存储额外的状态。
- **可以重载 **
operator():仿函数可以像普通函数一样调用,但它还能有更丰富的功能。通过重载operator(),仿函数可以接受不同的参数类型,也可以有不同的行为。 - 支持状态:仿函数是类的实例,它们可以拥有成员变量,从而支持存储状态。这对于某些需要记住状态的操作(如计数器、累加器等)非常有用。
- 与STL算法结合使用:STL算法(如
std::sort,std::for_each等)经常需要传入某些操作。使用仿函数可以使得操作更加灵活,仿函数可以是带状态的,因此能适应复杂的需求。
仿函数与普通函数的对比
- 普通函数:普通函数是独立的,不具有状态。每次调用时需要传递所有必要的参数。
- 仿函数:仿函数是类的成员,可以拥有状态和行为。可以在调用时动态改变它的状态,具有更强的灵活性。
示例:使用仿函数进行排序
下面是一个使用仿函数与 std::sort 一起排序的例子:
#include <iostream>
#include <vector>
#include <algorithm>
using namespace std;
// 定义一个仿函数类
class Compare {
public:
// 仿函数:重载 operator() 来定义排序的规则
bool operator()(int a, int b) {
return a > b; // 从大到小排序
}
};
int main() {
vector<int> vec = {1, 5, 3, 9, 2};
// 使用仿函数 Compare 来排序
sort(vec.begin(), vec.end(), Compare());
for (int num : vec) {
cout << num << " "; // 输出排序后的结果
}
return 0;
}
输出:
9 5 3 2 1
在这个例子中,Compare 类定义了一个排序规则(从大到小)。通过重载 operator(),我们将该类变成了一个仿函数,可以传递给 std::sort 来控制排序的顺序。
仿函数的应用
- 函数对象:仿函数可以作为函数对象传递给STL算法,例如
std::sort、std::transform等。 - 自定义排序规则:仿函数常常用来定义自定义的排序规则,作为
std::sort的第三个参数。 - 事件处理/回调:在事件驱动编程或回调函数的场景中,仿函数作为事件处理的实现,或者作为回调传递。
- 缓存和状态管理:仿函数可以存储和管理状态,例如计数器、缓存等。
总结
仿函数是通过重载 operator() 使得类的对象具备了像函数一样的调用能力。在C++中,仿函数常用于STL算法中,通过它们可以在算法中传递自定义操作,具备更高的灵活性和状态管理能力。
解法1:
class Solution {
public:
struct KVCompare {
bool operator()(const pair<string, int>& kv1, const pair<string, int>& kv2) {
// 首先按出现次数降序排序,次数相同则按字典顺序升序排序
if (kv1.second == kv2.second) {
return kv1.first < kv2.first; // 字典顺序
}
return kv1.second > kv2.second; // 出现次数降序
}
};
vector<string> topKFrequent(vector<string>& words, int k) {
map<string, int> countMap;
// 将单词及其出现次数放入 countMap 中
for (auto& e : words) {
countMap[e]++;
}
// 将 countMap 的内容转入 vector<pair<string, int>> 中
vector<pair<string, int>> v(countMap.begin(), countMap.end());
// 使用 stable_sort 保证相同频率的单词按照字典顺序排列
stable_sort(v.begin(), v.end(), KVCompare());
vector<string> res;
auto it = v.begin();
while (k--) {
res.push_back(it->first);
it++;
}
return res;
}
};
在 C++ 中,仿函数(或称为函数对象)是一种重载了
operator()的对象,可以像普通函数一样被调用。仿函数的定义可以使用结构体或类,两者的功能是相同的。这里使用结构体的原因主要是出于简化和代码风格的考虑。仿函数为什么可以用结构体?
仿函数(函数对象)本质上是一个包含重载了
operator()的对象,而这个对象的实现可以使用 结构体 或 类。对于这种场景来说,结构体和类的主要区别在于:
- 结构体 的默认访问控制是
public,而 类 的默认访问控制是private。- 结构体 通常用于只包含数据的简单对象,结构体的成员通常是
public,而 类 用于包含更多封装逻辑和行为。由于仿函数的定义通常较简单,只有一个
operator()成员函数和一些数据成员(如果需要的话),所以很多时候选择使用 结构体 来定义仿函数,这样代码更加简洁且清晰。仿函数用结构体的优势
- 简洁性:结构体的默认成员是
public,如果仿函数只需要暴露一个公共函数(例如operator()),使用结构体比类更简洁,避免了显式地声明成员为public。- 代码风格:在 C++ 中,通常用 结构体 来表示简单的数据结构或行为,而用 类 来表示封装性更强、包含更多功能和内部状态的对象。因此,如果仿函数只是为了提供一个简单的排序规则,结构体显得更为符合这种简洁的风格。
例子:仿函数使用结构体的情况
你给出的例子就是使用结构体来定义仿函数,它负责根据
pair<string, int>中的int值进行降序排序,如果出现次数相同则按string的字典顺序升序排序。
这里,结构体
KVCompare重载了operator(),使得它能够作为一个仿函数传递给 STL 容器(如priority_queue)来定制排序规则。
结构体与类的选择
如果你将来需要为仿函数添加更多的成员变量或成员函数,或者你希望更好地控制访问权限(例如把成员设置为
private),可以使用类。而如果仿函数非常简单且只包含公共成员,使用结构体会使代码更加清晰和简洁。使用结构体的情况:
- 只需要包含一个或少量的成员函数。
- 不需要复杂的封装和访问控制。
- 优先考虑简洁和可读性。
使用类的情况:
- 需要复杂的封装和数据管理。
- 成员函数较多,或者需要维护内部状态。
- 需要控制数据成员的访问权限(例如使用
private、protected)。
解法2:优先队列
这种解法的核心思路是使用 优先队列(Priority Queue) 来找到前 k 个频率最高的单词。优先队列能够高效地支持对最大值(或最小值)的快速查询和删除,因此非常适合用于这类问题。
详细思路:
- 统计单词频率:
- 我们首先用
unordered_map来统计每个单词在words中的出现次数。unordered_map<string, int>可以在平均 O(1) 时间内插入和查找元素。
- 我们首先用
- 创建一个优先队列:
- 使用一个小根堆(min-heap)来管理频率最高的 k 个单词。小根堆的特点是堆顶元素是最小的元素,这样可以确保堆中最多只有 k 个元素,当堆的大小超过 k 时,我们可以删除堆顶(即出现频率最小的元素)。
- 比较规则:
- 在优先队列中,元素是单词和它们出现次数的
pair。我们用自定义的比较器cmp来控制堆的排序规则:- 如果两个单词的出现次数相同,那么我们按字典顺序升序排列(即较小的单词排在前面)。
- 如果两个单词的出现次数不同,频率较高的单词排在前面(即频率较大的元素优先)。
- 在优先队列中,元素是单词和它们出现次数的
- 插入到优先队列:
- 对于
unordered_map中的每一个单词及其频率,我们将其插入到优先队列中。 - 每插入一个新元素后,如果优先队列的大小超过了 k,我们就弹出堆顶元素(即删除出现频率最低的元素)。这样优先队列中始终保持着出现频率前 k 高的元素。
- 对于
- 获取结果:
- 最后,优先队列中的元素就是出现次数最多的 k 个单词,但它们的顺序可能是从频率最低到最高的,因此需要通过逐个弹出堆顶元素的方式来得到按频率排序的前 k 个单词。
- 注意:
- 最终返回的是一个包含 k 个单词的向量,要求按频率排序,如果频率相同则按字典顺序排列。
代码解析:
class Solution {
public:
vector<string> topKFrequent(vector<string>& words, int k) {
unordered_map<string, int> cnt;
// 统计单词频率
for (auto& word : words) {
cnt[word]++;
}
// 自定义比较规则:频率相同按字典顺序排序,频率不同按降序排列
auto cmp = [](const pair<string, int>& a, const pair<string, int>& b) {
return a.second == b.second ? a.first < b.first : a.second > b.second;
};
// 小根堆优先队列,按照自定义规则排序
priority_queue<pair<string, int>, vector<pair<string, int>>, decltype(cmp)> que(cmp);
// 将所有单词频率插入到优先队列
for (auto& it : cnt) {
que.emplace(it); // 插入单词及其频率
if (que.size() > k) {
que.pop(); // 如果堆的大小超过 k,就弹出堆顶元素
}
}
// 结果存放在 ret 中,按照出现频率从高到低(及字典顺序)排序
vector<string> ret(k);
for (int i = k - 1; i >= 0; i--) {
ret[i] = que.top().first; // 将堆顶元素(单词)取出,放入结果中
que.pop(); // 弹出堆顶元素
}
return ret;
}
};
详细步骤:
- 统计单词频率:
unordered_map<string, int> cnt;
for (auto& word : words) {
cnt[word]++;
}
- 这段代码统计了 `words` 数组中每个单词的出现次数。`unordered_map` 是一个哈希表,它能够在常数时间内完成查找和插入。
- 创建优先队列:
auto cmp = [](const pair<string, int>& a, const pair<string, int>& b) {
return a.second == b.second ? a.first < b.first : a.second > b.second;
};
priority_queue<pair<string, int>, vector<pair<string, int>>, decltype(cmp)> que(cmp);
- 这里定义了一个 **lambda 表达式** `cmp`,用来比较两个单词频率的大小:
* 如果频率相同,则按字典顺序升序排列。
* 如果频率不同,则按频率降序排列。
- 接着使用该比较规则定义了一个小根堆 `que`,这个优先队列的元素类型是 `pair<string, int>`,即单词及其出现次数。
- 插入元素并维护堆的大小:
for (auto& it : cnt) {
que.emplace(it); // 插入元素到堆中
if (que.size() > k) {
que.pop(); // 如果堆的大小超过 k,就弹出堆顶元素
}
}
- 对于 `cnt` 中的每个元素(即每个单词及其频率),我们将它插入优先队列 `que` 中。
- 如果优先队列的大小超过了 k,我们就弹出堆顶元素,这样保证优先队列中最多只保留 k 个频率最高的单词。
- 从优先队列中取出前 k 个元素:
vector<string> ret(k);
for (int i = k - 1; i >= 0; i--) {
ret[i] = que.top().first; // 获取堆顶元素的单词(即频率最高的)
que.pop(); // 弹出堆顶元素
}
return ret;
- 最后,我们逐个从优先队列中取出单词(按频率从高到低),将它们存放到 `ret` 向量中,并返回结果。
时间复杂度:
- 统计频率:
unordered_map的插入操作平均时间复杂度是 O(1),因此统计频率的时间复杂度是 O(n),其中 n 是words的长度。 - 优先队列插入: 对于每个单词的频率,我们都要插入优先队列。每次插入的时间复杂度是 O(logk),因为队列中最多只能有 k 个元素。因此插入所有单词的时间复杂度是 O(n logk)。
- 取出 k 个元素: 最后从优先队列中取出 k 个元素,每次取出操作是 O(logk),因此取出所有 k 个元素的时间复杂度是 O(k logk)。
349. 两个数组的交集
解法1:set去重
解法思路
这道题的核心任务是找出两个数组中的公共元素,且每个元素只能出现一次。解决思路如下:
- 去重:可以使用
set数据结构,因为<font style="color:#DF2A3F;">set</font>自动去重。 - 查找交集:通过将两个数组转换为
set,可以很方便地进行交集操作。可以遍历一个set,在另一个set中查找是否存在相同的元素。
代码解释
class Solution {
public:
vector<int> intersection(vector<int>& nums1, vector<int>& nums2) {
// 将 nums1 和 nums2 转换为 set,这样可以去重并提供常数时间的查找操作
set<int> s1(nums1.begin(), nums1.end()); // nums1 去重并放入 set
set<int> s2(nums2.begin(), nums2.end()); // nums2 去重并放入 set
vector<int> ret; // 用于存放交集的结果
for (auto e : s2) { // 遍历 s2 中的元素
if (s1.count(e)) { // 如果 s1 中包含 e
ret.push_back(e); // 将 e 加入结果集
}
}
return ret; // 返回结果
}
};
代码详细解析
- 去重操作:
set<int> s1(nums1.begin(), nums1.end());
set<int> s2(nums2.begin(), nums2.end());
- `set<int>` 是一个自动去重的容器,能够保证每个元素只出现一次。这里,我们将 `nums1` 和 `nums2` 转换为两个 `set`,这样就自动去除了数组中的重复元素。
- `set` 的元素会自动按照升序排列(虽然题目没有要求顺序,但它的这一特性有时能帮助我们优化某些问题)。
- 查找交集:
for (auto e : s2) {
if (s1.count(e)) {
ret.push_back(e);
}
}
- 通过遍历 `s2` 中的每个元素 `e`,我们检查 `s1` 中是否包含该元素。这里使用了 `set` 提供的 `count()` 方法,`set.count(e)` 会在 `set` 中查找元素 `e`,如果找到,则返回 `1`,否则返回 `0`。
- 如果 `s1.count(e)` 为真,说明 `e` 是 `nums1` 和 `nums2` 的共同元素,就把它添加到结果数组 `ret` 中。
- 返回结果:
return ret;
- 最后返回交集元素的集合 `ret`,即包含 `nums1` 和 `nums2` 中公共元素的数组。
时间复杂度分析
- 将数组
nums1转换为set:时间复杂度为 O(n),其中n是nums1的元素个数。 - 将数组
nums2转换为set:时间复杂度为 O(m),其中m是nums2的元素个数。 - 遍历
s2中的每个元素并在s1中查找:对于每个元素e,查找操作的时间复杂度是 O(1)(因为set中的查找是常数时间)。所以,这一部分的时间复杂度为 O(m)。
因此,整个算法的时间复杂度为 O(n + m),其中 n 是 nums1 的大小,m 是 nums2 的大小。
空间复杂度分析
- 我们使用了两个
set来存储nums1和nums2中的元素,因此空间复杂度是 O(n + m)。 - 另外,还用了一个
vector来存储结果集,因此空间复杂度总的来说是 O(n + m)。
解法2-双指针法
class Solution {
public:
vector<int> intersection(vector<int>& nums1, vector<int>& nums2) {
// 使用 set 去重,并排序
set<int> s1(nums1.begin(), nums1.end());
set<int> s2(nums2.begin(), nums2.end());
vector<int> ret;
auto it1 = s1.begin();
auto it2 = s2.begin();
// 双指针遍历两个 set
while (it1 != s1.end() && it2 != s2.end()) {
if (*it1 < *it2) {
it1++; // it1 指向较小的元素,向后移动
} else if (*it1 > *it2) {
it2++; // it2 指向较小的元素,向后移动
} else {
ret.push_back(*it1); // 找到交集元素
it1++; // 向后移动指针
it2++; // 向后移动指针
}
}
return ret;
}
};
代码解释:
**set<int> s1(nums1.begin(), nums1.end())**** 和 ****set<int> s2(nums2.begin(), nums2.end())**: 将两个输入数组转换为set,这会自动去除重复的元素,并将元素排序。- **双指针遍历 **
**set**: 使用两个指针it1和it2分别指向两个set的开始位置,进行比较。- 如果
*it1 < *it2,说明it1指向的元素小,应该将it1向后移动。 - 如果
*it1 > *it2,说明it2指向的元素小,应该将it2向后移动。 - 如果
*it1 == *it2,说明找到了交集元素,将其加入结果中,并同时移动两个指针。
- 如果
- 返回交集结果: 最终返回
ret,即两个数组的交集。
复杂度分析:
- 时间复杂度:
- 将两个数组转换为
set的时间复杂度是 O(n log n + m log m),其中n和m分别是两个数组的长度。 - 双指针遍历两个
set的时间复杂度是 O(n + m),因为每个指针最多遍历一次。 - 总时间复杂度为 O(n log n + m log m),其中
n和m是输入数组的大小。
- 将两个数组转换为
- 空间复杂度:
- 存储
set的空间复杂度是 O(n + m),即两个set中的元素总数。 - 最终返回的
ret向量最多包含两个数组中交集的元素,空间复杂度为 O(min(n, m))。
- 存储
因此,总体空间复杂度为 O(n + m)。
这个解法的主要优势在于:
- 使用
set自动去重,简化了代码。 - 双指针法高效地找到了交集元素,避免了暴力算法的时间复杂度问题。

- 📜 [ 声明 ] 由于作者水平有限,本文有错误和不准确之处在所难免,
- 本人也很想知道这些错误,恳望读者批评指正!
- 我是:勇敢滴勇~感谢大家的支持!

欢迎加入DeepSeek 技术社区。在这里,你可以找到志同道合的朋友,共同探索AI技术的奥秘。
更多推荐


 88
88 0
0- 0



 已为社区贡献1条内容
已为社区贡献1条内容

所有评论(0)